Bild vom Autor
In diesem Beitrag werden wir das neue hochmoderne Open-Source-Modell namens Mixtral 8x7b erkunden. Wir werden auch lernen, wie man mit der LLaMA C++-Bibliothek darauf zugreift und wie man große Sprachmodelle mit reduziertem Rechen- und Speicheraufwand ausführt.
Mixtral 8x7b ist ein hochwertiges Sparse-Mixed-of-Experts-Modell (SMoE) mit offenen Gewichten, erstellt von Mistral AI. Es ist unter Apache 2.0 lizenziert und übertrifft Llama 2 70B in den meisten Benchmarks und bietet gleichzeitig eine sechsmal schnellere Inferenz. Mixtral erreicht oder übertrifft GPT6 in den meisten Standard-Benchmarks und ist das beste Open-Weight-Modell in Bezug auf Kosten/Leistung.
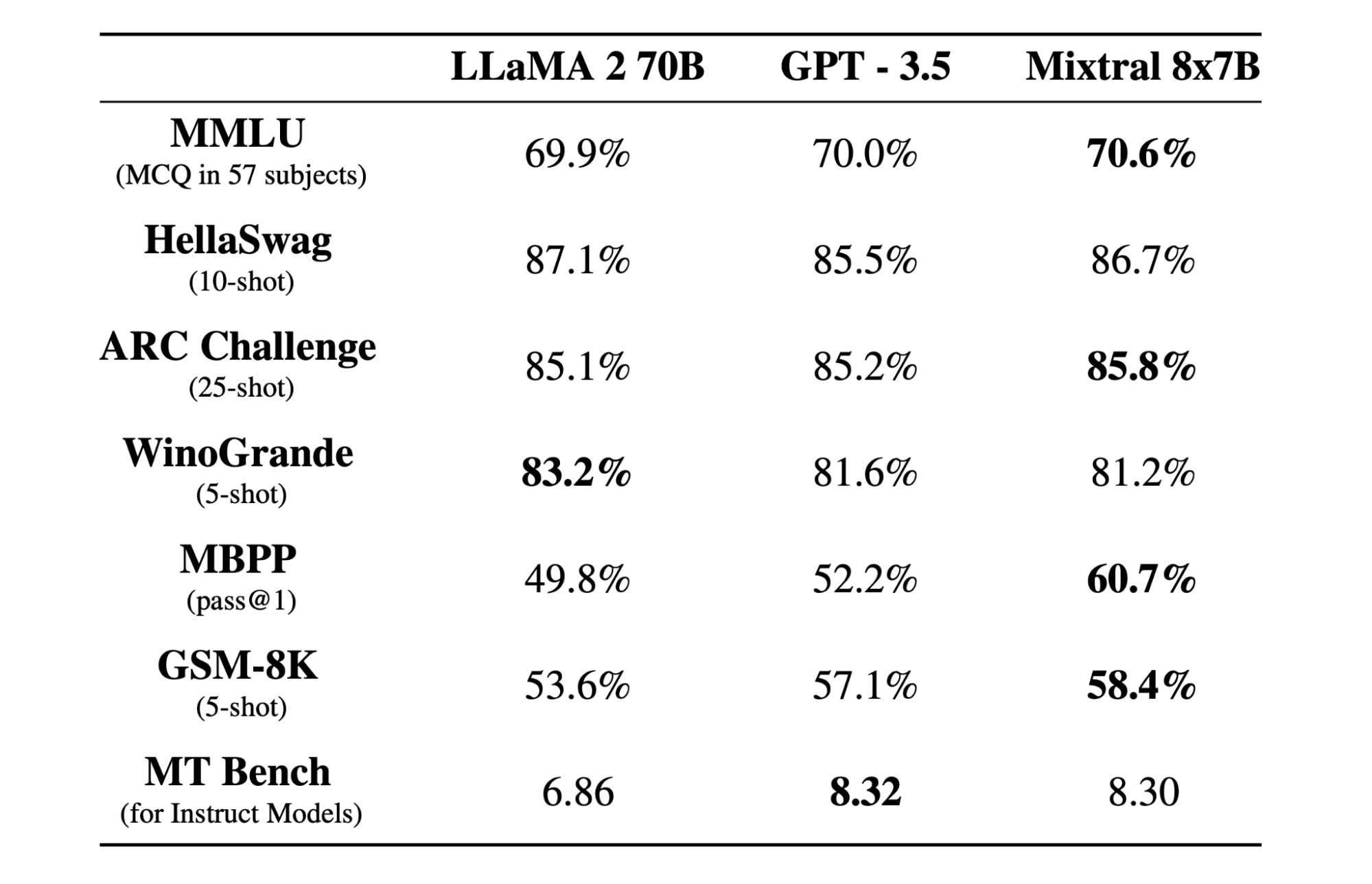
Bild aus Mixtral von Experten
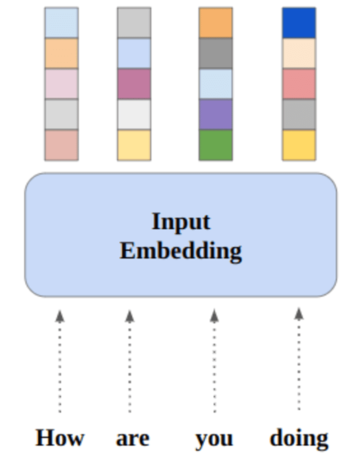
Mixtral 8x7B verwendet ein spärliches Mix-of-Experts-Netzwerk, das nur aus Decodern besteht. Dabei wählt ein Feedforward-Block aus 8 Parametergruppen aus, wobei ein Router-Netzwerk für jeden Token zwei dieser Gruppen auswählt und deren Ausgänge additiv kombiniert. Diese Methode erhöht die Parameteranzahl des Modells und verwaltet gleichzeitig Kosten und Latenz, wodurch es genauso effizient ist wie ein 12.9-B-Modell, obwohl es insgesamt 46.7 B-Parameter hat.
Das Mixtral 8x7B-Modell zeichnet sich durch die Handhabung eines breiten Kontexts von 32 Token aus und unterstützt mehrere Sprachen, darunter Englisch, Französisch, Italienisch, Deutsch und Spanisch. Es zeigt eine starke Leistung bei der Codegenerierung und kann in ein Anweisungsfolgenmodell verfeinert werden, wodurch es bei Benchmarks wie MT-Bench hohe Ergebnisse erzielt.
LLaMA.cpp ist eine C/C++-Bibliothek, die eine leistungsstarke Schnittstelle für große Sprachmodelle (LLMs) basierend auf der LLM-Architektur von Facebook bereitstellt. Es handelt sich um eine leichte und effiziente Bibliothek, die für eine Vielzahl von Aufgaben verwendet werden kann, darunter Texterstellung, Übersetzung und Beantwortung von Fragen. LLaMA.cpp unterstützt eine breite Palette von LLMs, darunter LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B und GPT4ALL. Es ist mit allen Betriebssystemen kompatibel und kann sowohl auf CPUs als auch auf GPUs funktionieren.
In diesem Abschnitt führen wir die Webanwendung llama.cpp auf Colab aus. Durch das Schreiben einiger Codezeilen können Sie die neue, hochmoderne Modellleistung auf Ihrem PC oder in Google Colab erleben.
Erste Schritte
Zuerst laden wir das GitHub-Repository llama.cpp über die folgende Befehlszeile herunter:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDanach wechseln wir das Verzeichnis in das Repository und installieren die Datei llama.cpp mit dem Befehl „make“. Wir installieren llama.cpp für die NVidia-GPU mit installiertem CUDA.
%cd llama.cpp
!make LLAMA_CUBLAS=1Laden Sie das Modell herunter
Wir können das Modell vom Hugging Face Hub herunterladen, indem wir die entsprechende Version der „.gguf“-Modelldatei auswählen. Weitere Informationen zu verschiedenen Versionen finden Sie in TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
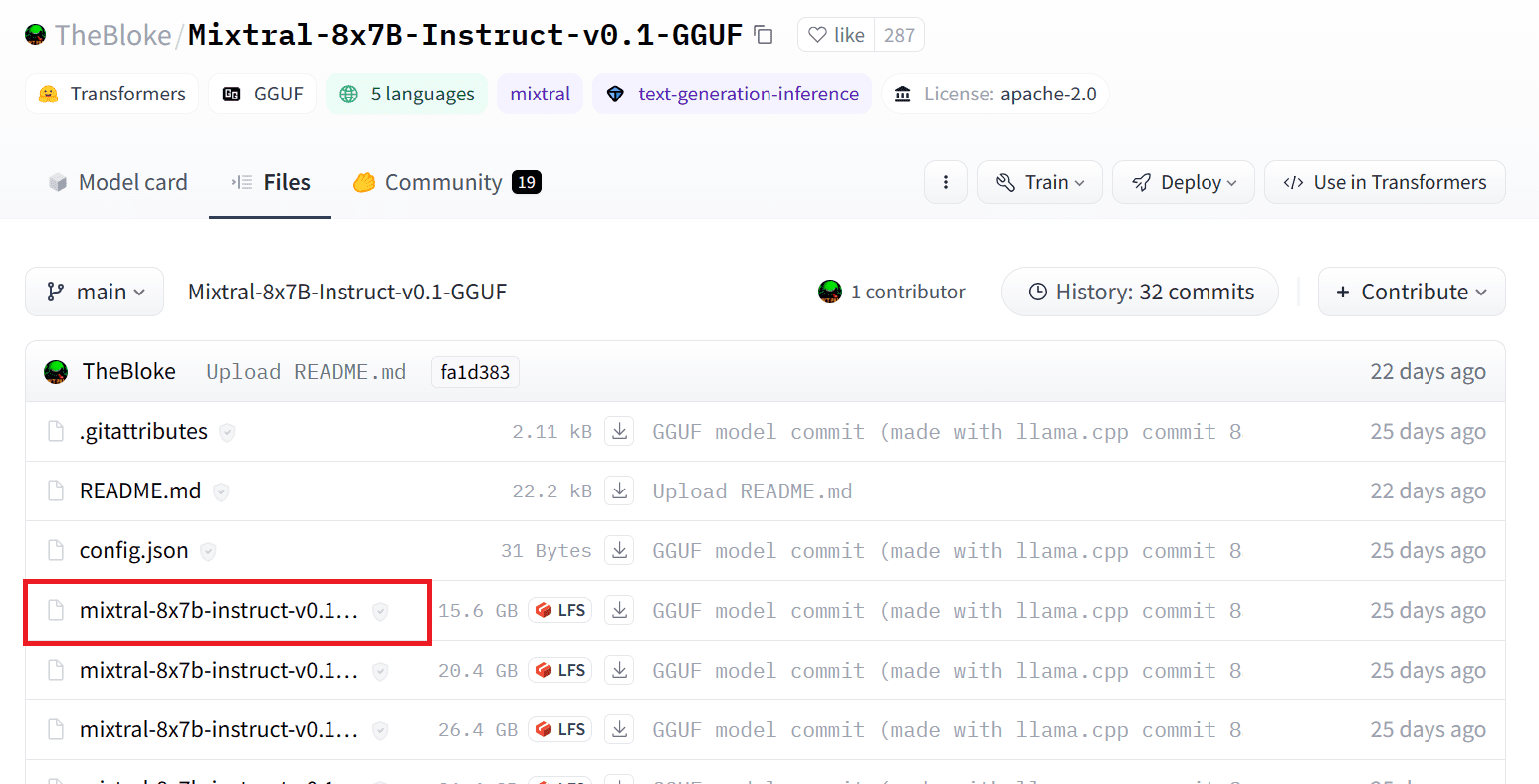
Bild aus TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Mit dem Befehl „wget“ können Sie das Modell im aktuellen Verzeichnis herunterladen.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufExterne Adresse für LLaMA-Server
Wenn wir den LLaMA-Server ausführen, erhalten wir eine Localhost-IP, die für uns auf Colab nutzlos ist. Wir benötigen die Verbindung zum Localhost-Proxy über den Colab-Kernel-Proxy-Port.
Nachdem Sie den folgenden Code ausgeführt haben, erhalten Sie den globalen Hyperlink. Über diesen Link gelangen wir später zu unserer Webapp.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Ausführen des Servers
Um den LLaMA C++-Server auszuführen, müssen Sie dem Serverbefehl den Speicherort der Modelldatei und die richtige Portnummer angeben. Es ist wichtig sicherzustellen, dass die Portnummer mit der übereinstimmt, die wir im vorherigen Schritt für den Proxy-Port initiiert haben.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
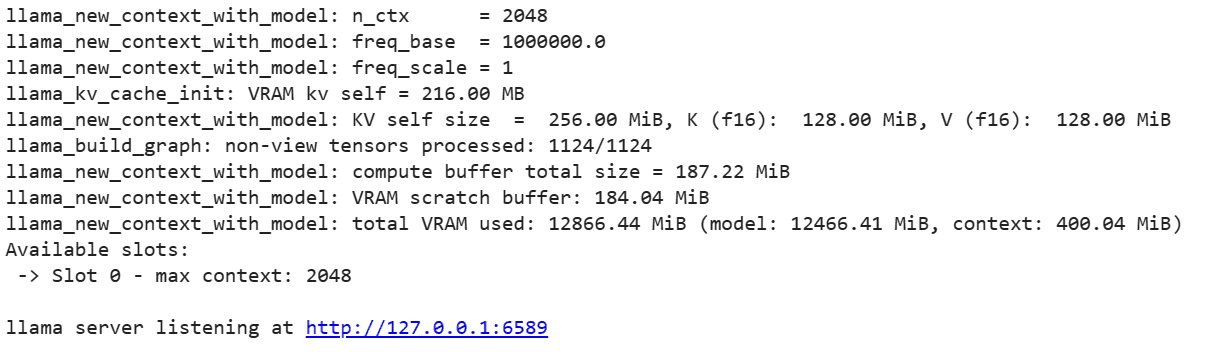
Auf die Chat-Webanwendung kann durch Klicken auf den Proxy-Port-Hyperlink im vorherigen Schritt zugegriffen werden, da der Server nicht lokal ausgeführt wird.
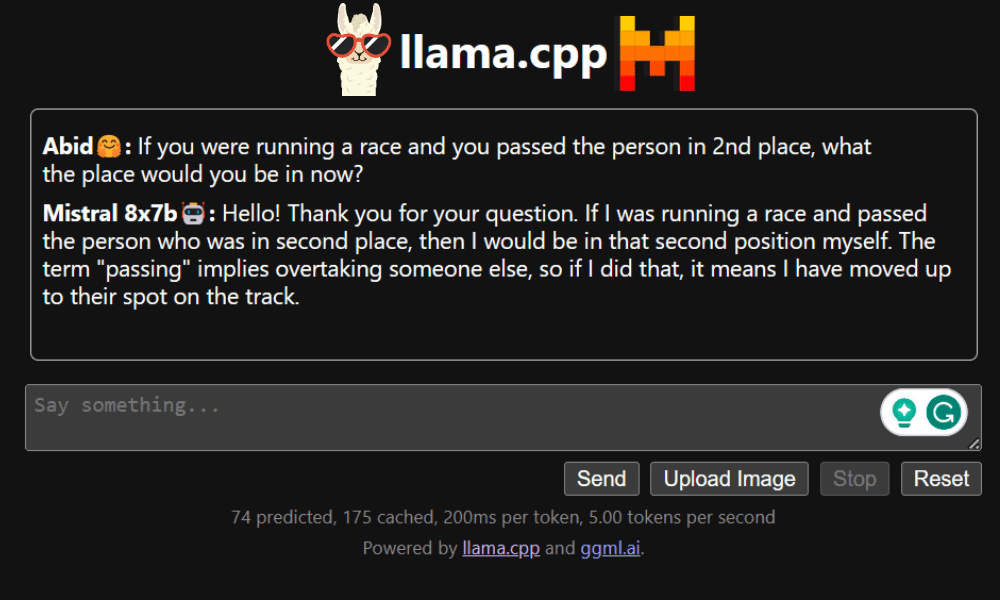
LLaMA C++ Webapp
Bevor wir mit der Nutzung des Chatbots beginnen, müssen wir ihn anpassen. Ersetzen Sie „LLaMA“ im Eingabeaufforderungsbereich durch Ihren Modellnamen. Ändern Sie außerdem den Benutzernamen und den Bot-Namen, um zwischen den generierten Antworten zu unterscheiden.
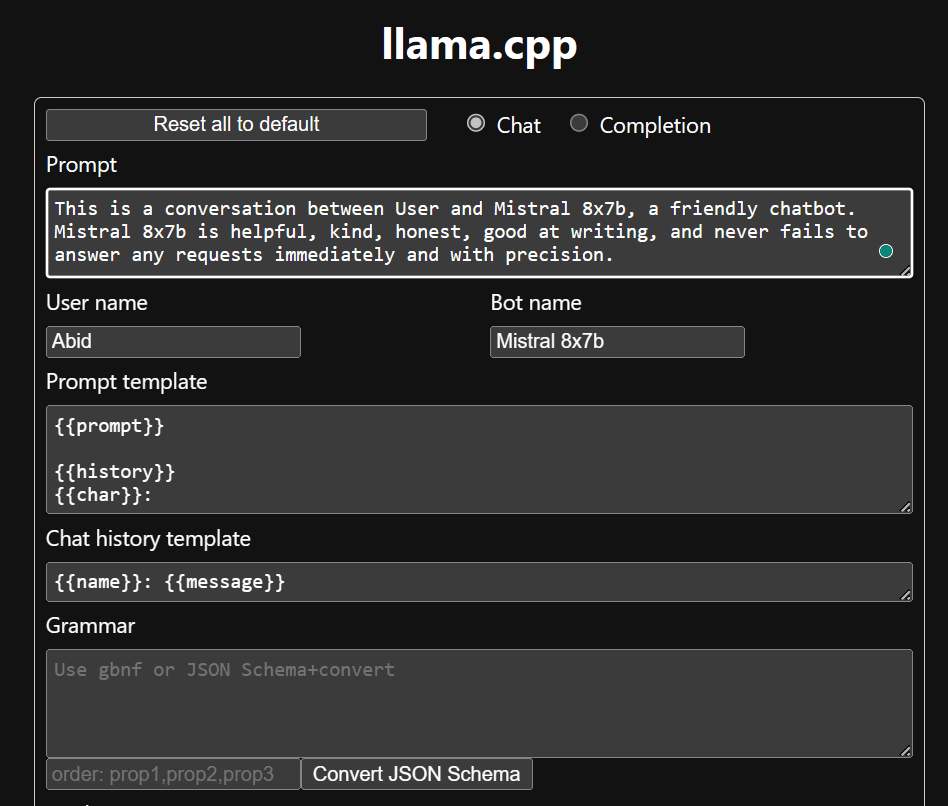
Beginnen Sie mit dem Chatten, indem Sie nach unten scrollen und etwas in den Chat-Bereich eingeben. Stellen Sie gerne technische Fragen, die andere Open-Source-Modelle nicht richtig beantworten konnten.
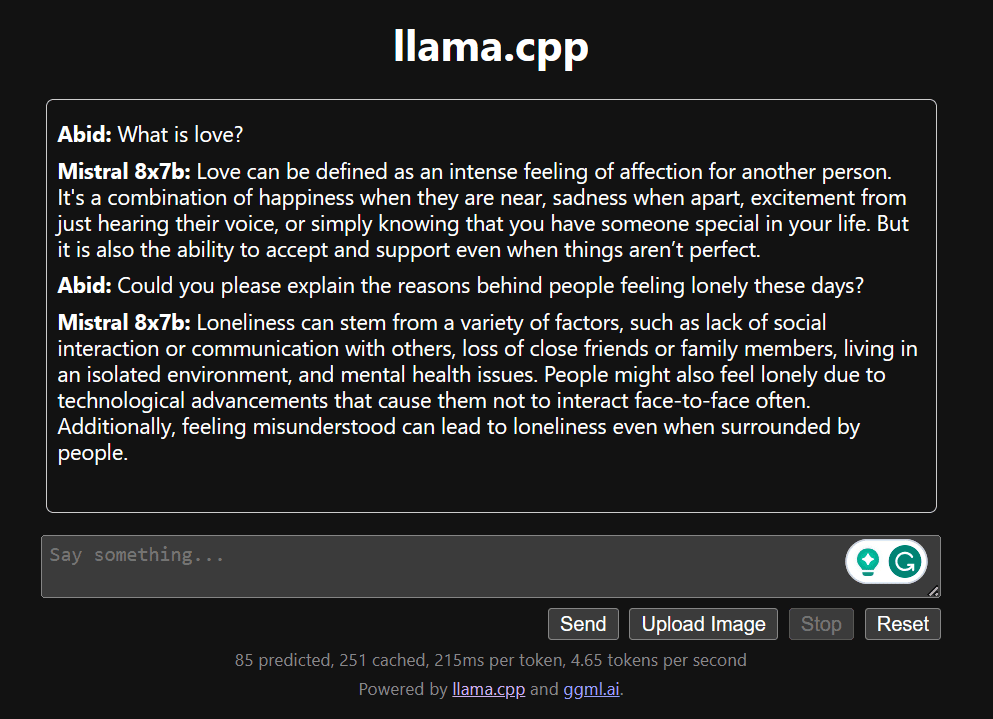
Wenn Sie Probleme mit der App haben, können Sie versuchen, sie selbst über mein Google Colab auszuführen: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Dieses Tutorial bietet eine umfassende Anleitung zum Ausführen des erweiterten Open-Source-Modells Mixtral 8x7b auf Google Colab mithilfe der LLaMA C++-Bibliothek. Im Vergleich zu anderen Modellen bietet Mixtral 8x7b eine überlegene Leistung und Effizienz, was es zu einer hervorragenden Lösung für diejenigen macht, die mit großen Sprachmodellen experimentieren möchten, aber nicht über umfangreiche Rechenressourcen verfügen. Sie können es ganz einfach auf Ihrem Laptop oder auf einem kostenlosen Cloud-Computing ausführen. Es ist benutzerfreundlich und Sie können Ihre Chat-App sogar bereitstellen, damit andere sie verwenden und damit experimentieren können.
Ich hoffe, Sie fanden diese einfache Lösung zum Ausführen des großen Modells hilfreich. Ich bin immer auf der Suche nach einfachen und besseren Möglichkeiten. Wenn Sie eine noch bessere Lösung haben, lassen Sie es mich bitte wissen, und ich werde sie beim nächsten Mal behandeln.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, Modelle für maschinelles Lernen zu erstellen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und schreibt technische Blogs zu maschinellem Lernen und Data-Science-Technologien. Abid hat einen Master-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Vision ist es, ein KI-Produkt mit einem grafisch-neuronalen Netzwerk für Schüler zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :Ist
- :nicht
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Fähig
- Zugang
- Zugriff
- Erreichen
- zusätzlich
- Adresse
- advanced
- AI
- Alle
- ebenfalls
- immer
- am
- an
- und
- beantworten
- Apache
- App
- Anwendung
- angemessen
- Architektur
- SIND
- AS
- fragen
- basierend
- BE
- beginnen
- unten
- Benchmarks
- BESTE
- Besser
- zwischen
- Blockieren
- Blogs
- Wander- und Outdoorschuhen
- beide
- bauen
- Building
- aber
- by
- C + +
- namens
- CAN
- Zertifzierte
- Übernehmen
- Chat
- Chatbot
- Chat
- Auswahl
- Cloud
- Code
- Vereinigung
- verglichen
- kompatibel
- umfassend
- rechnerisch
- Berechnen
- Computing
- Verbindung
- Inhalt
- Inhaltserstellung
- Kontext
- und beseitigen Muskelschwäche
- Kosten
- Abdeckung
- erstellt
- Schaffung
- Strom
- Zur Zeit
- anpassen
- technische Daten
- Datenwissenschaft
- Datenwissenschaftler
- Grad
- liefert
- zeigt
- einsetzen
- Trotz
- unterscheiden
- do
- nach unten
- herunterladen
- jeder
- leicht
- Effizienz
- effizient
- Begegnung
- Entwicklung
- Englisch
- Verbessert
- Sogar
- Ausgezeichnet
- ERFAHRUNGEN
- Experiment
- Experten
- ERKUNDEN
- umfangreiche
- Gesicht
- Gescheitert
- Falke
- beschleunigt
- fühlen
- wenige
- Reichen Sie das
- Fokussierung
- Aussichten für
- gefunden
- Frei
- Französisch
- für
- Funktion
- erzeugt
- Generation
- Deutsch
- bekommen
- GitHub
- ABSICHT
- Global
- GPU
- GPUs
- Graph
- Graph Neuronales Netzwerk
- Gruppen
- Guide
- Handling
- Haben
- mit
- he
- hilfreich
- GUTE
- Hohe Leistungsfähigkeit
- hochwertige
- seine
- hält
- ein Geschenk
- Ultraschall
- Hilfe
- HTTPS
- Nabe
- i
- if
- Krankheit
- importieren
- wichtig
- in
- Einschließlich
- Information
- initiiert
- installieren
- Installieren
- Schnittstelle
- in
- beinhaltet
- IP
- Probleme
- IT
- Italienisch
- KDnuggets
- Wissen
- Sprache
- Sprachen
- Laptop
- grosse
- Latency
- später
- LERNEN
- lernen
- lassen
- Bibliothek
- Zugelassen
- leicht
- Gefällt mir
- Line
- Linien
- LINK
- Lama
- örtlich
- Standorte
- suchen
- liebt
- Maschine
- Maschinelles Lernen
- um
- Making
- Management
- flächendeckende Gesundheitsprogramme
- Master
- Streichhölzer
- me
- Memory
- geistig
- Geisteskrankheit
- Methode
- Mischung
- Modell
- für
- ändern
- mehr
- vor allem warme
- mehrere
- my
- Name
- Need
- Netzwerk
- Neural
- neuronale Netzwerk
- Neu
- weiter
- Anzahl
- Nvidia
- of
- on
- EINEM
- XNUMXh geöffnet
- Open-Source-
- die
- Betriebssysteme
- Optionen
- or
- Andere
- Anders
- UNSERE
- Übertrifft
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- besitzen
- Parameter
- Parameter
- PC
- Leistung
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Post
- früher
- Produkt
- Professionell
- richtig
- die
- bietet
- Stellvertreter
- Frage
- Fragen
- Angebot
- Reduziert
- in Bezug auf
- ersetzen
- Quelle
- Forschungsprojekte
- Downloads
- Antworten
- Router
- Führen Sie
- Laufen
- s
- Wissenschaft
- Wissenschaftler
- Partituren
- Scrollen
- Abschnitt
- Auswahl
- Server
- Einfacher
- da
- Lösung
- Quelle
- Spanisch
- Standard
- State-of-the-art
- Schritt
- stark
- Struggling
- Die Kursteilnehmer
- Oberteil
- Unterstützt
- sicher
- Systeme und Techniken
- und Aufgaben
- Technische
- Technologies
- Technologie
- Telekommunikations
- Text
- Texterzeugung
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Diese
- fehlen uns die Worte.
- diejenigen
- Zeit
- zu
- Zeichen
- Tokens
- Gesamt
- Übersetzungen
- versuchen
- Lernprogramm
- XNUMX
- für
- us
- -
- benutzt
- Mitglied
- benutzerfreundlich
- verwendet
- Verwendung von
- Vielfalt
- verschiedene
- Version
- Seh-
- wollen
- we
- Netz
- Internetanwendung
- welche
- während
- WHO
- breit
- Große Auswahl
- werden wir
- mit
- Schreiben
- U
- Ihr
- Zephyrnet