Ein neu geschaffenes System der künstlichen Intelligenz (KI) auf Basis von Deep Reinforcement Learning (DRL) kann in einer simulierten Umgebung auf Angreifer reagieren und 95 % der Cyberangriffe blockieren, bevor sie eskalieren.
Das sagen die Forscher des Pacific Northwest National Laboratory des Energieministeriums, die eine abstrakte Simulation des digitalen Konflikts zwischen Angreifern und Verteidigern in einem Netzwerk erstellten und vier verschiedene neuronale DRL-Netzwerke trainierten, um die Belohnungen zu maximieren, indem sie Kompromisse verhindern und Netzwerkstörungen minimieren.
Die simulierten Angreifer wandten eine Reihe von Taktiken an, die auf dem basierten MITRE ATT & CK Framework-Klassifizierung, um von der anfänglichen Zugangs- und Aufklärungsphase zu anderen Angriffsphasen überzugehen, bis sie ihr Ziel erreicht haben: die Aufprall- und Exfiltrationsphase.
Das erfolgreiche Training des KI-Systems in der vereinfachten Angriffsumgebung zeigt, dass Verteidigungsreaktionen auf Angriffe in Echtzeit von einem KI-Modell gehandhabt werden könnten, sagt Samrat Chatterjee, ein Datenwissenschaftler, der die Arbeit des Teams auf der Jahrestagung der Association for the vorgestellt hat Advancement of Artificial Intelligence in Washington, DC am 14. Februar.
„Sie wollen nicht zu komplexeren Architekturen übergehen, wenn Sie nicht einmal zeigen können, wie vielversprechend diese Techniken sind“, sagt er. „Wir wollten zunächst zeigen, dass wir ein Tagfahrlicht tatsächlich erfolgreich trainieren und einige gute Testergebnisse zeigen können, bevor wir weitermachen.“
Die Anwendung von Techniken des maschinellen Lernens und der künstlichen Intelligenz auf verschiedene Bereiche der Cybersicherheit hat sich in den letzten zehn Jahren zu einem heißen Trend entwickelt, angefangen bei der frühen Integration des maschinellen Lernens in E-Mail-Sicherheits-Gateways in den frühen 2010s zu neueren Bemühungen um Verwenden Sie ChatGPT, um Code zu analysieren oder forensische Analysen durchführen. Jetzt, die meisten Sicherheitsprodukte haben – oder behaupten zu haben – ein paar Funktionen, die von maschinellen Lernalgorithmen unterstützt werden, die auf großen Datensätzen trainiert wurden.
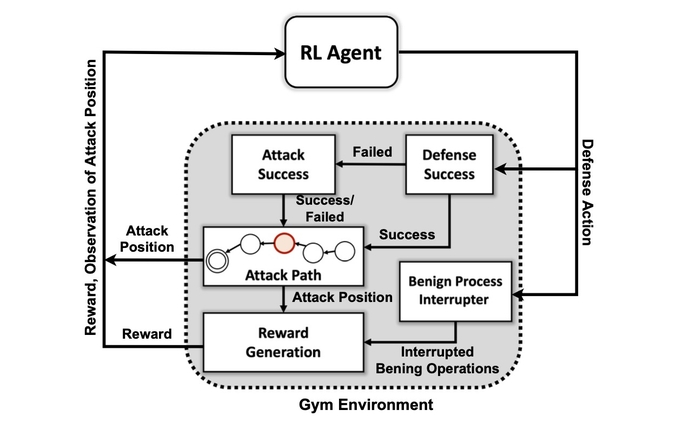
Die Schaffung eines KI-Systems, das zur proaktiven Verteidigung fähig ist, ist jedoch weiterhin eher ehrgeizig als praktisch. Während für Forscher noch eine Reihe von Hürden bestehen bleiben, zeigt die PNNL-Forschung, dass ein KI-Verteidiger in Zukunft möglich sein könnte.
„Die Bewertung mehrerer DRL-Algorithmen, die unter verschiedenen gegnerischen Einstellungen trainiert wurden, ist ein wichtiger Schritt in Richtung praktischer autonomer Cyber-Verteidigungslösungen“, so das PNNL-Forschungsteam in ihrem Papier angegeben. „Unsere Experimente deuten darauf hin, dass modellfreie DRL-Algorithmen unter mehrstufigen Angriffsprofilen mit unterschiedlichen Geschicklichkeits- und Beharrlichkeitsstufen effektiv trainiert werden können, was zu günstigen Verteidigungsergebnissen in umkämpften Umgebungen führt.“
Wie das System MITRE ATT&CK verwendet
Das erste Ziel des Forschungsteams war die Erstellung einer benutzerdefinierten Simulationsumgebung auf der Grundlage eines Open-Source-Toolkits namens Öffnen Sie das AI-Fitnessstudio. Unter Verwendung dieser Umgebung erstellten die Forscher Angreiferentitäten mit unterschiedlichen Fähigkeiten und Beharrlichkeitsstufen mit der Fähigkeit, eine Teilmenge von 7 Taktiken und 15 Techniken aus dem MITRE ATT&CK-Framework zu verwenden.
Die Ziele der Angreifer-Agenten bestehen darin, die sieben Schritte der Angriffskette zu durchlaufen, vom ersten Zugriff bis zur Ausführung, von der Persistenz bis zur Befehls- und Kontrollfunktion und von der Erfassung bis zur Auswirkung.
Für den Angreifer kann es komplex sein, seine Taktik an den Zustand der Umgebung und die aktuellen Aktionen des Verteidigers anzupassen, sagt Chatterjee von PNNL.
„Der Gegner muss seinen Weg von einem anfänglichen Aufklärungszustand bis hin zu einem Exfiltrations- oder Aufprallzustand navigieren“, sagt er. „Wir versuchen nicht, eine Art Modell zu erstellen, um einen Angreifer zu stoppen, bevor er in die Umgebung gelangt – wir gehen davon aus, dass das System bereits kompromittiert ist.“
Die Forscher verwendeten vier Ansätze für neuronale Netze, die auf Reinforcement Learning basieren. Reinforcement Learning (RL) ist ein maschineller Lernansatz, der das Belohnungssystem des menschlichen Gehirns nachahmt. Ein neuronales Netzwerk lernt, indem es bestimmte Parameter für einzelne Neuronen verstärkt oder schwächt, um bessere Lösungen zu belohnen, gemessen an einer Punktzahl, die angibt, wie gut das System funktioniert.
Reinforcement Learning ermöglicht es dem Computer im Wesentlichen, einen guten, aber nicht perfekten Ansatz für das vorliegende Problem zu entwickeln, sagt Mahantesh Halappanavar, ein PNNL-Forscher und Autor des Artikels.
„Ohne Verstärkungslernen könnten wir es immer noch tun, aber es wäre ein wirklich großes Problem, das nicht genug Zeit haben wird, um tatsächlich einen guten Mechanismus zu finden“, sagt er. „Unsere Forschung … gibt uns diesen Mechanismus, bei dem Deep Reinforcement Learning gewissermaßen einen Teil des menschlichen Verhaltens selbst nachahmt, und es kann diesen sehr weiten Raum sehr effizient erforschen.“
Nicht bereit für die Hauptsendezeit
Die Experimente ergaben, dass eine spezifische Reinforcement-Learning-Methode, bekannt als Deep Q Network, eine starke Lösung für das Abwehrproblem geschaffen hat, Fangen 97% der Angreifer im Testdatensatz. Doch die Forschung ist nur der Anfang. Sicherheitsexperten sollten nicht in naher Zukunft nach einem KI-Begleiter suchen, der ihnen bei der Reaktion auf Vorfälle und der Forensik hilft.
Zu den vielen Problemen, die noch gelöst werden müssen, gehört es, Verstärkungslernen und tiefe neuronale Netze dazu zu bringen, die Faktoren zu erklären, die ihre Entscheidungen beeinflusst haben, ein Forschungsgebiet, das als erklärbares Verstärkungslernen (XRL) bezeichnet wird.
Darüber hinaus sind die Robustheit der KI-Algorithmen und das Finden effizienter Wege zum Trainieren der neuronalen Netze beide Probleme, die gelöst werden müssen, sagt Chatterjee von PNNL.
„Ein Produkt zu entwickeln – das war nicht die Hauptmotivation für diese Forschung“, sagt er. „Hier ging es mehr um wissenschaftliches Experimentieren und algorithmische Entdeckungen.“
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- Fähigkeit
- Über Uns
- ABSTRACT
- Zugang
- Nach
- Aktionen
- berührt das Schneidwerkzeug
- Zusatz
- Förderung
- widersprüchlich
- Agenten
- AI
- AI-powered
- algorithmisch
- Algorithmen
- Alle
- erlaubt
- bereits
- Analyse
- analysieren
- und
- jährlich
- Anwendung
- Ansatz
- Ansätze
- Bereich
- künstlich
- künstliche Intelligenz
- Künstliche Intelligenz (AI)
- Verein
- Attacke
- Anschläge
- Autor
- Autonom
- basierend
- werden
- Bevor
- Besser
- zwischen
- Big
- Blockieren
- Gehirn
- erbaut
- namens
- kann keine
- fähig
- sicher
- Kette
- ChatGPT
- Anspruch
- Einstufung
- Sammlung
- wie die
- Komplex
- Kompromittiert
- Computer
- Leiten
- Konflikt
- weiter
- Smartgeräte App
- könnte
- erstellen
- erstellt
- Erstellen
- Strom
- Original
- Cyber-
- Cyber-Angriffe
- Internet-Sicherheit
- technische Daten
- Datenwissenschaftler
- Datensatz
- Datensätze
- dc
- Jahrzehnte
- Entscheidung
- Entscheidungen
- tief
- tiefe neuronale Netze
- Defenders
- Militär
- Abwehr-system
- zeigen
- zeigt
- Abteilung
- Department of Energy
- anders
- digital
- Entdeckung
- Störung
- verschieden
- DOE
- Früh
- effektiv
- effizient
- effizient
- Bemühungen
- E-Mail-Sicherheit
- Energie
- genug
- Entitäten
- Arbeitsumfeld
- im Wesentlichen
- Äther (ETH)
- Auswerten
- Sogar
- Ausführung
- Exfiltration
- Erklären
- ERKUNDEN
- Faktoren
- Eigenschaften
- wenige
- Felder
- Suche nach
- Vorname
- Fluss
- gerichtlich
- Forensik
- vorwärts
- gefunden
- Unser Ansatz
- für
- Zukunft
- bekommen
- bekommen
- gibt
- Kundenziele
- Ziele
- gut
- Pflege
- Hilfe
- HEISS
- Ultraschall
- HTTPS
- human
- Hürden
- Impact der HXNUMXO Observatorien
- wichtig
- in
- Zwischenfall
- Vorfallreaktion
- Anzeige
- Krankengymnastik
- beeinflusst
- Anfangs-
- Integration
- Intelligenz
- IT
- selbst
- Art
- bekannt
- Labor
- grosse
- lernen
- Cholesterinspiegel
- aussehen
- Maschine
- Maschinelles Lernen
- Main
- viele
- max-width
- Maximieren
- Mechanismus
- Treffen
- Methode
- minimieren
- Modell
- mehr
- Motivation
- schlauer bewegen
- ziehen um
- mehrere
- National
- Navigieren
- Need
- Netzwerk
- Netzwerke
- Neural
- neuronale Netzwerk
- Neuronale Netze
- Neuronen
- XNUMXh geöffnet
- Open-Source-
- Andere
- Pazifik
- Papier
- Parameter
- passt
- perfekt
- führt
- Beharrlichkeit
- Phase
- Plato
- Datenintelligenz von Plato
- PlatoData
- möglich
- angetriebene
- Praktisch
- vorgeführt
- Verhütung
- Prime
- Proaktives Handeln
- Aufgabenstellung:
- Probleme
- Produkte
- Profis
- Profil
- Versprechen
- RE
- erreicht
- Reagieren
- Reagiert
- bereit
- echt
- Echtzeit
- kürzlich
- Verstärkung lernen
- bleiben
- Forschungsprojekte
- Forscher
- Forscher
- Antwort
- Belohnen
- Belohnung
- Robustheit
- sagt
- Wissenschaftler
- Sicherheitdienst
- Modellreihe
- kompensieren
- Einstellungen
- sieben
- sollte
- erklären
- Konzerte
- vereinfachte
- Simulation
- Geschicklichkeit
- Lösung
- Lösungen
- einige
- Bald
- Quelle
- Raumfahrt
- spezifisch
- Anfang
- Bundesstaat
- Schritt
- Shritte
- Immer noch
- Stoppen
- Stärkung
- stark
- erfolgreich
- Erfolgreich
- System
- Taktik
- Team
- Techniken
- Testen
- Das
- Die Zukunft
- Der Staat
- ihr
- Durch
- Zeit
- zu
- Toolkit
- gegenüber
- Training
- trainiert
- Ausbildung
- Trend
- für
- us
- -
- Vielfalt
- riesig
- wollte
- Washington
- Wege
- während
- WHO
- werden wir
- .
- ohne
- Arbeiten
- würde
- nachgiebig
- Zephyrnet











