Im heutigen digitalen Zeitalter sind Daten das Herzstück des Erfolgs jedes Unternehmens. Eines der am häufigsten verwendeten Formate für den Datenaustausch ist XML. Die Analyse von XML-Dateien ist aus mehreren Gründen von entscheidender Bedeutung. Erstens werden XML-Dateien in vielen Branchen verwendet, darunter im Finanzwesen, im Gesundheitswesen und in der Regierung. Die Analyse von XML-Dateien kann Unternehmen dabei helfen, Einblicke in ihre Daten zu gewinnen und so bessere Entscheidungen zu treffen und ihre Abläufe zu verbessern. Auch die Analyse von XML-Dateien kann bei der Datenintegration hilfreich sein, da viele Anwendungen und Systeme XML als Standarddatenformat verwenden. Durch die Analyse von XML-Dateien können Unternehmen problemlos Daten aus verschiedenen Quellen integrieren und die Konsistenz ihrer Systeme sicherstellen. XML-Dateien enthalten jedoch halbstrukturierte, stark verschachtelte Daten, was den Zugriff auf und die Analyse von Informationen erschwert, insbesondere wenn die Datei groß ist komplexes, stark verschachteltes Schema.
XML-Dateien eignen sich gut für Anwendungen, für Analyse-Engines sind sie jedoch möglicherweise nicht optimal. Um die Abfrageleistung zu verbessern und einen einfachen Zugriff in nachgelagerten Analyse-Engines wie z. B. zu ermöglichen Amazonas Athenaist es wichtig, XML-Dateien in ein Spaltenformat wie Parquet vorzuverarbeiten. Diese Transformation ermöglicht eine verbesserte Effizienz und Benutzerfreundlichkeit in Analyse-Workflows. In diesem Beitrag zeigen wir, wie man XML-Daten verarbeitet AWS-Kleber und Athena.
Lösungsüberblick
Wir untersuchen zwei unterschiedliche Techniken, die Ihren XML-Dateiverarbeitungsworkflow optimieren können:
- Technik 1: Verwenden Sie einen AWS Glue-Crawler und den visuellen Editor von AWS Glue – Sie können die AWS Glue-Benutzeroberfläche in Verbindung mit einem Crawler verwenden, um die Tabellenstruktur für Ihre XML-Dateien zu definieren. Dieser Ansatz bietet eine benutzerfreundliche Oberfläche und eignet sich besonders für Personen, die einen grafischen Ansatz zur Verwaltung ihrer Daten bevorzugen.
- Technik 2: Verwenden Sie AWS Glue DynamicFrames mit abgeleiteten und festen Schemata – Der Crawler hat eine Einschränkung, wenn es darum geht, eine einzelne Zeile in XML-Dateien zu verarbeiten, die größer als sind 1 MB
. Um diese Einschränkung zu überwinden, verwenden wir ein AWS Glue-Notebook, um AWS Glue zu erstellen
DynamicFrames, wobei sowohl abgeleitete als auch feste Schemata verwendet werden. Diese Methode gewährleistet eine effiziente Verarbeitung von XML-Dateien mit Zeilen, die größer als 1 MB sind.
Bei beiden Ansätzen besteht unser oberstes Ziel darin, XML-Dateien in das Apache-Parquet-Format zu konvertieren und sie so für die Abfrage mit Athena verfügbar zu machen. Mit diesen Techniken können Sie die Verarbeitungsgeschwindigkeit und Zugänglichkeit Ihrer XML-Daten verbessern und so problemlos wertvolle Erkenntnisse gewinnen.
Voraussetzungen:
Bevor Sie mit diesem Tutorial beginnen, erfüllen Sie die folgenden Voraussetzungen (diese gelten für beide Techniken):
- Laden Sie die XML-Dateien herunter Technik1.xml und Technik2.xml.
- Laden Sie die Dateien auf eine hoch Amazon Simple Storage-Service (Amazon S3) Eimer. Sie können sie in verschiedene Ordner oder in verschiedene S3-Buckets in denselben S3-Bucket hochladen.
- Erstellen Sie ein AWS Identity and Access Management and (IAM)-Rolle für Ihren ETL-Job oder Ihr Notebook, wie in beschrieben Richten Sie IAM-Berechtigungen für AWS Glue Studio ein.
- Fügen Sie Ihrer Rolle eine Inline-Richtlinie hinzu iam:PassRole Aktion:
- Fügen Sie der Rolle mit Zugriff auf Ihren S3-Bucket eine Berechtigungsrichtlinie hinzu.
Nachdem wir nun mit den Voraussetzungen fertig sind, fahren wir mit der Implementierung der ersten Technik fort.
Technik 1: Verwenden Sie einen AWS Glue-Crawler und den visuellen Editor
Das folgende Diagramm veranschaulicht die einfache Architektur, die Sie zur Implementierung der Lösung verwenden können.
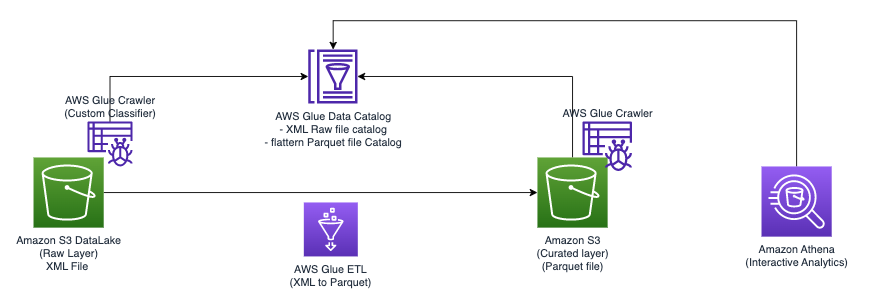
Um in Amazon S3 gespeicherte XML-Dateien mit AWS Glue und Athena zu analysieren, führen wir die folgenden allgemeinen Schritte aus:
- Erstellen Sie einen AWS Glue-Crawler, um XML-Metadaten zu extrahieren und eine Tabelle im AWS Glue-Datenkatalog zu erstellen.
- Verarbeiten und transformieren Sie XML-Daten in ein für Athena geeignetes Format (wie Parquet) mithilfe eines AWS Glue-ETL-Auftrags (Extrahieren, Transformieren und Laden).
- Richten Sie einen AWS Glue-Auftrag über die AWS Glue-Konsole oder das ein und führen Sie ihn aus AWS-Befehlszeilenschnittstelle (AWS-CLI).
- Verwenden Sie die verarbeiteten Daten (im Parquet-Format) mit Athena-Tabellen und ermöglichen Sie so SQL-Abfragen.
- Nutzen Sie die benutzerfreundliche Oberfläche in Athena, um die XML-Daten mit SQL-Abfragen auf Ihre in Amazon S3 gespeicherten Daten zu analysieren.
Diese Architektur ist eine skalierbare, kostengünstige Lösung für die Analyse von XML-Daten auf Amazon S3 mit AWS Glue und Athena. Sie können große Datensätze ohne komplexes Infrastrukturmanagement analysieren.
Wir verwenden den AWS Glue-Crawler, um XML-Dateimetadaten zu extrahieren. Sie können den standardmäßigen AWS Glue-Klassifikator für die allgemeine XML-Klassifizierung auswählen. Es erkennt automatisch die XML-Datenstruktur und das XML-Schema, was für gängige Formate nützlich ist.
Wir verwenden in dieser Lösung auch einen benutzerdefinierten XML-Klassifikator. Es wurde für bestimmte XML-Schemas oder -Formate entwickelt und ermöglicht eine präzise Metadatenextraktion. Dies ist ideal für nicht standardmäßige XML-Formate oder wenn Sie eine detaillierte Kontrolle über die Klassifizierung benötigen. Ein benutzerdefinierter Klassifikator stellt sicher, dass nur die erforderlichen Metadaten extrahiert werden, wodurch nachgelagerte Verarbeitungs- und Analyseaufgaben vereinfacht werden. Dieser Ansatz optimiert die Nutzung Ihrer XML-Dateien.
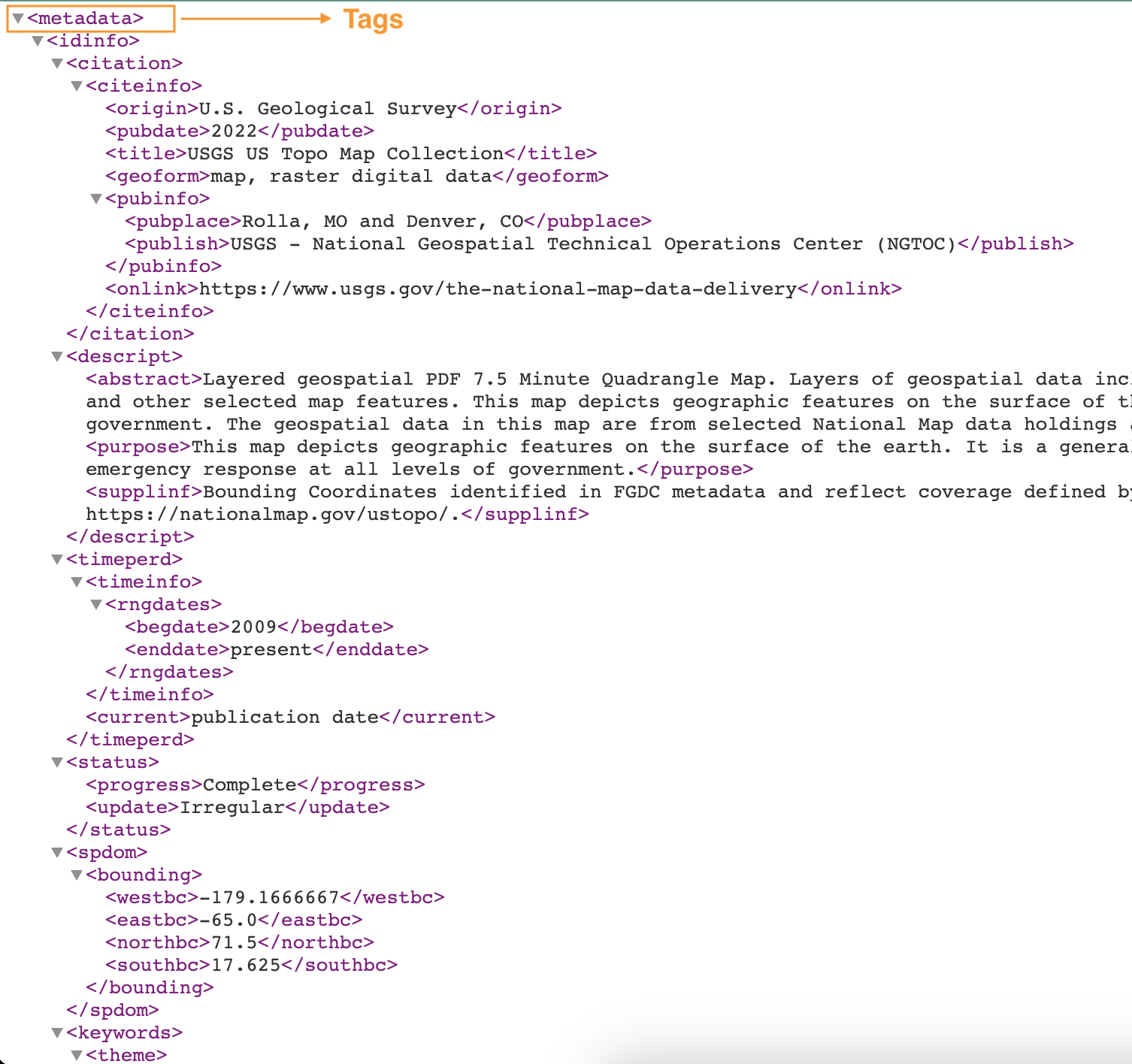
Der folgende Screenshot zeigt ein Beispiel einer XML-Datei mit Tags.
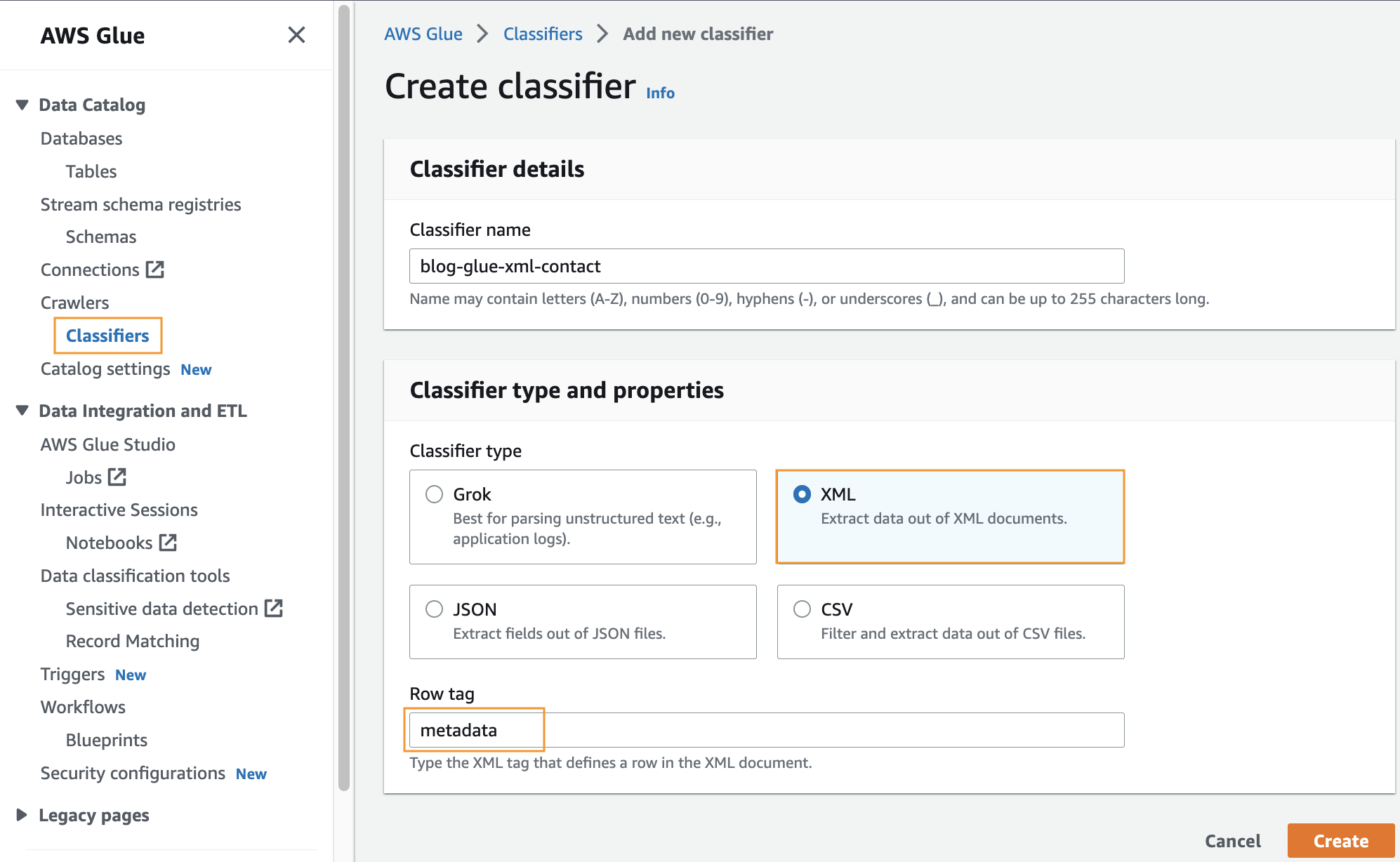
Erstellen Sie einen benutzerdefinierten Klassifikator
In diesem Schritt erstellen Sie einen benutzerdefinierten AWS Glue-Klassifikator, um Metadaten aus einer XML-Datei zu extrahieren. Führen Sie die folgenden Schritte aus:
- Auf der AWS Glue-Konsole unter Crawlers Wählen Sie im Navigationsbereich Sichter.
- Auswählen Klassifikator hinzufügen.
- Auswählen XML als Klassifikatortyp.
- Geben Sie einen Namen für den Klassifikator ein, z
blog-glue-xml-contact. - Aussichten für Zeilen-TagGeben Sie den Namen des Root-Tags ein, das die Metadaten enthält (z. B.
metadata). - Auswählen Erstellen.
Erstellen Sie einen AWS Glue Crawler zum Crawlen der XML-Datei
In diesem Abschnitt erstellen wir einen Glue Crawler, um die Metadaten aus der XML-Datei mithilfe des im vorherigen Schritt erstellten Kundenklassifikators zu extrahieren.
Erstellen Sie eine Datenbank
- Gehen Sie zum AWS Glue-Konsole, wählen Datenbanken im Navigationsbereich.
- Klicken Sie auf Datenbank hinzufügen.
- Geben Sie einen Namen ein, z
blog_glue_xml - Auswählen Erstellen Datenbase
Erstellen Sie einen Crawler
Führen Sie die folgenden Schritte aus, um Ihren ersten Crawler zu erstellen:
- Wählen Sie in der AWS Glue-Konsole aus Crawlers im Navigationsbereich.
- Auswählen Crawler erstellen.
- Auf dem Legen Sie Crawler-Eigenschaften fest Geben Sie auf der Seite einen Namen für den neuen Crawler ein (z. B
blog-glue-parquet), dann wähle Weiter. - Auf dem Wählen Sie Datenquellen und Klassifikatoren Seite auswählen Noch nicht für Konfiguration der Datenquelle.
- Auswählen Fügen Sie einen Datenspeicher hinzu.
- Aussichten für S3-Pfad, navigieren Sie zu
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Stellen Sie sicher, dass Sie den XML-Ordner und nicht die Datei im Ordner auswählen.
- Belassen Sie die restlichen Optionen als Standard und wählen Sie Fügen Sie eine S3-Datenquelle hinzu.
- Erweitern Sie die Funktionalität der Benutzerdefinierte Klassifikatoren – optional, wählen Sie „blog-glue-xml-contact“ und dann „ Weiter und behalten Sie die restlichen Optionen als Standard bei.
- Wählen Sie Ihre IAM-Rolle oder wählen Sie Neue IAM-Rolle erstellen, fügen Sie das Suffix hinzu
glue-xml-contact(zum Beispiel,AWSGlueServiceNotebookRoleBlog), und wähle Weiter. - Auf dem Ausgabe und Zeitplanung festlegen Seite unter Ausgabekonfiguration, wählen
blog_glue_xmlfür Zieldatenbank. - Enter
console_als Präfix, das Tabellen hinzugefügt wird (optional) und darunter Crawler-Zeitplan, behalten Sie die Frequenzeinstellung bei Auf Nachfrage. - Auswählen Weiter.
- Überprüfen Sie alle Parameter und wählen Sie aus Crawler erstellen.
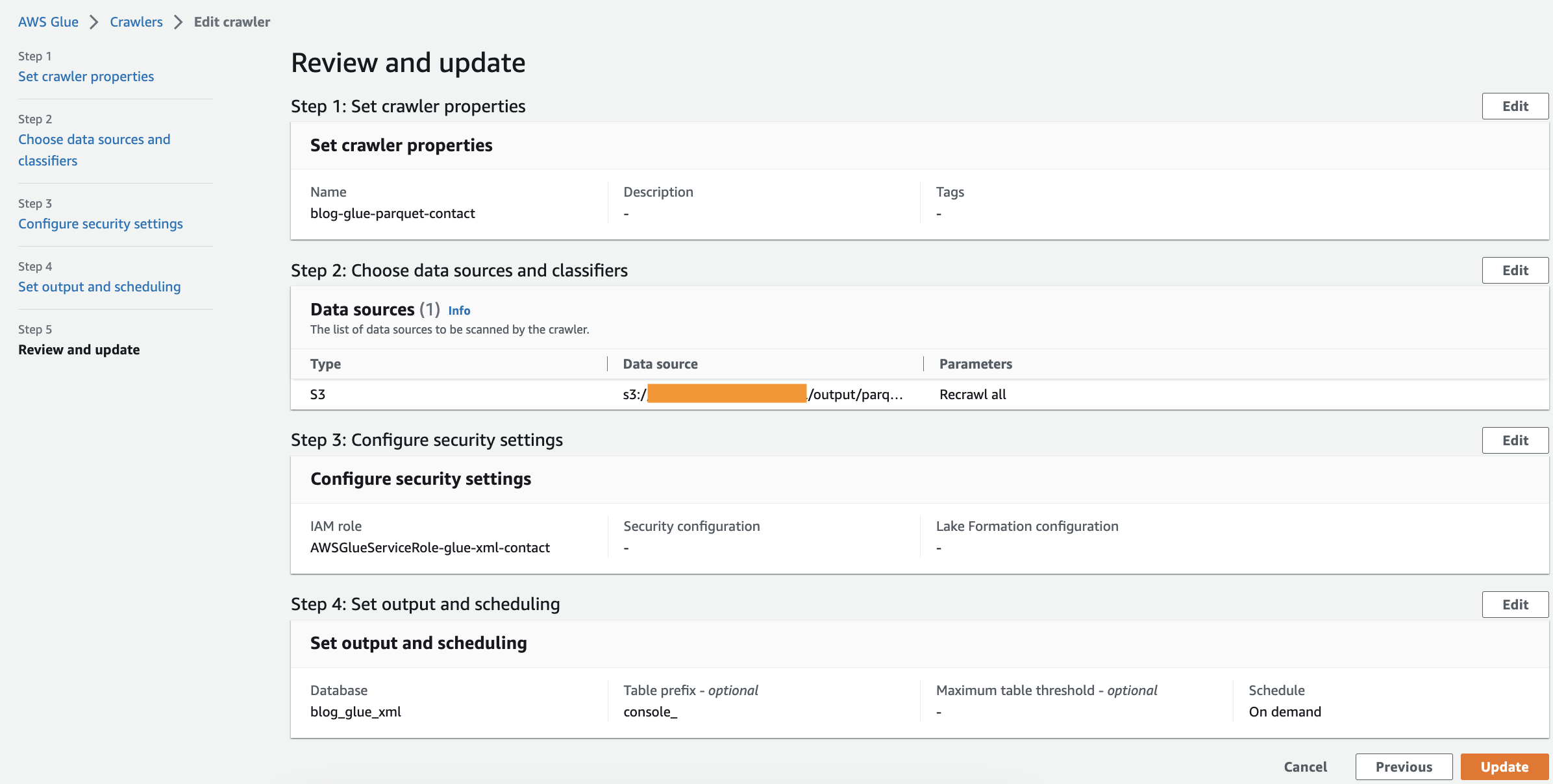
Führen Sie den Crawler aus
Nachdem Sie den Crawler erstellt haben, führen Sie die folgenden Schritte aus, um ihn auszuführen:
- Wählen Sie in der AWS Glue-Konsole aus Crawlers im Navigationsbereich.
- Öffnen Sie den von Ihnen erstellten Crawler und wählen Sie aus Führen Sie.
Die Fertigstellung des Crawlers dauert 1–2 Minuten.
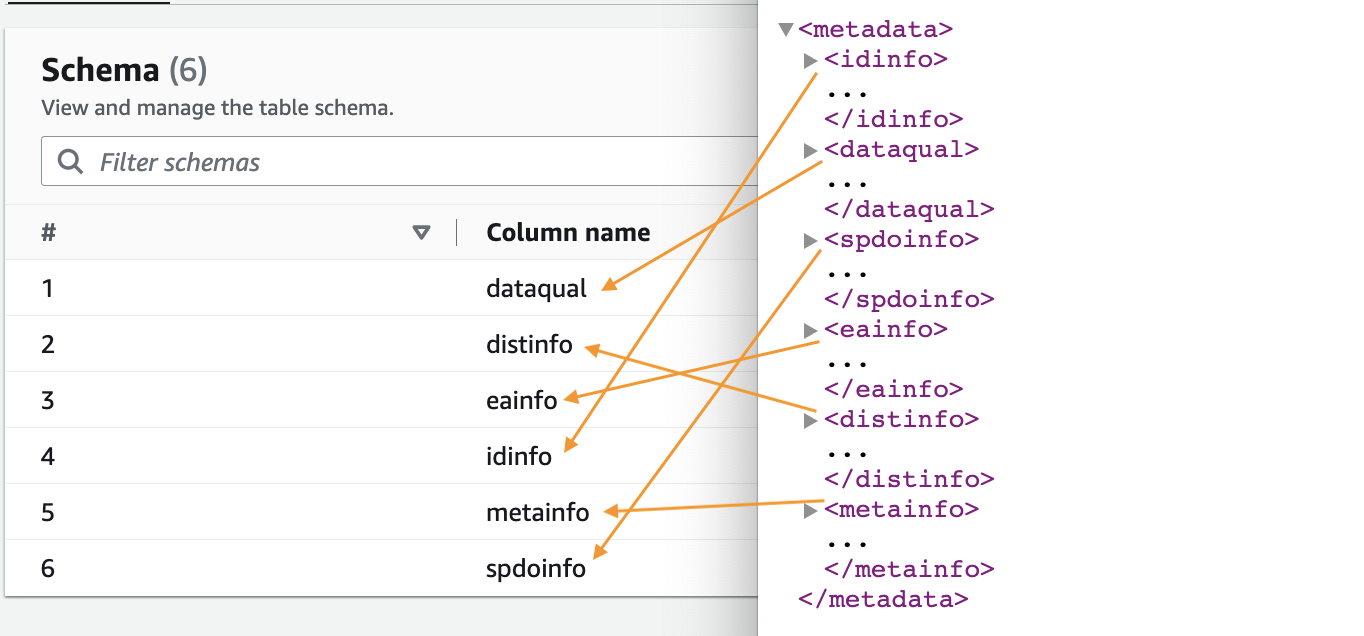
- Wenn der Crawler fertig ist, wählen Sie Datenbanken im Navigationsbereich.
- Wählen Sie die von Ihnen erstellte Datenbank und den Tabellennamen aus, um das vom Crawler extrahierte Schema anzuzeigen.
Erstellen Sie einen AWS Glue-Auftrag, um das XML in das Parquet-Format zu konvertieren
In diesem Schritt erstellen Sie einen AWS Glue Studio-Auftrag, um die XML-Datei in eine Parquet-Datei zu konvertieren. Führen Sie die folgenden Schritte aus:
- Wählen Sie in der AWS Glue-Konsole aus Jobs im Navigationsbereich.
- Der Job erstellenWählen Visuell mit einer leeren Leinwand.
- Auswählen Erstellen.
- Benennen Sie den Job um in
blog_glue_xml_job.
Jetzt haben Sie einen leeren visuellen Job-Editor für AWS Glue Studio. Oben im Editor befinden sich die Registerkarten für verschiedene Ansichten.
- Wähle die Skript Klicken Sie auf die Registerkarte, um eine leere Shell des AWS Glue ETL-Skripts anzuzeigen.
Wenn wir im visuellen Editor neue Schritte hinzufügen, wird das Skript automatisch aktualisiert.
- Wähle die Jobdetails Klicken Sie auf die Registerkarte, um alle Jobkonfigurationen anzuzeigen.
- Aussichten für IAM-Rolle, wählen
AWSGlueServiceNotebookRoleBlog. - Aussichten für Klebeversion, wählen Glue 4.0 – Unterstützt Spark 3.3, Scala 2, Python 3.
- Sept Angeforderte Anzahl von Arbeitern um 2.
- Sept Anzahl der Wiederholungen um 0.
- Wähle die visuell Klicken Sie auf die Registerkarte, um zum visuellen Editor zurückzukehren.
- Auf dem Quelle Dropdown-Menü auswählen AWS Glue-Datenkatalog.
- Auf dem Datenquelleneigenschaften – Datenkatalog Geben Sie auf der Registerkarte die folgenden Informationen an:
- Aussichten für Datenbase, wählen
blog_glue_xml. - Aussichten für Tisch, wählen Sie die Tabelle aus, die mit dem Namen console_ beginnt, den der Crawler erstellt hat (z. B.
console_geologicalsurvey).
- Aussichten für Datenbase, wählen
- Auf dem Knoteneigenschaften Geben Sie auf der Registerkarte die folgenden Informationen an:
- Change Name und Vorname zu
geologicalsurveyDatensatz. - Auswählen Action und die Transformation Schema ändern (Zuordnung anwenden).
- Auswählen
Knoteneigenschaften und ändern Sie den Namen der Transformation von Schema ändern (Zuordnung anwenden) in
ApplyMapping. - Auf dem Target Menü, wählen Sie S3.
- Change Name und Vorname zu
- Auf dem Datenquelleneigenschaften - S3 Geben Sie auf der Registerkarte die folgenden Informationen an:
- Aussichten für FormatWählen Parkett.
- Aussichten für KomprimierungsartWählen Unkomprimiert.
- Aussichten für S3-QuellentypWählen S3 Standort.
- Aussichten für S3-URL, eingeben
s3://${BUCKET_NAME}/output/parquet/. - Auswählen
Knoteneigenschaften und ändern Sie den Namen in
Output.
- Auswählen Speichern um die Arbeit zu retten.
- Auswählen Führen Sie um den Job auszuführen.
Der folgende Screenshot zeigt den Job im visuellen Editor.
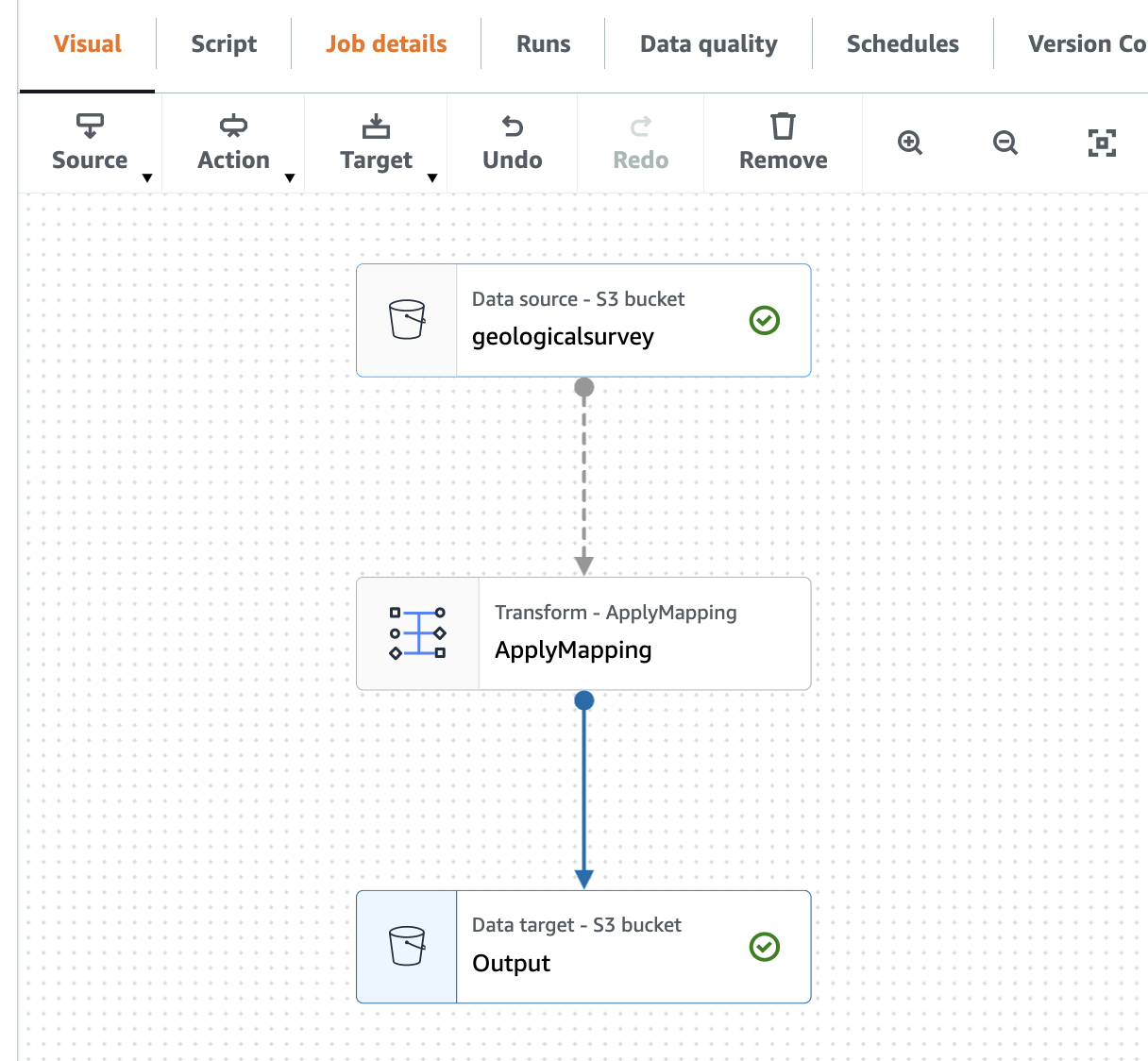
Erstellen Sie einen AWS Gue Crawler, um die Parquet-Datei zu crawlen
In diesem Schritt erstellen Sie einen AWS Glue-Crawler, um Metadaten aus der Parquet-Datei zu extrahieren, die Sie mit einem AWS Glue Studio-Auftrag erstellt haben. Dieses Mal verwenden Sie den Standardklassifikator. Führen Sie die folgenden Schritte aus:
- Wählen Sie in der AWS Glue-Konsole aus Crawlers im Navigationsbereich.
- Auswählen Crawler erstellen.
- Auf dem Legen Sie Crawler-Eigenschaften fest Geben Sie auf der Seite einen Namen für den neuen Crawler ein, z. B. blog-glue-parquet-contact, und wählen Sie dann aus Weiter.
- Auf dem Wählen Sie Datenquellen und Klassifikatoren Seite auswählen Noch nicht für Konfiguration der Datenquelle.
- Auswählen Fügen Sie einen Datenspeicher hinzu.
- Aussichten für S3-Pfad, navigieren Sie zu
s3://${BUCKET_NAME}/output/parquet/.
Stellen Sie sicher, dass Sie das auswählen parquet Ordner und nicht die Datei im Ordner.
- Wählen Sie Ihre IAM-Rolle aus, die im Abschnitt „Voraussetzungen“ erstellt wurde, oder wählen Sie „ Neue IAM-Rolle erstellen (zum Beispiel,
AWSGlueServiceNotebookRoleBlog), und wähle Weiter. - Auf dem Ausgabe und Zeitplanung festlegen Seite unter Ausgabekonfiguration, wählen
blog_glue_xmlfür Datenbase. - Enter
parquet_als Präfix, das Tabellen hinzugefügt wird (optional) und darunter Crawler-Zeitplan, behalten Sie die Frequenzeinstellung bei Auf Nachfrage. - Auswählen Weiter.
- Überprüfen Sie alle Parameter und wählen Sie aus Crawler erstellen.
Jetzt können Sie den Crawler ausführen, was 1–2 Minuten dauert.

Sie können eine Vorschau des neu erstellten Schemas für die Parquet-Datei im AWS Glue-Datenkatalog anzeigen, das dem Schema der XML-Datei ähnelt.
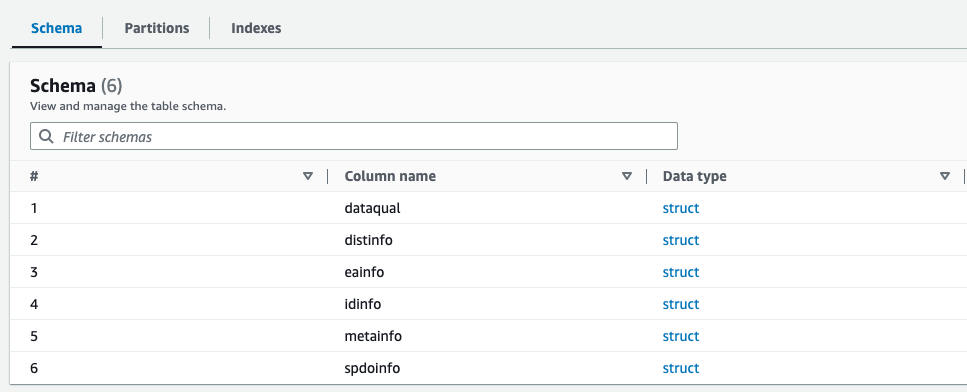
Wir verfügen nun über Daten, die für die Verwendung mit Athena geeignet sind. Im nächsten Abschnitt führen wir Datenabfragen mit Athena durch.
Fragen Sie die Parquet-Datei mit Athena ab
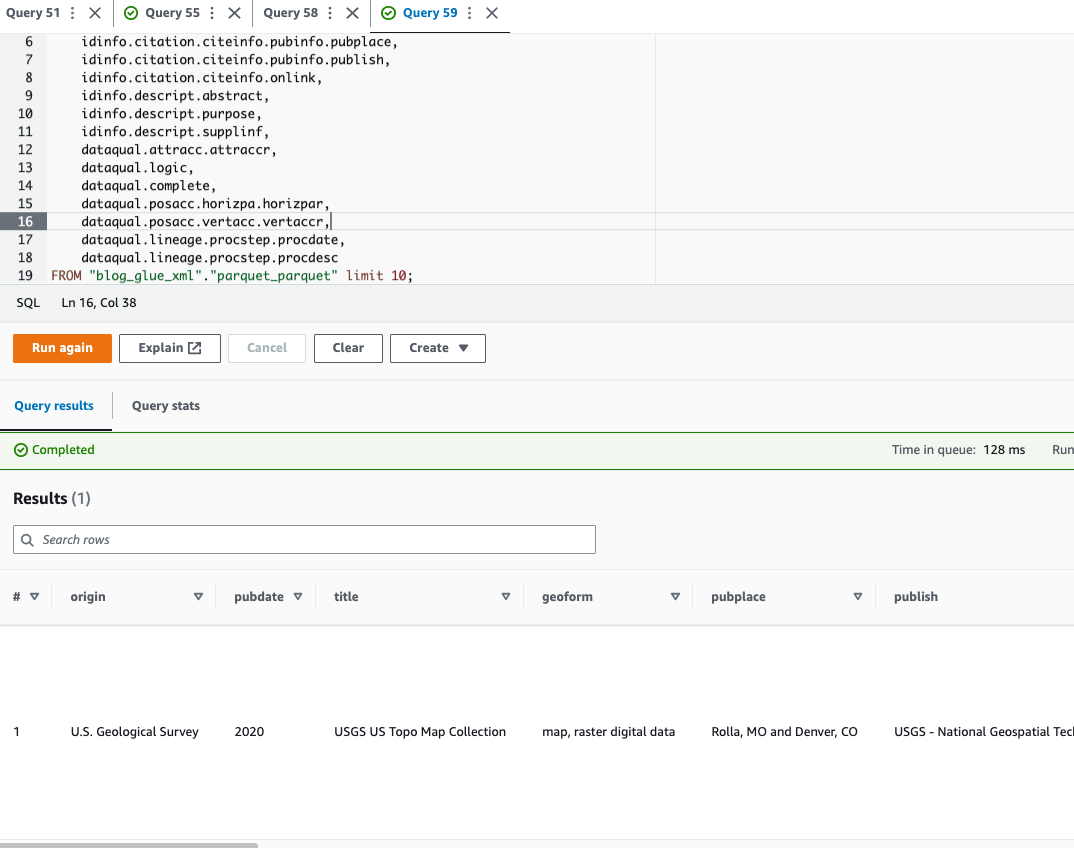
Athena unterstützt keine Abfrage XML-DateiformatAus diesem Grund haben Sie die XML-Datei für eine effizientere Datenabfrage und -nutzung in Parquet konvertiert Punktnotation um komplexe Typen und verschachtelte Strukturen abzufragen.
Der folgende Beispielcode verwendet die Punktnotation, um verschachtelte Daten abzufragen:
Nachdem wir nun Technik 1 abgeschlossen haben, lernen wir nun Technik 2 kennen.
Technik 2: Verwenden Sie AWS Glue DynamicFrames mit abgeleiteten und festen Schemata
Im vorherigen Abschnitt haben wir den Prozess der Verarbeitung einer kleinen XML-Datei mit einem AWS Glue-Crawler zum Generieren einer Tabelle, einem AWS Glue-Job zum Konvertieren der Datei in das Parquet-Format und Athena für den Zugriff auf die Parquet-Daten behandelt. Allerdings stößt der Crawler bei der Verarbeitung von XML-Dateien auf Einschränkungen 1 MB groß. In diesem Abschnitt befassen wir uns mit dem Thema der Stapelverarbeitung größerer XML-Dateien, die zusätzliches Parsen zum Extrahieren einzelner Ereignisse und zur Durchführung von Analysen mit Athena erfordern.
Unser Ansatz besteht darin, die XML-Dateien über AWS Glue zu lesen DynamicFrames, wobei sowohl abgeleitete als auch feste Schemata verwendet werden. Dann extrahieren wir die einzelnen Ereignisse im Parquet-Format mit dem relativieren Transformation, die es uns ermöglicht, sie nahtlos mit Athena abzufragen und zu analysieren.
Um diese Lösung zu implementieren, führen Sie die folgenden allgemeinen Schritte aus:
- Erstellen Sie ein AWS Glue-Notizbuch, um die XML-Datei zu lesen und zu analysieren.
- Verwenden Sie die
DynamicFramesmitInferSchemaum die XML-Datei zu lesen. - Verwenden Sie die Funktion „relationalize“, um die Verschachtelung aller Arrays aufzuheben.
- Konvertieren Sie die Daten in das Parquet-Format.
- Fragen Sie die Parquet-Daten mit Athena ab.
- Wiederholen Sie die vorherigen Schritte, aber übergeben Sie dieses Mal ein Schema an
DynamicFramesanstatt zu verwendenInferSchema.
Die XML-Datei mit Daten zur Elektrofahrzeugpopulation enthält eine response Tag auf seiner Stammebene. Dieses Tag enthält ein Array von row Tags, die darin verschachtelt sind. Das Zeilen-Tag ist ein Array, das eine Reihe weiterer Zeilen-Tags enthält, die Informationen über ein Fahrzeug bereitstellen, einschließlich Marke, Modell und andere relevante Details. Der folgende Screenshot zeigt ein Beispiel.

Erstellen Sie ein AWS Glue-Notizbuch
Führen Sie die folgenden Schritte aus, um ein AWS Glue-Notebook zu erstellen:
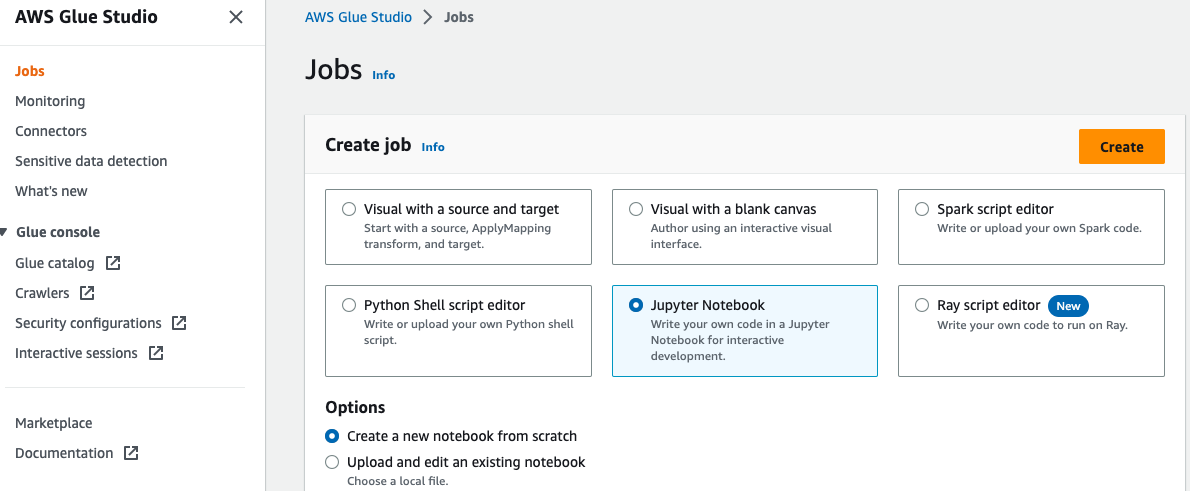
- Öffnen Sie den Microsoft Store auf Ihrem Windows-PC. AWS Glue Studio Konsole wählen Jobs im Navigationsbereich.
- Auswählen Jupyter Notizbuch und wählen Sie Erstellen.
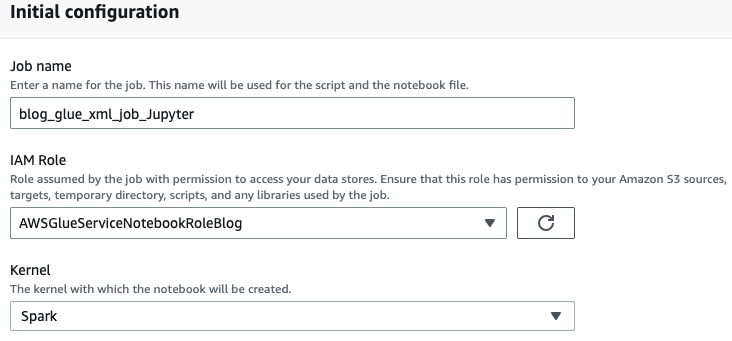
- Geben Sie einen Namen für Ihren AWS Glue-Auftrag ein, z
blog_glue_xml_job_Jupyter. - Wählen Sie die Rolle aus, die Sie in den Voraussetzungen erstellt haben (
AWSGlueServiceNotebookRoleBlog).
Das AWS Glue-Notizbuch enthält ein bereits vorhandenes Beispiel, das zeigt, wie eine Datenbank abgefragt und die Ausgabe in Amazon S3 geschrieben wird.
- Passen Sie das Timeout (in Minuten) wie im folgenden Screenshot gezeigt an und führen Sie die Zelle aus, um die interaktive AWS Glue-Sitzung zu erstellen.
Erstellen Sie grundlegende Variablen
Nachdem Sie die interaktive Sitzung erstellt haben, erstellen Sie am Ende des Notizbuchs eine neue Zelle mit den folgenden Variablen (geben Sie Ihren eigenen Bucket-Namen an):
Lesen Sie die XML-Datei, die das Schema ableitet
Wenn Sie kein Schema an übergeben DynamicFrame, wird das Schema der Dateien abgeleitet. Um die Daten mithilfe eines dynamischen Frames zu lesen, können Sie den folgenden Befehl verwenden:
Drucken Sie das DynamicFrame-Schema
Drucken Sie das Schema mit dem folgenden Code:
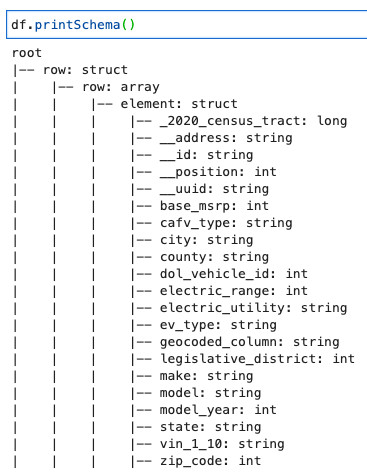
Das Schema zeigt eine verschachtelte Struktur mit a row Array mit mehreren Elementen. Um diese Struktur in Zeilen aufzulösen, können Sie AWS Glue verwenden relativieren Transformation:
Wir sind nur an den im Zeilenarray enthaltenen Informationen interessiert und können das Schema mit dem folgenden Befehl anzeigen:
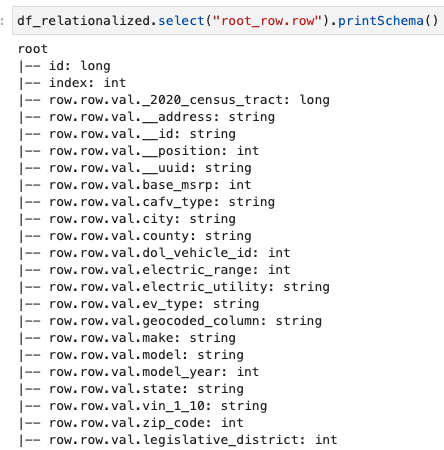
Die Spaltennamen enthalten row.row, die der Array-Struktur und der Array-Spalte im Datensatz entsprechen. Wir benennen die Spalten in diesem Beitrag nicht um; Anweisungen hierzu finden Sie unter Automatisieren Sie die dynamische Zuordnung und Umbenennung von Spaltennamen in Datendateien mit AWS Glue: Teil 1. Anschließend können Sie die Daten in das Parquet-Format konvertieren und die AWS Glue-Tabelle mit dem folgenden Befehl erstellen:
AWS-Kleber DynamicFrame stellt Funktionen bereit, die Sie in Ihrem ETL-Skript verwenden können, um ein Schema im Datenkatalog zu erstellen und zu aktualisieren. Wir benutzen das updateBehavior Parameter, um die Tabelle direkt im Datenkatalog zu erstellen. Bei diesem Ansatz müssen wir keinen AWS Glue-Crawler ausführen, nachdem der AWS Glue-Auftrag abgeschlossen ist.

Lesen Sie die XML-Datei, indem Sie ein Schema festlegen
Eine alternative Möglichkeit, die Datei zu lesen, besteht darin, ein Schema vorab zu definieren. Führen Sie dazu die folgenden Schritte aus:
- Importieren Sie die AWS Glue-Datentypen:
- Erstellen Sie ein Schema für die XML-Datei:
- Übergeben Sie das Schema beim Lesen der XML-Datei:
- Entschachteln Sie den Datensatz wie zuvor:
- Konvertieren Sie den Datensatz in Parquet und erstellen Sie die AWS Glue-Tabelle:
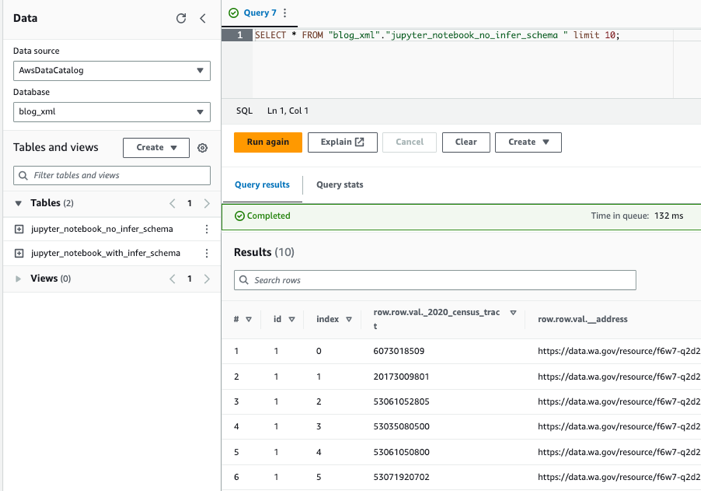
Fragen Sie die Tabellen mit Athena ab
Nachdem wir nun beide Tabellen erstellt haben, können wir die Tabellen mit Athena abfragen. Beispielsweise können wir die folgende Abfrage verwenden:
Aufräumen
In diesem Beitrag haben wir eine IAM-Rolle, ein AWS Glue Jupyter-Notebook und zwei Tabellen im AWS Glue-Datenkatalog erstellt. Wir haben auch einige Dateien in einen S3-Bucket hochgeladen. Um diese Objekte zu bereinigen, führen Sie die folgenden Schritte aus:
- Löschen Sie in der IAM-Konsole die von Ihnen erstellte Rolle.
- Löschen Sie in der AWS Glue Studio-Konsole den benutzerdefinierten Klassifikator, den Crawler, die ETL-Jobs und das Jupyter-Notebook.
- Navigieren Sie zum AWS Glue-Datenkatalog und löschen Sie die von Ihnen erstellten Tabellen.
- Navigieren Sie in der Amazon S3-Konsole zu dem von Ihnen erstellten Bucket und löschen Sie die genannten Ordner
temp,infer_schemaundno_infer_schema.
Key Take Away
In AWS Glue gibt es eine Funktion namens InferSchema in AWS Glue DynamicFrames. Es ermittelt automatisch die Struktur eines Datenrahmens anhand der darin enthaltenen Daten. Im Gegensatz dazu bedeutet die Definition eines Schemas, dass vor dem Laden der Daten explizit angegeben wird, wie die Struktur des Datenrahmens aussehen soll.
XML ist ein textbasiertes Format und schränkt die Datentypen seiner Spalten nicht ein. Dies kann zu Problemen mit der InferSchema-Funktion führen. Beispielsweise führt im ersten Durchlauf eine Datei mit Spalte A mit dem Wert 2 zu einer Parquet-Datei mit Spalte A als Ganzzahl. Im zweiten Durchlauf hat eine neue Datei Spalte A mit dem Wert C, was zu einer Parquet-Datei mit Spalte A als String führt. Jetzt gibt es auf S3 zwei Dateien mit jeweils einer Spalte A unterschiedlicher Datentypen, was nachgelagert zu Problemen führen kann.
Das Gleiche passiert mit komplexen Datentypen wie verschachtelten Strukturen oder Arrays. Wenn eine Datei beispielsweise über einen Tag-Eintrag mit dem Namen verfügt transaction, wird es als Struktur abgeleitet. Wenn jedoch eine andere Datei denselben Tag hat, wird sie als Array abgeleitet
Trotz dieser Datentypprobleme InferSchema ist nützlich, wenn Sie das Schema nicht kennen oder es unpraktisch ist, eines manuell zu definieren. Es ist jedoch nicht ideal für große oder sich ständig ändernde Datensätze. Das Definieren eines Schemas ist insbesondere bei komplexen Datentypen präziser, bringt jedoch eigene Probleme mit sich, z. B. erfordert es manuellen Aufwand und ist unflexibel gegenüber Datenänderungen.
InferSchema hat Einschränkungen, wie z. B. falsche Datentypinferenz und Probleme bei der Verarbeitung von Nullwerten. Das Definieren eines Schemas unterliegt auch Einschränkungen, z. B. manuellem Aufwand und möglichen Fehlern.
Die Wahl zwischen Ableiten und Definieren eines Schemas hängt von den Anforderungen des Projekts ab. InferSchema eignet sich hervorragend für die schnelle Untersuchung kleiner Datensätze, während die Definition eines Schemas besser für größere, komplexe Datensätze geeignet ist, die Genauigkeit und Konsistenz erfordern. Berücksichtigen Sie die Kompromisse und Einschränkungen jeder Methode, um auszuwählen, was am besten zu Ihrem Projekt passt.
Zusammenfassung
In diesem Beitrag haben wir zwei Techniken zur Verwaltung von XML-Daten mit AWS Glue untersucht, die jeweils auf die spezifischen Anforderungen und Herausforderungen zugeschnitten sind, denen Sie möglicherweise begegnen.
Technik 1 bietet einen benutzerfreundlichen Weg für diejenigen, die eine grafische Oberfläche bevorzugen. Mit einem AWS Glue-Crawler und dem visuellen Editor können Sie mühelos die Tabellenstruktur für Ihre XML-Dateien definieren. Dieser Ansatz vereinfacht den Datenverwaltungsprozess und ist besonders attraktiv für diejenigen, die einen unkomplizierten Umgang mit ihren Daten suchen.
Wir sind uns jedoch bewusst, dass der Crawler seine Grenzen hat, insbesondere beim Umgang mit XML-Dateien, deren Zeilen größer als 1 MB sind. Hier kommt Technik 2 zur Rettung. Durch die Nutzung von AWS Glue DynamicFrames Mit abgeleiteten und festen Schemata und der Verwendung eines AWS Glue-Notebooks können Sie XML-Dateien jeder Größe effizient verarbeiten. Diese Methode bietet eine robuste Lösung, die eine nahtlose Verarbeitung selbst für XML-Dateien mit Zeilen gewährleistet, die die 1-MB-Beschränkung überschreiten.
Wenn Sie sich in der Welt des Datenmanagements zurechtfinden, können Sie mit diesen Techniken in Ihrem Toolkit fundierte Entscheidungen auf der Grundlage der spezifischen Anforderungen Ihres Projekts treffen. Unabhängig davon, ob Sie die Einfachheit von Technik 1 oder die Skalierbarkeit von Technik 2 bevorzugen, bietet AWS Glue die Flexibilität, die Sie für den effektiven Umgang mit XML-Daten benötigen.
Über die Autoren
 Navnit Shuklafungiert als AWS Specialist Solution Architect mit Schwerpunkt auf Analytics. Er besitzt eine große Begeisterung dafür, Kunden dabei zu unterstützen, wertvolle Erkenntnisse aus ihren Daten zu gewinnen. Mit seinem Fachwissen entwickelt er innovative Lösungen, die es Unternehmen ermöglichen, fundierte, datengesteuerte Entscheidungen zu treffen. Insbesondere ist Navnit Shukla der versierte Autor des Buches mit dem Titel „Data Wrangling on AWS.
Navnit Shuklafungiert als AWS Specialist Solution Architect mit Schwerpunkt auf Analytics. Er besitzt eine große Begeisterung dafür, Kunden dabei zu unterstützen, wertvolle Erkenntnisse aus ihren Daten zu gewinnen. Mit seinem Fachwissen entwickelt er innovative Lösungen, die es Unternehmen ermöglichen, fundierte, datengesteuerte Entscheidungen zu treffen. Insbesondere ist Navnit Shukla der versierte Autor des Buches mit dem Titel „Data Wrangling on AWS.
 Patrick Müller arbeitet als Senior Data Lab Architect bei AWS. Seine Hauptaufgabe besteht darin, Kunden dabei zu unterstützen, ihre Ideen in ein produktionsreifes Datenprodukt umzusetzen. In seiner Freizeit spielt Patrick gerne Fußball, schaut Filme und reist.
Patrick Müller arbeitet als Senior Data Lab Architect bei AWS. Seine Hauptaufgabe besteht darin, Kunden dabei zu unterstützen, ihre Ideen in ein produktionsreifes Datenprodukt umzusetzen. In seiner Freizeit spielt Patrick gerne Fußball, schaut Filme und reist.
 Amog Gaikwad ist Senior Solutions Developer bei Amazon Web Services. Er unterstützt globale Kunden beim Aufbau und der Bereitstellung von KI/ML-Lösungen auf AWS. Seine Arbeit konzentriert sich hauptsächlich auf Computer Vision und die Verarbeitung natürlicher Sprache und hilft Kunden dabei, ihre KI/ML-Workloads im Hinblick auf Nachhaltigkeit zu optimieren. Amogh hat seinen Master in Informatik mit Spezialisierung auf maschinelles Lernen erhalten.
Amog Gaikwad ist Senior Solutions Developer bei Amazon Web Services. Er unterstützt globale Kunden beim Aufbau und der Bereitstellung von KI/ML-Lösungen auf AWS. Seine Arbeit konzentriert sich hauptsächlich auf Computer Vision und die Verarbeitung natürlicher Sprache und hilft Kunden dabei, ihre KI/ML-Workloads im Hinblick auf Nachhaltigkeit zu optimieren. Amogh hat seinen Master in Informatik mit Spezialisierung auf maschinelles Lernen erhalten.
 Sheela Sonone ist Senior Resident Architect bei AWS. Sie hilft AWS-Kunden dabei, fundierte Entscheidungen und Kompromisse zur Beschleunigung ihrer Daten-, Analyse- und KI/ML-Workloads und -Implementierungen zu treffen. In ihrer Freizeit verbringt sie gerne Zeit mit ihrer Familie – meist auf Tennisplätzen.
Sheela Sonone ist Senior Resident Architect bei AWS. Sie hilft AWS-Kunden dabei, fundierte Entscheidungen und Kompromisse zur Beschleunigung ihrer Daten-, Analyse- und KI/ML-Workloads und -Implementierungen zu treffen. In ihrer Freizeit verbringt sie gerne Zeit mit ihrer Familie – meist auf Tennisplätzen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- LiveBuzz
- ABSTRACT
- beschleunigend
- Zugang
- Zugänglichkeit
- erreicht
- Genauigkeit
- über
- Action
- hinzufügen
- hinzugefügt
- Zusätzliche
- Adresse
- Nach der
- Alter
- AI / ML
- Alle
- erlauben
- Zulassen
- erlaubt
- ebenfalls
- Alternative
- Amazon
- Amazonas Athena
- Amazon Web Services
- an
- Analyse
- Analytik
- analysieren
- Analyse
- und
- Ein anderer
- jedem
- Apache
- ansprechend
- Anwendungen
- Bewerben
- Ansatz
- Ansätze
- Architektur
- SIND
- Feld
- AS
- helfen
- Unterstützung
- At
- Autor
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- AWS-Kleber
- Zurück
- basierend
- basic
- BE
- weil
- Bevor
- beginnen
- Sein
- BESTE
- Besser
- zwischen
- leer
- buchen
- beide
- bauen
- Unternehmen
- aber
- by
- namens
- CAN
- Katalog
- Verursachen
- Zelle
- Herausforderungen
- Übernehmen
- Änderungen
- Ändern
- Entscheidungen
- Auswählen
- Stadt
- Einstufung
- Kunden
- Code
- Kolonne
- Spalten
- COM
- kommt
- gemeinsam
- häufig
- abschließen
- Abgeschlossene Verkäufe
- Komplex
- Computer
- Computerwissenschaften
- Computer Vision
- Zustand
- Leiten
- Verbindung
- Geht davon
- Konsul (Console)
- ständig
- Einschränkungen
- konstruieren
- enthalten
- enthalten
- enthält
- Kontrast
- Smartgeräte App
- verkaufen
- umgewandelt
- kostengünstiger
- kosteneffiziente Lösung
- Grafschaft
- Platz
- bedeckt
- Crawler
- erstellen
- erstellt
- Erstellen
- wichtig
- Original
- Kunde
- Kunden
- technische Daten
- Datenintegration
- Datenmanagement
- datengesteuerte
- Datenbase
- Datensätze
- Behandlung
- Entscheidungen
- Standard
- definieren
- Definition
- vertiefen
- zeigt
- hängt
- einsetzen
- entworfen
- detailliert
- Details
- Entwickler:in / Unternehmen
- anders
- schwer
- digital
- digitales Zeitalter
- Direkt
- entdecken
- deutlich
- do
- Tut nicht
- erledigt
- Nicht
- DOT
- im
- dynamisch
- jeder
- erleichtern
- leicht
- Einfache
- Herausgeber
- bewirken
- effektiv
- Effizienz
- effizient
- effizient
- Anstrengung
- mühelos
- Die elektrische
- Elektrofahrzeug
- Elemente
- anstellen
- ermächtigen
- befähigt
- leer
- ermöglichen
- ermöglichen
- Begegnung
- Ende
- Motor (en)
- zu steigern,
- gewährleisten
- sorgt
- Enter
- Begeisterung
- Eintrag
- Fehler
- insbesondere
- Äther (ETH)
- Sogar
- Veranstaltungen
- Jedes
- Beispiel
- überschreiten
- austauschen
- Expertise
- Exploration
- ERKUNDEN
- Erkundet
- Extrakt
- Extraktion
- Familie
- Merkmal
- Eigenschaften
- Zahlen
- Reichen Sie das
- Mappen
- Finanzen
- Vorname
- fixiert
- Flexibilität
- Setzen Sie mit Achtsamkeit
- konzentriert
- Folgende
- Aussichten für
- Format
- FRAME
- Frei
- Frequenz
- für
- Funktion
- Gewinnen
- allgemeiner Zweck
- erzeugen
- Global
- Go
- Kundenziele
- der Regierung
- groß
- Griff
- Handling
- das passiert
- Nutzen
- Haben
- mit
- he
- Gesundheitswesen
- Herz
- Hilfe
- Unternehmen
- hilft
- hier (auf dänisch)
- High-Level
- hoch
- seine
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- IAM
- ideal
- Ideen
- Identitätsschutz
- if
- zeigt
- implementieren
- Realisierungen
- Umsetzung
- importieren
- zu unterstützen,
- verbessert
- in
- Einschließlich
- Krankengymnastik
- Einzelpersonen
- Branchen
- Information
- informiert
- Infrastruktur
- innovativ
- innerhalb
- Einblicke
- beantragen müssen
- Anleitung
- integrieren
- Integration
- interaktive
- interessiert
- Schnittstelle
- in
- beinhaltet
- Probleme
- IT
- SEINE
- Job
- Jobs
- jpg
- JSON
- Jupyter Notizbuch
- Behalten
- Wissen
- Labor
- Sprache
- grosse
- größer
- führenden
- LERNEN
- lernen
- Niveau
- Gefällt mir
- LIMIT
- Einschränkung
- Einschränkungen
- Line
- Linien
- Belastung
- Laden
- Logik
- suchen
- Maschine
- Maschinelles Lernen
- Main
- hauptsächlich
- um
- Making
- Management
- flächendeckende Gesundheitsprogramme
- manuell
- manuell
- viele
- Mapping
- Meister
- Kann..
- Mittel
- MENÜ
- Metadaten
- Methode
- Minuten
- Modell
- mehr
- effizienter
- vor allem warme
- schlauer bewegen
- Filme
- mehrere
- Name
- Namens
- Namen
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Navigieren
- Menü
- notwendig,
- Need
- Bedürfnisse
- Neu
- neu
- weiter
- vor allem
- Notizbuch
- jetzt an
- Anzahl
- Objekte
- of
- Angebote
- on
- EINEM
- einzige
- Einkauf & Prozesse
- optimal
- Optimieren
- Verbessert
- Optionen
- or
- Auftrag
- Organisationen
- Origin
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- übrig
- Überwinden
- besitzen
- Seite
- Brot
- Parameter
- Parameter
- Teil
- besonders
- passieren
- Weg
- Patrick
- ausführen
- Leistung
- Berechtigungen
- wählen
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Datenschutzrichtlinien
- Bevölkerung
- besitzen
- Post
- Potenzial
- präzise
- bevorzugen
- Voraussetzungen
- Vorspann
- früher
- Probleme
- Prozessdefinierung
- verarbeitet
- Verarbeitung
- Produkt
- Projekt
- Projekte
- immobilien
- die
- bietet
- veröffentlichen
- Zweck
- Python
- Abfragen
- Direkt
- lieber
- Lesen Sie mehr
- leicht
- Lesebrillen
- Gründe
- Received
- erkennen
- siehe
- relevant
- Voraussetzungen:
- retten
- Ressourcen
- Antwort
- Verantwortung
- REST
- eine Beschränkung
- Einschränkung
- Die Ergebnisse
- robust
- Rollen
- Wurzel
- REIHE
- Führen Sie
- gleich
- Speichern
- Scala
- Skalierbarkeit
- skalierbaren
- Wissenschaft
- Skript
- nahtlos
- nahtlos
- Zweite
- Abschnitt
- sehen
- Senior
- Lösungen
- Sitzung
- kompensieren
- Einstellung
- mehrere
- sie
- Schale
- sollte
- erklären
- gezeigt
- Konzerte
- ähnlich
- Einfacher
- Einfachheit
- Vereinfachung
- Single
- Größe
- klein
- So
- Fußball
- Lösung
- Lösungen
- einige
- Quelle
- Quellen
- Spark
- Spezialist
- spezialisieren
- spezifisch
- speziell
- Geschwindigkeit
- Ausgabe
- SQL
- Standard
- beginnt
- Bundesstaat
- Erklärung
- Angabe
- Schritt
- Shritte
- Lagerung
- gelagert
- einfach
- rationalisieren
- Schnur
- stark
- Struktur
- Strukturen
- Studio Adressen
- Erfolg
- so
- geeignet
- Support
- sicher
- Nachhaltigkeit
- Systeme und Techniken
- Tabelle
- TAG
- zugeschnitten
- Nehmen
- nimmt
- und Aufgaben
- Techniken
- Tennis
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- die Informationen
- die Welt
- ihr
- Sie
- dann
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- Durch
- Zeit
- Titel
- betitelt
- zu
- heutigen
- Toolkit
- Top
- Thema
- Transformieren
- Transformation
- Reise
- Drehung
- Lernprogramm
- XNUMX
- tippe
- Typen
- letzte
- für
- Aktualisierung
- aktualisiert
- hochgeladen
- us
- Nutzbarkeit
- -
- benutzt
- Mitglied
- Benutzerschnittstelle
- benutzerfreundlich
- verwendet
- Verwendung von
- gewöhnlich
- Verwendung
- wertvoll
- Wert
- Werte
- Fahrzeug
- Version
- Anzeigen
- Ansichten
- Seh-
- beobachten
- Weg..
- we
- Netz
- Web-Services
- Was
- wann
- während
- ob
- welche
- WHO
- warum
- werden wir
- mit
- .
- ohne
- Arbeiten
- Arbeitsablauf.
- Workflows
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- schreiben
- XML
- U
- Ihr
- Zephyrnet