Generiert mit Midjourney
Die NeurIPS 2023-Konferenz, die vom 10. bis 16. Dezember in der pulsierenden Stadt New Orleans stattfand, legte einen besonderen Schwerpunkt auf generative KI und große Sprachmodelle (LLMs). Angesichts der jüngsten bahnbrechenden Fortschritte in diesem Bereich war es keine Überraschung, dass diese Themen die Diskussionen dominierten.
Eines der Kernthemen der diesjährigen Konferenz war die Suche nach effizienteren KI-Systemen. Forscher und Entwickler suchen aktiv nach Möglichkeiten, KI zu konstruieren, die nicht nur schneller lernt als aktuelle LLMs, sondern auch über verbesserte Denkfähigkeiten verfügt und gleichzeitig weniger Rechenressourcen verbraucht. Dieses Streben ist von entscheidender Bedeutung im Wettlauf um die Verwirklichung künstlicher allgemeiner Intelligenz (AGI), ein Ziel, das in absehbarer Zukunft zunehmend erreichbar zu sein scheint.
Die eingeladenen Vorträge bei NeurIPS 2023 spiegelten diese dynamischen und sich schnell entwickelnden Interessen wider. Referenten aus verschiedenen Bereichen der KI-Forschung stellten ihre neuesten Errungenschaften vor und boten einen Einblick in die neuesten KI-Entwicklungen. In diesem Artikel gehen wir tiefer in diese Vorträge ein und extrahieren und diskutieren die wichtigsten Erkenntnisse und Erkenntnisse, die für das Verständnis der aktuellen und zukünftigen Landschaften der KI-Innovation unerlässlich sind.
NextGenAI: Der Skalierungswahn und die Zukunft der generativen KI
In sein VortragBjörn Ommer, Leiter der Computer Vision & Learning Group an der Ludwig-Maximilians-Universität München, erzählte, wie sein Labor zur Entwicklung der stabilen Diffusion kam, einige Lehren, die sie aus diesem Prozess gezogen haben, und die jüngsten Entwicklungen, einschließlich der Frage, wie wir Diffusionsmodelle damit kombinieren können unter anderem Flow Matching, Retrieval Augmentation und LoRA-Approximationen.
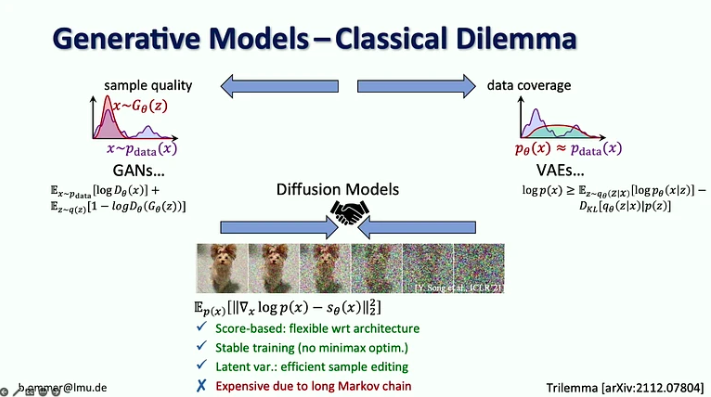
Die zentralen Thesen:
- Im Zeitalter der generativen KI haben wir uns vom Fokus auf die Wahrnehmung in Sehmodellen (d. h. Objekterkennung) auf die Vorhersage der fehlenden Teile (z. B. Bild- und Videoerzeugung mit Diffusionsmodellen) verlagert.
- 20 Jahre lang konzentrierte sich Computer Vision auf Benchmark-Forschung, was dazu beitrug, sich auf die wichtigsten Probleme zu konzentrieren. Bei der generativen KI gibt es keine Benchmarks für die Optimierung, was jedem die Möglichkeit gibt, seinen eigenen Weg zu gehen.
- Diffusionsmodelle vereinen die Vorteile früherer generativer Modelle, da sie punktebasiert sind, mit einem stabilen Trainingsverfahren und einer effizienten Probenbearbeitung, sind jedoch aufgrund ihrer langen Markov-Kette teuer.
- Die Herausforderung bei Modellen mit starker Wahrscheinlichkeit besteht darin, dass die meisten Bits in Details gehen, die für das menschliche Auge kaum wahrnehmbar sind, während die Codierung der Semantik, die am wichtigsten ist, nur wenige Bits benötigt. Eine Skalierung allein würde dieses Problem nicht lösen, da die Nachfrage nach Rechenressourcen neunmal schneller wächst als das GPU-Angebot.
- Die vorgeschlagene Lösung besteht darin, die Stärken von Diffusionsmodellen und ConvNets zu kombinieren, insbesondere die Effizienz von Faltungen zur Darstellung lokaler Details und die Ausdruckskraft von Diffusionsmodellen für weitreichende Kontexte.
- Björn Ommer schlägt außerdem die Verwendung eines Flow-Matching-Ansatzes vor, um eine hochauflösende Bildsynthese aus kleinen latenten Diffusionsmodellen zu ermöglichen.
- Ein weiterer Ansatz zur Steigerung der Effizienz der Bildsynthese besteht darin, sich auf die Szenenkomposition zu konzentrieren und gleichzeitig die Retrieval-Augmentation zum Ausfüllen der Details zu verwenden.
- Schließlich stellte er den iPoke-Ansatz für die kontrollierte stochastische Videosynthese vor.
Wenn dieser ausführliche Inhalt für Sie nützlich ist, abonnieren Sie unsere KI-Mailingliste benachrichtigt werden, wenn wir neues Material veröffentlichen.
Die vielen Gesichter verantwortungsvoller KI
In ihr VortragLora Aroyo, Forschungswissenschaftlerin bei Google Research, wies auf eine wesentliche Einschränkung traditioneller Ansätze des maschinellen Lernens hin: ihre Abhängigkeit von der binären Kategorisierung von Daten als positive oder negative Beispiele. Diese übermäßige Vereinfachung, so argumentierte sie, übersehe die komplexe Subjektivität, die realen Szenarien und Inhalten innewohne. Anhand verschiedener Anwendungsfälle zeigte Aroyo, wie inhaltliche Mehrdeutigkeit und die natürliche Varianz menschlicher Standpunkte oft zu unvermeidlichen Meinungsverschiedenheiten führen. Sie betonte, wie wichtig es sei, diese Meinungsverschiedenheiten als bedeutungsvolle Signale und nicht als bloßen Lärm zu behandeln.

Hier sind die wichtigsten Erkenntnisse aus dem Vortrag:
- Meinungsverschiedenheiten zwischen menschlichen Laboren können produktiv sein. Anstatt alle Antworten entweder als richtig oder falsch zu behandeln, führte Lora Aroyo „Wahrheit durch Meinungsverschiedenheit“ ein, einen Ansatz der Verteilungswahrheit zur Beurteilung der Zuverlässigkeit von Daten durch Nutzung der Meinungsverschiedenheiten der Bewerter.
- Die Datenqualität ist selbst mit Experten schwierig, da Experten ebenso unterschiedlicher Meinung sind wie Crowd-Lab-Leute. Diese Meinungsverschiedenheiten können viel informativer sein als die Antworten eines einzelnen Experten.
- Bei Sicherheitsbewertungsaufgaben sind sich Experten in 40 % der Beispiele uneinig. Anstatt zu versuchen, diese Meinungsverschiedenheiten zu lösen, müssen wir mehr solcher Beispiele sammeln und sie zur Verbesserung der Modelle und Bewertungsmetriken nutzen.
- Lora Aroyo präsentierte auch ihre Sicherheit mit Vielfalt Methode zur Untersuchung der Daten im Hinblick darauf, was darin enthalten ist und wer sie mit Anmerkungen versehen hat.
- Diese Methode erzeugte einen Benchmark-Datensatz mit Variabilität in der LLM-Sicherheitsbeurteilung über verschiedene demografische Gruppen von Bewertern hinweg (insgesamt 2.5 Millionen Bewertungen).
- Bei 20 % der Gespräche war es schwierig zu entscheiden, ob die Chatbot-Antwort sicher oder unsicher war, da etwa gleich viele Befragte sie als sicher oder unsicher bezeichneten.
- Die Vielfalt der Bewerter und Daten spielt bei der Bewertung von Modellen eine entscheidende Rolle. Wenn das breite Spektrum menschlicher Perspektiven und die in den Inhalten vorhandene Mehrdeutigkeit nicht berücksichtigt werden, kann dies dazu führen, dass die Leistung des maschinellen Lernens nicht mit den Erwartungen der realen Welt in Einklang gebracht wird.
- 80 % der KI-Sicherheitsbemühungen sind bereits recht gut, aber die restlichen 20 % erfordern eine Verdoppelung der Anstrengungen, um Grenzfälle und alle Varianten im unendlichen Raum der Vielfalt anzugehen.
Kohärenzstatistiken, selbstgenerierte Erfahrungen und warum junge Menschen viel schlauer sind als aktuelle KI
In ihr GesprächLinda Smith, eine angesehene Professorin an der Indiana University Bloomington, untersuchte das Thema der Datenknappheit in den Lernprozessen von Säuglingen und Kleinkindern. Sie konzentrierte sich insbesondere auf Objekterkennung und Namenslernen und untersuchte, wie die Statistiken selbst generierter Erfahrungen von Säuglingen potenzielle Lösungen für die Herausforderung der Datenknappheit bieten.
Die zentralen Thesen:
- Im Alter von drei Jahren haben Kinder die Fähigkeit entwickelt, in verschiedenen Bereichen einmalig zu lernen. In weniger als 16,000 wachen Stunden vor ihrem vierten Geburtstag gelingt es ihnen, über 1,000 Objektkategorien zu lernen, die Syntax ihrer Muttersprache zu beherrschen und die kulturellen und sozialen Nuancen ihrer Umgebung zu absorbieren.
- Dr. Linda Smith und ihr Team entdeckten drei Prinzipien des menschlichen Lernens, die es Kindern ermöglichen, aus solch spärlichen Daten so viel zu erfassen:
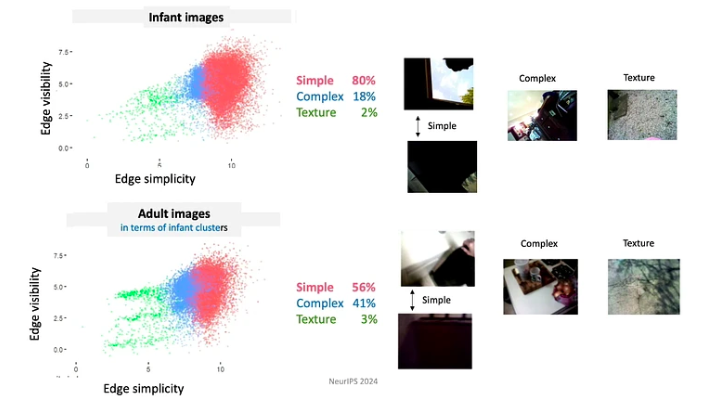
- Die Lernenden kontrollieren den Input, von Moment zu Moment gestalten und strukturieren sie den Input. Beispielsweise neigen Babys in den ersten Lebensmonaten dazu, eher auf Objekte mit einfachen Kanten zu blicken.
- Da Babys ihr Wissen und ihre Fähigkeiten ständig weiterentwickeln, folgen sie einem stark eingeschränkten Lehrplan. Die Daten, denen sie ausgesetzt sind, sind auf äußerst bedeutsame Weise organisiert. Beispielsweise verbringen Babys unter 4 Monaten die meiste Zeit damit, in Gesichter zu schauen, etwa 15 Minuten pro Stunde, während sich Babys über 12 Monaten hauptsächlich auf die Hände konzentrieren und diese etwa 20 Minuten pro Stunde beobachten.
- Lernepisoden bestehen aus einer Reihe miteinander verbundener Erfahrungen. Räumliche und zeitliche Zusammenhänge schaffen Kohärenz, die wiederum die Bildung bleibender Erinnerungen an einmalige Ereignisse ermöglicht. Wenn Kindern beispielsweise eine zufällige Auswahl an Spielzeugen präsentiert wird, konzentrieren sie sich oft auf einige wenige „Lieblingsspielzeuge“. Sie beschäftigen sich mit diesen Spielzeugen nach sich wiederholenden Mustern, was zu einem schnelleren Erlernen der Objekte beiträgt.
- Vorübergehende (Arbeits-)Erinnerungen bleiben länger bestehen als der sensorische Input. Zu den Eigenschaften, die den Lernprozess verbessern, gehören Multimodalität, Assoziationen, prädiktive Beziehungen und die Aktivierung vergangener Erinnerungen.
- Für schnelles Lernen benötigen Sie eine Allianz zwischen den Mechanismen, die die Daten generieren, und den Mechanismen, die lernen.
Skizzieren: Kernwerkzeuge, Lernerweiterung und adaptive Robustheit
Jelani Nelson, Professorin für Elektrotechnik und Informatik an der UC Berkeley, führte das Konzept der Datenskizzen ein – eine speicherkomprimierte Darstellung eines Datensatzes, die dennoch die Beantwortung nützlicher Abfragen ermöglicht. Obwohl der Vortrag recht technisch war, bot er einen hervorragenden Überblick über einige grundlegende Skizzierwerkzeuge, einschließlich der jüngsten Fortschritte.
Wichtige Erkenntnisse:
- CountSketch, das zentrale Skizziertool, wurde erstmals im Jahr 2002 eingeführt, um das Problem der „Heavy Hitter“ anzugehen, indem es eine kleine Liste der häufigsten Elemente aus dem gegebenen Elementstrom meldete. CountSketch war der erste bekannte sublineare Algorithmus, der für diesen Zweck verwendet wurde.
- Zu den zwei Nicht-Streaming-Anwendungen von Heavy Hittern gehören:
- Interne punktbasierte Methode (IPM), die einen asymptotisch schnellsten bekannten Algorithmus für die lineare Programmierung liefert.
- HyperAttention-Methode, die sich mit der Rechenherausforderung befasst, die sich aus der wachsenden Komplexität langer Kontexte in LLMs ergibt.
- Viele neuere Arbeiten konzentrierten sich auf das Entwerfen von Skizzen, die gegenüber adaptiver Interaktion robust sind. Die Hauptidee besteht darin, Erkenntnisse aus der adaptiven Datenanalyse zu nutzen.
Jenseits des Skalierungspanels
Dieser Tolles Panel über große Sprachmodelle Moderiert wurde Alexander Rush, außerordentlicher Professor an der Cornell Tech und Forscher bei Hugging Face. Zu den weiteren Teilnehmern gehörten:
- Aakanksha Chowdhery – Forschungswissenschaftlerin bei Google DeepMind mit Forschungsinteressen in den Bereichen Systeme, LLM-Vortraining und Multimodalität. Sie war Teil des Teams, das PaLM, Gemini und Pathways entwickelte.
- Angela Fan – Forschungswissenschaftlerin bei Meta Generative AI mit Forschungsinteressen in den Bereichen Ausrichtung, Rechenzentren und Mehrsprachigkeit. Sie war an der Entwicklung von Llama-2 und Meta AI Assistant beteiligt.
- Percy Liang – Professor an der Stanford University, der sich mit der Erforschung von Schöpfern, Open Source und generativen Agenten beschäftigt. Er ist Direktor des Center for Research on Foundation Models (CRFM) in Stanford und Gründer von Together AI.
Die Diskussion konzentrierte sich auf vier Schlüsselthemen: (1) Architekturen und Technik, (2) Daten und Ausrichtung, (3) Bewertung und Transparenz und (4) Ersteller und Mitwirkende.
Hier sind einige der Erkenntnisse aus diesem Panel:
- Das Training aktueller Sprachmodelle ist nicht grundsätzlich schwierig. Die größte Herausforderung beim Training eines Modells wie Llama-2-7b liegt in den Infrastrukturanforderungen und der Notwendigkeit der Koordination zwischen mehreren GPUs, Rechenzentren usw. Wenn die Anzahl der Parameter jedoch klein genug ist, um das Training auf einer einzelnen GPU zu ermöglichen, Sogar ein Student kann es schaffen.
- Während autoregressive Modelle normalerweise für die Textgenerierung und Diffusionsmodelle für die Generierung von Bildern und Videos verwendet werden, gab es Experimente mit der Umkehrung dieser Ansätze. Konkret wird im Gemini-Projekt ein autoregressives Modell zur Bildgenerierung verwendet. Es gibt auch Untersuchungen zur Verwendung von Diffusionsmodellen zur Textgenerierung, diese haben sich jedoch noch nicht als ausreichend wirksam erwiesen.
- Angesichts der begrenzten Verfügbarkeit englischsprachiger Daten für Trainingsmodelle prüfen Forscher alternative Ansätze. Eine Möglichkeit besteht darin, multimodale Modelle auf einer Kombination aus Text, Video, Bildern und Audio zu trainieren, mit der Erwartung, dass die aus diesen alternativen Modalitäten erlernten Fähigkeiten auf Text übertragen werden können. Eine weitere Möglichkeit ist die Nutzung synthetischer Daten. Es ist wichtig zu beachten, dass synthetische Daten häufig mit realen Daten vermischt werden, diese Integration jedoch nicht zufällig erfolgt. Online veröffentlichte Texte werden in der Regel von Menschen kuratiert und bearbeitet, was einen zusätzlichen Mehrwert für das Modelltraining darstellen kann.
- Open-Foundation-Modelle werden häufig als vorteilhaft für Innovationen, aber potenziell schädlich für die KI-Sicherheit angesehen, da sie von böswilligen Akteuren ausgenutzt werden können. Allerdings argumentiert Dr. Percy Liang, dass offene Modelle auch einen positiven Beitrag zur Sicherheit leisten. Er argumentiert, dass sie durch ihre Zugänglichkeit mehr Forschern die Möglichkeit bieten, KI-Sicherheitsforschung durchzuführen und die Modelle auf potenzielle Schwachstellen zu überprüfen.
- Heutzutage erfordert die Annotation von Daten deutlich mehr Fachwissen im Annotationsbereich als noch vor fünf Jahren. Wenn KI-Assistenten jedoch in Zukunft die erwartete Leistung erbringen, erhalten wir mehr wertvolle Feedbackdaten von Benutzern, wodurch die Abhängigkeit von umfangreichen Daten von Annotatoren verringert wird.
Systeme für Basismodelle und Basismodelle für Systeme
In dieses GesprächChristopher Ré, außerordentlicher Professor am Fachbereich Informatik der Stanford University, zeigt, wie Grundlagenmodelle die von uns gebauten Systeme verändert haben. Er untersucht außerdem, wie man Basismodelle effizient erstellen kann, indem er Erkenntnisse aus der Datenbanksystemforschung nutzt, und diskutiert potenziell effizientere Architekturen für Basismodelle als den Transformer.
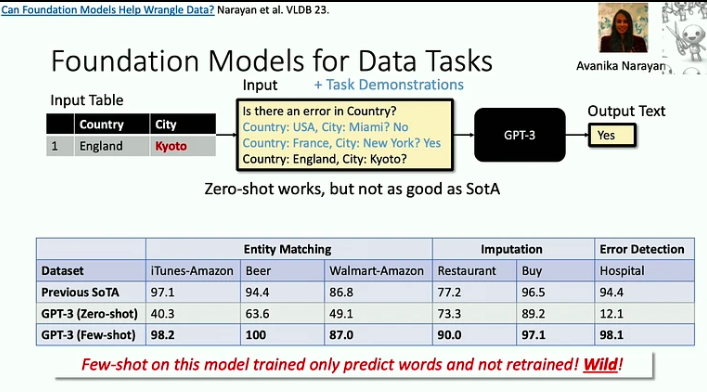
Hier sind die wichtigsten Erkenntnisse aus diesem Vortrag:
- Foundation-Modelle sind wirksam bei der Bewältigung von „Tod durch 1000 Schnitte“-Problemen, bei denen jede einzelne Aufgabe relativ einfach sein mag, die schiere Breite und Vielfalt der Aufgaben jedoch eine erhebliche Herausforderung darstellt. Ein gutes Beispiel hierfür ist das Datenbereinigungsproblem, das LLMs nun viel effizienter lösen helfen können.
- Da Beschleuniger immer schneller werden, entsteht häufig ein Speicherengpass. Dies ist ein Problem, mit dem sich Datenbankforscher seit Jahrzehnten befassen, und wir können einige ihrer Strategien übernehmen. Beispielsweise minimiert der Flash-Attention-Ansatz den Input-Output-Fluss durch Blockierung und aggressive Fusion: Wann immer wir auf eine Information zugreifen, führen wir so viele Operationen wie möglich daran durch.
- Es gibt eine neue Klasse von Architekturen, die auf der Signalverarbeitung basieren und insbesondere bei der Verarbeitung langer Sequenzen effizienter sein könnten als das Transformer-Modell. Die Signalverarbeitung bietet Stabilität und Effizienz und legt den Grundstein für innovative Modelle wie S4.
Online-Lernen zur Verstärkung digitaler Gesundheitsinterventionen
In ihr GesprächSusan Murphy, Professorin für Statistik und Informatik an der Harvard University, präsentierte erste Lösungen für einige der Herausforderungen, denen sie bei der Entwicklung von Online-RL-Algorithmen für den Einsatz bei digitalen Gesundheitsinterventionen gegenüberstehen.
Hier ein paar Erkenntnisse aus der Präsentation:
- Dr. Susan Murphy besprach zwei Projekte, an denen sie gearbeitet hat:
- HeartStep, wo Aktivitäten basierend auf Daten von Smartphones und tragbaren Trackern vorgeschlagen wurden, und
- Oralytics für Mundgesundheitscoaching, bei dem die Interventionen auf Interaktionsdaten basierten, die von einer elektronischen Zahnbürste empfangen wurden.
- Bei der Entwicklung einer Verhaltensrichtlinie für einen KI-Agenten müssen Forscher sicherstellen, dass diese autonom ist und im breiteren Gesundheitssystem realisierbar ist. Dabei muss sichergestellt werden, dass der Zeitaufwand für das Engagement einer Person angemessen ist und dass die empfohlenen Maßnahmen sowohl ethisch einwandfrei als auch wissenschaftlich plausibel sind.
- Zu den Hauptherausforderungen bei der Entwicklung eines RL-Agenten für digitale Gesundheitsinterventionen gehört der Umgang mit hohen Lärmpegeln, da die Menschen ihr Leben führen und möglicherweise nicht immer in der Lage sind, auf Nachrichten zu reagieren, selbst wenn sie dies wünschen, sowie die Bewältigung starker, verzögerter negativer Auswirkungen .
Wie Sie sehen, hat NeurIPS 2023 einen erhellenden Einblick in die Zukunft der KI gegeben. Die eingeladenen Vorträge verdeutlichten einen Trend hin zu effizienteren, ressourcenschonenderen Modellen und der Erforschung neuartiger Architekturen jenseits traditioneller Paradigmen.
Genießen Sie diesen Artikel? Melden Sie sich für weitere AI-Forschungsupdates an.
Wir werden Sie informieren, wenn wir weitere zusammenfassende Artikel wie diesen veröffentlichen.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.topbots.com/neurips-2023-invited-talks/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 10
- 10.
- 11
- 110
- 12
- 12 Monate
- 125
- 13
- 14
- 15%
- 154
- 16
- 16.
- 17
- 20
- 20 Jahre
- 2023
- 32
- 35%
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- Fähigkeit
- Fähig
- Über uns
- Beschleuniger
- Zugang
- zugänglich
- Leistungen
- Erreichen
- anerkennen
- über
- Aktionen
- Aktivierung
- aktiv
- Aktivitäten
- Akteure
- adaptiv
- hinzufügen
- Zusätzliche
- Adresse
- Adressen
- Adressierung
- adoptieren
- Fortschritte
- Vorteilen
- Alter
- Makler
- Agenten
- aggressiv
- AGI
- vor
- AI
- AI-Assistent
- ai Forschung
- KI-Systeme
- AIDS
- Udo
- Algorithmus
- Algorithmen
- Ausrichtung
- Alle
- Allianz
- erlauben
- allein
- bereits
- ebenfalls
- Alternative
- Obwohl
- immer
- Mehrdeutigkeit
- unter
- an
- Analyse
- und
- Ein anderer
- jedem
- Anwendungen
- Ansatz
- Ansätze
- ca.
- SIND
- argumentierte
- Argumentiert
- Artikel
- Artikel
- künstlich
- künstliche allgemeine Intelligenz
- AS
- Beurteilung
- Assistentin
- Assistenten
- Partnerschaftsräte
- Verbände
- Sortiment
- At
- Erreichbar
- Aufmerksamkeit
- Audio-
- Autonom
- Verfügbarkeit
- basierend
- BE
- weil
- werden
- war
- Verhalten
- Sein
- Benchmark
- Benchmarks
- vorteilhaft
- Berkeley
- zwischen
- Beyond
- Blend
- Mischungen
- Sperrung
- Ausleihen
- beide
- Breite
- breiteres
- bauen
- aber
- by
- kam
- CAN
- Fähigkeiten
- Erfassung
- Fälle
- Kategorien
- Center
- Centers
- Kette
- challenges
- Herausforderungen
- geändert
- Chatbot
- weltweit
- Friedrich
- Stadt
- Klasse
- Reinigung
- test name
- sammeln
- Kombination
- kombinieren
- verglichen
- Komplex
- Komplexität
- Zusammensetzung
- rechnerisch
- Computer
- Computerwissenschaften
- Computer Vision
- Computing
- konzept
- Leiten
- Konferenz
- konstruieren
- Inhalt
- Kontext
- Kontexte
- ständig
- beitragen
- mitwirkende
- Smartgeräte App
- gesteuert
- Gespräche
- Koordinate
- Kernbereich
- Cornell
- und beseitigen Muskelschwäche
- Korrelationen
- könnte
- erstellen
- Schöpfer
- Menschenmenge
- wichtig
- Kultur-
- curation
- Strom
- Curriculum
- innovativ, auf dem neuesten Stand
- technische Daten
- Datenanalyse
- Rechenzentren
- Datenbase
- Behandlung
- Jahrzehnte
- Dezember
- entscheidet
- DeepMind
- Verspätet
- vertiefen
- Demand
- Anforderungen
- demographisch
- weisen nach, dass
- Abteilung
- Entwerfen
- Detail
- Details
- entwickeln
- entwickelt
- Entwickler
- Entwicklung
- Entwicklung
- Entwicklungen
- schwer
- Rundfunk
- digital
- Digitale Gesundheit
- Richtung
- Direktor
- entdeckt
- diskutiert
- diskutieren
- Diskussion
- Diskussionen
- Distinguished
- Diversität
- Domain
- Domains
- dominierten
- Nicht
- Verdoppelung
- dr
- zwei
- im
- dynamisch
- e
- jeder
- Edge
- Bearbeitung
- Effektiv
- Effekten
- Effizienz
- effizient
- effizient
- Anstrengung
- Bemühungen
- entweder
- Elektrotechnik
- elektronisch
- taucht auf
- Betonung
- betont
- ermöglichen
- ermöglicht
- Codierung
- engagieren
- Engagement
- Entwicklung
- zu steigern,
- verbesserte
- genug
- gewährleisten
- Gewährleistung
- Arbeitsumfeld
- Folgen
- gleich
- insbesondere
- essential
- etc
- Äther (ETH)
- Auswerten
- Auswertung
- Sogar
- Veranstaltungen
- jedermann
- entwickelt sich
- sich entwickelnden
- Beispiel
- Beispiele
- Ausgezeichnet
- Erwartung
- Erwartungen
- erwartet
- teuer
- ERFAHRUNGEN
- Erfahrungen
- Experimente
- Experte
- Expertise
- Experten
- Exploited
- Exploration
- Erkundet
- erforscht
- Möglichkeiten sondieren
- ausgesetzt
- umfangreiche
- Auge
- Gesicht
- Gesichter
- erleichtert
- andernfalls
- Fan
- beschleunigt
- schnellsten
- Feedback
- wenige
- Weniger
- Feld
- füllen
- Vorname
- fünf
- Blinken (Flash)
- Fluss
- Fließt
- Setzen Sie mit Achtsamkeit
- konzentriert
- folgen
- Aussichten für
- absehbar
- Ausbildung
- Foundation
- Gründer
- vier
- Vierte
- häufig
- häufig
- für
- fundamental
- Verschmelzung
- Zukunft
- Zukunft der KI
- Gemini
- Allgemeines
- generelle Intelligenz
- erzeugen
- Erzeugung
- Generation
- generativ
- Generative KI
- gegeben
- gibt
- Blick
- Go
- Kundenziele
- gut
- GPU
- GPUs
- bahnbrechend
- Gruppe an
- Gruppen
- persönlichem Wachstum
- hätten
- Handling
- Hände
- schädlich
- Nutzen
- Harvard
- Harvard Universität
- Haben
- he
- ganzer
- Gesundheit
- Gesundheitswesen
- schwer
- Statt
- Hilfe
- dazu beigetragen,
- hier (auf dänisch)
- GUTE
- hochauflösenden
- Besondere
- hoch
- behindern
- seine
- Stunde
- STUNDEN
- Ultraschall
- Hilfe
- aber
- http
- HTTPS
- human
- Humans
- i
- Idee
- if
- aufschlussreich
- Image
- Bilderzeugung
- Bilder
- umgesetzt
- Bedeutung
- wichtig
- zu unterstützen,
- in
- eingehende
- das
- inklusive
- Einschließlich
- zunehmend
- zunehmend
- Indiana
- Krankengymnastik
- unvermeidlich
- Information
- informativ
- Infrastruktur
- inhärent
- von Natur aus
- Innovation
- innovativ
- Varianten des Eingangssignals:
- Einblicke
- Instanz
- beantragen müssen
- Integration
- Intelligenz
- Interaktion
- verbunden
- Interessen
- Interventionen
- in
- eingeführt
- eingeladen
- IT
- Artikel
- jpg
- Urteile
- Wesentliche
- Wissen
- Wissen
- bekannt
- Labor
- Beschriftung
- Sprache
- grosse
- dauerhaft
- neueste
- Verlegung
- führen
- führenden
- LERNEN
- gelernt
- Lerner
- lernen
- Legacy
- weniger
- Programm
- lassen
- Cholesterinspiegel
- liegt
- !
- Gefällt mir
- Wahrscheinlichkeit
- Einschränkung
- Limitiert
- Linda
- Liste
- Leben
- aus einer regionalen
- Lang
- länger
- aussehen
- suchen
- Maschine
- Maschinelles Lernen
- Postversand
- Main
- verwalten
- flächendeckende Gesundheitsprogramme
- viele
- Master
- Abstimmung
- Ihres Materials
- Angelegenheiten
- max-width
- Kann..
- sinnvoll
- Mechanismen
- Memories
- Memory
- bloß
- Nachrichten
- Meta
- Methode
- Metrik
- könnte
- Million
- minimiert
- Minuten
- Kommt demnächst...
- Modalitäten
- Modell
- für
- Moment
- Monat
- mehr
- effizienter
- vor allem warme
- gerührt
- viel
- mehrere
- München
- sollen
- Name
- nativen
- Natürliche
- Need
- Negativ
- NeuroIPS
- Neu
- New Orleans
- nicht
- Lärm
- Andere
- beachten
- Roman
- jetzt an
- Abschattung
- Anzahl
- Objekt
- Objekte
- of
- bieten
- bieten
- Angebote
- vorgenommen,
- Telefongebühren sparen
- on
- EINEM
- Online
- einzige
- XNUMXh geöffnet
- Open-Source-
- geöffnet
- Einkauf & Prozesse
- Entwicklungsmöglichkeiten
- Optimieren
- Option
- or
- oral
- Mundhygiene
- Organisiert
- Orleans
- Andere
- Andere Teilnehmer
- Anders
- UNSERE
- übrig
- Überblick
- besitzen
- Palme
- Tafel
- Paradigmen
- Parameter
- Teil
- Teilnehmer
- teil
- besondere
- besonders
- Teile
- passt
- Wegen
- Muster
- Personen
- für
- Wahrnehmung
- ausführen
- Leistung
- Perspektiven
- Stück
- Plato
- Datenintelligenz von Plato
- PlatoData
- plausibel
- spielt
- Datenschutzrichtlinien
- gestellt
- positiv
- positiv
- besitzt
- Möglichkeit
- möglich
- Potenzial
- möglicherweise
- Vorhersage
- prädiktive
- Gegenwart
- presentation
- vorgeführt
- früher
- in erster Linie
- primär
- Grundsätze
- Aufgabenstellung:
- Probleme
- Verfahren
- Prozessdefinierung
- anpassen
- Verarbeitung
- Produziert
- produktiv
- Professor
- zutiefst
- Programmierung
- Projekt
- Projekte
- prominent
- immobilien
- zuverlässig
- die
- vorausgesetzt
- veröffentlicht
- Zweck
- Verfolgung
- Qualität
- Abfragen
- Suche
- ganz
- Rennen
- zufällig
- Angebot
- schnell
- schnell
- lieber
- Bewertungen
- echt
- realen Welt
- vernünftig
- erhalten
- Received
- kürzlich
- Anerkennung
- empfohlen
- Reduzierung
- Betrachtung
- Verstärkung lernen
- Verhältnis
- verhältnismäßig
- Release
- Zuverlässigkeit
- Vertrauen
- verbleibenden
- repetitiv
- Reporting
- Darstellung
- Darstellen
- erfordern
- falls angefordert
- Voraussetzungen:
- Forschungsprojekte
- Forscher
- Forscher
- lösen
- Downloads
- Reagieren
- Befragte
- Antwort
- Antworten
- für ihren Verlust verantwortlich.
- Überprüfen
- robust
- Rollen
- verwurzelt
- rund
- überstürzen
- Safe
- Sicherheit
- Skalierung
- Szenarien
- Szene
- Wissenschaft
- WISSENSCHAFTEN
- Wissenschaftler
- sehen
- auf der Suche nach
- scheint
- gesehen
- Semantik
- Modellreihe
- Gestaltung
- von Locals geführtes
- sie
- Konzerte
- Schild
- Signal
- Signale
- signifikant
- bedeutend
- Einfacher
- Single
- Fähigkeiten
- klein
- schlauer
- Smartphones
- Schmied
- So
- Social Media
- Lösung
- Lösungen
- LÖSEN
- einige
- Klingen
- Quelle
- Raumfahrt
- räumlich
- speziell
- verbringen
- Stabilität
- stabil
- Stanford
- Stanford Universität
- Statistiken
- Immer noch
- Strategien
- Strom
- Stärken
- stark
- Strukturierung
- so
- Schlägt vor
- ZUSAMMENFASSUNG
- liefern
- Überraschung
- Susan
- Syntax
- Synthese
- synthetisch
- synthetische Daten
- System
- Systeme und Techniken
- Takeaways
- nimmt
- Reden
- Gespräche
- Aufgabe
- und Aufgaben
- Team
- Tech
- Technische
- Neigen
- AGB
- Text
- Texterzeugung
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- ihr
- Sie
- Themen
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- Zeit
- zu
- gemeinsam
- Werkzeug
- Werkzeuge
- TOPBOTS
- Thema
- Themen
- Gesamt
- gegenüber
- Tracker
- traditionell
- Ausbildung
- privaten Transfer
- Transformator
- Transparenz
- Bearbeitung
- Trend
- Wahrheit
- Versuch
- WENDE
- XNUMX
- typisch
- für
- erfährt
- Verständnis
- Universität
- Updates
- -
- benutzt
- Nutzer
- Verwendung von
- gewöhnlich
- seit
- wertvoll
- Wert
- Vielfalt
- verschiedene
- lebendig
- Video
- Videos
- Standpunkte
- Seh-
- Sicherheitslücken
- W3
- wurde
- Wege
- we
- tragbar
- GUT
- waren
- Was
- wann
- sobald
- während
- ob
- welche
- während
- WHO
- warum
- breit
- Große Auswahl
- werden wir
- Fenster
- mit
- Arbeiten
- arbeiten,
- Falsch
- Jahr
- noch
- U
- jung
- Zephyrnet