Bezahlte Werbung

Die Herausforderungen beim Erstellen multimodaler Modelle von Grund auf neu
Für viele Anwendungsfälle des maschinellen Lernens verlassen sich Unternehmen ausschließlich auf tabellarische Daten und baumbasierte Modelle wie XGBoost und LightGBM. Denn Deep Learning ist für die meisten ML-Teams einfach zu schwer. Häufige Herausforderungen sind:
- Fehlendes Expertenwissen zur Entwicklung komplexer Deep-Learning-Modelle
- Bei Frameworks wie PyTorch und Tensorflow müssen Teams Tausende von Codezeilen schreiben, die anfällig für menschliche Fehler sind
- Das Trainieren verteilter DL-Pipelines erfordert fundierte Kenntnisse der Infrastruktur und kann Wochen dauern, um Modelle zu trainieren
Infolgedessen verpassen Teams wertvolle Signale, die in unstrukturierten Daten wie Text und Bildern verborgen sind.
Schnelle Modellentwicklung mit deklarativen Systemen
Neue deklarative maschinelle Lernsysteme – wie Open Source Ludwig, das bei Uber gestartet wurde – bieten einen Low-Code-Ansatz zur Automatisierung von ML, der es Datenteams ermöglicht, hochmoderne Modelle mit einer einfachen Konfigurationsdatei schneller zu erstellen und bereitzustellen. Insbesondere Predibase – die führende deklarative Low-Code-ML-Plattform – zusammen mit Ludwig macht es einfach, multimodale Deep-Learning-Modelle in weniger als 15 Codezeilen zu erstellen.
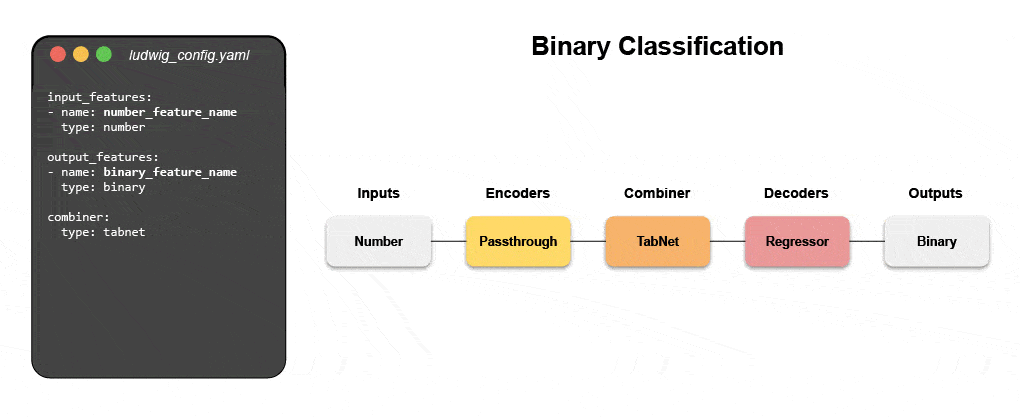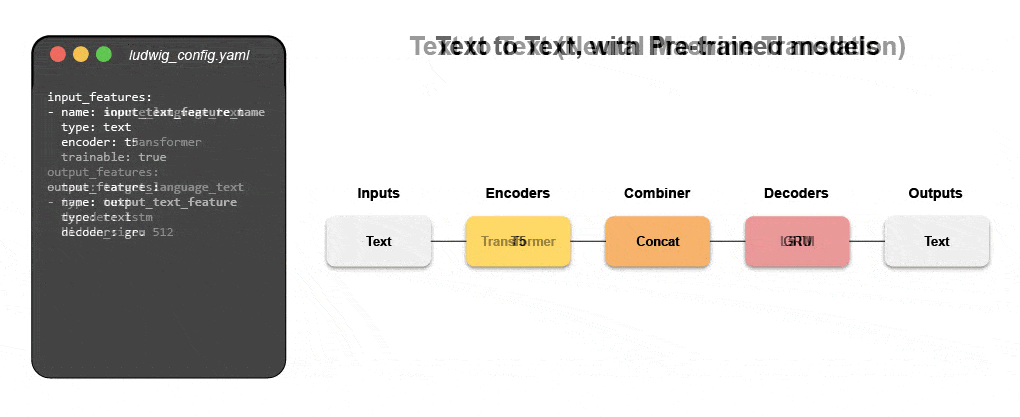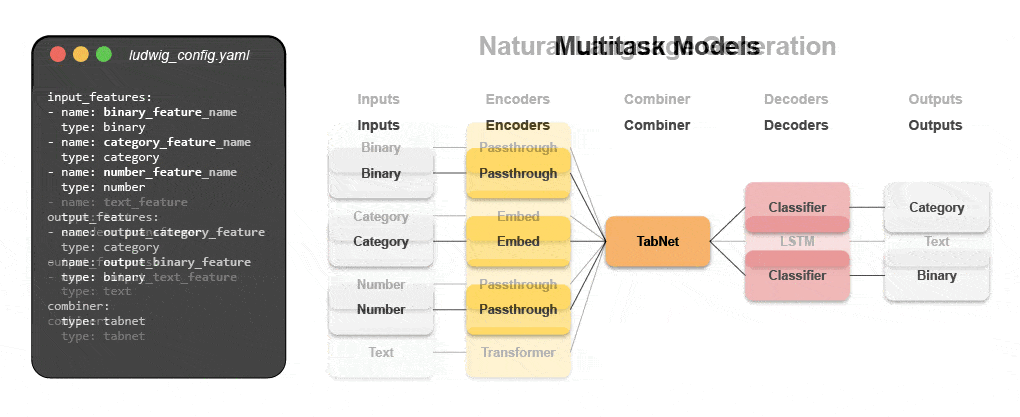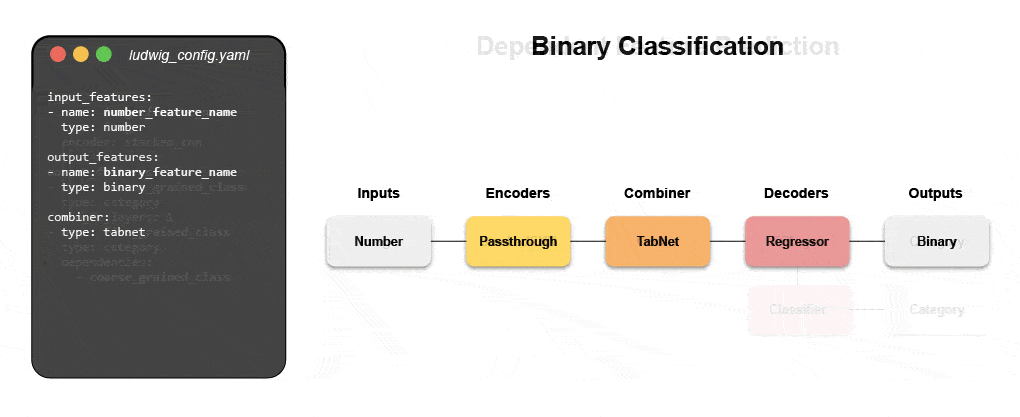
Erfahren Sie, wie Sie mit deklarativem ML ein multimodales Modell erstellen
Nehmen Sie an unserem bevorstehenden Webinar teil und ein Live-Tutorial, um mehr über deklarative Systeme wie Ludwig zu erfahren und Schritt-für-Schritt-Anleitungen zum Erstellen eines multimodalen Vorhersagemodells für Kundenbewertungen unter Nutzung von Text- und Tabellendaten zu befolgen.
In dieser Sitzung lernen Sie, wie Sie:
- Schnelles Trainieren, Iterieren und Bereitstellen eines multimodalen Modells für Vorhersagen von Kundenbewertungen,
- Verwenden Sie Low-Code-Tools für deklaratives ML, um die Zeit, die zum Erstellen mehrerer ML-Modelle benötigt wird, drastisch zu reduzieren.
- Nutzen Sie unstrukturierte Daten genauso einfach wie strukturierte Daten mit Open Source Ludwig und Predibase
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- Über uns
- und
- Ansatz
- automatisieren
- weil
- bauen
- Building
- Herausforderungen
- Code
- gemeinsam
- Komplex
- Konfiguration
- Kunde
- technische Daten
- tief
- tiefe Lernen
- einsetzen
- entwickeln
- Entwicklung
- verteilt
- Dramatisch
- leicht
- ermöglicht
- Fehler
- Experte
- beschleunigt
- Reichen Sie das
- folgen
- für
- gif
- hart
- versteckt
- Ultraschall
- Hilfe
- HTML
- HTTPS
- human
- Bilder
- in
- das
- Infrastruktur
- Anleitung
- IT
- KDnuggets
- Wissen
- führenden
- LERNEN
- lernen
- Nutzung
- Linien
- leben
- Maschine
- Maschinelles Lernen
- um
- viele
- ML
- Modell
- für
- vor allem warme
- mehrere
- erforderlich
- Open-Source-
- Organisationen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Prognose
- Prognosen
- Pytorch
- Veteran
- erfordern
- erfordert
- Folge
- Überprüfen
- Sitzung
- Signale
- Einfacher
- einfach
- speziell
- begonnen
- State-of-the-art
- Schritt
- strukturierte
- Systeme und Techniken
- Nehmen
- nimmt
- Teams
- Tensorfluss
- Das
- Tausende
- Zeit
- zu
- auch
- Werkzeuge
- Training
- Lernprogramm
- anstehende
- Anwendungsfälle
- wertvoll
- Wochen
- werden wir
- .
- schreiben
- XGBoost
- Ihr
- Zephyrnet





