
Während KI von der Cloud zum Edge migriert, sehen wir, dass die Technologie in einer immer größeren Vielfalt von Anwendungsfällen eingesetzt wird – von der Anomalieerkennung bis hin zu Anwendungen wie Smart Shopping, Überwachung, Robotik und Fabrikautomation. Daher gibt es keine einheitliche Lösung. Doch mit der rasanten Zunahme kamerafähiger Geräte wird KI am weitesten verbreitet, um Echtzeit-Videodaten zu analysieren und die Videoüberwachung zu automatisieren, um die Sicherheit zu erhöhen, die Betriebseffizienz zu verbessern und ein besseres Kundenerlebnis zu bieten, was letztlich zu einem Wettbewerbsvorteil in der jeweiligen Branche führt . Um die Videoanalyse besser zu unterstützen, müssen Sie die Strategien zur Optimierung der Systemleistung in Edge-KI-Bereitstellungen verstehen.
- Auswahl der richtigen Rechen-Engines, um die erforderlichen Leistungsniveaus zu erreichen oder zu übertreffen. Für eine KI-Anwendung müssen diese Rechenmaschinen die Funktionen der gesamten Vision-Pipeline ausführen (z. B. Video-Vor- und Nachbearbeitung, neuronale Netzinferenz).
Möglicherweise ist ein dedizierter KI-Beschleuniger erforderlich, sei es diskret oder in einen SoC integriert (im Gegensatz zur Ausführung der KI-Inferenz auf einer CPU oder GPU).
- Den Unterschied zwischen Durchsatz und Latenz verstehen; Dabei ist der Durchsatz die Rate, mit der Daten in einem System verarbeitet werden können, und die Latenz misst die Datenverarbeitungsverzögerung durch das System und wird oft mit der Echtzeit-Reaktionsfähigkeit in Verbindung gebracht. Beispielsweise kann ein System Bilddaten mit 100 Bildern pro Sekunde (Durchsatz) erzeugen, es dauert jedoch 100 ms (Latenz), bis ein Bild das System durchläuft.
- Erwägen Sie die Möglichkeit, die KI-Leistung in Zukunft einfach zu skalieren, um wachsenden Anforderungen, sich ändernden Anforderungen und sich entwickelnden Technologien gerecht zu werden (z. B. fortschrittlichere KI-Modelle für mehr Funktionalität und Genauigkeit). Eine Leistungsskalierung können Sie mit KI-Beschleunigern im Modulformat oder mit zusätzlichen KI-Beschleuniger-Chips erreichen.
Die tatsächlichen Leistungsanforderungen sind anwendungsabhängig. Normalerweise kann man davon ausgehen, dass das System für die Videoanalyse von Kameras eingehende Datenströme mit 30–60 Bildern pro Sekunde und einer Auflösung von 1080p oder 4k verarbeiten muss. Eine KI-fähige Kamera würde einen einzelnen Stream verarbeiten; Eine Edge-Appliance würde mehrere Streams parallel verarbeiten. In jedem Fall muss das Edge-KI-System die Vorverarbeitungsfunktionen unterstützen, um die Sensordaten der Kamera in ein Format umzuwandeln, das den Eingabeanforderungen des KI-Inferenzabschnitts entspricht (Abbildung 1).
Vorverarbeitungsfunktionen nehmen die Rohdaten auf und führen Aufgaben wie Größenänderung, Normalisierung und Farbraumkonvertierung durch, bevor sie die Eingabe in das Modell einspeisen, das auf dem KI-Beschleuniger läuft. Bei der Vorverarbeitung können effiziente Bildverarbeitungsbibliotheken wie OpenCV verwendet werden, um die Vorverarbeitungszeiten zu verkürzen. Bei der Nachbearbeitung wird die Ausgabe der Inferenz analysiert. Es nutzt Aufgaben wie die nicht-maximale Unterdrückung (NMS interpretiert die Ausgabe der meisten Objekterkennungsmodelle) und die Bildanzeige, um umsetzbare Erkenntnisse wie Begrenzungsrahmen, Klassenbezeichnungen oder Konfidenzwerte zu generieren.

Abbildung 1. Bei der KI-Modellinferenzierung werden die Vor- und Nachverarbeitungsfunktionen typischerweise auf einem Anwendungsprozessor ausgeführt.
Die KI-Modellinferenzierung kann je nach den Fähigkeiten der Anwendung die zusätzliche Herausforderung mit sich bringen, mehrere neuronale Netzwerkmodelle pro Frame zu verarbeiten. Computer-Vision-Anwendungen umfassen in der Regel mehrere KI-Aufgaben, die eine Pipeline mehrerer Modelle erfordern. Darüber hinaus ist die Ausgabe eines Modells häufig die Eingabe des nächsten Modells. Mit anderen Worten: Modelle in einer Anwendung hängen oft voneinander ab und müssen nacheinander ausgeführt werden. Der genaue Satz auszuführender Modelle ist möglicherweise nicht statisch und kann dynamisch variieren, sogar von Bild zu Bild.
Die Herausforderung, mehrere Modelle dynamisch auszuführen, erfordert einen externen KI-Beschleuniger mit dediziertem und ausreichend großem Speicher zum Speichern der Modelle. Oft ist der integrierte KI-Beschleuniger in einem SoC aufgrund von Einschränkungen durch das Shared-Memory-Subsystem und andere Ressourcen im SoC nicht in der Lage, die Arbeitslast mit mehreren Modellen zu bewältigen.
Beispielsweise beruht die auf Bewegungsvorhersagen basierende Objektverfolgung auf kontinuierlichen Erkennungen, um einen Vektor zu bestimmen, der zur Identifizierung des verfolgten Objekts an einer zukünftigen Position verwendet wird. Die Wirksamkeit dieses Ansatzes ist begrenzt, da ihm die Fähigkeit zur echten Reidentifizierung fehlt. Bei der Bewegungsvorhersage kann die Spur eines Objekts aufgrund von fehlenden Erkennungen, Verdeckungen oder dem Verlassen des Sichtfelds durch das Objekt verloren gehen, und sei es auch nur vorübergehend. Sobald das Objekt verloren geht, gibt es keine Möglichkeit, die Spur des Objekts erneut zuzuordnen. Das Hinzufügen einer Neuidentifizierung löst diese Einschränkung, erfordert jedoch die Einbettung eines visuellen Erscheinungsbilds (z. B. einen Bildfingerabdruck). Bei der Einbettung des Erscheinungsbilds muss ein zweites Netzwerk einen Merkmalsvektor generieren, indem es das Bild verarbeitet, das im Begrenzungsrahmen des vom ersten Netzwerk erkannten Objekts enthalten ist. Diese Einbettung kann genutzt werden, um das Objekt unabhängig von Zeit und Raum erneut zu identifizieren. Da für jedes im Sichtfeld erkannte Objekt Einbettungen generiert werden müssen, steigen die Verarbeitungsanforderungen, je geschäftiger die Szene wird. Die Objektverfolgung mit Neuidentifizierung erfordert eine sorgfältige Abwägung zwischen der Durchführung einer Erkennung mit hoher Genauigkeit/hoher Auflösung/hoher Bildrate und der Bereitstellung ausreichenden Overheads für die Skalierbarkeit von Einbettungen. Eine Möglichkeit, die Verarbeitungsanforderungen zu lösen, ist die Verwendung eines dedizierten KI-Beschleunigers. Wie bereits erwähnt, kann die KI-Engine des SoC unter dem Mangel an gemeinsam genutzten Speicherressourcen leiden. Die Modelloptimierung kann auch verwendet werden, um den Verarbeitungsbedarf zu senken, sie könnte sich jedoch auf die Leistung und/oder Genauigkeit auswirken.
In einer Smart-Kamera oder einem Edge-Gerät erfasst der integrierte SoC (dh der Host-Prozessor) die Videobilder und führt die zuvor beschriebenen Vorverarbeitungsschritte aus. Diese Funktionen können mit den CPU-Kernen oder der GPU des SoC (sofern verfügbar) ausgeführt werden, sie können aber auch durch dedizierte Hardwarebeschleuniger im SoC (z. B. Bildsignalprozessor) ausgeführt werden. Nachdem diese Vorverarbeitungsschritte abgeschlossen sind, kann der im SoC integrierte KI-Beschleuniger direkt auf diese quantisierte Eingabe aus dem Systemspeicher zugreifen. Im Fall eines diskreten KI-Beschleunigers wird die Eingabe dann zur Inferenz übermittelt, typischerweise über die USB- oder PCIe-Schnittstelle.
Ein integrierter SoC kann eine Reihe von Recheneinheiten enthalten, darunter CPUs, GPUs, KI-Beschleuniger, Vision-Prozessoren, Video-Encoder/Decoder, Bildsignalprozessor (ISP) und mehr. Diese Recheneinheiten teilen sich alle den gleichen Speicherbus und greifen somit auf den gleichen Speicher zu. Darüber hinaus müssen möglicherweise auch die CPU und die GPU eine Rolle bei der Schlussfolgerung spielen, und diese Einheiten sind damit beschäftigt, andere Aufgaben in einem bereitgestellten System auszuführen. Das meinen wir mit Overhead auf Systemebene (Abbildung 2).
Viele Entwickler bewerten fälschlicherweise die Leistung des integrierten KI-Beschleunigers im SoC, ohne die Auswirkungen des Overheads auf Systemebene auf die Gesamtleistung zu berücksichtigen. Betrachten Sie als Beispiel die Ausführung eines YOLO-Benchmarks auf einem 50 TOPS-KI-Beschleuniger, der in einen SoC integriert ist, wodurch möglicherweise ein Benchmark-Ergebnis von 100 Inferenzen/Sekunde (IPS) erzielt wird. Aber in einem eingesetzten System, bei dem alle anderen Recheneinheiten aktiv sind, könnten sich diese 50 TOPS auf etwa 12 TOPS reduzieren und die Gesamtleistung würde nur 25 IPS ergeben, wenn man von einem großzügigen Auslastungsfaktor von 25 % ausgeht. Der Systemaufwand ist immer ein Faktor, wenn die Plattform kontinuierlich Videostreams verarbeitet. Alternativ könnte mit einem diskreten KI-Beschleuniger (z. B. Kinara Ara-1, Hailo-8, Intel Myriad Daten läuft der Beschleuniger autonom und nutzt seinen dedizierten Speicher für den Zugriff auf Modellgewichte und Parameter.
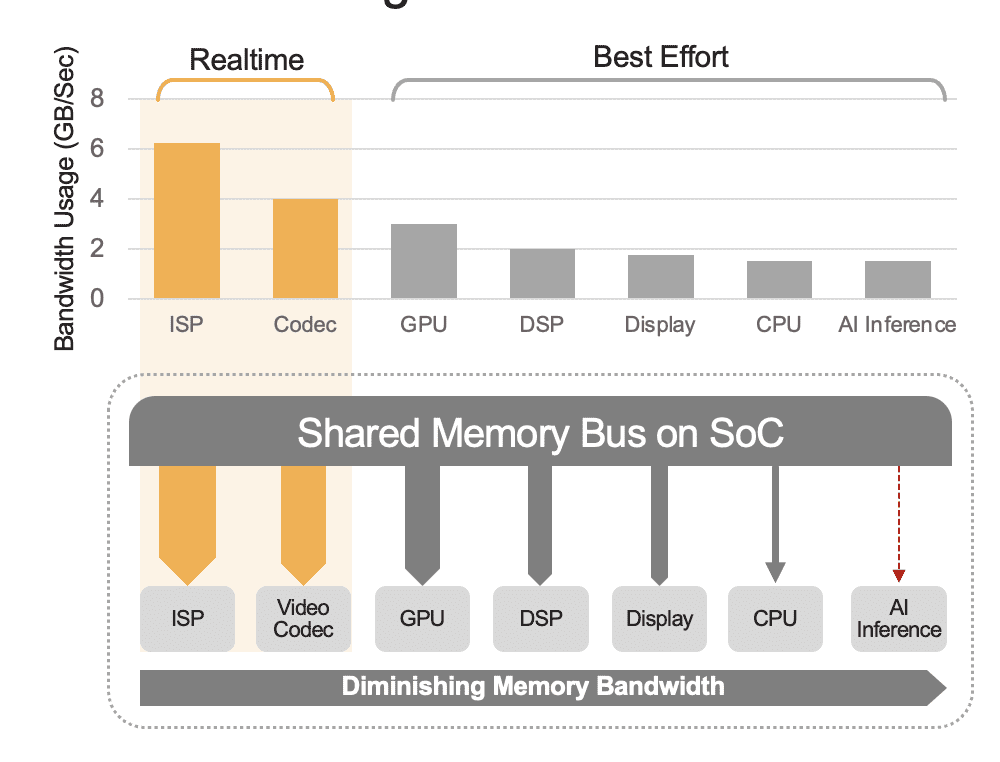
Abbildung 2. Der Shared-Memory-Bus regelt die Leistung auf Systemebene, hier mit geschätzten Werten dargestellt. Die tatsächlichen Werte variieren je nach Anwendungsnutzungsmodell und der Konfiguration der Recheneinheit des SoC.
Bis zu diesem Punkt haben wir die KI-Leistung in Bezug auf Bilder pro Sekunde und TOPS besprochen. Eine geringe Latenz ist jedoch eine weitere wichtige Voraussetzung für die Echtzeit-Reaktionsfähigkeit eines Systems. Beim Spielen beispielsweise ist eine niedrige Latenz entscheidend für ein nahtloses und reaktionsschnelles Spielerlebnis, insbesondere bei bewegungsgesteuerten Spielen und Virtual-Reality-Systemen (VR). In autonomen Fahrsystemen ist eine geringe Latenz für die Echtzeit-Objekterkennung, Fußgängererkennung, Spurerkennung und Verkehrszeichenerkennung von entscheidender Bedeutung, um die Sicherheit nicht zu beeinträchtigen. Autonome Fahrsysteme erfordern typischerweise eine End-to-End-Latenz von weniger als 150 ms von der Erkennung bis zur tatsächlichen Aktion. Ebenso ist in der Fertigung eine niedrige Latenzzeit für die Fehlererkennung und Anomalieerkennung in Echtzeit unerlässlich, und die Roboterführung ist auf Videoanalysen mit geringer Latenz angewiesen, um einen effizienten Betrieb sicherzustellen und Produktionsausfallzeiten zu minimieren.
Im Allgemeinen gibt es drei Latenzkomponenten in einer Videoanalyseanwendung (Abbildung 3):
- Die Datenerfassungslatenz ist die Zeit von der Erfassung eines Videobilds durch den Kamerasensor bis zur Verfügbarkeit des Bilds für das Analysesystem zur Verarbeitung. Sie können diese Latenz optimieren, indem Sie eine Kamera mit einem schnellen Sensor und einem Prozessor mit geringer Latenz wählen, optimale Bildraten auswählen und effiziente Videokomprimierungsformate verwenden.
- Die Datenübertragungslatenz ist die Zeit, die erfasste und komprimierte Videodaten von der Kamera zu den Edge-Geräten oder lokalen Servern benötigen. Dazu gehören Verzögerungen bei der Netzwerkverarbeitung, die an jedem Endpunkt auftreten.
- Die Datenverarbeitungslatenz bezieht sich auf die Zeit, die die Edge-Geräte benötigen, um Videoverarbeitungsaufgaben wie Bilddekomprimierung und Analysealgorithmen (z. B. bewegungsvorhersagebasierte Objektverfolgung, Gesichtserkennung) auszuführen. Wie bereits erwähnt, ist die Verarbeitungslatenz noch wichtiger für Anwendungen, die für jedes Videobild mehrere KI-Modelle ausführen müssen.
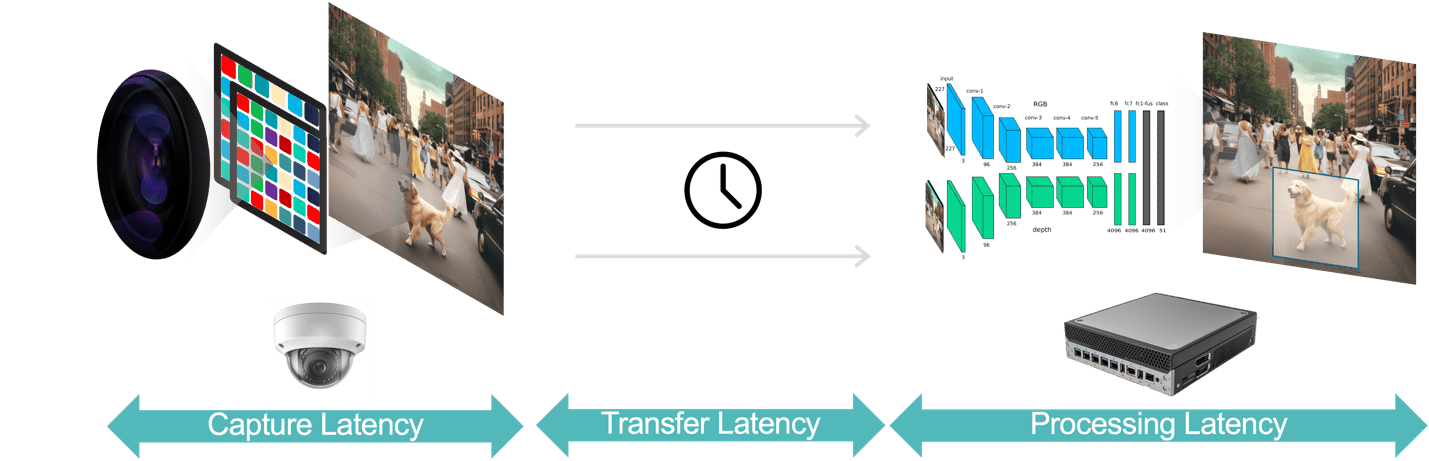
Abbildung 3. Die Videoanalyse-Pipeline besteht aus Datenerfassung, Datenübertragung und Datenverarbeitung.
Die Datenverarbeitungslatenz kann mithilfe eines KI-Beschleunigers optimiert werden, dessen Architektur darauf ausgelegt ist, die Datenbewegung über den Chip und zwischen Rechenleistung und verschiedenen Ebenen der Speicherhierarchie zu minimieren. Um die Latenz und die Effizienz auf Systemebene zu verbessern, muss die Architektur außerdem eine Umschaltzeit von Null (oder nahezu Null) zwischen Modellen unterstützen, um die zuvor besprochenen Anwendungen mit mehreren Modellen besser zu unterstützen. Ein weiterer Faktor für verbesserte Leistung und Latenz betrifft die algorithmische Flexibilität. Mit anderen Worten: Einige Architekturen sind nur für ein optimales Verhalten bei bestimmten KI-Modellen konzipiert, aber angesichts der sich schnell verändernden KI-Umgebung erscheinen scheinbar jeden zweiten Tag neue Modelle für höhere Leistung und bessere Genauigkeit. Wählen Sie daher einen Edge-KI-Prozessor ohne praktische Einschränkungen hinsichtlich Modelltopologie, Operatoren und Größe.
Bei der Maximierung der Leistung einer Edge-KI-Appliance müssen viele Faktoren berücksichtigt werden, darunter Leistungs- und Latenzanforderungen sowie System-Overhead. Eine erfolgreiche Strategie sollte einen externen KI-Beschleuniger in Betracht ziehen, um die Speicher- und Leistungsbeschränkungen in der KI-Engine des SoC zu überwinden.
CH Chee Chee ist ein versierter Produktmarketing- und Managementmanager und verfügt über umfassende Erfahrung in der Förderung von Produkten und Lösungen in der Halbleiterindustrie mit Schwerpunkt auf visionärer KI, Konnektivität und Videoschnittstellen für mehrere Märkte, darunter Unternehmen und Verbraucher. Als Unternehmer war Chee Mitbegründer zweier Video-Halbleiter-Start-ups, die von einem börsennotierten Halbleiterunternehmen übernommen wurden. Chee leitete Produktmarketingteams und arbeitet gerne mit einem kleinen Team zusammen, das sich darauf konzentriert, großartige Ergebnisse zu erzielen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :hast
- :Ist
- :nicht
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- Fähigkeit
- Beschleuniger
- Beschleuniger
- Zugang
- Zugriff
- unterbringen
- erreichen
- Genauigkeit
- Erreichen
- erworben
- Erwirbt
- über
- Action
- aktiv
- präsentieren
- Hinzufügen
- Zusätzliche
- angenommen
- advanced
- Nach der
- aufs Neue
- AI
- KI-Engine
- KI-Modelle
- algorithmisch
- Algorithmen
- Alle
- ebenfalls
- immer
- an
- Analyse
- Analytik
- Analyse
- und
- Anomalieerkennung
- Ein anderer
- Anwendung
- Anwendungen
- Ansatz
- Architektur
- SIND
- AS
- damit verbundenen
- At
- automatisieren
- Automation
- Autonom
- autonom
- Verfügbarkeit
- verfügbar
- vermeiden
- basierend
- Grundlage
- BE
- weil
- wird
- war
- Bevor
- Sein
- Benchmark
- Besser
- zwischen
- beide
- Box
- Boxen
- eingebaut
- Bus
- beschäftigt
- aber
- by
- Kamera
- Kameras
- CAN
- Fähigkeiten
- capability
- Erfassung
- gefangen
- Capturing
- vorsichtig
- Häuser
- Fälle
- challenges
- Ändern
- Chip
- Pommes frites
- Auswahl
- Klasse
- Cloud
- Farbe
- Kommen
- Unternehmen
- wettbewerbsfähig
- Abgeschlossene Verkäufe
- Komponenten
- kompromittierend
- Berechnung
- rechnerisch
- Berechnen
- Computer
- Computer Vision
- Computer Vision-Anwendungen
- Vertrauen
- Konfiguration
- Konnektivität
- Folglich
- Geht davon
- Berücksichtigung
- betrachtet
- Berücksichtigung
- besteht
- Einschränkungen
- Verbraucher
- enthalten
- enthalten
- kontinuierlich
- ständig
- Umwandlung (Conversion)
- könnte
- CPU
- kritischem
- Kunde
- technische Daten
- Datenverarbeitung
- Tag
- gewidmet
- verzögern
- Verzögerungen
- Übergeben
- geliefert
- abhängig
- Abhängig
- Einsatz
- Implementierungen
- beschrieben
- entworfen
- erkannt
- Entdeckung
- Bestimmen
- Entwickler
- Geräte
- Unterschied
- Direkt
- diskutiert
- Display
- Ausfallzeit
- Fahren
- zwei
- dynamisch
- e
- jeder
- Früher
- leicht
- Edge
- bewirken
- Wirksamkeit
- Wirkungsgrade
- Effizienz
- effizient
- entweder
- Einbettung
- Ende
- End-to-End
- Motor
- Motor (en)
- zu steigern,
- gewährleisten
- Unternehmen
- Ganz
- Unternehmer
- Arbeitsumfeld
- essential
- geschätzt
- bewerten
- Sogar
- Jedes
- sich entwickelnden
- Beispiel
- überschreiten
- ausführen
- ausgeführt
- Exekutive
- erwarten
- ERFAHRUNGEN
- Erfahrungen
- umfangreiche
- Langjährige Erfahrung
- extern
- Gesicht
- Gesichtserkennung
- Faktor
- Faktoren
- Fabrik
- FAST
- Merkmal
- Fütterung
- Feld
- Abbildung
- Fingerabdruck
- Vorname
- Flexibilität
- konzentriert
- Fokussierung
- Aussichten für
- Format
- FRAME
- für
- Funktion
- Funktionalität
- Funktionen
- Außerdem
- Zukunft
- gewinnen
- Games
- Gaming
- Spielerlebnis
- Allgemeines
- erzeugen
- erzeugt
- großzügig
- Go
- GPU
- GPUs
- groß
- mehr
- persönlichem Wachstum
- Wachstum
- die Vermittlung von Kompetenzen,
- Hardware
- Haben
- daher
- hier
- Hierarchie
- GUTE
- höher
- Gastgeber
- HTTPS
- i
- identifizieren
- if
- Image
- Impact der HXNUMXO Observatorien
- wichtig
- auferlegten
- zu unterstützen,
- verbessert
- in
- In anderen
- Dazu gehören
- Einschließlich
- Erhöhung
- hat
- Branchen
- Energiegewinnung
- Initiiert
- Varianten des Eingangssignals:
- innerhalb
- Einblicke
- integriert
- Intel
- Schnittstelle
- Schnittstellen
- in
- beteiligen
- beinhaltet
- unabhängig
- ISP
- IT
- SEINE
- KDnuggets
- Etiketten
- Mangel
- Spur
- grosse
- Latency
- Verlassen
- geführt
- weniger
- Cholesterinspiegel
- Bibliotheken
- Gefällt mir
- Einschränkung
- Einschränkungen
- Limitiert
- aus einer regionalen
- verloren
- Sneaker
- senken
- verwalten
- Management
- Herstellung
- viele
- Marketing
- Märkte
- Maximieren
- Maximierung
- Kann..
- bedeuten
- Maßnahmen
- Triff
- Memory
- erwähnt
- könnte
- vermisst
- Modell
- für
- Modulen
- Überwachung
- mehr
- vor allem warme
- Bewegung
- Bewegung
- mehrere
- sollen
- Myriade
- In der Nähe von
- Bedürfnisse
- Netzwerk
- Neural
- neuronale Netzwerk
- Neu
- weiter
- nicht
- Objekt
- Objekterkennung
- auftreten
- of
- vorgenommen,
- on
- einmal
- EINEM
- einzige
- OpenCV
- Betrieb
- Betriebs-
- Betreiber
- entgegengesetzt
- optimal
- Optimierung
- Optimieren
- optimiert
- Optimierung
- or
- Andere
- Möglichkeiten für das Ausgangssignal:
- übrig
- Gesamt-
- Überwinden
- Parallel
- Parameter
- besonders
- für
- ausführen
- Leistung
- durchgeführt
- Durchführung
- führt
- Pipeline
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- Points
- Position
- Nachbearbeitung
- Praktisch
- Prognose
- Prozessdefinierung
- verarbeitet
- Verarbeitung
- Prozessor
- Prozessoren
- Produkt
- Produktion
- Produkte
- Die Förderung der
- die
- Öffentlichkeit
- Angebot
- Bereich
- schnell
- schnell
- Bewerten
- Honorar
- Roh
- Rohdaten
- echt
- Echtzeit
- Realität
- Anerkennung
- Veteran
- bezieht sich
- erfordern
- falls angefordert
- Anforderung
- Voraussetzungen:
- erfordert
- Auflösung
- Downloads
- ansprechbar
- Einschränkungen
- Folge
- Die Ergebnisse
- Robotik
- Rollen
- Führen Sie
- Laufen
- läuft
- Sicherheit
- gleich
- Skalierbarkeit
- Skalieren
- Skala ai
- Skalierung
- Szene
- Partituren
- nahtlos
- Zweite
- Abschnitt
- sehen
- scheint
- Auswahl
- Halbleiter
- kompensieren
- Teilen
- von Locals geführtes
- Shopping
- sollte
- gezeigt
- Schild
- Signal
- Ähnlich
- da
- Single
- Größe
- klein
- smart
- Lösung
- Lösungen
- LÖSEN
- Löst
- einige
- etwas
- Raumfahrt
- spezifisch
- Start-ups
- Shritte
- speichern
- Strategien
- Strategie
- Strom
- Ströme
- erfolgreich
- so
- ausreichend
- Support
- Unterdrückung
- Überwachung
- System
- Systeme und Techniken
- Nehmen
- nimmt
- und Aufgaben
- Team
- Teams
- Technologies
- Technologie
- AGB
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- ihr
- dann
- Dort.
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- Durchsatz
- Zeit
- mal
- zu
- Tops & Pullover
- Gesamt
- verfolgen sind
- Tracking
- der Verkehr
- privaten Transfer
- Transfers
- Transformieren
- reisen
- was immer dies auch sein sollte.
- XNUMX
- typisch
- Letztlich
- nicht fähig
- verstehen
- Einheit
- Bereiche
- Anwendungsbereich
- USB
- -
- benutzt
- verwendet
- Verwendung von
- gewöhnlich
- Verwendung
- Werte
- Vielfalt
- verschiedene
- Video
- Anzeigen
- Assistent
- Virtuelle Realität
- Seh-
- lebenswichtig
- vr
- Weg..
- we
- waren
- Was
- ob
- welche
- weit
- werden wir
- mit
- ohne
- Worte
- arbeiten,
- würde
- X
- Ausbeute
- Yolo
- U
- Ihr
- Zephyrnet
- Null







