Zusammenfassungsagenten, vorgestellt vom KI-Bildgenerierungstool Dall-E.
Gehören Sie zu der Bevölkerung, die jedes Mal, wenn Sie ein neues Restaurant besuchen, eine Bewertung auf Google Maps hinterlässt?
Oder sind Sie vielleicht der Typ, der Ihre Meinung zu Amazon-Käufen äußert, insbesondere wenn Sie von einem minderwertigen Produkt angeregt werden?
Mach dir keine Sorgen, ich werde dir keine Vorwürfe machen – wir alle haben unsere Momente!
In der heutigen Datenwelt tragen wir alle auf vielfältige Weise zur Datenflut bei. Ein Datentyp, den ich aufgrund seiner Vielfalt und Schwierigkeit der Interpretation besonders interessant finde, sind Textdaten, wie beispielsweise die unzähligen Rezensionen, die täglich im Internet veröffentlicht werden. Haben Sie schon einmal darüber nachgedacht, wie wichtig die Standardisierung und Verdichtung von Textdaten ist? Willkommen in der Welt der Zusammenfassungsagenten!
Zusammenfassungsagenten haben sich nahtlos in unser tägliches Leben integriert, indem sie Informationen zusammenfassen und schnellen Zugriff auf relevante Inhalte über eine Vielzahl von Anwendungen und Plattformen hinweg ermöglichen.
In diesem Artikel untersuchen wir die Verwendung von ChatGPT als leistungsstarken Zusammenfassungsagenten für unsere benutzerdefinierten Anwendungen. Dank der Fähigkeit von Large Language Models (LLM), Texte zu verarbeiten und zu verstehen, Sie können dabei helfen, Texte zu lesen und genaue Zusammenfassungen zu erstellen oder Informationen zu standardisieren. Es ist jedoch wichtig zu wissen, wie man sein Potenzial bei der Bewältigung einer solchen Aufgabe ausschöpft und sich seiner Grenzen bewusst ist.
Die größte Einschränkung für die Zusammenfassung? LLMs versagen oft, wenn es darum geht, bestimmte Zeichen- oder Wortbeschränkungen einzuhalten in ihren Zusammenfassungen.
Sehen wir uns die Best Practices zum Erstellen von Zusammenfassungen mit ChatGPT an für unsere benutzerdefinierte Anwendung sowie die Gründe für ihre Einschränkungen und wie man diese überwindet!
Wenn dieser ausführliche Bildungsinhalt für Sie nützlich ist, können Sie dies tun Abonnieren Sie unsere AI Research Mailingliste benachrichtigt werden, wenn wir neues Material veröffentlichen.
Effektive Zusammenfassung mit ChatGPT
Zusammenfassungsagenten werden überall im Internet verwendet. Beispielsweise verwenden Websites Zusammenfassungsagenten, um prägnante Zusammenfassungen von Artikeln anzubieten, sodass Benutzer sich einen schnellen Überblick über die Nachrichten verschaffen können, ohne sich in den gesamten Inhalt vertiefen zu müssen. Dies tun auch Social-Media-Plattformen und Suchmaschinen.
Von Nachrichtenaggregatoren und Social-Media-Plattformen bis hin zu E-Commerce-Websites sind Zusammenfassungsagenten zu einem integralen Bestandteil unserer digitalen Landschaft geworden. Und mit der Verbreitung von LLMs nutzen einige dieser Agenten jetzt KI für effektivere Zusammenfassungsergebnisse.
ChatGPT kann ein guter Verbündeter beim Erstellen einer Anwendung sein, die Zusammenfassungsagenten verwendet, um Leseaufgaben zu beschleunigen und Texte zu klassifizieren. Stellen Sie sich zum Beispiel vor, wir haben ein E-Commerce-Unternehmen und sind daran interessiert, alle unsere Kundenbewertungen zu verarbeiten. ChatGPT könnte uns dabei helfen, eine bestimmte Bewertung in wenigen Sätzen zusammenzufassen, sie in ein generisches Format zu standardisieren und zu bestimmen die Stimmung der Rezension und die Klassifizierung es entsprechend.
Es stimmt zwar, dass wir die Bewertung einfach an ChatGPT weiterleiten könnten, es gibt jedoch eine Liste mit Best Practices – und Dinge, die man vermeiden sollte – um die Leistungsfähigkeit von ChatGPT bei dieser konkreten Aufgabe zu nutzen.
Lassen Sie uns die Möglichkeiten erkunden, indem wir dieses Beispiel zum Leben erwecken!
Beispiel: E-Commerce-Bewertungen
Selbstgemachtes GIF.
Betrachten Sie das obige Beispiel, in dem wir daran interessiert sind, alle Bewertungen für ein bestimmtes Produkt auf unserer E-Commerce-Website zu verarbeiten. Wir wären daran interessiert, Bewertungen wie die folgende zu unserem Spitzenprodukt zu bearbeiten: der erste Computer für Kinder!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
In diesem Fall möchten wir, dass ChatGPT:
Klassifizieren Sie die Bewertung in positiv oder negativ.
Geben Sie eine Zusammenfassung der Rezension von 20 Wörtern an.
Geben Sie die Antwort mit einer konkreten Struktur aus, um alle Bewertungen in einem einzigen Format zu standardisieren.
Implementierungshinweise
Hier ist die grundlegende Codestruktur, die wir verwenden könnten, um ChatGPT aus unserer benutzerdefinierten Anwendung aufzurufen. Ich stelle auch einen Link zu a zur Verfügung Jupyter Notizbuch mit allen in diesem Artikel verwendeten Beispielen.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
Die Funktion get_completion() ruft die ChatGPT-API mit einem gegebenen Wert auf Eingabeaufforderung. Wenn die Eingabeaufforderung zusätzliche Informationen enthält Benutzertext, wie in unserem Fall die Rezension selbst, wird sie durch dreifache Anführungszeichen vom Rest des Codes getrennt.
Verwenden wir die get_completion() Funktion zur Aufforderung an ChatGPT!
Hier ist eine Eingabeaufforderung, die die oben beschriebenen Anforderungen erfüllt:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Wie wir jedoch anhand der Ausgabe sehen können, ist die Rezension korrekt und gut strukturiert Es fehlen einige Informationen, die für uns als Eigentümer des E-Commerce von Interesse sein könnten, beispielsweise Informationen zur Lieferung des Produkts.
Fassen Sie mit einem Fokus auf zusammen
Wir können unsere Eingabeaufforderung iterativ verbessern und ChatGPT bitten, sich auf bestimmte Dinge in der Zusammenfassung zu konzentrieren. In diesem Fall sind wir an den Angaben zum Versand und zur Lieferung interessiert:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Diesmal lautet die Antwort von ChatGPT wie folgt:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Jetzt ist die Rezension viel vollständiger. Es ist wichtig, Einzelheiten zum wichtigen Schwerpunkt der ursprünglichen Überprüfung anzugeben, um zu vermeiden, dass ChatGPT einige Informationen überspringt, die für unseren Anwendungsfall wertvoll sein könnten.
Ist Ihnen aufgefallen, dass dieser zweite Test zwar Informationen zur Lieferung enthält, der einzige negative Aspekt der ursprünglichen Rezension jedoch übersprungen wurde?
Lassen Sie uns das beheben!
„Extrahieren“ statt „Zusammenfassen“
Durch die Untersuchung von Zusammenfassungsaufgaben habe ich das herausgefunden Die Zusammenfassung kann für LLMs eine schwierige Aufgabe sein, wenn die Benutzeraufforderung nicht genau genug ist.
Wenn ChatGPT gebeten wird, eine Zusammenfassung eines bestimmten Textes bereitzustellen, kann es Informationen überspringen, die für uns relevant sein könnten – wie wir kürzlich erfahren haben – Oder es gibt allen Themen im Text die gleiche Bedeutung und gibt nur einen Überblick über die Hauptpunkte.
Experten für LLMs verwenden den Begriff Extrakt und zusätzliche Informationen zu ihren Schwerpunkten statt zusammenfassen bei der Ausführung solcher Aufgaben mit Unterstützung dieser Art von Modellen.
Während die Zusammenfassung darauf abzielt, einen prägnanten Überblick über die Hauptpunkte des Textes zu geben, einschließlich der Themen, die nichts mit dem Schwerpunktthema zu tun haben, konzentriert sich die Informationsextraktion auf das Abrufen spezifischer Details und können uns genau das geben, was wir suchen. Versuchen wir es dann mit der Extraktion!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
In diesem Fall erhalten wir durch die Extraktion nur Informationen zu unserem Schwerpunktthema: Shipping: Arrived a day earlier than expected.
Automatisierung
Dieses System funktioniert für eine einzelne Rezension. Dennoch gilt es bei der Gestaltung einer Aufforderung für eine konkrete Anwendung Es ist wichtig, es anhand einer Reihe von Beispielen zu testen, damit wir Ausreißer oder Fehlverhalten im Modell erkennen können.
Im Falle der Verarbeitung mehrerer Bewertungen finden Sie hier eine Beispiel-Python-Codestruktur, die hilfreich sein kann.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Hier sind die Zusammenfassungen unserer Reihe von Rezensionen:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Beachten Sie, dass die Wortbeschränkung unserer Zusammenfassungen zwar in unseren Eingabeaufforderungen klar genug war, wir jedoch leicht erkennen können, dass diese Wortbeschränkung in keiner der Iterationen umgesetzt wird.
Diese Diskrepanz bei der Wortzählung entsteht, weil LLMs kein genaues Verständnis der Wort- oder Zeichenanzahl haben. Der Grund dafür liegt in einer der wichtigsten Komponenten ihrer Architektur: der Tokenizer.
Tokenisierer
LLMs wie ChatGPT sind darauf ausgelegt, Text auf der Grundlage statistischer Muster zu generieren, die aus riesigen Mengen an Sprachdaten gelernt wurden. Obwohl sie sehr effektiv darin sind, flüssige und kohärente Texte zu erzeugen, mangelt es ihnen an präziser Kontrolle über die Wortzahl.
Wenn wir in den obigen Beispielen Anweisungen zu einer sehr genauen Wortanzahl gegeben haben, ChatGPT hatte Mühe, diese Anforderungen zu erfüllen. Stattdessen wurde Text generiert, der tatsächlich kürzer als die angegebene Wortanzahl ist.
In anderen Fällen kann es zu längeren Texten oder einfach zu ausführlichen Texten oder fehlenden Details kommen. Zusätzlich, ChatGPT priorisiert möglicherweise andere Faktoren wie Kohärenz und Relevanz gegenüber der strikten Einhaltung der Wortanzahl. Dies kann dazu führen, dass der Text inhaltlich und kohärent hochwertig ist, aber nicht genau den Anforderungen an die Wortanzahl entspricht.
Der Tokenizer ist das Schlüsselelement in der Architektur von ChatGPT, das die Anzahl der Wörter in der generierten Ausgabe deutlich beeinflusst.
Selbstgemachtes GIF.
Tokenizer-Architektur
Der Tokenizer ist der erste Schritt im Prozess der Textgenerierung. Es ist dafür verantwortlich, den Text, den wir in ChatGPT eingeben, in einzelne Elemente zu zerlegen — Token —, die dann vom Sprachmodell verarbeitet werden, um neuen Text zu generieren.
Wenn der Tokenizer einen Text in Token zerlegt, geschieht dies auf der Grundlage einer Reihe von Regeln, die darauf ausgelegt sind, die sinnvollen Einheiten der Zielsprache zu identifizieren. Allerdings sind diese Regeln nicht immer perfekt, und Es kann vorkommen, dass der Tokenizer Token auf eine Weise aufteilt oder zusammenführt, die sich auf die Gesamtwortzahl des Textes auswirkt.
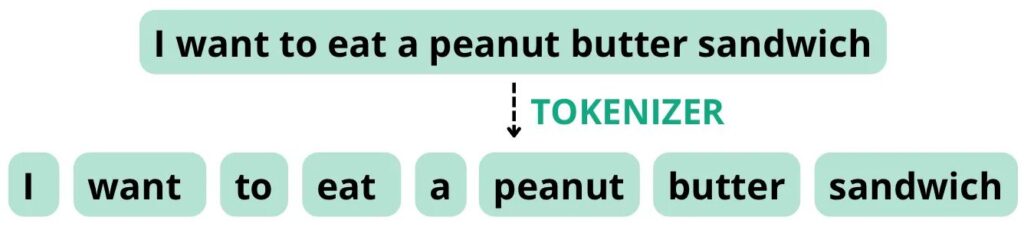
Betrachten Sie zum Beispiel den folgenden Satz: „Ich möchte ein Erdnussbutter-Sandwich essen.“ Wenn der Tokenizer so konfiguriert ist, dass er Token basierend auf Leerzeichen und Satzzeichen aufteilt, kann er diesen Satz in die folgenden Token mit einer Gesamtwortanzahl von 8 aufteilen, was der Tokenanzahl entspricht.
Selbstgemachtes Bild.
Wenn der Tokenizer jedoch für die Behandlung konfiguriert ist "Erdnussbutter" Als zusammengesetztes Wort kann es den Satz in die folgenden Token zerlegen: mit einer Gesamtwortzahl von 8, aber einer Tokenzahl von 7.
Daher kann die Art und Weise, wie der Tokenizer konfiguriert ist, die Gesamtwortzahl des Textes beeinflussen, und dies kann sich auf die Fähigkeit des LLM auswirken, Anweisungen zur genauen Wortanzahl zu befolgen. Während einige Tokenizer Optionen zum Anpassen der Texttokenisierung bieten, reicht dies nicht immer aus, um die genaue Einhaltung der Anforderungen an die Wortzahl sicherzustellen. Für ChatGPT können wir in diesem Fall diesen Teil seiner Architektur nicht kontrollieren.
Dadurch ist ChatGPT nicht so gut darin, Zeichen- oder Wortbeschränkungen einzuhalten, aber man kann es stattdessen mit Sätzen versuchen, da der Tokenizer keine Auswirkungen hat die Anzahl der Sätze, sondern ihre Länge.
Wenn Sie sich dieser Einschränkung bewusst sind, können Sie die für Ihre Anwendung am besten geeignete Eingabeaufforderung erstellen. Nachdem wir nun wissen, wie die Wortzählung bei ChatGPT funktioniert, machen wir einen letzten Schritt mit unserer Eingabeaufforderung für die E-Commerce-Anwendung!
Zusammenfassung: E-Commerce-Bewertungen
Lassen Sie uns unsere Erkenntnisse aus diesem Artikel in einer abschließenden Aufforderung zusammenfassen! In diesem Fall werden wir nach den Ergebnissen fragen HTML Format für eine schönere Ausgabe:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
Und hier ist die endgültige Ausgabe von ChatGPT:
Selbst gemachter Screenshot von der Jupyter Notizbuch mit den in diesem Artikel verwendeten Beispielen.
Zusammenfassung
In diesem Artikel Wir haben die Best Practices für die Verwendung von ChatGPT als Zusammenfassungsagent für unsere benutzerdefinierte Anwendung besprochen.
Wir haben gesehen, dass es beim Erstellen einer Anwendung äußerst schwierig ist, im ersten Versuch die perfekte Eingabeaufforderung zu finden, die Ihren Anwendungsanforderungen entspricht. Ich denke, eine nette Botschaft zum Mitnehmen ist es Stellen Sie sich Aufforderungen als einen iterativen Prozess vor Hier verfeinern und modellieren Sie Ihre Eingabeaufforderung, bis Sie genau die gewünschte Ausgabe erhalten.
Indem Sie Ihre Eingabeaufforderung iterativ verfeinern und auf eine Reihe von Beispielen anwenden, bevor Sie sie in der Produktion bereitstellen, können Sie dies sicherstellen Die Ausgabe ist über mehrere Beispiele hinweg konsistent und deckt Ausreißerantworten ab. In unserem Beispiel könnte es vorkommen, dass jemand statt einer Rezension einen zufälligen Text liefert. Wir können ChatGPT anweisen, auch eine standardisierte Ausgabe zu haben, um diese Ausreißerantworten auszuschließen.
Wenn Sie ChatGPT für eine bestimmte Aufgabe verwenden, empfiehlt es sich außerdem, sich über die Vor- und Nachteile der Verwendung von LLMs für unsere Zielaufgabe zu informieren. So sind wir auf die Tatsache gestoßen, dass Extraktionsaufgaben effektiver sind als Zusammenfassungen, wenn wir eine allgemeine, menschenähnliche Zusammenfassung eines Eingabetextes wünschen. Wir haben auch gelernt, dass die Bereitstellung des Schwerpunkts der Zusammenfassung eine sein kann Game-Changer bezüglich der generierten Inhalte.
Schließlich können LLMs zwar sehr effektiv bei der Textgenerierung sein, Sie sind nicht ideal, um genaue Anweisungen zur Wortzahl oder anderen spezifischen Formatierungsanforderungen zu befolgen. Um diese Ziele zu erreichen, kann es notwendig sein, beim Satzzählen zu bleiben oder andere Tools oder Methoden zu verwenden, wie z. B. manuelle Bearbeitung oder speziellere Software.
Dieser Artikel wurde ursprünglich veröffentlicht am Auf dem Weg zu Data Science und mit Genehmigung des Autors erneut auf TOPBOTS veröffentlicht.
Genießen Sie diesen Artikel? Melden Sie sich für weitere AI-Forschungsupdates an.
Wir werden Sie informieren, wenn wir weitere zusammenfassende Artikel wie diesen veröffentlichen.