Amazon RedShift, ein weit verbreitetes Cloud-Data-Warehouse, wurde erheblich weiterentwickelt, um den Leistungsanforderungen der anspruchsvollsten Arbeitslasten gerecht zu werden. In diesem Beitrag geht es um eine dieser neuen Funktionen: den Sortierschlüssel für das mehrdimensionale Datenlayout.
Amazon Redshift verbessert jetzt Ihre Abfrageleistung durch die Unterstützung mehrdimensionaler Datenlayout-Sortierschlüssel. Dabei handelt es sich um einen neuen Typ von Sortierschlüsseln, der die Daten einer Tabelle nach Filterprädikaten statt nach physischen Spalten der Tabelle sortiert. Sortierschlüssel für mehrdimensionale Datenlayouts verbessern die Leistung von Tabellenscans erheblich, insbesondere wenn Ihre Abfragearbeitslast sich wiederholende Scanfilter enthält.
Amazon Redshift bietet bereits die Möglichkeit dazu automatische Tabellenoptimierung (ATO), das das Design von Tabellen automatisch optimiert, indem es Sortier- und Verteilungsschlüssel anwendet, ohne dass ein Administratoreingriff erforderlich ist. In diesem Beitrag stellen wir mehrdimensionale Datenlayout-Sortierschlüssel als zusätzliche Funktion vor, die von ATO angeboten und durch den Sortierschlüssel-Advisor-Algorithmus von Amazon Redshift verstärkt wird.
Sortierschlüssel für mehrdimensionale Datenlayouts
Wenn Sie eine Tabelle mit dem Sortierschlüssel AUTO definieren, analysiert Amazon Redshift ATO Ihren Abfrageverlauf und wählt automatisch entweder einen einspaltigen Sortierschlüssel oder einen mehrdimensionalen Datenlayout-Sortierschlüssel für Ihre Tabelle aus, je nachdem, welche Option für Ihre Arbeitslast besser ist. Wenn ein mehrdimensionales Datenlayout ausgewählt ist, erstellt Amazon Redshift eine mehrdimensionale Sortierfunktion, die Zeilen anordnet, auf die normalerweise von denselben Abfragen zugegriffen wird, und die Sortierfunktion wird anschließend während der Abfrageläufe verwendet, um Datenblöcke und sogar das Scannen des einzelnen Prädikats zu überspringen Säulen.
Betrachten Sie die folgende Benutzerabfrage, die ein dominantes Abfragemuster in der Arbeitslast des Benutzers darstellt:
Amazon Redshift speichert Daten für jede Spalte in 1-MB-Festplattenblöcken und speichert die Minimal- und Maximalwerte in jedem Block als Teil der Metadaten der Tabelle. Wenn eine Abfrage a verwendet Bereichsbeschränktes PrädikatAmazon Redshift kann die Minimal- und Maximalwerte verwenden, um bei Tabellenscans schnell eine große Anzahl von Blöcken zu überspringen. Der Filter dieser Abfrage für die Subregion-Spalte kann jedoch nicht verwendet werden, um basierend auf Mindest- und Höchstwerten zu bestimmen, welche Blöcke übersprungen werden sollen. Daher durchsucht Amazon Redshift alle Zeilen aus der Titeltabelle:
Wann die Abfrage des Benutzers ausgeführt wurde mit titles Verwenden eines einspaltigen Sortierschlüssels subregion, das Ergebnis der vorherigen Abfrage lautet wie folgt:
Dies zeigt, dass der Tabellenscan 2,164,081,640 Zeilen gelesen hat.
Um die Scans zu verbessern titles In der Tabelle entscheidet sich Amazon Redshift möglicherweise automatisch für die Verwendung eines Sortierschlüssels für das mehrdimensionale Datenlayout. Alle Zeilen, die die Anforderungen erfüllen lower(subregion) like '%United States%' Das Prädikat würde sich in einem dedizierten Bereich der Tabelle befinden, und daher scannt Amazon Redshift nur Datenblöcke, die das Prädikat erfüllen.
Wenn die Abfrage des Benutzers mit ausgeführt wird titles Verwenden eines mehrdimensionalen Datenlayout-Sortierschlüssels, der Folgendes umfasst: lower(subregion) like '%United States%' als Prädikat das Ergebnis des sys_query_detail Die Abfrage lautet wie folgt:
Dies zeigt, dass der Tabellenscan 152,324,046 Zeilen gelesen hat, was nur 7 % des Originals entspricht, und dass der Sortierschlüssel für das mehrdimensionale Datenlayout verwendet wurde.
Beachten Sie, dass dieses Beispiel eine einzelne Abfrage verwendet, um die Funktion des mehrdimensionalen Datenlayouts zu veranschaulichen, Amazon Redshift jedoch alle Abfragen berücksichtigt, die für die Tabelle ausgeführt werden, und mehrere Regionen erstellen kann, um die am häufigsten ausgeführten Prädikate zu erfüllen.
Nehmen wir ein weiteres Beispiel, dieses Mal mit komplexeren Prädikaten und mehreren Abfragen.
Stellen Sie sich vor, Sie hätten einen Tisch items (cost int, available int, demand int) mit vier Reihen, wie im folgenden Beispiel gezeigt.
| #Ich würde | kosten | verfügbar | Nachfrage |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Ihre dominante Arbeitslast besteht aus zwei Abfragen:
- 70 % Abfragemuster:
- 20 % Abfragemuster:
Bei herkömmlichen Sortiertechniken könnten Sie sich dafür entscheiden, die Tabelle nach der Kostenspalte zu sortieren, sodass die Auswertung von erfolgt cost > 3 wird von der Sorte profitieren. Also, die Artikeltabelle wird nach dem Sortieren mit einem einzigen verwendet cost Die Spalte sieht wie folgt aus.
| #Ich würde | kosten | verfügbar | Nachfrage |
| Region Nr. 1, mit Kosten <= 3 | |||
| Region Nr. 2, mit Kosten > 3 | |||
| #Ich würde | kosten | verfügbar | Nachfrage |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Durch die Verwendung dieser herkömmlichen Sortierung können wir die beiden obersten (blauen) Zeilen mit ID 4 und ID 2 sofort ausschließen, da sie die Anforderungen nicht erfüllen cost > 3.
Andererseits wird die Tabelle mit einem mehrdimensionalen Datenlayout-Sortierschlüssel basierend auf einer Kombination der beiden häufig vorkommenden Prädikate in der Arbeitslast des Benutzers sortiert: cost > 3 und available < demand. Dadurch werden die Zeilen der Tabelle in vier Bereiche sortiert.
| #Ich würde | kosten | verfügbar | Nachfrage |
| Region Nr. 1, mit Kosten <= 3 und Verfügbarkeit < Nachfrage | |||
| Region Nr. 2, mit Kosten <= 3 und Verfügbarkeit >= Nachfrage | |||
| Region Nr. 3, mit Kosten > 3 und Verfügbarkeit < Nachfrage | |||
| Region Nr. 4, mit Kosten > 3 und Verfügbarkeit >= Nachfrage | |||
| #Ich würde | kosten | verfügbar | Nachfrage |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Dieses Konzept ist noch leistungsfähiger, wenn es auf ganze Blöcke statt auf einzelne Zeilen angewendet wird, wenn es auf komplexe Prädikate angewendet wird, die Operatoren verwenden, die für herkömmliche Sortiertechniken nicht geeignet sind (z. B like) und wenn es auf mehr als zwei Prädikate angewendet wird.
Systemtabellen
Die folgenden Amazon-Redshift-Systemtabellen zeigen Benutzern, ob in ihren Tabellen und Abfragen mehrdimensionale Datenlayouts verwendet werden:
- Um festzustellen, ob eine bestimmte Tabelle einen mehrdimensionalen Datenlayout-Sortierschlüssel verwendet, können Sie prüfen, ob dies der Fall ist
sortkey1in svv_table_info entsprichtAUTO(SORTKEY(padb_internal_mddl_key_col)). - Um festzustellen, ob eine bestimmte Abfrage ein mehrdimensionales Datenlayout verwendet, um Tabellenscans zu beschleunigen, können Sie dies überprüfen
step_attributeder sys_query_detail Sicht. Der Wert wird gleich seinmulti-dimensionalwenn der mehrdimensionale Datenlayout-Sortierschlüssel der Tabelle während des Scans verwendet wurde.
Leistungsbenchmarks
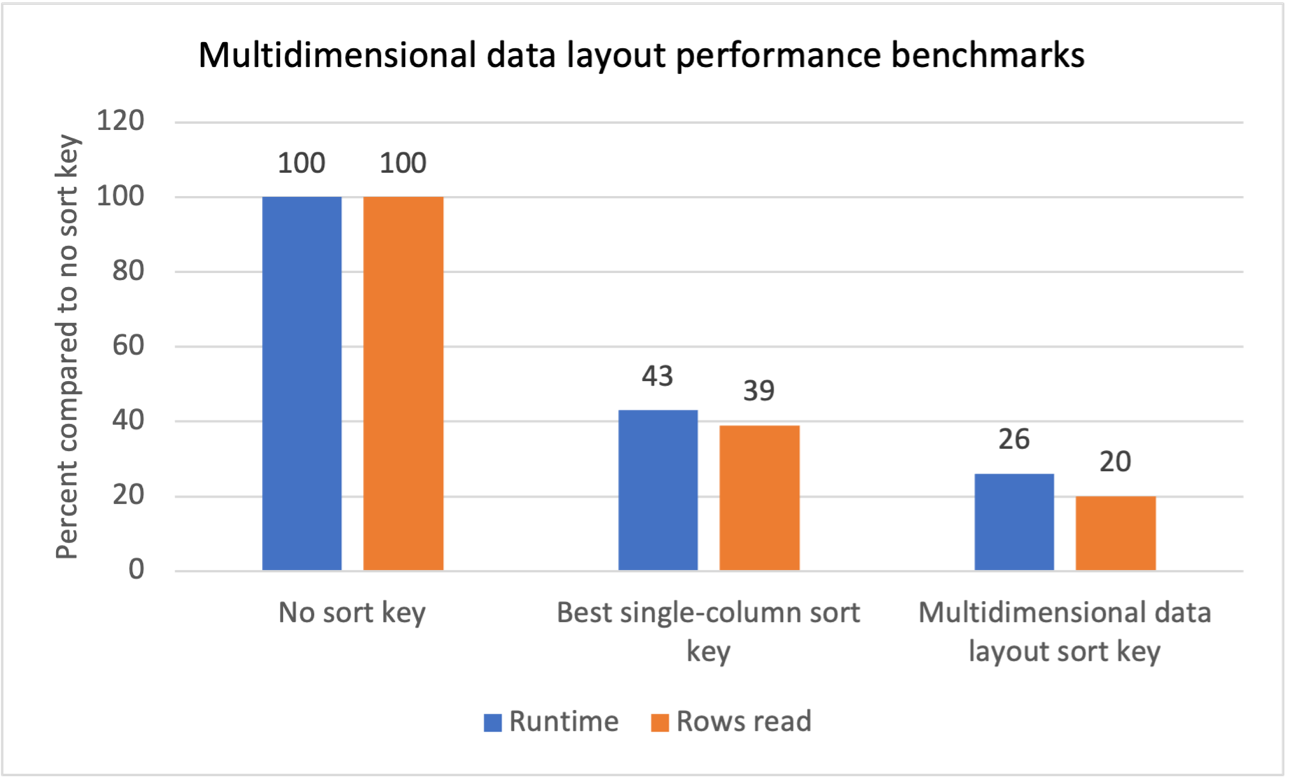
Wir haben interne Benchmark-Tests für mehrere Workloads mit sich wiederholenden Scanfiltern durchgeführt und festgestellt, dass die Einführung mehrdimensionaler Datenlayout-Sortierschlüssel zu den folgenden Ergebnissen führte:
- Eine Gesamtlaufzeitverkürzung von 74 % im Vergleich zum Fehlen eines Sortierschlüssels.
- Eine Reduzierung der Gesamtlaufzeit um 40 % im Vergleich zur Verwendung des besten Sortierschlüssels für eine Spalte in jeder Tabelle.
- Eine Reduzierung der Gesamtzahl der aus Tabellen gelesenen Zeilen um 80 % im Vergleich zum Fehlen eines Sortierschlüssels.
- Eine Reduzierung der Gesamtzahl der aus Tabellen gelesenen Zeilen um 47 % im Vergleich zur Verwendung des besten Einzelspalten-Sortierschlüssels für jede Tabelle.
Funktionsvergleich
Mit der Einführung mehrdimensionaler Datenlayout-Sortierschlüssel können Ihre Tabellen jetzt nach Ausdrücken sortiert werden, die auf den häufig vorkommenden Filterprädikaten in Ihrer Arbeitslast basieren. Die folgende Tabelle bietet einen Funktionsvergleich von Amazon Redshift mit zwei Mitbewerbern.
| Merkmal | Amazon RedShift | Wettbewerber A | Wettbewerber B |
| Unterstützung für die Sortierung nach Spalten | Ja | Ja | Ja |
| Unterstützung für die Sortierung nach Ausdruck | Ja | Ja | Nein |
| Automatische Spaltenauswahl zum Sortieren | Ja | Nein | Ja |
| Automatische Auswahl von Ausdrücken zum Sortieren | Ja | Nein | Nein |
| Automatische Auswahl zwischen Spaltensortierung oder Ausdruckssortierung | Ja | Nein | Nein |
| Automatische Verwendung von Sortiereigenschaften für Ausdrücke während Scans | Ja | Nein | Nein |
Überlegungen
Beachten Sie Folgendes, wenn Sie ein mehrdimensionales Datenlayout verwenden:
- Das mehrdimensionale Datenlayout ist aktiviert, wenn Sie Ihre Tabelle auf SORTKEY AUTO festlegen.
- Amazon Redshift Advisor wählt automatisch entweder einen einspaltigen Sortierschlüssel oder ein mehrdimensionales Datenlayout für die Tabelle aus, indem er Ihre historische Arbeitslast analysiert.
- Amazon Redshift ATO passt die Sortierergebnisse des mehrdimensionalen Datenlayouts basierend auf der Art und Weise an, in der laufende Abfragen mit der Arbeitslast interagieren.
- Amazon Redshift ATO verwaltet Sortierschlüssel für mehrdimensionale Datenlayouts auf die gleiche Weise wie derzeit für vorhandene Sortierschlüssel. Beziehen auf Arbeiten mit automatischer Tabellenoptimierung Weitere Informationen zu ATO.
- Sortierschlüssel für mehrdimensionale Datenlayouts funktionieren sowohl mit bereitgestellten Clustern als auch mit serverlosen Arbeitsgruppen.
- Sortierschlüssel für mehrdimensionale Datenlayouts funktionieren mit Ihren vorhandenen Daten, solange der AUTO SORTKEY für Ihre Tabelle aktiviert ist und eine Arbeitslast mit sich wiederholenden Scanfiltern erkannt wird. Die Tabelle wird basierend auf den Ergebnissen der mehrdimensionalen Sortierfunktion neu organisiert.
- Um mehrdimensionale Datenlayout-Sortierschlüssel für eine Tabelle zu deaktivieren, verwenden Sie alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Dadurch wird die AUTO-Sortierschlüsselfunktion für die Tabelle deaktiviert. - Sortierschlüssel für mehrdimensionale Datenlayouts bleiben erhalten, wenn Sie Ihren bereitgestellten Cluster wiederherstellen oder zu einem serverlosen Cluster migrieren oder umgekehrt.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, dass mehrdimensionale Datenlayout-Sortierschlüssel die Laufzeitleistung von Abfragen für Arbeitslasten erheblich verbessern können, bei denen dominante Abfragen über sich wiederholende Scanfilter verfügen.
Um einen Vorschau-Cluster über die Amazon-Redshift-Konsole zu erstellen, navigieren Sie zu Cluster Seite und wählen Vorschaucluster erstellen. Sie können einen Cluster in den Regionen USA Ost (Ohio), USA Ost (Nord-Virginia), USA West (Oregon), Asien-Pazifik (Tokio), Europa (Irland) und Europa (Stockholm) erstellen und Ihre Arbeitslasten testen.
Wir würden uns über Ihr Feedback zu dieser neuen Funktion freuen und freuen uns auf Ihre Kommentare zu diesem Beitrag.
Über die Autoren
 Milin Oke ist ein Data Warehouse Specialist Solutions Architect mit Sitz in New York. Er baut seit über 15 Jahren Data-Warehouse-Lösungen und ist auf Amazon Redshift spezialisiert.
Milin Oke ist ein Data Warehouse Specialist Solutions Architect mit Sitz in New York. Er baut seit über 15 Jahren Data-Warehouse-Lösungen und ist auf Amazon Redshift spezialisiert.
 Jialin Ding ist ein angewandter Wissenschaftler in der Learned Systems Group, der sich auf die Anwendung maschineller Lern- und Optimierungstechniken zur Verbesserung der Leistung von Datensystemen wie Amazon Redshift spezialisiert hat.
Jialin Ding ist ein angewandter Wissenschaftler in der Learned Systems Group, der sich auf die Anwendung maschineller Lern- und Optimierungstechniken zur Verbesserung der Leistung von Datensystemen wie Amazon Redshift spezialisiert hat.
 Yanzhu Ji ist Produktmanager im Amazon Redshift-Team. Sie hat Erfahrung in Produktvision und -strategie in branchenführenden Datenprodukten und -plattformen. Sie verfügt über hervorragende Fähigkeiten in der Erstellung umfangreicher Softwareprodukte unter Verwendung von Webentwicklung, Systemdesign, Datenbanken und verteilten Programmiertechniken. In ihrem Privatleben malt, fotografiert und spielt Yanzhu gerne Tennis.
Yanzhu Ji ist Produktmanager im Amazon Redshift-Team. Sie hat Erfahrung in Produktvision und -strategie in branchenführenden Datenprodukten und -plattformen. Sie verfügt über hervorragende Fähigkeiten in der Erstellung umfangreicher Softwareprodukte unter Verwendung von Webentwicklung, Systemdesign, Datenbanken und verteilten Programmiertechniken. In ihrem Privatleben malt, fotografiert und spielt Yanzhu gerne Tennis.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :hast
- :Ist
- :nicht
- :Wo
- 1
- 100
- 15 Jahre
- 15%
- 152
- 7
- 8
- 9
- a
- beschleunigen
- Zugriff
- Zusätzliche
- Berater
- Nach der
- gegen
- Algorithmus
- Alle
- bereits
- Amazon
- Amazon Web Services
- an
- analysieren
- Analyse
- und
- Ein anderer
- angewandt
- Anwendung
- SIND
- AS
- Asien
- Asien-Pazifik-
- Auto
- automatische
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- basierend
- BE
- weil
- war
- Benchmark
- Nutzen
- BESTE
- Besser
- zwischen
- Blockieren
- Blockiert
- Blau
- beide
- Building
- aber
- by
- CAN
- capability
- aus der Ferne überprüfen
- Auswählen
- Cloud
- Cluster
- Kolonne
- Spalten
- Kombination
- Bemerkungen
- häufig
- verglichen
- Vergleich
- Konkurrenz
- Komplex
- konzept
- Geht davon
- besteht
- Konsul (Console)
- konstruieren
- enthält
- Kosten
- deckt
- erstellen
- Zur Zeit
- technische Daten
- Data Warehouse
- Datenbase
- entscheidet
- gewidmet
- definieren
- Demand
- anspruchsvoll
- Design
- Details
- erkannt
- Bestimmen
- Entwicklung
- verteilt
- Verteilung
- die
- dominant
- Nicht
- im
- jeder
- Osten
- entweder
- freigegeben
- Ganz
- gleich
- insbesondere
- Äther (ETH)
- Europa
- Auswertung
- Sogar
- entwickelt
- Beispiel
- vorhandenen
- ERFAHRUNGEN
- Ausdrücke
- Merkmal
- Feedback
- Filter
- Filter
- Folgende
- folgt
- Aussichten für
- vorwärts
- vier
- für
- Funktion
- Gruppe an
- Pflege
- Haben
- mit
- he
- hören
- hier (auf dänisch)
- historisch
- Geschichte
- aber
- HTML
- HTTPS
- ID
- if
- sofort
- zu unterstützen,
- verbessert
- in
- Dazu gehören
- Krankengymnastik
- branchenführend
- beantragen müssen
- interagieren
- intern
- Intervention
- in
- einführen
- Einführung
- Einleitung
- Irland
- IT
- Artikel
- Wesentliche
- Tasten
- grosse
- Layout
- gelernt
- lernen
- Lebensdauer
- Gefällt mir
- Gleichen
- Lang
- aussehen
- aussehen wie
- ich liebe
- Maschine
- Maschinelles Lernen
- unterhält
- Manager
- Weise
- maximal
- Triff
- Metadaten
- könnte
- Migration
- Geist / Bewusstsein
- Minimum
- mehr
- vor allem warme
- mehrere
- Navigieren
- Need
- Neu
- neue Funktion
- New York
- nicht
- jetzt an
- Zahlen
- vorkommend
- of
- WOW!
- angeboten
- Ohio
- on
- EINEM
- laufend
- einzige
- Betreiber
- Optimierung
- Verbessert
- Option
- or
- Auftrag
- Oregon
- Original
- Andere
- hervorragend
- übrig
- Pazifik
- Malerei
- Teil
- besondere
- Schnittmuster
- Leistung
- durchgeführt
- persönliche
- Fotografie
- physikalisch
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Post
- größte treibende
- konserviert
- Vorspann
- Produziert
- Produkt
- Produkt-Manager
- Produkte
- Programmierung
- immobilien
- bietet
- Abfragen
- schnell
- Lesen Sie mehr
- Reduktion
- siehe
- Region
- Regionen
- repetitiv
- Voraussetzungen:
- Wiederherstellen
- Folge
- Die Ergebnisse
- Führen Sie
- Laufen
- läuft
- gleich
- Scan
- Scannen
- scannt
- Wissenschaftler
- Jahreszeit
- sehen
- wählen
- ausgewählt
- Auswahl
- Serverlos
- Lösungen
- kompensieren
- sie
- erklären
- Vitrine
- zeigte
- gezeigt
- Konzerte
- bedeutend
- Single
- Geschicklichkeit
- So
- Software
- Lösungen
- Spezialist
- spezialisiert
- spezialisieren
- Läden
- Strategie
- Anschließend
- wesentlich
- so
- geeignet
- Unterstützung
- System
- Systeme und Techniken
- Tabelle
- Nehmen
- Team
- Techniken
- Tennis
- Test
- Testen
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- deswegen
- vom Nutzer definierten
- fehlen uns die Worte.
- Zeit
- Titel
- zu
- Tokio
- Top
- Gesamt
- traditionell
- XNUMX
- tippe
- typisch
- us
- -
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- Wert
- Werte
- Schraubstock
- Anzeigen
- Virginia
- Seh-
- Warehouse
- wurde
- Weg..
- we
- Netz
- Web-Entwicklung
- Web-Services
- West
- wann
- ob
- welche
- weit
- werden wir
- mit
- ohne
- Arbeiten
- würde
- Jahr
- York
- U
- Ihr
- Zephyrnet