Einleitung
Der Zusammenschluss von künstliche Intelligenz (KI) und Kunst eröffnen neue Wege in der kreativen digitalen Kunst, vor allem durch Diffusionsmodelle. Diese Modelle stechen in der kreativen KI-Kunstgeneration hervor und bieten einen anderen Ansatz als herkömmliche neuronale Netze. Dieser Artikel nimmt Sie mit auf eine Entdeckungsreise in die Tiefen der Diffusionsmodelle und erläutert ihren einzigartigen Mechanismus bei der Herstellung visuell beeindruckender und kreativ reichhaltiger Kunstwerke. Verstehen Sie die Nuancen von Diffusionsmodellen und gewinnen Sie Einblick in ihre Rolle bei der Neudefinition des künstlerischen Ausdrucks durch die Linse fortschrittlicher KI-Technologien.

Lernziele
- Verstehen Sie die grundlegenden Konzepte von Diffusionsmodellen in der KI.
- Entdecken Sie den Unterschied zwischen Diffusionsmodellen und traditionellen neuronalen Netzen in der Kunstgenerierung.
- Analysieren Sie den Prozess der Kunstschaffung mithilfe von Diffusionsmodellen.
- Bewerten Sie die kreativen und ästhetischen Auswirkungen von KI auf die digitale Kunst.
- Besprechen Sie die ethischen Überlegungen bei KI-generierten Kunstwerken.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Diffusionsmodelle verstehen

Diffusionsmodelle revolutionieren die generative KI und stellen eine einzigartige Methode zur Bilderzeugung dar, die sich von herkömmlichen Techniken wie Generative Adversarial Networks (GANs) unterscheidet. Diese Modelle beginnen mit zufälligem Rauschen und verfeinern es schrittweise. Sie ähneln einem Künstler, der ein Gemälde verfeinert, was zu komplexen und kohärenten Bildern führt.
Dieser schrittweise Verfeinerungsprozess spiegelt die methodische Natur der Verbreitung wider. Hier verändert jede Iteration das Rauschen auf subtile Weise und bringt es näher an die endgültige künstlerische Vision heran. Das Ergebnis ist nicht nur ein Produkt des Zufalls, sondern ein weiterentwickeltes Kunstwerk, das sich in seinem Verlauf und Ende deutlich unterscheidet.
Das Codieren für Diffusionsmodelle erfordert ein fundiertes Verständnis neuronaler Netze und Frameworks für maschinelles Lernen wie TensorFlow oder PyTorch. Der resultierende Code ist komplex und erfordert umfangreiches Training an umfangreichen Datensätzen, um die nuancierten Effekte zu erzielen, die in KI-generierter Kunst beobachtet werden.
Anwendung der stabilen Diffusion in Art
Das Aufkommen von KI-Kunstgeneratoren wie stabilen Diffusionsmodellen erfordert eine ausgefeilte Codierung innerhalb von Plattformen wie TensorFlow oder PyTorch. Diese Modelle zeichnen sich durch ihre Fähigkeit aus, Zufälligkeit methodisch in Struktur umzuwandeln, ähnlich wie ein Künstler, der eine vorläufige Skizze zu einem lebendigen Meisterwerk verfeinert.
Stabile Diffusionsmodelle gestalten die KI-Kunstszene neu, indem sie aus dem Zufall geordnete Bilder formen und dabei die für GANs charakteristische Wettbewerbsdynamik meiden. Sie zeichnen sich dadurch aus, dass sie konzeptionelle Anregungen in visuelle Kunst umsetzen und einen synergetischen Tanz zwischen KI-Fähigkeiten und menschlichem Einfallsreichtum fördern. Indem wir PyTorch nutzen, beobachten wir, wie diese Modelle das Chaos iterativ in Klarheit verfeinern und so den Weg des Künstlers von einer entstehenden Idee zu einer ausgefeilten Kreation widerspiegeln.
Experimentieren mit KI-generierter Kunst
Diese Demonstration taucht in die faszinierende Welt der KI-generierten Kunst mithilfe eines Faltungs-Neuronalen Netzwerks namens ein ConvDiffusionModel. Dieses Modell ist an verschiedenen Kunstbildern geschult, darunter Zeichnungen, Gemälde, Skulpturen und Gravuren, je nach Quelle Dieser Kaggle-Datensatz. Unser Ziel ist es, die Fähigkeit des Modells zu untersuchen, die komplexe Ästhetik dieser Kunstwerke einzufangen und zu reproduzieren.
Modellarchitektur und Training
Architekturdesign
Das ConvDiffusionModel ist im Kern ein Wunderwerk der Neurotechnik und verfügt über eine hochentwickelte Encoder-Decoder-Architektur, die auf die Anforderungen der Kunstgenerierung zugeschnitten ist. Die Struktur des Modells ist ein komplexes neuronales Netzwerk, das raffinierte Encoder-Decoder-Mechanismen integriert, die speziell für die Kunsterzeugung entwickelt wurden. Mit zusätzlichen Faltungsebenen und Sprungverbindungen, die künstlerische Intuition nachahmen, kann das Modell Kunst mit einem scharfsinnigen Verständnis für Komposition und Stil zerlegen und neu zusammensetzen.
- Encoder: Der Encoder ist das analytische Auge des Modells und prüft die kleinsten Details jedes Eingabebilds. Während Bilder die Faltungsschichten des Encoders durchlaufen, werden sie zunehmend in einen latenten Raum komprimiert – eine kompakte, codierte Darstellung des Originalkunstwerks. Unser Encoder prüft nicht nur Eingabebilder, sondern tut dies dank zusätzlicher Ebenen und Batch-Normalisierungstechniken jetzt auch mit einer größeren Wahrnehmungstiefe. Diese erweiterte Untersuchung ermöglicht eine reichhaltigere, komprimierte Darstellung innerhalb des latenten Raums und spiegelt die tiefe Betrachtung eines Künstlers über ein Thema wider.
- Decoder: Im Gegensatz dazu fungiert der Decoder als kreative Hand des Modells, indem er die abstrakten Skizzen vom Encoder aufnimmt und ihnen Leben einhaucht. Es rekonstruiert das Kunstwerk aus dem latenten Raum, Schicht für Schicht, Detail für Detail, bis ein vollständiges Bild entsteht. Unser Decoder profitiert von Skip-Verbindungen und kann Kunstwerke mit größerer Präzision rekonstruieren. Es greift die abstrahierte Essenz der Eingabe auf und verschönert sie nach und nach, um eine Wiedergabe zu erzielen, die dem Ausgangsmaterial treuer ist. Die verbesserten Ebenen arbeiten zusammen, um sicherzustellen, dass das endgültige Bild ein lebendiges, komplexes Stück ist, das die Kunstfertigkeit der Eingabe widerspiegelt.
Trainingsprozess
Das Training des ConvDiffusionModel ist eine Reise durch eine künstlerische Landschaft aus 150 Epochen. Jede Epoche stellt einen vollständigen Durchgang durch den gesamten Datensatz dar, wobei das Modell bestrebt ist, sein Verständnis zu verfeinern und die Genauigkeit der generierten Bilder zu verbessern.
- Hybride Verlustfunktion: Im Mittelpunkt des Trainings steht die Verlustfunktion des mittleren quadratischen Fehlers (MSE). Diese Funktion quantifiziert den Unterschied zwischen dem ursprünglichen Meisterwerk und der Nachbildung des Modells und liefert so eine klare Metrik zur Minimierung. Wir werden eine Wahrnehmungsverlustkomponente einführen, die aus einem vorab trainierten VGG-Netzwerk abgeleitet ist und die Metrik des mittleren quadratischen Fehlers (MSE) ergänzt. Diese Dual-Loss-Strategie bringt das Modell dazu, die künstlerische Integrität der Originale zu würdigen und gleichzeitig die technische Wiedergabe ihrer Details zu perfektionieren.
- Optimierer: Da die Lernrate von einem Planer dynamisch angepasst wird, steuert der Adam-Optimierer das Lernen des Modells mit erhöhter Scharfsinnigkeit. Dieser adaptive Ansatz stellt sicher, dass der Fortschritt des Modells beim Lernen, Kunst zu reproduzieren und zu erneuern, sowohl stetig als auch robust ist.
- Iteration und Verfeinerung: Die Trainingsiterationen sind ein Tanz zwischen der Bewahrung künstlerischer Essenz und dem Streben nach technischer Replikation. Mit jedem Zyklus nähert sich das Modell einer Synthese aus Treue und Kreativität.
- Visualisierung des Fortschritts: Während des Trainings werden in regelmäßigen Abständen Bilder gespeichert, um den Fortschritt des Modells zu visualisieren. Diese Schnappschüsse bieten einen Einblick in die Lernkurve des Modells und zeigen, wie sich die erzeugte Kunst weiterentwickelt und mit jeder Epoche klarer, detaillierter und künstlerisch kohärenter wird.



Das Obige wird anhand des folgenden Codeabschnitts demonstriert:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Visualisierung des generierten Kunstwerks
KI-gefertigte Kunstfertigkeit manifestieren
Da das ConvDiffusionModel nun vollständig trainiert ist, verlagert sich der Fokus vom Abstrakten zum Konkreten – vom Potenzial zur Verwirklichung KI-gefertigter Kunst. Das anschließende Code-Snippet materialisiert die erlernten künstlerischen Fähigkeiten des Modells und wandelt Eingabedaten in eine digitale Ausdrucksfläche um.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()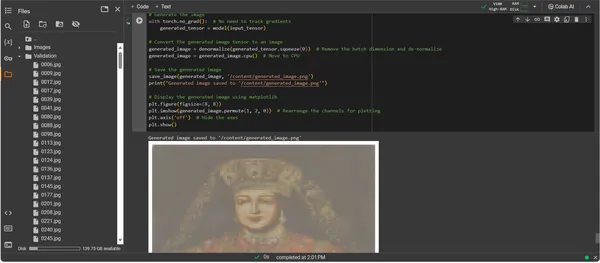

Exemplarische Vorgehensweise zum Generierungscode für Kunstwerke
- Modellauferstehung: Der erste Schritt bei der Generierung von Grafiken besteht darin, unser trainiertes ConvDiffusionModel wiederzubeleben. Die erlernten Gewichte des Modells werden geladen und in den Bewertungsmodus gebracht, wodurch die Voraussetzungen für die Erstellung geschaffen werden, ohne dass die Parameter weiter geändert werden müssen.
- Bildtransformation: Um die Konsistenz mit dem Trainingsprogramm sicherzustellen, werden Eingabebilder durch dieselbe Transformationssequenz verarbeitet. Dazu gehören die Größenanpassung an die Eingabedimensionen des Modells, die Tensorkonvertierung für PyTorch-Kompatibilität und die Normalisierung basierend auf dem statistischen Profil der Trainingsdaten.
- Denormalisierungsdienstprogramm: Eine benutzerdefinierte Funktion kehrt die Vorverarbeitungseffekte um und skaliert den Tensor neu auf den Farbbereich des Originalbilds. Dieser Schritt ist wichtig, um die generierte Ausgabe in eine visuell korrekte Darstellung umzuwandeln.
- Eingabevorbereitung: Ein Bild wird geladen und den oben genannten Transformationen unterzogen. Es ist wichtig zu beachten, dass dieses Bild als Muse dient, von der sich die KI inspirieren lässt – das stille Flüstern regt die synthetische Vorstellungskraft des Modells an.
- Kunstwerk-Synthese: In einem zarten Tanz der Vorwärtsausbreitung interpretiert das Modell den Eingabetensor und ermöglicht so die Zusammenarbeit seiner Schichten bei der Entwicklung einer neuen künstlerischen Vision. Führen Sie diesen Vorgang aus, ohne Farbverläufe zu verfolgen, da wir uns jetzt im Bereich der Anwendung und nicht im Bereich des Trainings befinden.
- Bildkonvertierung: Die Tensorausgabe des Modells, das nun das digital entstandene Kunstwerk enthält, wird denormalisiert, wodurch die Modellerstellung zurück in den vertrauten Farb- und Lichtraum übersetzt wird, den unsere Augen wahrnehmen können.
- Offenbarung des Kunstwerks: Der transformierte Tensor wird auf einer digitalen Leinwand ausgelegt und gipfelt in einer gespeicherten Bilddatei. Diese Datei ist ein Fenster in die kreative Seele der KI, ein statisches Echo des dynamischen Prozesses, der sie zum Leben erweckte.
- Abruf von Kunstwerken: Das Skript schließt mit dem Speichern des generierten Bildes in einem angegebenen Pfad und der Ankündigung seiner Fertigstellung ab. Das gespeicherte Bild, eine Synthese erlernter künstlerischer Prinzipien und entstehender Kreativität, steht zur Ausstellung und Betrachtung bereit.
Analyse der Ausgabe
Die Ausgabe des ConvDiffusionModel präsentiert eine Figur mit einer klaren Anspielung auf historische Kunst. Das in aufwändige Gewänder gehüllte, von der KI gerenderte Bild erinnert an die Erhabenheit klassischer Porträts, weist jedoch einen deutlichen, modernen Touch auf. Die Kleidung des Probanden ist reich an Texturen und verbindet die erlernten Muster des Modells mit einer neuartigen Interpretation. Zarte Gesichtszüge und ein subtiles Zusammenspiel von Licht und Schatten zeigen das differenzierte Verständnis der KI für traditionelle Kunsttechniken. Dieses Kunstwerk ist ein Beweis für die anspruchsvolle Ausbildung des Modells und spiegelt eine elegante Synthese historischer Kunstfertigkeit durch das Prisma fortschrittlichen maschinellen Lernens wider. Im Wesentlichen handelt es sich um eine digitale Hommage an die Vergangenheit, erstellt mit den Algorithmen der Gegenwart.
Herausforderungen und ethische Überlegungen
Die Implementierung von Diffusionsmodellen für die Kunstgenerierung bringt mehrere Herausforderungen und ethische Überlegungen mit sich, die Sie berücksichtigen sollten:
- Datenherkunft: Die Trainingsdatensätze müssen verantwortungsvoll kuratiert werden. Es ist wichtig zu überprüfen, dass die zum Training von Diffusionsmodellen verwendeten Daten keine urheberrechtlich geschützten oder geschützten Werke ohne entsprechende Genehmigung enthalten.
- Voreingenommenheit und Repräsentation: KI-Modelle können Verzerrungen in ihren Trainingsdaten aufrechterhalten. Die Sicherstellung vielfältiger und integrativer Datensätze ist wichtig, um eine Verstärkung von Stereotypen in der KI-generierten Kunst zu vermeiden.
- Kontrolle über die Ausgabe: Da Verbreitungsmodelle ein breites Spektrum an Ergebnissen generieren können, ist es notwendig, Grenzen zu setzen, um die Erstellung unangemessener oder anstößiger Inhalte zu verhindern.
- Rechtliche Rahmenbedingungen: Das Fehlen eines robusten Rechtsrahmens, um die Nuancen der KI im kreativen Prozess zu berücksichtigen, stellt eine Herausforderung dar. Die Gesetzgebung muss weiterentwickelt werden, um die Rechte aller Beteiligten zu schützen.
Zusammenfassung
Der Aufstieg von Diffusionsmodellen in KI und Kunst markiert eine transformative Ära, in der rechnerische Präzision mit ästhetischer Erforschung verschmilzt. Ihre Reise in die Kunstwelt zeigt ein erhebliches Innovationspotenzial auf, ist jedoch auch mit Komplexitäten verbunden. Die Balance zwischen Originalität, Einfluss, ethischem Schaffen und Respekt für bestehende Werke ist ein wesentlicher Bestandteil des künstlerischen Prozesses.
Key Take Away
- Diffusionsmodelle stehen an der Spitze eines transformativen Wandels im Kunstschaffen. Sie bieten neue digitale Werkzeuge, die die Leinwand des künstlerischen Ausdrucks über traditionelle Grenzen hinaus erweitern.
- In der KI-gestützten Kunst ist es unerlässlich, der ethischen Erfassung von Trainingsdaten Priorität einzuräumen und das geistige Eigentum der Urheber zu respektieren, um die Integrität der digitalen Kunst zu wahren.
- Die Konvergenz von künstlerischer Vision und technologischer Innovation öffnet Türen zu einer symbiotischen Beziehung zwischen Künstlern und KI-Entwicklern. Fördern Sie ein kollaboratives Umfeld, das bahnbrechende Kunst hervorbringen kann.
- Es ist von entscheidender Bedeutung, sicherzustellen, dass KI-generierte Kunst ein breites Spektrum an Perspektiven repräsentiert. Integrieren Sie vielfältige Daten, die den Reichtum verschiedener Kulturen und Standpunkte widerspiegeln, und fördern Sie so die Inklusivität.
- Das wachsende Interesse an KI-Kunst erfordert die Schaffung robuster rechtlicher Rahmenbedingungen. Diese Rahmenwerke sollen Urheberrechtsfragen klären, Beiträge anerkennen und die kommerzielle Nutzung von KI-generierten Kunstwerken regeln.
Der Beginn dieser künstlerischen Entwicklung bietet einen Weg voller kreativem Potenzial, der jedoch achtsame Bewahrung erfordert. Es ist unsere Aufgabe, eine Landschaft zu schaffen, in der die Verschmelzung von KI und Kunst gedeiht, geleitet von verantwortungsvollen und kulturell sensiblen Praktiken.
Häufig gestellte Fragen
A. Diffusionsmodelle sind generative ML-Algorithmen, die Bilder erstellen, indem sie mit einem Muster aus zufälligem Rauschen beginnen und es schrittweise zu einem kohärenten Bild formen. Dieser Prozess ähnelt dem eines Künstlers, der mit einer leeren Leinwand beginnt und nach und nach Detailebenen hinzufügt.
A. GANs und Diffusionsmodelle erfordern kein separates Netzwerk zur Beurteilung der Ausgabe. Sie funktionieren durch das iterative Hinzufügen und Entfernen von Rauschen, was oft zu detaillierteren und nuancierteren Bildern führt.
A. Ja, Diffusionsmodelle können Originalkunstwerke erzeugen, indem sie aus einem Bilddatensatz lernen. Allerdings wird die Originalität durch die Vielfalt und den Umfang der Trainingsdaten beeinflusst. Es gibt eine anhaltende Debatte über die Ethik der Verwendung vorhandener Kunstwerke zum Trainieren dieser Modelle.
A. Zu den ethischen Bedenken gehört die Vermeidung von Urheberrechtsverletzungen durch KI-generierte Kunst. Die Originalität menschlicher Künstler respektieren, die Aufrechterhaltung von Vorurteilen verhindern und Transparenz im kreativen Prozess der KI gewährleisten.
A. Die Zukunft der KI-generierten Kunst sieht vielversprechend aus, da Diffusionsmodelle neue Werkzeuge für Künstler und Schöpfer bieten. Mit fortschreitender Technologie können wir davon ausgehen, dass wir anspruchsvollere und komplexere Kunstwerke sehen werden. Die kreative Gemeinschaft muss jedoch ethische Überlegungen berücksichtigen und auf klare Richtlinien und Best Practices hinarbeiten.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :Ist
- :nicht
- :Wo
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- Fähigkeit
- Über Uns
- oben
- ABSTRACT
- genau
- Erreichen
- Erreichen
- Marcus
- adaptiv
- Hinzufügen
- Zusätzliche
- Adresse
- Bereinigt
- advanced
- Vorschüsse
- Advent
- widersprüchlich
- AI
- Kunst
- verwandt
- Algorithmen
- Alle
- Zulassen
- erlaubt
- an
- Analytische
- Analytik
- Analytics-Vidhya
- und
- Ankündigung
- Anwendung
- schätzen
- Ansatz
- Architektur
- SIND
- Kunst
- Artikel
- Künstler
- künstlerisch
- künstlerisch
- Kunst
- Künstler
- Kunstwerk
- Kunstwerke
- AS
- At
- Augmented
- Genehmigung
- verfügbar
- Alleen
- vermeiden
- Vermeidung von
- ACHSEN
- Zurück
- Badewanne
- Balancing
- basierend
- BE
- Werden
- Vorteile
- BESTE
- Best Practices
- zwischen
- Beyond
- vorspannen
- Vorurteile
- leer
- Vermischung
- Blogathon
- geboren
- beide
- Grenzen
- Atmen
- überfüllt
- Brings
- breit
- gebracht
- aufkeimenden
- aber
- by
- Berechnen
- namens
- CAN
- Leinwand
- Fähigkeiten
- capability
- Erfassung
- challenges
- Herausforderungen
- Kanäle
- Chaos
- Merkmal
- aus der Ferne überprüfen
- Überprüfung
- Klemme
- Clarity
- Klasse
- klar
- klarer
- näher
- Code
- Programmierung
- KOHÄRENT
- zusammenarbeiten
- kollaborative
- Farbe
- kommt
- kommerziell
- community
- kompakt
- Kompatibilität
- wettbewerbsfähig
- abschließen
- Abschluss
- Komplex
- Komplexität
- Komponente
- Zusammensetzung
- rechnerisch
- Berechnen
- Konzepte
- begrifflich
- Bedenken
- Konzert
- schließt ab
- Verbindungen
- Geht davon
- Überlegungen
- enthalten
- Inhalt
- Kontrast
- Beiträge
- konventionellen
- Konvergenz
- Umwandlung (Conversion)
- Umwandlung
- Faltungs neuronales Netzwerk
- Urheberrecht
- Urheberrechtsverletzung
- Kernbereich
- korrupt
- CPU
- Gefertigt
- erstellen
- Erstellen
- Schaffung
- Kreativ (Creative)
- Kreativ
- Kreativität
- Schöpfer
- wichtig
- kulminierend
- Pflegen
- kulturell
- kuratiert
- Kurve
- Original
- Zyklus
- tanzen
- technische Daten
- Datensätze
- Debatten.
- tief
- Definition
- Anforderungen
- Synergie
- Tiefe
- Tiefe
- Abgeleitet
- bezeichnet
- Detail
- detailliert
- Details
- Entwickler
- Gerät
- abweichen
- Unterschied
- anders
- Rundfunk
- digital
- digitale Kunst
- digital
- Abmessungen
- Größe
- Diskretion
- Display
- Anzeige
- deutlich
- Unterscheidung
- verschieden
- Diversität
- do
- die
- Türen
- zeichnen
- Zeichnungen
- im
- dynamisch
- dynamisch
- Dynamik
- e
- jeder
- Echo
- Echos
- Effekten
- Erarbeiten
- sonst
- taucht auf
- codiert
- umfassen
- umfassend
- Entwicklung
- verbesserte
- gewährleisten
- sorgt
- Gewährleistung
- Ganz
- Arbeitsumfeld
- Epoche
- Epochen
- Era
- Fehler
- Essenz
- essential
- Gründung
- Äther (ETH)
- ethisch
- Ethik
- Auswertung
- Jedes
- Evolution
- entwickelt sich
- entwickelt
- entwickelt sich
- Untersuchung
- Excel
- Außer
- vorhandenen
- Erweitern Sie die Funktionalität der
- expansiv
- erwarten
- Exploration
- ERKUNDEN
- Ausdruck
- verlängert
- umfangreiche
- Auge
- Augenfarbe
- Gesichts-
- treu
- falsch
- vertraut
- faszinierend
- Eigenschaften
- Einzigartige
- Treue
- Abbildung
- Reichen Sie das
- Mappen
- Finale
- Fertig
- Vorname
- Setzen Sie mit Achtsamkeit
- Folgende
- Aussichten für
- Vordergrund
- vorwärts
- Fördern
- Förderung
- Unser Ansatz
- Gerüste
- für
- voll
- Funktion
- funktional
- fundamental
- weiter
- Verschmelzung
- Zukunft
- Gewinnen
- GANs
- Sammlung
- gab
- erzeugen
- erzeugt
- Erzeugung
- Generation
- generativ
- generative kontradiktorische Netzwerke
- Generative KI
- Generatoren
- ABSICHT
- Kundenziele
- GPU
- Steigungen
- allmählich
- Größe
- Griff
- mehr
- bahnbrechend
- geführt
- Richtlinien
- Anleitungen
- Pflege
- Nutzen
- Herz
- hier
- Verbergen
- Highlights
- historisch
- Halten
- Huldigung
- Ehre
- Ultraschall
- aber
- HTTPS
- human
- i
- Idee
- if
- zündet
- Image
- Bilder
- Phantasie
- Imperativ
- Umsetzung
- Auswirkungen
- importieren
- wichtig
- zu unterstützen,
- in
- Dazu gehören
- Inklusive
- Inklusivität
- integrieren
- hat
- inkremental
- Amtsinhaber
- beeinflussen
- beeinflusst
- Verletzung
- Einfallsreichtum
- wir innovieren
- Innovation
- Varianten des Eingangssignals:
- Eingänge
- Einblick
- Integral
- Integration
- Integrität
- geistigen
- geistiges Eigentum
- Interesse
- Interpretation
- in
- kompliziert
- einführen
- Intuition
- beteiligt
- Probleme
- IT
- Iteration
- Iterationen
- SEINE
- Reise
- jpg
- Richter
- Mangel
- Landschaft
- Schicht
- Lagen
- gelernt
- lernen
- Rechtlich
- Rechtliche Rahmenbedingungen
- Gesetzgebung
- Lens
- liegt
- Lebensdauer
- !
- Gefällt mir
- Laden
- SIEHT AUS
- Verlust
- Verluste
- Maschine
- Maschinelles Lernen
- halten
- Wunder
- Meisterstück
- Spiel
- Ihres Materials
- Matplotlib
- bedeuten
- Mechanismus
- Mechanismen
- Medien
- nur
- Verschmelzung
- Methode
- methodisch
- Metrisch
- minimieren
- Minute
- Spiegelung
- ML
- ML-Algorithmen
- Model
- Modell
- für
- modern
- Modulen
- mehr
- schlauer bewegen
- viel
- MUSE
- sollen
- Namen
- im Entstehen begriffen
- Natur
- Navigieren
- notwendig,
- Bedürfnisse
- Netzwerk
- Netzwerke
- Neural
- Neurotechnik
- neuronale Netzwerk
- Neuronale Netze
- Neu
- Lärm
- beachten
- Roman
- jetzt an
- Abschattung
- beobachten
- beobachtet
- of
- WOW!
- Offensive
- bieten
- bieten
- Angebote
- vorgenommen,
- on
- laufend
- einzige
- öffnet
- Optimieren
- or
- Original
- Originalität
- Originale
- OS
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- übrig
- Besitz
- Malerei
- Gemälde
- Parameter
- Parameter
- Teil
- Parteien
- passieren
- passt
- Weg
- Schnittmuster
- Muster
- Wahrnehmung
- Perfektionierung
- ausführen
- Perspektiven
- ein Bild
- Stück
- Stücke
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Porträts
- Potenzial
- Praktiken
- Präzision
- vorläufig
- Gegenwart
- Geschenke
- Erhaltung
- verhindern
- Verhütung
- Grundsätze
- Priorisierung
- Prozessdefinierung
- verarbeitet
- Herstellung
- Produkt
- Profil
- tiefgreifende
- Fortschritt
- Progression
- zunehmend
- aussichtsreich
- Die Förderung der
- Eingabeaufforderungen
- Fortpflanzung
- ordnungsgemäße
- Resorts
- Risiken zu minimieren
- geschützt
- Herkunft
- Bereitstellung
- veröffentlicht
- verfolgt
- Pytorch
- quantifiziert
- zufällig
- Zufälligkeit
- Angebot
- Bewerten
- bereit
- Reich
- erkennen
- Neudefinition
- verfeinern
- raffiniert
- reflektieren
- spiegelt
- Regime
- regulär
- Beziehung
- Entfernen
- Rendering
- Replikation
- Darstellung
- representiert
- Reproduktion
- erfordern
- erfordert
- ähnlich
- umformen
- Umwelt und Kunden
- respektieren
- für ihren Verlust verantwortlich.
- verantwortungsbewusst
- was zu
- Rückkehr
- Offenbarung
- Revive
- revolutionieren
- RGB
- Reiches
- Rechte
- Rise
- robust
- Rollen
- gleich
- Gerettet
- Einsparung
- Szene
- Wissenschaft
- Umfang
- Skript
- sehen
- SELF
- empfindlich
- getrennte
- Reihenfolge
- dient
- kompensieren
- Einstellung
- Setup
- mehrere
- Shadow
- Gestaltung
- verschieben
- Schichten
- sollte
- Vitrine
- präsentiert
- gezeigt
- signifikant
- da
- Langsam
- Schnipsel
- So
- anspruchsvoll
- Seele
- Quelle
- bezogen
- Raumfahrt
- überspannend
- speziell
- Spektrum
- Kariert
- stabil
- Stufe
- Stand
- Beginnen Sie
- statistisch
- stetig
- Schritt
- Strategie
- Streben
- Struktur
- Atemberaubende
- Stil
- Fach
- Folge
- so
- Symbiotisch
- synergistisch
- Synthese
- synthetisch
- zugeschnitten
- nimmt
- Einnahme
- Target
- Technische
- Techniken
- technologische
- Technologies
- Technologie
- Tensorfluss
- Testament
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- Die Quelle
- ihr
- Sie
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- gedeiht
- Durch
- So
- zu
- Werkzeuge
- Fackel
- Fackelvision
- aufnehmen
- gegenüber
- Tracking
- traditionell
- Training
- trainiert
- Ausbildung
- Transformieren
- Transformation
- Transformationen
- Transformativ
- verwandelt
- Transformieren
- Transformationen
- Transparenz
- was immer dies auch sein sollte.
- versuchen
- verstehen
- Verständnis
- einzigartiges
- bis
- Präsentiert
- Aktualisierung
- auf
- us
- -
- benutzt
- Verwendung von
- Nutzen
- gültig
- verifizieren
- Besichtigung
- Standpunkte
- Seh-
- visuell
- visuelle Kunst
- Visualisierung
- visualisieren
- visuell
- lebenswichtig
- wurde
- we
- webp
- Was
- Was ist
- welche
- während
- Flüstern
- WHO
- breit
- Große Auswahl
- werden wir
- Fenster
- mit
- .
- ohne
- Arbeiten
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- X
- ja
- noch
- U
- Zephyrnet
- Null