Dies ist ein Gastbeitrag, der von Julian Blau, Data Scientist bei xarvio Digital Farming Solutions, mitgeschrieben wurde; BASF Digital Farming GmbH und Antonio Rodriguez, AI/ML Specialist Solutions Architect bei AWS
xarvio Digital Farming Solutions ist eine Marke der BASF Digital Farming GmbH, die Teil des BASF-Unternehmensbereichs Agricultural Solutions ist. xarvio Digital Farming Solutions bietet Präzisionsprodukte für die digitale Landwirtschaft, um Landwirte bei der Optimierung der Pflanzenproduktion zu unterstützen. Die weltweit verfügbaren xarvio-Produkte nutzen maschinelles Lernen (ML), Bilderkennungstechnologie und fortschrittliche Pflanzen- und Krankheitsmodelle in Kombination mit Daten von Satelliten und Wetterstationen, um genaue und zeitnahe agronomische Empfehlungen zu liefern, um die Bedürfnisse einzelner Felder zu bewältigen. xarvio-Produkte sind auf die lokalen landwirtschaftlichen Bedingungen zugeschnitten, können Wachstumsstadien überwachen und Krankheiten und Schädlinge erkennen. Sie steigern die Effizienz, sparen Zeit, reduzieren Risiken und sorgen für mehr Planungs- und Entscheidungssicherheit – und tragen gleichzeitig zu einer nachhaltigen Landwirtschaft bei.
Für einige unserer Anwendungsfälle arbeiten wir mit verschiedenen Geodaten, einschließlich Satellitenbildern der Gebiete, in denen sich die Felder unserer Benutzer befinden. Daher verwenden und verarbeiten wir täglich Hunderte von großen Bilddateien. Anfangs mussten wir viel manuelle Arbeit und Mühe investieren, um diese Daten mit Tools von Drittanbietern, Open-Source-Bibliotheken oder allgemeinen Cloud-Diensten aufzunehmen, zu verarbeiten und zu analysieren. In einigen Fällen kann es bis zu 2 Monate dauern, bis wir die Pipelines für jedes spezifische Projekt erstellt haben. Jetzt, durch die Nutzung der Geodaten-Fähigkeiten von Amazon Sage Maker, haben wir diese Zeit auf nur 1–2 Wochen verkürzt.
Diese Zeitersparnis ist das Ergebnis der Automatisierung der Geodaten-Pipelines zur effizienteren Bereitstellung unserer Anwendungsfälle sowie der Verwendung integrierter wiederverwendbarer Komponenten zur Beschleunigung und Verbesserung ähnlicher Projekte in anderen geografischen Gebieten, während dieselben bewährten Schritte für andere Zwecke angewendet werden Fällen auf der Grundlage ähnlicher Daten.
In diesem Beitrag gehen wir einen beispielhaften Anwendungsfall durch, um einige der Techniken zu beschreiben, die wir häufig verwenden, und zeigen, wie die Implementierung dieser Techniken mit SageMaker-Geodatenfunktionen in Kombination mit anderen SageMaker-Funktionen messbare Vorteile bringt. Wir fügen auch Codebeispiele hinzu, damit Sie diese an Ihre eigenen spezifischen Anwendungsfälle anpassen können.
Lösungsübersicht
Ein typisches Fernerkundungsprojekt zur Entwicklung neuer Lösungen erfordert eine schrittweise Analyse von Bilddaten, die von optischen Satelliten wie z Wache or Landsat, in Kombination mit anderen Daten, einschließlich Wettervorhersagen oder spezifischen Feldeigenschaften. Die Satellitenbilder liefern uns wertvolle Informationen, die in unseren Digital-Farming-Lösungen verwendet werden, um unsere Benutzer bei der Erfüllung verschiedener Aufgaben zu unterstützen:
- Krankheiten frühzeitig auf ihrem Gebiet erkennen
- Planung der richtigen Ernährung und der anzuwendenden Behandlungen
- Erhalten Sie Einblicke in Wetter und Wasser für die Planung der Bewässerung
- Ernteertrag vorhersagen
- Durchführung anderer Pflanzenmanagementaufgaben
Um diese Ziele zu erreichen, erfordern unsere Analysen in der Regel eine Vorverarbeitung der Satellitenbilder mit verschiedenen Techniken, die im Geodatenbereich üblich sind.
Um die Fähigkeiten von SageMaker Geospatial zu demonstrieren, haben wir mit der Identifizierung landwirtschaftlicher Felder durch ML-Segmentierungsmodelle experimentiert. Darüber hinaus haben wir die bereits vorhandenen Geodatenmodelle von SageMaker und die Bring-Your-Own-Model-Funktionalität (BYOM) für Geodatenaufgaben wie Landnutzungs- und Landbedeckungsklassifizierung oder Pflanzenklassifizierung untersucht, die häufig panoptische oder semantische Segmentierungstechniken als zusätzliche Schritte im Prozess erfordern.
In den folgenden Abschnitten gehen wir einige Beispiele durch, wie Sie diese Schritte mit den raumbezogenen Funktionen von SageMaker ausführen können. Sie können diese auch in dem nachfolgend verfügbaren End-to-End-Beispiel-Notebook nachvollziehen GitHub-Repository.
Wie bereits erwähnt, haben wir den Anwendungsfall der Landbedeckungsklassifizierung ausgewählt, der darin besteht, die Art der physischen Bedeckung zu identifizieren, die wir auf einem bestimmten geografischen Gebiet auf der Erdoberfläche haben, organisiert in einer Reihe von Klassen, einschließlich Vegetation, Wasser oder Schnee. Diese hochauflösende Klassifizierung ermöglicht es uns, die Details für die Lage der Felder und ihre Umgebung mit hoher Genauigkeit zu erkennen, die später mit anderen Analysen wie der Erkennung von Änderungen in der Pflanzenklassifizierung verkettet werden können.
Client-Setup
Nehmen wir zunächst an, wir haben Benutzer mit Feldfrüchten, die in einem bestimmten geografischen Gebiet angebaut werden, das wir innerhalb eines Polygons von Geokoordinaten identifizieren können. Für diesen Beitrag definieren wir ein Beispielgebiet über Deutschland. Wir können auch einen bestimmten Zeitraum definieren, beispielsweise in den ersten Monaten des Jahres 2022. Siehe den folgenden Code:
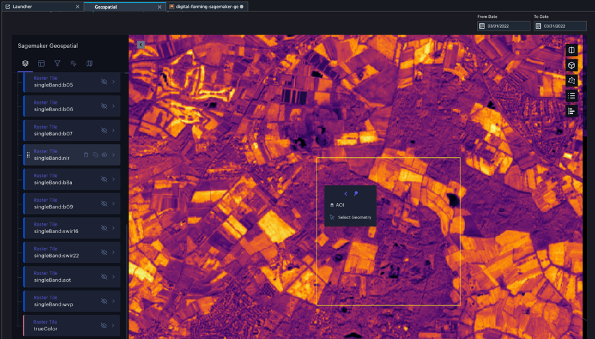
In unserem Beispiel arbeiten wir mit dem Geodaten-SDK von SageMaker durch programmgesteuerte oder Code-Interaktion, weil wir daran interessiert sind, Code-Pipelines zu erstellen, die mit den verschiedenen Schritten, die in unserem Prozess erforderlich sind, automatisiert werden können. Beachten Sie, dass Sie auch mit einer Benutzeroberfläche über die grafischen Erweiterungen arbeiten können, die mit SageMaker Geospatial in bereitgestellt werden Amazon SageMaker-Studio wenn Sie diesen Ansatz bevorzugen, wie in den folgenden Screenshots gezeigt. Um auf die Benutzeroberfläche von Geospatial Studio zuzugreifen, öffnen Sie den SageMaker Studio Launcher und wählen Sie Verwalten Sie Geodaten-Ressourcen. Sie können weitere Details in der Dokumentation nachlesen Beginnen Sie mit den raumbezogenen Funktionen von Amazon SageMaker.
Hier können Sie die Ergebnisse der Erdbeobachtungsaufträge (EOJs), die Sie mit den Geodatenfunktionen von SageMaker ausführen, grafisch erstellen, überwachen und visualisieren.
Zurück zu unserem Beispiel: Der erste Schritt für die Interaktion mit dem Geodaten-SDK von SageMaker besteht darin, den Client einzurichten. Wir können dies tun, indem wir eine Sitzung mit dem einrichten botocore Bibliothek:
Von diesem Punkt an können wir den Client verwenden, um beliebige EOJs von Interesse auszuführen.
Daten beschaffen
Für diesen Anwendungsfall beginnen wir mit dem Sammeln von Satellitenbildern für unser bestimmtes geografisches Gebiet. Abhängig vom interessierenden Ort kann es mehr oder weniger häufige Abdeckung durch die verfügbaren Satelliten geben, deren Bilddaten in dem organisiert sind, was normalerweise als bezeichnet wird Raster-Sammlungen.
Mit den raumbezogenen Funktionen von SageMaker haben Sie direkten Zugriff auf hochwertige Datenquellen, um die raumbezogenen Daten direkt zu erhalten, einschließlich derer aus AWS-Datenaustausch und für Registrierung von Open Data in AWS, unter anderen. Wir können den folgenden Befehl ausführen, um die bereits von SageMaker bereitgestellten Rastersammlungen aufzulisten:
Dadurch werden die Details für die verschiedenen verfügbaren Raster-Sammlungen zurückgegeben, einschließlich Landsat C2L2 Surface Reflectance (SR), Landsat C2L2 Surface Temperature (ST) oder Sentinel 2A & 2B. Praktischerweise sind Level-2A-Bilddaten bereits in Cloud-optimierte GeoTIFFs (COGs) optimiert. Siehe folgenden Code:
Nehmen wir das letzte als unser Beispiel, indem wir unsere setzen data_collection_arn -Parameter zum Sammlungs-ARN der Sentinel 2 L2A COGs.
Wir können auch die verfügbaren Bilder nach einem bestimmten geografischen Ort durchsuchen, indem wir die Koordinaten eines Polygons übergeben, das wir als unseren Interessenbereich (AOI) definiert haben. Auf diese Weise können Sie die verfügbaren Bildkacheln visualisieren, die das Polygon abdecken, das Sie für das angegebene AOI übermitteln, einschließlich der Amazon Simple Storage-Service (Amazon S3) URIs für diese Bilder. Beachten Sie, dass Satellitenbilder in der Regel in unterschiedlichen Formaten bereitgestellt werden Bands entsprechend der Wellenlänge der Beobachtung; Wir diskutieren dies später in der Post.
Der vorangehende Code gibt die S3-URIs für die verschiedenen verfügbaren Bildkacheln zurück, die Sie direkt mit jeder Bibliothek visualisieren können, die mit GeoTIFFs kompatibel ist, z Raster. Lassen Sie uns beispielsweise zwei der True Color Image (TCI)-Kacheln visualisieren.
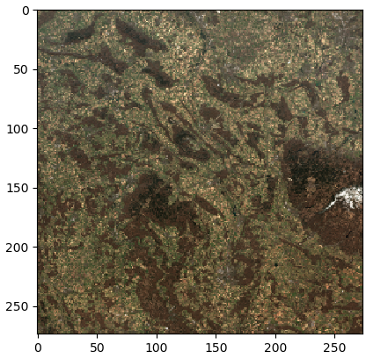
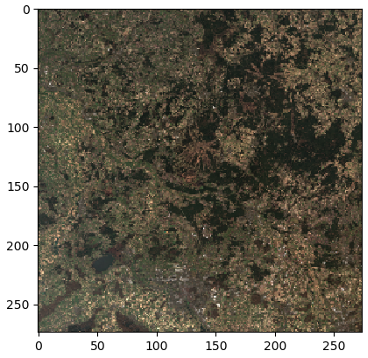
Verarbeitungstechniken
Zu den gängigsten Vorverarbeitungstechniken, die wir anwenden, gehören Wolkenentfernung, Geo-Mosaik, zeitliche Statistiken, Bandmathematik oder Stacking. Alle diese Prozesse können jetzt direkt durch die Verwendung von EOJs in SageMaker durchgeführt werden, ohne dass eine manuelle Codierung oder die Verwendung komplexer und teurer Tools von Drittanbietern erforderlich ist. Dadurch können wir unsere Datenverarbeitungspipelines um 50 % schneller erstellen. Mit den Geodatenfunktionen von SageMaker können wir diese Prozesse über verschiedene Eingabetypen ausführen. Zum Beispiel:
- Führen Sie über die direkt eine Abfrage für eine der im Dienst enthaltenen Rastersammlungen aus
RasterDataCollectionQueryParameter - Übergeben Sie in Amazon S3 gespeicherte Bilder als Eingabe durch die
DataSourceConfigParameter - Verketten Sie einfach die Ergebnisse eines vorherigen EOJ durch die
PreviousEarthObservationJobArnParameter
Diese Flexibilität ermöglicht es Ihnen, jede Art von Verarbeitungspipeline zu erstellen, die Sie benötigen.
Das folgende Diagramm veranschaulicht die Prozesse, die wir in unserem Beispiel abdecken.
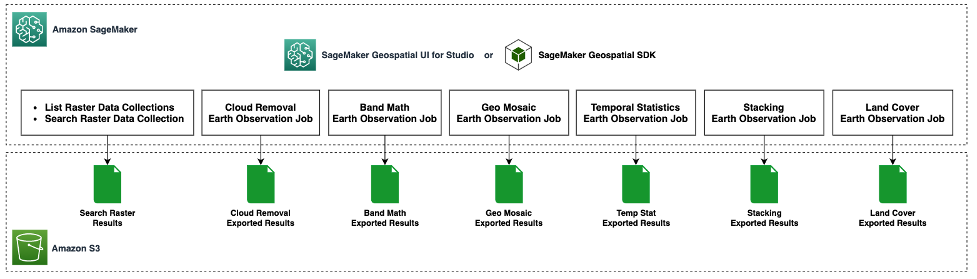
In unserem Beispiel verwenden wir eine Rasterdatenerfassungsabfrage als Eingabe, für die wir die Koordinaten unseres AOI und den interessierenden Zeitbereich übergeben. Wir geben auch einen Prozentsatz der maximalen Bewölkung von 2% an, weil wir klare und rauschfreie Beobachtungen unseres geografischen Gebiets wollen. Siehe folgenden Code:
Weitere Informationen zur unterstützten Abfragesyntax finden Sie unter Erstellen Sie einen Erdbeobachtungsjob.
Entfernen von Wolkenlücken
Satellitenbeobachtungen sind aufgrund der hohen Bewölkung oft weniger sinnvoll. Das Füllen von Wolkenlücken oder das Entfernen von Wolken ist der Prozess des Ersetzens der trüben Pixel aus den Bildern, was mit verschiedenen Methoden erfolgen kann, um die Daten für weitere Verarbeitungsschritte vorzubereiten.
Mit den Geodatenfunktionen von SageMaker können wir dies erreichen, indem wir a angeben CloudRemovalConfig Parameter in der Konfiguration unseres Jobs.
Beachten Sie, dass wir in unserem Beispiel einen Interpolationsalgorithmus mit einem festen Wert verwenden, aber es werden auch andere Konfigurationen unterstützt, wie in erläutert Erstellen Sie einen Erdbeobachtungsjob Dokumentation. Die Interpolation erlaubt es, einen Wert zum Ersetzen der wolkigen Pixel abzuschätzen, indem die umgebenden Pixel berücksichtigt werden.
Wir können jetzt unser EOJ mit unseren Eingabe- und Jobkonfigurationen ausführen:
Dieser Job dauert je nach Eingabebereich und Verarbeitungsparametern einige Minuten.
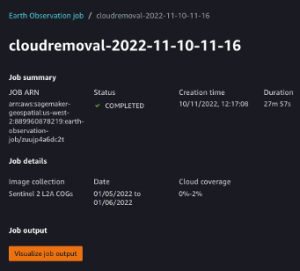
Wenn es abgeschlossen ist, werden die Ergebnisse des EOJ an einem serviceeigenen Ort gespeichert, von wo aus wir die Ergebnisse entweder nach Amazon S3 exportieren oder diese als Eingabe für ein anderes EOJ verketten können. In unserem Beispiel exportieren wir die Ergebnisse nach Amazon S3, indem wir den folgenden Code ausführen:
Jetzt können wir die resultierenden Bilder visualisieren, die an unserem angegebenen Amazon S3-Speicherort für die einzelnen Spektralbänder gespeichert sind. Lassen Sie uns beispielsweise zwei der zurückgegebenen blauen Bandbilder untersuchen.
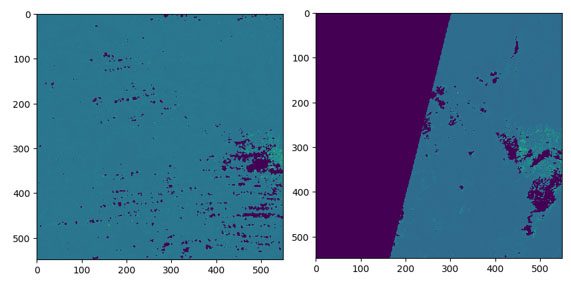
Alternativ können Sie die Ergebnisse des EOJ auch grafisch überprüfen, indem Sie die in Studio verfügbaren Geodatenerweiterungen verwenden, wie in den folgenden Screenshots gezeigt.
Zeitliche Statistiken
Da die Satelliten kontinuierlich um die Erde kreisen, werden die Bilder für einen bestimmten interessierenden geographischen Bereich zu bestimmten Zeitrahmen mit einer bestimmten zeitlichen Häufigkeit aufgenommen, wie z. B. täglich, alle 5 Tage oder 2 Wochen, je nach Satellit. Der zeitliche Statistikprozess ermöglicht es uns, verschiedene Beobachtungen zu verschiedenen Zeiten zu kombinieren, um eine aggregierte Ansicht zu erstellen, z. B. einen Jahresmittelwert oder den Mittelwert aller Beobachtungen in einem bestimmten Zeitraum für das gegebene Gebiet.
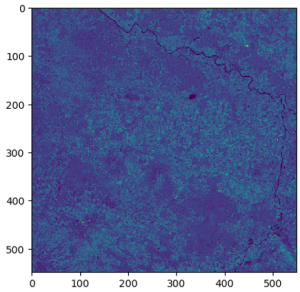
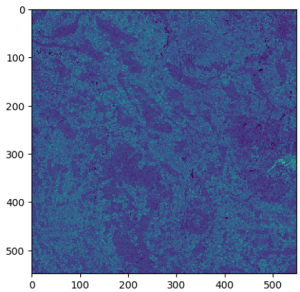
Mit den raumbezogenen Funktionen von SageMaker können wir dies tun, indem wir die TemporalStatisticsConfig Parameter. In unserem Beispiel erhalten wir die Jahresmittelwertaggregation für das Nahinfrarotband (NIR), da dieses Band Unterschiede in der Vegetationsdichte unterhalb der Baumkronen aufzeigen kann:
Nach einigen Minuten, in denen ein EOJ mit dieser Konfiguration ausgeführt wird, können wir die Ergebnisse nach Amazon S3 exportieren, um Bilder wie in den folgenden Beispielen zu erhalten, in denen wir die unterschiedlichen Vegetationsdichten beobachten können, die mit unterschiedlichen Farbintensitäten dargestellt werden. Beachten Sie, dass das EOJ abhängig von den verfügbaren Satellitendaten für den angegebenen Zeitraum und die angegebenen Koordinaten mehrere Bilder als Kacheln erzeugen kann.
Band-Mathematik
Erdbeobachtungssatelliten sollen Licht in verschiedenen Wellenlängen erfassen, von denen einige für das menschliche Auge unsichtbar sind. Jeder Bereich enthält bestimmte Bänder des Lichtspektrums bei unterschiedlichen Wellenlängen, die in Kombination mit Arithmetik Bilder mit reichhaltigen Informationen über Eigenschaften des Feldes wie Vegetationszustand, Temperatur oder Vorhandensein von Wolken und vielem mehr erzeugen können. Dies wird in einem Prozess durchgeführt, der allgemein als Bandmathematik oder Bandarithmetik bezeichnet wird.
Mit den Geodatenfunktionen von SageMaker können wir dies ausführen, indem wir die BandMathConfig Parameter. Lassen Sie uns beispielsweise die Feuchtigkeitsindexbilder abrufen, indem Sie den folgenden Code ausführen:
Nach ein paar Minuten, in denen ein EOJ mit dieser Konfiguration ausgeführt wird, können wir die Ergebnisse exportieren und Bilder erhalten, wie in den folgenden beiden Beispielen.
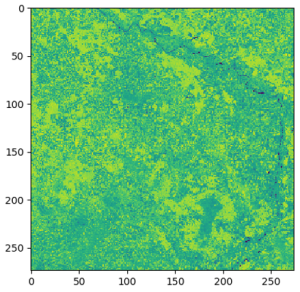
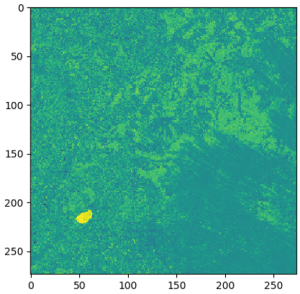

Stacking
Ähnlich wie bei der Bandmathematik wird der Vorgang des Kombinierens von Bändern, um zusammengesetzte Bilder aus den ursprünglichen Bändern zu erzeugen, als Stapeln bezeichnet. Beispielsweise könnten wir die roten, blauen und grünen Lichtbänder eines Satellitenbildes stapeln, um das Echtfarbenbild des AOI zu erzeugen.
Mit den raumbezogenen Funktionen von SageMaker können wir dies tun, indem wir die StackConfig Parameter. Lassen Sie uns die RGB-Bänder wie im vorherigen Beispiel mit dem folgenden Befehl stapeln:
Nach ein paar Minuten, in denen ein EOJ mit dieser Konfiguration ausgeführt wird, können wir die Ergebnisse exportieren und Bilder erhalten.
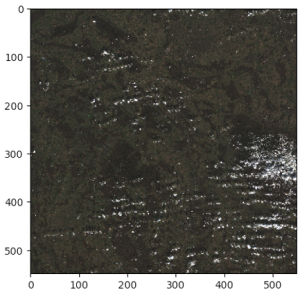
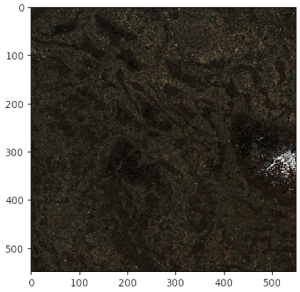
Semantische Segmentierungsmodelle
Im Rahmen unserer Arbeit verwenden wir häufig ML-Modelle, um Rückschlüsse auf die vorverarbeiteten Bilder zu ziehen, z. B. um bewölkte Bereiche zu erkennen oder die Art des Landes in jedem Bereich der Bilder zu klassifizieren.
Mit den raumbezogenen Funktionen von SageMaker können Sie dies tun, indem Sie sich auf die integrierten Segmentierungsmodelle verlassen.
Verwenden wir für unser Beispiel das Landbedeckungs-Segmentierungsmodell, indem wir die angeben LandCoverSegmentationConfig Parameter. Dadurch werden mithilfe des integrierten Modells Rückschlüsse auf die Eingabe ausgeführt, ohne dass eine Infrastruktur in SageMaker trainiert oder gehostet werden muss:
Nach ein paar Minuten, in denen ein Job mit dieser Konfiguration ausgeführt wird, können wir die Ergebnisse exportieren und Bilder erhalten.


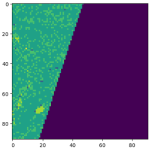
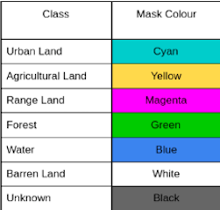
In den vorangegangenen Beispielen entspricht jedes Pixel in den Bildern einer Landtypklasse, wie in der folgenden Legende gezeigt.
![]()
Dadurch können wir die spezifischen Arten von Bereichen in der Szene wie Vegetation oder Wasser direkt identifizieren, was wertvolle Erkenntnisse für zusätzliche Analysen liefert.
Bringen Sie Ihr eigenes Modell mit SageMaker mit
Wenn die mit SageMaker bereitgestellten hochmodernen Geodatenmodelle für unseren Anwendungsfall nicht ausreichen, können wir die Ergebnisse aller bisher gezeigten Vorverarbeitungsschritte auch mit jedem benutzerdefinierten Modell verketten, das für Rückschlüsse in SageMaker integriert ist, wie erläutert in diesem SageMaker-Skriptmodus Beispiel. Wir können dies mit jedem der in SageMaker unterstützten Inferenzmodi tun, einschließlich synchron mit Echtzeit-SageMaker-Endpunkten, asynchron mit asynchronen SageMaker-Endpunkten, Batch oder offline mit SageMaker-Batch-Transformationen und serverlos mit serverloser SageMaker-Inferenz. Weitere Einzelheiten zu diesen Modi finden Sie in der Modelle für Inferenz bereitstellen Dokumentation. Das folgende Diagramm veranschaulicht den Workflow auf hoher Ebene.
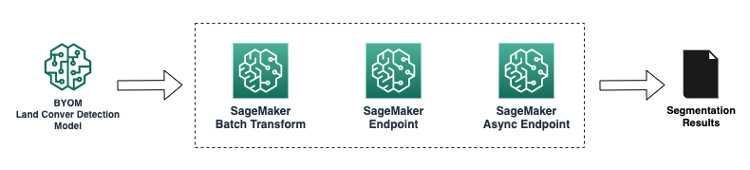
Nehmen wir für unser Beispiel an, wir haben zwei Modelle integriert, um eine Landbedeckungsklassifizierung und eine Klassifizierung von Pflanzenarten durchzuführen.
Wir müssen nur auf unser trainiertes Modellartefakt zeigen, in unserem Beispiel ein PyTorch-Modell, ähnlich dem folgenden Code:
Auf diese Weise können Sie je nach verwendetem Modell die resultierenden Bilder nach der Inferenz erhalten.
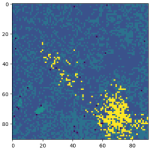
In unserem Beispiel erzeugt das Modell beim Ausführen einer benutzerdefinierten Landbedeckungssegmentierung Bilder ähnlich den folgenden, in denen wir die Eingabe- und Vorhersagebilder mit der entsprechenden Legende vergleichen.

 .
. 
Das Folgende ist ein weiteres Beispiel für ein Pflanzenklassifikationsmodell, in dem wir den Vergleich der ursprünglichen vs. resultierenden panoptischen und semantischen Segmentierungsergebnisse mit der entsprechenden Legende zeigen.

Automatisierung von Geodaten-Pipelines
Schließlich können wir die vorherigen Schritte auch automatisieren, indem wir Geodatenverarbeitungs- und Inferenzpipelines mit erstellen Amazon SageMaker-Pipelines. Wir verketten einfach jeden erforderlichen Vorverarbeitungsschritt durch die Verwendung von Lambda-Schritte und Callback-Schritte in Rohrleitungen. Sie könnten beispielsweise auch einen letzten Inferenzschritt mithilfe eines Transformationsschritts oder direkt über eine andere Kombination aus Lambda-Schritten und Callback-Schritten hinzufügen, um ein EOJ mit einem der integrierten semantischen Segmentierungsmodelle in den Geodatenfunktionen von SageMaker auszuführen.
Beachten Sie, dass wir Lambda-Schritte und Callback-Schritte in Pipelines verwenden, da die EOJs asynchron sind, sodass wir mit dieser Art von Schritt die Ausführung des Verarbeitungsauftrags überwachen und die Pipeline fortsetzen können, wenn sie durch Nachrichten in einer abgeschlossen ist Amazon Simple Queue-Dienst Warteschlange (Amazon SQS).
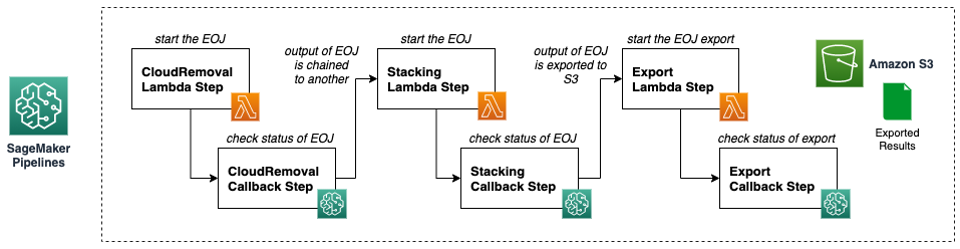
Sie können das Notizbuch im überprüfen GitHub-Repository für ein detailliertes Beispiel dieses Codes.
Jetzt können wir das Diagramm unserer Geodaten-Pipeline über Studio visualisieren und die Läufe in Pipelines überwachen, wie im folgenden Screenshot gezeigt.
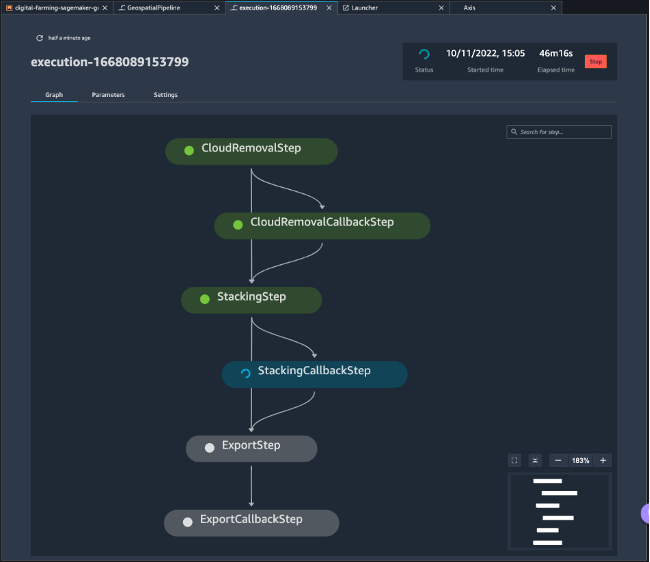
Zusammenfassung
In diesem Beitrag haben wir eine Zusammenfassung der Prozesse präsentiert, die wir mit den Geodatenfunktionen von SageMaker zum Erstellen von Geodaten-Pipelines für unsere fortschrittlichen Produkte von xarvio Digital Farming Solutions implementiert haben. Die Verwendung von SageMaker Geospatial steigerte die Effizienz unserer Geodatenarbeit um mehr als 50 % durch die Verwendung vorgefertigter APIs, die unsere Vorverarbeitungs- und Modellierungsschritte für ML beschleunigen und vereinfachen.
Als nächsten Schritt integrieren wir weitere Modelle aus unserem Katalog in SageMaker, um die Automatisierung unserer Lösungspipelines fortzusetzen, und werden im Zuge der Weiterentwicklung des Dienstes weitere Geodatenfunktionen von SageMaker nutzen.
Wir empfehlen Ihnen, die Geodatenfunktionen von SageMaker auszuprobieren, indem Sie das in diesem Beitrag bereitgestellte End-to-End-Beispiel-Notebook anpassen und mehr über den Dienst in erfahren Was sind die Geodatenfunktionen von Amazon SageMaker?.
Über die Autoren
 Julian Blau ist Data Scientist bei der BASF Digital Farming GmbH mit Sitz in Köln. Er entwickelt digitale Lösungen für die Landwirtschaft und geht auf die Bedürfnisse des globalen Kundenstamms von BASF ein, indem er Geodaten und maschinelles Lernen nutzt. Außerhalb der Arbeit reist er gerne und ist gerne mit Freunden und Familie im Freien.
Julian Blau ist Data Scientist bei der BASF Digital Farming GmbH mit Sitz in Köln. Er entwickelt digitale Lösungen für die Landwirtschaft und geht auf die Bedürfnisse des globalen Kundenstamms von BASF ein, indem er Geodaten und maschinelles Lernen nutzt. Außerhalb der Arbeit reist er gerne und ist gerne mit Freunden und Familie im Freien.
 Antonio Rodriguez ist ein auf künstliche Intelligenz und maschinelles Lernen spezialisierter Lösungsarchitekt bei Amazon Web Services mit Sitz in Spanien. Er hilft Unternehmen jeder Größe, ihre Herausforderungen durch Innovation zu lösen, und schafft neue Geschäftsmöglichkeiten mit AWS Cloud- und KI/ML-Services. Neben der Arbeit verbringt er am liebsten Zeit mit seiner Familie und treibt mit seinen Freunden Sport.
Antonio Rodriguez ist ein auf künstliche Intelligenz und maschinelles Lernen spezialisierter Lösungsarchitekt bei Amazon Web Services mit Sitz in Spanien. Er hilft Unternehmen jeder Größe, ihre Herausforderungen durch Innovation zu lösen, und schafft neue Geschäftsmöglichkeiten mit AWS Cloud- und KI/ML-Services. Neben der Arbeit verbringt er am liebsten Zeit mit seiner Familie und treibt mit seinen Freunden Sport.
- Luft- und Raumfahrt & Satellit
- Landwirtschaft
- AI
- Kunst
- KI-Kunstgenerator
- KI-Roboter
- Amazon Sage Maker
- künstliche Intelligenz
- Zertifizierung für künstliche Intelligenz
- Künstliche Intelligenz im Bankwesen
- Roboter mit künstlicher Intelligenz
- Roboter mit künstlicher Intelligenz
- Software für künstliche Intelligenz
- AWS Maschinelles Lernen
- Blockchain
- Blockchain-Konferenz ai
- Fallstudie
- Einfallsreichtum
- dialogorientierte künstliche Intelligenz
- Krypto-Konferenz ai
- Kundenlösungen
- Dalls
- tiefe Lernen
- Geodaten-ML
- Google Ai
- Maschinelles Lernen
- Plato
- platon ai
- Datenintelligenz von Plato
- Plato-Spiel
- PlatoData
- Platogaming
- Satellit
- Skala ai
- Nachhaltigkeit
- Syntax
- Zephyrnet