Bild vom Autor
Gemini ist ein neues von Google entwickeltes Modell und Bard wird wieder verwendbar. Mit Gemini ist es nun möglich, durch die Bereitstellung von Bildern, Audio und Text nahezu perfekte Antworten auf Ihre Fragen zu erhalten.
In diesem Tutorial lernen wir die Gemini-API kennen und erfahren, wie Sie sie auf Ihrem Computer einrichten. Wir werden auch verschiedene Python-API-Funktionen untersuchen, einschließlich Textgenerierung und Bildverständnis.
Gemini ist ein neues KI-Modell, das in Zusammenarbeit zwischen Teams bei Google, darunter Google Research und Google DeepMind, entwickelt wurde. Es wurde speziell für die Multimodalität entwickelt, was bedeutet, dass es verschiedene Arten von Daten wie Text, Code, Audio, Bilder und Video verstehen und damit arbeiten kann.
Gemini ist das fortschrittlichste und größte KI-Modell, das Google bisher entwickelt hat. Es wurde so konzipiert, dass es äußerst flexibel ist, sodass es auf einer Vielzahl von Systemen, von Rechenzentren bis hin zu mobilen Geräten, effizient betrieben werden kann. Dies bedeutet, dass es das Potenzial hat, die Art und Weise zu revolutionieren, wie Unternehmen und Entwickler KI-Anwendungen erstellen und skalieren können.
Hier sind drei Versionen des Gemini-Modells, die für unterschiedliche Anwendungsfälle entwickelt wurden:
- Zwillinge Ultra: Größte und fortschrittlichste KI, die komplexe Aufgaben ausführen kann.
- Zwillinge Pro: Ein ausgewogenes Modell mit guter Leistung und Skalierbarkeit.
- Zwillinge Nano: Am effizientesten für mobile Geräte.
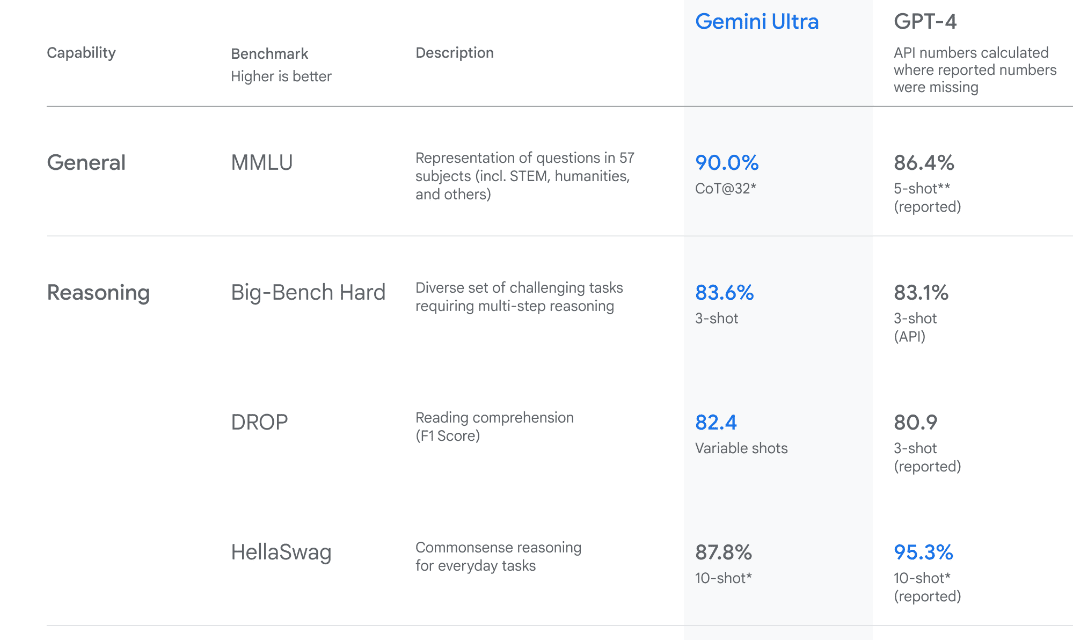
Bild aus Wir stellen Zwillinge vor
Gemini Ultra verfügt über eine Leistung auf dem neuesten Stand der Technik und übertrifft die Leistung von GPT-4 in mehreren Metriken. Es ist das erste Modell, das menschliche Experten beim Massive Multitask Language Understanding-Benchmark übertrifft, bei dem Weltwissen und Problemlösung in 57 verschiedenen Fächern getestet werden. Dies zeigt sein fortgeschrittenes Verständnis und seine Fähigkeiten zur Problemlösung.
Um die API nutzen zu können, müssen wir zunächst einen API-Schlüssel erhalten, den Sie hier abrufen können: https://ai.google.dev/tutorials/setup
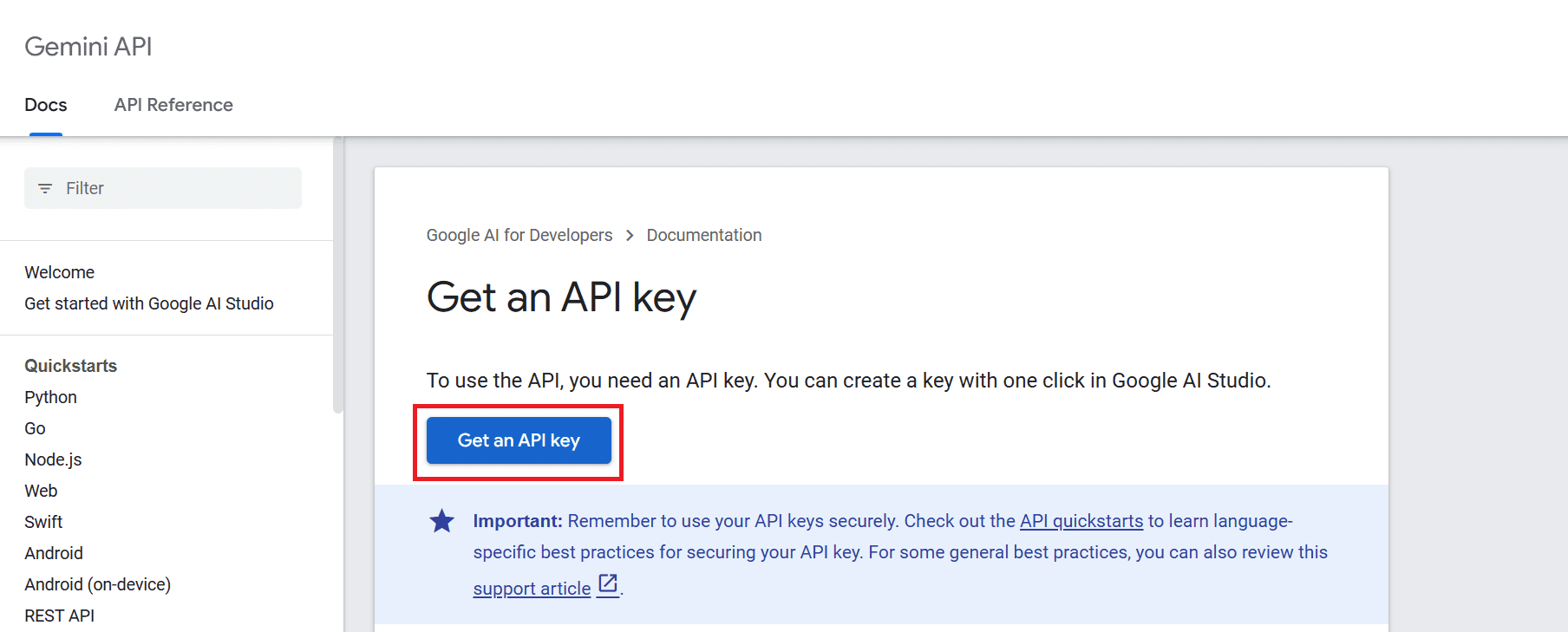
Klicken Sie anschließend auf die Schaltfläche „API-Schlüssel abrufen“ und dann auf „API-Schlüssel in neuem Projekt erstellen“.
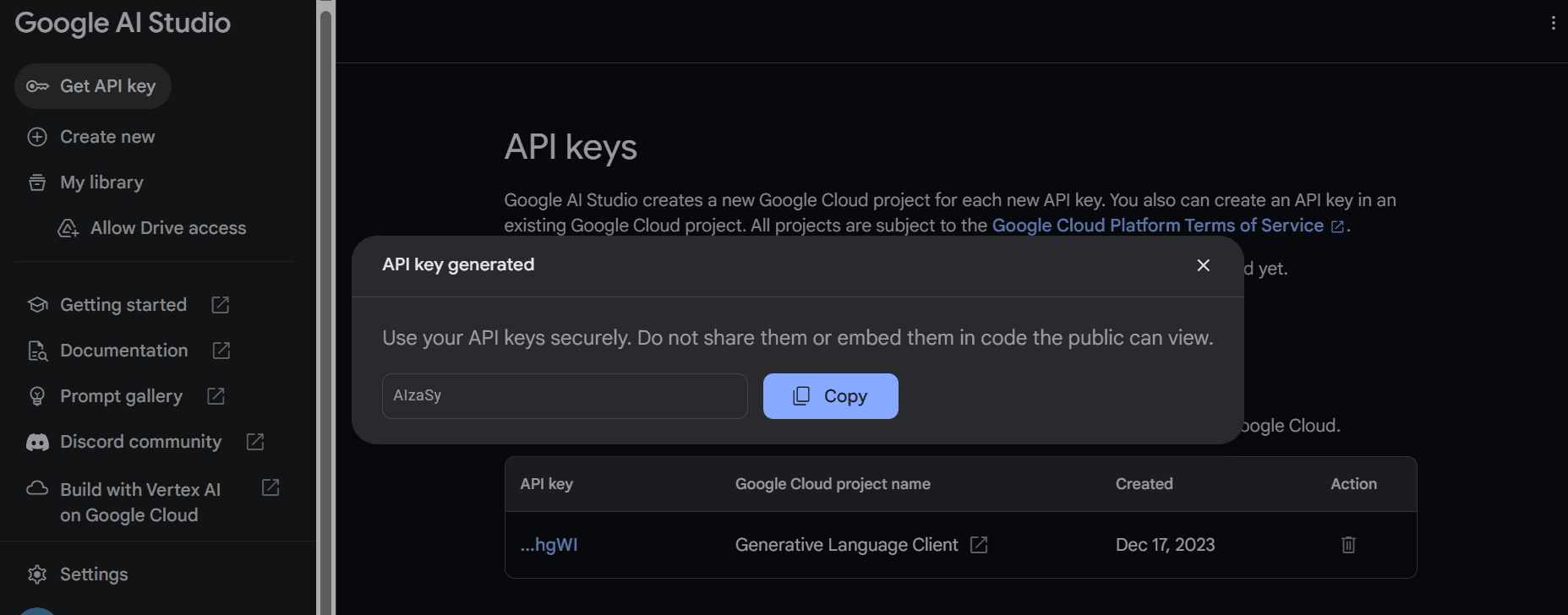
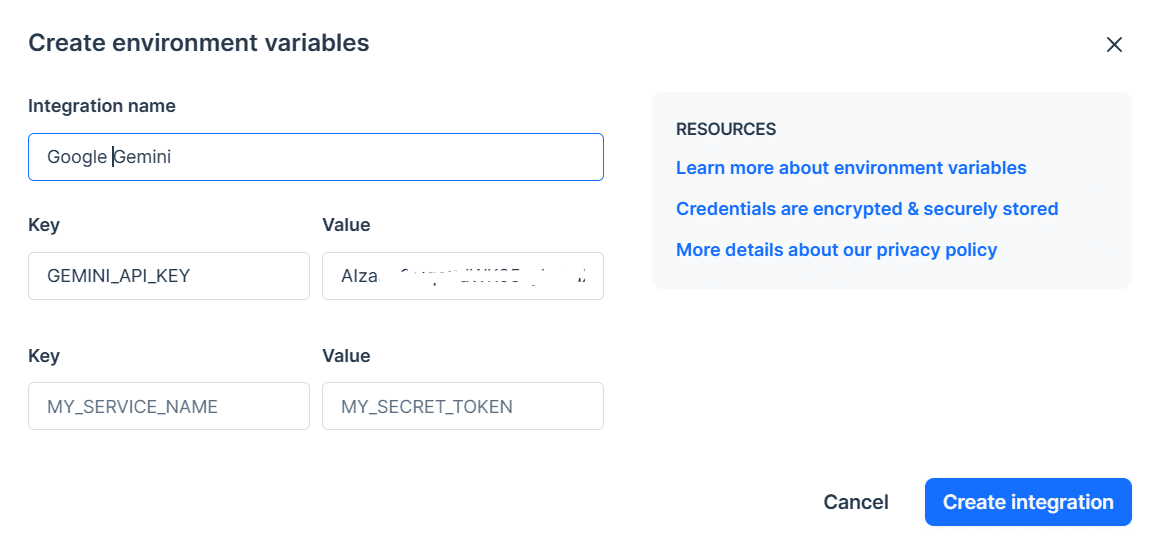
Kopieren Sie den API-Schlüssel und legen Sie ihn als Umgebungsvariable fest. Wir verwenden Deepnote und es ist für uns ganz einfach, den Schlüssel mit dem Namen „GEMINI_API_KEY“ festzulegen. Gehen Sie einfach zur Integration, scrollen Sie nach unten und wählen Sie Umgebungsvariablen aus.
Im nächsten Schritt installieren wir die Python-API mithilfe von PIP:
pip install -q -U google-generativeaiDanach setzen wir den API-Schlüssel auf Googles GenAI und initiieren die Instanz.
import google.generativeai as genai
import os
gemini_api_key = os.environ["GEMINI_API_KEY"]
genai.configure(api_key = gemini_api_key)Nach dem Einrichten des API-Schlüssels ist die Verwendung des Gemini Pro-Modells zum Generieren von Inhalten einfach. Stellen Sie eine Eingabeaufforderung für die Funktion „generate_content“ bereit und zeigen Sie die Ausgabe als Markdown an.
from IPython.display import Markdown
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Who is the GOAT in the NBA?")
Markdown(response.text)Das ist erstaunlich, aber ich bin mit der Liste nicht einverstanden. Ich verstehe jedoch, dass es nur um persönliche Vorlieben geht.

Gemini kann für eine einzige Eingabeaufforderung mehrere Antworten, sogenannte Kandidaten, generieren. Sie können die am besten geeignete auswählen. In unserem Fall hatten wir nur eine Antwort.
response.candidates
Bitten wir ihn, ein einfaches Spiel in Python zu schreiben.
response = model.generate_content("Build a simple game in Python")
Markdown(response.text)Das Ergebnis ist einfach und auf den Punkt. Die meisten LLMs beginnen damit, den Python-Code zu erklären, anstatt ihn zu schreiben.

Sie können Ihre Antwort mit dem Argument „generation_config“ anpassen. Wir begrenzen die Anzahl der Kandidaten auf 1, fügen das Stoppwort „Leerzeichen“ hinzu und legen maximale Token und Temperatur fest.
response = model.generate_content(
'Write a short story about aliens.',
generation_config=genai.types.GenerationConfig(
candidate_count=1,
stop_sequences=['space'],
max_output_tokens=200,
temperature=0.7)
)
Markdown(response.text)Wie Sie sehen können, endete die Antwort vor dem Wort „Leerzeichen“. Toll.

Sie können auch das Argument „stream“ verwenden, um die Antwort zu streamen. Es ähnelt den Anthropic- und OpenAI-APIs, ist jedoch schneller.
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Write a Julia function for cleaning the data.", stream=True)
for chunk in response:
print(chunk.text)
In diesem Abschnitt werden wir laden Masood Aslamis Foto und testen Sie damit die Multimodalität von Gemini Pro Vision.
Laden Sie die Bilder in das „PIL“ und zeigen Sie es an.
import PIL.Image
img = PIL.Image.open('images/photo-1.jpg')
imgWir haben ein hochwertiges Foto des Rua Augusta Arch.

Laden wir das Gemini Pro Vision-Modell und versehen es mit dem Bild.
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)Das Modell identifizierte den Palast genau und lieferte zusätzliche Informationen über seine Geschichte und Architektur.

Stellen wir dem GPT-4 dasselbe Bild zur Verfügung und fragen Sie ihn nach dem Bild. Beide Modelle haben nahezu ähnliche Antworten geliefert. Aber mir gefällt die GPT-4-Antwort besser.

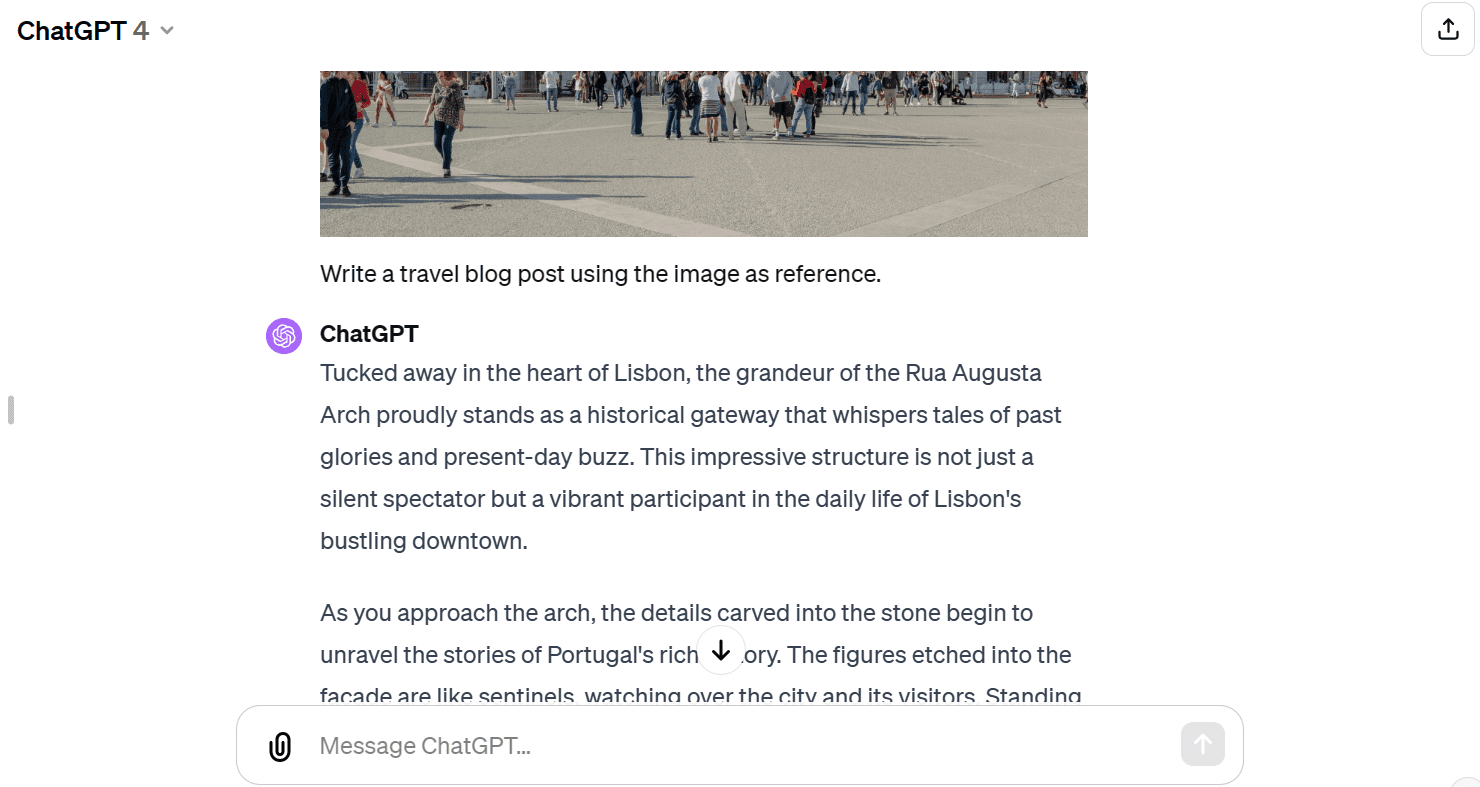
Wir werden nun der API Text und das Bild bereitstellen. Wir haben das Vision-Modell gebeten, einen Reiseblog zu schreiben, der das Bild als Referenz verwendet.
response = model.generate_content(["Write a travel blog post using the image as reference.", img])
Markdown(response.text)Es hat mir einen kurzen Blog zur Verfügung gestellt. Ich hatte ein längeres Format erwartet.

Im Vergleich zu GPT-4 hatte das Gemini Pro Vision-Modell Schwierigkeiten, einen Blog im Langformat zu erstellen.
Wir können das Modell so einrichten, dass eine Hin- und Her-Chat-Sitzung stattfindet. Auf diese Weise merkt sich das Modell den Kontext und die Reaktion anhand der vorherigen Gespräche.
In unserem Fall haben wir die Chat-Sitzung gestartet und das Model gebeten, mir beim Einstieg in das Dota 2-Spiel zu helfen.
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=[])
chat.send_message("Can you please guide me on how to start playing Dota 2?")
chat.historyWie Sie sehen können, speichert das „Chat“-Objekt den Verlauf des Benutzers und den Modus-Chat.

Wir können sie auch im Markdown-Stil anzeigen.
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))
Stellen wir die Folgefrage.
chat.send_message("Which Dota 2 heroes should I start with?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))Wir können nach unten scrollen und die gesamte Sitzung mit dem Modell sehen.

Einbettungsmodelle werden für kontextsensitive Anwendungen immer beliebter. Das Embedding-001-Modell von Gemini ermöglicht die Darstellung von Wörtern, Sätzen oder ganzen Dokumenten als dichte Vektoren, die semantische Bedeutung kodieren. Diese Vektordarstellung ermöglicht einen einfachen Vergleich der Ähnlichkeit zwischen verschiedenen Textteilen durch Vergleich ihrer entsprechenden Einbettungsvektoren.
Wir können den Inhalt für „embed_content“ bereitstellen und den Text in Einbettungen umwandeln. So einfach ist das.
output = genai.embed_content(
model="models/embedding-001",
content="Can you please guide me on how to start playing Dota 2?",
task_type="retrieval_document",
title="Embedding of Dota 2 question")
print(output['embedding'][0:10])[0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664]Wir können mehrere Textblöcke in Einbettungen umwandeln, indem wir eine Liste von Zeichenfolgen an das Argument „content“ übergeben.
output = genai.embed_content(
model="models/embedding-001",
content=[
"Can you please guide me on how to start playing Dota 2?",
"Which Dota 2 heroes should I start with?",
],
task_type="retrieval_document",
title="Embedding of Dota 2 question")
for emb in output['embedding']:
print(emb[:10])[0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664]
[0.04775657, -0.044990525, -0.014886052, -0.08473655, 0.04060122, 0.035374347, 0.031866882, 0.071754575, 0.042207796, 0.04577447]Wenn Sie Probleme haben, dasselbe Ergebnis zu reproduzieren, schauen Sie sich meine an Deepnote-Arbeitsbereich.
Es gibt so viele erweiterte Funktionen, die wir in diesem Einführungs-Tutorial nicht behandelt haben. Weitere Informationen zur Gemini-API finden Sie unter Gemini API: Schnellstart mit Python.
In diesem Tutorial haben wir etwas über Gemini gelernt und erfahren, wie man auf die Python-API zugreift, um Antworten zu generieren. Insbesondere haben wir etwas über Textgenerierung, visuelles Verständnis, Streaming, Konversationsverlauf, benutzerdefinierte Ausgabe und Einbettungen gelernt. Dies kratzt jedoch nur an der Oberfläche dessen, was Gemini leisten kann.
Teilen Sie mir gerne mit, was Sie mit der kostenlosen Gemini-API erstellt haben. Die Möglichkeiten sind grenzenlos.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, Modelle für maschinelles Lernen zu erstellen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und schreibt technische Blogs zu maschinellem Lernen und Data-Science-Technologien. Abid hat einen Master-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Vision ist es, ein KI-Produkt mit einem grafisch-neuronalen Netzwerk für Schüler zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/how-to-access-and-use-gemini-api-for-free?utm_source=rss&utm_medium=rss&utm_campaign=how-to-access-and-use-gemini-api-for-free
- :hast
- :Ist
- $UP
- 1
- 10
- 12
- 13
- 14
- 17
- 27
- 7
- 8
- 9
- a
- LiveBuzz
- Zugang
- genau
- über
- Hinzufügen
- Zusätzliche
- Zusätzliche Angaben
- advanced
- aufs Neue
- AI
- Aliens
- Alle
- erlaubt
- fast
- ebenfalls
- erstaunlich
- an
- und
- Antworten
- Anthropisch
- Bienen
- APIs
- Anwendungen
- Architektur
- SIND
- Argument
- AS
- fragen
- At
- Audio-
- Ausgewogen
- BE
- Werden
- war
- Bevor
- Benchmark
- zwischen
- Blog
- Blogs
- beide
- bauen
- Building
- erbaut
- Unternehmen
- aber
- Taste im nun erscheinenden Bestätigungsfenster nun wieder los.
- by
- namens
- CAN
- Kandidat
- Kandidaten
- Fähigkeiten
- fähig
- Häuser
- Fälle
- Centers
- Zertifzierte
- Chat
- aus der Ferne überprüfen
- Reinigung
- klicken Sie auf
- Code
- Zusammenarbeit
- vergleichen
- Vergleich
- Komplex
- Inhalt
- Inhaltserstellung
- Kontext
- Gespräch
- Gespräche
- verkaufen
- Dazugehörigen
- Abdeckung
- Schaffung
- Zur Zeit
- Original
- anpassen
- technische Daten
- Rechenzentren
- Datenwissenschaft
- Datenwissenschaftler
- Datum
- DeepMind
- Grad
- dicht
- entworfen
- entwickelt
- Entwickler
- Geräte
- didn
- anders
- Display
- verschieden
- do
- Unterlagen
- Don
- DotA
- Dota 2
- nach unten
- leicht
- Einfache
- effizient
- effizient
- Einbettung
- Entwicklung
- Ganz
- Arbeitsumfeld
- Äther (ETH)
- erwartet
- Experten
- Erklären
- ERKUNDEN
- beschleunigt
- Vorname
- flexibel
- Fokussierung
- folgen
- Aussichten für
- Format
- Frei
- für
- Funktion
- Funktionen
- Spiel
- Gemini
- erzeugen
- Generation
- bekommen
- gif
- Go
- gehen
- gut
- Graph
- Graph Neuronales Netzwerk
- Guide
- hätten
- Haben
- mit
- he
- Hilfe
- hier
- Helden
- GUTE
- hoch
- seine
- Geschichte
- hält
- Ultraschall
- Hilfe
- aber
- HTTPS
- human
- i
- identifiziert
- Krankheit
- Image
- Bilder
- importieren
- in
- Einschließlich
- zunehmend
- Information
- initiieren
- installieren
- Instanz
- beantragen müssen
- Integration
- in
- einleitend
- IT
- SEINE
- jpg
- julia
- nur
- KDnuggets
- Wesentliche
- Wissen
- Sprache
- höchste
- LERNEN
- gelernt
- lernen
- Gefällt mir
- grenzenlos
- Liste
- Belastung
- länger
- liebt
- Maschine
- Maschinelles Lernen
- MACHT
- Management
- viele
- massiv
- Master
- max
- me
- Bedeutung
- Mittel
- geistig
- Geisteskrankheit
- Metrik
- Mobil
- mobile Geräte
- Model
- Modell
- für
- mehr
- vor allem warme
- mehrere
- Name
- nano
- NBA
- Netzwerk
- Neural
- neuronale Netzwerk
- Neu
- weiter
- jetzt an
- Objekt
- of
- on
- EINEM
- einzige
- OpenAI
- betreiben
- or
- OS
- UNSERE
- Übertreffen
- Möglichkeiten für das Ausgangssignal:
- Palast
- besondere
- Bestehen
- perfekt
- Leistung
- Durchführung
- persönliche
- für Ihre privaten Foto
- Stücke
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Bitte
- Points
- Beliebt
- Möglichkeiten
- möglich
- Post
- Potenzial
- früher
- Pro
- Aufgabenstellung:
- Problemlösung
- Produkt
- Professionell
- die
- vorausgesetzt
- Bereitstellung
- Python
- Qualität
- Abfragen
- Frage
- ganz
- Angebot
- RE
- Referenz
- Darstellung
- vertreten
- Forschungsprojekte
- Antwort
- Antworten
- Folge
- revolutionieren
- s
- gleich
- Einsparung
- Skalierbarkeit
- Skalieren
- Skala ai
- Wissenschaft
- Wissenschaftler
- blättern
- Abschnitt
- sehen
- wählen
- Sitzung
- kompensieren
- Einstellung
- mehrere
- Teilen
- Short
- sollte
- ähnlich
- Einfacher
- Single
- So
- Auflösung
- Raumfahrt
- speziell
- Anfang
- begonnen
- State-of-the-art
- Schritt
- Stoppen
- gestoppt
- Geschichte
- Strom
- Streaming
- Struggling
- Die Kursteilnehmer
- Stil
- geeignet
- Oberfläche
- Systeme und Techniken
- T
- und Aufgaben
- Teams
- Technische
- Technologies
- Technologie
- Telekommunikations
- Test
- Tests
- Text
- Texterzeugung
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- fehlen uns die Worte.
- nach drei
- Durch
- zu
- Tokens
- reisen
- Ärger
- Lernprogramm
- Typen
- Ultra-
- verstehen
- Verständnis
- us
- verwendbar
- -
- Mitglied
- Verwendung von
- Variable
- verschiedene
- Video
- Seh-
- visuell
- wurde
- Weg..
- we
- Was
- welche
- WHO
- breit
- Große Auswahl
- werden wir
- mit
- Word
- Worte
- Arbeiten
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- schreiben
- Schreiben
- U
- Ihr
- Zephyrnet