Dies ist ein Gastbeitrag, der von Alex Naumov, Principal Data Architect bei smava, mitgeschrieben wurde.
smava GmbH ist eines der führenden Finanzdienstleistungsunternehmen in Deutschland, das Privatkredite für Verbraucher transparent, fair und erschwinglich macht. Auf Basis digitaler Prozesse vergleicht smava Kreditangebote von mehr als 20 Banken. Auf diese Weise können Kreditnehmer schnell, digitalisiert und effizient die für sie günstigsten Angebote auswählen.
smava glaubt an datengesteuerte Entscheidungen und nutzt diese, um Marktführer zu werden. Das Data Platform-Team ist für die Unterstützung datengesteuerter Entscheidungen bei smava verantwortlich, indem es Datenprodukte für alle Abteilungen und Niederlassungen des Unternehmens bereitstellt. Die Abteilungen umfassen Teams vom Engineering bis zum Vertrieb und Marketing. Die Filialen sind nach Produkten gegliedert, nämlich B2C-Kredite, B2B-Kredite und früher auch B2C-Hypotheken. Zu den im Unternehmen verwendeten Datenprodukten gehören unter anderem Erkenntnisse aus User Journeys, Betriebsberichten und Ergebnissen von Marketingkampagnen. Die Datenplattform bedient durchschnittlich 60 Abfragen pro Tag. Das Datenvolumen liegt im zweistelligen TB-Bereich und wächst stetig, da sich das Geschäft und die Datenquellen weiterentwickeln.
Das Datenplattform-Team von smava stand vor der Herausforderung, Daten an Stakeholder mit unterschiedlichen SLAs bereitzustellen und gleichzeitig die Flexibilität zur Skalierung nach oben und unten bei gleichzeitiger Kosteneffizienz zu wahren. Die Erstellung täglicher Berichte dauerte bis zu drei Stunden, was sich auf die Geschäftsentscheidung auswirkte, wenn im Laufe des Tages Neuberechnungen durchgeführt werden mussten. Um die Self-Service-Analyse zu beschleunigen und datenbasierte Innovationen zu fördern, wurde eine Lösung benötigt, die es jedem Team ermöglicht, Datenprodukte selbst und dezentral zu erstellen. Zur Erstellung und Verwaltung der Datenprodukte nutzt smava Amazon RedShift, ein Cloud-Data-Warehouse.
In diesem Beitrag zeigen wir, wie smava seine Datenplattform optimiert hat Amazon Redshift ohne Server und Amazon Redshift-Datenfreigabe um Herausforderungen bei der richtigen Dimensionierung für unvorhersehbare Arbeitslasten zu meistern und das Preis-Leistungs-Verhältnis weiter zu verbessern. Durch die Optimierungen erzielte smava bis zu 50 % Kosteneinsparungen und eine bis zu dreimal schnellere Berichtserstellung im Vergleich zur bisherigen Analytics-Infrastruktur.
Lösungsübersicht
Als datengesteuertes Unternehmen verlässt sich smava auf die AWS Cloud, um seine Analyse-Anwendungsfälle voranzutreiben. Um seinen Kunden die besten Angebote und das beste Benutzererlebnis zu bieten, folgt smava dem Moderne Datenarchitektur Prinzipien mit einem Data Lake als skalierbarem, dauerhaftem Datenspeicher und speziell entwickelten Datenspeichern für die analytische Verarbeitung und Datennutzung.
smava nimmt Daten aus verschiedenen externen und internen Datenquellen in eine Anlegestelle auf dem Data Lake auf Amazon Simple Storage-Service (Amazon S3). Um die Daten aufzunehmen, nutzt smava eine Reihe beliebter Kundendatenplattformen von Drittanbietern, ergänzt durch benutzerdefinierte Skripte.
Nachdem die Daten in Amazon S3 gelandet sind, verwendet smava die AWS-Kleber Datenkatalog und Crawler um die verfügbaren Daten automatisch zu katalogisieren, die Metadaten zu erfassen und eine Schnittstelle bereitzustellen, die die Abfrage aller Datenbestände ermöglicht.
Datenanalysten, die Zugriff auf die Rohressourcen im Data Lake benötigen Amazonas Athena, ein serverloser, interaktiver Analysedienst zur Erkundung mit Ad-hoc-Abfragen. Für die nachgelagerte Nutzung durch alle Abteilungen im gesamten Unternehmen bereitet das Datenplattform-Team von smava kuratierte Datenprodukte vor extrahieren, laden und transformieren (ELT)-Muster. smava nutzt Amazon Redshift als Cloud-Data-Warehouse, um Daten zu transformieren, zu speichern, zu analysieren und zu nutzen Amazon Redshift-Spektrum um strukturierte und halbstrukturierte Daten mithilfe von SQL effizient aus dem Data Lake abzufragen und abzurufen.
smava folgt dem Datentresormodellierung Methodik mit den Phasen Raw Vault, Business Vault und Data Mart, um die Datenprodukte für Endverbraucher vorzubereiten. Der Raw Vault beschreibt Objekte, die direkt aus den Datenquellen geladen werden, und stellt eine Kopie der Landeplattform im Data Lake dar. Der Business Vault wird mit Daten aus dem Raw Vault gefüllt und gemäß den Geschäftsregeln transformiert. Abschließend werden die Daten zu spezifischen Datenprodukten aggregiert, die auf einen bestimmten Geschäftsbereich ausgerichtet sind. Dies ist das Datenmarkt Bühne. Die Datenprodukte aus den Phasen Business Vault und Data Mart sind jetzt für Verbraucher verfügbar. smava entschied sich für den Einsatz von Tableau für Business Intelligence, Datenvisualisierung und weitere Analysen. Die Datentransformationen werden mit verwaltet dbt um die Workflow-Governance und Teamzusammenarbeit zu vereinfachen.
Das folgende Diagramm zeigt die High-Level-Datenplattformarchitektur vor den Optimierungen.
Entwicklung der Anforderungen an die Datenplattform
smava begann mit einem einzigen Redshift-Cluster, um alle drei Datenphasen zu hosten. Sie wählten bereitgestellte Clusterknoten der RA3-Typ mit Reservierte Instanzen (RIs) zur Kostenoptimierung. Da das Datenvolumen im Jahresvergleich um 53 % zunahm, stiegen auch die Komplexität und die Anforderungen verschiedener Analyse-Workloads.
smava reagierte schnell auf die wachsenden Datenmengen, indem es den Cluster richtig dimensionierte und nutzte Parallelitätsskalierung von Amazon Redshift für Spitzenbelastungen. Darüber hinaus wollte smava allen Teams die Möglichkeit geben, ihre eigenen Datenprodukte im Self-Service-Verfahren zu erstellen, um das Innovationstempo zu erhöhen. Um jegliche Beeinträchtigung der zentral verwalteten Datenprodukte zu vermeiden, mussten die dezentralen Produktentwicklungsumgebungen strikt isoliert werden. Die gleiche Anforderung galt auch für die Isolierung verschiedener Produktphasen, die vom Data Platform-Team kuratiert wurden.
Optimierung der Architektur mit Datenfreigabe und Redshift Serverless
Um den gewachsenen Anforderungen gerecht zu werden, entschied sich smava, die Arbeitslast zu trennen, indem der einzelne bereitgestellte Redshift-Cluster in mehrere Data Warehouses aufgeteilt wurde, wobei jedes Warehouse eine andere Phase bedient. Darüber hinaus hat smava neue Staging-Umgebungen im Business Vault hinzugefügt, um neue Datenprodukte zu entwickeln, ohne das Risiko einer Beeinträchtigung bestehender Produktpipelines einzugehen. Um jegliche Beeinträchtigung der zentral verwalteten Datenprodukte des Data Platform-Teams zu vermeiden, hat smava einen zusätzlichen Redshift-Cluster eingeführt, der die dezentralen Workloads isoliert.
smava war auf der Suche nach einer sofort einsatzbereiten Lösung, um eine Workload-Isolierung zu erreichen, ohne eine komplexe Datenreplikationspipeline verwalten zu müssen.
Gleich nach dem Start von Redshift-Datenaustausch Aufgrund seiner Leistungsfähigkeit im Jahr 2021 erkannte das Data Platform-Team, dass dies die Lösung war, nach der es gesucht hatte. smava hat die Datenfreigabefunktion übernommen, um die Daten von Produzenten-Clustern für den Lesezugriff auf verschiedene Konsumenten-Cluster verfügbar zu machen, wobei jeder dieser Konsumenten-Cluster eine andere Stufe bedient.
Die gemeinsame Nutzung von Redshift-Daten ermöglicht den sofortigen, granularen und schnellen Datenzugriff über Redshift-Cluster hinweg, ohne dass Daten kopiert werden müssen. Es bietet Live-Zugriff auf Daten, sodass Benutzer bei der Aktualisierung im Data Warehouse immer die aktuellsten und konsistentesten Informationen sehen. Mit der Datenfreigabe können Sie Live-Daten sicher mit Redshift-Clustern im gleichen oder in verschiedenen AWS-Konten und über Regionen hinweg teilen.
Mit der Redshift-Datenfreigabe konnte smava die Datenarchitektur optimieren, indem die Daten-Workloads auf einzelne Verbrauchercluster aufgeteilt wurden, ohne dass die Daten repliziert werden mussten. Das folgende Diagramm veranschaulicht die übergeordnete Datenplattformarchitektur nach der Aufteilung des einzelnen Redshift-Clusters in mehrere Cluster.
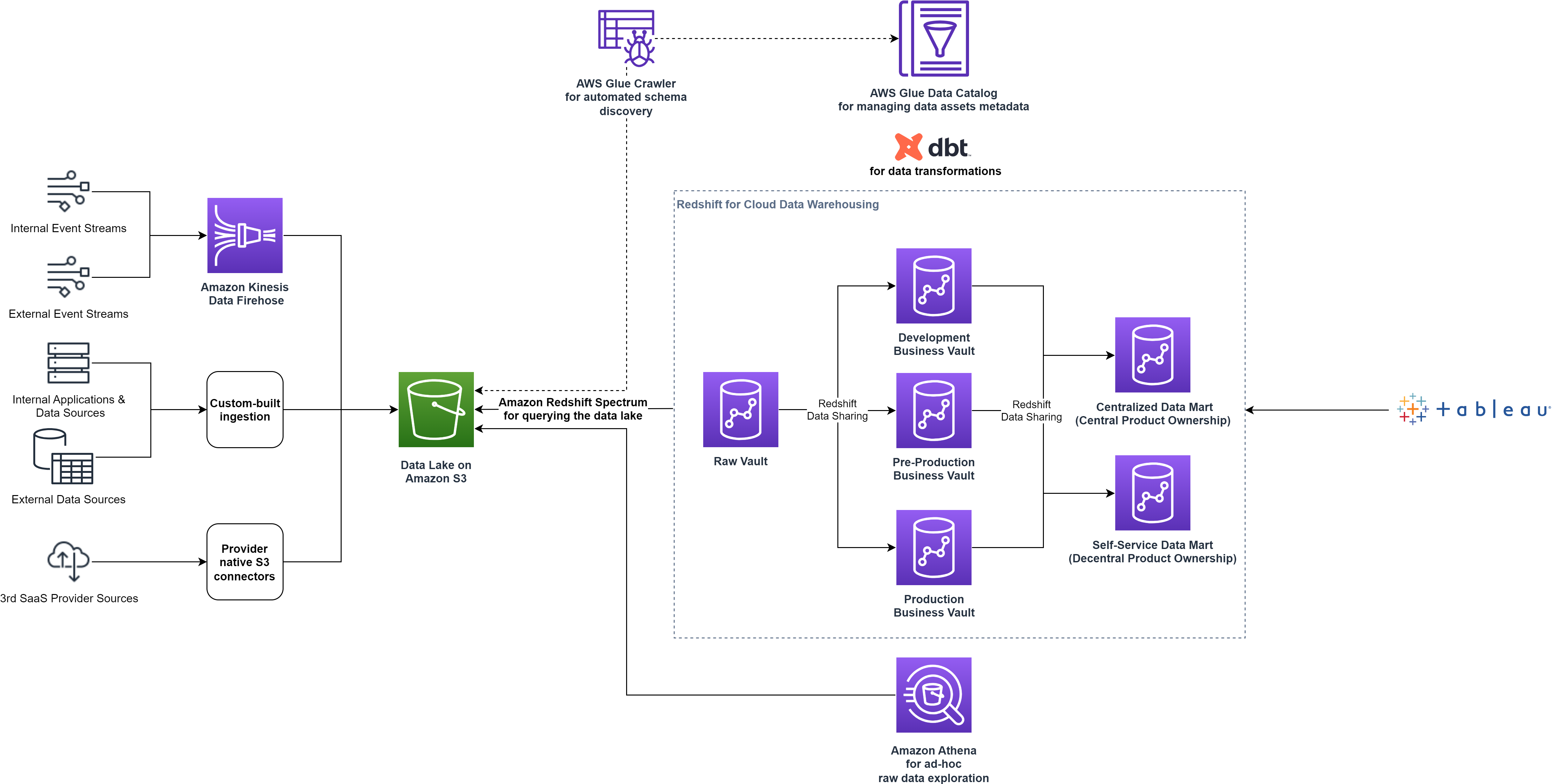
Durch die Bereitstellung eines Self-Service-Data-Marts steigerte smava die Datendemokratisierung, indem es Benutzern Zugriff auf alle Aspekte der Daten ermöglichte. Sie stellten den Teams außerdem eine Reihe benutzerdefinierter Tools für die Datenermittlung, Ad-hoc-Analyse, Prototyping und den Betrieb des gesamten Lebenszyklus ausgereifter Datenprodukte zur Verfügung.
Nach der Erfassung der Betriebsdaten der einzelnen Cluster identifizierte das Data Platform-Team weitere Optimierungsmöglichkeiten: Der Raw Vault-Cluster stand rund um die Uhr unter konstanter Auslastung, die Business Vault-Cluster wurden jedoch nur jede Nacht aktualisiert. Zur Kostenoptimierung nutzte smava die Funktionen zum Anhalten und Fortsetzen der von Redshift bereitgestellten Cluster. Diese Funktionen sind nützlich für Cluster, die zu bestimmten Zeiten verfügbar sein müssen. Während der Cluster pausiert ist, wird die On-Demand-Abrechnung ausgesetzt. Nur für den Speicher des Clusters fallen Gebühren an.
Die Funktion zum Anhalten und Fortsetzen half smava bei der Kostenoptimierung, erforderte jedoch zusätzlichen Betriebsaufwand, um die Cluster-Vorgänge auszulösen. Darüber hinaus kam es in den Entwicklungsclustern weiterhin zu Leerlaufzeiten während der Arbeitszeit. Diese Herausforderungen wurden schließlich durch die Einführung von Redshift Serverless im Jahr 2022 gelöst. Das Data Platform-Team beschloss, die Business Data Vault-Stufencluster auf Redshift Serverless zu verlagern, was es ihnen ermöglicht, für das Data Warehouse nur dann zu bezahlen, wenn es zuverlässig und effizient genutzt wird.
Redshift Serverless ist ideal für Fälle, in denen es schwierig ist, den Rechenbedarf vorherzusagen, wie z. B. variable Arbeitslasten, periodische Arbeitslasten mit Leerlaufzeiten und stationäre Arbeitslasten mit Spitzen. Wenn sich der Nutzungsbedarf mit neuen Arbeitslasten und mehr gleichzeitigen Benutzern entwickelt, stellt Redshift Serverless außerdem automatisch die richtigen Rechenressourcen bereit und das Data Warehouse skaliert nahtlos und automatisch, ohne dass manuelle Eingriffe erforderlich sind. Der Datenaustausch zwischen Redshift Serverless und bereitgestellten Redshift-Clustern mit RA3-Knoten wird in beide Richtungen unterstützt, sodass keine Änderungen an der Smava-Architektur erforderlich waren. Das folgende Diagramm zeigt den Aufbau der High-Level-Architektur nach der Umstellung auf Redshift Serverless.
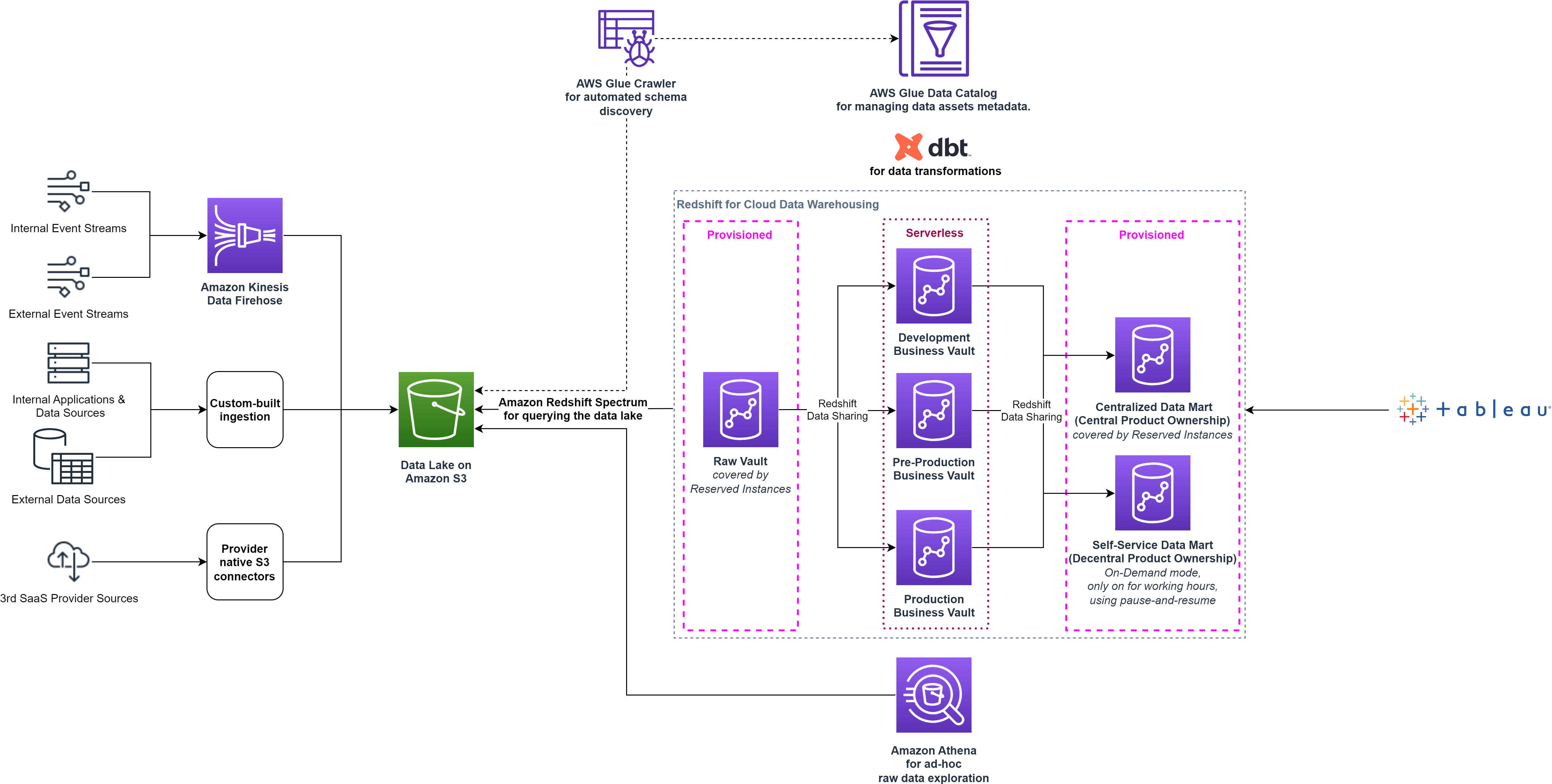
smava kombinierte die Vorteile von Redshift Serverless und dbt durch eine nahtlose CI/CD-Pipeline und übernahm eine Trunk-basierte Entwicklungsmethodik. Änderungen am Git-Repository werden automatisch in einer Testphase bereitgestellt und mithilfe automatisierter Integrationstests validiert. Dieser Ansatz steigerte die Effizienz der Entwickler und verkürzte die durchschnittliche Zeit bis zur Produktion von Tagen auf Minuten.
smava hat eine Architektur eingeführt, die sowohl bereitgestellte als auch serverlose Redshift-Data-Warehouses nutzt, zusammen mit der Datenfreigabefunktion zur Isolierung der Arbeitslasten. Durch die Auswahl der richtigen Architekturmuster für ihre Bedürfnisse konnte smava Folgendes erreichen:
- Vereinfachen Sie die Datenpipelines und reduzieren Sie den Betriebsaufwand
- Reduzieren Sie die Zeit für die Veröffentlichung von Funktionen von Tagen auf Minuten
- Steigern Sie das Preis-Leistungs-Verhältnis, indem Sie Leerlaufzeiten reduzieren und die Arbeitslast richtig dimensionieren
- Erreichen Sie eine bis zu dreimal schnellere Berichtserstellung (schnellere Berechnungen und höhere Parallelisierung) bei 50 % der ursprünglichen Einrichtungskosten
- Erhöhen Sie die Agilität aller Abteilungen und unterstützen Sie die datengesteuerte Entscheidungsfindung durch die Demokratisierung des Datenzugriffs
- Erhöhen Sie die Innovationsgeschwindigkeit, indem Sie Self-Service-Datenfunktionen für Teams in allen Abteilungen bereitstellen und die A/B-Testfunktionen stärken, um die gesamte Customer Journey abzudecken
Mittlerweile nutzen alle Abteilungen bei smava die verfügbaren Datenprodukte, um datengesteuerte, genaue und agile Entscheidungen zu treffen.
Zukunftsvision
Für die Zukunft plant smava, die Datenplattform basierend auf betrieblichen Kennzahlen weiter zu optimieren. Sie erwägen, stärker bereitgestellte Cluster wie den Self-Service Data Mart-Cluster auf serverlose Cluster umzustellen. Darüber hinaus optimiert smava die ELT-Orchestrierungs-Toolchain, um die Anzahl der parallel auszuführenden Datenpipelines zu erhöhen. Dadurch wird die Nutzung der bereitgestellten Redshift-Ressourcen erhöht und Kostensenkungen ermöglicht.
Mit der Einführung des dezentralen Self-Service zur Datenprodukterstellung hat smava einen Schritt in Richtung a gemacht Datenmaschenarchitektur. In Zukunft plant das Data Platform-Team, die Bedürfnisse seiner Servicenutzer weiter zu bewerten und weitere Data-Mesh-Prinzipien wie die föderierte Datenverwaltung zu etablieren.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie smava seine Datenplattform durch die Isolierung von Umgebungen und Arbeitslasten mithilfe von Redshift Serverless und Datenfreigabefunktionen optimiert hat. Diese Redshift-Umgebungen sind gut in ihre Infrastruktur integriert, flexibel bei Bedarf skalierbar, hochverfügbar und erfordern nur minimalen Verwaltungsaufwand. Insgesamt hat smava die Leistung um das Dreifache gesteigert und gleichzeitig die Gesamtkosten der Plattform um 50 % gesenkt. Darüber hinaus wurde der Betriebsaufwand auf ein Minimum reduziert und gleichzeitig die bestehenden SLAs für die Berichtserstellungszeiten beibehalten. Darüber hinaus hat smava die Innovationskultur durch die Bereitstellung von Self-Service-Funktionen für Datenprodukte gestärkt, um die Markteinführungszeit zu verkürzen.
Wenn Sie mehr über die Funktionen von Amazon Redshift erfahren möchten, empfehlen wir Ihnen, sich die neueste Version anzusehen Was ist neu bei der Amazon Redshift-Sitzung im AWS Events-Kanal? um einen Überblick über die kürzlich zum Dienst hinzugefügten Funktionen zu erhalten. Sie können auch die erkunden Self-Service-, praktische Amazon-Redshift-Labore um auf geführte Weise mit den wichtigsten Funktionen von Amazon Redshift zu experimentieren.
Sie können auch tiefer eintauchen Serverlose Redshift-Anwendungsfälle und Anwendungsfälle für den Datenaustausch. Schauen Sie sich außerdem die an Best Practices für den Datenaustausch und entdecken wie andere Kunden optimieren Kosten und Leistung mit Redshift-Datenaustausch um sich für Ihr eigenes Arbeitspensum inspirieren zu lassen.
Wenn Sie Bücher bevorzugen, schauen Sie vorbei Amazon Redshift: The Definitive Guide von O’Reilly, in dem die Autoren die Funktionen von Amazon Redshift detailliert beschreiben und Ihnen Einblicke in entsprechende Muster und Techniken geben.
Über die Autoren
 Alex Naumow ist Principal Data Architect bei der smava GmbH und leitet die Transformationsprojekte in der Datenabteilung. Zuvor arbeitete Alex 10 Jahre lang als Berater und Daten-/Lösungsarchitekt in einer Vielzahl von Bereichen wie Telekommunikation, Bankwesen, Energie und Finanzen, wobei er verschiedene Tech-Stacks und in vielen verschiedenen Ländern nutzte. Er hat eine große Leidenschaft für Daten und die Transformation von Organisationen, um datengesteuert zu werden und in dem, was sie tun, die Besten zu sein.
Alex Naumow ist Principal Data Architect bei der smava GmbH und leitet die Transformationsprojekte in der Datenabteilung. Zuvor arbeitete Alex 10 Jahre lang als Berater und Daten-/Lösungsarchitekt in einer Vielzahl von Bereichen wie Telekommunikation, Bankwesen, Energie und Finanzen, wobei er verschiedene Tech-Stacks und in vielen verschiedenen Ländern nutzte. Er hat eine große Leidenschaft für Daten und die Transformation von Organisationen, um datengesteuert zu werden und in dem, was sie tun, die Besten zu sein.
 Lingli Zheng arbeitet als Business Development Manager in der weltweiten Spezialorganisation AWS und unterstützt Kunden in der DACH-Region dabei, den größtmöglichen Nutzen aus den Analysediensten von Amazon zu ziehen. Mit über 12 Jahren Erfahrung in den Bereichen Energie, Automatisierung und Softwareindustrie mit Schwerpunkt auf Datenanalyse, KI und ML engagiert sie sich dafür, Kunden dabei zu helfen, durch digitale Transformation greifbare Geschäftsergebnisse zu erzielen.
Lingli Zheng arbeitet als Business Development Manager in der weltweiten Spezialorganisation AWS und unterstützt Kunden in der DACH-Region dabei, den größtmöglichen Nutzen aus den Analysediensten von Amazon zu ziehen. Mit über 12 Jahren Erfahrung in den Bereichen Energie, Automatisierung und Softwareindustrie mit Schwerpunkt auf Datenanalyse, KI und ML engagiert sie sich dafür, Kunden dabei zu helfen, durch digitale Transformation greifbare Geschäftsergebnisse zu erzielen.
 Alexander Spivak ist Senior Startup Solutions Architect bei AWS und konzentriert sich auf B2B-ISV-Kunden in der gesamten EMEA-Region Nord. Vor AWS arbeitete Alexander als Berater im Finanzdienstleistungsbereich, einschließlich verschiedener Rollen in der Softwareentwicklung und -architektur. Seine Leidenschaft gilt der Datenanalyse, serverlosen Architekturen und dem Aufbau effizienter Organisationen.
Alexander Spivak ist Senior Startup Solutions Architect bei AWS und konzentriert sich auf B2B-ISV-Kunden in der gesamten EMEA-Region Nord. Vor AWS arbeitete Alexander als Berater im Finanzdienstleistungsbereich, einschließlich verschiedener Rollen in der Softwareentwicklung und -architektur. Seine Leidenschaft gilt der Datenanalyse, serverlosen Architekturen und dem Aufbau effizienter Organisationen.
Dieser Beitrag wurde von David Greenshtein, Senior Analytics Solutions Architect, auf technische Richtigkeit überprüft.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/how-smava-makes-loans-transparent-and-affordable-using-amazon-redshift-serverless/
- :hast
- :Ist
- :Wo
- $UP
- 10
- 100
- 12
- 125
- 20
- 2021
- 2022
- 60
- a
- Fähig
- Über Uns
- Zugang
- Zugriff auf Daten
- erreichen
- Nach
- Trading Konten
- Genauigkeit
- genau
- Erreichen
- erreicht
- über
- Ad
- hinzugefügt
- Zusatz
- Zusätzliche
- zusätzlich
- angesprochen
- Verwaltung
- angenommen
- Die Annahme
- Vorteil
- Ranking
- Nach der
- agil
- AI
- alex
- Udo
- Alle
- erlauben
- erlaubt
- ebenfalls
- immer
- Amazon
- Amazon Web Services
- unter
- an
- Analyse
- Business Analysten
- Analytisch
- Analytische
- Analytik
- analysieren
- und
- jedem
- angewandt
- Ansatz
- architektonisch
- Architektur
- SIND
- AS
- Aspekte
- Details
- At
- Autor
- Autoren
- Automatisiert
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Automation
- verfügbar
- durchschnittlich
- vermeiden
- AWS
- B2B
- B2C
- Bankinggg
- Banken
- basierend
- BE
- werden
- war
- Bevor
- glaubt,
- Vorteile
- BESTE
- zwischen
- Rechnungs-
- Blog
- Bücher
- Kreditnehmer
- beide
- Geäst
- bringen
- Geschäft
- Geschäftsentwicklung
- Business Intelligence
- aber
- by
- Kampagnen (Campaign)
- CAN
- Fähigkeiten
- capability
- Erfassung
- Fälle
- Katalog
- challenges
- Herausforderungen
- Änderungen
- Gebühren
- aus der Ferne überprüfen
- Auswählen
- Auswahl
- wählten
- Cloud
- Cluster
- Zusammenarbeit
- Das Sammeln
- kombiniert
- Unternehmen
- Unternehmen
- verglichen
- abschließen
- Komplex
- Komplexität
- Berechnen
- Wettbewerber
- Berücksichtigung
- konsistent
- Berater
- Verbraucher
- KUNDEN
- Verbrauch
- fortsetzen
- Dazugehörigen
- Kosten
- Einsparmaßnahmen
- Kosten
- Ländern
- Abdeckung
- erstellen
- Erstellen
- Schaffung
- KULTUR
- kuratiert
- Original
- Kunde
- Kundendaten
- Kunden
- Unterricht
- technische Daten
- Datenzugriff
- Datenanalyse
- Datensee
- Datenplattform
- Datenübertragung
- Datenvisualisierung
- Data Warehouse
- Data Warehouse
- datengesteuerte
- Christian
- Tag
- Tage
- Angebote
- dezentralisiert
- entschieden
- Decision Making
- Entscheidungen
- verringert
- gewidmet
- tiefer
- definitiv
- Übergeben
- Demand
- Demokratisierung
- Demokratisierung
- Abteilung
- Abteilungen
- Einsatz
- Detail
- entwickeln
- Entwickler
- Entwicklung
- DID
- anders
- schwer
- digital
- Digitale Transformation
- Richtungen
- Direkt
- entdeckt,
- Entdeckung
- tauchen
- do
- Domains
- nach unten
- im
- jeder
- Effizienz
- effizient
- effizient
- Bemühungen
- EMEA
- ermöglicht
- Ende
- Energie
- Engagements
- Entwicklung
- Umgebungen
- etablieren
- Äther (ETH)
- bewerten
- Veranstaltungen
- entwickelt sich
- entwickelt
- entwickelt sich
- vorhandenen
- ERFAHRUNGEN
- Experiment
- Exploration
- ERKUNDEN
- extern
- konfrontiert
- Messe
- FAST
- beschleunigt
- günstig
- Merkmal
- Eigenschaften
- Endlich
- Finanzen
- Revolution
- Finanzdienstleistungen
- Flexibilität
- flexibel
- Setzen Sie mit Achtsamkeit
- Fokussierung
- Folgende
- folgt
- Aussichten für
- Für Verbraucher
- früher
- vorwärts
- Fördern
- für
- voller
- Funktionsumfang
- weiter
- Außerdem
- Zukunft
- erzeugen
- Generation
- Deutschland
- bekommen
- Git
- ABSICHT
- GmbH
- Governance
- groß
- wuchs
- persönlichem Wachstum
- Wachstum
- GUEST
- Guest Post
- Guide
- geführt
- hätten
- praktische
- passieren
- Haben
- mit
- he
- dazu beigetragen,
- Unternehmen
- High-Level
- höher
- hoch
- Gastgeber
- STUNDEN
- Ultraschall
- HTML
- HTTPS
- ideal
- identifiziert
- Leerlauf
- zeigt
- wirkt
- zu unterstützen,
- in
- das
- Einschließlich
- Erhöhung
- hat
- Krankengymnastik
- Energiegewinnung
- Information
- Infrastruktur
- Innovation
- innerhalb
- Einblicke
- inspirierte
- Instanzen
- sofortig
- integriert
- Integration
- Intelligenz
- interaktive
- interessiert
- Schnittstelle
- Einmischung
- störende
- intern
- Intervention
- in
- eingeführt
- Einführung
- Einleitung
- isoliert
- Isolierung
- Isv
- IT
- Reisen
- Wesentliche
- See
- Landung
- landet
- starten
- Führer
- führenden
- umwandeln
- lernen
- Lebenszyklus
- Gefällt mir
- Line
- leben
- Lebensdaten
- Belastung
- Darlehen
- Kredite
- suchen
- gemacht
- Aufrechterhaltung
- um
- MACHT
- Making
- verwalten
- verwaltet
- Manager
- flächendeckende Gesundheitsprogramme
- Weise
- manuell
- viele
- Markt
- Marktführer
- Marketing
- reifen
- Triff
- ineinander greifen
- Metadaten
- Methodik
- Metrik
- Minimum
- Minuten
- ML
- mehr
- Zudem zeigt
- Hypotheken
- vor allem warme
- schlauer bewegen
- mehrere
- nämlich
- Need
- erforderlich
- Bedürfnisse
- Neu
- nicht
- Fiber Node
- Norden
- jetzt an
- Anzahl
- Objekte
- of
- Angebote
- on
- On-Demand
- EINEM
- einzige
- die
- Betriebs-
- Einkauf & Prozesse
- Optimierung
- Optimieren
- optimiert
- Optimierung
- Option
- or
- Orchesterbearbeitung
- Auftrag
- Organisation
- Organisationen
- Original
- Andere
- Anders
- übrig
- Gesamt-
- Überwinden
- Überblick
- besitzen
- Frieden
- Parallel
- Leidenschaft & KREATIVITÄT
- leidenschaftlich
- Schnittmuster
- Muster
- Pause
- pausiert
- AUFMERKSAMKEIT
- Haupt
- für
- Leistung
- periodisch
- persönliche
- Gesicherter Privatkredit
- Pipeline
- Pläne
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Beliebt
- besiedelt
- Post
- Potenzial
- Werkzeuge
- vorhersagen
- bevorzugen
- Danach
- Bereitet sich vor
- früher
- vorher
- Principal
- Grundsätze
- Vor
- anpassen
- Verarbeitung
- Hersteller
- Produkt
- Produktentwicklung
- Produktion
- Produkte
- Projekte
- Prototyping
- die
- vorausgesetzt
- bietet
- Bereitstellung
- Abfragen
- schnell
- Angebot
- Roh
- Lesen Sie mehr
- kürzlich
- kürzlich
- anerkannt
- empfehlen
- Veteran
- Reduziert
- Reduzierung
- Ermäßigungen
- Region
- Regionen
- Release
- blieb
- Replikation
- berichten
- Reporting
- Meldungen
- Quelle
- representiert
- erfordern
- falls angefordert
- Anforderung
- Voraussetzungen:
- Downloads
- für ihren Verlust verantwortlich.
- Die Ergebnisse
- fortsetzen
- bewertet
- Recht
- Risiko
- Rollen
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Führen Sie
- Vertrieb
- Vertrieb und Marketing
- gleich
- Ersparnisse
- skalierbaren
- Skalieren
- Waage
- Skalierung
- Skripte
- nahtlos
- nahtlos
- sicher
- sehen
- Selbstbedienung
- Senior
- getrennte
- Trennung
- Serverlos
- dient
- Lösungen
- Dienst
- Sitzung
- kompensieren
- Setup
- Teilen
- ,,teilen"
- sie
- erklären
- zeigte
- Konzerte
- Einfacher
- vereinfachen
- Single
- So
- Software
- Software-Entwicklung
- Lösung
- Lösungen
- gelöst
- bezogen
- Quellen
- Spezialist
- spezifisch
- Geschwindigkeit
- Spikes
- SQL
- Stacks
- Stufe
- Stufen
- Aufführung
- Stakeholder
- begonnen
- Anfang
- bleiben
- stetig
- Schritt
- Lagerung
- speichern
- Läden
- gestärkt
- Stärkung
- strukturierte
- Fach
- so
- Support
- Unterstützte
- Unterstützung
- suspendiert
- Tableau
- nimmt
- greifbar
- Team
- Teams
- Tech
- Technische
- Techniken
- Telekommunikation
- Test
- Tests
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- ihr
- Sie
- Diese
- vom Nutzer definierten
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- fehlen uns die Worte.
- diejenigen
- tausend
- nach drei
- Durch
- Zeit
- mal
- zu
- gemeinsam
- nahm
- Werkzeuge
- Gesamt
- gegenüber
- Transformieren
- Transformation
- Transformationen
- verwandelt
- Transformieren
- transparent
- auslösen
- für
- unberechenbar
- auf dem neusten Stand
- aktualisiert
- Anwendungsbereich
- -
- benutzt
- Mitglied
- Benutzererfahrung
- Nutzer
- verwendet
- Verwendung von
- die
- validiert
- Wert
- Variable
- Vielfalt
- verschiedene
- Gewölbe
- Visualisierung
- Volumen
- Volumen
- wollte
- Warehouse
- wurde
- beobachten
- Weg..
- Wege
- we
- Netz
- Web-Services
- GUT
- waren
- Was
- wann
- welche
- während
- WHO
- breit
- Wikipedia
- werden wir
- mit
- ohne
- gearbeitet
- Arbeitsablauf.
- arbeiten,
- Arbeitsstunden
- Werk
- Workshops
- Das weltweit
- Jahr
- Jahr
- U
- Ihr
- Youtube
- Zephyrnet