Einleitung
In der sich schnell entwickelnden Landschaft der generativen KI wird die zentrale Rolle von Vektordatenbanken immer deutlicher. Dieser Artikel befasst sich mit der dynamischen Synergie zwischen Vektordatenbanken und generativen KI-Lösungen und untersucht, wie diese technologischen Grundlagen die Zukunft der Kreativität im Bereich der künstlichen Intelligenz prägen. Begleiten Sie uns auf einer Reise durch die Feinheiten dieser leistungsstarken Allianz und gewinnen Sie Einblicke in die transformative Wirkung, die Vektordatenbanken auf die Spitze innovativer KI-Lösungen haben.
Lernziele
Dieser Artikel hilft Ihnen, die folgenden Aspekte der Vektordatenbank zu verstehen.
- Bedeutung von Vektordatenbanken und ihren Schlüsselkomponenten
- Detaillierte Untersuchung des Vergleichs der Vektordatenbank mit der traditionellen Datenbank
- Untersuchung von Vektoreinbettungen aus Anwendungssicht
- Aufbau einer Vektordatenbank mit Pincone
- Implementierung der Pinecone Vector-Datenbank mithilfe des Langchain-LLM-Modells
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
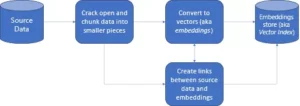
Was ist eine Vektordatenbank?
Eine Vektordatenbank ist eine im Weltraum gespeicherte Form der Datensammlung. Dennoch wird es hier in mathematischen Darstellungen gespeichert, da das in den Datenbanken gespeicherte Format es offenen KI-Modellen erleichtert, sich die Eingaben zu merken, und es unserer offenen KI-Anwendung ermöglicht, kognitive Suche, Empfehlungen und Textgenerierung für verschiedene Anwendungsfälle zu verwenden die digital transformierten Industrien. Das Speichern und Abrufen von Daten wird als „Vektor-Einbettungen“ oder „Einbettungen“ bezeichnet. Darüber hinaus wird dies in einem numerischen Array-Format dargestellt. Die Suche ist viel einfacher als bei herkömmlichen Datenbanken, die für KI-Perspektiven mit umfangreichen indizierten Funktionen verwendet werden.
Eigenschaften von Vektordatenbanken
- Es nutzt die Leistungsfähigkeit dieser Vektoreinbettungen und ermöglicht die Indizierung und Suche in einem riesigen Datensatz.
- Komprimierbar mit allen Datenformaten (Bilder, Text oder Daten).
- Da es Einbettungstechniken und hochgradig indizierte Funktionen anpasst, kann es eine vollständige Lösung für die Verwaltung von Daten und Eingaben für das gegebene Problem bieten.
- Eine Vektordatenbank organisiert Daten anhand hochdimensionaler Vektoren mit Hunderten von Dimensionen. Wir können sie sehr schnell konfigurieren.
- Jede Dimension entspricht einem bestimmten Merkmal oder einer bestimmten Eigenschaft des Datenobjekts, das sie darstellt.
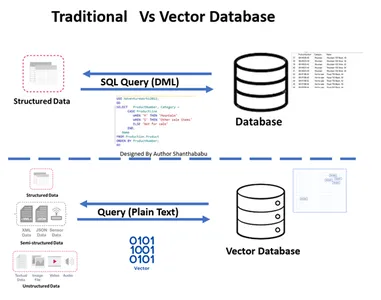
Traditionell vs. Vektordatenbank
- Das Bild zeigt den herkömmlichen und Vektordatenbank-Workflow auf hoher Ebene
- Formale Datenbankinteraktionen erfolgen durch SQL Anweisungen und Daten, die im zeilenbasierten und tabellarischen Format gespeichert sind.
- In der Vector-Datenbank erfolgen Interaktionen über Klartext (z. B. Englisch) und in mathematischen Darstellungen gespeicherte Daten.
Ähnlichkeit traditioneller Datenbanken und Vektordatenbanken
Wir müssen berücksichtigen, wie sich Vektordatenbanken von herkömmlichen unterscheiden. Lassen Sie uns das hier besprechen. Ein kurzer Unterschied, den ich nennen kann, ist der in herkömmlichen Datenbanken. Die Daten werden genau so gespeichert, wie sie sind. Wir könnten Geschäftslogik hinzufügen, um die Daten abzustimmen und die Daten basierend auf den Geschäftsanforderungen oder -anforderungen zusammenzuführen oder aufzuteilen. Die Vektordatenbank unterliegt jedoch einer massiven Transformation und die Daten werden zu einer komplexen Vektordarstellung.
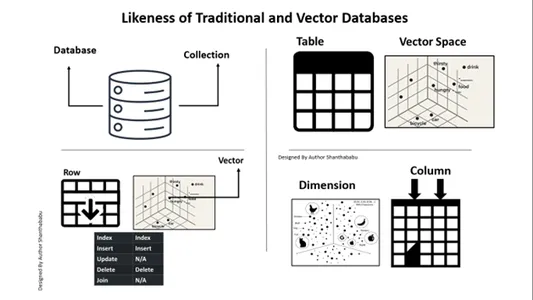
Hier ist eine Karte für Ihr Verständnis und Ihre klare Perspektive relationale Datenbanken gegen Vektordatenbanken. Das Bild unten ist selbsterklärend, um Vektordatenbanken im Vergleich zu herkömmlichen Datenbanken zu verstehen. Kurz gesagt, wir können Einfügungen und Löschungen in Vektordatenbanken ausführen, keine Update-Anweisungen.
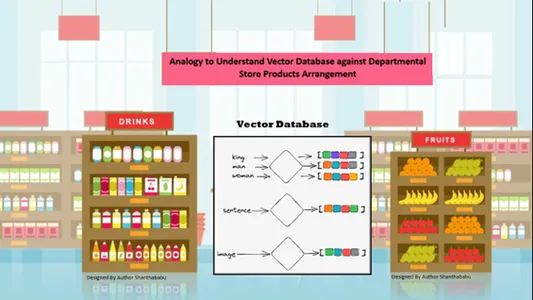
Einfache Analogie zum Verständnis von Vektordatenbanken
Die Daten werden anhand der inhaltlichen Ähnlichkeit der gespeicherten Informationen automatisch räumlich angeordnet. Betrachten wir also die Analogie zum Kaufhaus für Vektordatenbanken. Alle Produkte werden im Regal nach Art, Zweck, Herstellung, Verwendung und Menge sortiert. In einem ähnlichen Verhalten sind die Daten
automatisch nach einer ähnlichen Sortierung in der Vektordatenbank angeordnet, auch wenn das Genre beim Speichern oder Zugreifen auf die Daten nicht genau definiert wurde.
Die Vektordatenbanken ermöglichen eine ausgeprägte Granularität und Dimensionierung der spezifischen Ähnlichkeiten, sodass der Kunde nach dem gewünschten Produkt, Hersteller und der gewünschten Menge sucht und den Artikel im Warenkorb behält. Die Vector-Datenbank speichert alle Daten in einer perfekten Speicherstruktur; Hier müssen Ingenieure für maschinelles Lernen und KI die gespeicherten Inhalte nicht manuell kennzeichnen oder mit Tags versehen.
Grundlegende Theorien hinter Vektordatenbanken
- Vektoreinbettungen und ihr Umfang
- Indexierungsanforderungen
- Semantische Suche und Ähnlichkeitssuche verstehen
Vektoreinbettung und ihr Umfang
Eine Vektoreinbettung ist eine Vektordarstellung anhand der numerischen Werte. In einem komprimierten Format erfassen Einbettungen die inhärenten Eigenschaften und Zusammenhänge der Originaldaten und machen sie zu einem festen Bestandteil in Anwendungsfällen für künstliche Intelligenz und maschinelles Lernen. Das Entwerfen von Einbettungen zur Codierung relevanter Informationen über die Originaldaten in einen niedrigerdimensionalen Raum gewährleistet eine hohe Abrufgeschwindigkeit, Recheneffizienz und effiziente Speicherung.
Das Erfassen des Wesens von Daten auf eine identischer strukturierte Weise ist der Prozess der Vektoreinbettung, wodurch ein „Einbettungsmodell“ entsteht. Letztendlich berücksichtigen diese Modelle alle Datenobjekte, extrahieren sinnvolle Muster und Beziehungen innerhalb der Datenquelle und wandeln sie in Vektoreinbettungen um. Anschließend nutzen Algorithmen diese Vektoreinbettungen, um verschiedene Aufgaben auszuführen. Zahlreiche hochentwickelte Einbettungsmodelle, die online kostenlos oder nutzungsabhängig verfügbar sind, erleichtern die Durchführung der Vektoreinbettung.
Umfang der Vektoreinbettungen aus Anwendungssicht
Diese Einbettungen sind kompakt, enthalten komplexe Informationen, erben Beziehungen zwischen den in einer Vektordatenbank gespeicherten Daten, ermöglichen eine effiziente Datenverarbeitungsanalyse, um das Verständnis und die Entscheidungsfindung zu erleichtern, und erstellen dynamisch verschiedene innovative Datenprodukte in jeder Organisation.
Vektoreinbettungstechniken sind von wesentlicher Bedeutung, um die Lücke zwischen lesbaren Daten und komplexen Algorithmen zu schließen. Da es sich bei den Datentypen um numerische Vektoren handelt, konnten wir das Potenzial für eine Vielzahl generativer KI-Anwendungen zusammen mit verfügbaren offenen KI-Modellen erschließen.
Mehrere Jobs mit Vektoreinbettung
Diese Vektoreinbettung hilft uns bei der Erledigung mehrerer Aufgaben:
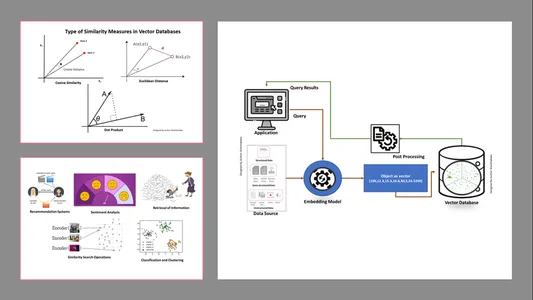
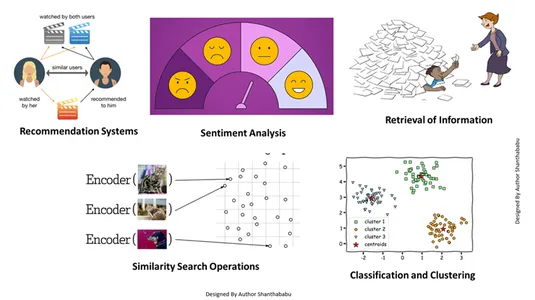
- Informationsabruf: Mit Hilfe dieser leistungsstarken Techniken können wir einflussreiche Suchmaschinen aufbauen, die uns dabei helfen können, Antworten auf der Grundlage von Benutzeranfragen aus gespeicherten Dateien, Dokumenten oder Medien zu finden
- Ähnlichkeitssuchoperationen: Dies ist gut organisiert und indexiert; Es hilft uns, die Ähnlichkeit zwischen verschiedenen Vorkommen in den Vektordaten zu finden.
- Klassifizierung und Clustering: Mithilfe dieser Einbettungstechniken können wir diese Modelle ausführen, um relevante Algorithmen für maschinelles Lernen zu trainieren und sie zu gruppieren und zu klassifizieren.
- Empfehlungssysteme: Da die Einbettungstechniken richtig organisiert sind, führt dies zu Empfehlungssystemen, die Produkte, Medien und Artikel auf der Grundlage historischer Daten genau in Beziehung setzen.
- Stimmungsanalyse: Dieses Einbettungsmodell hilft uns, Sentiment-Lösungen zu kategorisieren und abzuleiten.
Indexierungsanforderungen
Wie wir wissen, verbessert der Index die Suchdaten aus der Tabelle in herkömmlichen Datenbanken, ähnlich wie bei Vektordatenbanken, und stellt die Indexierungsfunktionen bereit.
Vektordatenbanken stellen „Flachindizes“ bereit, die die direkte Darstellung der Vektoreinbettung darstellen. Die Suchfunktion ist umfassend und es werden keine vorab trainierten Cluster verwendet. Es führt eine Vektorabfrage über die Einbettung jedes einzelnen Vektors durch und berechnet K-Abstände für jedes Paar.
- Aufgrund der Einfachheit dieses Index ist nur ein minimaler Rechenaufwand erforderlich, um die neuen Indizes zu erstellen.
- Tatsächlich kann ein flacher Index Abfragen effektiv verarbeiten und kurze Abrufzeiten ermöglichen.
Semantische Suche und Ähnlichkeitssuche verstehen
Wir führen zwei verschiedene Suchen in Vektordatenbanken durch: semantische und Ähnlichkeitssuchen.
- Semantische Suche: Bei der Suche nach Informationen können Sie diese anhand sinnvoller Konversationsmethoden finden, statt nach Schlüsselwörtern zu suchen. Bei der Weiterleitung der Eingaben an das System spielt eine zeitnahe Technik eine entscheidende Rolle. Diese Suche ermöglicht zweifellos eine qualitativ hochwertigere Suche und Ergebnisse, die für innovative Anwendungen, SEO, Textgenerierung und Zusammenfassungen genutzt werden können.
- Ähnlichkeitssuche: Immer in der Datenanalyse ermöglicht die Ähnlichkeitssuche unstrukturierte, viel besser gegebene Datensätze. Bei Vektordatenbanken müssen wir die Nähe zweier Vektoren und ihre Ähnlichkeit zueinander ermitteln: Tabellen, Text, Dokumente, Bilder, Wörter und Audiodateien. Im Prozess des Verstehens wird die Ähnlichkeit zwischen Vektoren als Ähnlichkeit zwischen den Datenobjekten im gegebenen Datensatz offenbart. Diese Übung hilft uns, Interaktionen zu verstehen, Muster zu erkennen, Erkenntnisse zu gewinnen und Entscheidungen aus Anwendungsperspektive zu treffen. Die Semantik- und Ähnlichkeitssuche würde uns dabei helfen, die folgenden Anwendungen zum Nutzen der Branche zu erstellen.
- Informationsrückgewinnung: Unter Verwendung von Open AI und Vektordatenbanken würden wir Suchmaschinen für den Informationsabruf erstellen, indem wir die Abfragen von Geschäftsbenutzern oder Endbenutzern und indizierte Dokumente innerhalb der Vektordatenbank nutzen.
- Klassifizierung und Clustering:Um ähnliche Datenpunkte oder Gruppen von Objekten zu klassifizieren oder zu gruppieren, müssen sie auf der Grundlage gemeinsamer Merkmale mehreren Kategorien zugeordnet werden.
- Anomalieerkennung: Entdecken Sie Anomalien aus üblichen Mustern, indem Sie die Ähnlichkeit von Datenpunkten messen und Unregelmäßigkeiten erkennen.
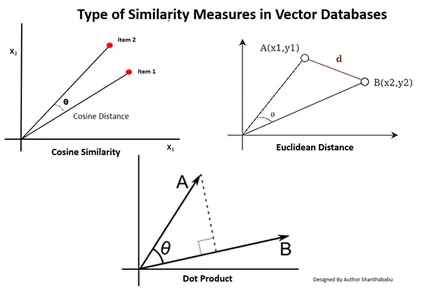
Arten von Ähnlichkeitsmaßen in Vektordatenbanken
Die Messmethoden hängen von der Art der Daten und der spezifischen Anwendung ab. Im Allgemeinen werden drei Methoden verwendet, um die Ähnlichkeit und Vertrautheit mit maschinellem Lernen zu messen.
Euklidische Entfernung
Vereinfacht ausgedrückt ist der Abstand zwischen den beiden Vektoren der geradlinige Abstand zwischen den beiden Vektorpunkten, die den st messen.
Skalarprodukt
Dies hilft uns, die Ausrichtung zwischen zwei Vektoren zu verstehen und anzugeben, ob sie in die gleiche Richtung, in entgegengesetzte Richtungen oder senkrecht zueinander zeigen.
Kosinus-Ähnlichkeit
Es beurteilt die Ähnlichkeit zweier Vektoren anhand des Winkels zwischen ihnen, wie in der Abbildung dargestellt. In diesem Fall sind die Werte und die Größe der Vektoren unbedeutend und haben keinen Einfluss auf die Ergebnisse; Bei der Berechnung wird nur der Winkel berücksichtigt.
Herkömmliche Datenbanken suchen nach exakten SQL-Anweisungsübereinstimmungen und rufen die Daten im Tabellenformat ab. Gleichzeitig befassen wir uns mit Vektordatenbanken, die mithilfe von Prompt-Engineering-Techniken im Klartext nach dem Vektor suchen, der der Eingabeabfrage am ähnlichsten ist. Die Datenbank verwendet den Suchalgorithmus Approximate Nearest Neighbour (ANN), um ähnliche Daten zu finden. Liefern Sie immer einigermaßen genaue Ergebnisse bei hoher Leistung, Genauigkeit und Reaktionszeit.
Arbeitsmechanismus
- Vektordatenbanken konvertieren Daten zunächst in Einbettungsvektoren, speichern sie in Vektordatenbanken und erstellen eine Indizierung für eine schnellere Suche.
- Eine Abfrage der Anwendung interagiert mit dem Einbettungsvektor, sucht mithilfe eines Index nach dem nächsten Nachbarn oder ähnlichen Daten in der Vektordatenbank und ruft die an die Anwendung übergebenen Ergebnisse ab.
- Basierend auf den Geschäftsanforderungen werden die abgerufenen Daten fein abgestimmt, formatiert und dem Endbenutzer oder dem Abfrage- oder Aktionsfeed angezeigt.
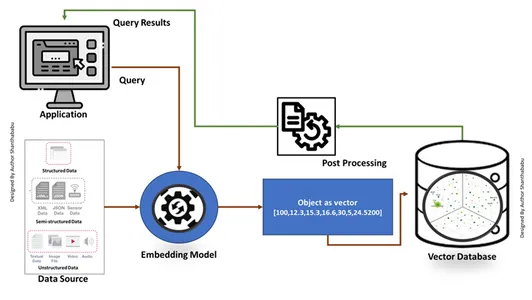
Erstellen einer Vektordatenbank
Lassen Sie uns mit Pinecone in Kontakt treten.
Sie können über Google, GitHub oder Microsoft ID eine Verbindung zu Pinecone herstellen.
Erstellen Sie ein neues Benutzer-Login für Ihre Nutzung.
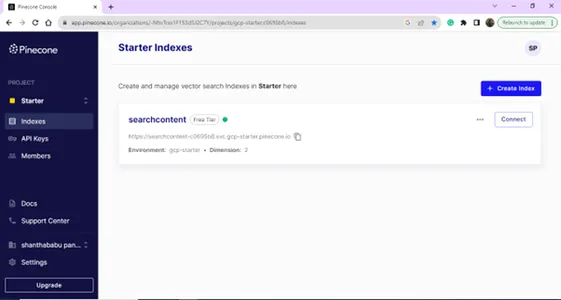
Nach erfolgreicher Anmeldung landen Sie auf der Indexseite; Sie können einen Index für Ihre Vector-Datenbankzwecke erstellen. Klicken Sie auf die Schaltfläche Index erstellen.
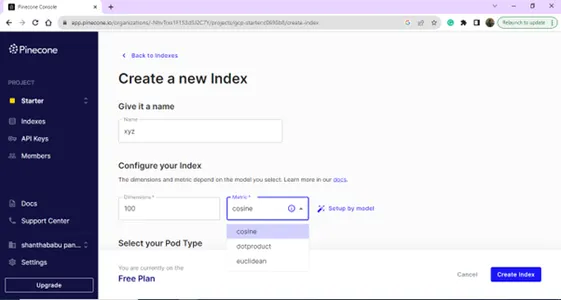
Erstellen Sie Ihren neuen Index, indem Sie den Namen und die Dimensionen angeben.
Indexlistenseite,
Indexdetails – Name, Region und Umgebung – Wir benötigen alle diese Details, um unsere Vektordatenbank aus dem Modellbaucode zu verbinden.
Details zu den Projekteinstellungen,
Sie können Ihre Einstellungen für mehrere Indizes und Schlüssel für Projektzwecke aktualisieren.
Bisher haben wir die Erstellung des Vektordatenbankindex und der Einstellungen in Pinecone besprochen.
Vektordatenbankimplementierung mit Python
Lassen Sie uns jetzt etwas programmieren.
Bibliotheken importieren
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIBereitstellung eines API-Schlüssels für die OpenAI- und Vector-Datenbank
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Initiierung des LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Tannenzapfen initiieren
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Laden der CSV-Datei zum Erstellen einer Vektordatenbank
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Teilen Sie den Text in Abschnitte auf
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Den Text in text_chunk finden
text_chunksOutput
Dokument 100nEmpfehlung: Kinder, Metadaten={ 'source': '70% Bran', 'row': 4}), , …..
Gebäudeeinbettung
embeddings = OpenAIEmbeddings()Erstellen Sie eine Pinecone-Instanz für die Vektordatenbank aus „Daten“.
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Erstellen Sie einen Retriever zum Abfragen der Vektordatenbank.
retriever = vectordb.as_retriever(score_threshold = 0.7)Abrufen von Daten aus der Vektordatenbank
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsVerwenden Sie „Prompt“ und rufen Sie die Daten ab
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Lassen Sie uns die Daten abfragen.
chain('Can you please provide cereal recommendation for Kids?')Ausgabe der Abfrage
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Zusammenfassung
Ich hoffe, Sie können verstehen, wie Vektordatenbanken funktionieren, welche Komponenten sie haben, welche Architektur sie haben und welche Eigenschaften Vektordatenbanken in generativen KI-Lösungen haben. Verstehen Sie, wie sich die Vektordatenbank von herkömmlichen Datenbanken unterscheidet und vergleichen Sie sie mit herkömmlichen Datenbankelementen. Tatsächlich hilft Ihnen die Analogie, die Vektordatenbank besser zu verstehen. Die Pinecone-Vektordatenbank und die Indizierungsschritte helfen Ihnen beim Erstellen einer Vektordatenbank und liefern den Schlüssel für die folgende Codeimplementierung.
Key Take Away
- Komprimierbar mit strukturierten, unstrukturierten und halbstrukturierten Daten.
- Es passt Einbettungstechniken und hochindizierte Funktionen an.
- Die Interaktionen erfolgen über Klartext mit einer Eingabeaufforderung (z. B. Englisch). Und Daten, die in mathematischen Darstellungen gespeichert sind.
- Ähnlichkeit wird in Vektordatenbanken durch Euklidische Distanz, Kosinusähnlichkeit und Skalarprodukt kalibriert.
Häufig gestellte Fragen
A. Eine Vektordatenbank speichert eine Sammlung von Daten im Weltraum. Es speichert die Daten in mathematischen Darstellungen. da das in den Datenbanken gespeicherte Format es offenen KI-Modellen erleichtert, sich die vorherigen Eingaben zu merken, und es unserer offenen KI-Anwendung ermöglicht, kognitive Suche, Empfehlungen und präzise Textgenerierung für verschiedene Anwendungsfälle in digital transformierten Branchen zu nutzen.
A. Einige der Merkmale sind: 1. Es nutzt die Leistungsfähigkeit dieser Vektoreinbettungen und führt zur Indizierung und Suche in einem riesigen Datensatz. 2. Komprimierbar mit strukturierten, unstrukturierten und halbstrukturierten Daten. 3. Eine Vektordatenbank organisiert Daten anhand hochdimensionaler Vektoren, die Hunderte von Dimensionen enthalten
A. Datenbank ==> Sammlungen
Tabelle==> Vektorraum
Zeile==>Cector
Spalte==>Dimension
Das Einfügen und Löschen ist in Vector-Datenbanken wie in einer herkömmlichen Datenbank möglich.
Update und Join sind nicht im Geltungsbereich.
– Schnelles Abrufen von Informationen für eine umfangreiche Datenerfassung.
– Semantische und Ähnlichkeitssuchoperationen aus großen Dokumenten.
– Klassifizierungs- und Clustering-Anwendung.
– Empfehlungs- und Stimmungsanalysesysteme.
A5: Nachfolgend sind die drei Methoden zur Messung der Ähnlichkeit aufgeführt:
- Euklidische Entfernung
– Kosinusähnlichkeit
- Skalarprodukt
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :hast
- :Ist
- :nicht
- $UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Fähig
- Über uns
- Zugriff
- Genauigkeit
- genau
- genau
- über
- passt sich an
- hinzufügen
- beeinflussen
- AI
- KI-Modelle
- Algorithmus
- Algorithmen
- Ausrichtung
- Alle
- Allianz
- erlauben
- erlaubt
- entlang
- immer
- unter
- an
- Analyse
- Analytik
- Analytics-Vidhya
- und
- beantworten
- jedem
- Bienen
- ersichtlich
- Anwendung
- anwendungsspezifisch
- Anwendungen
- ungefähr
- Architektur
- SIND
- vereinbart worden
- Feld
- Artikel
- Artikel
- künstlich
- künstliche Intelligenz
- Künstliche Intelligenz und maschinelles Lernen
- AS
- Aspekte
- schätzt ein
- Verbände
- At
- Audio-
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- basierend
- BE
- werden
- wird
- Verhalten
- hinter
- Sein
- unten
- Vorteile
- Besser
- zwischen
- Blogathon
- bringen
- bauen
- Building
- Geschäft
- Taste im nun erscheinenden Bestätigungsfenster nun wieder los.
- by
- berechnet
- Berechnung
- namens
- CAN
- Fähigkeiten
- capability
- Erfassung
- Häuser
- Fälle
- Kategorien
- Kette
- Ketten
- Charakteristik
- Clarity
- Einstufung
- klassifizieren
- klicken Sie auf
- Clustering
- Code
- Programmierung
- kognitiv
- Sammlung
- häufig
- kompakt
- vergleichen
- Vergleich
- abschließen
- Komplex
- Komponenten
- umfassend
- Berechnung
- rechnerisch
- Vernetz Dich
- Sich zusammenschliessen
- Geht davon
- betrachtet
- enthalten
- Inhalt
- Kontext
- konventionellen
- Gespräch
- verkaufen
- entspricht
- könnte
- erstellen
- Erstellen
- Kreativität
- Kunde
- technische Daten
- Datenanalyse
- Datenpunkte
- Datenverarbeitung
- Datenbase
- Datenbanken
- Datensätze
- Deal
- Decision Making
- Entscheidungen
- Anforderungen
- ableiten
- Entwerfen
- erwünscht
- Details
- Entdeckung
- entwickelt
- abweichen
- Unterschied
- anders
- digital
- Abmessungen
- Größe
- Direkt
- Richtung
- Richtungen
- entdecken
- Diskretion
- diskutieren
- diskutiert
- angezeigt
- Abstand
- do
- Unterlagen
- die
- Don
- DOT
- dynamisch
- dynamisch
- e
- jeder
- erleichtern
- einfacher
- effektiv
- Effizienz
- effizient
- entweder
- Elemente
- Einbettung
- ermöglichen
- Ende
- Entwicklung
- Ingenieure
- Motor (en)
- Englisch
- sorgt
- Arbeitsumfeld
- Essenz
- essential
- Äther (ETH)
- Sogar
- sich entwickelnden
- ausführen
- Training
- Möglichkeiten sondieren
- Extrakt
- erleichtern
- Vertrautheit
- weit
- Merkmal
- Eigenschaften
- Fed
- Abbildung
- Reichen Sie das
- Mappen
- Finden Sie
- Vorname
- Wohnung
- Folgende
- Aussichten für
- Vordergrund
- unten stehende Formular
- Format
- Frei
- für
- Zukunft
- Lücke
- erzeugen
- Generation
- generativ
- Generative KI
- Geschlecht
- GitHub
- ABSICHT
- gegeben
- Gruppe an
- Gruppen
- Griff
- passieren
- Haben
- Hilfe
- hilft
- hier
- GUTE
- High-Level
- hoch
- historisch
- Ultraschall
- aber
- HTTPS
- riesig
- hunderte
- i
- ID
- identifizieren
- if
- Bilder
- Impact der HXNUMXO Observatorien
- Implementierung
- importieren
- zu unterstützen,
- in
- zunehmend
- Index
- indiziert
- Indizes
- Anzeige
- Indizes
- Branchen
- Energiegewinnung
- Einflussreich
- Information
- inhärent
- innovativ
- Varianten des Eingangssignals:
- Eingänge
- Einsätze
- innerhalb
- Einblicke
- Instanz
- beantragen müssen
- Intelligenz
- interagieren
- Interaktion
- Interaktionen
- in
- Feinheiten
- beinhaltet
- IT
- SEINE
- Jobs
- join
- Karriere
- Reise
- nur
- Wesentliche
- Tasten
- Schlüsselwörter
- Kinder
- Wissen
- Label
- Land
- Landschaft
- grosse
- führenden
- umwandeln
- lernen
- Hebelwirkung
- Hebelwirkungen
- Gefällt mir
- Liste
- Ladeprogramm
- Logik
- login
- Maschine
- Maschinelles Lernen
- Dur
- um
- MACHT
- Making
- flächendeckende Gesundheitsprogramme
- Weise
- manuell
- Hersteller
- Karte
- massiv
- Streichhölzer
- mathematisch
- sinnvoll
- messen
- Maßnahmen
- Messen
- Mechanismus
- Medien
- Merge
- Methodik
- Methoden
- Microsoft
- minimal
- Modell
- für
- mehr
- Zudem zeigt
- vor allem warme
- viel
- mehrere
- sollen
- Name
- Natur
- Need
- Neu
- jetzt an
- und viele
- Objekt
- Objekte
- of
- bieten
- on
- EINEM
- Einsen
- Online
- einzige
- XNUMXh geöffnet
- OpenAI
- Einkauf & Prozesse
- gegenüber
- or
- Organisation
- Organisiert
- organisiert
- Original
- OS
- Andere
- UNSERE
- Besitz
- Seite
- Paar
- Teil
- Bestanden
- Bestehen
- Muster
- perfekt
- ausführen
- Leistung
- durchgeführt
- führt
- Perspektive
- Perspektiven
- ein Bild
- zentrale
- Ebene
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielt
- Bitte
- Points
- Punkte
- möglich
- Potenzial
- Werkzeuge
- größte treibende
- Praktisch
- Praktische Anwendungen
- präzise
- genau
- Vorlieben
- früher
- Aufgabenstellung:
- Prozessdefinierung
- Produkt
- Produkte
- Projekt
- prominent
- Eingabeaufforderungen
- richtig
- immobilien
- Resorts
- die
- Bereitstellung
- Bereitstellung
- veröffentlicht
- Poufs
- Zweck
- Zwecke
- Menge
- Abfragen
- Frage
- Direkt
- schneller
- schnell
- schnell
- Software Empfehlungen
- Empfehlungen
- in Bezug auf
- Region
- Verhältnis
- Beziehungen
- relevant
- Darstellung
- vertreten
- representiert
- falls angefordert
- Voraussetzungen:
- Antwort
- Antworten
- Folge
- Die Ergebnisse
- Revealed
- Rollen
- REIHE
- s
- gleich
- Wissenschaft
- Umfang
- Suche
- Suchmaschinen
- Suchbegriffe
- Suche
- Gefühl
- seo
- Einstellungen
- Form
- Gestaltung
- von Locals geführtes
- Regal
- Short
- gezeigt
- Konzerte
- Seite
- ähnlich
- Ähnlichkeiten
- Einfacher
- da
- Single
- Größe
- So
- Lösung
- Lösungen
- einige
- Quelle
- Raumfahrt
- spezifisch
- Geschwindigkeit
- gespalten
- Spek
- SQL
- Bundesstaat
- Erklärung
- Aussagen
- Shritte
- Immer noch
- Lagerung
- speichern
- gelagert
- Läden
- Struktur
- strukturierte
- Studie
- Anschließend
- erfolgreich
- Synergie
- System
- Systeme und Techniken
- T
- Tabelle
- TAG
- und Aufgaben
- Techniken
- technologische
- AGB
- Text
- Texterzeugung
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- ihr
- Sie
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- nach drei
- Durch
- Zeit
- mal
- zu
- traditionell
- Training
- Transformieren
- Transformation
- Transformativ
- verwandelt
- versuchen
- XNUMX
- Typen
- Letztlich
- verstehen
- Verständnis
- zweifellos
- öffnen
- Entriegelung
- Aktualisierung
- mehr Stunden
- us
- Anwendungsbereich
- -
- benutzt
- Mitglied
- verwendet
- Verwendung von
- üblich
- Werte
- Vielfalt
- verschiedene
- sehr
- lebenswichtig
- vs
- wurde
- we
- webp
- gut definiert
- waren
- Was
- Was ist
- ob
- welche
- während
- werden wir
- mit
- .
- Worte
- Arbeiten
- arbeiten,
- würde
- U
- Ihr
- Zephyrnet