Einleitung
Im Bereich der akademischen Forschung kann der Weg von Rohdaten zu aufschlussreichen Schlussfolgerungen für Anfänger oder Neulinge eine Herausforderung sein. Mit dem richtigen Ansatz und den richtigen Tools ist die Umwandlung von Daten in aussagekräftiges Wissen jedoch eine äußerst lohnende Erfahrung. In diesem Leitfaden führen wir Sie durch einen typischen akademischen Datenanalyse-Workflow und verwenden dabei ein praktisches Beispiel aus einer aktuellen Studie über die Wirksamkeit verschiedener Diäten bei der Gewichtsabnahme.

Inhaltsverzeichnis
Lernziel
Wir werden ein fortgeschrittenes verwenden KI-Datentool - Julius, um die Analyse durchzuführen. Unser Ziel ist es, den Prozess der akademischen Forschungsanalyse zu entmystifizieren und zu zeigen, wie Daten, wenn sie sorgfältig und richtig analysiert werden, faszinierende Trends beleuchten und Antworten auf kritische Forschungsfragen liefern können.
Navigieren im akademischen Daten-Workflow mit Julius
In der akademischen Forschung ist die Art und Weise, wie wir mit Daten umgehen, entscheidend für die Gewinnung neuer Erkenntnisse. Dieser Teil unseres Leitfadens führt Sie durch die Standardschritte zur Analyse von Forschungsdaten. Vom Beginn einer klaren Frage bis hin zur Weitergabe der Endergebnisse ist jeder Schritt entscheidend.
Wir zeigen, wie Forscher, wenn sie diesem klaren Weg folgen, Rohdaten in vertrauenswürdige und wertvolle Erkenntnisse umwandeln können. Anschließend führen wir Sie anhand einer Beispielfallstudie durch jeden Schritt und zeigen Ihnen, wie Sie durch den Einsatz von Julius im gesamten Prozess Zeit sparen und gleichzeitig qualitativ hochwertigere Ergebnisse erzielen können.
1. Frageformulierung
Beginnen Sie damit, Ihre Forschungsfrage oder Hypothese klar zu definieren. Dies leitet die gesamte Analyse und bestimmt die von Ihnen verwendeten Methoden.
2. Datensammlung
Sammeln Sie die erforderlichen Daten und stellen Sie sicher, dass sie mit Ihrer Forschungsfrage übereinstimmen. Dies kann das Sammeln neuer Daten oder die Verwendung bestehender Datensätze umfassen. Die Daten sollten Variablen enthalten, die für Ihre Studie relevant sind.
3. Datenbereinigung und Vorverarbeitung
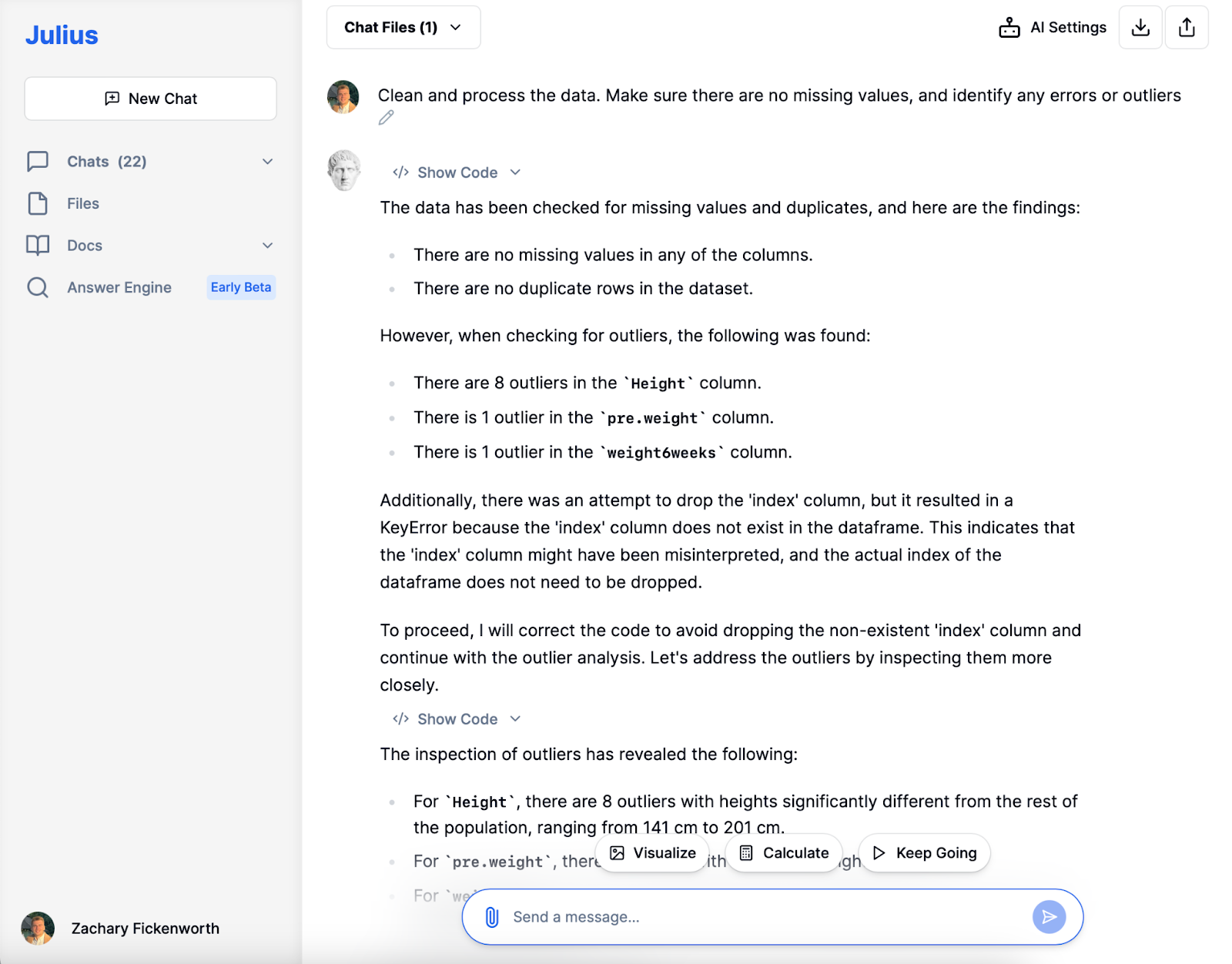
Bereiten Sie Ihren Datensatz für die Analyse vor. Dieser Schritt umfasst die Sicherstellung der Datenkonsistenz (z. B. standardisierte Maßeinheiten), den Umgang mit fehlenden Werten und die Identifizierung etwaiger Fehler oder Ausreißer in Ihren Daten.
4. Explorative Datenanalyse (EDA)
Führen Sie eine erste Prüfung der Daten durch. Dazu gehört die Analyse der Verteilung von Variablen, die Identifizierung von Mustern oder Ausreißern und das Verständnis der Eigenschaften Ihres Datensatzes.
5. Methodenauswahl
- Bestimmung der Analysetechniken: Wählen Sie geeignete statistische Methoden oder Modelle basierend auf Ihren Daten und Ihrer Forschungsfrage. Dies kann den Vergleich von Gruppen, die Identifizierung von Beziehungen oder die Vorhersage von Ergebnissen umfassen.
- Überlegungen zur Methodenwahl: Die Auswahl wird durch die Art der Daten (z. B. kategorisch oder kontinuierlich), die Anzahl der verglichenen Gruppen und die Art der Beziehungen, die Sie untersuchen, beeinflusst.
6. Statistische Analyse
- Operationalisierung von Variablen: Erstellen Sie bei Bedarf neue Variablen, die die Konzepte, die Sie studieren, besser darstellen.
- Durchführen statistischer Tests: Wenden Sie die gewählten statistischen Methoden an, um Ihre Daten zu analysieren. Dies könnte Tests wie T-Tests, ANOVA, Regressionsanalyse usw. umfassen.
- Berücksichtigung von Kovariaten: Beziehen Sie in komplexere Analysen andere relevante Variablen ein, um deren mögliche Auswirkungen zu kontrollieren.
7. Deutung
Interpretieren Sie die Ergebnisse sorgfältig im Kontext Ihrer Forschungsfrage. Dazu gehört es, zu verstehen, was die statistischen Ergebnisse in der Praxis bedeuten, und etwaige Einschränkungen zu berücksichtigen.
8. Berichterstattung
Fassen Sie Ihre Erkenntnisse, Methoden und Interpretationen in einem umfassenden Bericht oder einer wissenschaftlichen Arbeit zusammen. Dies sollte klar, prägnant und gut strukturiert sein, um Ihre Forschung effektiv zu kommunizieren.
Einführung in die Fallstudie
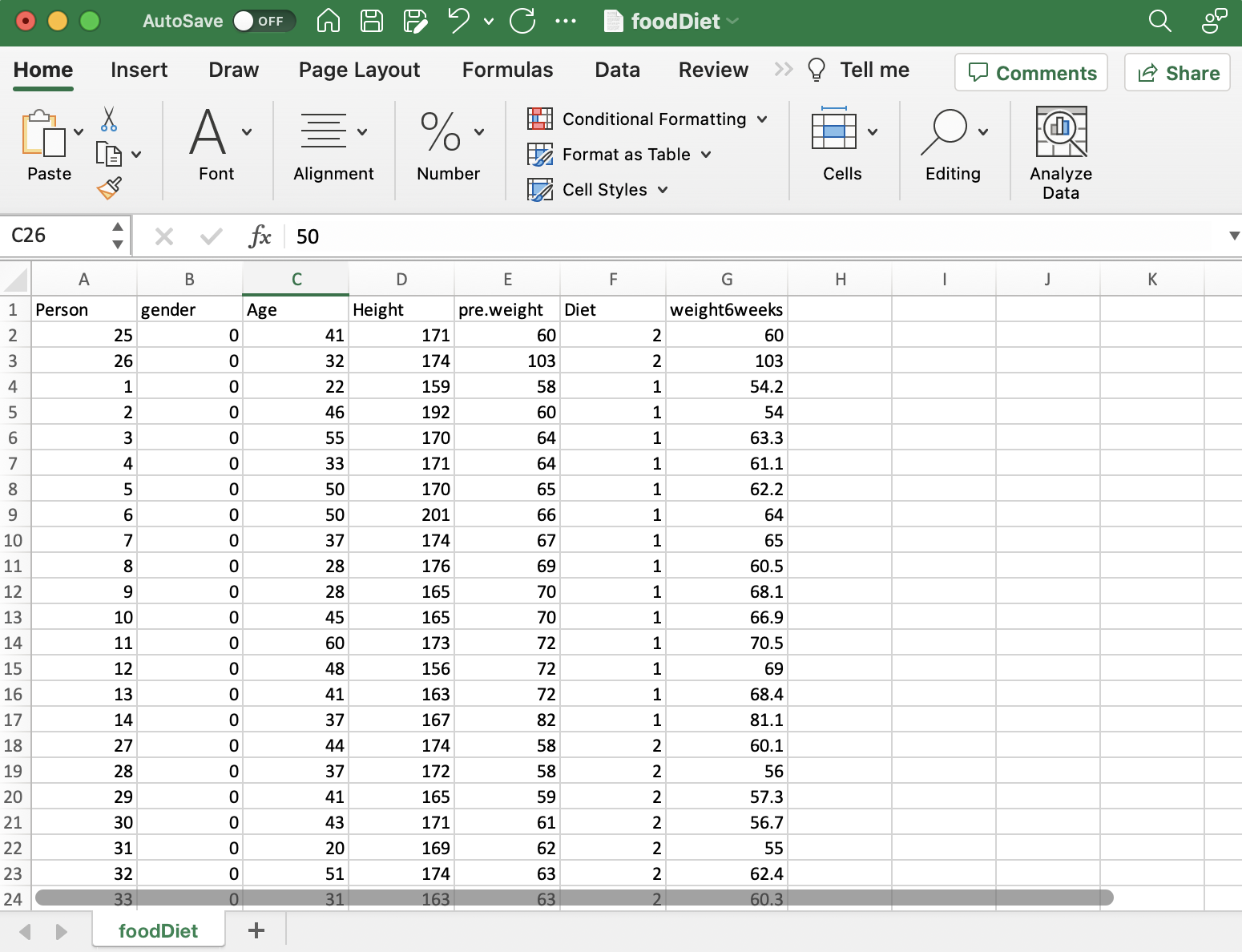
In dieser Fallstudie untersuchen wir, wie sich verschiedene Diäten auf die Gewichtsabnahme auswirken. Uns liegen Daten wie Alter, Geschlecht, Ausgangsgewicht, Ernährungsart und Gewicht nach sechs Wochen vor. Unser Ziel ist es, anhand realer Daten von echten Menschen herauszufinden, welche Diäten zur Gewichtsreduktion am effektivsten sind.
Frageformulierung
Bei jeder Forschung, wie unserer Studie zu Diäten und Gewichtsverlust, beginnt alles mit einer guten Frage. Es ist wie eine Roadmap für Ihre Recherche, die Ihnen zeigt, worauf Sie sich konzentrieren sollten.
Bei unseren Ernährungsdaten fragten wir beispielsweise: Führt eine bestimmte Diät zu einem deutlichen Gewichtsverlust in sechs Wochen?
Diese Frage ist unkompliziert und sagt uns genau, worauf wir in unseren Daten achten müssen. Dazu gehören Details wie der Ernährungstyp jeder Person, das Gewicht vor und nach sechs Wochen, das Alter und das Geschlecht. Eine klare Frage wie diese stellt sicher, dass wir auf dem richtigen Weg bleiben und die richtigen Dinge in unseren Daten untersuchen, um die Antworten zu finden, die wir brauchen.
Datensammlung
In der Forschung kommt es darauf an, die richtigen Daten zu sammeln. Für unsere Studie zu Diäten und Gewichtsverlust haben wir Informationen über die Art der Ernährung jeder Person, ihr Gewicht vor und nach der Diät, ihr Alter und ihr Geschlecht gesammelt. Es ist wichtig sicherzustellen, dass die Daten zu Ihrer Forschungsfrage passen. In einigen Fällen müssen Sie möglicherweise neue Informationen sammeln, aber hier haben wir vorhandene Daten verwendet, die bereits alle benötigten Details enthielten. Gute Daten zu erhalten ist der erste große Schritt, um herauszufinden, was Sie wissen möchten.
Datenbereinigung und Vorverarbeitung
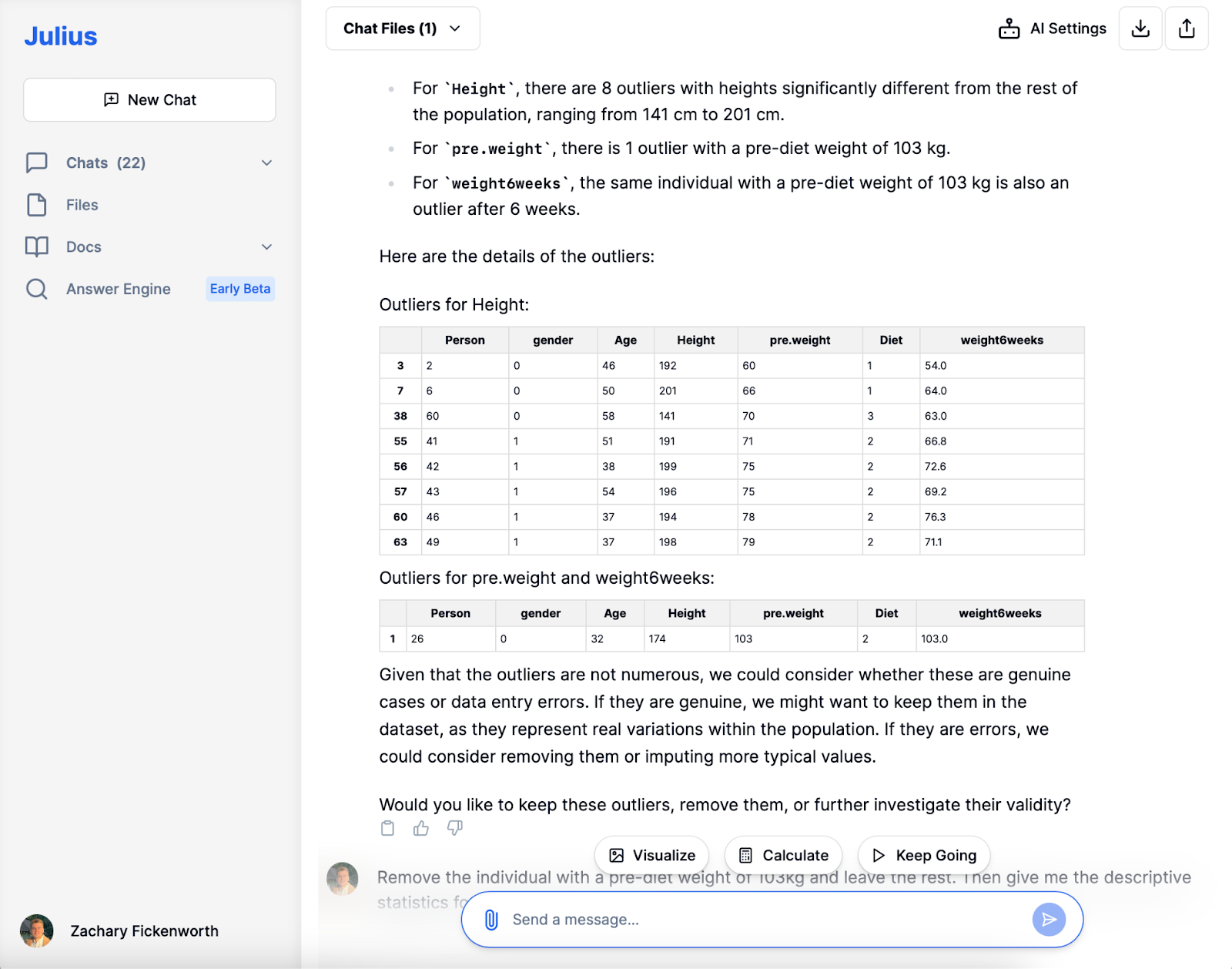
In unserer Ernährungsstudie war die Datenbereinigung mit Julius von zentraler Bedeutung. Nach dem Laden der Daten identifizierte Julius fehlende Werte und Duplikate und sorgte so für Klarheit im Datensatz. Während wir aus Gründen der Diversität Größenausreißer beibehalten, haben wir uns dafür entschieden, eine Person mit einem außergewöhnlich hohen Gewicht vor der Diät (103 kg) auszuschließen, um die Integrität der Analyse zu wahren und die Verfügbarkeit des Datensatzes für nachfolgende Phasen sicherzustellen.
Explorative Datenanalyse (EDA)
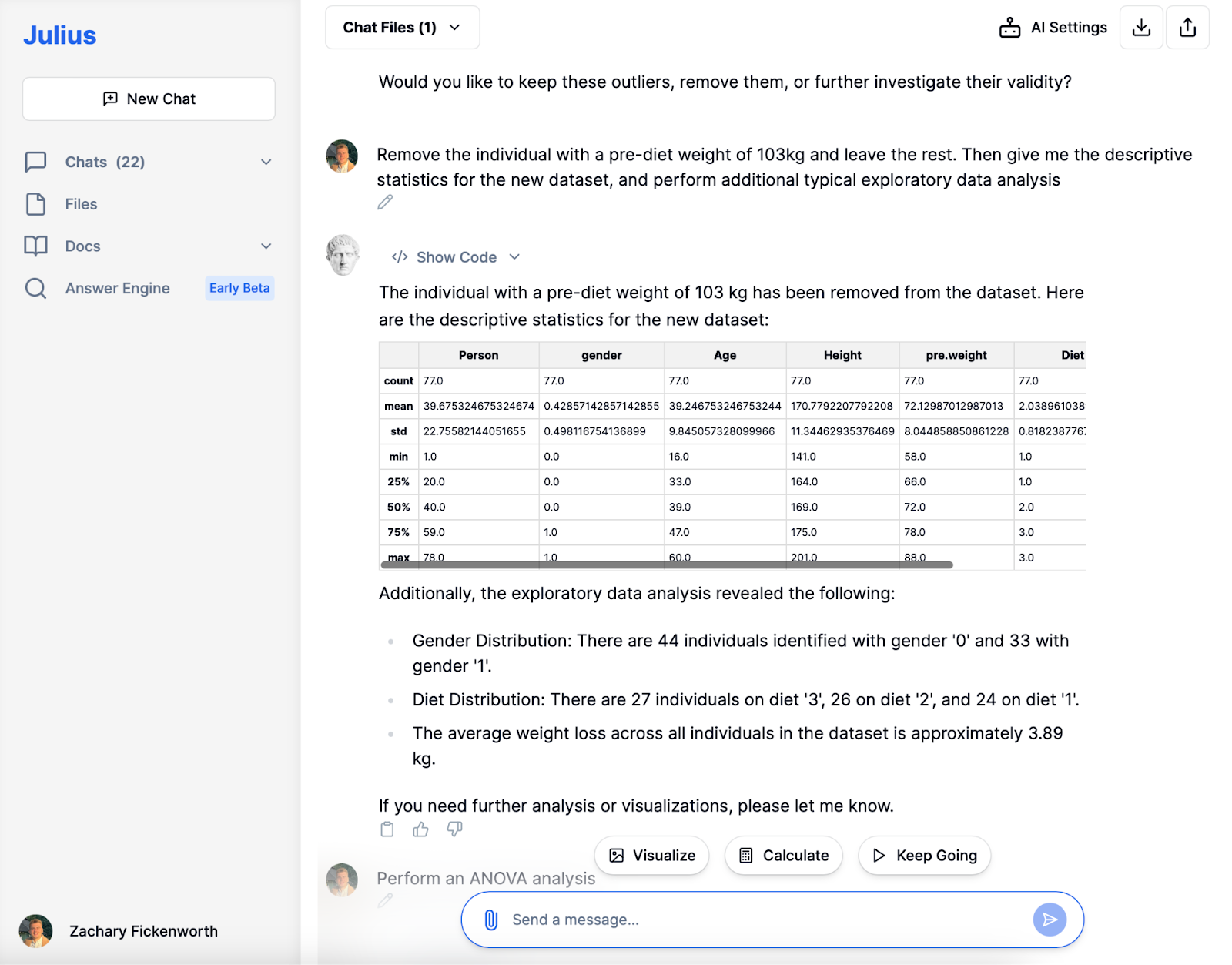
Nachdem wir den Ausreißer mit einem ungewöhnlich hohen Gewicht vor der Diät entfernt hatten, befassten wir uns mit der Phase der explorativen Datenanalyse (EDA). Julius lieferte schnell neue deskriptive Statistiken und bot so einen klareren Überblick über unsere 77 Teilnehmer. Die Feststellung eines durchschnittlichen Gewichts vor der Diät von etwa 72 kg und eines durchschnittlichen Gewichtsverlusts von etwa 3.89 kg lieferte wertvolle Erkenntnisse.
Über die grundlegenden Statistiken hinaus ermöglichte Julius eine Untersuchung der Geschlechter- und Ernährungsverteilung. Die Studie ergab eine ausgewogene Geschlechteraufteilung und eine gleichmäßige Verteilung auf verschiedene Ernährungsformen. Dieses EDA fasst nicht nur Daten zusammen; Es deckt Muster und Trends auf, die für eine tiefergehende Analyse von entscheidender Bedeutung sind. Das Verständnis des durchschnittlichen Gewichtsverlusts schafft beispielsweise die Grundlage für die Bestimmung der effektivsten Diät. Diese KI-gestützte Phase schafft die Grundlage für die anschließende detaillierte Analyse.
Methodenauswahl
In unserer Ernährungsstudie war die Auswahl der geeigneten statistischen Methoden ein entscheidender Schritt. Unser Hauptziel bestand darin, den Gewichtsverlust bei verschiedenen Diäten zu vergleichen, was einen direkten Einfluss auf unsere Wahl der Analysetechniken hatte. Da wir mehr als zwei Gruppen (die verschiedenen Diätarten) vergleichen mussten, war eine Varianzanalyse (ANOVA) die ideale Wahl. ANOVA ist in Situationen wie unserer von großer Bedeutung, wenn wir verstehen müssen, ob es signifikante Unterschiede in einer kontinuierlichen Variablen (Gewichtsverlust) zwischen mehreren unabhängigen Gruppen (den Ernährungsarten) gibt.
Die ANOVA sagt uns zwar, ob es Unterschiede gibt, gibt jedoch nicht an, wo diese Unterschiede liegen. Um herauszufinden, welche spezifischen Diäten am effektivsten waren, brauchten wir einen gezielteren Ansatz. Hier kamen paarweise Vergleiche ins Spiel. Nachdem wir mit ANOVA signifikante Ergebnisse gefunden hatten, verwendeten wir paarweise Vergleiche, um die Gewichtsverlustunterschiede zwischen den einzelnen Paaren von Diättypen zu untersuchen.
Dieser zweistufige Ansatz – beginnend mit der ANOVA zur Erkennung etwaiger Gesamtunterschiede, gefolgt von paarweisen Vergleichen zur Detaillierung dieser Unterschiede – war strategisch. Es lieferte ein umfassendes Verständnis darüber, wie jede Diät im Verhältnis zu den anderen funktionierte, und gewährleistete eine gründliche und differenzierte Analyse unserer Diätdaten.
Statistische Analyse
ANOVA
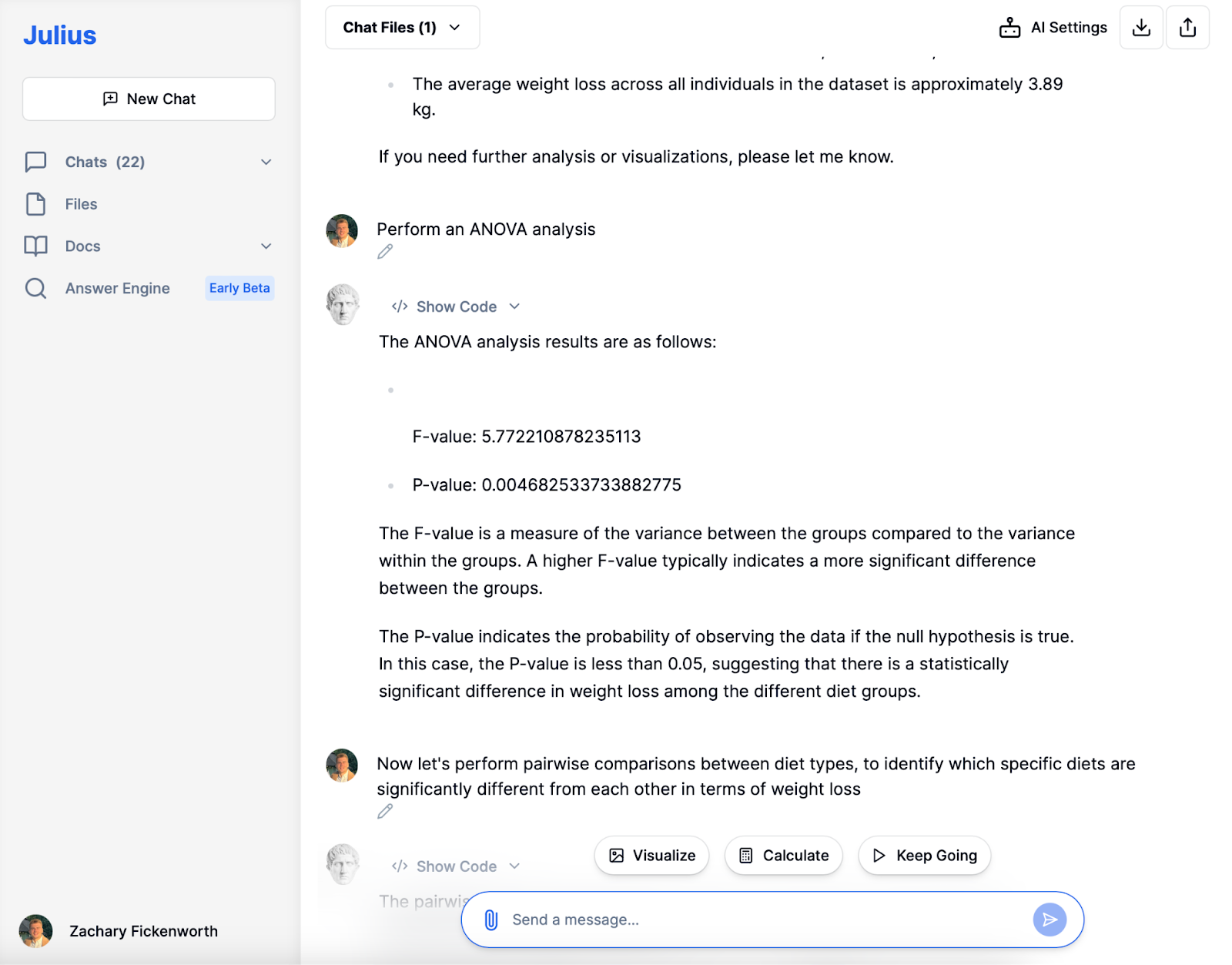
Im Mittelpunkt unserer statistischen Untersuchung haben wir eine durchgeführt ANOVA Analyse, um zu verstehen, ob die Gewichtsverlustunterschiede zwischen den verschiedenen Diätarten statistisch signifikant waren. Die Ergebnisse waren ziemlich aufschlussreich. Mit einem F-Wert von 5.772 deutete die Analyse auf eine bemerkenswerte Varianz zwischen den Diätgruppen im Vergleich zur Varianz innerhalb jeder Gruppe hin. Da dieser F-Wert höher war, deutete er auf signifikante Unterschiede im Gewichtsverlust zwischen den Diäten hin.
Noch wichtiger ist, dass der P-Wert mit 0.00468 herausragte. Dieser Wert, der deutlich unter dem herkömmlichen Schwellenwert von 0.05 liegt, deutet stark darauf hin, dass die Unterschiede, die wir beim Gewichtsverlust zwischen den Diätgruppen beobachteten, nicht zufällig waren. Statistisch gesehen bedeutete dies, dass wir die Nullhypothese – die keinen Unterschied in der Gewichtsabnahme zwischen den Diäten annehmen würde – ablehnen und zu dem Schluss kommen konnten, dass die Art der Diät tatsächlich einen signifikanten Einfluss auf die Gewichtsabnahme hatte. Dieses ANOVA-Ergebnis war ein entscheidender Meilenstein, der uns dazu veranlasste, genauer zu untersuchen, welche Diäten sich voneinander unterschieden.
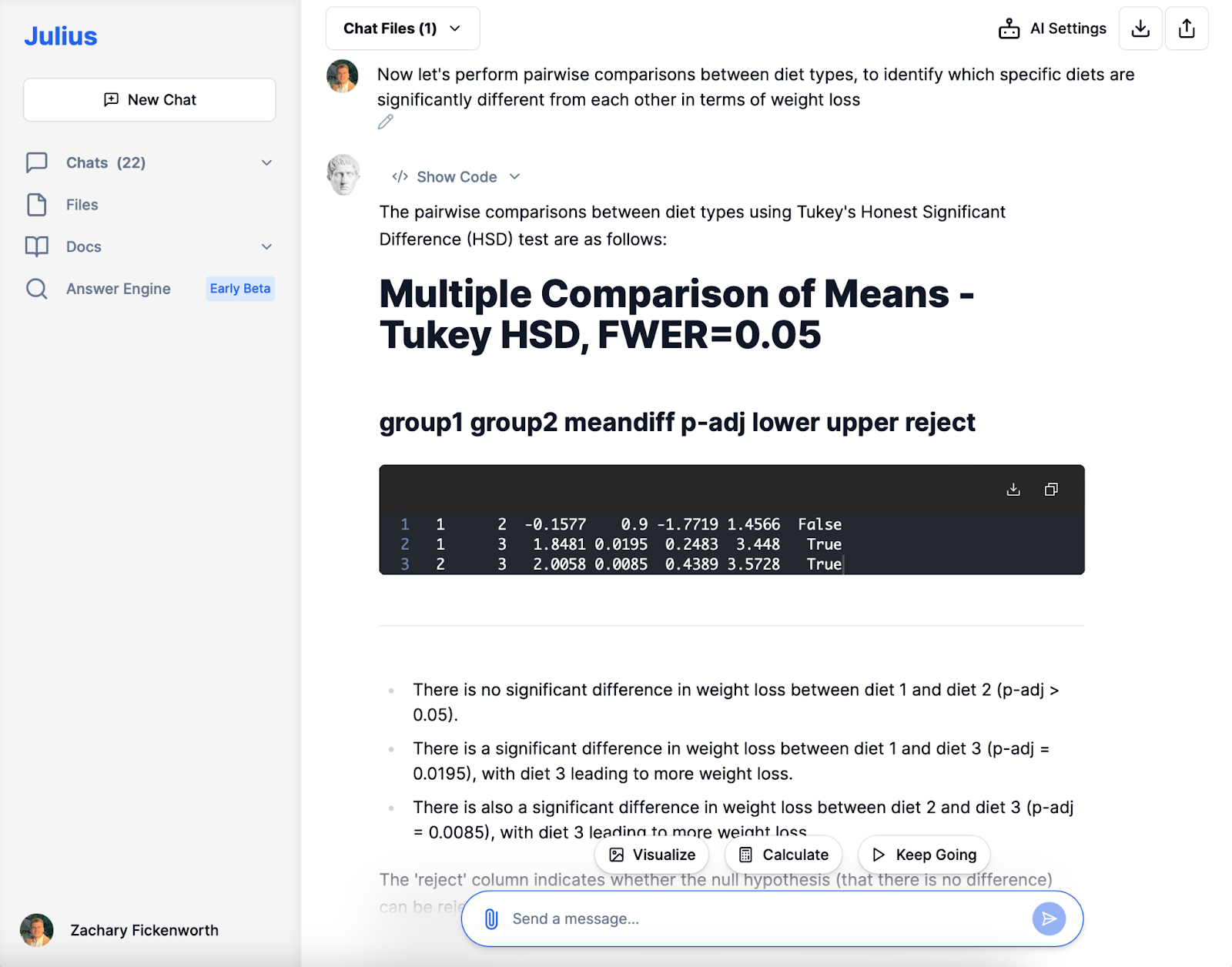
Paarweise
In der anschließenden Analysephase mit Julius führten wir paarweise Vergleiche zwischen Diättypen durch, um spezifische Unterschiede bei der Gewichtsabnahme zu identifizieren. Der Tukey-HSD-Test zeigte keinen signifikanten Unterschied zwischen Diät 1 und Diät 2. Er ergab jedoch, dass Diät 3 im Vergleich zu Diät 1 und Diät 2 zu einem deutlich größeren Gewichtsverlust führte, was durch statistisch signifikante p-Werte gestützt wird. Diese prägnante, aber aufschlussreiche Analyse von Julius spielte eine entscheidende Rolle beim Verständnis der relativen Wirksamkeit jeder Diät.
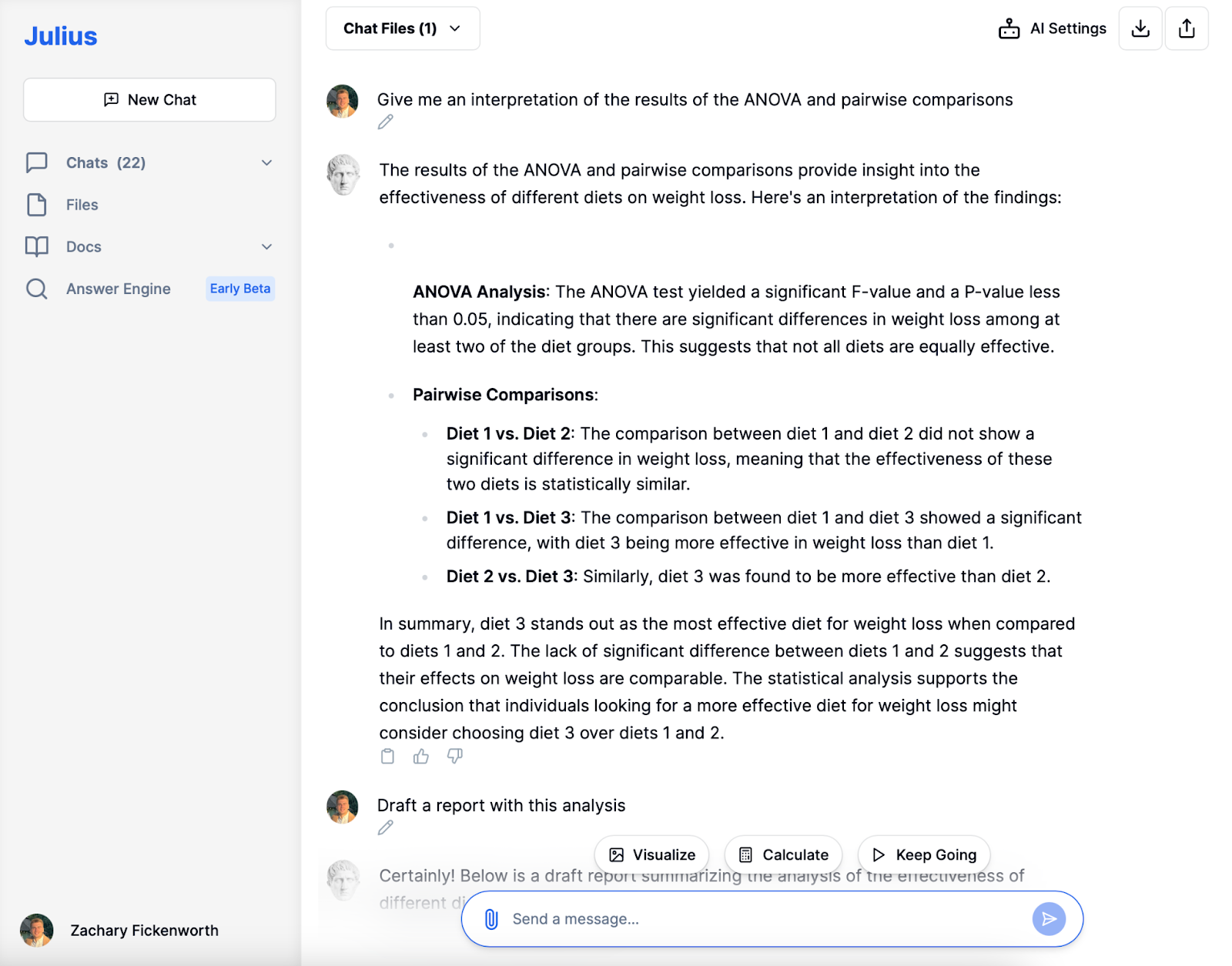
Dolmetschen
In unserer Studie zur Wirksamkeit von Diäten spielte Julius eine Schlüsselrolle bei der Interpretation und Erklärung der Ergebnisse der ANOVA und der paarweisen Vergleiche. So hat es uns geholfen, die Ergebnisse zu verstehen:
ANOVA-Interpretation
Zunächst wurden die ANOVA-Ergebnisse analysiert, die einen signifikanten F-Wert und einen P-Wert von weniger als 0.05 zeigten. Dies deutete darauf hin, dass es zwischen den verschiedenen Diätgruppen erhebliche Unterschiede beim Gewichtsverlust gab. Dies half uns zu verstehen, dass dies bedeutete, dass nicht alle Diäten in der Studie die Gewichtsabnahme gleichermaßen wirksam förderten.
Interpretation paarweiser Vergleiche
- Diät 1 vs. Diät 2: Sie verglich diese beiden Diäten und stellte keinen signifikanten Unterschied in der Gewichtsabnahme fest. Diese Interpretation bedeutete, dass diese beiden Diäten statistisch gesehen ähnlich wirksam waren.
- Diät 1 vs. Diät 3 & Diät 2 vs. Diät 3: In beiden Vergleichen stellte ich fest, dass Diät 3 die Gewichtsabnahme deutlich wirksamer förderte als Diät 1 oder Diät 2.
Julius‘ Interpretation war entscheidend, um aus unserer Analyse konkrete Schlussfolgerungen zu ziehen. Es wurde klargestellt, dass Diät 1 und 2 zwar in ihrer Wirksamkeit ähnlich waren, Diät 3 jedoch die herausragende Option zur Gewichtsabnahme war. Diese Interpretation verschaffte uns nicht nur ein klares Ergebnis der Studie, sondern zeigte auch die praktischen Auswirkungen unserer Ergebnisse. Mit diesen Informationen können wir mit Sicherheit davon ausgehen, dass Diät 3 die bessere Wahl für Personen sein könnte, die nach wirksamen Lösungen zur Gewichtsabnahme suchen.
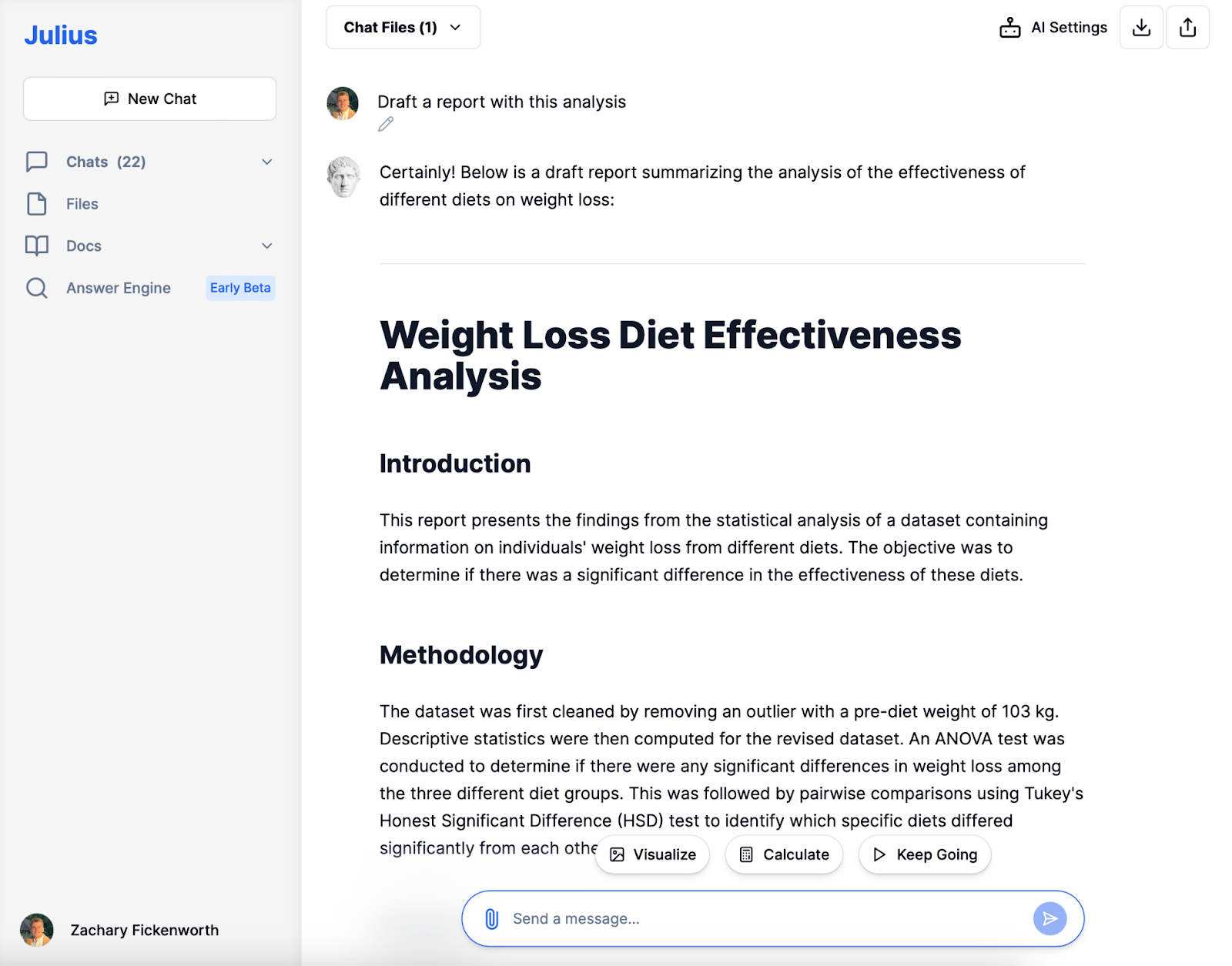
Reporting
In der letzten Phase unserer Ernährungsstudie würden wir einen Bericht erstellen, der unseren gesamten Forschungsprozess und unsere Ergebnisse übersichtlich zusammenfasst. Dieser Bericht, der sich an der mit Julius durchgeführten Analyse orientiert, würde Folgendes umfassen:
- Einführung: Eine kurze Erläuterung des Ziels der Studie, die Wirksamkeit verschiedener Diäten bei der Gewichtsabnahme zu bewerten.
- Methodik: Eine kurze Beschreibung, wie wir die Daten bereinigt haben, welche statistischen Methoden (ANOVA und Tukey's HSD) verwendet wurden und warum sie ausgewählt wurden.
- Erkenntnisse und Interpretation: Eine klare Darstellung der Ergebnisse, einschließlich der signifikanten Unterschiede zwischen den Diäten, wobei insbesondere die Wirksamkeit von Diät 3 hervorgehoben wird.
- Fazit: Abschließende Schlussfolgerungen aus den Daten ziehen und auf der Grundlage unserer Erkenntnisse praktische Implikationen oder Empfehlungen vorschlagen.
- References: Unter Berufung auf die Tools und statistischen Methoden wie Julius, die unsere Analyse unterstützt haben.
Dieser Bericht würde als klare, strukturierte und umfassende Aufzeichnung unserer Forschung dienen und sie für ihre Leser zugänglich und informativ machen.
Zusammenfassung
Wir sind am Ende unserer akademischen Forschungsreise angelangt und haben einen Datensatz über Ernährung in aussagekräftige Erkenntnisse umgewandelt. Dieser Prozess von der ersten Frage bis zum Abschlussbericht zeigt, wie die richtigen Tools und Methoden die Datenanalyse auch für Einsteiger zugänglich machen können.
Die richtigen Julius, unserem fortschrittlichen KI-Tool, haben wir gesehen, wie strukturierte Schritte in der Datenanalyse wichtige Trends aufdecken und wichtige Fragen beantworten können. Unsere Studie zu Diäten und Gewichtsverlust ist nur ein Beispiel dafür, wie Daten bei sorgfältiger Analyse nicht nur eine Geschichte erzählen, sondern auch klare, umsetzbare Schlussfolgerungen liefern. Wir hoffen, dass dieser Leitfaden Licht in den Datenanalyseprozess bringt und ihn weniger entmutigend und spannender für alle macht, die daran interessiert sind, die in ihren Daten verborgenen Geschichten aufzudecken.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/01/guide-to-academic-data-analysis-with-julius-ai/
- :hast
- :Ist
- :nicht
- :Wo
- 1
- 72
- 77
- a
- akademisch
- akademische Forschung
- zugänglich
- über
- advanced
- Nach der
- Alter
- AI
- AI-powered
- Ziel
- Richtet sich aus
- Alle
- bereits
- ebenfalls
- unter
- an
- Analysen
- Analyse
- analysieren
- analysiert
- Analyse
- machen
- beantworten
- Antworten
- jedem
- jemand
- Ansatz
- zugänglich
- angemessen
- ca.
- SIND
- Bereich
- um
- AS
- annehmen
- At
- durchschnittlich
- Ausgewogen
- basierend
- basic
- BE
- Bevor
- Anfänger
- Anfänger
- Sein
- unten
- Besser
- zwischen
- Big
- beide
- aber
- by
- kam
- CAN
- vorsichtig
- Häuser
- Fallstudie
- Fälle
- Chance
- Charakteristik
- Wahl
- gewählt
- geklärt
- Clarity
- Reinigung
- klar
- klarer
- sammeln
- Das Sammeln
- Sammlung
- wie die
- mit uns kommunizieren,
- vergleichen
- verglichen
- Vergleich
- Vergleiche
- Komplex
- umfassend
- Konzepte
- prägnant
- Schluss
- Beton
- durchgeführt
- zuversichtlich
- Berücksichtigung
- Kontext
- kontinuierlich
- Smartgeräte App
- konventionellen
- könnte
- erstellen
- kritischem
- wichtig
- entscheidend
- technische Daten
- Datenanalyse
- Datensätze
- tiefer
- Definition
- weisen nach, dass
- entmystifizieren
- Beschreibung
- Detail
- detailliert
- Details
- entdecken
- entschlossen
- Festlegung
- DID
- Diät
- Unterschied
- Unterschiede
- anders
- Direkt
- entdecken
- Verteilung
- Diversität
- Tut nicht
- erledigt
- Zeichnung
- Duplikate
- e
- jeder
- Effektiv
- effektiv
- Wirksamkeit
- Effekten
- entweder
- Ende
- Gewährleistung
- Ganz
- gleichermaßen
- Fehler
- insbesondere
- etabliert
- etc
- Äther (ETH)
- bewerten
- Sogar
- alles
- genau
- Untersuchung
- untersuchen
- Untersuchen
- Beispiel
- außergewöhnlich
- unterhaltsame Programmpunkte
- vorhandenen
- ERFAHRUNGEN
- Erläuterung
- Erklärung
- Exploration
- Explorative Datenanalyse
- erleichtert
- faszinierend
- Finale
- Finden Sie
- Suche nach
- Befund
- Vorname
- fits
- Setzen Sie mit Achtsamkeit
- gefolgt
- Folgende
- Aussichten für
- Formulierung
- gefunden
- frisch
- für
- weiter
- gesammelt
- gab
- Geschlecht
- bekommen
- gegeben
- Kundenziele
- gut
- mehr
- Grundlage
- Gruppe an
- Gruppen
- Guide
- geführt
- Anleitungen
- führen
- hätten
- Griff
- Handling
- Haben
- Herz
- Höhe
- dazu beigetragen,
- hier
- versteckt
- GUTE
- höher
- Hervorheben
- ein Geschenk
- Ultraschall
- Hilfe
- aber
- HTTPS
- i
- ideal
- identifiziert
- identifizieren
- Identifizierung
- if
- beleuchten
- immens
- Impact der HXNUMXO Observatorien
- Auswirkungen
- wichtig
- in
- das
- Dazu gehören
- Einschließlich
- unabhängig
- angegeben
- indikativ
- Krankengymnastik
- Einzelpersonen
- beeinflusst
- Information
- informativ
- informiert
- Anfangs-
- aufschlussreiche
- Einblicke
- Integrität
- interessiert
- Interpretation
- in
- untersuchen
- beteiligen
- beinhaltet
- IT
- SEINE
- Reise
- Julius
- nur
- nur einer
- Wesentliche
- Wissen
- Wissen
- führen
- führenden
- weniger
- Lüge
- !
- Gefällt mir
- Einschränkungen
- Laden
- aussehen
- Verlust
- Main
- halten
- um
- MACHT
- Making
- max-width
- Kann..
- bedeuten
- sinnvoll
- gemeint
- Messung
- nur
- Methode
- Methodik
- Methoden
- könnte
- Meilenstein
- Kommt demnächst...
- für
- mehr
- vor allem warme
- Natur
- notwendig,
- Need
- erforderlich
- Neu
- nicht
- bemerkenswert
- Anfänger
- nuance
- Anzahl
- Ziel
- beobachtet
- of
- bieten
- on
- EINEM
- einzige
- Option
- or
- Andere
- Anders
- UNSERE
- Ergebnis
- Ergebnisse
- Ausreißer
- Gesamt-
- Paar
- Papier
- Teil
- Teilnehmer
- Weg
- Muster
- Personen
- ausführen
- durchgeführt
- Phase
- zentrale
- Plato
- Datenintelligenz von Plato
- PlatoData
- gespielt
- Potenzial
- größte treibende
- Praktisch
- Vorhersage
- presentation
- Erhaltung
- Prozessdefinierung
- Die Förderung der
- richtig
- die
- vorausgesetzt
- bietet
- Qualität
- Frage
- Fragen
- ganz
- Roh
- Rohdaten
- Leser
- Bereitschaft
- echt
- kürzlich
- Empfehlungen
- Rekord
- Regression
- Beziehung
- Beziehungen
- relativ
- relevant
- Entfernung
- berichten
- vertreten
- Forschungsprojekte
- Forscher
- Folge
- Folge
- Die Ergebnisse
- zeigen
- Revealed
- aufschlussreich
- lohnend
- Recht
- Fahrplan
- Rollen
- Speichern
- auf der Suche nach
- gesehen
- Auswahl
- Auswahl
- brauchen
- Sets
- mehrere
- ,,teilen"
- beleuchtete
- sollte
- erklären
- zeigte
- zeigt
- Konzerte
- signifikant
- bedeutend
- ähnlich
- Ähnlich
- Umstände
- SIX
- Lösungen
- einige
- spezifisch
- gespalten
- Stufe
- Stufen
- Standard
- standardisiert
- standout
- Beginnen Sie
- statistisch
- statistisch
- Statistiken
- bleiben
- Schritt
- Shritte
- stand
- Geschichten
- Geschichte
- einfach
- Strategisch
- starker
- strukturierte
- Studie
- Studieren
- Folge
- vorschlagen
- Unterstützte
- sicher
- SVG
- schnell
- gezielt
- Techniken
- erzählt
- AGB
- Test
- Tests
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Gegend
- ihr
- dann
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Schwelle
- Durch
- während
- Zeit
- zu
- Werkzeug
- Werkzeuge
- verfolgen sind
- Transformieren
- Trends
- vertrauenswürdig
- WENDE
- Drehung
- XNUMX
- tippe
- Typen
- typisch
- verstehen
- Verständnis
- Bereiche
- enthüllt
- Präsentiert
- us
- -
- benutzt
- Verwendung von
- wertvoll
- Wert
- Werte
- Variable
- verschiedene
- Anzeigen
- vs
- Spaziergang
- geht
- wollen
- wurde
- Weg..
- we
- Wochen
- Gewicht
- GUT
- waren
- Was
- wann
- ob
- welche
- während
- warum
- werden wir
- mit
- .
- Arbeitsablauf.
- würde
- noch
- U
- Ihr
- Zach
- Zephyrnet