
20. September 2023
Grundlegende Modelle (FMs) markieren den Beginn einer neuen Ära in maschinelles Lernen (ML) und Künstliche Intelligenz (KI)Dies führt zu einer schnelleren Entwicklung von KI, die an eine Vielzahl nachgelagerter Aufgaben angepasst und für eine Reihe von Anwendungen feinabgestimmt werden kann.
Angesichts der zunehmenden Bedeutung der Datenverarbeitung dort, wo Arbeit ausgeführt wird, ermöglicht die Bereitstellung von KI-Modellen am Unternehmensrand nahezu Echtzeitvorhersagen unter Einhaltung der Anforderungen an Datensouveränität und Datenschutz. Durch die Kombination der IBM Watsonx Daten- und KI-Plattformfunktionen für FMs mit Edge-Computing können Unternehmen KI-Workloads für die FM-Feinabstimmung und Inferenzierung am operativen Rand ausführen. Dies ermöglicht es Unternehmen, KI-Bereitstellungen an der Edge zu skalieren und so den Zeit- und Kostenaufwand für die Bereitstellung durch schnellere Reaktionszeiten zu reduzieren.
Bitte schauen Sie sich unbedingt alle Teile dieser Reihe von Blogbeiträgen zum Thema Edge Computing an:
Was sind grundlegende Modelle?
Grundlagenmodelle (FMs), die auf einer breiten Menge unbeschrifteter Daten in großem Maßstab trainiert werden, treiben hochmoderne Anwendungen der künstlichen Intelligenz (KI) voran. Sie können an eine Vielzahl nachgelagerter Aufgaben angepasst und für eine Reihe von Anwendungen fein abgestimmt werden. Moderne KI-Modelle, die bestimmte Aufgaben in einer einzelnen Domäne ausführen, weichen FMs, weil sie allgemeiner lernen und domänen- und problemübergreifend arbeiten. Wie der Name schon sagt, kann ein FM die Grundlage für viele Anwendungen des KI-Modells sein.
FMs bewältigen zwei zentrale Herausforderungen, die Unternehmen davon abgehalten haben, die Einführung von KI voranzutreiben. Erstens produzieren Unternehmen eine große Menge unbeschrifteter Daten, von denen nur ein Bruchteil für das Training von KI-Modellen gekennzeichnet ist. Zweitens ist diese Beschriftungs- und Anmerkungsaufgabe äußerst arbeitsintensiv und erfordert oft mehrere hundert Stunden Zeit eines Fachexperten (KMU). Dies macht eine Skalierung über mehrere Anwendungsfälle hinweg zu kostenintensiv, da dafür Heerscharen von KMU und Datenexperten erforderlich wären. Durch die Aufnahme riesiger Mengen unbeschrifteter Daten und den Einsatz selbstüberwachter Techniken für das Modelltraining haben FMs diese Engpässe beseitigt und den Weg für eine breite Einführung von KI im gesamten Unternehmen geebnet. Diese riesigen Datenmengen, die in jedem Unternehmen vorhanden sind, warten darauf, freigesetzt zu werden, um Erkenntnisse zu gewinnen.
Was sind große Sprachmodelle?
Große Sprachmodelle (LLMs) sind eine Klasse grundlegender Modelle (FM), die aus Schichten von bestehen Neuronale Netze die mit diesen riesigen Mengen unbeschrifteter Daten trainiert wurden. Sie verwenden selbstüberwachte Lernalgorithmen, um eine Vielzahl von Aufgaben auszuführen Verarbeitung natürlicher Sprache (NLP) Aufgaben auf eine Art und Weise zu erledigen, die der Art und Weise ähnelt, wie Menschen Sprache verwenden (siehe Abbildung 1).
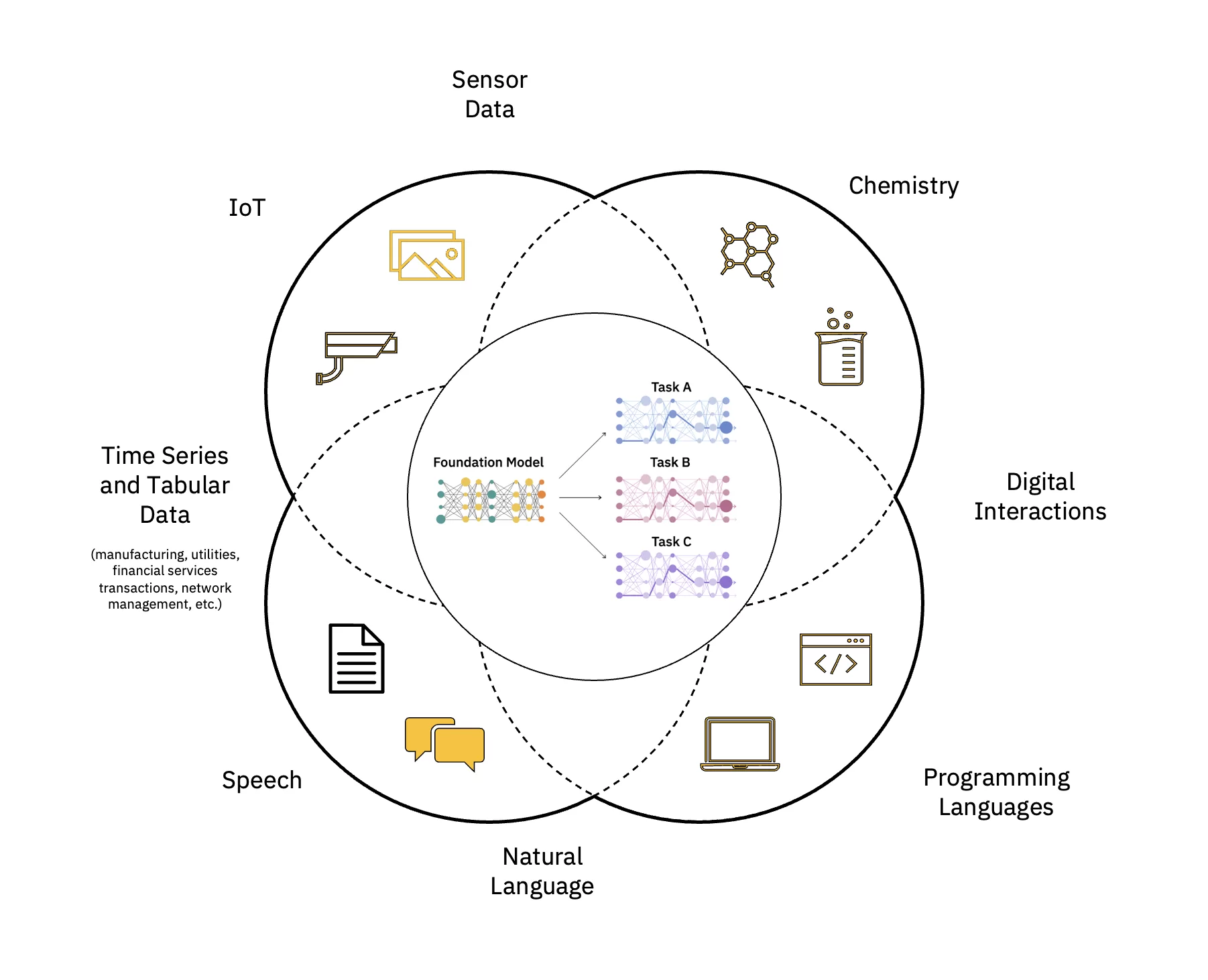
Skalieren und beschleunigen Sie die Wirkung von KI
Die Erstellung und Bereitstellung eines Basismodells (FM) umfasst mehrere Schritte. Dazu gehören Datenaufnahme, Datenauswahl, Datenvorverarbeitung, FM-Vorschulung, Modellabstimmung für eine oder mehrere nachgelagerte Aufgaben, Inferenzbereitstellung sowie Daten- und KI-Modell-Governance und Lebenszyklusmanagement – all dies kann als beschrieben werden FMOps.
Um all dies zu unterstützen, bietet IBM Unternehmen die notwendigen Tools und Funktionen an, um die Leistungsfähigkeit dieser FMs zu nutzen IBM Watsonx, eine unternehmenstaugliche KI- und Datenplattform, die darauf ausgelegt ist, die Wirkung von KI im gesamten Unternehmen zu vervielfachen. IBM watsonx besteht aus Folgendem:
- IBM watsonx.ai bringt Neues generative KI Funktionen – unterstützt durch FMs und traditionelles maschinelles Lernen (ML) – in ein leistungsstarkes Studio, das den gesamten KI-Lebenszyklus abdeckt.
- IBM watsonx.data ist ein zweckmäßiger Datenspeicher, der auf einer offenen Lakehouse-Architektur basiert, um KI-Workloads für alle Ihre Daten überall zu skalieren.
- IBM watsonx.governance ist ein durchgängig automatisiertes AI-Lifecycle-Governance-Toolkit, das darauf ausgelegt ist, verantwortungsvolle, transparente und erklärbare KI-Workflows zu ermöglichen.
Ein weiterer wichtiger Faktor ist die zunehmende Bedeutung der Datenverarbeitung am Unternehmensrand, beispielsweise an Industriestandorten, Fertigungshallen, Einzelhandelsgeschäften, Telekommunikationsrandstandorten usw. Genauer gesagt ermöglicht KI am Unternehmensrand die Verarbeitung von Daten dort, wo Arbeit ausgeführt wird Analyse nahezu in Echtzeit. Am Unternehmensrand werden riesige Mengen an Unternehmensdaten generiert und KI kann wertvolle, zeitnahe und umsetzbare Geschäftserkenntnisse liefern.
Die Bereitstellung von KI-Modellen an der Edge ermöglicht Vorhersagen nahezu in Echtzeit unter Einhaltung der Datensouveränitäts- und Datenschutzanforderungen. Dadurch wird die Latenzzeit, die häufig mit der Erfassung, Übertragung, Transformation und Verarbeitung von Inspektionsdaten verbunden ist, erheblich reduziert. Durch die Arbeit am Edge können wir sensible Unternehmensdaten schützen und die Datenübertragungskosten durch schnellere Reaktionszeiten senken.
Angesichts der Herausforderungen im Zusammenhang mit Daten (Heterogenität, Menge und Vorschriften) und begrenzten Ressourcen (Rechenleistung, Netzwerkkonnektivität, Speicher und sogar IT-Kenntnisse) ist die Skalierung von KI-Bereitstellungen am Rande jedoch keine leichte Aufgabe. Diese lassen sich grob in zwei Kategorien einteilen:
- Zeit/Kosten für die Bereitstellung: Jede Bereitstellung besteht aus mehreren Hardware- und Softwareebenen, die vor der Bereitstellung installiert, konfiguriert und getestet werden müssen. Heutzutage kann die Installation durch einen Servicetechniker bis zu ein oder zwei Wochen dauern an jedem Ort, Dies schränkt die schnelle und kosteneffektive Skalierung von Bereitstellungen im gesamten Unternehmen erheblich ein.
- Tag-2-Management: Aufgrund der großen Anzahl bereitgestellter Edges und der geografischen Lage jeder Bereitstellung kann es häufig unerschwinglich teuer werden, an jedem Standort lokalen IT-Support für die Überwachung, Wartung und Aktualisierung dieser Bereitstellungen bereitzustellen.
Edge-KI-Bereitstellungen
IBM hat eine Edge-Architektur entwickelt, die diese Herausforderungen angeht, indem sie ein integriertes Hardware-/Software-Appliance-Modell (HW/SW) in Edge-KI-Bereitstellungen einbringt. Es besteht aus mehreren Schlüsselparadigmen, die die Skalierbarkeit von KI-Bereitstellungen unterstützen:
- Richtlinienbasierte Zero-Touch-Bereitstellung des gesamten Software-Stacks.
- Kontinuierliche Überwachung des Zustands des Edge-Systems
- Funktionen zur Verwaltung und Übertragung von Software-/Sicherheits-/Konfigurationsaktualisierungen an zahlreiche Edge-Standorte – alles von einem zentralen cloudbasierten Standort aus für die Verwaltung am zweiten Tag.
Eine verteilte Hub-and-Spoke-Architektur kann zur Skalierung von KI-Bereitstellungen in Unternehmen am Edge genutzt werden, wobei eine zentrale Cloud oder ein Unternehmensrechenzentrum als Hub fungiert und die Edge-in-a-Box-Appliance als Spoke an einem Edge-Standort fungiert. Dieses Hub-and-Spoke-Modell, das sich über hybride Cloud- und Edge-Umgebungen erstreckt, veranschaulicht am besten die erforderliche Ausgewogenheit, um die für den FM-Betrieb erforderlichen Ressourcen optimal zu nutzen (siehe Abbildung 2).
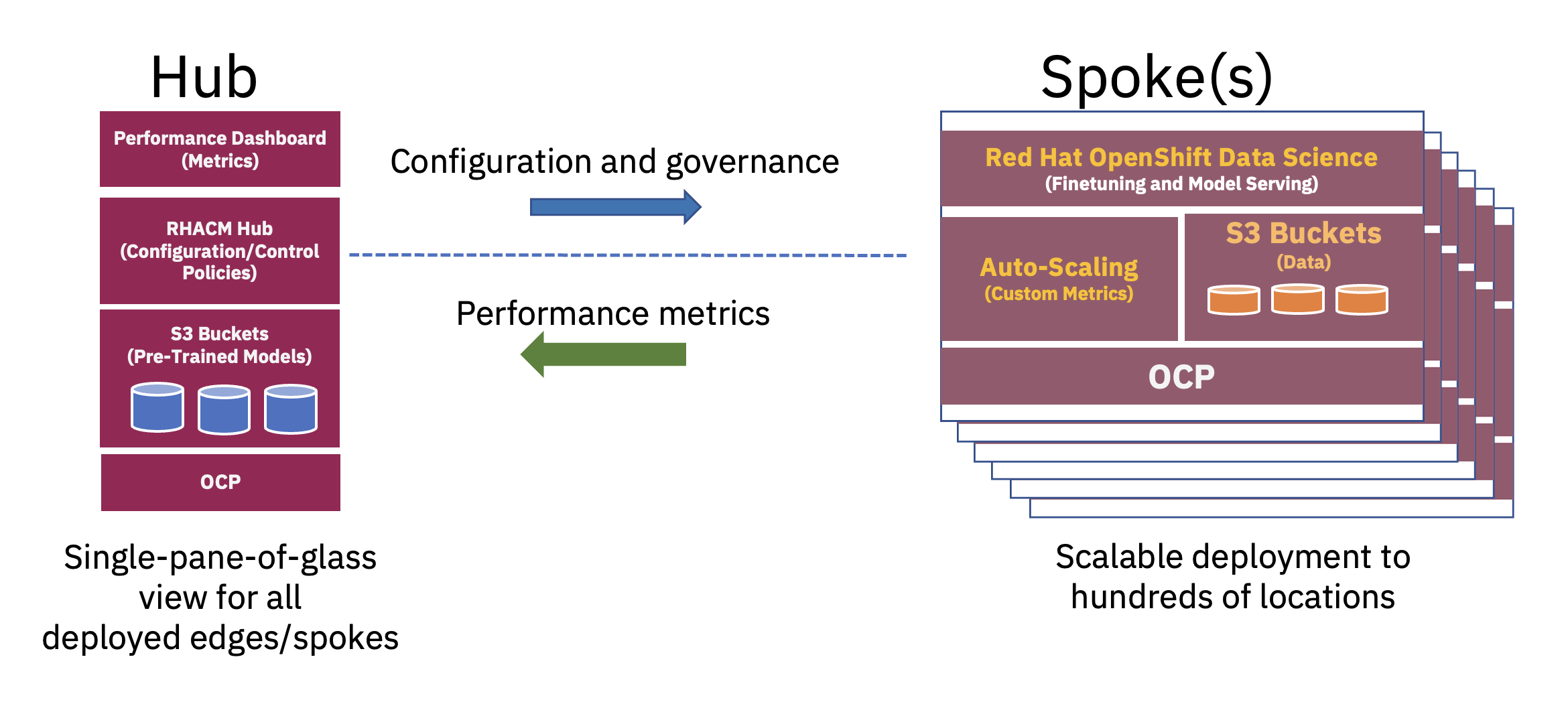
Das Vortraining dieser Basis-LLMs (Large Language Models) und anderer Arten von Basismodellen mithilfe selbstüberwachter Techniken an riesigen, unbeschrifteten Datensätzen erfordert häufig erhebliche Rechenressourcen (GPU) und wird am besten an einem Hub durchgeführt. Die praktisch unbegrenzten Rechenressourcen und großen Datenmengen, die häufig in der Cloud gespeichert werden, ermöglichen das Vortraining großer Parametermodelle und die kontinuierliche Verbesserung der Genauigkeit dieser Basismodelle.
Andererseits kann die Abstimmung dieser Basis-FMs für nachgelagerte Aufgaben – die nur einige Dutzend oder Hunderte gekennzeichneter Datenproben und Inferenzbereitstellung erfordern – mit nur wenigen GPUs am Unternehmensrand durchgeführt werden. Dies ermöglicht, dass vertrauliche gekennzeichnete Daten (oder Kronjuwelendaten des Unternehmens) sicher in der Betriebsumgebung des Unternehmens verbleiben und gleichzeitig die Kosten für die Datenübertragung gesenkt werden.
Mithilfe eines Full-Stack-Ansatzes für die Bereitstellung von Anwendungen am Rande kann ein Datenwissenschaftler die Feinabstimmung, das Testen und die Bereitstellung der Modelle durchführen. Dies kann in einer einzigen Umgebung erreicht werden und gleichzeitig den Entwicklungslebenszyklus für die Bereitstellung neuer KI-Modelle für die Endbenutzer verkürzen. Plattformen wie Red Hat OpenShift Data Science (RHODS) und das kürzlich angekündigte Red Hat OpenShift AI bieten Tools für die schnelle Entwicklung und Bereitstellung produktionsbereiter KI-Modelle verteilte Cloud und Edge-Umgebungen.
Schließlich reduziert die Bereitstellung des fein abgestimmten KI-Modells am Unternehmensrand die Latenz, die häufig mit der Erfassung, Übertragung, Transformation und Verarbeitung von Daten verbunden ist, erheblich. Durch die Entkopplung des Vortrainings in der Cloud von der Feinabstimmung und Inferenzierung am Rand werden die Gesamtbetriebskosten gesenkt, indem der Zeitaufwand und die Kosten für die Datenverschiebung im Zusammenhang mit Inferenzaufgaben reduziert werden (siehe Abbildung 3).
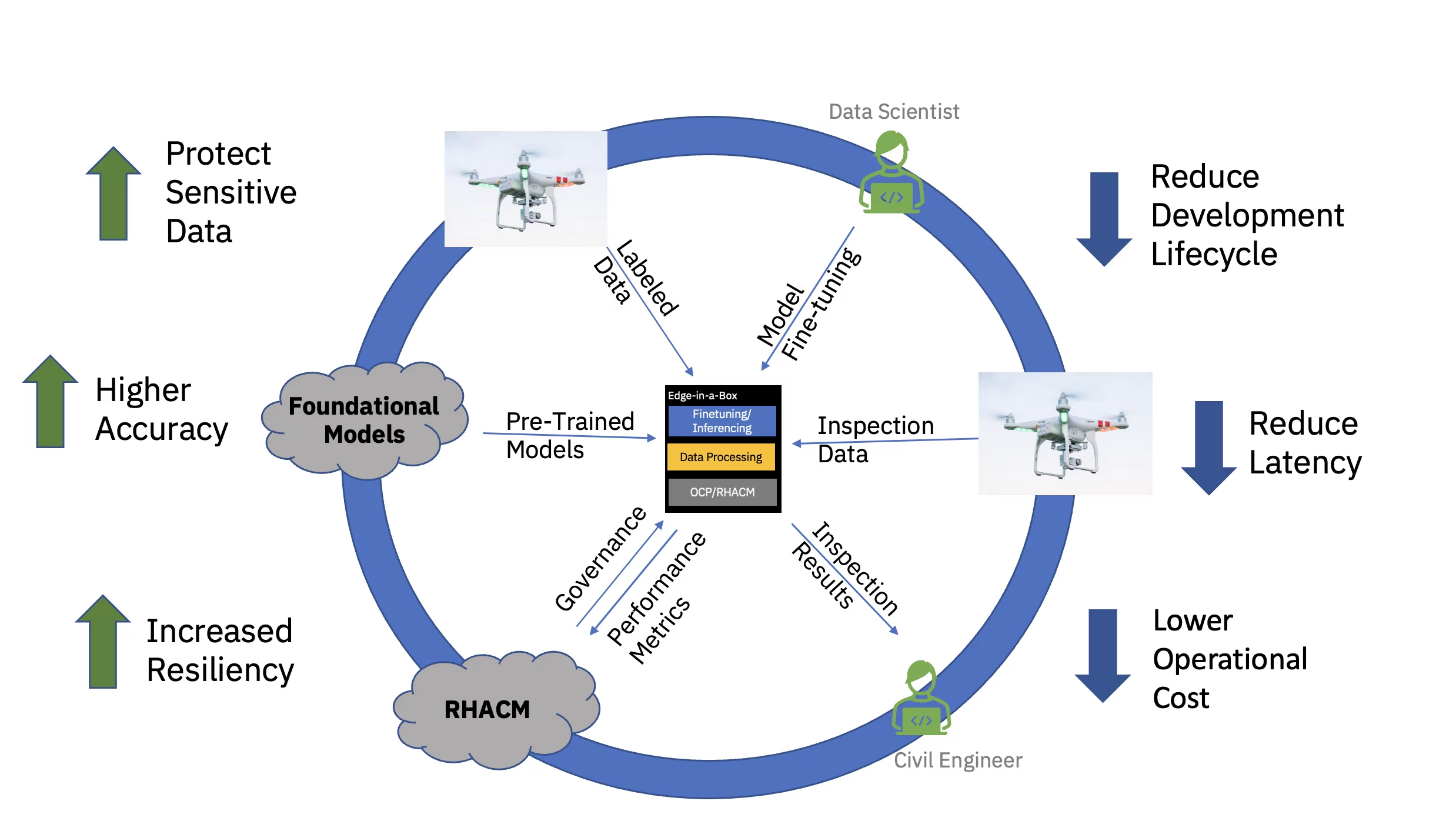
Um dieses Wertversprechen durchgängig zu demonstrieren, wurde ein beispielhaftes Vision-Transformer-basiertes Basismodell für die zivile Infrastruktur (vorab trainiert unter Verwendung öffentlicher und benutzerdefinierter branchenspezifischer Datensätze) verfeinert und zur Inferenz auf einem Drei-Knoten-Rand bereitgestellt (Speichen-)Cluster. Der Software-Stack umfasste die Red Hat OpenShift Container Platform und Red Hat OpenShift Data Science. Dieser Edge-Cluster war auch mit einer Instanz des Red Hat Advanced Cluster Management for Kubernetes (RHACM)-Hubs verbunden, der in der Cloud läuft.
Zero-Touch-Bereitstellung
Die richtlinienbasierte Zero-Touch-Bereitstellung erfolgte mit Red Hat Advanced Cluster Management for Kubernetes (RHACM) über Richtlinien und Platzierungs-Tags, die bestimmte Edge-Cluster an eine Reihe von Softwarekomponenten und -konfigurationen binden. Diese Softwarekomponenten – die sich über den gesamten Stack erstrecken und Rechenleistung, Speicher, Netzwerk und die KI-Arbeitslast abdecken – wurden mithilfe verschiedener OpenShift-Operatoren, Bereitstellung der erforderlichen Anwendungsdienste und S3-Bucket (Speicher) installiert.
Das vorab trainierte Basismodell (FM) für die zivile Infrastruktur wurde mithilfe eines Jupyter-Notebooks innerhalb von Red Hat OpenShift Data Science (RHODS) verfeinert. Dabei wurden gekennzeichnete Daten verwendet, um sechs Arten von Mängeln zu klassifizieren, die auf Betonbrücken gefunden wurden. Die Inferenzbereitstellung dieses fein abgestimmten FM wurde auch mithilfe eines Triton-Servers demonstriert. Darüber hinaus wurde die Überwachung des Zustands dieses Edge-Systems durch die Aggregation von Beobachtbarkeitsmetriken von den Hardware- und Softwarekomponenten über Prometheus zum zentralen RHACM-Dashboard in der Cloud ermöglicht. Unternehmen der zivilen Infrastruktur können diese FMs an ihren Edge-Standorten einsetzen und Drohnenbilder verwenden, um Fehler nahezu in Echtzeit zu erkennen – was die Zeit bis zur Einsicht verkürzt und die Kosten für die Übertragung großer Mengen hochauflösender Daten in und aus der Cloud senkt.
Zusammenfassung
Kombination IBM Watsonx Daten- und KI-Plattformfunktionen für Foundation Models (FMs) mit einer Edge-in-a-Box-Appliance ermöglichen es Unternehmen, KI-Workloads für die FM-Feinabstimmung und Inferenzierung am operativen Edge auszuführen. Diese Appliance kann komplexe Anwendungsfälle sofort verarbeiten und bildet das Hub-and-Spoke-Framework für zentralisierte Verwaltung, Automatisierung und Self-Service. Edge-FM-Bereitstellungen können von Wochen auf Stunden verkürzt werden, mit wiederholbarem Erfolg, höherer Ausfallsicherheit und Sicherheit.
Erfahren Sie mehr über grundlegende Modelle
Bitte schauen Sie sich unbedingt alle Teile dieser Reihe von Blogbeiträgen zum Thema Edge Computing an:
Mehr von Cloud




- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Über Uns
- beschleunigen
- Zugang
- erreicht
- Genauigkeit
- Erwerb
- über
- Handlungen
- angepasst
- zusätzlich
- Adresse
- Adressen
- Adoption
- advanced
- Fortschritte
- Marketings
- AI
- KI-Adoption
- KI-Modelle
- KI-Plattform
- Hilfe
- Algorithmen
- Alle
- erlauben
- erlaubt
- ebenfalls
- Inmitten
- Betrag
- Beträge
- amp
- an
- Analyse
- Analytik
- und
- angekündigt
- jedem
- von jedem Standort
- Anwendung
- Anwendungen
- Ansatz
- Architektur
- SIND
- Feld
- Artikel
- künstlich
- künstliche Intelligenz
- Künstliche Intelligenz (AI)
- AS
- damit verbundenen
- At
- Autor
- Automatisiert
- Automation
- verfügbar
- Avenue
- Zurück
- Balance
- Bank
- Banken
- Base
- BE
- weil
- werden
- Werden
- war
- Anfang
- Sein
- Glauben
- BESTE
- binden
- Blog
- Blog-Beiträge
- Blogs
- beide
- Box
- Brücken
- Bringing
- Brings
- breit
- allgemein
- Building
- baut
- erbaut
- Geschäft
- by
- CAN
- Fähigkeiten
- Hauptstadt
- Capturing
- Kohlenstoff
- Karte
- Karten
- Fälle
- CAT
- Kategorien
- Verursachen
- Center
- Hauptgeschäftsstelle
- Zentralbank
- digitale Währungen der Zentralbank
- zentralisierte
- Kette
- Herausforderungen
- Übernehmen
- Ändern
- aus der Ferne überprüfen
- Entscheidungen
- Kreise
- CIS
- zivil
- Klasse
- klassifizieren
- klar
- Kunden
- eng
- Cloud
- Cluster
- Farbe
- bunt
- Vereinigung
- wettbewerbsfähig
- Komplex
- Komplexität
- Compliance
- Komponenten
- Berechnen
- Computing
- Konfiguration
- konfiguriert
- Sie
- Konnektivität
- besteht
- Container
- fortsetzen
- Smartgeräte App
- Kosten
- Kosten
- könnte
- Abdeckung
- kryptowährung
- CSS
- Coins
- Original
- Kunde
- Customer Experience
- Kunden
- Armaturenbrett
- technische Daten
- Data Center
- Datenplattform
- Datenwissenschaft
- Datenwissenschaftler
- Datensätze
- Datum
- gewidmet
- Standard
- Definitionen
- Übergeben
- zeigen
- Synergie
- einsetzen
- Einsatz
- Bereitstellen
- Einsatz
- Implementierungen
- beschrieben
- Beschreibung
- entworfen
- entwickeln
- entwickelt
- Entwicklung
- digital
- digitale Währungen
- Digitalisierung
- Störung
- störend
- Disruptoren
- verteilt
- Bezirk
- Domain
- Domains
- erledigt
- Antrieb
- Fahren
- Drohne
- jeder
- Einfache
- Ökosystem
- Edge
- Edge-Computing
- ELEVATE
- erhöhten
- ermöglichen
- ermöglicht
- Ende
- End-to-End
- Ingenieur
- Entwicklung
- Enter
- Unternehmen
- Unternehmen
- eingehend
- Arbeitsumfeld
- Umgebungen
- Era
- insbesondere
- etc
- Äther (ETH)
- Sogar
- Veranstaltungen
- Jedes
- entwickelt
- Untersuchen
- Beispiele
- ausführen
- existieren
- Beenden
- teuer
- ERFAHRUNGEN
- Experten
- Erklärbare KI
- Erläuterung
- Verlängerung
- äußerst
- Faktoren
- FAST
- beschleunigt
- wenige
- Feld
- Abbildung
- Revolution
- Finanzinstitutionen
- Finanzierung
- Vorname
- Böden
- folgen
- Folgende
- Schriftarten
- Aussichten für
- Vordergrund
- gefunden
- Foundation
- Fraktion
- Unser Ansatz
- für
- voller
- Voller Stapel
- Außerdem
- allgemein
- erzeugt
- Generator
- geographisch
- Geopolitik
- Unterstützung
- Global
- Welthandel
- Governance
- GPU
- GPUs
- Gitter
- Pflege
- Griff
- Hardware
- Hut
- Haben
- Gesundheit
- Höhe
- Hilfe
- Unternehmen
- hilft
- High-Definition
- höher
- hoch
- Geschichte
- Gastgeber
- STUNDEN
- Ultraschall
- Hilfe
- aber
- HTTPS
- Nabe
- Humans
- hunderte
- Hybrid
- Hybride wolke
- IBM
- IBM Cloud
- ICO
- ICON
- zeigt
- Image
- Impact der HXNUMXO Observatorien
- Bedeutung
- Verbesserung
- in
- das
- inklusive
- zunehmend
- zunehmend
- Index
- industriell
- Branchen
- Energiegewinnung
- branchenspezifisch
- Inflation
- Flexion
- Wendepunkt
- beeinflusst
- Infrastruktur
- Initiative
- Innovation
- innovativ
- Eingänge
- Einblicke
- Instanz
- Institutionen
- integriert
- Intelligenz
- innere
- Einführung
- IT
- IT Support
- Reisen
- jpg
- springen
- Jupyter Notizbuch
- nur
- nur einer
- gehalten
- Wesentliche
- Kubernetes
- Beschriftung
- Sprache
- grosse
- weitgehend
- Latency
- neueste
- Lagen
- führenden
- LERNEN
- lernen
- Hebelwirkung
- Lebenszyklus
- Gefällt mir
- grenzenlos
- linux
- aus einer regionalen
- lokal
- Standorte
- Standorte
- Lang
- aussehen
- Maschine
- Maschinelles Lernen
- gemacht
- halten
- um
- MACHT
- verwalten
- Management
- Herstellung
- viele
- Markierung
- massiv
- Master
- Materie
- max-width
- Mechanismen
- Methoden
- Metrik
- Min.
- minimieren
- Minuten
- ML
- Mobil
- Modell
- für
- modern
- Modernisierung
- modernisieren
- Überwachen
- Überwachung
- mehr
- Bewegung
- ziehen um
- Name
- Menü
- In der Nähe von
- notwendig,
- Need
- erforderlich
- Bedürfnisse
- Netzwerk
- Neu
- weiter
- Nlp
- Notizbuch
- nichts
- jetzt an
- Anzahl
- und viele
- of
- bieten
- vorgenommen,
- on
- EINEM
- einzige
- XNUMXh geöffnet
- geöffnet
- Betriebs-
- Einkauf & Prozesse
- Betreiber
- optimiert
- or
- Organisation
- Andere
- UNSERE
- Gesamt-
- Pakete
- Seite
- Parameter
- Zahlung
- Zahlungsarten
- Zahlungen
- ausführen
- durchgeführt
- PHP
- Platzierung
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Plugin
- Points
- Politik durchzulesen
- Datenschutzrichtlinien
- Position
- möglich
- Post
- BLOG-POSTS
- Potenzial
- Werkzeuge
- größte treibende
- Prognosen
- Vor
- Datenschutz
- privat
- Probleme
- Verarbeitung
- produziert
- Professionell
- Vorschlag
- die
- Öffentlichkeit
- Push
- Angebot
- schnell
- Lesebrillen
- Echtzeit
- kürzlich
- Rekord
- Einspielung vor
- Rot
- Red Hat
- Veteran
- Reduziert
- reduziert
- Reduzierung
- Vorschriften
- Regulators
- Regulierungsbehörden
- bezogene
- Entfernt
- wiederholbar
- erfordern
- falls angefordert
- Voraussetzungen:
- Requisit
- Forschungsprojekte
- Downloads
- Antwort
- für ihren Verlust verantwortlich.
- ansprechbar
- Einzelhandel
- Rise
- Roboter
- Führen Sie
- Laufen
- sicher
- gleich
- Skalierbarkeit
- Skalieren
- Skala ai
- Skalierung
- Wissenschaft
- Wissenschaftler
- Bildschirm
- Skripte
- Zweite
- sicher
- Sicherheitdienst
- sehen
- Sehen
- Auswahl
- Selbstbedienung
- empfindlich
- seo
- September
- Modellreihe
- Server
- Lösungen
- Dienst
- Sitzung
- Sessions
- kompensieren
- mehrere
- Teilen
- erklären
- signifikant
- bedeutend
- ähnlich
- da
- Singapur
- Single
- einzelne Umgebung
- am Standort
- Seiten
- SIX
- Fähigkeiten
- klein
- KMU
- KMU
- Software
- Softwarekomponenten
- Lösung
- Souveränität
- Raumfahrt
- überspannend
- spezifisch
- speziell
- Sponsored
- Stapel
- Anfang
- State-of-the-art
- bleiben
- Shritte
- Lagerung
- speichern
- gelagert
- Läden
- Sturm
- Studio Adressen
- Fach
- Erfolg
- so
- Schlägt vor
- liefern
- Supply Chain
- Support
- sicher
- System
- Nehmen
- gemacht
- Aufgabe
- und Aufgaben
- Techniken
- Technologie
- Telco
- Temenos
- Zehn
- Terraform
- getestet
- Testen
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Thema
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Durch
- Zeit
- rechtzeitig
- mal
- Titel
- zu
- heute
- gemeinsam
- Toolkit
- Werkzeuge
- Top
- Handel
- traditionell
- Training
- trainiert
- Ausbildung
- privaten Transfer
- Transformieren
- Transformation
- Transformationen
- transparent
- Triton
- XNUMX
- tippe
- Typen
- entfesselt
- Aktualisierung
- Updates
- URL
- us
- -
- benutzt
- Nutzer
- Verwendung von
- Nutzen
- seit
- wertvoll
- Wert
- Value Proposition
- Vielfalt
- verschiedene
- riesig
- Anzeigen
- praktisch
- Volumen
- Volumen
- W
- Warten
- Wallet
- wurde
- Wave
- Weg..
- Wege
- we
- Woche
- Wochen
- Was
- Was ist
- wann
- welche
- während
- WHO
- warum
- breit
- Große Auswahl
- mit
- .
- Frau
- WordPress
- Arbeiten
- Workflows
- arbeiten,
- würde
- geschrieben
- Ihr
- Zephyrnet











