Viele kleine und große Organisationen arbeiten daran, ihre Analyse-Workloads auf Amazon Web Services (AWS) zu migrieren und zu modernisieren. Es gibt viele Gründe für Kunden, zu AWS zu migrieren, aber einer der Hauptgründe ist die Möglichkeit, vollständig verwaltete Dienste zu nutzen, anstatt Zeit mit der Wartung der Infrastruktur, Patches, Überwachung, Backups und mehr zu verbringen. Führungs- und Entwicklungsteams können mehr Zeit damit verbringen, aktuelle Lösungen zu optimieren und sogar mit neuen Anwendungsfällen zu experimentieren, anstatt die aktuelle Infrastruktur zu warten.
Da Sie mit AWS schnell vorankommen können, müssen Sie bei der weiteren Skalierung auch verantwortungsvoll mit den Daten umgehen, die Sie empfangen und verarbeiten. Zu diesen Verantwortlichkeiten gehört die Einhaltung von Datenschutzgesetzen und -vorschriften und die Nichtspeicherung oder Offenlegung sensibler Daten wie personenbezogener Daten (PII) oder geschützter Gesundheitsinformationen (PHI) aus vorgelagerten Quellen.
In diesem Beitrag gehen wir eine allgemeine Architektur und einen spezifischen Anwendungsfall durch, der zeigt, wie Sie die Datenplattform Ihres Unternehmens weiter skalieren können, ohne viel Entwicklungszeit für die Bewältigung von Datenschutzbedenken aufwenden zu müssen. Wir gebrauchen AWS-Kleber um PII-Daten vor dem Laden zu erkennen, zu maskieren und zu schwärzen Amazon OpenSearch-Dienst.
Lösungsüberblick
Das folgende Diagramm veranschaulicht die übergeordnete Lösungsarchitektur. Wir haben alle Ebenen und Komponenten unseres Designs im Einklang mit definiert AWS Well-Architected Framework Data Analytics Lens.
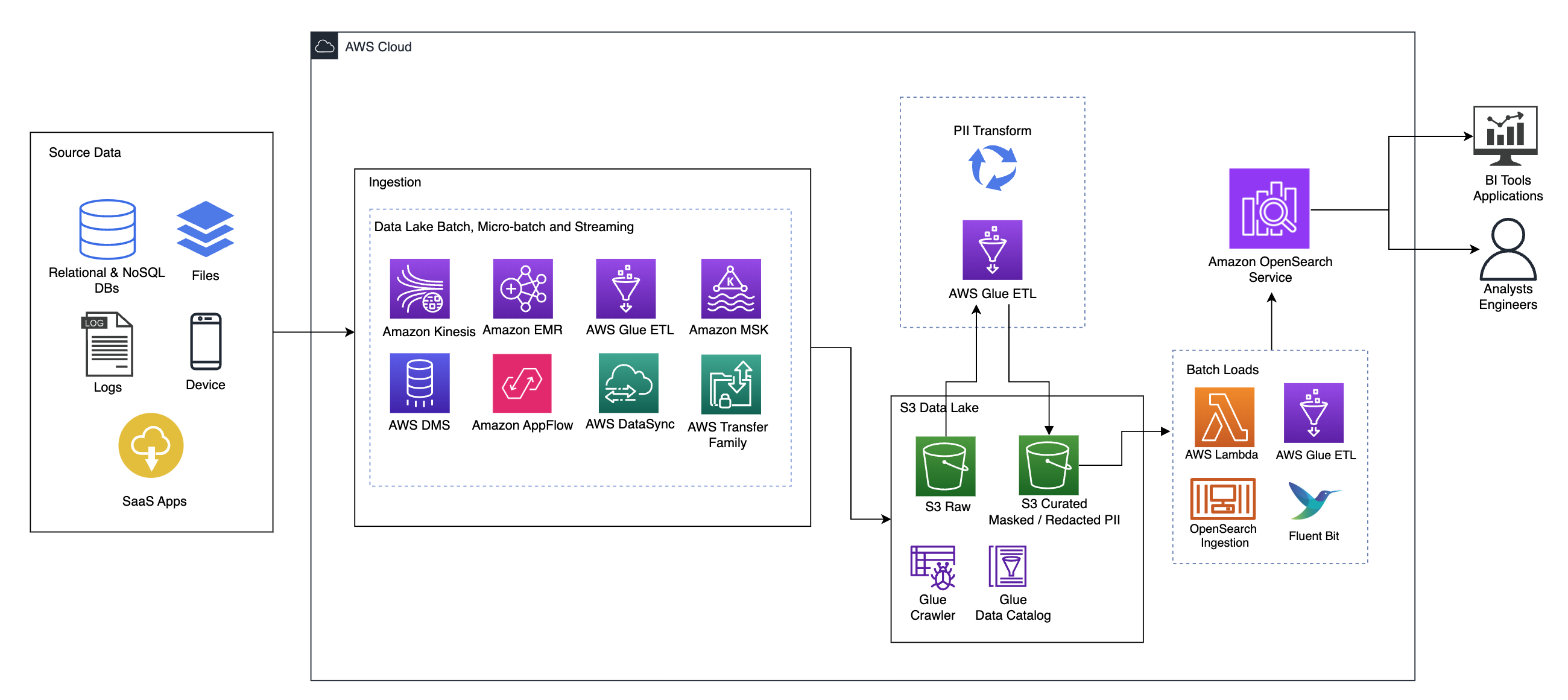
Die Architektur besteht aus mehreren Komponenten:
Quelldaten
Daten können aus Dutzenden bis Hunderten von Quellen stammen, darunter Datenbanken, Dateiübertragungen, Protokolle, Software-as-a-Service-Anwendungen (SaaS) und mehr. Unternehmen haben möglicherweise nicht immer die Kontrolle darüber, welche Daten über diese Kanäle in ihre nachgelagerten Speicher und Anwendungen gelangen.
Aufnahme: Data Lake Batch, Micro-Batch und Streaming
Viele Unternehmen laden ihre Quelldaten auf verschiedene Weise in ihren Data Lake ein, einschließlich Batch-, Micro-Batch- und Streaming-Jobs. Zum Beispiel, Amazon EMR, AWS-Kleber und AWS-Datenbankmigrationsservice (AWS DMS) können alle zum Ausführen von Batch- und/oder Streaming-Vorgängen verwendet werden, die in einen Datensee übergehen Amazon Simple Storage-Service (Amazon S3). Amazon App-Flow kann verwendet werden, um Daten aus verschiedenen SaaS-Anwendungen in einen Data Lake zu übertragen. AWS DataSync und AWS-Übertragungsfamilie kann beim Verschieben von Dateien zu und von einem Data Lake über eine Reihe verschiedener Protokolle helfen. Amazon Kinesis und Amazon MSK verfügen außerdem über die Möglichkeit, Daten direkt in einen Data Lake auf Amazon S3 zu streamen.
S3-Datensee
Die Verwendung von Amazon S3 für Ihren Data Lake entspricht der modernen Datenstrategie. Es bietet kostengünstigen Speicher ohne Einbußen bei Leistung, Zuverlässigkeit oder Verfügbarkeit. Mit diesem Ansatz können Sie Ihre Daten nach Bedarf mit Rechenleistung ausstatten und zahlen nur für die Kapazität, die sie zum Betrieb benötigen.
In dieser Architektur können Rohdaten aus verschiedenen Quellen (intern und extern) stammen, die möglicherweise sensible Daten enthalten.
Mithilfe von AWS Glue-Crawlern können wir die Daten erkennen und katalogisieren, wodurch die Tabellenschemata für uns erstellt werden. Dadurch wird es letztendlich einfacher, AWS Glue ETL mit der PII-Transformation zu verwenden, um eventuell eingetroffene sensible Daten zu erkennen, zu maskieren oder zu schwärzen im Datensee.
Geschäftskontext und Datensätze
Um den Wert unseres Ansatzes zu demonstrieren, stellen wir uns vor, Sie wären Teil eines Data-Engineering-Teams für ein Finanzdienstleistungsunternehmen. Ihre Anforderungen bestehen darin, sensible Daten zu erkennen und zu maskieren, während sie in die Cloud-Umgebung Ihres Unternehmens aufgenommen werden. Die Daten werden von nachgelagerten Analyseprozessen verarbeitet. Zukünftig können Ihre Benutzer historische Zahlungstransaktionen basierend auf Datenströmen, die aus internen Banksystemen gesammelt werden, sicher durchsuchen. Suchergebnisse von Betriebsteams, Kunden und Schnittstellenanwendungen müssen in sensiblen Feldern maskiert werden.
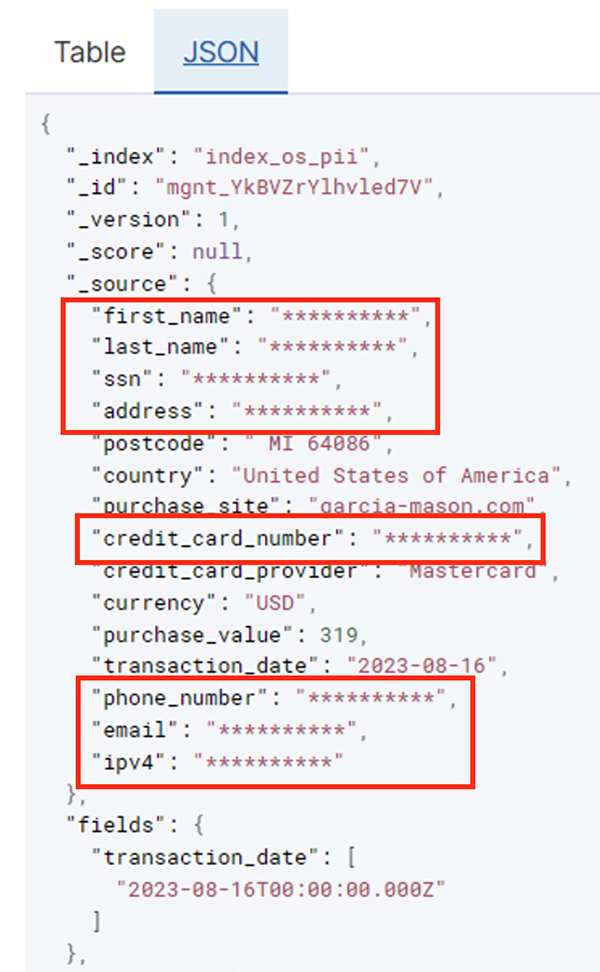
Die folgende Tabelle zeigt die für die Lösung verwendete Datenstruktur. Aus Gründen der Übersichtlichkeit haben wir die Namen der Rohspalten den kuratierten Spaltennamen zugeordnet. Sie werden feststellen, dass mehrere Felder in diesem Schema als vertrauliche Daten gelten, z. B. Vorname, Nachname, Sozialversicherungsnummer (SSN), Adresse, Kreditkartennummer, Telefonnummer, E-Mail und IPv4-Adresse.
| Roher Spaltenname | Kuratierter Spaltenname | Typ |
| c0 | Vorname | Schnur |
| c1 | Familienname, Nachname | Schnur |
| c2 | ssn | Schnur |
| c3 | Adresse | Schnur |
| c4 | Postleitzahl | Schnur |
| c5 | Land | Schnur |
| c6 | Kaufseite | Schnur |
| c7 | Kreditkartennummer | Schnur |
| c8 | kreditkartenanbieter | Schnur |
| c9 | Währung | Schnur |
| c10 | Einkaufswert | ganze Zahl |
| c11 | Transaktionsdatum | Datum |
| c12 | Telefonnummer | Schnur |
| c13 | Schnur | |
| c14 | ipv4 | Schnur |
Anwendungsfall: PII-Batch-Erkennung vor dem Laden in den OpenSearch-Dienst
Kunden, die die folgende Architektur implementieren, haben ihren Data Lake auf Amazon S3 aufgebaut, um verschiedene Arten von Analysen im großen Maßstab auszuführen. Diese Lösung eignet sich für Kunden, die keine Echtzeitaufnahme in den OpenSearch Service benötigen und Datenintegrationstools verwenden möchten, die nach einem Zeitplan ausgeführt oder durch Ereignisse ausgelöst werden.
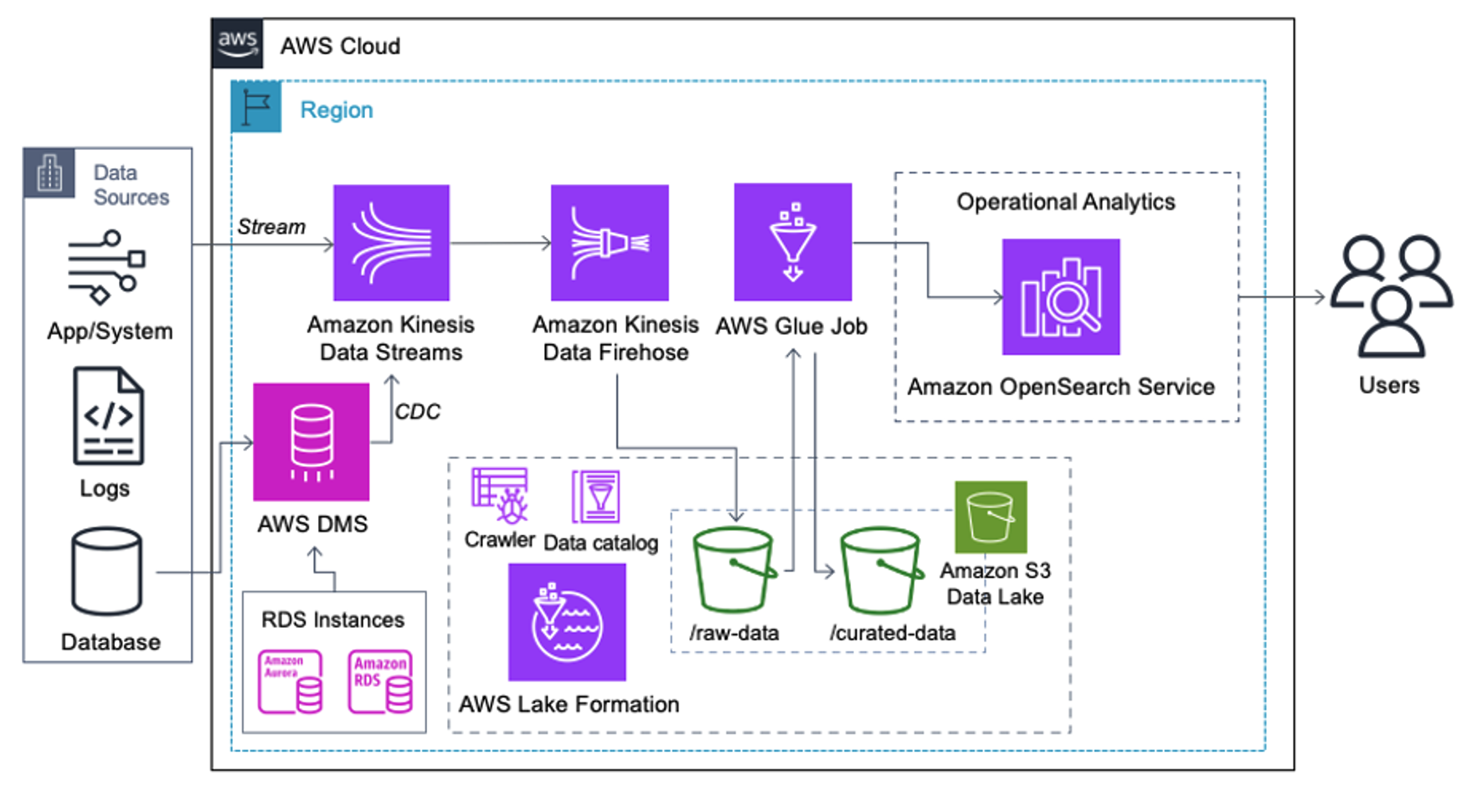
Bevor Datensätze auf Amazon S3 landen, implementieren wir eine Ingestion-Schicht, um alle Datenströme zuverlässig und sicher in den Data Lake zu bringen. Kinesis Data Streams wird als Aufnahmeschicht für die beschleunigte Aufnahme strukturierter und halbstrukturierter Datenströme eingesetzt. Beispiele hierfür sind relationale Datenbankänderungen, Anwendungen, Systemprotokolle oder Clickstreams. Für Anwendungsfälle der Change Data Capture (CDC) können Sie Kinesis Data Streams als Ziel für AWS DMS verwenden. Anwendungen oder Systeme, die Streams mit vertraulichen Daten generieren, werden über eine der drei unterstützten Methoden an den Kinesis-Datenstream gesendet: den Amazon Kinesis Agent, das AWS SDK für Java oder die Kinesis Producer Library. Als letzten Schritt Amazon Kinesis Data Firehose hilft uns, Datenstapel nahezu in Echtzeit zuverlässig in unser S3-Data-Lake-Ziel zu laden.
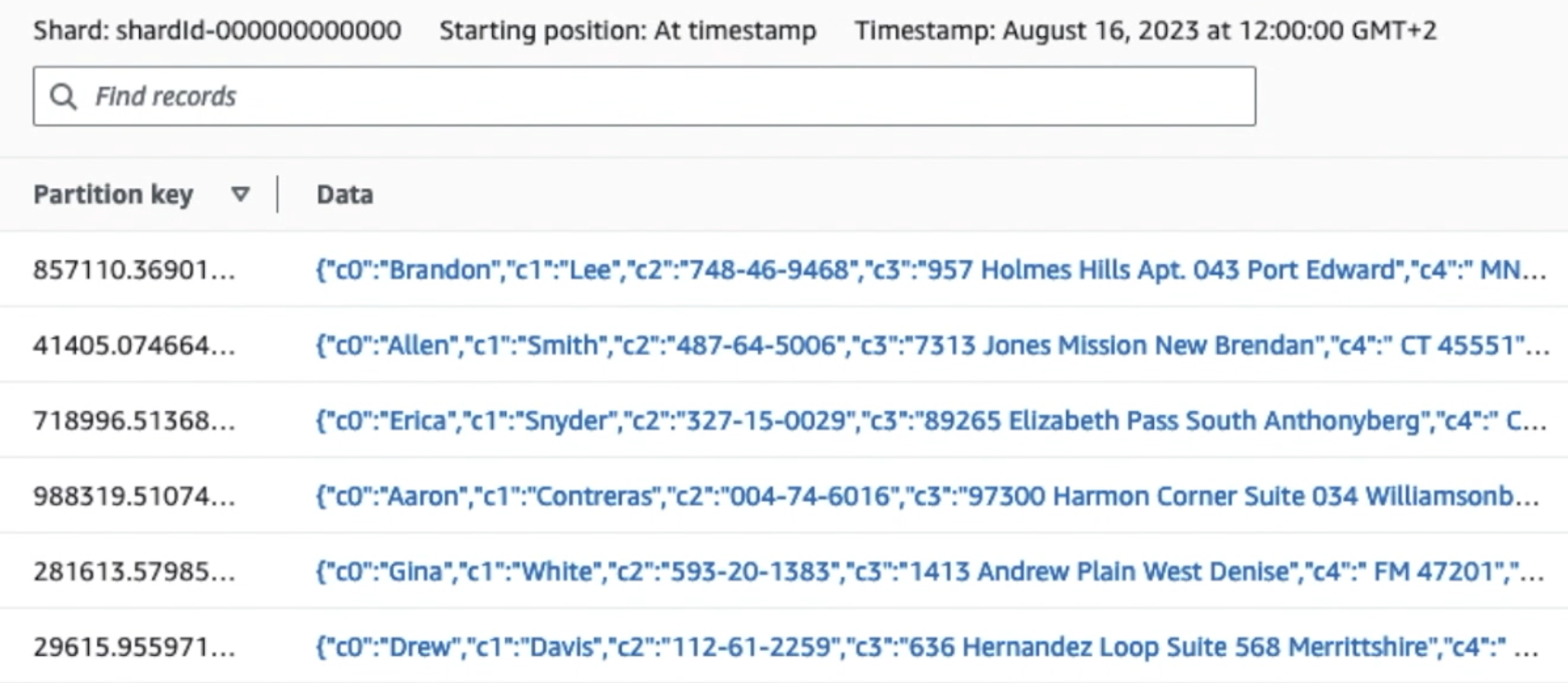
Der folgende Screenshot zeigt, wie Daten über Kinesis Data Streams fließen Daten-Viewer und ruft Beispieldaten ab, die auf dem rohen S3-Präfix landen. Für diese Architektur haben wir den Datenlebenszyklus für S3-Präfixe befolgt, wie in empfohlen Data-Lake-Stiftung.
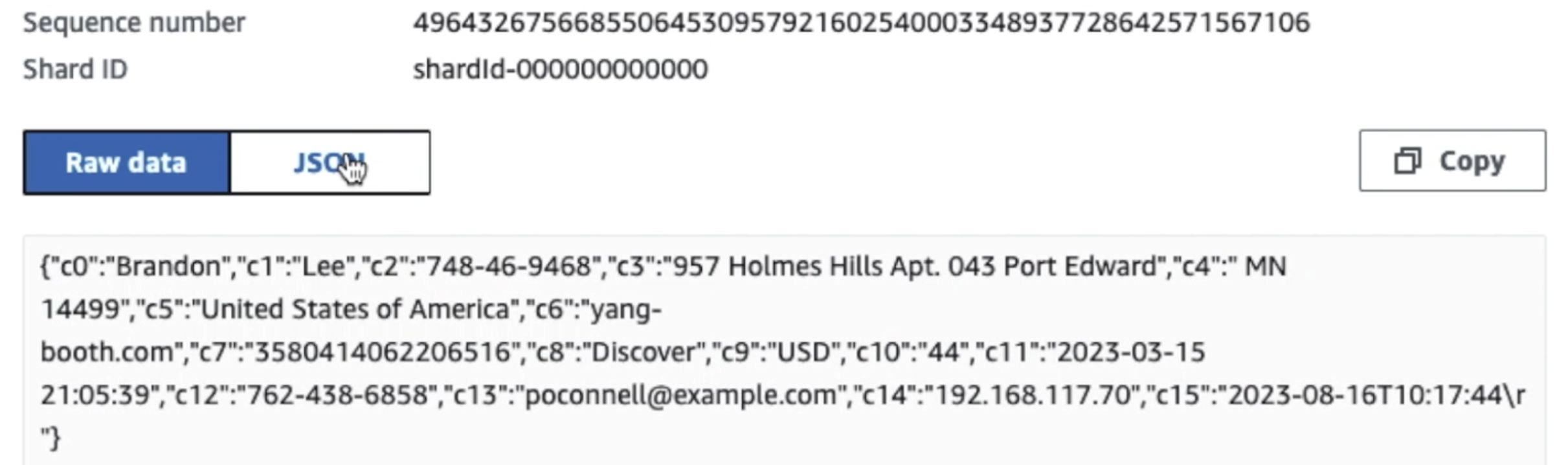
Wie Sie den Details des ersten Datensatzes im folgenden Screenshot entnehmen können, folgt die JSON-Nutzlast demselben Schema wie im vorherigen Abschnitt. Sie können sehen, wie die nicht redigierten Daten in den Kinesis-Datenstrom fließen, der später in nachfolgenden Phasen verschleiert wird.
Nachdem die Daten gesammelt und in Kinesis Data Streams aufgenommen und mithilfe von Kinesis Data Firehose an den S3-Bucket übermittelt wurden, übernimmt die Verarbeitungsschicht der Architektur. Wir verwenden die AWS Glue PII-Transformation, um die Erkennung und Maskierung sensibler Daten in unserer Pipeline zu automatisieren. Wie im folgenden Workflow-Diagramm dargestellt, haben wir einen visuellen ETL-Ansatz ohne Code gewählt, um unseren Transformationsauftrag in AWS Glue Studio zu implementieren.
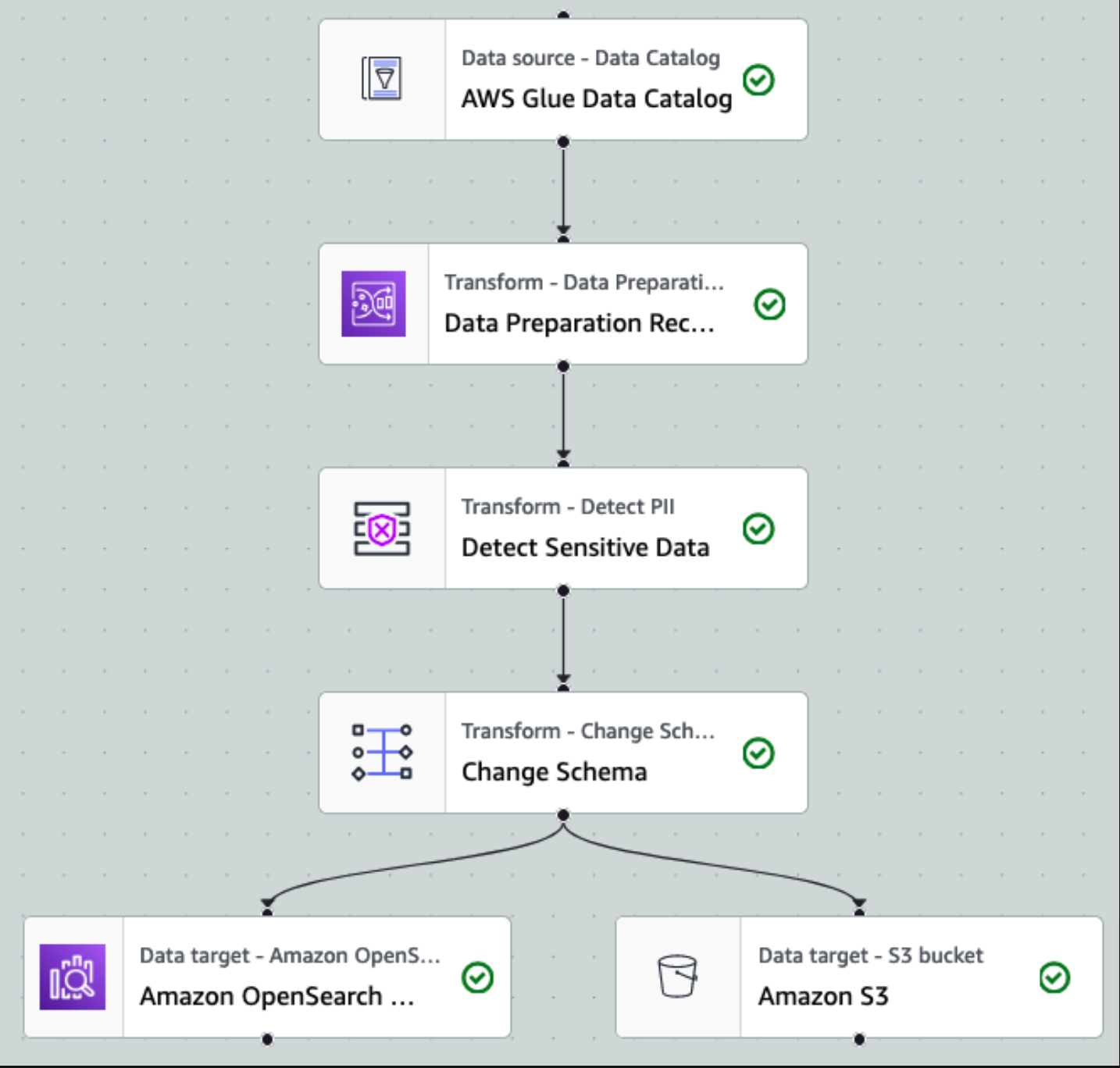
Zuerst greifen wir im Rohformat auf die Quelldatenkatalogtabelle zu pii_data_db Datenbank. Die Tabelle weist die im vorherigen Abschnitt dargestellte Schemastruktur auf. Um den Überblick über die verarbeiteten Rohdaten zu behalten, haben wir verwendet Job-Lesezeichen.

Wir nutzen die AWS Glue DataBrew-Rezepte im visuellen ETL-Job von AWS Glue Studio Um zwei Datumsattribute so umzuwandeln, dass sie mit OpenSearch kompatibel sind, wird erwartet Formate. Dies ermöglicht uns ein vollständiges No-Code-Erlebnis.
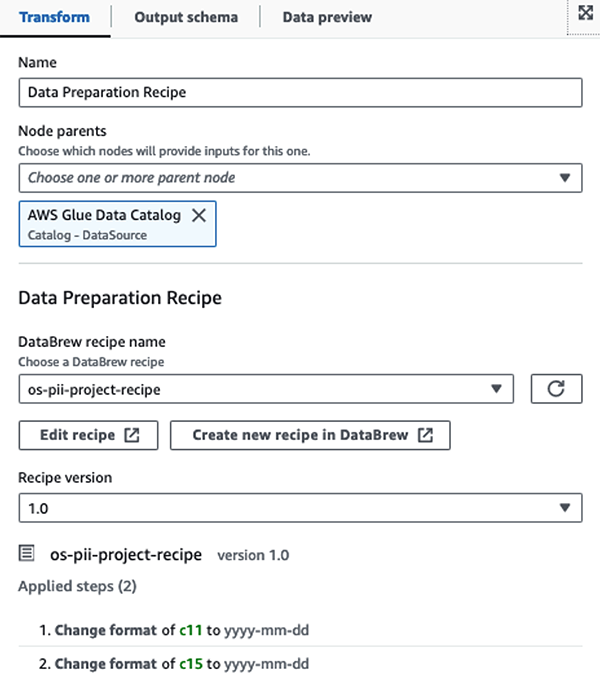
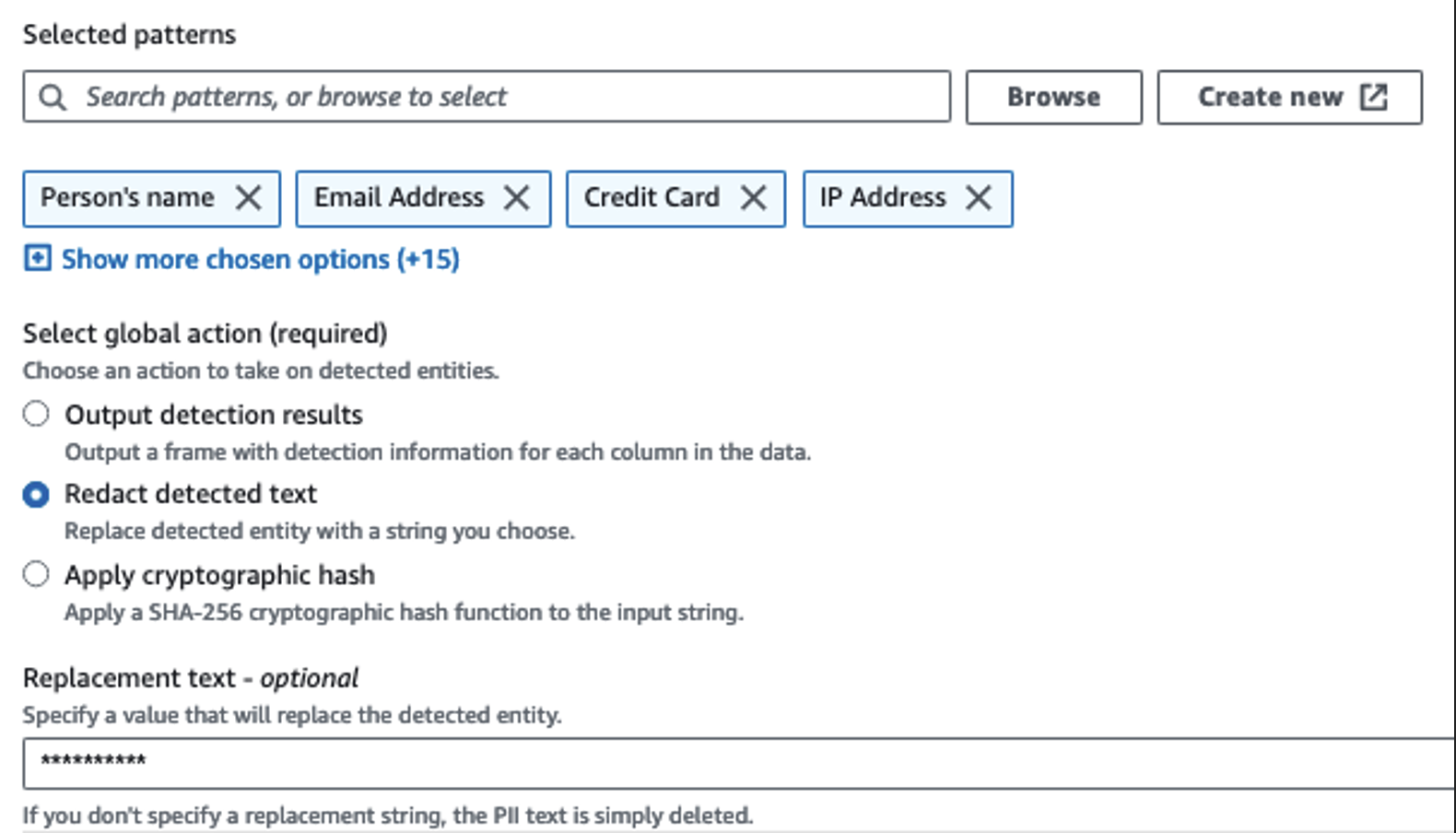
Wir verwenden die Aktion „PII erkennen“, um sensible Spalten zu identifizieren. Wir lassen dies von AWS Glue anhand ausgewählter Muster, Erkennungsschwellenwerten und Stichprobenanteilen von Zeilen aus dem Datensatz ermitteln. In unserem Beispiel haben wir Muster verwendet, die speziell für die USA gelten (z. B. SSNs) und möglicherweise keine sensiblen Daten aus anderen Ländern erkennen. Sie können nach verfügbaren Kategorien und Standorten suchen, die für Ihren Anwendungsfall gelten, oder reguläre Ausdrücke (Regex) in AWS Glue verwenden, um Erkennungseinheiten für sensible Daten aus anderen Ländern zu erstellen.
Es ist wichtig, die richtige Stichprobenmethode auszuwählen, die AWS Glue bietet. In diesem Beispiel ist bekannt, dass die aus dem Stream eingehenden Daten in jeder Zeile vertrauliche Daten enthalten, sodass es nicht erforderlich ist, 100 % der Zeilen im Datensatz abzutasten. Wenn Sie eine Anforderung haben, bei der keine sensiblen Daten an nachgelagerte Quellen weitergegeben werden dürfen, sollten Sie erwägen, 100 % der Daten für die von Ihnen gewählten Muster abzufragen, oder den gesamten Datensatz zu scannen und auf jede einzelne Zelle zu reagieren, um sicherzustellen, dass alle sensiblen Daten erkannt werden. Der Vorteil, den Sie durch die Stichprobenerhebung erzielen, sind geringere Kosten, da Sie nicht so viele Daten scannen müssen.

Mit der Aktion „PII erkennen“ können Sie beim Maskieren vertraulicher Daten eine Standardzeichenfolge auswählen. In unserem Beispiel verwenden wir die Zeichenfolge **********.
Wir verwenden den Vorgang „Zuordnung anwenden“, um unnötige Spalten umzubenennen und zu entfernen, z ingestion_year, ingestion_month und ingestion_day. Dieser Schritt ermöglicht es uns auch, den Datentyp einer der Spalten zu ändern (purchase_value) von String zu Integer.

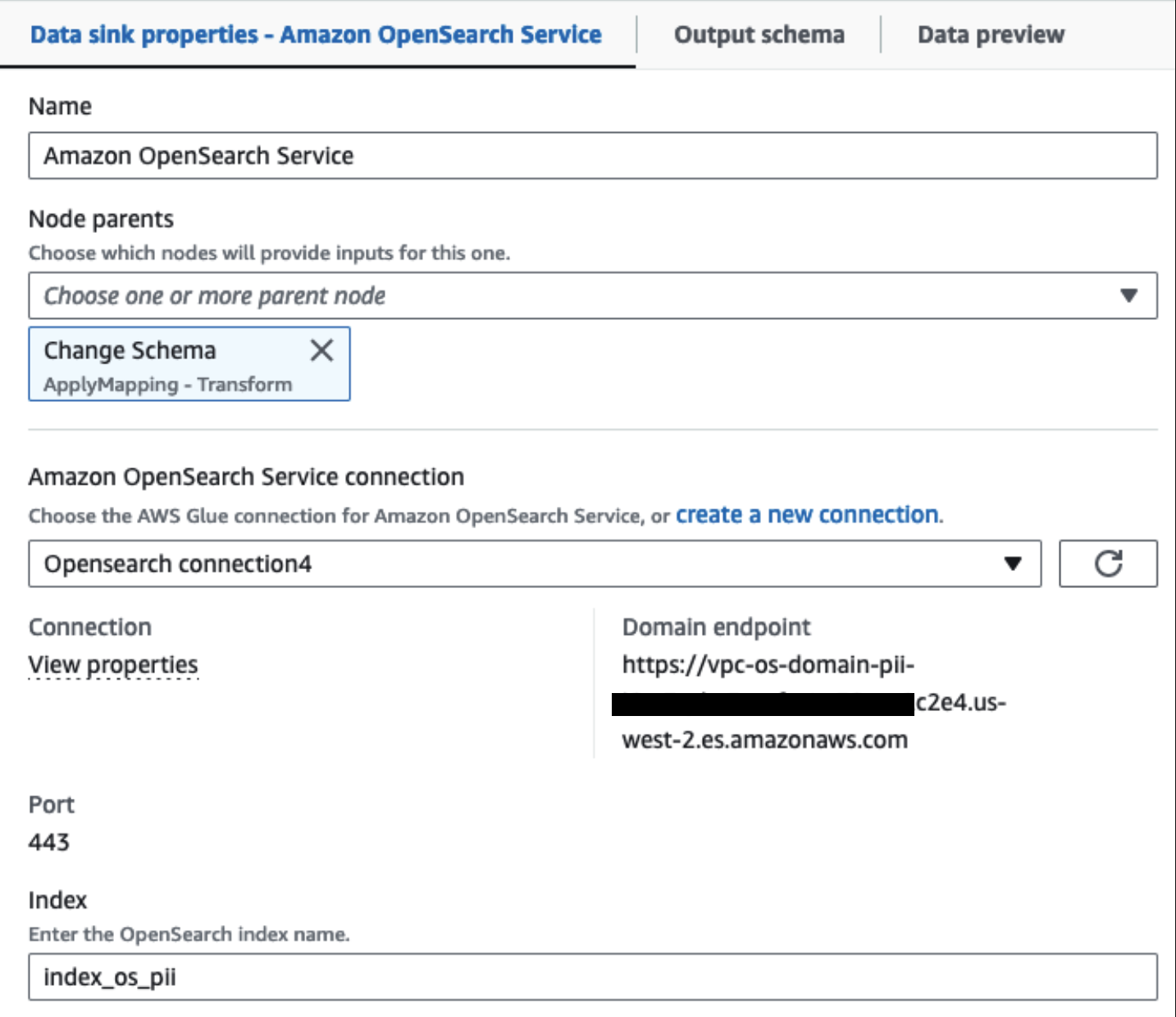
Ab diesem Zeitpunkt teilt sich der Job in zwei Ausgabeziele auf: OpenSearch Service und Amazon S3.
Unser bereitgestellter OpenSearch Service-Cluster ist über verbunden Integrierter OpenSearch-Connector für Glue. Wir geben den OpenSearch-Index an, in den wir schreiben möchten, und der Connector verwaltet die Anmeldeinformationen, die Domäne und den Port. Im Screenshot unten schreiben wir in den angegebenen Index index_os_pii.
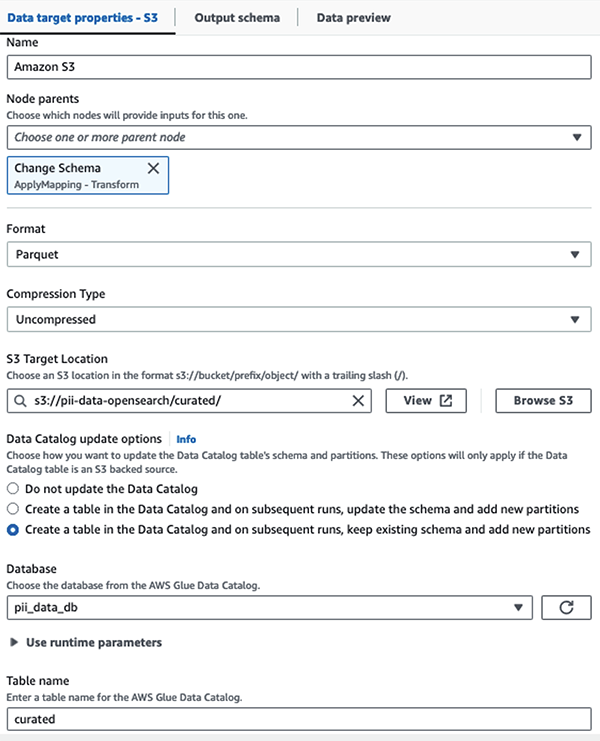
Wir speichern den maskierten Datensatz im kuratierten S3-Präfix. Dort verfügen wir über Daten, die auf einen bestimmten Anwendungsfall normalisiert und von Datenwissenschaftlern oder für Ad-hoc-Berichtsanforderungen sicher genutzt werden können.
Für eine einheitliche Governance, Zugriffskontrolle und Audit-Trails aller Datensätze und Datenkatalogtabellen können Sie Folgendes verwenden: AWS Lake-Formation. Dadurch können Sie den Zugriff auf die AWS Glue Data Catalog-Tabellen und die zugrunde liegenden Daten nur auf die Benutzer und Rollen beschränken, denen die erforderlichen Berechtigungen dafür erteilt wurden.
Nachdem der Batch-Job erfolgreich ausgeführt wurde, können Sie den OpenSearch-Dienst zum Ausführen von Suchabfragen oder Berichten verwenden. Wie im folgenden Screenshot gezeigt, maskierte die Pipeline vertrauliche Felder automatisch und ohne Code-Entwicklungsaufwand.

Anhand der Betriebsdaten können Sie Trends erkennen, z. B. die Anzahl der Transaktionen pro Tag, gefiltert nach Kreditkartenanbieter, wie im vorherigen Screenshot dargestellt. Sie können auch die Standorte und Domänen bestimmen, an denen Benutzer Einkäufe tätigen. Der transaction_date Das Attribut hilft uns, diese Trends im Zeitverlauf zu erkennen. Der folgende Screenshot zeigt einen Datensatz, in dem alle Informationen zur Transaktion entsprechend geschwärzt sind.
Alternative Methoden zum Laden von Daten in Amazon OpenSearch finden Sie unter Laden von Streaming-Daten in den Amazon OpenSearch Service.
Darüber hinaus können sensible Daten auch mit anderen AWS-Lösungen entdeckt und maskiert werden. Sie könnten zum Beispiel verwenden Amazon Macie um sensible Daten in einem S3-Bucket zu erkennen und dann zu verwenden Amazon verstehen um die erkannten sensiblen Daten zu schwärzen. Weitere Informationen finden Sie unter Gängige Techniken zur Erkennung von PHI- und PII-Daten mithilfe von AWS Services.
Zusammenfassung
In diesem Beitrag wurde die Bedeutung des Umgangs mit sensiblen Daten in Ihrer Umgebung sowie verschiedene Methoden und Architekturen erörtert, um die Einhaltung der Vorschriften zu gewährleisten und gleichzeitig eine schnelle Skalierung Ihres Unternehmens zu ermöglichen. Sie sollten nun gut wissen, wie Sie Ihre Daten erkennen, maskieren oder redigieren und in Amazon OpenSearch Service laden.
Über die Autoren
 Michael Hamilton ist Senior Analytics Solutions Architect und konzentriert sich darauf, Unternehmenskunden bei der Modernisierung und Vereinfachung ihrer Analyse-Workloads auf AWS zu unterstützen. Er fährt gerne Mountainbike und verbringt in seiner Freizeit gerne Zeit mit seiner Frau und seinen drei Kindern.
Michael Hamilton ist Senior Analytics Solutions Architect und konzentriert sich darauf, Unternehmenskunden bei der Modernisierung und Vereinfachung ihrer Analyse-Workloads auf AWS zu unterstützen. Er fährt gerne Mountainbike und verbringt in seiner Freizeit gerne Zeit mit seiner Frau und seinen drei Kindern.
 Daniel Roso ist Senior Solutions Architect bei AWS und unterstützt Kunden in den Niederlanden. Seine Leidenschaft ist die Entwicklung einfacher Daten- und Analyselösungen und die Unterstützung von Kunden bei der Umstellung auf moderne Datenarchitekturen. Außerhalb der Arbeit spielt er gerne Tennis und Fahrrad.
Daniel Roso ist Senior Solutions Architect bei AWS und unterstützt Kunden in den Niederlanden. Seine Leidenschaft ist die Entwicklung einfacher Daten- und Analyselösungen und die Unterstützung von Kunden bei der Umstellung auf moderne Datenarchitekturen. Außerhalb der Arbeit spielt er gerne Tennis und Fahrrad.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :hast
- :Ist
- :nicht
- :Wo
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- Fähigkeit
- Fähig
- beschleunigt
- Zugang
- Handlung
- Action
- Ad
- Adresse
- Makler
- Alle
- erlaubt
- Zulassen
- erlaubt
- ebenfalls
- immer
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- Betrag
- Beträge
- an
- Analytische
- Analytik
- und
- jedem
- anwendbar
- Anwendungen
- Jetzt bewerben
- Ansatz
- passend
- Architektur
- SIND
- AS
- At
- Attribute
- Prüfung
- automatisieren
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Verfügbarkeit
- verfügbar
- AWS
- AWS-Kleber
- Sicherungen
- Bankinggg
- Bankensysteme
- basierend
- BE
- weil
- war
- Bevor
- Sein
- unten
- Nutzen
- bringen
- bauen
- erbaut
- eingebaut
- aber
- by
- CAN
- Fähigkeiten
- Kapazität
- Erfassung
- Karte
- Häuser
- Fälle
- Katalog
- Kategorien
- CDC
- Zelle
- Übernehmen
- Änderungen
- Kanäle
- weltweit
- wählten
- Clarity
- Cloud
- Cluster
- Code
- Kolonne
- Spalten
- wie die
- kommt
- Kommen
- kompatibel
- konform
- Komponenten
- Bestehend
- Berechnen
- Bedenken
- Sie
- Geht davon
- betrachtet
- verbraucht
- Verbrauch
- enthalten
- Kontext
- fortsetzen
- Smartgeräte App
- und beseitigen Muskelschwäche
- Kosten
- könnte
- Ländern
- erstellen
- Referenzen
- Kredit
- Kreditkarte
- kuratiert
- Strom
- Kunden
- technische Daten
- Datenanalyse
- Datenintegration
- Datensee
- Datenplattform
- Datenschutz
- Datenstrategie
- Datenbase
- Datenbanken
- Datensätze
- Datum
- Tag
- Standard
- definiert
- geliefert
- zeigen
- zeigt
- Einsatz
- Design
- Reiseziel
- Reiseziele
- Details
- entdecken
- erkannt
- Entdeckung
- Bestimmen
- Entwicklung
- Entwicklungsteams
- anders
- Direkt
- entdeckt,
- entdeckt
- diskutiert
- do
- Domain
- Domains
- Nicht
- jeder
- Bemühungen
- Entwicklung
- gewährleisten
- Unternehmen
- Unternehmenskunden
- Ganz
- Entitäten
- Arbeitsumfeld
- Äther (ETH)
- Sogar
- Veranstaltungen
- Jedes
- Beispiel
- Beispiele
- erwartet
- ERFAHRUNGEN
- Ausdrücke
- extern
- FAST
- Felder
- Reichen Sie das
- Mappen
- Revolution
- Finanzdienstleistungen
- Vorname
- Fließen
- Fließt
- Fokussierung
- gefolgt
- Folgende
- folgt
- Aussichten für
- Unser Ansatz
- für
- voller
- voll
- Zukunft
- Erzeugung
- bekommen
- gut
- Governance
- erteilt
- Griffe
- Handling
- Haben
- he
- Gesundheit
- Gesundheitsinformationen
- Hilfe
- Unternehmen
- hilft
- High-Level
- seine
- historisch
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- hunderte
- identifizieren
- if
- zeigt
- Bild
- implementieren
- Bedeutung
- wichtig
- in
- das
- Einschließlich
- Index
- Krankengymnastik
- Information
- Infrastruktur
- innerhalb
- Integration
- intern
- in
- IT
- Javac
- Job
- Jobs
- jpg
- JSON
- Behalten
- Kinesis Data Firehose
- Kinesis-Datenströme
- bekannt
- See
- Land
- landet
- grosse
- Nachname
- später
- Gesetze
- Gesetze und Richtlinien
- Schicht
- Lagen
- Leadership
- lassen
- Bibliothek
- Lebenszyklus
- Gefällt mir
- Line
- Belastung
- Laden
- Standorte
- aussehen
- kostengünstig
- Main
- Aufrechterhaltung
- um
- verwaltet
- viele
- Mapping
- Maske"
- Kann..
- Methode
- Methoden
- migriert
- Migration
- modern
- modernisieren
- Überwachung
- mehr
- Mountain
- schlauer bewegen
- ziehen um
- viel
- mehrere
- sollen
- Name
- Namen
- notwendig,
- Need
- erforderlich
- benötigen
- Bedürfnisse
- Niederlande
- Neu
- nicht
- Fiber Node
- Notiz..
- jetzt an
- Anzahl
- of
- Angebote
- on
- EINEM
- einzige
- Betrieb
- Betriebs-
- Einkauf & Prozesse
- Optimierung
- Optionen
- or
- Organisation
- Organisationen
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- aussen
- übrig
- Teil
- Leidenschaft & KREATIVITÄT
- Patchen
- Muster
- AUFMERKSAMKEIT
- Zahlung
- für
- ausführen
- Leistung
- Berechtigungen
- Persönlich
- Telefon
- pii
- Pipeline
- Plan
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Points
- Teil
- Post
- vor
- vorgeführt
- früher
- Datenschutz
- Datenschutzgesetze
- verarbeitet
- anpassen
- Verarbeitung
- Hersteller
- geschützt
- Protokolle
- Versorger
- bietet
- Einkäufe
- Abfragen
- schnell
- lieber
- Roh
- Rohdaten
- Echtzeit
- Gründe
- Empfang
- Rezepte
- empfohlen
- Rekord
- Aufzeichnungen
- Reduziert
- siehe
- regulär
- Vorschriften
- Zuverlässigkeit
- bleiben
- entfernen
- Reporting
- Meldungen
- erfordern
- Anforderung
- Voraussetzungen:
- Verantwortlichkeiten
- für ihren Verlust verantwortlich.
- eine Beschränkung
- Die Ergebnisse
- Rollen
- REIHE
- Führen Sie
- läuft
- SaaS
- opfern
- Safe
- sicher
- gleich
- Skalieren
- Scan
- Zeitplan
- Wissenschaftler
- Bildschirm
- Sdk
- Suche
- Abschnitt
- sicher
- Sicherheitdienst
- sehen
- wählen
- ausgewählt
- Senior
- empfindlich
- geschickt
- Dienstleistungen
- Schuss
- sollte
- gezeigt
- Konzerte
- Einfacher
- vereinfachen
- klein
- So
- Social Media
- Software
- Software als Service
- Lösung
- Lösungen
- Quelle
- Quellen
- spezifisch
- speziell
- angegeben
- verbringen
- Ausgabe
- Spagat
- Stufen
- Staaten
- Schritt
- Lagerung
- speichern
- einfach
- Strategie
- Strom
- Streaming
- Ströme
- Schnur
- Struktur
- strukturierte
- Studio Adressen
- Folge
- Erfolgreich
- so
- geeignet
- Unterstützte
- Unterstützung
- System
- Systeme und Techniken
- Tabelle
- nimmt
- Target
- Team
- Teams
- Techniken
- Tennis
- Zehn
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- Niederlande
- Die Quelle
- ihr
- dann
- Dort.
- Diese
- fehlen uns die Worte.
- diejenigen
- nach drei
- Schwelle
- Durch
- Zeit
- zu
- nahm
- Werkzeuge
- verfolgen sind
- Transaktionen
- privaten Transfer
- Transfers
- Transformieren
- Transformation
- Trends
- ausgelöst
- XNUMX
- tippe
- Typen
- Letztlich
- zugrunde liegen,
- Verständnis
- einheitlich
- Vereinigt
- USA
- us
- -
- Anwendungsfall
- benutzt
- Nutzer
- Verwendung von
- Wert
- Vielfalt
- verschiedene
- visuell
- Spaziergang
- wurde
- Wege
- we
- Netz
- Web-Services
- Was
- wann
- welche
- während
- WHO
- Frau
- werden wir
- mit
- .
- ohne
- Arbeiten
- Arbeitsablauf.
- arbeiten,
- schreiben
- U
- Ihr
- Zephyrnet