Bild vom Autor
Wenn Sie in die Welt der Datenwissenschaft und des maschinellen Lernens eintauchen, ist die Kunst, Daten zu lesen, eine der grundlegenden Fähigkeiten, auf die Sie stoßen werden. Wenn Sie bereits Erfahrung damit haben, kennen Sie wahrscheinlich JSON (JavaScript Object Notation) – ein beliebtes Format sowohl zum Speichern als auch zum Austauschen von Daten.
Denken Sie daran, wie gerne NoSQL-Datenbanken wie MongoDB Daten in JSON speichern oder wie REST-APIs oft im gleichen Format reagieren.
Allerdings eignet sich JSON zwar perfekt für die Speicherung und den Austausch, ist jedoch in seiner Rohform noch nicht ganz bereit für eine eingehende Analyse. Hier verwandeln wir es in etwas analytischeres, freundlicheres – ein tabellarisches Format.
Ganz gleich, ob Sie es mit einem einzelnen JSON-Objekt oder einer Vielzahl davon zu tun haben, in Pythons Worten handelt es sich im Wesentlichen um ein Diktat oder eine Liste von Diktaten.
Lassen Sie uns gemeinsam erkunden, wie sich diese Transformation entwickelt und unsere Daten für die Analyse reif machen ????
Heute erkläre ich einen magischen Befehl, mit dem wir jeden JSON-Code in Sekundenschnelle in ein Tabellenformat umwandeln können.
Und es ist… pd.json_normalize()
Sehen wir uns also an, wie es mit verschiedenen Arten von JSONs funktioniert.
Der erste JSON-Typ, mit dem wir arbeiten können, sind einstufige JSONs mit wenigen Schlüsseln und Werten. Wir definieren unsere ersten einfachen JSONs wie folgt:
Code nach Autor
Lassen Sie uns also die Notwendigkeit simulieren, mit diesem JSON zu arbeiten. Wir alle wissen, dass es in ihrem JSON-Format nicht viel zu tun gibt. Wir müssen diese JSONs in ein lesbares und modifizierbares Format umwandeln … und zwar in Pandas DataFrames!
1.1 Umgang mit einfachen JSON-Strukturen
Zuerst müssen wir die Pandas-Bibliothek importieren und dann können wir den Befehl pd.json_normalize() wie folgt verwenden:
import pandas as pd
pd.json_normalize(json_string)
Indem wir diesen Befehl auf ein JSON mit einem einzelnen Datensatz anwenden, erhalten wir die grundlegendste Tabelle. Wenn unsere Daten jedoch etwas komplexer sind und eine Liste von JSONs darstellen, können wir immer noch denselben Befehl ohne weitere Komplikationen verwenden und die Ausgabe entspricht einer Tabelle mit mehreren Datensätzen.

Bild vom Autor
Einfach richtig?
Die nächste natürliche Frage ist, was passiert, wenn einige Werte fehlen.
1.2 Umgang mit Nullwerten
Stellen Sie sich vor, dass einige Werte nicht mitgeteilt werden, wie zum Beispiel, dass der Einkommensdatensatz für David fehlt. Bei der Umwandlung unseres JSON in einen einfachen Pandas-Datenrahmen wird der entsprechende Wert als NaN angezeigt.
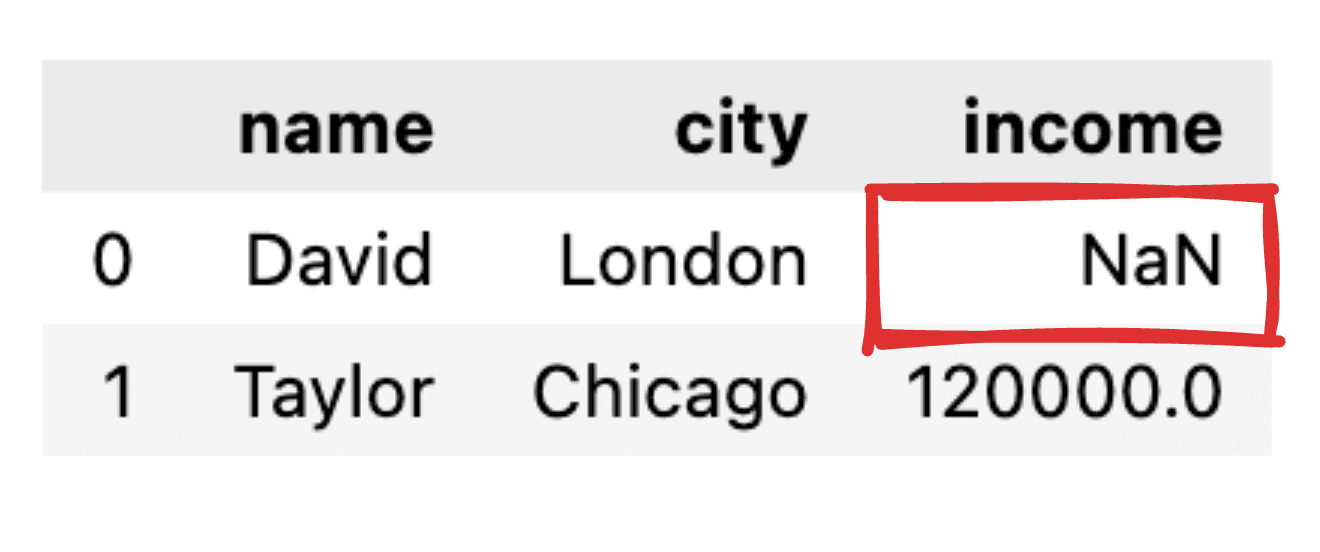
Bild vom Autor
Und was ist, wenn ich nur einige der Felder haben möchte?
1.3 Auswahl nur der interessanten Spalten
Falls wir nur einige bestimmte Felder in einen tabellarischen Pandas-DataFrame umwandeln möchten, können wir mit dem Befehl json_normalize() nicht auswählen, welche Felder transformiert werden sollen.
Daher sollte eine kleine Vorverarbeitung des JSON durchgeführt werden, bei der wir nur die interessierenden Spalten filtern.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Kommen wir also zu einer fortgeschritteneren JSON-Struktur.
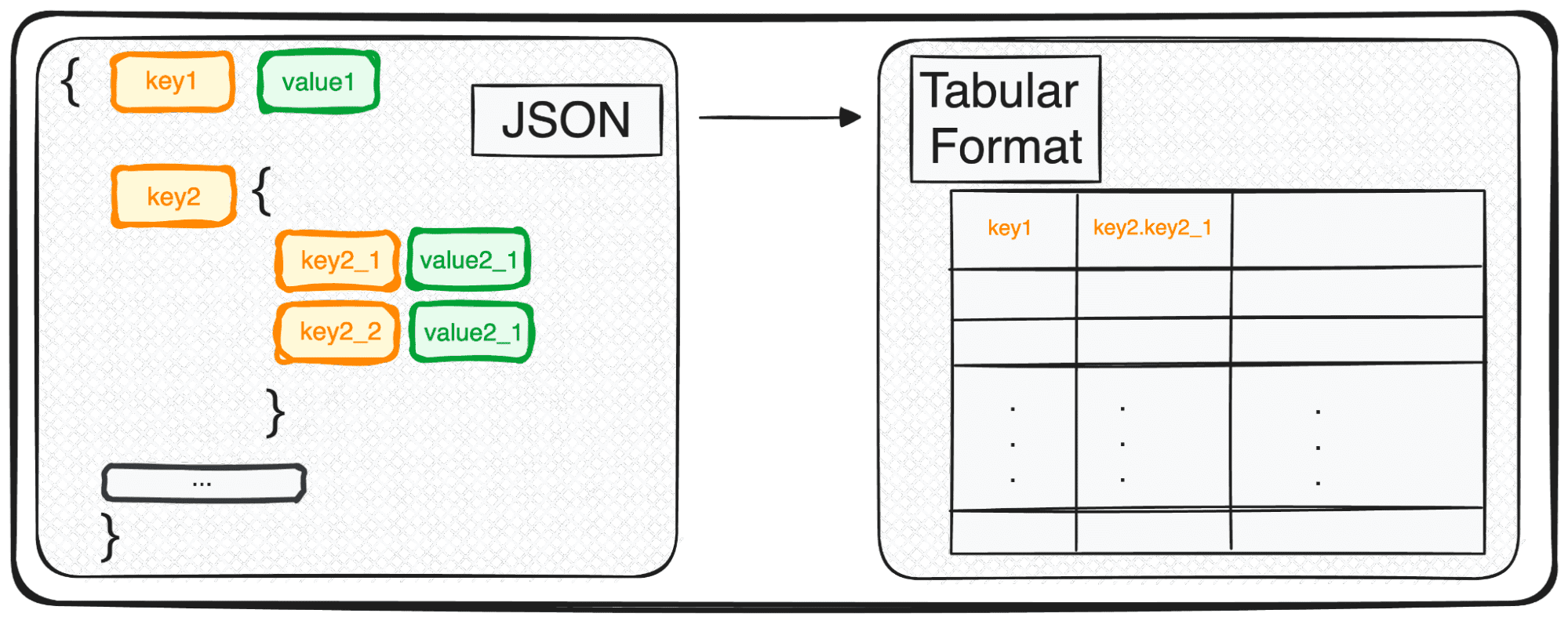
Wenn wir mit mehrstufigen JSONs arbeiten, sehen wir uns mit verschachtelten JSONs auf verschiedenen Ebenen konfrontiert. Die Vorgehensweise ist die gleiche wie zuvor, aber in diesem Fall können wir wählen, wie viele Ebenen wir transformieren möchten. Standardmäßig erweitert der Befehl immer alle Ebenen und generiert neue Spalten, die die verketteten Namen aller verschachtelten Ebenen enthalten.
Wenn wir also die folgenden JSONs normalisieren.
Code nach Autor
Wir würden die folgende Tabelle mit 3 Spalten unter den Feldkenntnissen erhalten:
- skills.python
- skills.SQL
- skills.GCP
und 4 Spalten unter dem Feld Rollen
- Rollen.Projektmanager
- Rollen.Dateningenieur
- Rollen. Datenwissenschaftler
- Rollen.Datenanalyst

Bild vom Autor
Stellen Sie sich jedoch vor, wir wollen nur unsere oberste Ebene umgestalten. Wir können dies tun, indem wir den Parameter max_level gezielt auf 0 definieren (den max_level, den wir erweitern möchten).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Die ausstehenden Werte werden in JSONs in unserem Pandas DataFrame verwaltet.
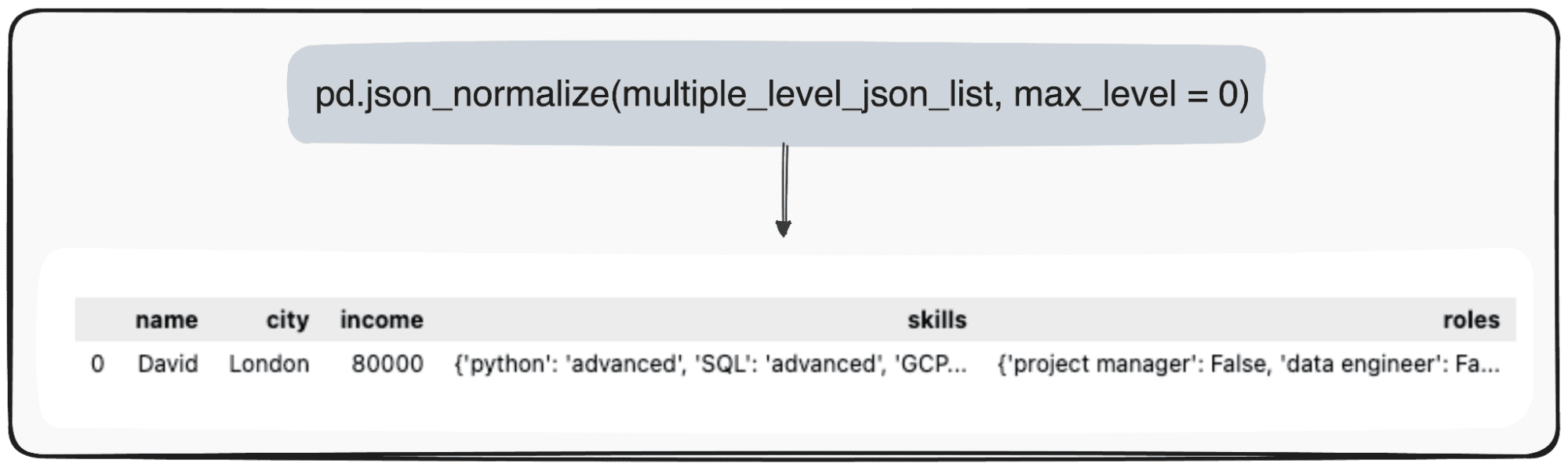
Bild vom Autor
Der letzte Fall, den wir finden können, ist eine verschachtelte Liste in einem JSON-Feld. Daher definieren wir zunächst unsere zu verwendenden JSONs.
Code nach Autor
Mit Pandas in Python können wir diese Daten effektiv verwalten. Besonders nützlich ist in diesem Zusammenhang die Funktion pd.json_normalize(). Es kann die JSON-Daten, einschließlich der verschachtelten Liste, in ein strukturiertes Format reduzieren, das für die Analyse geeignet ist. Wenn diese Funktion auf unsere JSON-Daten angewendet wird, erzeugt sie eine normalisierte Tabelle, die die verschachtelte Liste als Teil ihrer Felder enthält.
Darüber hinaus bietet Pandas die Möglichkeit, diesen Prozess weiter zu verfeinern. Durch die Verwendung des Parameters „record_path“ in pd.json_normalize() können wir die Funktion anweisen, die verschachtelte Liste gezielt zu normalisieren.
Diese Aktion führt zu einer dedizierten Tabelle ausschließlich für den Inhalt der Liste. Standardmäßig werden bei diesem Vorgang nur die Elemente innerhalb der Liste entfaltet. Um diese Tabelle jedoch mit zusätzlichem Kontext anzureichern, beispielsweise um für jeden Datensatz eine zugehörige ID beizubehalten, können wir den Parameter „meta“ verwenden.

Bild vom Autor
Zusammenfassend lässt sich sagen, dass die Umwandlung von JSON-Daten in CSV-Dateien mithilfe der Pandas-Bibliothek von Python einfach und effektiv ist.
JSON ist immer noch das am weitesten verbreitete Format in der modernen Datenspeicherung und dem Datenaustausch, insbesondere in NoSQL-Datenbanken und REST-APIs. Der Umgang mit Daten im Rohformat stellt jedoch einige wichtige analytische Herausforderungen dar.
Die zentrale Rolle von pd.json_normalize() von Pandas erweist sich als eine großartige Möglichkeit, mit solchen Formaten umzugehen und unsere Daten in Pandas DataFrame zu konvertieren.
Ich hoffe, dieser Leitfaden war hilfreich und Sie können es beim nächsten Mal, wenn Sie sich mit JSON befassen, effektiver machen.
Sie können das entsprechende Jupyter-Notizbuch im überprüfen folgendes GitHub-Repo.
Josef Ferrer ist Analytikingenieur aus Barcelona. Er hat einen Abschluss in Physikingenieurwesen und arbeitet derzeit im Bereich Data Science für die menschliche Mobilität. Er ist ein Teilzeit-Content-Creator, der sich auf Data Science und Technologie konzentriert. Sie können ihn unter kontaktieren LinkedIn, Twitter or Medium.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :Ist
- :nicht
- :Wo
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Über uns
- Action
- Zusätzliche
- advanced
- Alle
- erlauben
- erlaubt
- bereits
- immer
- an
- Analyse
- Analytiker
- Analytisch
- Analytik
- machen
- jedem
- APIs
- erscheinen
- angewandt
- Anwendung
- SIND
- Feld
- Kunst
- AS
- damit verbundenen
- Barcelona
- basic
- BE
- Bevor
- Bit
- beide
- aber
- by
- CAN
- capability
- Häuser
- Herausforderungen
- aus der Ferne überprüfen
- Auswählen
- Stadt
- Spalten
- gemeinsam
- Komplex
- Komplikationen
- Kontakt
- Inhalt
- Inhalt
- Kontext
- verkaufen
- Umwandlung
- entsprechen
- Dazugehörigen
- Schöpfer
- Zur Zeit
- technische Daten
- Datenanalytiker
- Dateningenieur
- Datenwissenschaft
- Datenwissenschaftler
- Datenspeichervorrichtung
- Datenbanken
- Christian
- Behandlung
- gewidmet
- Standard
- definieren
- Definition
- reizvoll
- DICT
- anders
- Direkt
- do
- die
- jeder
- leicht
- Einfache
- Effektiv
- effektiv
- Elemente
- taucht auf
- Begegnung
- Ingenieur
- Entwicklung
- bereichern
- im Wesentlichen
- Austausch-
- austauschen
- ausschließlich
- Erweitern Sie die Funktionalität der
- ERFAHRUNGEN
- Erläuterung
- ERKUNDEN
- vertraut
- wenige
- Feld
- Felder
- Mappen
- Filter
- Finden Sie
- Vorname
- konzentriert
- Folgende
- folgt
- Aussichten für
- unten stehende Formular
- Format
- freundlich
- für
- Funktion
- fundamental
- weiter
- GCP
- erzeugen
- bekommen
- GitHub
- Go
- groß
- Guide
- Griff
- Handling
- das passiert
- Haben
- mit
- he
- ihm
- ein Geschenk
- Ultraschall
- aber
- HTTPS
- human
- i
- KRANK
- ID
- if
- Bild
- importieren
- wichtig
- in
- eingehende
- das
- Einschließlich
- Einkommen
- beinhaltet
- informiert
- Instanz
- Interesse
- in
- isn
- IT
- SEINE
- JavaScript
- JSON
- Jupyter Notizbuch
- nur
- KDnuggets
- Wesentliche
- Tasten
- Wissen
- Nachname
- lernen
- Niveau
- Cholesterinspiegel
- Bibliothek
- Gefällt mir
- Liste
- wenig
- ll
- ich liebe
- Maschine
- Maschinelles Lernen
- Magie
- gepflegt
- Making
- verwalten
- Manager
- viele
- Mittel
- Meta
- Kommt demnächst...
- Mobilität
- modern
- MongoDB
- mehr
- vor allem warme
- schlauer bewegen
- viel
- mehrere
- Name
- Natürliche
- Need
- verschachtelt
- Neu
- weiter
- nicht
- vor allem
- Notizbuch
- Objekt
- erhalten
- of
- Angebote
- vorgenommen,
- on
- EINEM
- einzige
- or
- UNSERE
- uns
- Möglichkeiten für das Ausgangssignal:
- Pandas
- Parameter
- Teil
- besonders
- schwebend
- perfekt
- durchgeführt
- Physik
- zentrale
- Plato
- Datenintelligenz von Plato
- PlatoData
- Beliebt
- Geschenke
- wahrscheinlich
- Verfahren
- Prozessdefinierung
- produziert
- Projekt
- Python
- Frage
- ganz
- Roh
- RE
- Lesebrillen
- bereit
- Rekord
- Aufzeichnungen
- verfeinern
- Reagieren
- REST
- Die Ergebnisse
- Halte
- Recht
- Rollen
- s
- gleich
- Wissenschaft
- Wissenschaft und Technologie
- Wissenschaftler
- Sekunden
- sehen
- Auswahl
- sollte
- Einfacher
- simulieren
- Single
- Fähigkeiten
- klein
- So
- einige
- etwas
- spezifisch
- speziell
- SQL
- Immer noch
- Lagerung
- speichern
- Struktur
- strukturierte
- so
- geeignet
- ZUSAMMENFASSUNG
- T
- Tabelle
- Technologie
- AGB
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- die Welt
- ihr
- Sie
- dann
- Diese
- fehlen uns die Worte.
- diejenigen
- Zeit
- zu
- gemeinsam
- Top
- Transformieren
- Transformation
- Transformieren
- tippe
- Typen
- für
- us
- -
- nützlich
- Verwendung von
- Verwendung
- Wert
- Werte
- wollen
- wurde
- Weg..
- we
- Was
- wann
- ob
- welche
- während
- werden wir
- mit
- .
- Arbeiten
- arbeiten,
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- U
- Zephyrnet