Im heutigen datengesteuerten Geschäftsumfeld stehen Unternehmen vor der Herausforderung, große Datenmengen für Analyse- und Data-Science-Zwecke effizient aufzubereiten und umzuwandeln. Unternehmen müssen Data Warehouses und Data Lakes auf der Grundlage operativer Daten aufbauen. Dies ist auf die Notwendigkeit zurückzuführen, Daten aus unterschiedlichen Quellen zu zentralisieren und zu integrieren.
Gleichzeitig stammen Betriebsdaten häufig aus Anwendungen, die auf alten Datenspeichern basieren. Die Modernisierung von Anwendungen erfordert eine Microservice-Architektur, die wiederum die Konsolidierung von Daten aus mehreren Quellen zum Aufbau eines operativen Datenspeichers erfordert. Ohne Modernisierung könnten für Legacy-Anwendungen steigende Wartungskosten anfallen. Zur Modernisierung von Anwendungen gehört die Umstellung der zugrunde liegenden Datenbank-Engine auf eine moderne dokumentenbasierte Datenbank wie MongoDB.
Diese beiden Aufgaben (Aufbau von Data Lakes oder Data Warehouses und Anwendungsmodernisierung) umfassen die Datenverschiebung, die einen ETL-Prozess (Extrahieren, Transformieren und Laden) verwendet. Der ETL-Job ist eine Schlüsselfunktion für einen gut strukturierten Prozess und den Erfolg.
AWS-Kleber ist ein serverloser Datenintegrationsdienst, der die einfache Erkennung, Vorbereitung, Verschiebung und Integration von Daten aus mehreren Quellen für Analysen, maschinelles Lernen (ML) und Anwendungsentwicklung ermöglicht. MongoDB-Atlas ist eine integrierte Suite aus Cloud-Datenbank- und Datendiensten, die Transaktionsverarbeitung, relevanzbasierte Suche, Echtzeitanalysen und Mobil-zu-Cloud-Datensynchronisierung in einer eleganten und integrierten Architektur kombiniert.
Durch die Verwendung von AWS Glue mit MongoDB Atlas können Unternehmen ihre ETL-Prozesse optimieren. Mit seiner vollständig verwalteten, skalierbaren und sicheren Datenbanklösung bietet MongoDB Atlas eine flexible und zuverlässige Umgebung für die Speicherung und Verwaltung von Betriebsdaten. Zusammen bilden AWS Glue ETL und MongoDB Atlas eine leistungsstarke Lösung für Unternehmen, die den Aufbau von Data Lakes und Data Warehouses optimieren und ihre Anwendungen modernisieren möchten, um die Geschäftsleistung zu verbessern, Kosten zu senken und Wachstum und Erfolg voranzutreiben.
In diesem Beitrag zeigen wir, wie man Daten migriert Amazon Simple Storage-Service (Amazon S3) Buckets zu MongoDB Atlas mit AWS Glue ETL und wie man Daten aus MongoDB Atlas in einen Amazon S3-basierten Data Lake extrahiert.
Lösungsüberblick
In diesem Beitrag untersuchen wir die folgenden Anwendungsfälle:
- Extrahieren von Daten aus MongoDB – MongoDB ist eine beliebte Datenbank, die von Tausenden von Kunden zum Speichern von Anwendungsdaten in großem Maßstab verwendet wird. Unternehmenskunden können Daten aus mehreren Datenspeichern zentralisieren und integrieren, indem sie Data Lakes und Data Warehouses aufbauen. Bei diesem Prozess werden Daten aus den Betriebsdatenspeichern extrahiert. Wenn sich die Daten an einem Ort befinden, können Kunden sie schnell für Business-Intelligence-Anforderungen oder für ML nutzen.
- Daten in MongoDB aufnehmen – MongoDB dient auch als No-SQL-Datenbank zum Speichern von Anwendungsdaten und zum Aufbau betrieblicher Datenspeicher. Die Modernisierung von Anwendungen erfordert häufig die Migration des Betriebsspeichers zu MongoDB. Kunden müssten vorhandene Daten aus relationalen Datenbanken oder aus Flatfiles extrahieren. Für Mobil- und Webanwendungen müssen Dateningenieure häufig Datenpipelines erstellen, um eine einzige Datenansicht in Atlas zu erstellen und gleichzeitig Daten aus mehreren isolierten Quellen aufzunehmen. Während dieser Migration müssten sie verschiedene Datenbanken zusammenführen, um Dokumente zu erstellen. Dieser komplexe Join-Vorgang würde eine erhebliche, einmalige Rechenleistung erfordern. Entwickler müssten dies auch schnell erstellen, um die Daten zu migrieren.
AWS Glue ist in diesen Fällen mit dem Pay-as-you-go-Modell und seiner Fähigkeit, komplexe Transformationen über große Datenmengen hinweg durchzuführen, praktisch. Entwickler können AWS Glue Studio verwenden, um solche Datenpipelines effizient zu erstellen.
Das folgende Diagramm zeigt den Datenextraktionsworkflow von MongoDB Atlas in einen S3-Bucket mithilfe von AWS Glue Studio.
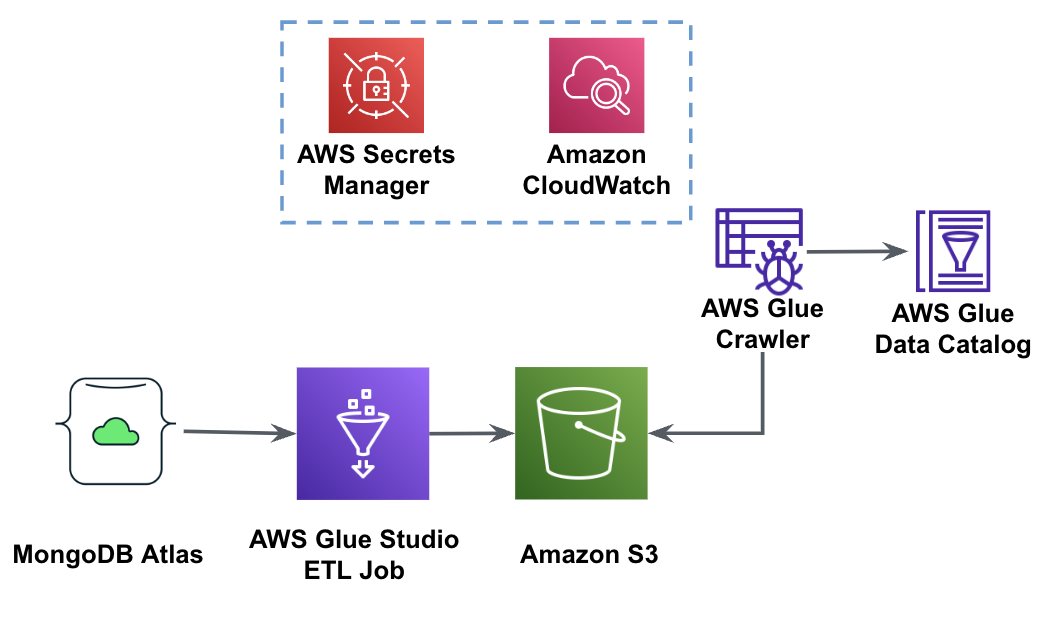
Um diese Architektur zu implementieren, benötigen Sie einen MongoDB Atlas-Cluster, einen S3-Bucket und einen AWS Identity and Access Management and (IAM)-Rolle für AWS Glue. Informationen zum Konfigurieren dieser Ressourcen finden Sie im Folgenden in den erforderlichen Schritten GitHub Repo.
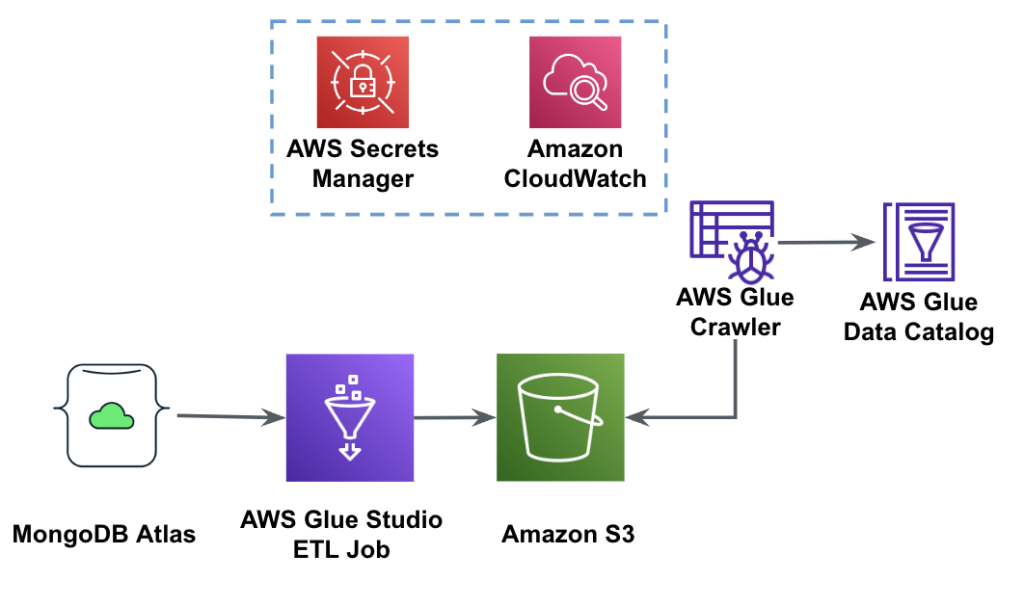
Die folgende Abbildung zeigt den Arbeitsablauf zum Laden von Daten aus einem S3-Bucket in MongoDB Atlas mithilfe von AWS Glue.
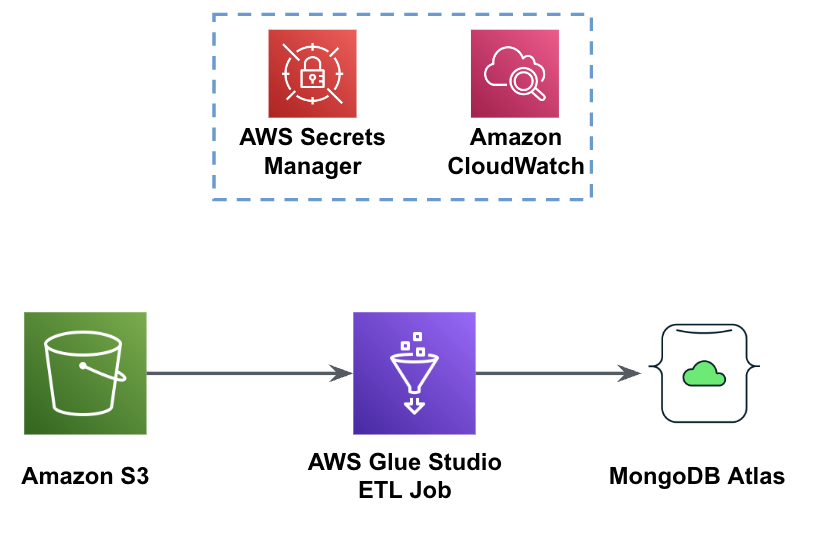
Hier sind die gleichen Voraussetzungen erforderlich: ein S3-Bucket, eine IAM-Rolle und ein MongoDB Atlas-Cluster.
Laden Sie Daten von Amazon S3 in MongoDB Atlas mit AWS Glue
Die folgenden Schritte beschreiben, wie Sie mithilfe eines AWS Glue-Jobs Daten aus dem S3-Bucket in MongoDB Atlas laden. Der Extraktionsprozess von MongoDB Atlas zu Amazon S3 ist bis auf das verwendete Skript sehr ähnlich. Wir weisen auf die Unterschiede zwischen den beiden Verfahren hin.
- Erstellen Sie einen kostenlosen Cluster im MongoDB Atlas.
- Laden Sie die JSON-Beispieldatei zu Ihrem S3-Bucket.
- Erstellen Sie einen neuen AWS Glue Studio-Auftrag mit Spark-Skript-Editor .

- Je nachdem, ob Sie Daten aus dem MongoDB Atlas-Cluster laden oder extrahieren möchten, geben Sie Folgendes ein Skript laden or Skript extrahieren im AWS Glue Studio-Skripteditor.
Der folgende Screenshot zeigt einen Codeausschnitt zum Laden von Daten in den MongoDB Atlas-Cluster.

Der Code verwendet AWS Secrets Manager um den Namen, den Benutzernamen und das Passwort des MongoDB Atlas-Clusters abzurufen. Dann wird ein erstellt DynamicFrame für den S3-Bucket und Dateiname, die als Parameter an das Skript übergeben werden. Der Code ruft die Datenbank- und Sammlungsnamen aus der Jobparameterkonfiguration ab. Schließlich schreibt der Code die DynamicFrame zum MongoDB Atlas-Cluster mithilfe der abgerufenen Parameter.
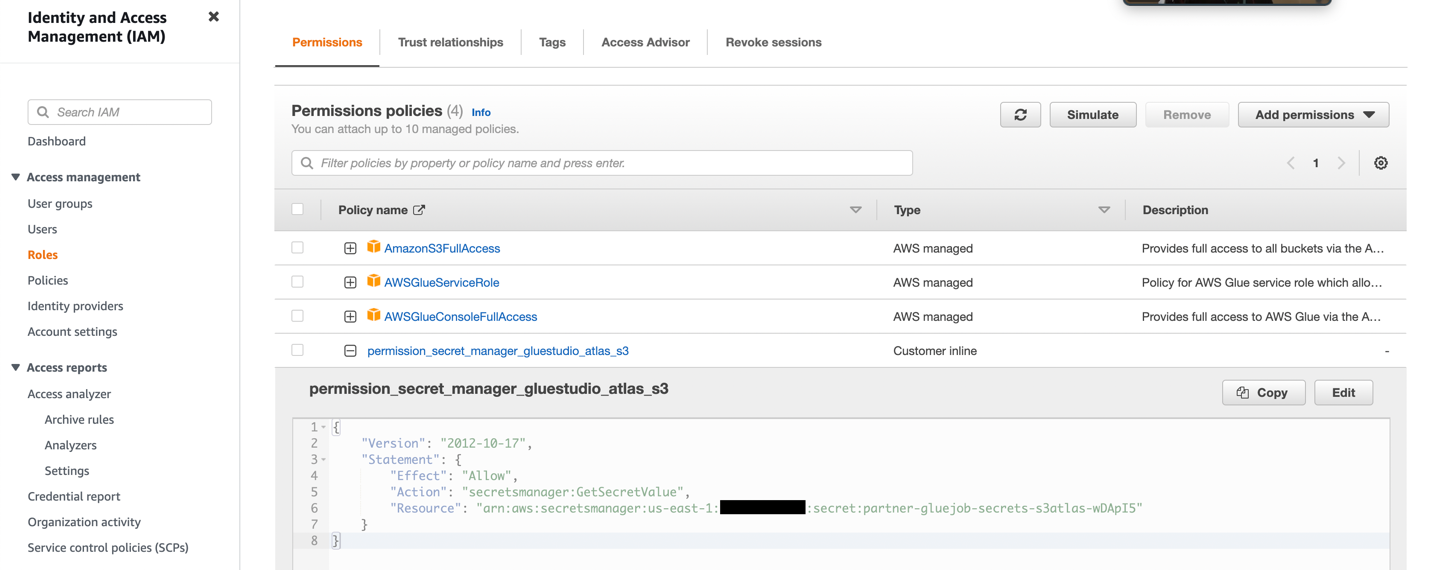
- Erstellen Sie eine IAM-Rolle mit den Berechtigungen, wie im folgenden Screenshot gezeigt.
Weitere Einzelheiten finden Sie unter Konfigurieren Sie eine IAM-Rolle für Ihren ETL-Job.
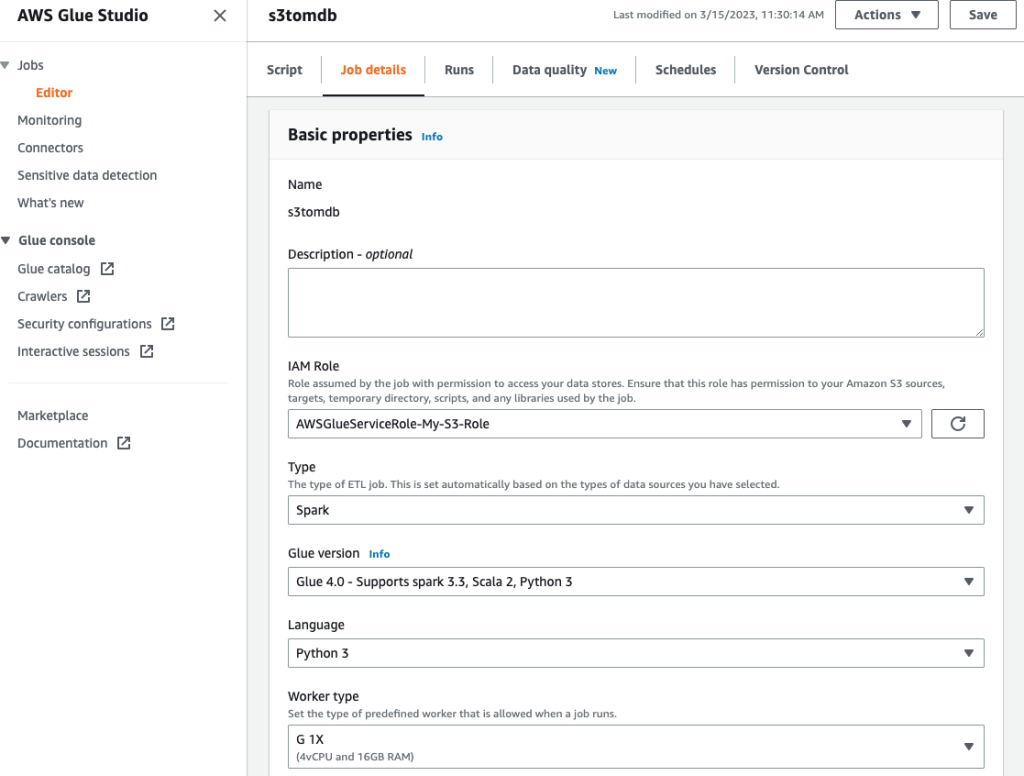
- Geben Sie dem Job einen Namen und geben Sie die im vorherigen Schritt erstellte IAM-Rolle an Jobdetails Tab.
- Die restlichen Parameter können Sie als Standard belassen, wie in den folgenden Screenshots gezeigt.
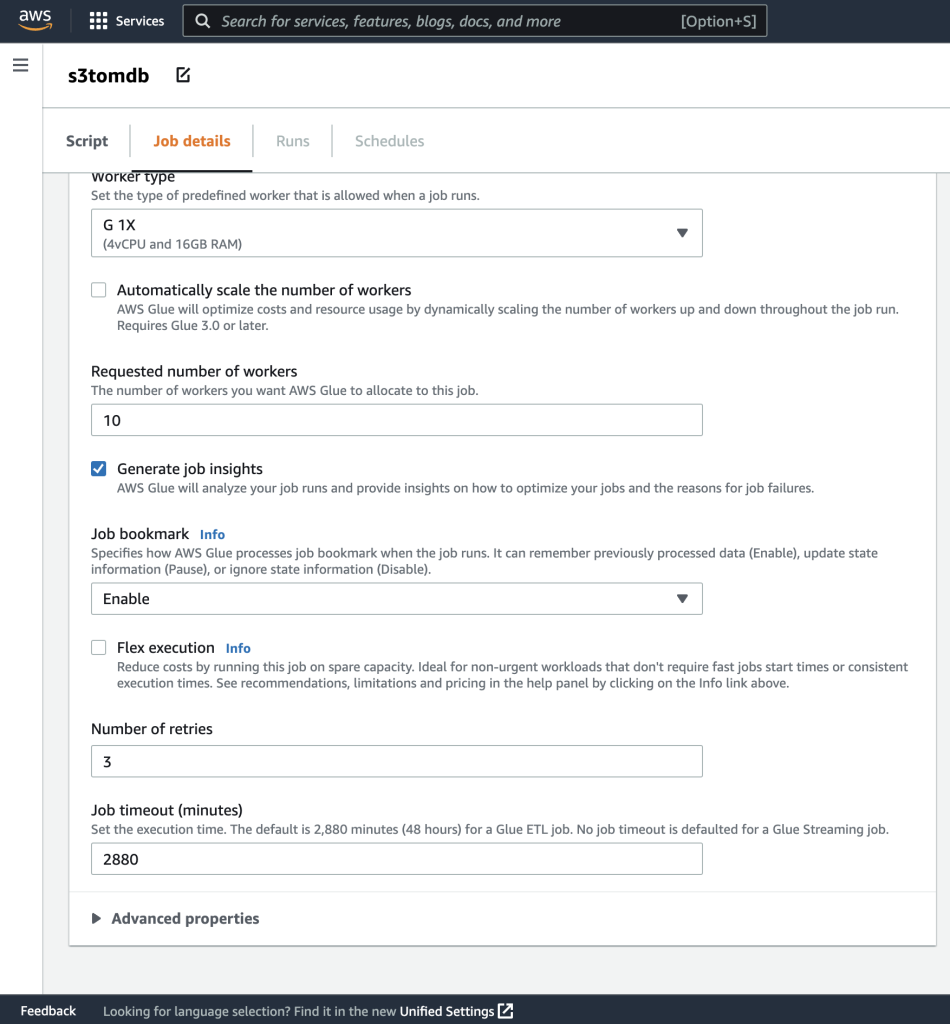
- Definieren Sie als Nächstes die Jobparameter, die das Skript verwendet, und geben Sie die Standardwerte an.
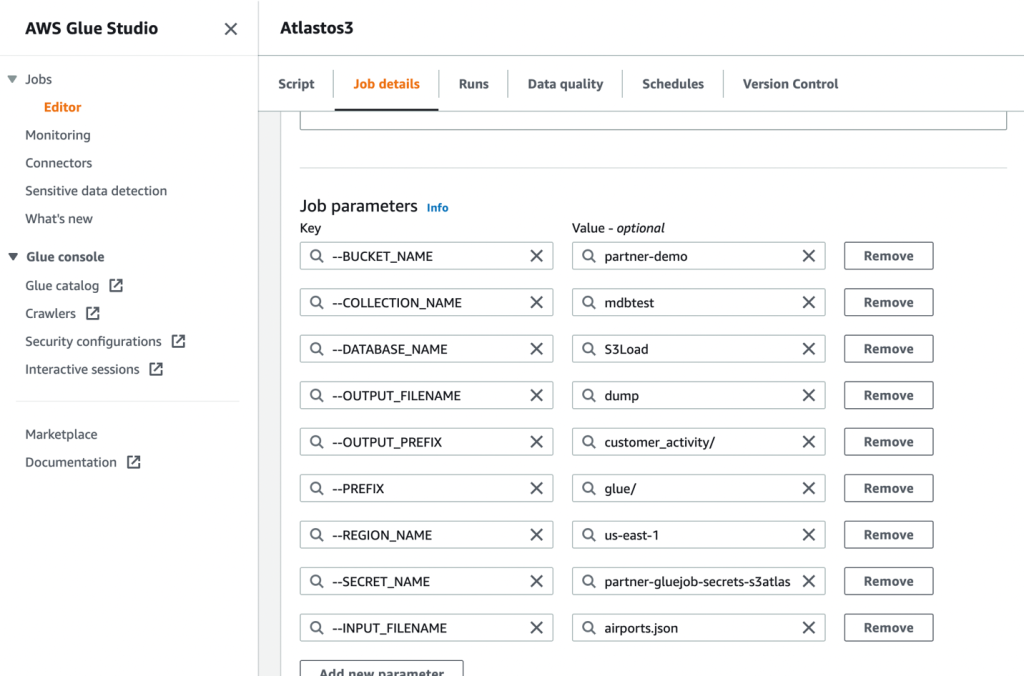
- Speichern Sie den Job und führen Sie ihn aus.
- Um eine erfolgreiche Ausführung zu bestätigen, beobachten Sie den Inhalt der MongoDB Atlas-Datenbanksammlung, wenn Sie die Daten laden, oder des S3-Buckets, wenn Sie eine Extraktion durchführen.



Der folgende Screenshot zeigt die Ergebnisse eines erfolgreichen Datenladens aus einem Amazon S3-Bucket in den MongoDB Atlas-Cluster. Die Daten stehen jetzt für Abfragen in der MongoDB Atlas-Benutzeroberfläche zur Verfügung.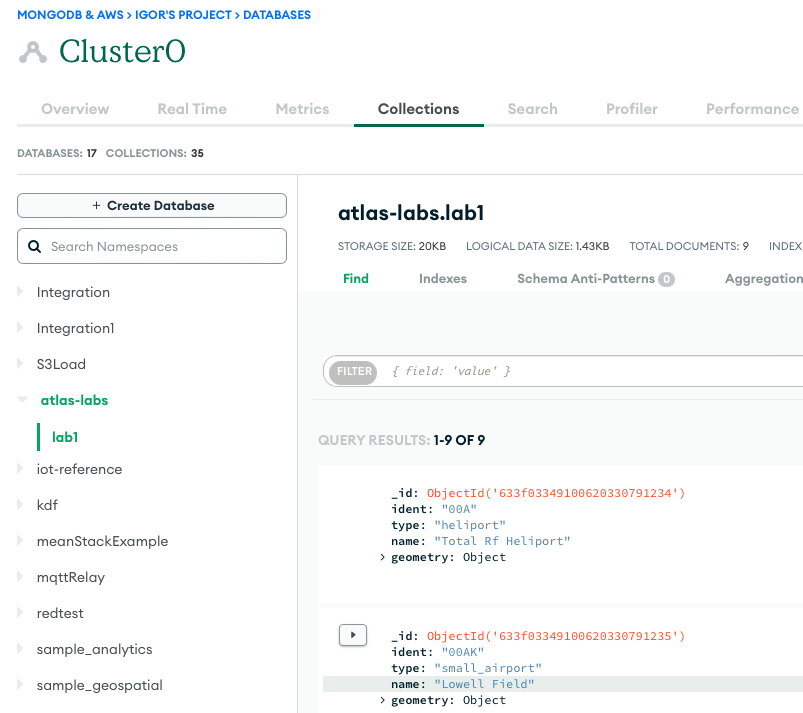
- Um Fehler bei Ihren Läufen zu beheben, lesen Sie die Amazon CloudWatch Protokolle über den Link zum Job Führen Sie Tab.
Der folgende Screenshot zeigt, dass der Job erfolgreich ausgeführt wurde, mit zusätzlichen Details wie Links zu den CloudWatch-Protokollen.

Zusammenfassung
In diesem Beitrag haben wir beschrieben, wie Sie mit AWS Glue Daten extrahieren und in MongoDB Atlas aufnehmen.
Mit AWS Glue ETL-Jobs können wir nun die Daten von MongoDB Atlas an AWS Glue-kompatible Quellen übertragen und umgekehrt. Sie können die Lösung auch erweitern, um mithilfe von AWS AI- und ML-Services Analysen zu erstellen.
Weitere Informationen finden Sie unter GitHub-Repository Schritt-für-Schritt-Anleitungen und Beispielcode finden Sie hier. Sie können beschaffen MongoDB-Atlas auf AWS Marketplace.
Über die Autoren

Igor Alexejew ist Senior Partner Solution Architect bei AWS im Bereich Data and Analytics. In seiner Funktion arbeitet Igor mit strategischen Partnern zusammen und hilft ihnen beim Aufbau komplexer, AWS-optimierter Architekturen. Bevor er zu AWS kam, implementierte er als Data/Solution Architect viele Projekte im Bereich Big Data, darunter mehrere Data Lakes im Hadoop-Ökosystem. Als Data Engineer war er an der Anwendung von KI/ML zur Betrugserkennung und Büroautomatisierung beteiligt.
 Babu Srinivasan ist Senior Partner Solutions Architect bei MongoDB. In seiner derzeitigen Rolle arbeitet er mit AWS zusammen, um die technischen Integrationen und Referenzarchitekturen für die AWS- und MongoDB-Lösungen zu erstellen. Er verfügt über mehr als zwei Jahrzehnte Erfahrung in Datenbank- und Cloud-Technologien. Seine Leidenschaft gilt der Bereitstellung technischer Lösungen für Kunden, die mit mehreren globalen Systemintegratoren (GSIs) in mehreren Regionen zusammenarbeiten.
Babu Srinivasan ist Senior Partner Solutions Architect bei MongoDB. In seiner derzeitigen Rolle arbeitet er mit AWS zusammen, um die technischen Integrationen und Referenzarchitekturen für die AWS- und MongoDB-Lösungen zu erstellen. Er verfügt über mehr als zwei Jahrzehnte Erfahrung in Datenbank- und Cloud-Technologien. Seine Leidenschaft gilt der Bereitstellung technischer Lösungen für Kunden, die mit mehreren globalen Systemintegratoren (GSIs) in mehreren Regionen zusammenarbeiten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :hast
- :Ist
- 100
- 11
- a
- Fähigkeit
- Über uns
- Zugang
- über
- Zusätzliche
- AI
- AI / ML
- ebenfalls
- Amazon
- Beträge
- an
- Analytik
- und
- Anwendung
- Anwendungsentwicklung
- Anwendungen
- Anwendung
- Apps
- Architektur
- SIND
- AS
- At
- Atlas
- Automation
- verfügbar
- AWS
- AWS-Kleber
- AWS-Marktplatz
- unterstützt
- basierend
- Sein
- zwischen
- Big
- Big Data
- bauen
- Building
- Geschäft
- Business Intelligence
- Geschäftsleistung
- Unternehmen
- by
- rufen Sie uns an!
- CAN
- Fälle
- challenges
- Ändern
- Cloud
- Cluster
- Code
- Sammlung
- vereint
- kommt
- Kommen
- Komplex
- Berechnen
- Konfiguration
- Schichtannahme
- Festigung
- konstruieren
- Inhalt
- weiter
- Kosten
- erstellen
- erstellt
- schafft
- Schaffung
- Strom
- Kunden
- technische Daten
- Dateningenieur
- Datenintegration
- Datensee
- Datenwissenschaft
- Data Warehouse
- datengesteuerte
- Datenbase
- Datenbanken
- Datensätze
- Jahrzehnte
- Standard
- zeigen
- beschreiben
- beschrieben
- Details
- Entdeckung
- Entwickler
- Entwicklung
- Unterschiede
- anders
- entdeckt,
- disparat
- Unterlagen
- Domain
- Antrieb
- angetrieben
- im
- Ökosystem
- Herausgeber
- effizient
- Motor
- Ingenieur
- Ingenieure
- Enter
- Unternehmen
- Unternehmenskunden
- Arbeitsumfeld
- Äther (ETH)
- Ausnahme
- vorhandenen
- ERFAHRUNGEN
- ERKUNDEN
- erweitern
- Extrakt
- Extraktion
- Gesicht
- Abbildung
- Reichen Sie das
- Mappen
- Endlich
- Wohnung
- flexibel
- Folgende
- Aussichten für
- Betrug
- Betrugserkennung
- Frei
- für
- voll
- Funktionalität
- geographien
- Global
- Wachstum
- Hadoop
- praktisch
- mit
- he
- Unternehmen
- hier
- seine
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- riesig
- IAM
- Identitätsschutz
- if
- implementieren
- umgesetzt
- zu unterstützen,
- in
- Einschließlich
- zunehmend
- Varianten des Eingangssignals:
- Anleitung
- integrieren
- integriert
- Integration
- Integrationen
- Intelligenz
- in
- beteiligen
- beteiligt
- IT
- SEINE
- Job
- Jobs
- join
- Beitritt
- JSON
- Wesentliche
- See
- grosse
- LERNEN
- lernen
- Verlassen
- Legacy
- Gefällt mir
- LINK
- Links
- Belastung
- Laden
- suchen
- Maschine
- Maschinelles Lernen
- Wartung
- MACHT
- verwaltet
- flächendeckende Gesundheitsprogramme
- viele
- Marktplatz
- Kann..
- migriert
- Migration
- ML
- Mobil
- Modell
- modern
- Modernisierung
- modernisieren
- MongoDB
- mehr
- schlauer bewegen
- Bewegung
- mehrere
- Name
- Namen
- Need
- erforderlich
- Bedürfnisse
- Neu
- jetzt an
- beobachten
- of
- Office
- vorgenommen,
- on
- EINEM
- Betrieb
- Betriebs-
- Optimieren
- Option
- or
- Auftrag
- Organisationen
- Parameter
- Partner
- Bestanden
- leidenschaftlich
- Passwort
- Leistung
- Durchführung
- Berechtigungen
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- Beliebt
- Post
- Werkzeuge
- größte treibende
- Danach
- Vorbereitung
- Voraussetzungen
- früher
- Vor
- Prozessdefinierung
- anpassen
- Verarbeitung
- Projekte
- bietet
- Bereitstellung
- Zwecke
- Abfragen
- schnell
- Echtzeit
- Veteran
- zuverlässig
- erfordern
- erfordert
- Downloads
- REST
- Die Ergebnisse
- Überprüfen
- Rollen
- Führen Sie
- gleich
- skalierbaren
- Skalieren
- Wissenschaft
- Screenshots
- Suche
- Verbindung
- Senior
- Serverlos
- dient
- Leistungen
- mehrere
- gezeigt
- Konzerte
- signifikant
- ähnlich
- Einfacher
- Single
- Lösung
- Lösungen
- Quellen
- Schritt
- Shritte
- Lagerung
- speichern
- Läden
- einfach
- Strategisch
- strategische Partner
- rationalisieren
- Studio Adressen
- Erfolg haben
- Erfolg
- erfolgreich
- Erfolgreich
- so
- Suite
- liefern
- Synchronisation
- System
- und Aufgaben
- Technische
- Technologies
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Tausende
- Zeit
- zu
- heutigen
- gemeinsam
- Transaktion
- privaten Transfer
- Transformieren
- Transformationen
- Transformieren
- WENDE
- XNUMX
- ui
- zugrunde liegen,
- -
- benutzt
- Mitglied
- Verwendung von
- Werte
- sehr
- Anzeigen
- wollen
- wurde
- we
- Netz
- waren
- wann
- ob
- welche
- während
- werden wir
- mit
- ohne
- Arbeitsablauf.
- arbeiten,
- würde
- U
- Ihr
- Zephyrnet