Der Wert von Daten ist zeitkritisch. Die Echtzeitverarbeitung macht datengesteuerte Entscheidungen in Sekunden oder Minuten statt in Stunden oder Tagen genau und umsetzbar. Change Data Capture (CDC) bezieht sich auf den Prozess der Identifizierung und Erfassung von Änderungen an Daten in einer Datenbank und die anschließende Übermittlung dieser Änderungen in Echtzeit an ein nachgelagertes System. Das Erfassen jeder Änderung von Transaktionen in einer Quelldatenbank und das Verschieben in Echtzeit zum Ziel hält die Systeme synchron und hilft bei Anwendungsfällen für Echtzeitanalysen und Datenbankmigrationen ohne Ausfallzeiten. Im Folgenden sind einige Vorteile von CDC aufgeführt:
- Es eliminiert die Notwendigkeit von Bulk-Load-Aktualisierungen und unbequemen Batch-Fenstern, indem es inkrementelles Laden oder Echtzeit-Streaming von Datenänderungen in Ihr Ziel-Repository ermöglicht.
- Es stellt sicher, dass Daten in mehreren Systemen synchron bleiben. Dies ist besonders wichtig, wenn Sie zeitkritische Entscheidungen in einer Umgebung mit Hochgeschwindigkeitsdaten treffen.
Kafka Connect ist eine Open-Source-Komponente von Apache Kafka, die als zentralisierte Datendrehscheibe für eine einfache Datenintegration zwischen Datenbanken, Schlüsselwertspeichern, Suchindizes und Dateisystemen fungiert. Der AWS Glue-Schema-Registrierung ermöglicht es Ihnen, Datenstromschemata zentral zu erkennen, zu steuern und weiterzuentwickeln. Kafka Connect und Schema Registry lassen sich integrieren, um Schemainformationen von Konnektoren zu erfassen. Kafka Connect bietet einen Mechanismus zum Konvertieren von Daten aus den von Kafka Connect verwendeten internen Datentypen in Datentypen, die als Avro-, Protobuf- oder JSON-Schema dargestellt werden. AvroConverter, ProtobufConverter und JsonSchemaConverter registrieren automatisch Schemas, die von Kafka-Konnektoren (Quelle) generiert werden, die Daten für Kafka erzeugen. Konnektoren (Senke), die Daten von Kafka konsumieren, erhalten Schemainformationen zusätzlich zu den Daten für jede Nachricht. Dadurch können Senkenkonnektoren die Struktur der Daten kennen, um Funktionen wie die Verwaltung eines Datenbanktabellenschemas in einem Datenkatalog bereitzustellen.
Der Beitrag zeigt, wie Sie eine End-to-End-CDC mit erstellen Amazon MSK Connect, ein von AWS verwalteter Service zum Bereitstellen und Ausführen von Kafka Connect-Anwendungen und AWS Glue Schema Registry, mit dem Sie Datenstromschemata zentral erkennen, steuern und weiterentwickeln können.
Lösungsüberblick
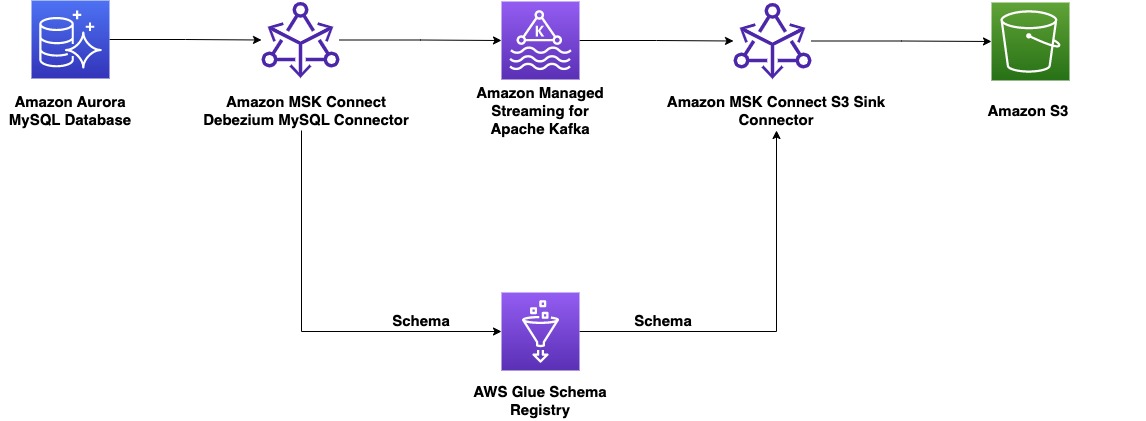
Auf Herstellerseite wählen wir für dieses Beispiel einen MySQL-kompatiblen Amazonas-Aurora Datenbank als Datenquelle, und wir haben eine Debezium MySQL-Connector zum Ausführen von CDC. Der Debezium-Konnektor überwacht kontinuierlich die Datenbanken und überträgt Änderungen auf Zeilenebene an ein Kafka-Thema. Der Konnektor ruft das Schema aus der Datenbank ab, um die Datensätze in binärer Form zu serialisieren. Wenn das Schema noch nicht in der Registrierung vorhanden ist, wird das Schema registriert. Wenn das Schema vorhanden ist, der Serializer jedoch eine neue Version verwendet, überprüft die Schemaregistrierung die Kompatibilitätsmodus des Schemas, bevor Sie das Schema aktualisieren. In dieser Lösung verwenden wir Abwärtskompatibilitätsmodus. Die Schemaregistrierung gibt einen Fehler zurück, wenn eine neue Version des Schemas nicht abwärtskompatibel ist, und wir können Kafka Connect so konfigurieren, dass inkompatible Nachrichten an die Warteschlange für unzustellbare Nachrichten gesendet werden.
Auf der Verbraucherseite verwenden wir eine Amazon Simple Storage-Service (Amazon S3) Sink Connector, um den Datensatz zu deserialisieren und Änderungen in Amazon S3 zu speichern. Wir erstellen und implementieren den Debezium-Konnektor und die Amazon S3-Senke mit MSK Connect.
Beispielschema
Für diesen Beitrag verwenden wir das folgende Schema als erste Version der Tabelle:
Voraussetzungen:
Vor der Konfiguration der MSK-Producer- und -Consumer-Konnektoren müssen wir zunächst eine Datenquelle, einen MSK-Cluster und eine neue Schemaregistrierung einrichten. Wir bieten eine AWS CloudFormation Vorlage zum Generieren der für die Lösung erforderlichen unterstützenden Ressourcen:
- Eine MySQL-kompatible Aurora-Datenbank als Datenquelle. Um CDC durchzuführen, schalten wir die binäre Protokollierung in ein DB-Cluster-Parametergruppe.
- Ein MSK-Cluster. Um die Netzwerkverbindung zu vereinfachen, verwenden wir dieselbe VPC für die Aurora-Datenbank und den MSK-Cluster.
- Zwei Schemaregistrierungen zur Handhabung von Schemas für Nachrichtenschlüssel und Nachrichtenwert.
- Ein S3-Bucket als Datensenke.
- MSK Connect-Plugins und Worker-Konfiguration, die für diese Demo benötigt werden.
- Eins Amazon Elastic Compute-Cloud (Amazon EC2)-Instanz zum Ausführen von Datenbankbefehlen.
Um Ressourcen in Ihrem AWS-Konto einzurichten, führen Sie die folgenden Schritte in einer AWS-Region durch, die Amazon MSK, MSK Connect und die AWS Glue Schema Registry unterstützt:
- Auswählen
Stack starten:
- Auswählen Weiter.
- Aussichten für Stapelname, geben Sie einen geeigneten Namen ein.
- Aussichten für Datenbankpasswort, geben Sie das gewünschte Passwort für den Datenbankbenutzer ein.
- Behalten Sie andere Werte als Standard bei.
- Auswählen Weiter.
- Wählen Sie auf der nächsten Seite Weiter.
- Überprüfen Sie die Details auf der letzten Seite und wählen Sie Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt.
- Auswählen Stapel erstellen.
Benutzerdefiniertes Plugin für den Quell- und Zielconnector
Ein benutzerdefiniertes Plugin ist ein Satz von JAR-Dateien, die die Implementierung eines oder mehrerer Konnektoren, Transformationen oder Konverter enthalten. Amazon MSK installiert das Plugin auf den Workern des MSK Connect-Clusters, auf dem der Connector ausgeführt wird. Als Teil dieser Demo verwenden wir für den Source Connector Open Source Debezium MySQL-Connector-JARs, und für den Zielkonnektor verwenden wir die lizenzierte Confluent-Community Amazon S3 Sink-Connector-JARs. Beide Plugins werden auch mit Bibliotheken für hinzugefügt Avro-Serialisierer und -Deserialisierer der AWS Glue Schema Registry. Diese benutzerdefinierten Plugins werden bereits als Teil der im vorherigen Schritt bereitgestellten CloudFormation-Vorlage erstellt.
Verwenden Sie die AWS Glue Schema Registry mit dem Debezium-Konnektor auf MSK Connect als MSK-Produzent
Wir stellen zuerst den Quellkonnektor mit dem Debezium-MySQL-Plugin bereit, um Daten von einem zu streamen Amazon Aurora MySQL-kompatible Edition Datenbank zu Amazon MSK. Führen Sie die folgenden Schritte aus:
- Auf der Amazon MSK-Konsole im Navigationsbereich unter MSK Connect, wählen Anschluss.
- Auswählen Konnektor erstellen.
- Auswählen
Verwenden Sie das vorhandene benutzerdefinierte Plugin und wählen Sie dann das benutzerdefinierte Plugin mit dem Namen ab
msk-blog-debezium-source-plugin. - Auswählen Weiter.
- Geben Sie einen passenden Namen wie z
debezium-mysql-connectorund eine optionale Beschreibung. - Aussichten für Apache Kafka-Cluster, wählen MSK-Cluster und wählen Sie den von der CloudFormation-Vorlage erstellten Cluster aus.
- In Steckerkonfiguration, löschen Sie die Standardwerte und verwenden Sie die folgenden Konfigurationsschlüssel-Wert-Paare und mit den entsprechenden Werten:
- Name – Der für den Konnektor verwendete Name.
- Datenbank.Hostname – Die CloudFormation-Ausgabe für Datenbank-Endpunkt.
- Datenbank.Benutzer und Datenbank.Passwort – Die in der CloudFormation-Vorlage übergebenen Parameter.
- Datenbank.history.kafka.bootstrap.servers – Die CloudFormation-Ausgabe für Kafka Bootstrap.
- key.converter.region und value.converter.region – Ihre Region.
Einige dieser Einstellungen sind generisch und sollten für jeden Connector angegeben werden. Zum Beispiel:
- connector.class ist die Java-Klasse des Connectors
- task.max ist die maximale Anzahl von Aufgaben, die für diesen Konnektor erstellt werden sollten
Einige Einstellungen (database.*, transforms.*) sind spezifisch für den Debezium-MySQL-Connector. Beziehen auf Debezium MySQL Source Connector-Konfigurationseigenschaften um mehr zu erfahren.
Einige Einstellungen (key.converter.* und value.converter.*) sind spezifisch für die Schemaregistrierung. Wir benutzen das AWSKafkaAvroConverter von dem AWS Glue Schema-Registrierungsbibliothek als Formatkonverter. Konfigurieren AWSKafkaAvroConverter, verwenden wir den Wert der String-Konstanteneigenschaften in der AWSSchemaRegistryConstants Klasse:
key.converterundvalue.converterSteuern Sie das Format der Daten, die für Quellkonnektoren in Kafka geschrieben oder für Senkenkonnektoren aus Kafka gelesen werden. Wir gebrauchenAWSKafkaAvroConverterfür Avro-Format.key.converter.registry.nameundvalue.converter.registry.nameDefinieren Sie, welche Schemaregistrierung verwendet werden soll.key.converter.compatibilityundvalue.converter.compatibilityDefinieren Sie das Kompatibilitätsmodell.
Beziehen auf Verwenden von Kafka Connect mit AWS Glue Schema Registry um mehr zu erfahren.
- Als nächstes konfigurieren wir Anschlusskapazität. Wir können wählen Vorausgesetzt und belassen Sie andere Eigenschaften als Standard
- Aussichten für Worker-Konfiguration, wählen Sie die benutzerdefinierte Worker-Konfiguration mit beginnendem Namen aus
msk-gsr-blogerstellt als Teil der CloudFormation-Vorlage. - Aussichten für Zugriffsberechtigungen, Verwenden Sie die AWS Identity and Access Management and (IAM)-Rolle, die von der CloudFormation-Vorlage generiert wird
MSKConnectRole. - Auswählen Weiter.
- Aussichten für Sicherheit, wählen Sie die Standardeinstellungen.
- Auswählen Weiter.
- Aussichten für Lieferung protokollierenWählen An Amazon CloudWatch Logs liefern und suchen Sie nach der Protokollgruppe, die von der CloudFormation-Vorlage erstellt wurde (
msk-connector-logs). - Auswählen Weiter.
- Überprüfen Sie die Einstellungen und wählen Sie Konnektor erstellen.
Nach einigen Minuten wechselt der Connector in den Status Running.
Verwenden Sie die AWS Glue Schema Registry mit dem Confluent S3-Senkenkonnektor, der auf MSK Connect als MSK-Verbraucher ausgeführt wird
Wir stellen den Sink-Connector mit dem Confluent S3-Sink-Plugin bereit, um Daten von Amazon MSK zu Amazon S3 zu streamen. Führen Sie die folgenden Schritte aus:
-
- Auf der Amazon MSK-Konsole im Navigationsbereich unter MSK Connect, wählen Anschluss.
- Auswählen Konnektor erstellen.
- Auswählen
Verwenden Sie das vorhandene benutzerdefinierte Plugin und wählen Sie das benutzerdefinierte Plugin mit dem Namen beginnend aus
msk-blog-S3sink-plugin. - Auswählen Weiter.
- Geben Sie einen passenden Namen wie z
s3-sink-connectorund eine optionale Beschreibung. - Aussichten für Apache Kafka-Cluster, wählen MSK-Cluster und wählen Sie den von der CloudFormation-Vorlage erstellten Cluster aus.
- In Steckerkonfiguration, löschen Sie die bereitgestellten Standardwerte und verwenden Sie die folgenden Konfigurationsschlüssel/Wert-Paare mit den entsprechenden Werten:
-
- Name – Derselbe Name, der für den Konnektor verwendet wird.
- s3.bucket.name – Die CloudFormation-Ausgabe für Bucket-Name.
- s3.region, key.converter.region und value.converter.region – Ihre Region.
-
- Als nächstes konfigurieren wir Anschlusskapazität. Wir können wählen Vorausgesetzt und belassen Sie andere Eigenschaften als Standard
- Aussichten für Worker-Konfiguration, wählen Sie die benutzerdefinierte Worker-Konfiguration mit beginnendem Namen aus
msk-gsr-blogerstellt als Teil der CloudFormation-Vorlage. - Aussichten für Zugriffsberechtigungenverwenden Sie die von der CloudFormation-Vorlage generierte IAM-Rolle
MSKConnectRole. - Auswählen Weiter.
- Aussichten für Sicherheit, wählen Sie die Standardeinstellungen.
- Auswählen Weiter.
- Aussichten für Lieferung protokollierenWählen An Amazon CloudWatch Logs liefern und suchen Sie nach der Protokollgruppe, die von der CloudFormation-Vorlage erstellt wurde
msk-connector-logs. - Auswählen Weiter.
- Überprüfen Sie die Einstellungen und wählen Sie Konnektor erstellen.
Nach einigen Minuten läuft der Connector.
Testen Sie den End-to-End-CDC-Protokollstream
Nachdem sowohl der Debezium- als auch der S3-Sink-Connector betriebsbereit sind, führen Sie die folgenden Schritte aus, um die End-to-End-CDC zu testen:
- Navigieren Sie auf der Amazon EC2-Konsole zu der Sicherheitsgruppen
- Wählen Sie die Sicherheitsgruppe aus
ClientInstanceSecurityGroupund wählen Sie Eingehende Regeln bearbeiten. - Fügen Sie eine eingehende Regel hinzu, die eine SSH-Verbindung von Ihrem lokalen Netzwerk zulässt.
- Auf dem Instanzen Seite, wählen Sie die Instanz aus
ClientInstanceund wählen Sie Vernetz Dich. - Auf dem EC2-Instance-Verbindung Tab, wählen Sie Vernetz Dich.
- Stellen Sie sicher, dass Ihr aktuelles Arbeitsverzeichnis ist
/home/ec2-userund es hat die Dateiencreate_table.sql,alter_table.sql,initial_insert.sqlundinsert_data_with_new_column.sql. - Erstellen Sie eine Tabelle in Ihrer MySQL-Datenbank, indem Sie den folgenden Befehl ausführen (geben Sie den Datenbank-Hostnamen aus den Ausgaben der CloudFormation-Vorlage an):
- Wenn Sie zur Eingabe eines Passworts aufgefordert werden, geben Sie das Passwort aus den CloudFormation-Vorlagenparametern ein.
- Fügen Sie mit dem folgenden Befehl einige Beispieldaten in die Tabelle ein:
- Wenn Sie zur Eingabe eines Passworts aufgefordert werden, geben Sie das Passwort aus den CloudFormation-Vorlagenparametern ein.
- Wählen Sie in der AWS Glue-Konsole aus Schemaregistrierungen im Navigationsbereich und wählen Sie dann aus Schemata.
- Navigieren
db1.sampledatabase.moviesVersion 1, um das neue Schema zu überprüfen, das für die Filmtabelle erstellt wurde:
Für jede Partition des Kafka-Themas wird ein separater S3-Ordner erstellt, und Daten für das Thema werden in diesen Ordner geschrieben.
- Suchen Sie in der Amazon S3-Konsole nach Daten, die im Parquet-Format im Ordner für Ihr Kafka-Thema geschrieben sind.
Schemaentwicklung
Nachdem das anfängliche Schema definiert wurde, müssen Anwendungen es möglicherweise im Laufe der Zeit weiterentwickeln. In diesem Fall ist es entscheidend, dass die nachgelagerten Verbraucher Daten, die sowohl mit dem alten als auch mit dem neuen Schema codiert sind, nahtlos verarbeiten können. Mit Kompatibilitätsmodi können Sie steuern, wie sich Schemas im Laufe der Zeit entwickeln können oder nicht. Diese Modi bilden den Vertrag zwischen Anwendungen, die Daten produzieren und verbrauchen. Ausführliche Informationen zu den verschiedenen Kompatibilitätsmodi, die in der AWS Glue Schema Registry verfügbar sind, finden Sie unter AWS Glue-Schema-Registrierung. In unserem Beispiel verwenden wir die Rückwärtskämmbarkeit, um sicherzustellen, dass Verbraucher sowohl die aktuelle als auch die vorherige Schemaversion lesen können. Führen Sie die folgenden Schritte aus:
- Fügen Sie der Tabelle eine neue Spalte hinzu, indem Sie den folgenden Befehl ausführen:
- Fügen Sie neue Daten in die Tabelle ein, indem Sie den folgenden Befehl ausführen:
- Wählen Sie in der AWS Glue-Konsole aus Schemaregistrierungen im Navigationsbereich und wählen Sie dann aus Schemata.
- Navigieren Sie zum Schema
db1.sampledatabase.moviesVersion 2, um die neue Version des Schemas zu überprüfen, das für die Filme in der Tabelle Filme erstellt wurde, einschließlich der Länderspalte, die Sie hinzugefügt haben:
- Suchen Sie auf der Amazon S3-Konsole nach Daten, die im Parquet-Format im Ordner für das Kafka-Thema geschrieben sind.
Aufräumen
Um unerwünschte Belastungen Ihres AWS-Kontos zu vermeiden, löschen Sie die AWS-Ressourcen, die Sie in diesem Beitrag verwendet haben:
- Navigieren Sie in der Amazon S3-Konsole zu dem S3-Bucket, der von der CloudFormation-Vorlage erstellt wurde.
- Wählen Sie alle Dateien und Ordner aus und wählen Sie Löschen.
- Geben Sie wie angewiesen dauerhaft löschen ein und wählen Sie aus Objekte löschen.
- Löschen Sie in der AWS CloudFormation-Konsole den von Ihnen erstellten Stack.
- Warten Sie, bis sich der Stack-Status auf ändert DELETE_COMPLETE.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie Sie Amazon MSK, MSK Connect und die AWS Glue Schema Registry verwenden, um einen CDC-Protokollstream zu erstellen und Schemas für Datenströme zu entwickeln, wenn sich die Geschäftsanforderungen ändern. Sie können dieses Architekturmuster auf andere Datenquellen mit anderen Kafka-Konnektoren anwenden. Weitere Informationen finden Sie unter MSK Connect-Beispiele.
Über den Autor
 Kaljan Janaki ist Senior Big Data & Analytics Specialist bei Amazon Web Services. Er unterstützt Kunden beim Entwerfen und Erstellen hochskalierbarer, leistungsfähiger und sicherer Cloud-basierter Lösungen auf AWS.
Kaljan Janaki ist Senior Big Data & Analytics Specialist bei Amazon Web Services. Er unterstützt Kunden beim Entwerfen und Erstellen hochskalierbarer, leistungsfähiger und sicherer Cloud-basierter Lösungen auf AWS.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :Ist
- $UP
- 1
- 10
- 11
- 7
- 8
- a
- Fähig
- Über uns
- Zugang
- Konto
- genau
- anerkennen
- hinzugefügt
- Zusatz
- Alle
- Zulassen
- erlaubt
- bereits
- Amazon
- Amazon EC2
- Amazon Web Services
- Analytik
- und
- Apache
- Apache Kafka
- Anwendungen
- Jetzt bewerben
- angemessen
- Architektur
- SIND
- AS
- Aurora
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- AWS CloudFormation
- AWS-Kleber
- BE
- Bevor
- Vorteile
- zwischen
- Big
- Big Data
- Bootstrap
- bauen
- Geschäft
- by
- CAN
- Fähigkeiten
- Erfassung
- Capturing
- Fälle
- Katalog
- CDC
- zentralisierte
- Übernehmen
- Änderungen
- Gebühren
- aus der Ferne überprüfen
- Schecks
- Auswählen
- Klasse
- Cluster
- Kolonne
- community
- Kompatibilität
- kompatibel
- abschließen
- Komponente
- Berechnen
- Konfiguration
- Confluent
- Vernetz Dich
- Verbindung
- Konsul (Console)
- konstante
- verbrauchen
- Verbraucher
- KUNDEN
- ständig
- Vertrag
- Smartgeräte App
- Land
- erstellen
- erstellt
- kritischem
- Strom
- Original
- Kunden
- technische Daten
- Datenintegration
- datengesteuerte
- Datenbase
- Datenbanken
- Tage
- Entscheidungen
- Standard
- defaults
- definiert
- liefern
- Demo
- weisen nach, dass
- zeigt
- einsetzen
- Einsatz
- Beschreibung
- Reiseziel
- detailliert
- Details
- anders
- entdeckt,
- Tut nicht
- Drop
- jeder
- eliminiert
- ermöglichen
- End-to-End
- gewährleisten
- sorgt
- Enter
- Arbeitsumfeld
- Fehler
- insbesondere
- Äther (ETH)
- Jedes
- entwickelt sich
- Beispiel
- vorhandenen
- existiert
- wenige
- Felder
- Reichen Sie das
- Mappen
- Finale
- Vorname
- Folgende
- Aussichten für
- unten stehende Formular
- Format
- für
- erzeugen
- erzeugt
- Gruppe an
- Gruppen
- Griff
- Handling
- das passiert
- Haben
- Hilfe
- hilft
- hoch
- Geschichte
- Gastgeber
- STUNDEN
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- Nabe
- IAM
- Identifizierung
- Identitätsschutz
- Implementierung
- wichtig
- in
- Einschließlich
- Indizes
- Information
- Anfangs-
- installieren
- Instanz
- beantragen müssen
- integrieren
- Integration
- intern
- IT
- Javac
- jpg
- JSON
- kafka
- Wesentliche
- Wissen
- Verlassen
- Bibliotheken
- Zugelassen
- Gefällt mir
- Belastung
- Laden
- aus einer regionalen
- Lang
- gemacht
- MACHT
- Making
- verwaltet
- Master
- max
- maximal
- Mechanismus
- Nachricht
- Nachrichten
- könnte
- Minuten
- Modell
- Modi
- Monitore
- mehr
- Filme
- ziehen um
- mehrere
- MySQL
- Name
- Navigieren
- Navigation
- Need
- erforderlich
- Bedürfnisse
- Netzwerk
- Neu
- weiter
- Anzahl
- of
- Alt
- on
- EINEM
- Open-Source-
- Andere
- Möglichkeiten für das Ausgangssignal:
- Seite
- Paare
- Brot
- Parameter
- Parameter
- Teil
- Bestanden
- Passwort
- Schnittmuster
- ausführen
- permanent
- wählen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Plugin
- Plugins
- Post
- verhindern
- früher
- Prozessdefinierung
- Verarbeitung
- produziert
- Hersteller
- immobilien
- die
- vorausgesetzt
- bietet
- Lesen Sie mehr
- echt
- Echtzeit
- erhalten
- Rekord
- Aufzeichnungen
- bezieht sich
- Region
- Registrieren
- eingetragen
- Registratur
- Quelle
- vertreten
- Downloads
- Rückgabe
- Rollen
- Regel
- Führen Sie
- Laufen
- gleich
- skalierbaren
- nahtlos
- Suche
- Sekunden
- Verbindung
- Sicherheitdienst
- Senior
- empfindlich
- getrennte
- Leistungen
- kompensieren
- Einstellungen
- sollte
- Einfacher
- vereinfachen
- Lösung
- Lösungen
- einige
- Quelle
- Quellen
- Spezialist
- spezifisch
- angegeben
- Stapel
- Beginnen Sie
- Status
- Schritt
- Shritte
- Lagerung
- speichern
- Läden
- Strom
- Streaming
- Ströme
- Struktur
- geeignet
- Unterstützung
- Unterstützt
- synchronisieren
- System
- Systeme und Techniken
- Tabelle
- Target
- und Aufgaben
- Vorlage
- Test
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- Sie
- Diese
- Zeit
- Zeitempfindlich
- Titel
- zu
- Thema
- Transaktionen
- WENDE
- Typen
- für
- unerwünscht
- Aktualisierung
- -
- Mitglied
- Wert
- Werte
- Version
- Netz
- Web-Services
- welche
- werden wir
- Fenster
- mit
- Arbeiter
- Arbeiter
- arbeiten,
- Werk
- geschrieben
- Ihr
- Zephyrnet