- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :Ist
- 10
- 100
- 15%
- 2023
- 7
- a
- Fähig
- über
- Die Annahme
- AI
- gleich
- Alle
- Obwohl
- unter
- an
- und
- Antworten
- angewandt
- SIND
- AS
- fragen
- Aspekte
- Assistenten
- damit verbundenen
- At
- Attacke
- Anschläge
- verfügbar
- ein Weg
- BE
- Sein
- zwischen
- Milliarden
- bauen
- Unternehmen
- aber
- by
- CAN
- vorsichtig
- CEO
- Chatbots
- ChatGPT
- klar
- geschlossen
- gemeinsam
- Unternehmen
- Computer
- Hautpflegeprobleme
- über
- Konferenz
- könnte
- erstellen
- Erstellen
- kritischem
- Zur Zeit
- Cyber-
- Datum
- zeigen
- Synergie
- Bereitstellen
- detailliert
- Entdeckung
- entwickeln
- anders
- digital
- entdeckt
- dr
- Unternehmen
- Ganz
- Sogar
- Beweis
- existieren
- vorhandenen
- Ausnutzen
- Extraktion
- äußerst
- faszinierend
- Revolution
- Finanzdienstleistungen
- Vorname
- konzentriert
- Aussichten für
- für
- weiter
- gewonnen
- gegeben
- Unterstützung
- Boden
- Haben
- versteckt
- Highlights
- gehostet
- Ultraschall
- Hilfe
- aber
- HTTPS
- Umarmendes Gesicht
- wichtig
- in
- hat
- zunehmend
- Energiegewinnung
- informieren
- Information
- Informationssicherheit
- aufschlussreiche
- Internet
- Investieren
- Investitionen
- IT
- jpg
- Wesentliche
- Wissen
- bekannt
- Sprache
- grosse
- Große Unternehmen
- starten
- führenden
- LERNEN
- lernen
- weniger
- wenig
- Maschine
- Maschinelles Lernen
- Dur
- Kann..
- Messen
- Millionen
- Modell
- für
- viel
- Neu
- of
- on
- XNUMXh geöffnet
- Open-Source-
- or
- besitzen
- Papier
- Party
- Jürgen
- Länder/Regionen
- Planung
- Plato
- Datenintelligenz von Plato
- PlatoData
- möglich
- möglicherweise
- größte treibende
- Vorbereitung
- vorgeführt
- Principal
- privat
- die
- öffentlich
- Angebot
- Bewerten
- repliziert
- Zugriffe
- Forschungsprojekte
- Forscher
- zeigen
- Risiken
- Said
- Wissenschaftler
- Sicherheitdienst
- Lösungen
- kompensieren
- sollte
- erklären
- kleinere
- smart
- So
- einige
- Quelle
- Stufe
- anfang
- Sturm
- Studie
- Erfolg
- Erfolgreich
- so
- gemacht
- sprechen
- gezielt
- Targeting
- und Aufgaben
- Team
- Technologies
- Technologie
- Testen
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- die Informationen
- Großbritannien
- die Welt
- ihr
- dann
- Dort.
- Diese
- vom Nutzer definierten
- think
- Dritte
- fehlen uns die Worte.
- dieses Jahr
- mal
- zu
- Werkzeuge
- übertragen
- Transformativ
- Uk
- Verständnis
- unternehmen
- Universität
- -
- benutzt
- verwendet
- geschätzt
- sehr
- Sicherheitslücken
- wurde
- Weg..
- we
- Woche
- waren
- welche
- breit
- Große Auswahl
- werden wir
- mit
- .
- ohne
- Arbeiten
- trainieren
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- besorgniserregend
- Jahr
- Zephyrnet
Mehr von Nanowerk
Beginn einer neuen Ära farbabstimmbarer Nanogeräte – kleinste Lichtquelle aller Zeiten mit umschaltbaren Farben
Quellknoten: 2801585
Zeitstempel: 3. August 2023

„Magisches“ Lösungsmittel erzeugt stärkere dünne Filme
Quellknoten: 1957849
Zeitstempel: 14. Februar 2023
Kohlenstoffnanoröhren könnten eine wichtige Rolle bei der Bindung von atmosphärischem Kohlendioxid spielen
Quellknoten: 2836729
Zeitstempel: 21. August 2023

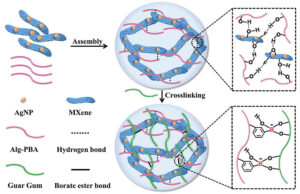
Antibakterielle Epidermissensoren auf MXene-Hydrogelbasis
Quellknoten: 2661017
Zeitstempel: 18. Mai 2023
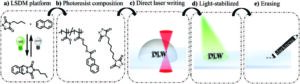
3D-Drucke schließen sich der dunklen Seite an und verschwinden
Quellknoten: 2903619
Zeitstempel: 27. September 2023
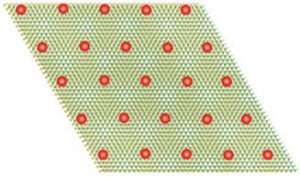
Wenn Material zu Quanten wird, werden Elektronen langsamer und bilden einen Kristall
Quellknoten: 1975767
Zeitstempel: 23. Februar 2023

Ingenieure entwickeln ein effizientes Verfahren zur Herstellung von Treibstoff aus Kohlendioxid
Quellknoten: 2963812
Zeitstempel: 30. Oktober 2023