Amazon OpenSearch-Dienst kürzlich eingeführt Multi-AZ mit Standby, eine Bereitstellungsoption, die Unternehmen eine verbesserte Verfügbarkeit und konsistente Leistung für kritische Workloads bieten soll. Mit dieser Funktion können verwaltete Cluster eine Verfügbarkeit von 99.99 % erreichen und gleichzeitig widerstandsfähig gegenüber Ausfällen der zonalen Infrastruktur bleiben.
In diesem Beitrag untersuchen wir, wie Suche und Indizierung mit Multi-AZ mit Standby funktionieren, und befassen uns mit den zugrunde liegenden Mechanismen, die zu seiner Zuverlässigkeit, Einfachheit und Fehlertoleranz beitragen.
Hintergrund
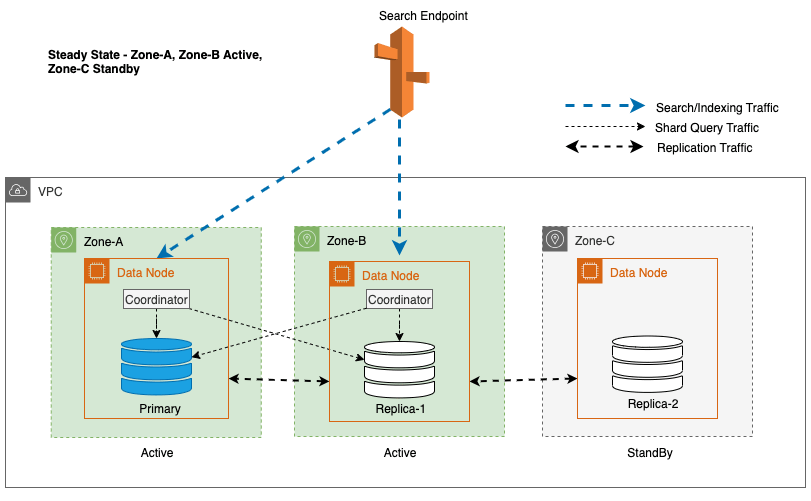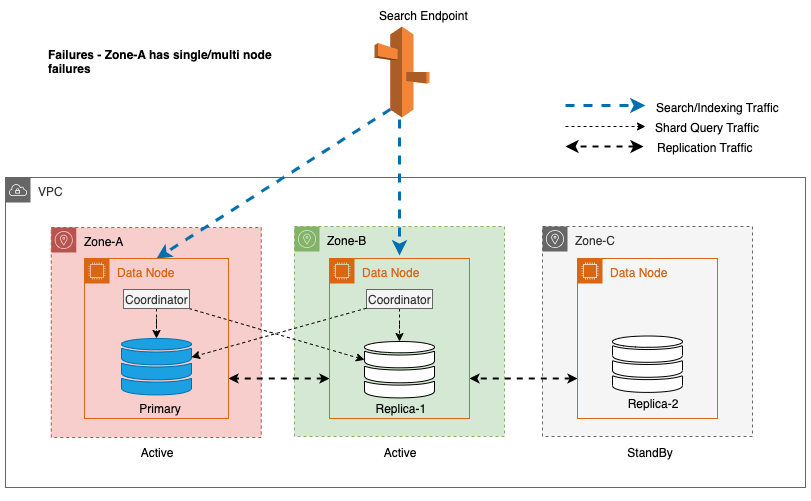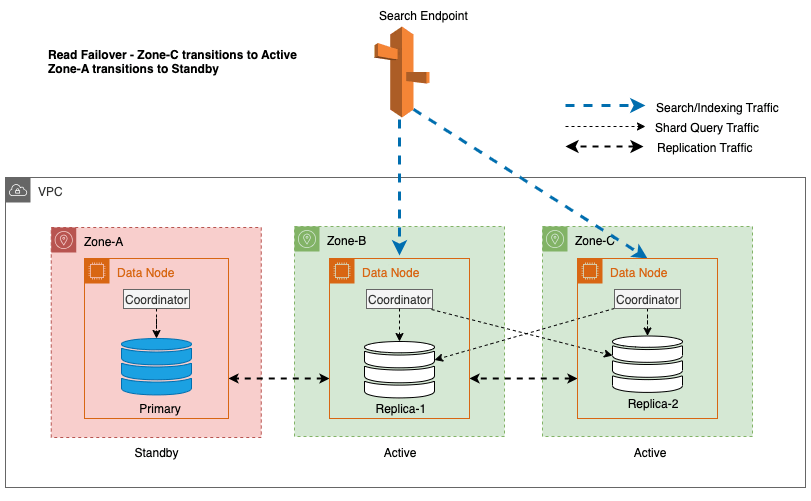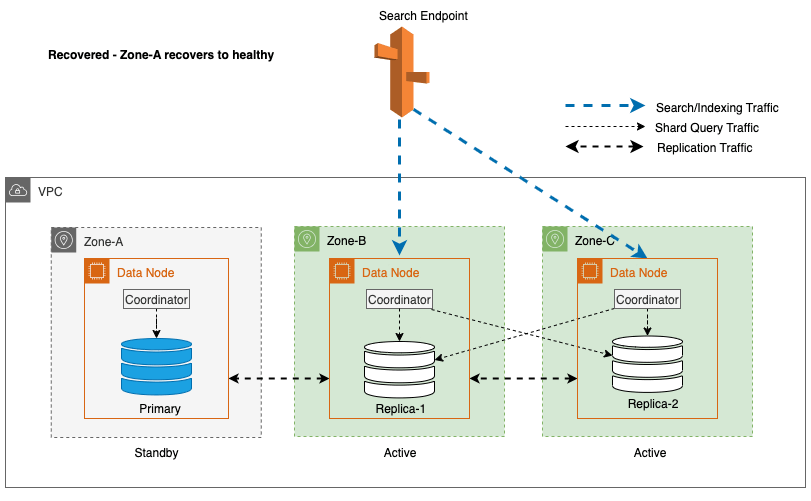
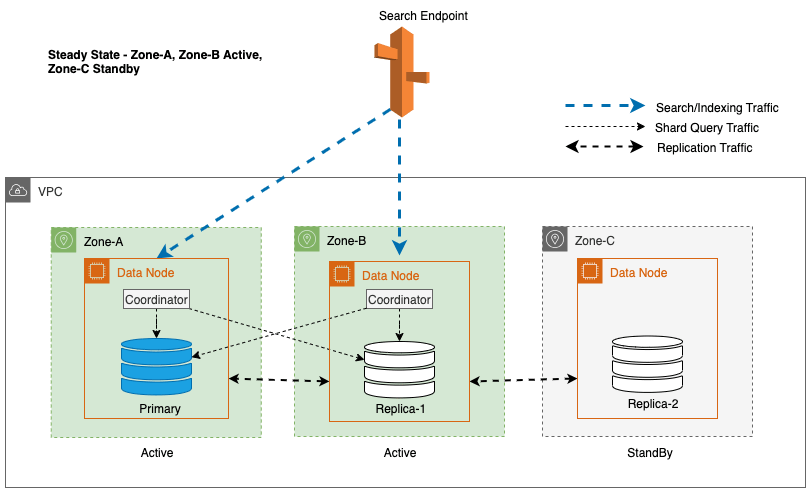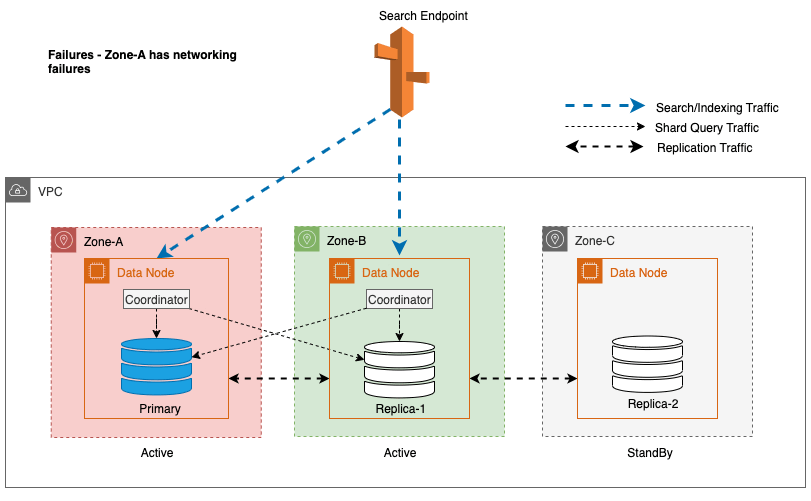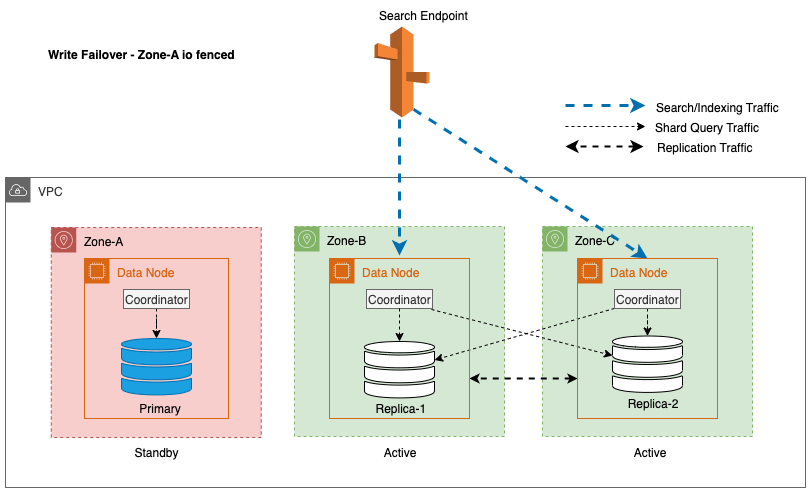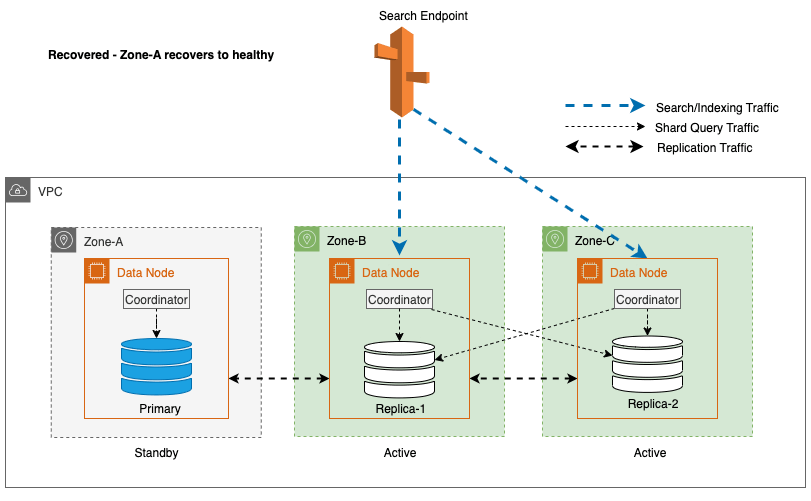
Multi-AZ mit Standby stellt OpenSearch Service-Domäneninstanzen in drei Availability Zones bereit, wobei zwei Zonen als aktiv und eine als Standby gekennzeichnet sind. Diese Konfiguration gewährleistet eine konsistente Leistung auch bei Zonenausfällen, indem in allen Zonen die gleiche Kapazität aufrechterhalten wird. Wichtig ist, dass diese Standby-Zone a folgt statisch stabile AusführungDadurch entfällt die Notwendigkeit einer Kapazitätsbereitstellung oder Datenverschiebung bei Ausfällen.
Während des regulären Betriebs verarbeitet die aktive Zone den Koordinatorverkehr für Lese- und Schreibanforderungen sowie den Shard-Abfrageverkehr. Die Standby-Zone hingegen empfängt nur Replikationsverkehr. Der OpenSearch-Dienst verwendet ein synchrones Replikationsprotokoll für Schreibanforderungen. Dies ermöglicht es dem Dienst, eine Standby-Zone im Falle eines Fehlers (mittlere Zeit bis zum Failover <= 1 Minute), bekannt als a, umgehend in den aktiven Status heraufzustufen Zonen-Failover. Die zuvor aktive Zone wird dann in den Standby-Modus herabgestuft und Wiederherstellungsvorgänge beginnen, um ihren fehlerfreien Zustand wiederherzustellen.
Durchsuchen Sie Traffic-Routing und Failover, um eine hohe Verfügbarkeit zu gewährleisten
In einer OpenSearch Service-Domäne a Koordinator ist ein beliebiger Knoten, der HTTP(S)-Anfragen verarbeitet, insbesondere Indizierungs- und Suchanfragen. In einer Multi-AZ mit Standby-Domäne fungieren die Datenknoten in der aktiven Zone als Koordinatoren für Suchanfragen.
Während der Abfragephase einer Suchanfrage bestimmt der Koordinator die abzufragenden Shards und sendet eine Anfrage an den Datenknoten, der die Shard-Kopie hostet. Die Abfrage wird lokal auf jedem Shard ausgeführt und übereinstimmende Dokumente werden an den Koordinatorknoten zurückgegeben. Der Koordinatorknoten, der für das Senden der Anfrage an Knoten mit Shard-Kopien verantwortlich ist, führt den Prozess in zwei Schritten aus. Zunächst wird ein Iterator erstellt, der die Reihenfolge definiert, in der Knoten nach einer Shard-Kopie abgefragt werden müssen, damit der Datenverkehr gleichmäßig auf die Shard-Kopien verteilt wird. Anschließend wird die Anfrage an die entsprechenden Knoten gesendet.
Um eine geordnete Liste von Knoten zu erstellen, die nach einer Shard-Kopie abgefragt werden sollen, verwendet der Koordinatorknoten verschiedene Algorithmen. Zu diesen Algorithmen gehören Round-Robin-Auswahl, adaptive Replikatauswahl, präferenzbasiertes Shard-Routing usw gewichtetes Round-Robin.
Bei Multi-AZ mit Standby wird der gewichtete Round-Robin-Algorithmus für die Auswahl der Shard-Kopie verwendet. Bei diesem Ansatz wird den aktiven Zonen eine Gewichtung von 1 und der Standby-Zone eine Gewichtung von 0 zugewiesen. Dadurch wird sichergestellt, dass kein Leseverkehr an Datenknoten in der Standby-Availability Zone gesendet wird.
Die Gewichtungen werden in den Metadaten des Clusterstatus als JSON-Objekt gespeichert:
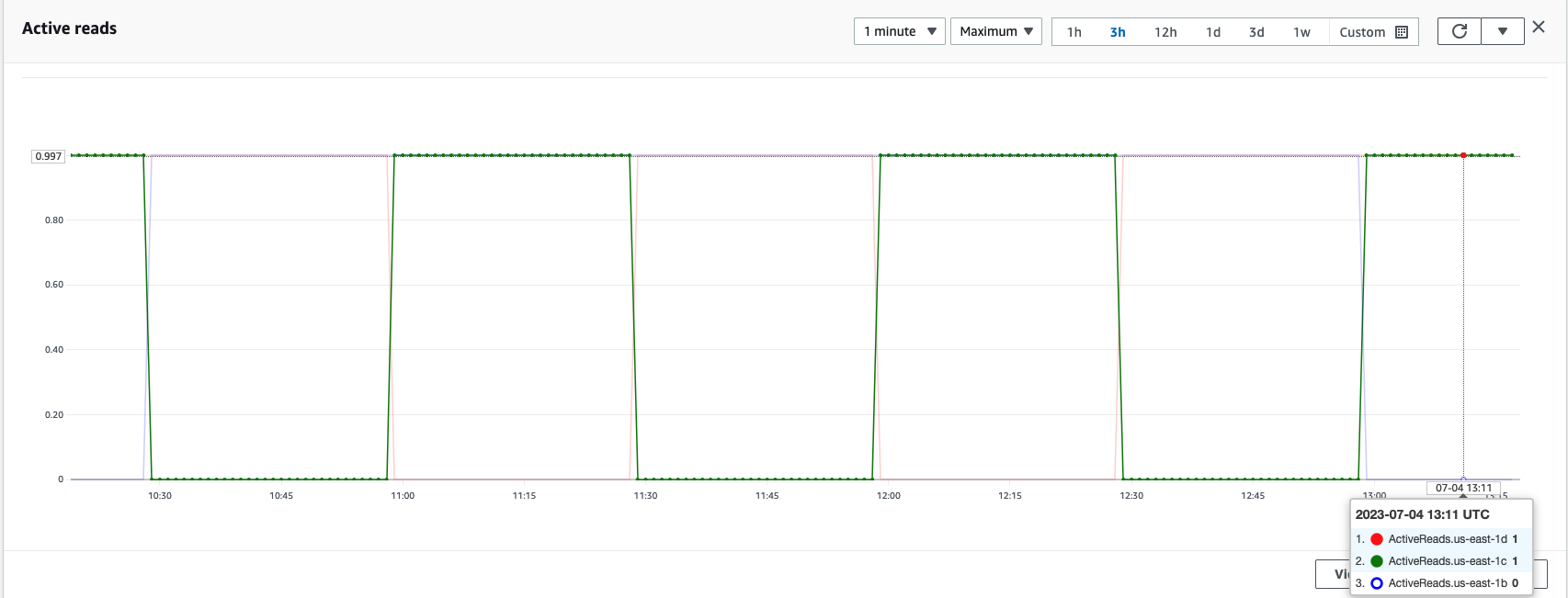
Wie im folgenden Screenshot gezeigt, ist die us-east-1b Die Region hat ihren Zonenstatus als StandBy, was darauf hinweist, dass sich die Datenknoten in dieser Availability Zone im Standby-Zustand befinden und keine Such- oder Indizierungsanforderungen vom Load Balancer erhalten.

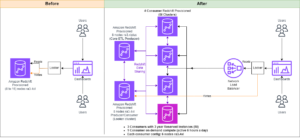
Um einen stabilen Betrieb aufrechtzuerhalten, wird die Standby-Availability Zone alle 30 Minuten gewechselt, um sicherzustellen, dass alle Netzwerkteile über die Availability Zones hinweg abgedeckt sind. Dieser proaktive Ansatz überprüft die Verfügbarkeit von Lesepfaden und erhöht so die Widerstandsfähigkeit des Systems bei potenziellen Ausfällen weiter. Das folgende Diagramm veranschaulicht diese Architektur.
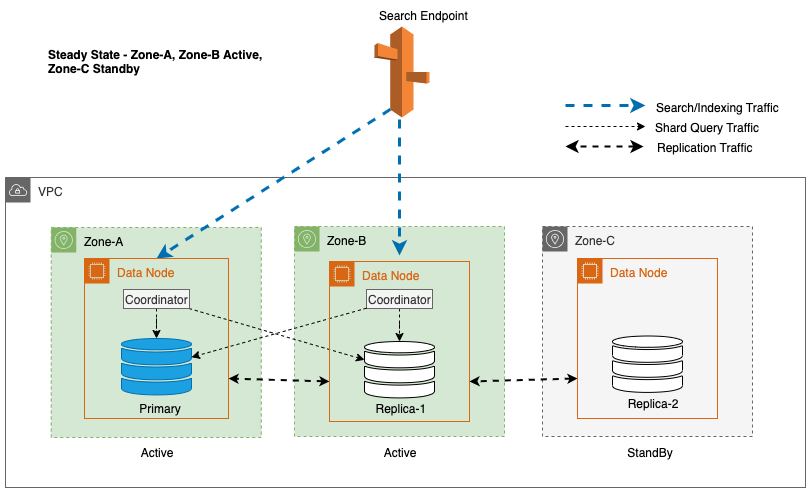
Im vorherigen Diagramm ist für Zone-C eine gewichtete Round-Robin-Gewichtung auf Null gesetzt. Dadurch wird sichergestellt, dass die Datenknoten in der Standby-Zone keinen Indexierungs- oder Suchverkehr erhalten. Wenn der Koordinator Datenknoten nach Shard-Kopien abfragt, verwendet er eine gewichtete Round-Robin-Gewichtung, um über die Reihenfolge zu entscheiden, in der die Knoten abgefragt werden sollen. Da die Gewichtung für die Standby-Availability Zone Null ist, werden keine Koordinatoranfragen gesendet.
In einem OpenSearch Service-Cluster können die aktiven und Standby-Zonen jederzeit mithilfe von Availability Zone-Rotationsmetriken überprüft werden, wie im folgenden Screenshot gezeigt.
Bei Zonenausfällen wechselt die Standby-Availability Zone nahtlos in den Fail-Open-Modus für Suchanfragen. Dies bedeutet, dass der Shard-Abfrageverkehr an alle Availability Zones weitergeleitet wird, auch an die im Standby-Modus, wenn eine fehlerfreie Shard-Kopie in der aktiven Availability Zone nicht verfügbar ist. Dieser Fail-Open-Ansatz schützt Suchanfragen vor Unterbrechungen bei Ausfällen und gewährleistet so einen kontinuierlichen Service. Das folgende Diagramm veranschaulicht diese Architektur.
Im vorherigen Diagramm wird im stabilen Zustand der Shard-Abfrageverkehr an den Datenknoten in den aktiven Availability Zones (Zone-A und Zone-B) gesendet. Aufgrund von Knotenausfällen in Zone-A ist die Standby-Verfügbarkeitszone (Zone-C) nicht für den Shard-Abfrageverkehr geöffnet, sodass es keine Auswirkungen auf die Suchanfragen gibt. Schließlich wird Zone-A als fehlerhaft erkannt und das Lese-Failover schaltet den Standby-Modus auf Zone-A um.
Wie ein Failover bei Schreibbeeinträchtigungen eine hohe Verfügbarkeit gewährleistet
Das Replikationsmodell des OpenSearch Service folgt einem primären Backup-Modell, das sich durch seinen synchronen Charakter auszeichnet, bei dem eine Bestätigung von allen Shard-Kopien erforderlich ist, bevor eine Schreibanforderung an den Benutzer bestätigt werden kann. Ein bemerkenswerter Nachteil dieses Replikationsmodells ist seine Anfälligkeit für Verlangsamungen im Falle einer Beeinträchtigung des Schreibpfads. Diese Systeme verlassen sich auf einen aktiven führenden Knoten, um Ausfälle oder Verzögerungen zu erkennen und diese Informationen dann an alle Knoten weiterzuleiten. Die Dauer, die benötigt wird, um diese Probleme zu erkennen (mittlere Erkennungszeit) und anschließend zu beheben (mittlere Reparaturzeit), bestimmt weitgehend, wie lange das System in einem beeinträchtigten Zustand betrieben wird. Darüber hinaus kann jedes Netzwerkereignis, das sich auf die Kommunikation zwischen Zonen auswirkt, aufgrund der synchronen Natur der Replikation Schreibanforderungen erheblich behindern.
Der OpenSearch-Dienst nutzt ein internes Knoten-zu-Knoten-Kommunikationsprotokoll zur Replikation des Schreibverkehrs und zur Koordinierung von Metadatenaktualisierungen durch einen gewählten Leiter. Folglich würde das Versetzen der belasteten Zone in den Standby-Modus das Problem der Schreibbeeinträchtigung nicht wirksam lösen.
Zonenaler Schreib-Failover: Unterbrechen des zonenübergreifenden Replikationsverkehrs
Für Multi-AZ mit Standby ist zonales Schreib-Failover ein wirksamer Ansatz, um potenzielle Leistungsprobleme zu mindern, die durch unvorhergesehene Ereignisse wie Zonenausfälle und Netzwerkereignisse verursacht werden. Dieser Ansatz beinhaltet die ordnungsgemäße Entfernung von Knoten in der betroffenen Zone aus dem Cluster, wodurch der ein- und ausgehende Datenverkehr zwischen den Zonen effektiv unterbrochen wird. Durch die Trennung des zonenübergreifenden Replikationsverkehrs können die Auswirkungen von Zonenausfällen innerhalb der betroffenen Zone eingedämmt werden. Dies bietet den Kunden ein vorhersehbareres Erlebnis und stellt sicher, dass das System weiterhin zuverlässig funktioniert.
Graceful Write-Failover
Die Orchestrierung eines Schreib-Failovers innerhalb des OpenSearch-Dienstes wird vom gewählten Führungsknoten über einen genau definierten Mechanismus durchgeführt. Dieser Mechanismus beinhaltet ein Konsensprotokoll für die Veröffentlichung des Clusterstatus, das eine einstimmige Zustimmung aller Knoten zur Festlegung einer einzigen Zone (jederzeit) für die Stilllegung gewährleistet. Wichtig ist, dass Metadaten im Zusammenhang mit der betroffenen Zone auf allen Knoten repliziert werden, um ihre Persistenz auch während eines vollständigen Neustarts im Falle eines Ausfalls sicherzustellen.
Darüber hinaus sorgt der Leader-Knoten für einen reibungslosen und reibungslosen Übergang, indem er die Knoten in den betroffenen Zonen zunächst für eine Dauer von 5 Minuten in den Standby-Modus versetzt, bevor er das I/O-Fencing initiiert. Dieser bewusste Ansatz verhindert, dass neuer Koordinatorverkehr oder Shard-Abfrageverkehr an die Knoten innerhalb der betroffenen Zone weitergeleitet wird. Dies wiederum ermöglicht es diesen Knoten, ihre laufenden Aufgaben ordnungsgemäß zu erledigen und alle Inflight-Anfragen nach und nach zu bearbeiten, bevor sie außer Betrieb genommen werden. Das folgende Diagramm veranschaulicht diese Architektur.
Bei der Implementierung eines Schreib-Failovers für einen Leader-Knoten befolgt OpenSearch Service die folgenden wichtigen Schritte:
- Abdankung des Anführers – Wenn sich der Leader-Knoten zufällig in einer Zone befindet, die für einen Schreib-Failover geplant ist, stellt das System sicher, dass der Leader-Knoten freiwillig von seiner Führungsrolle zurücktritt. Dieser Verzicht erfolgt kontrolliert und der gesamte Prozess wird an einen anderen berechtigten Knoten übergeben, der dann die erforderlichen Maßnahmen übernimmt.
- Verhindern Sie die Wiederwahl des aus dem Amt kommenden Führers – Um die Wiederwahl eines Leaders aus einer für Schreib-Failover markierten Zone zu verhindern, ergreift der berechtigte Leader-Knoten, wenn er die Schreib-Failover-Aktion initiiert, Maßnahmen, um sicherzustellen, dass alle außer Betrieb genommenen Leader-Knoten nicht an weiteren Wahlen teilnehmen. Dies wird dadurch erreicht, dass der zu stilllegende Führungsknoten von der Abstimmungskonfiguration ausgeschlossen wird, wodurch er effektiv daran gehindert wird, in kritischen Phasen des Clusterbetriebs abzustimmen.
Metadaten im Zusammenhang mit der Schreib-Failover-Zone werden im Clusterstatus gespeichert und diese Informationen werden wie folgt auf allen Knoten im verteilten OpenSearch Service-Cluster veröffentlicht:
Der folgende Screenshot zeigt, dass während einer Netzwerkverlangsamung in einer Zone ein Schreib-Failover dabei hilft, die Verfügbarkeit wiederherzustellen.
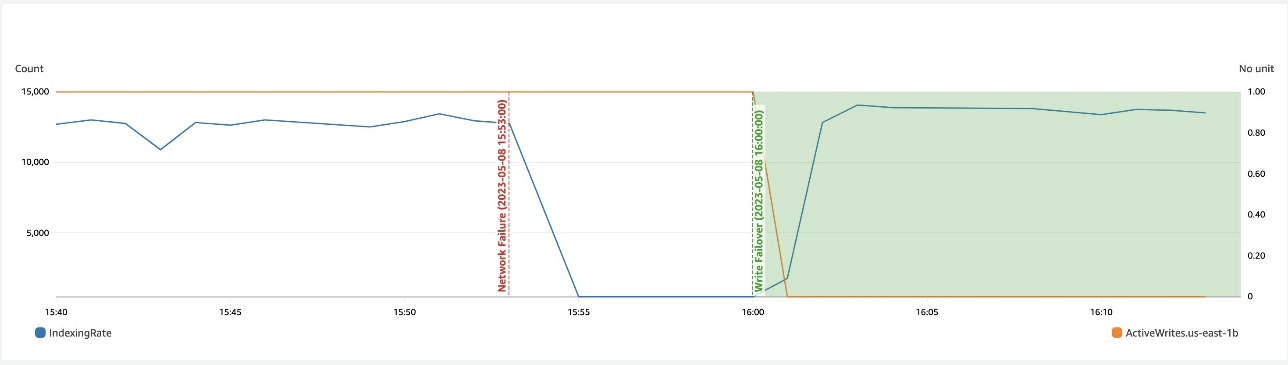
Zonenwiederherstellung nach Schreib-Failover
Der Prozess der zonalen Wiederinbetriebnahme spielt eine entscheidende Rolle in der Wiederherstellungsphase nach einem zonalen Schreib-Failover. Nachdem die betroffene Zone wiederhergestellt wurde und als stabil gilt, werden die zuvor außer Betrieb genommenen Knoten wieder dem Cluster beitreten. Diese Wiederinbetriebnahme erfolgt typischerweise innerhalb eines Zeitrahmens von 2 Minuten nach der Wiederinbetriebnahme der Zone.
Dies ermöglicht ihnen die Synchronisierung mit ihren Peer-Knoten und leitet den Wiederherstellungsprozess für Replikat-Shards ein, wodurch der Cluster effektiv in den gewünschten Zustand zurückversetzt wird.
Zusammenfassung
Die Einführung von OpenSearch Service Multi-AZ mit Standby bietet Unternehmen eine leistungsstarke Lösung, um hohe Verfügbarkeit und konsistente Leistung für kritische Workloads zu erreichen. Mit dieser Bereitstellungsoption können Unternehmen die Widerstandsfähigkeit ihrer Infrastruktur verbessern, die Clusterkonfiguration und -verwaltung vereinfachen und Best Practices durchsetzen. Mit Funktionen wie der gewichteten Round-Robin-Shard-Kopienauswahl, proaktiven Failover-Mechanismen und Fail-Open-Standby-Verfügbarkeitszonen gewährleistet OpenSearch Service Multi-AZ mit Standby ein zuverlässiges und effizientes Sucherlebnis für anspruchsvolle Unternehmensumgebungen.
Weitere Informationen zu Multi-AZ mit Standby finden Sie unter Amazon OpenSearch-Service unter der Haube: Multi-AZ mit Standby.
Über den Autor
 Anshu Agarwal ist Senior Software Engineer und arbeitet an AWS OpenSearch bei Amazon Web Services. Ihre Leidenschaft gilt der Lösung von Problemen im Zusammenhang mit dem Aufbau skalierbarer und hochzuverlässiger Systeme.
Anshu Agarwal ist Senior Software Engineer und arbeitet an AWS OpenSearch bei Amazon Web Services. Ihre Leidenschaft gilt der Lösung von Problemen im Zusammenhang mit dem Aufbau skalierbarer und hochzuverlässiger Systeme.
 Rishab Nahata ist ein Software Engineer, der bei Amazon Web Services an OpenSearch arbeitet. Er ist fasziniert davon, Probleme in verteilten Systemen zu lösen. Er ist aktiver Mitarbeiter von OpenSearch.
Rishab Nahata ist ein Software Engineer, der bei Amazon Web Services an OpenSearch arbeitet. Er ist fasziniert davon, Probleme in verteilten Systemen zu lösen. Er ist aktiver Mitarbeiter von OpenSearch.
 Buchtawar Khan ist leitender Ingenieur und arbeitet am Amazon OpenSearch Service. Sein Interesse gilt verteilten und autonomen Systemen. Er ist ein aktiver Mitarbeiter von OpenSearch.
Buchtawar Khan ist leitender Ingenieur und arbeitet am Amazon OpenSearch Service. Sein Interesse gilt verteilten und autonomen Systemen. Er ist ein aktiver Mitarbeiter von OpenSearch.
 Ranjith Ramachandra ist Engineering Manager und arbeitet am Amazon OpenSearch Service bei Amazon Web Services.
Ranjith Ramachandra ist Engineering Manager und arbeitet am Amazon OpenSearch Service bei Amazon Web Services.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :hast
- :Ist
- :nicht
- :Wo
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Über uns
- Erreichen
- erreicht
- anerkannt
- über
- Handlung
- Action
- Aktionen
- aktiv
- adaptiv
- zusätzlich
- Adresse
- betroffen
- Nach der
- Zustimmung
- Algorithmus
- Algorithmen
- Alle
- erlauben
- Amazon
- Amazon Web Services
- unter
- an
- und
- Ein anderer
- jedem
- Ansatz
- Architektur
- SIND
- AS
- zugewiesen
- At
- Autonom
- autonome Systeme
- Verfügbarkeit
- Bewusstsein
- AWS
- Sicherungskopie
- Balancer
- BE
- weil
- war
- Bevor
- Sein
- BESTE
- Best Practices
- zwischen
- beide
- Sendung
- Building
- Unternehmen
- by
- CAN
- Kapazität
- durchgeführt
- verursacht
- dadurch gekennzeichnet
- berechnen
- geprüft
- Cluster
- Kommunikation
- Kommunikation
- abschließen
- Konfiguration
- Konsens
- Folglich
- betrachtet
- konsistent
- Konsul (Console)
- enthalten
- weiter
- kontinuierlich
- beitragen
- Beiträger
- gesteuert
- koordinieren
- -Koordinator
- Koordinatoren
- Kopien
- bedeckt
- erstellen
- schafft
- kritischem
- wichtig
- Kunden
- Schneiden
- technische Daten
- entscheidet
- tief
- Tieftauchgang
- Definiert
- Verzögerungen
- vertiefen
- anspruchsvoll
- Einsatz
- setzt ein
- bezeichnet
- entworfen
- erwünscht
- entdecken
- erkannt
- entschlossen
- gerichtet
- Störung
- verteilt
- verteilte Systeme
- tauchen
- do
- Unterlagen
- Domain
- Domains
- Nicht
- nach unten
- zwei
- Dauer
- im
- jeder
- Effektiv
- effektiv
- effizient
- gewählt
- Wahlen
- förderfähigen
- eliminieren
- freigegeben
- ermöglicht
- erzwingen
- Ingenieur
- Entwicklung
- zu steigern,
- verbesserte
- Eine Verbesserung der
- gewährleisten
- sorgt
- Gewährleistung
- Unternehmen
- Ganz
- Umgebungen
- insbesondere
- Äther (ETH)
- Sogar
- Event
- Veranstaltungen
- schließlich
- Jedes
- ohne
- ERFAHRUNGEN
- erleben
- ERKUNDEN
- scheitert
- Scheitern
- Ausfälle
- Merkmal
- Eigenschaften
- Fechten
- Vorname
- Folgende
- folgt
- Aussichten für
- FRAME
- für
- voller
- weiter
- gif
- Anmutig
- allmählich
- Garantie
- Pflege
- Griff
- Griffe
- das passiert
- he
- gesund
- hilft
- GUTE
- hoch
- Haube
- Hosting
- Ultraschall
- http
- HTTPS
- identifizieren
- if
- zeigt
- Impact der HXNUMXO Observatorien
- wirkt
- Beeinträchtigung
- Umsetzung
- wichtig
- in
- das
- Anzeige
- Information
- Infrastruktur
- anfänglich
- Initiiert
- Einleiten
- Instanzen
- interessiert
- intern
- in
- eingeführt
- Einleitung
- beinhaltet
- Problem
- Probleme
- IT
- SEINE
- jpg
- JSON
- Wesentliche
- bekannt
- weitgehend
- Führer
- Leadership
- Gefällt mir
- Liste
- Belastung
- örtlich
- located
- Lang
- halten
- Aufrechterhaltung
- verwaltet
- Management
- Manager
- Weise
- markiert
- abgestimmt
- bedeuten
- Mittel
- Maßnahmen
- Mechanismus
- Mechanismen
- Metadaten
- Metrik
- Minute
- Minuten
- Mildern
- Model
- Modell
- mehr
- Bewegung
- Natur
- notwendig,
- Need
- Netzwerk
- Vernetzung
- Neu
- nicht
- Knoten
- Fiber Node
- bemerkenswert
- Objekt
- of
- WOW!
- on
- EINEM
- laufend
- einzige
- XNUMXh geöffnet
- betreiben
- Betrieb
- Einkauf & Prozesse
- Option
- or
- Orchesterbearbeitung
- Auftrag
- Andere
- Ausfall
- Ausfälle
- übrig
- teilnehmen
- Teile
- leidenschaftlich
- Weg
- Pfade
- Peer
- Leistung
- Beharrlichkeit
- Phase
- Platzierung
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielt
- Post
- Potenzial
- größte treibende
- Praktiken
- vor
- Vorhersagbar
- verhindern
- Verhütung
- verhindert
- vorher
- primär
- Principal
- Proaktives Handeln
- Probleme
- Prozessdefinierung
- fördern
- Protokoll
- die
- bietet
- Publikationen
- veröffentlicht
- Putting
- Abfragen
- Lesen Sie mehr
- erhalten
- erhält
- kürzlich
- Entspannung
- erholt
- Erholung
- siehe
- Region
- regulär
- bezogene
- relevant
- Zuverlässigkeit
- zuverlässig
- verlassen
- verbleibenden
- Entfernung
- Knorpel zu reparieren,
- antworten
- repliziert
- Replikation
- Anforderung
- Zugriffe
- falls angefordert
- Elastizität
- federnde
- lösen
- für ihren Verlust verantwortlich.
- wiederherstellen
- wiederhergestellt
- Wiederherstellen
- Rollen
- Routing
- Führen Sie
- läuft
- s
- Schutzmaßnahmen
- gleich
- skalierbaren
- vorgesehen
- nahtlos
- Suche
- Auswahl
- Sendung
- sendet
- Senior
- geschickt
- Dienstleistungen
- kompensieren
- sie
- gezeigt
- bedeutend
- Einfachheit
- vereinfachen
- Single
- Langsamer
- Verlangsamungen
- glätten
- So
- Software
- Software IngenieurIn
- Lösung
- Auflösung
- stabil
- Bundesstaat
- Status
- stetig
- Shritte
- gelagert
- Der Stress
- Anschließend
- erfolgreich
- Anfälligkeit
- System
- Systeme und Techniken
- Nehmen
- gemacht
- nimmt
- und Aufgaben
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Dort.
- Diese
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- Zeit
- mal
- zu
- Toleranz
- der Verkehr
- Übergang
- WENDE
- XNUMX
- typisch
- für
- zugrunde liegen,
- unvorhergesehen
- Updates
- benutzt
- Mitglied
- verwendet
- Verwendung von
- die
- verschiedene
- freiwillig
- Abstimmungen (Votings):
- we
- Netz
- Web-Services
- Gewicht
- GUT
- gut definiert
- waren
- wann
- welche
- während
- werden wir
- mit
- .
- arbeiten,
- Werk
- schreiben
- Zephyrnet
- Null
- Zonen