15 Python-Snippets zur Optimierung Ihrer Data Science-Pipeline
Schnelle Python-Lösungen zur Unterstützung Ihres Data-Science-Zyklus.
By Lucas Soares, Ingenieur für maschinelles Lernen bei K1 Digital

Photo by Carlos muza on Unsplash
Warum Snippets für die Datenwissenschaft wichtig sind
In meiner täglichen Routine muss ich mich mit vielen der gleichen Situationen auseinandersetzen, vom Laden von CSV-Dateien bis zur Visualisierung von Daten. Um meinen Prozess zu optimieren, habe ich es mir zur Gewohnheit gemacht, Codeausschnitte zu speichern, die in verschiedenen Situationen hilfreich sind, vom Laden von CSV-Dateien bis zur Visualisierung von Daten.
In diesem Beitrag werde ich 15 Codeausschnitte teilen, die Sie bei verschiedenen Aspekten Ihrer Datenanalyse-Pipeline unterstützen
1. Laden mehrerer Dateien mit Glob- und Listenverständnis
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. Eindeutige Werte aus einer Spaltentabelle abrufen
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. Pandas-Datenrahmen nebeneinander anzeigen
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
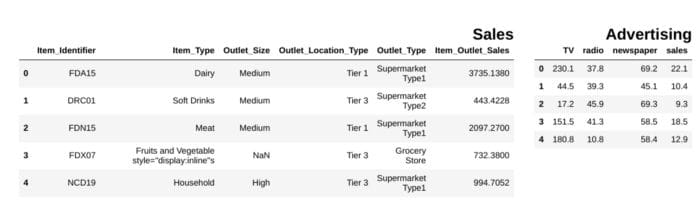
Bild vom Autor
4. Entfernen Sie alle NaNs im Pandas-Datenrahmen
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. Anzahl der NaN-Einträge in DataFrame-Spalten anzeigen
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. Spalten transformieren mit .apply und Lambda-Funktionen
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. Umwandeln von 2 DataFrame-Spalten in ein Wörterbuch
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. Zeichnen eines Verteilungsgitters mit Bedingungen für Spalten
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
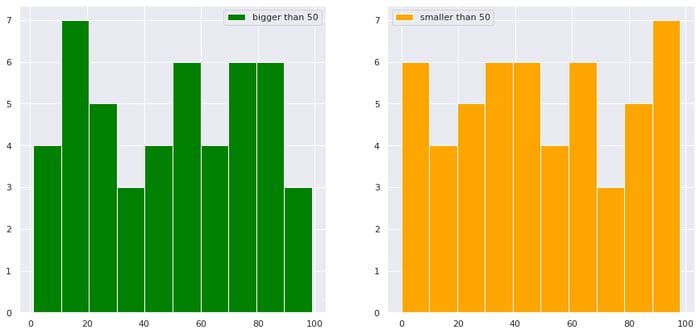
Bild vom Autor
9. Ausführen von T-Tests für Werte verschiedener Spalten in Pandas
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. Datenrahmen in einer bestimmten Spalte zusammenführen
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. Werte in einer Pandas-Spalte mit sklearn normalisieren
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. Löschen von NaNs in einer bestimmten Spalte in Pandas
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. Auswählen einer Teilmenge eines Datenrahmens mit Bedingungen und or Aussage
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. Einfaches Kreisdiagramm
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. Ändern einer Prozentzeichenfolge in einen numerischen Wert mit .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

Zusammenfassung
Ich halte Codeschnipsel für sehr wertvoll. Das Umschreiben von Code kann echte Zeitverschwendung sein. Daher kann es eine große Hilfe sein, über ein komplettes Toolkit mit allen einfachen Lösungen zu verfügen, die Sie zur Optimierung Ihres Datenanalyseprozesses benötigen.
Wenn Ihnen dieser Beitrag gefallen hat, kontaktieren Sie mich unter Twitter, LinkedIn und folge mir weiter Medium. Danke und bis zum nächsten Mal! 🙂
Weitere Inhalte unter plainenglish.io
Bio: Lucas Soares ist ein KI-Ingenieur, der an Deep-Learning-Anwendungen für eine Vielzahl von Problemen arbeitet.
Original. Mit Genehmigung erneut veröffentlicht.
Related:
Quelle: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
- '
- "
- &
- 100
- 7
- Marketings
- AI
- Alle
- Analyse
- Anwendung
- Anwendungen
- Auto
- AWS
- Code
- Kolonne
- gemeinsam
- Inhalt
- technische Daten
- Datenanalyse
- Datenwissenschaft
- Deal
- tiefe Lernen
- Direktor
- Ingenieur
- Eigenschaften
- Vorname
- folgen
- GPUs
- groß
- Grün
- Gitter
- Ultraschall
- Hilfe
- HTTPS
- Interview
- Etiketten
- LERNEN
- lernen
- Liste
- Maschinelles Lernen
- mittlere
- ML
- Neural
- XNUMXh geöffnet
- Open-Source-
- Python
- Angebot
- Gründe
- Regression
- Laufen
- Vertrieb
- Wissenschaft
- Wissenschaftler
- Teilen
- Einfacher
- So
- Lösungen
- quadratisch
- Statistik
- Geschichten
- TD
- Testen
- Zeit
- Top
- Transformieren
- Wert
- X