OpenAI Whisper er en avanceret automatisk talegenkendelse (ASR) model med en MIT-licens. ASR-teknologi finder nytte i transskriptionstjenester, stemmeassistenter og forbedring af tilgængeligheden for personer med hørehandicap. Denne state-of-the-art model er trænet på et stort og mangfoldigt datasæt af flersprogede og multitask-overvågede data indsamlet fra nettet. Dens høje nøjagtighed og tilpasningsevne gør den til et værdifuldt aktiv til en bred vifte af stemmerelaterede opgaver.
I det stadigt udviklende landskab af maskinlæring og kunstig intelligens, Amazon SageMaker giver et omfattende økosystem. SageMaker giver datavidenskabsfolk, udviklere og organisationer mulighed for at udvikle, træne, implementere og administrere maskinlæringsmodeller i stor skala. Den tilbyder en bred vifte af værktøjer og muligheder og forenkler hele maskinlærings-workflowet, fra dataforbehandling og modeludvikling til ubesværet implementering og overvågning. SageMakers brugervenlige grænseflade gør det til en afgørende platform for at frigøre det fulde potentiale af AI, og etablere det som en spilskiftende løsning inden for kunstig intelligens.
I dette indlæg går vi i gang med en udforskning af SageMakers muligheder, specielt med fokus på hosting af Whisper-modeller. Vi dykker dybt ned i to metoder til at gøre dette: den ene ved at bruge Whisper PyTorch-modellen og den anden ved at bruge Hugging Face-implementeringen af Whisper-modellen. Derudover vil vi foretage en dybdegående undersøgelse af SageMakers slutningsmuligheder, og sammenligne dem på tværs af parametre såsom hastighed, omkostninger, nyttelaststørrelse og skalerbarhed. Denne analyse giver brugerne mulighed for at træffe informerede beslutninger, når de integrerer Whisper-modeller i deres specifikke use cases og systemer.
Løsningsoversigt
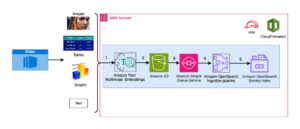
Følgende diagram viser hovedkomponenterne i denne løsning.
- For at være vært for modellen på Amazon SageMaker er det første skridt at gemme modelartefakterne. Disse artefakter refererer til de væsentlige komponenter i en maskinlæringsmodel, der er nødvendige for forskellige applikationer, herunder implementering og genoptræning. De kan omfatte modelparametre, konfigurationsfiler, forbehandlingskomponenter samt metadata, såsom versionsdetaljer, forfatterskab og eventuelle noter relateret til dens ydeevne. Det er vigtigt at bemærke, at Whisper-modeller til PyTorch- og Hugging Face-implementeringer består af forskellige modelartefakter.
- Dernæst opretter vi brugerdefinerede slutningsscripts. Inden for disse scripts definerer vi, hvordan modellen skal indlæses, og specificerer slutningsprocessen. Det er også her, vi kan indarbejde brugerdefinerede parametre efter behov. Derudover kan du liste de nødvendige Python-pakker i en
requirements.txtfil. Under modellens implementering installeres disse Python-pakker automatisk i initialiseringsfasen. - Derefter vælger vi enten PyTorch eller Hugging Face deep learning containere (DLC), der leveres og vedligeholdes af AWS. Disse containere er forudbyggede Docker-billeder med dybe læringsrammer og andre nødvendige Python-pakker. For mere information kan du tjekke dette link.
- Med modelartefakter, brugerdefinerede slutningsscripts og udvalgte DLC'er skaber vi Amazon SageMaker-modeller til henholdsvis PyTorch og Hugging Face.
- Endelig kan modellerne implementeres på SageMaker og bruges med følgende muligheder: realtidsslutningsendepunkter, batchtransformationsjob og asynkrone inferensslutpunkter. Vi vil dykke ned i disse muligheder mere detaljeret senere i dette indlæg.
Eksempelnotebooken og koden til denne løsning er tilgængelig på dette GitHub repository.
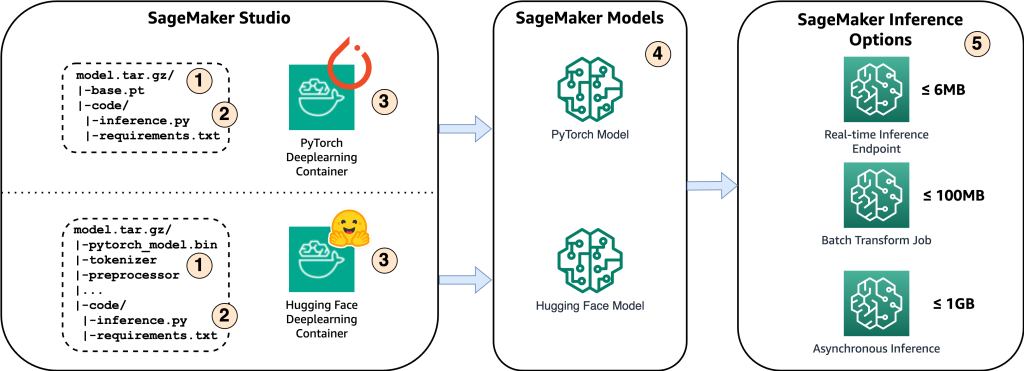
Figur 1. Oversigt over nøgleløsningskomponenter
Går igennem
Vært for Whisper-modellen på Amazon SageMaker
I dette afsnit forklarer vi trinene til at være vært for Whisper-modellen på Amazon SageMaker ved hjælp af henholdsvis PyTorch og Hugging Face Frameworks. For at eksperimentere med denne løsning skal du have en AWS-konto og adgang til Amazon SageMaker-tjenesten.
PyTorch framework
- Gem modelartefakter
Den første mulighed for at være vært for modellen er at bruge Whisper officielle Python-pakke, som kan installeres vha pip install openai-whisper. Denne pakke indeholder en PyTorch-model. Når du gemmer modelartefakter i det lokale lager, er det første trin at gemme modellens parametre, der kan læres, såsom modelvægte og skævheder for hvert lag i det neurale netværk, som en 'pt'-fil. Du kan vælge mellem forskellige modelstørrelser, herunder 'lille', 'base', 'lille', 'medium' og 'large'. Større modelstørrelser giver højere nøjagtighed, men kommer på bekostning af længere slutningsforsinkelse. Derudover skal du gemme modeltilstandsordbogen og dimensionsordbogen, som indeholder en Python-ordbog, der kortlægger hvert lag eller parameter i PyTorch-modellen til dets tilsvarende indlærelige parametre sammen med andre metadata og brugerdefinerede konfigurationer. Koden nedenfor viser, hvordan du gemmer Whisper PyTorch-artefakter.
- Vælg DLC
Det næste trin er at vælge den forudbyggede DLC fra denne link. Vær forsigtig, når du vælger det korrekte billede ved at overveje følgende indstillinger: framework (PyTorch), framework-version, opgave (inferens), Python-version og hardware (dvs. GPU). Det anbefales at bruge de nyeste versioner til frameworket og Python, når det er muligt, da dette resulterer i bedre ydeevne og adresserer kendte problemer og fejl fra tidligere udgivelser.
- Opret Amazon SageMaker-modeller
Dernæst bruger vi SageMaker Python SDK at skabe PyTorch-modeller. Det er vigtigt at huske at tilføje miljøvariabler, når du opretter en PyTorch-model. Som standard kan TorchServe kun behandle filstørrelser op til 6 MB, uanset hvilken inferenstype der bruges.
Følgende tabel viser indstillingerne for forskellige PyTorch-versioner:
| Framework | Miljøvariabler |
| PyTorch 1.8 (baseret på TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (baseret på MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definer modelindlæsningsmetoden i inference.py
I skik og brug inference.py script, tjekker vi først for tilgængeligheden af en CUDA-kompatibel GPU. Hvis en sådan GPU er tilgængelig, så tildeler vi 'cuda' enhed til DEVICE variabel; ellers tildeler vi 'cpu' enhed. Dette trin sikrer, at modellen placeres på den tilgængelige hardware for effektiv beregning. Vi indlæser PyTorch-modellen ved hjælp af Whisper Python-pakken.
Hugging Face ramme
- Gem modelartefakter
Den anden mulighed er at bruge Hugging Face's Whisper implementering. Modellen kan indlæses ved hjælp af AutoModelForSpeechSeq2Seq transformator klasse. De indlærelige parametre gemmes i en binær (bin) fil ved hjælp af save_pretrained metode. Tokenizeren og præprocessoren skal også gemmes separat for at sikre, at Hugging Face-modellen fungerer korrekt. Alternativt kan du implementere en model på Amazon SageMaker direkte fra Hugging Face Hub ved at indstille to miljøvariabler: HF_MODEL_ID , HF_TASK. For mere information henvises til denne webside.
- Vælg DLC
I lighed med PyTorch-rammeværket kan du vælge en forudbygget Hugging Face DLC fra det samme link. Sørg for at vælge en DLC, der understøtter de nyeste Hugging Face-transformere og inkluderer GPU-understøttelse.
- Opret Amazon SageMaker-modeller
På samme måde bruger vi SageMaker Python SDK at skabe Hugging Face-modeller. Hugging Face Whisper-modellen har en standardbegrænsning, hvor den kun kan behandle lydsegmenter i op til 30 sekunder. For at løse denne begrænsning kan du inkludere chunk_length_s parameter i miljøvariablen, når du opretter Hugging Face-modellen, og senere overføre denne parameter til det brugerdefinerede inferensscript, når modellen indlæses. Til sidst skal du indstille miljøvariablerne for at øge nyttelaststørrelsen og responstimeout for Hugging Face-beholderen.
| Framework | Miljøvariabler |
|
HuggingFace Inference Container (baseret på MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definer modelindlæsningsmetoden i inference.py
Når vi opretter et brugerdefineret inferensscript til Hugging Face-modellen, bruger vi en pipeline, der giver os mulighed for at bestå chunk_length_s som en parameter. Denne parameter gør det muligt for modellen effektivt at behandle lange lydfiler under inferens.
Udforskning af forskellige slutningsmuligheder på Amazon SageMaker
Trinnene til valg af slutningsmuligheder er de samme for både PyTorch- og Hugging Face-modeller, så vi vil ikke skelne mellem dem nedenfor. Det er dog værd at bemærke, at på tidspunktet for skrivningen af dette indlæg serverløs slutning option fra SageMaker understøtter ikke GPU'er, og som et resultat udelukker vi denne mulighed for denne use-case.
Vi kan implementere modellen som et slutpunkt i realtid, der giver svar på millisekunder. Det er dog vigtigt at bemærke, at denne mulighed er begrænset til at behandle input under 6 MB. Vi definerer serializeren som en lydserializer, som er ansvarlig for at konvertere inputdataene til et passende format til den installerede model. Vi bruger en GPU-instans til slutninger, hvilket giver mulighed for accelereret behandling af lydfiler. Inferensinputtet er en lydfil, der er fra det lokale lager.
Den anden slutningsmulighed er batch-transformationsjobbet, som er i stand til at behandle input-nyttelaster på op til 100 MB. Denne metode kan dog tage et par minutters latenstid. Hver instans kan kun håndtere én batch-anmodning ad gangen, og instansinitieringen og nedlukningen kræver også et par minutter. Inferensresultaterne gemmes i en Amazon Simple Storage Service (Amazon S3) spand efter afslutning af batchtransformationsjobbet.
Når du konfigurerer batch-transformatoren, skal du sørge for at inkludere max_payload = 100 at håndtere større nyttelast effektivt. Inferensinputtet skal være Amazon S3-stien til en lydfil eller en Amazon S3 Bucket-mappe, der indeholder en liste over lydfiler, hver med en størrelse mindre end 100 MB.
Batch Transform opdeler Amazon S3-objekterne i input med nøgle og tildeler Amazon S3-objekter til instanser. For eksempel, når du har flere lydfiler, kan én instans behandle input1.wav, og en anden instans kan behandle filen med navnet input2.wav for at forbedre skalerbarheden. Batch Transform giver dig mulighed for at konfigurere max_concurrent_transforms for at øge antallet af HTTP-anmodninger til hver enkelt transformercontainer. Det er dog vigtigt at bemærke, at værdien af (max_concurrent_transforms* max_payload) må ikke overstige 100 MB.
Endelig er Amazon SageMaker Asynchronous Inference ideel til at behandle flere anmodninger samtidigt, der tilbyder moderat latenstid og understøtter input-nyttelast på op til 1 GB. Denne mulighed giver fremragende skalerbarhed, hvilket muliggør konfiguration af en autoskaleringsgruppe for slutpunktet. Når der opstår en bølge af anmodninger, skaleres den automatisk op for at håndtere trafikken, og når alle anmodninger er behandlet, skaleres slutpunktet ned til 0 for at spare omkostninger.
Ved hjælp af asynkron inferens gemmes resultaterne automatisk i en Amazon S3-bøtte. I den AsyncInferenceConfig, kan du konfigurere meddelelser for vellykkede eller mislykkede fuldførelser. Inputstien peger på en Amazon S3-placering af lydfilen. For yderligere detaljer henvises til koden på GitHub.
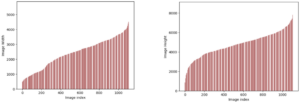
Valgfrit: Som tidligere nævnt har vi mulighed for at konfigurere en autoskaleringsgruppe for det asynkrone inferensendepunkt, hvilket gør det muligt for den at håndtere en pludselig stigning i inferensanmodninger. Et kodeeksempel er givet i denne GitHub repository. I det følgende diagram kan du observere et linjediagram, der viser to metrics fra amazoncloudwatch: ApproximateBacklogSize , ApproximateBacklogSizePerInstance. Til at begynde med, da 1000 anmodninger blev udløst, var kun én instans tilgængelig til at håndtere slutningen. I tre minutter oversteg backlog-størrelsen konsekvent tre (bemærk venligst, at disse tal kan konfigureres), og autoskaleringsgruppen reagerede ved at samle yderligere forekomster op for effektivt at rydde ud af backloggen. Dette resulterede i et markant fald i ApproximateBacklogSizePerInstance, hvilket gør det muligt at behandle backlog-anmodninger meget hurtigere end i den indledende fase.

Figur 2. Linjediagram, der illustrerer de tidsmæssige ændringer i Amazon CloudWatch-metrics
Komparativ analyse for slutningsmulighederne
Sammenligningerne for forskellige inferensmuligheder er baseret på almindelige anvendelsesscenarier for lydbehandling. Realtidsinferens giver den hurtigste inferenshastighed, men begrænser nyttelaststørrelsen til 6 MB. Denne inferenstype er velegnet til lydkommandosystemer, hvor brugere kontrollerer eller interagerer med enheder eller software ved hjælp af stemmekommandoer eller talte instruktioner. Stemmekommandoer er typisk små i størrelse, og lav inferensforsinkelse er afgørende for at sikre, at transskriberede kommandoer straks kan udløse efterfølgende handlinger. Batch Transform er ideel til planlagte offline opgaver, når hver lydfils størrelse er under 100 MB, og der ikke er noget specifikt krav om hurtige reaktionstider. Asynkron inferens giver mulighed for uploads på op til 1 GB og tilbyder moderat inferensforsinkelse. Denne inferenstype er velegnet til transskribering af film, tv-serier og optagede konferencer, hvor større lydfiler skal behandles.
Både realtids- og asynkrone inferensmuligheder giver mulighed for autoskalering, hvilket gør det muligt for slutpunktsforekomsterne automatisk at skalere op eller ned baseret på mængden af anmodninger. I tilfælde uden anmodninger fjerner autoskalering unødvendige forekomster, hvilket hjælper dig med at undgå omkostninger forbundet med klargjorte forekomster, der ikke er aktivt i brug. For realtidsslutning skal der dog bibeholdes mindst én vedvarende instans, hvilket kan føre til højere omkostninger, hvis endepunktet fungerer kontinuerligt. I modsætning hertil tillader asynkron inferens instansvolumen at blive reduceret til 0, når den ikke er i brug. Når du konfigurerer et batchtransformationsjob, er det muligt at bruge flere instanser til at behandle jobbet og justere max_concurrent_transforms for at gøre det muligt for én instans at håndtere flere anmodninger. Derfor tilbyder alle tre inferensmuligheder stor skalerbarhed.
Gøre rent
Når du har afsluttet brugen af løsningen, skal du sørge for at fjerne SageMaker-endepunkterne for at forhindre ekstraomkostninger. Du kan bruge den medfølgende kode til at slette henholdsvis realtids- og asynkrone inferensendepunkter.
Konklusion
I dette indlæg viste vi dig, hvordan implementering af maskinlæringsmodeller til lydbehandling er blevet mere og mere vigtigt i forskellige industrier. Med Whisper-modellen som eksempel demonstrerede vi, hvordan man hoster open source ASR-modeller på Amazon SageMaker ved hjælp af PyTorch- eller Hugging Face-tilgange. Udforskningen omfattede forskellige slutningsmuligheder på Amazon SageMaker, der giver indsigt i effektiv håndtering af lyddata, lave forudsigelser og styring af omkostninger effektivt. Dette indlæg har til formål at give viden til forskere, udviklere og dataforskere, der er interesserede i at udnytte Whisper-modellen til lydrelaterede opgaver og træffe informerede beslutninger om slutningsstrategier.
For mere detaljeret information om implementering af modeller på SageMaker, se venligst dette Udviklervejledning. Derudover kan Whisper-modellen implementeres ved hjælp af SageMaker JumpStart. For yderligere detaljer, tjek venligst Whisper-modeller til automatisk talegenkendelse er nu tilgængelige i Amazon SageMaker JumpStart stolpe.
Du er velkommen til at tjekke notesbogen og koden til dette projekt på GitHub og del din kommentar med os.
Om forfatteren
 Ying Hou, PhD, er Machine Learning Prototyping Architect hos AWS. Hendes primære interesseområder omfatter Deep Learning med fokus på GenAI, Computer Vision, NLP og forudsigelse af tidsseriedata. I sin fritid nyder hun at tilbringe kvalitetsøjeblikke med sin familie, fordybe sig i romaner og vandre i Storbritanniens nationalparker.
Ying Hou, PhD, er Machine Learning Prototyping Architect hos AWS. Hendes primære interesseområder omfatter Deep Learning med fokus på GenAI, Computer Vision, NLP og forudsigelse af tidsseriedata. I sin fritid nyder hun at tilbringe kvalitetsøjeblikke med sin familie, fordybe sig i romaner og vandre i Storbritanniens nationalparker.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- accelereret
- adgang
- tilgængelighed
- Konto
- nøjagtighed
- tværs
- aktioner
- aktivt
- tilføje
- Yderligere
- Derudover
- adresse
- justere
- fremskreden
- AI
- målsætninger
- Alle
- tillade
- tillader
- sammen
- også
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- analyse
- ,
- En anden
- enhver
- applikationer
- tilgange
- ER
- områder
- Array
- kunstig
- kunstig intelligens
- AS
- aktiv
- assistenter
- forbundet
- At
- lyd
- Forfatterskab
- Automatisk Ur
- automatisk
- tilgængelighed
- til rådighed
- undgå
- AWS
- bund
- baseret
- BE
- bliver
- jf. nedenstående
- Bedre
- mellem
- fordomme
- BIN
- både
- bugs
- men
- by
- CAN
- kapaciteter
- stand
- forsigtig
- tilfælde
- Ændringer
- Chart
- kontrollere
- Vælg
- vælge
- klasse
- klar
- kode
- Kom
- KOMMENTAR
- Fælles
- sammenligne
- sammenligninger
- Afsluttet
- færdiggørelse
- komponenter
- omfattende
- beregning
- computer
- Computer Vision
- Adfærd
- konferencer
- Konfiguration
- konfigureret
- konfigurering
- Overvejer
- konsekvent
- indeholder
- Container
- Beholdere
- kontinuerligt
- kontrast
- kontrol
- konvertering af
- korrigere
- Tilsvarende
- Koste
- Omkostninger
- kunne
- CPU
- skabe
- Oprettelse af
- afgørende
- skik
- data
- afgørelser
- falde
- dyb
- dyb læring
- Standard
- definere
- demonstreret
- indsætte
- indsat
- implementering
- implementering
- detail
- detaljeret
- detaljer
- udvikle
- udviklere
- Udvikling
- enhed
- Enheder
- forskellige
- differentiere
- Dimension
- direkte
- visning
- dyk
- forskelligartede
- Docker
- Er ikke
- gør
- ned
- i løbet af
- e
- hver
- tidligere
- økosystem
- effektivt
- effektiv
- effektivt
- nemt
- enten
- andet
- gå i gang
- bemyndiger
- muliggøre
- muliggør
- muliggør
- Encompass
- Endpoint
- endpoints
- forbedre
- styrke
- sikre
- sikrer
- Hele
- Miljø
- væsentlig
- oprettelse
- Ether (ETH)
- undersøgelse
- eksempel
- overstige
- overskredet
- fremragende
- eksperiment
- Forklar
- udforskning
- Udforskning
- Ansigtet
- mislykkedes
- falsk
- familie
- FAST
- hurtigere
- hurtigste
- få
- File (Felt)
- Filer
- fund
- Fornavn
- Fokus
- fokusering
- efter
- Til
- format
- Framework
- rammer
- Gratis
- fra
- fuld
- GPU
- GPU'er
- stor
- gruppe
- håndtere
- Håndtering
- Hardware
- Have
- høre
- hjælpe
- hende
- Høj
- højere
- hiking
- host
- Hosting
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- Hub
- KrammerFace
- i
- ideal
- if
- illustrerer
- billede
- billeder
- implementering
- implementeringer
- importere
- vigtigt
- in
- dybdegående
- omfatter
- omfatter
- Herunder
- indarbejde
- Forøg
- stigende
- individuel
- enkeltpersoner
- industrier
- oplysninger
- informeret
- initial
- i første omgang
- indledning
- indgang
- indgange
- indsigt
- installere
- instans
- forekomster
- anvisninger
- Integration
- Intelligens
- interagere
- interesse
- interesseret
- grænseflade
- ind
- spørgsmål
- IT
- ITS
- Job
- Karriere
- jpg
- Nøgle
- viden
- kendt
- landskab
- større
- endelig
- Latency
- senere
- seneste
- lag
- føre
- læring
- mindst
- løftestang
- Licens
- begrænsning
- Limited
- Line (linje)
- Liste
- belastning
- lastning
- lokale
- placering
- Lang
- længere
- Lav
- maskine
- machine learning
- lavet
- Main
- lave
- maerker
- Making
- administrere
- styring
- Maps
- Kan..
- nævnte
- Metadata
- metode
- metoder
- Metrics
- måske
- millisekunder
- minutter
- MIT
- ML
- model
- modeller
- moderat
- Moments
- overvågning
- mere
- Film
- meget
- flere
- skal
- Som hedder
- national
- nationalparker
- nødvendig
- Behov
- behov
- netværk
- Neural
- neurale netværk
- næste
- NLP
- ingen
- Bemærk
- notesbog
- Noter
- underretning
- meddelelser
- bemærke
- nu
- nummer
- numre
- objekt
- objekter
- observere
- of
- tilbyde
- tilbyde
- Tilbud
- officiel
- offline
- on
- engang
- ONE
- kun
- open source
- opererer
- Option
- Indstillinger
- or
- ordrer
- organisationer
- OS
- Andet
- Ellers
- ud
- oversigt
- pakke
- pakker
- parameter
- parametre
- parker
- passerer
- sti
- udføre
- ydeevne
- fase
- pipeline
- afgørende
- placeret
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- punkter
- mulig
- Indlæg
- potentiale
- forudsigelse
- Forudsigelser
- forhindre
- tidligere
- primære
- behandle
- bearbejdet
- forarbejdning
- Processor
- projekt
- korrekt
- prototyping
- give
- forudsat
- giver
- leverer
- Python
- pytorch
- kvalitet
- rækkevidde
- realtid
- rige
- anerkendelse
- anbefales
- registreres
- Reduceret
- henvise
- Uanset
- relaterede
- Udgivelser
- huske
- Fjern
- fjerner
- Repository
- anmode
- anmodninger
- kræver
- påkrævet
- krav
- forskere
- henholdsvis
- svar
- reaktioner
- ansvarlige
- resultere
- resulteret
- Resultater
- bevaret
- omskoling
- afkast
- sagemaker
- samme
- Gem
- gemt
- besparelse
- Skalerbarhed
- Scale
- skalaer
- planlagt
- forskere
- script
- scripts
- Anden
- sekunder
- Sektion
- segmenter
- Vælg
- valgt
- udvælgelse
- Series
- tjeneste
- Tjenester
- sæt
- indstilling
- indstillinger
- Del
- hun
- bør
- viste
- Shows
- nedlukning
- signifikant
- Simpelt
- forenkler
- Størrelse
- størrelser
- lille
- mindre
- So
- Software
- løsninger
- specifikke
- specifikt
- specificeret
- tale
- Talegenkendelse
- hastighed
- udgifterne
- talt
- starte
- Tilstand
- state-of-the-art
- Trin
- Steps
- opbevaring
- strategier
- efterfølgende
- vellykket
- sådan
- pludselige
- egnede
- support
- Støtte
- Understøtter
- sikker
- bølge
- Systemer
- bord
- Tag
- tager
- Opgaver
- opgaver
- Teknologier
- end
- at
- UK
- deres
- Them
- derefter
- Der.
- derfor
- Disse
- de
- denne
- tre
- tid
- Tidsserier
- gange
- til
- værktøjer
- fakkel
- Trafik
- Tog
- uddannet
- Transform
- transformer
- transformers
- udløse
- udløst
- tv
- TV serier
- to
- typen
- typisk
- Uk
- under
- oplåsning
- på
- us
- brug
- anvendte
- brugervenlig
- brugere
- ved brug af
- nytte
- udnytte
- Ved hjælp af
- Værdifuld
- værdi
- variabel
- forskellige
- Vast
- udgave
- vision
- Voice
- stemmekommandoer
- bind
- vente
- ønsker
- var
- we
- web
- webservices
- GODT
- var
- hvornår
- når
- som
- Hviske
- bred
- Bred rækkevidde
- med
- inden for
- workflow
- virker
- værd
- skrivning
- dig
- Din
- zephyrnet