Billede af redaktør
Nøgleforsøg
- T-testen er en statistisk test, der kan bruges til at bestemme, om der er en signifikant forskel mellem middelværdierne af to uafhængige stikprøver af data.
- Vi illustrerer, hvordan en t-test kan anvendes ved hjælp af iris-datasættet og Pythons Scipy-bibliotek.
T-testen er en statistisk test, der kan bruges til at bestemme, om der er en signifikant forskel mellem middelværdierne af to uafhængige stikprøver af data. I denne vejledning illustrerer vi den mest grundlæggende version af t-testen, hvor vi vil antage, at de to prøver har lige store varianser. Andre avancerede versioner af t-testen omfatter Welch's t-test, som er en tilpasning af t-testen, og som er mere pålidelig, når de to prøver har ulige varianser og muligvis ulige stikprøvestørrelser.
t-statistikken eller t-værdien beregnes som følger:
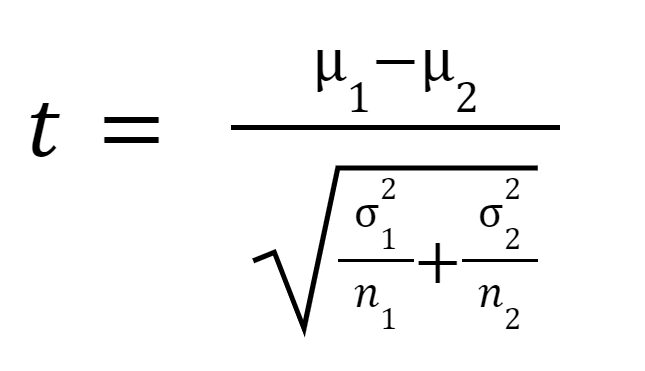
hvor
er middelværdien af prøve 1,
er middelværdien af prøve 2,
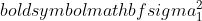 er variansen af prøve 1,
er variansen af prøve 1, 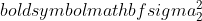 er variansen af prøve 2,
er variansen af prøve 2, 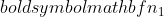 er stikprøvestørrelsen af prøve 1, og
er stikprøvestørrelsen af prøve 1, og 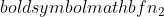 er stikprøvestørrelsen af prøve 2.
er stikprøvestørrelsen af prøve 2.
For at illustrere brugen af t-testen vil vi vise et simpelt eksempel ved hjælp af iris-datasættet. Antag, at vi observerer to uafhængige prøver, f.eks. blomsterbægerbladslængder, og vi overvejer, om de to prøver er trukket fra den samme population (f.eks. den samme blomsterart eller to arter med lignende bægerbladskarakteristika) eller to forskellige populationer.
t-testen kvantificerer forskellen mellem de aritmetiske middelværdier af de to prøver. P-værdien kvantificerer sandsynligheden for at opnå de observerede resultater, forudsat at nulhypotesen (at prøverne er trukket fra populationer med samme populationsmiddelværdi) er sand. En p-værdi større end en valgt tærskel (f.eks. 5 % eller 0.05) indikerer, at vores observation ikke er så usandsynligt, at den er sket tilfældigt. Derfor accepterer vi nulhypotesen om lige befolkningsmidler. Hvis p-værdien er mindre end vores tærskel, så har vi beviser imod nulhypotesen om lige befolkningsmidler.
T-test input
De input eller parametre, der er nødvendige for at udføre en t-test, er:
- To arrays a , b indeholdende data for prøve 1 og prøve 2
T-test udgange
T-testen returnerer følgende:
- Den beregnede t-statistik
- p-værdien
Importer nødvendige biblioteker
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Indlæs Iris-datasæt
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Beregn stikprøvegennemsnittet og prøvevarianserne
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementer t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Produktion
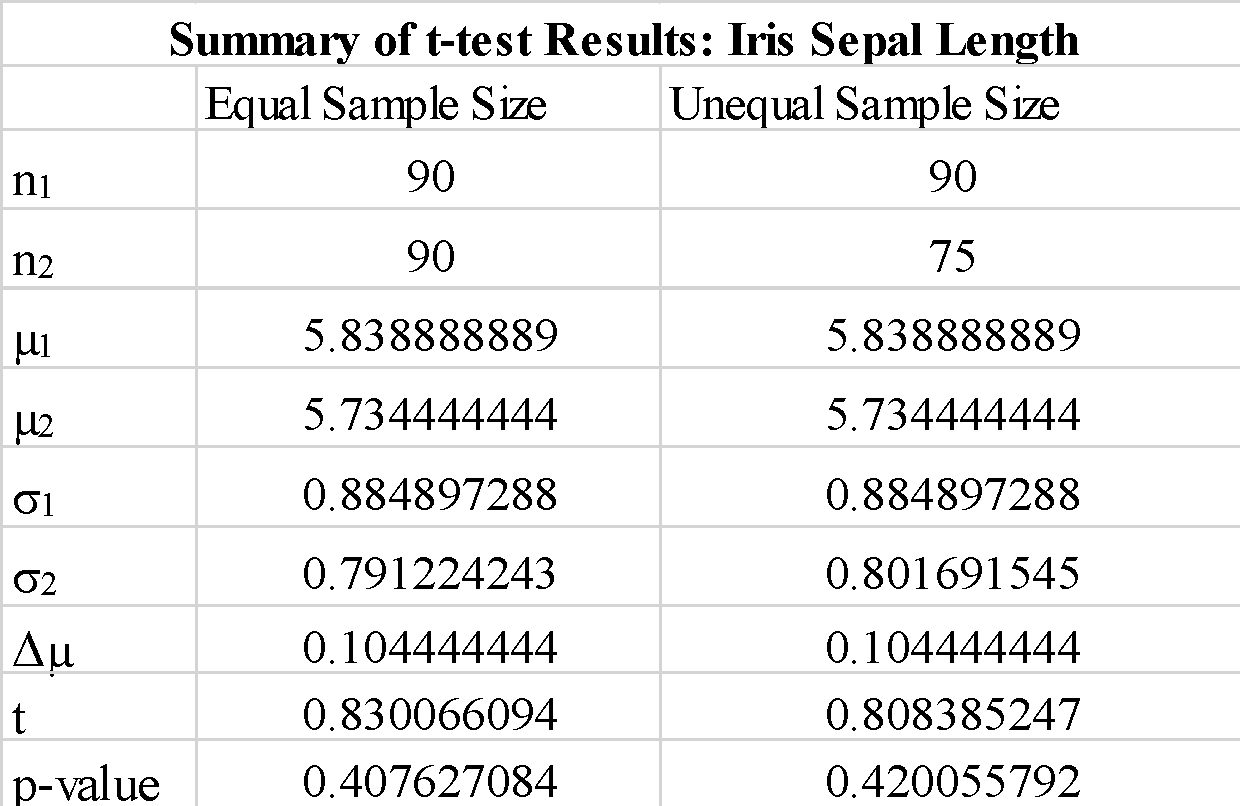
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Produktion
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Produktion
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Kommentarer
Vi observerer, at brugen af "sand" eller "falsk" for parameteren "equal-var" ikke ændrer t-testresultaterne så meget. Vi observerer også, at udskiftning af rækkefølgen af prøveopstillingerne a_1 og b_1 giver en negativ t-testværdi, men ændrer ikke størrelsen af t-testværdien som forventet. Da den beregnede p-værdi er langt større end tærskelværdien på 0.05, kan vi afvise nulhypotesen om, at forskellen mellem gennemsnittet af prøve 1 og prøve 2 er signifikant. Dette viser, at bægerbladlængderne for prøve 1 og prøve 2 blev trukket fra samme populationsdata.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Beregn stikprøvegennemsnittet og prøvevarianserne
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementer t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Produktion
stats.ttest_ind(a_1, b_1, equal_var = False)Kommentarer
Vi observerer, at brug af prøver med ulige størrelse ikke ændrer t-statistikken og p-værdien signifikant.
Sammenfattende har vi vist, hvordan en simpel t-test kunne implementeres ved hjælp af scipy-biblioteket i python.
Benjamin O. Tayo er fysiker, underviser i datavidenskab og forfatter, samt ejer af DataScienceHub. Tidligere underviste Benjamin i Engineering and Physics ved U. of Central Oklahoma, Grand Canyon U. og Pittsburgh State U.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Acceptere
- fremskreden
- mod
- ,
- anvendt
- grundlæggende
- Benjamin
- mellem
- beregnet
- central
- chance
- lave om
- karakteristika
- valgt
- Overvejer
- kunne
- data
- datalogi
- datasæt
- Bestem
- forskel
- forskellige
- trukket
- Engineering
- bevismateriale
- eksempel
- forventet
- blomst
- efter
- følger
- fra
- Hvordan
- HTTPS
- implementeret
- importere
- in
- omfatter
- uafhængig
- angiver
- KDnuggets
- større
- Bibliotek
- matplotlib
- midler
- mere
- mest
- nødvendig
- negativ
- bedøvet
- observere
- opnå
- forekom
- Oklahoma
- ordrer
- Andet
- ejer
- parameter
- parametre
- udfører
- Fysik
- Pittsburgh
- plato
- Platon Data Intelligence
- PlatoData
- befolkning
- populationer
- tidligere
- sandsynlighed
- Python
- pålidelig
- Resultater
- afkast
- samme
- Videnskab
- Vis
- vist
- Shows
- signifikant
- betydeligt
- lignende
- Simpelt
- siden
- Størrelse
- størrelser
- mindre
- So
- Tilstand
- statistiske
- statistik
- RESUMÉ
- Undervisning
- prøve
- derfor
- tærskel
- til
- sand
- tutorial
- brug
- værdi
- udgave
- hvorvidt
- som
- vilje
- forfatter
- udbytter
- zephyrnet