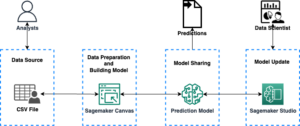
I første del af denne tredelte serie præsenterede vi en løsning, der demonstrerer, hvordan du kan automatisere registrering af dokumentmanipulation og bedrageri i stor skala ved hjælp af AWS AI og maskinlæringstjenester (ML) til en brugssituation for pantebreve.
I dette indlæg præsenterer vi en tilgang til at udvikle en deep learning-baseret computervisionsmodel til at opdage og fremhæve forfalskede billeder i realkreditgarantier. Vi giver vejledning om opbygning, træning og implementering af deep learning netværk på Amazon SageMaker.
I del 3 demonstrerer vi, hvordan man implementerer løsningen på Amazon svindeldetektor.
Løsningsoversigt
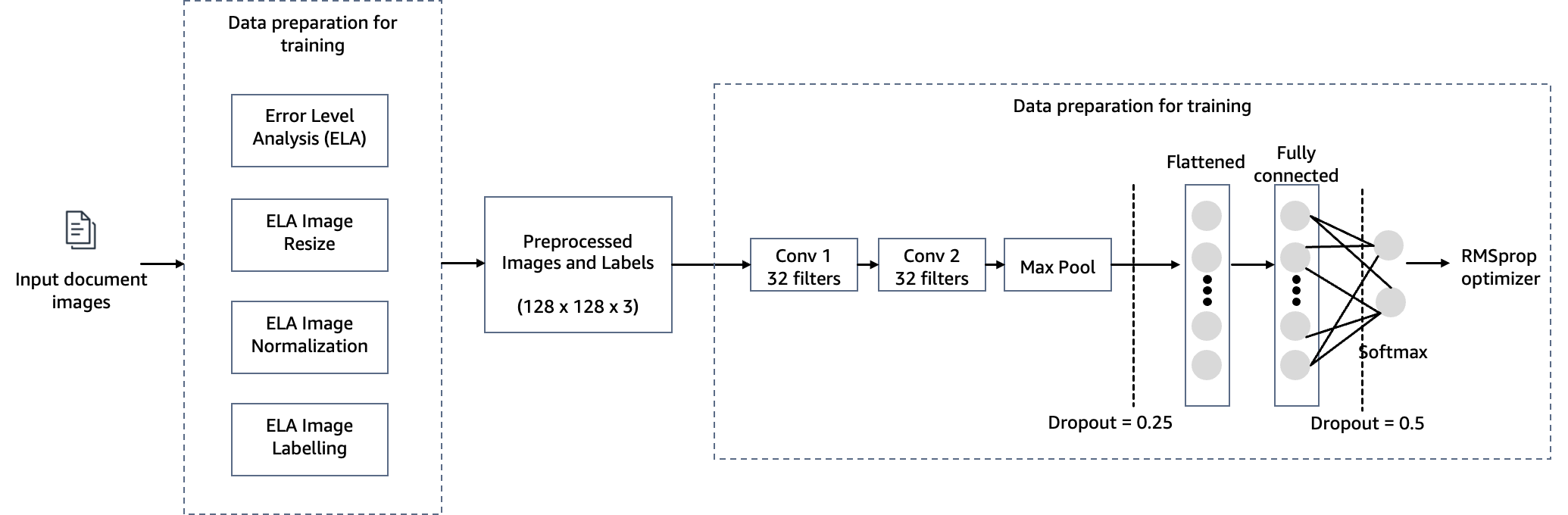
For at imødekomme målet om at opdage dokumentmanipulation i realkreditgarantier, anvender vi en computervisionsmodel hostet på SageMaker til vores løsning til registrering af billedfalsk. Denne model modtager et testbillede som input og genererer en sandsynlighedsforudsigelse af forfalskning som output. Netværksarkitekturen er som vist i det følgende diagram.
Billedforfalskning involverer hovedsageligt fire teknikker: splejsning, kopiering-flytning, fjernelse og forbedring. Afhængigt af forfalskningens karakteristika kan forskellige spor bruges som grundlag for påvisning og lokalisering. Disse ledetråde inkluderer JPEG-komprimeringsartefakter, kantinkonsistens, støjmønstre, farvekonsistens, visuel lighed, EXIF-konsistens og kameramodel.
I betragtning af det ekspansive område af billedforfalskningsdetektering bruger vi algoritmen Error Level Analysis (ELA) som en illustrativ metode til at opdage forfalskninger. Vi valgte ELA-teknikken til dette indlæg af følgende grunde:
- Det er hurtigere at implementere og kan nemt fange manipulation af billeder.
- Det fungerer ved at analysere komprimeringsniveauerne for forskellige dele af et billede. Dette gør det muligt at opdage uoverensstemmelser, der kan indikere manipulation - for eksempel hvis et område blev kopieret og indsat fra et andet billede, der var blevet gemt på et andet komprimeringsniveau.
- Den er god til at opdage mere subtil eller problemfri manipulation, som kan være svær at få øje på med det blotte øje. Selv små ændringer i et billede kan introducere påviselige komprimeringsanomalier.
- Den er ikke afhængig af at have det originale umodificerede billede til sammenligning. ELA kan kun identificere manipulationstegn i selve det udspurgte billede. Andre teknikker kræver ofte den umodificerede original at sammenligne med.
- Det er en letvægtsteknik, der kun er afhængig af at analysere kompressionsartefakter i de digitale billeddata. Det afhænger ikke af specialiseret hardware eller retsmedicinsk ekspertise. Dette gør ELA tilgængeligt som et førstegangsanalyseværktøj.
- Udgangs-ELA-billedet kan tydeligt fremhæve forskelle i kompressionsniveauer, hvilket gør manipulerede områder synligt. Dette gør det muligt for selv en ikke-ekspert at genkende tegn på mulig manipulation.
- Det virker på mange billedtyper (såsom JPEG, PNG og GIF) og kræver kun selve billedet at analysere. Andre retsmedicinske teknikker kan være mere begrænsede i formater eller krav til originale billeder.
I scenarier i den virkelige verden, hvor du muligvis har en kombination af inputdokumenter (JPEG, PNG, GIF, TIFF, PDF), anbefaler vi dog at bruge ELA sammen med forskellige andre metoder, som f.eks. opdage uoverensstemmelser i kanter, støjmønstre, farve ensartethed, EXIF-datakonsistens, identifikation af kameramodelog ensartet skrifttype. Vi sigter efter at opdatere koden til dette indlæg med yderligere forfalskningsdetektionsteknikker.
ELAs underliggende forudsætning antager, at inputbillederne er i JPEG-format, kendt for sin tabsgivende komprimering. Ikke desto mindre kan metoden stadig være effektiv, selvom inputbillederne oprindeligt var i et tabsfrit format (såsom PNG, GIF eller BMP) og senere konverteret til JPEG under manipulationsprocessen. Når ELA anvendes på originale tabsfrie formater, indikerer det typisk ensartet billedkvalitet uden nogen forringelse, hvilket gør det vanskeligt at lokalisere ændrede områder. I JPEG-billeder er den forventede norm, at hele billedet udviser lignende komprimeringsniveauer. Men hvis et bestemt afsnit i billedet viser et markant anderledes fejlniveau, tyder det ofte på, at der er foretaget en digital ændring.
ELA fremhæver forskelle i JPEG-komprimeringshastigheden. Regioner med ensartet farve vil sandsynligvis have et lavere ELA-resultat (for eksempel en mørkere farve sammenlignet med højkontrastkanter). De ting, du skal kigge efter for at identificere manipulation eller ændring, omfatter følgende:
- Lignende kanter bør have lignende lysstyrke i ELA-resultatet. Alle kanter med høj kontrast skal ligne hinanden, og alle kanter med lav kontrast skal ligne hinanden. Med et originalt foto bør kanter med lav kontrast være næsten lige så lyse som kanter med høj kontrast.
- Lignende teksturer bør have lignende farve under ELA. Områder med flere overfladedetaljer, såsom et nærbillede af en basketball, vil sandsynligvis have et højere ELA-resultat end en glat overflade.
- Uanset overfladens faktiske farve, bør alle flade overflader have omtrent samme farve under ELA.
JPEG-billeder bruger et komprimeringssystem med tab. Hver genkodning (genlagring) af billedet tilføjer mere kvalitetstab til billedet. Specifikt fungerer JPEG-algoritmen på et 8×8 pixel-gitter. Hver 8×8 firkant komprimeres uafhængigt. Hvis billedet er fuldstændig umodificeret, så burde alle 8×8 firkanter have lignende fejlpotentialer. Hvis billedet er uændret og gemt igen, skal hver firkant nedbrydes med omtrent samme hastighed.
ELA gemmer billedet i et specificeret JPEG-kvalitetsniveau. Denne genlagring introducerer en kendt mængde fejl på tværs af hele billedet. Det gengemte billede sammenlignes derefter med det originale billede. Hvis et billede er modificeret, skal hver 8×8 firkant, der blev berørt af ændringen, have et højere fejlpotentiale end resten af billedet.
Resultaterne fra ELA er direkte afhængige af billedkvaliteten. Du vil måske gerne vide, om noget blev tilføjet, men hvis billedet kopieres flere gange, tillader ELA muligvis kun at detektere genoplagringerne. Prøv at finde den bedste kvalitetsversion af billedet.
Med træning og øvelse kan ELA også lære at identificere billedskalering, kvalitet, beskæring og genlagring af transformationer. For eksempel, hvis et ikke-JPEG-billede indeholder synlige gitterlinjer (1 pixel bred i 8×8 kvadrater), betyder det, at billedet startede som en JPEG og blev konverteret til ikke-JPEG-format (såsom PNG). Hvis nogle områder af billedet mangler gitterlinjer, eller gitterlinjerne skifter, angiver det en splejsning eller tegnet del i ikke-JPEG-billedet.
I de følgende afsnit demonstrerer vi trinene til konfiguration, træning og implementering af computervisionsmodellen.
Forudsætninger
For at følge med i dette indlæg skal du udfylde følgende forudsætninger:
- Har en AWS-konto.
- Opsætning Amazon SageMaker Studio. Du kan hurtigt starte SageMaker Studio ved at bruge standardforudindstillinger, hvilket letter en hurtig lancering. For mere information, se Amazon SageMaker forenkler Amazon SageMaker Studio-opsætningen for individuelle brugere.
- Åbn SageMaker Studio og start en systemterminal.
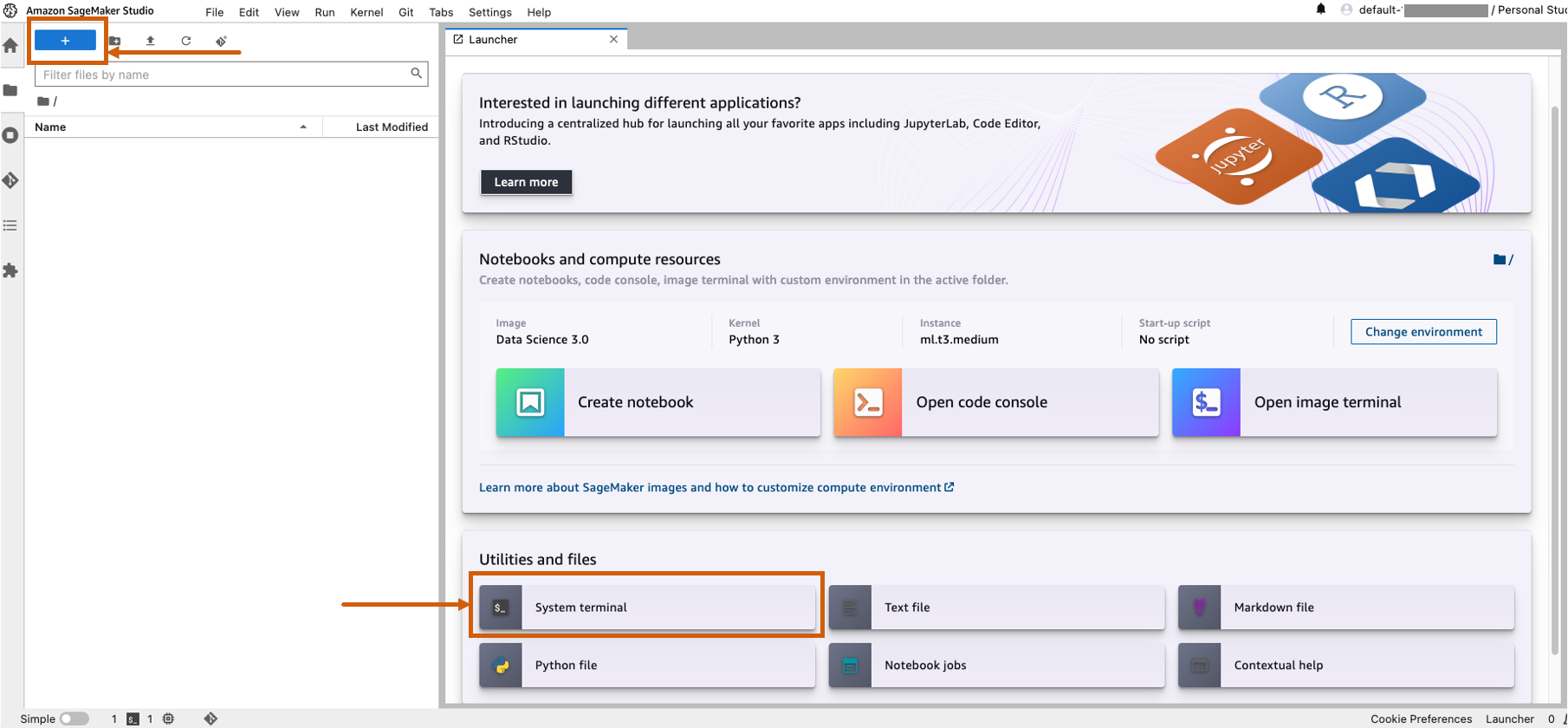
- Kør følgende kommando i terminalen:
git clone https://github.com/aws-samples/document-tampering-detection.git - De samlede omkostninger ved at køre SageMaker Studio for én bruger og konfigurationerne af notebookmiljøet er $7.314 USD pr. time.
Opsæt modeltræningsnotesbogen
Udfør følgende trin for at konfigurere din træningsnotesbog:
- Åbne
tampering_detection_training.ipynbfil fra mappen dokument-manipulation-detektion. - Konfigurer notebookmiljøet med billedet TensorFlow 2.6 Python 3.8 CPU eller GPU Optimized.
Du kan støde på spørgsmålet om utilstrækkelig tilgængelighed eller ramme kvotegrænsen for GPU-forekomster på din AWS-konto, når du vælger GPU-optimerede forekomster. For at øge kvoten skal du besøge Service Quotas-konsollen og øge servicegrænsen for den specifikke forekomsttype, du har brug for. Du kan også bruge et CPU-optimeret notebook-miljø i sådanne tilfælde. - Til kernel, vælg Python3.
- Til Forekomsttype, vælg ml.m5d.24xlarge eller enhver anden stor instans.
Vi valgte en større instanstype for at reducere træningstiden for modellen. Med et ml.m5d.24xlarge notebook-miljø er prisen pr. time $7.258 USD pr. time.
Kør træningsnotesbogen
Kør hver celle i notesbogen tampering_detection_training.ipynb i orden. Vi diskuterer nogle celler mere detaljeret i de følgende afsnit.
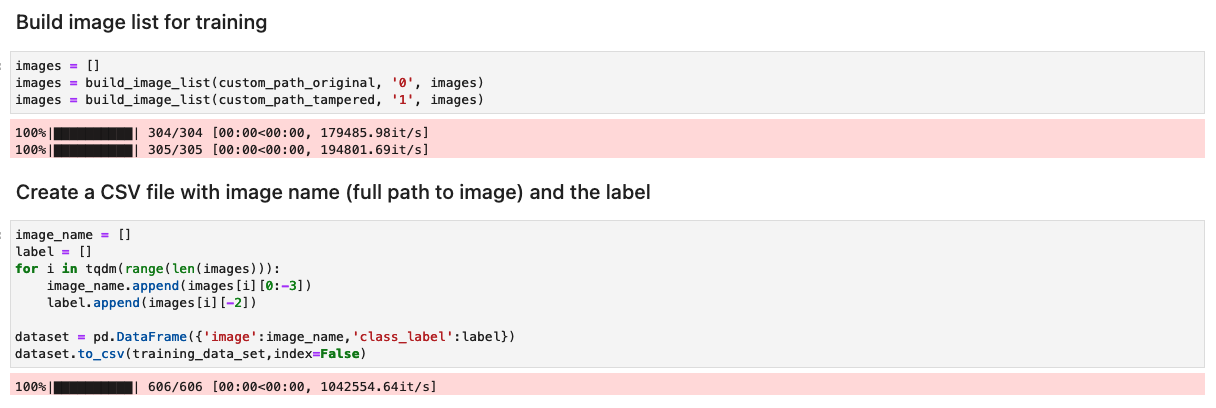
Forbered datasættet med en liste over originale og manipulerede billeder
Før du kører følgende celle i notesbogen, skal du forberede et datasæt med originale og manipulerede dokumenter baseret på dine specifikke forretningskrav. Til dette indlæg bruger vi et eksempeldatasæt af manipulerede lønsedler og kontoudtog. Datasættet er tilgængeligt i billedbiblioteket i GitHub repository.

Notesbogen læser de originale og manipulerede billeder fra images/training mappe.
Datasættet til træning oprettes ved hjælp af en CSV-fil med to kolonner: stien til billedfilen og etiketten for billedet (0 for originalbillede og 1 for manipuleret billede).
Bearbejd datasættet ved at generere ELA-resultaterne for hvert træningsbillede
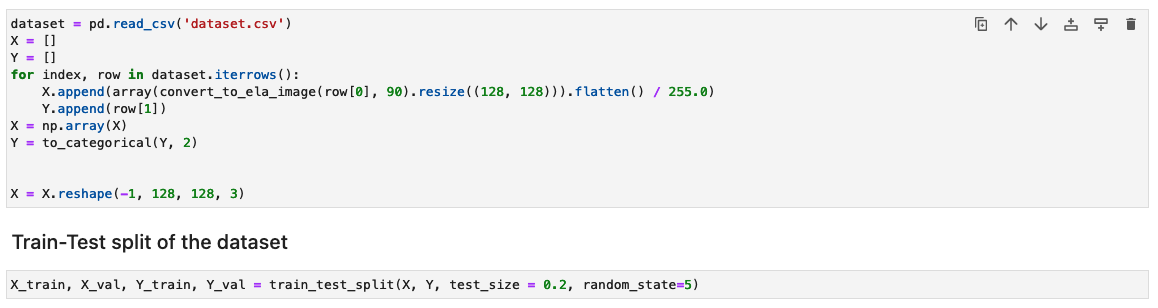
I dette trin genererer vi ELA-resultatet (ved 90 % kvalitet) af inputtræningsbilledet. Funktionen convert_to_ela_image tager to parametre: sti, som er stien til en billedfil, og kvalitet, der repræsenterer kvalitetsparameteren for JPEG-komprimering. Funktionen udfører følgende trin:
- Konverter billedet til RGB-format og gem billedet igen som en JPEG-fil med den angivne kvalitet under navnet tempresaved.jpg.
- Beregn forskellen mellem det originale billede og det gengemte JPEG-billede (ELA) for at bestemme den maksimale forskel i pixelværdier mellem de originale og gengemte billeder.
- Beregn en skaleringsfaktor baseret på den maksimale forskel for at justere lysstyrken af ELA-billedet.
- Forøg lysstyrken af ELA-billedet ved hjælp af den beregnede skaleringsfaktor.
- Tilpas størrelsen på ELA-resultatet til 128x128x3, hvor 3 repræsenterer antallet af kanaler for at reducere inputstørrelsen til træning.
- Returner ELA-billedet.
I billedformater med tab, såsom JPEG, fører den indledende lagringsproces til betydeligt farvetab. Men når billedet indlæses og efterfølgende genkodes i det samme tabsgivende format, er der generelt mindre tilføjet farveforringelse. ELA-resultater understreger de billedområder, der er mest modtagelige for farveforringelse ved genlagring. Generelt forekommer ændringer fremtrædende i områder, der udviser højere potentiale for nedbrydning sammenlignet med resten af billedet.
Derefter behandles billederne til et NumPy-array til træning. Vi opdeler derefter inputdatasættet tilfældigt i trænings- og test- eller valideringsdata (80/20). Du kan ignorere alle advarsler, når du kører disse celler.
Afhængigt af datasættets størrelse kan det tage tid at udføre disse celler at køre disse celler. For prøvedatasættet, vi leverede i dette lager, kan det tage 5-10 minutter.
Konfigurer CNN-modellen
I dette trin konstruerer vi en minimal version af VGG-netværket med små foldningsfiltre. VGG-16 består af 13 foldede lag og tre fuldt forbundne lag. Følgende skærmbillede illustrerer arkitekturen af vores Convolutional Neural Network (CNN) model.
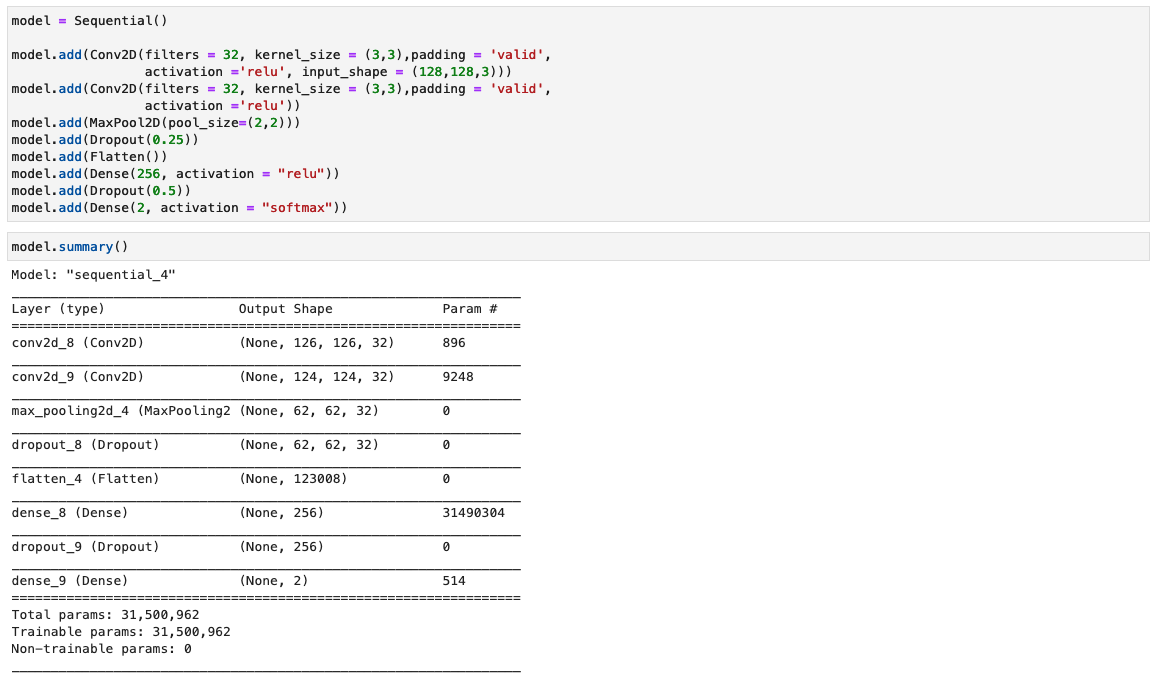
Bemærk følgende konfigurationer:
- Input – Modellen tager en billedinputstørrelse på 128x128x3.
- Konvolutionerende lag – De foldede lag bruger et minimalt modtageligt felt (3×3), den mindst mulige størrelse, der stadig fanger op/ned og venstre/højre. Dette efterfølges af en rectified linear unit (ReLU) aktiveringsfunktion, der reducerer træningstiden. Dette er en lineær funktion, der udsender input, hvis det er positivt; ellers er udgangen nul. Faldningsskridtet er fastsat til standard (1 pixel) for at bevare den rumlige opløsning efter foldning (skridt er antallet af pixelskift over inputmatrixen).
- Fuldt forbundne lag – Netværket har to fuldt forbundne lag. Det første tætte lag bruger ReLU-aktivering, og det andet bruger softmax til at klassificere billedet som originalt eller manipuleret.
Du kan ignorere alle advarsler, når du kører disse celler.
Gem modellens artefakter
Gem den trænede model med et unikt filnavn – for eksempel baseret på den aktuelle dato og klokkeslæt – i en mappe med navnet model.

Modellen gemmes i Keras-format med udvidelsen .keras. Vi gemmer også modelartefakterne som en mappe ved navn 1, der indeholder serialiserede signaturer og den tilstand, der er nødvendig for at køre dem, inklusive variable værdier og ordforråd til at implementere til en SageMaker-runtime (som vi diskuterer senere i dette indlæg).
Mål modellens ydeevne
Følgende tabskurve viser progressionen af modellens tab over træningsepoker (iterationer).
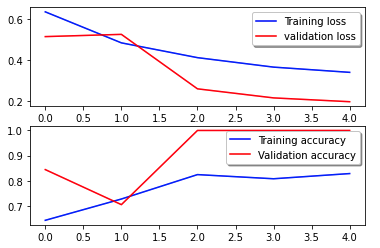
Tabsfunktionen måler, hvor godt modellens forudsigelser matcher de faktiske mål. Lavere værdier indikerer bedre tilpasning mellem forudsigelser og sande værdier. Faldende tab over epoker betyder, at modellen er i bedring. Nøjagtighedskurven illustrerer modellens nøjagtighed over træningsepoker. Nøjagtighed er forholdet mellem korrekte forudsigelser og det samlede antal forudsigelser. Højere nøjagtighed indikerer en bedre ydende model. Typisk øges nøjagtigheden under træning, efterhånden som modellen lærer mønstre og forbedrer dens forudsigelsesevne. Disse vil hjælpe dig med at afgøre, om modellen er overfitting (præsterer godt på træningsdata, men dårligt på usete data) eller underfitting (lærer ikke nok af træningsdataene).
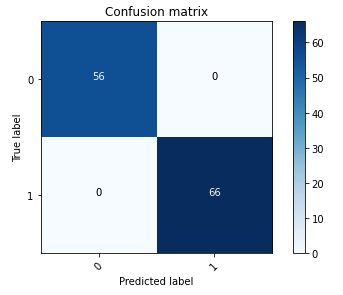
Følgende forvirringsmatrix repræsenterer visuelt, hvor godt modellen nøjagtigt skelner mellem de positive (smedet billede, repræsenteret som værdi 1) og negative (uforfalskede billede, repræsenteret som værdi 0) klasser.
Efter modeluddannelsen involverer vores næste trin at implementere computervisionsmodellen som en API. Denne API vil blive integreret i forretningsapplikationer som en komponent i underwriting-workflowet. For at opnå dette bruger vi Amazon SageMaker Inference, en fuldt administreret tjeneste. Denne service integreres problemfrit med MLOps-værktøjer, hvilket muliggør skalerbar modelimplementering, omkostningseffektiv inferens, forbedret modelstyring i produktionen og reduceret operationel kompleksitet. I dette indlæg implementerer vi modellen som et slutpunkt i realtid. Det er dog vigtigt at bemærke, at afhængigt af arbejdsgangen for dine forretningsapplikationer, kan modelimplementeringen også skræddersyes som batchbehandling, asynkron håndtering eller gennem en serverløs implementeringsarkitektur.
Konfigurer modelimplementeringsnotesbogen
Udfør følgende trin for at konfigurere din modelimplementeringsnotesbog:
- Åbne
tampering_detection_model_deploy.ipynbfil fra mappen dokument-manipulation-detektion. - Konfigurer notebookmiljøet med billedet Data Science 3.0.
- Til kernel, vælg Python3.
- Til Forekomsttype, vælg ml.t3.medium.
Med et ml.t3.medium notebook-miljø er prisen pr. time $0.056 USD.
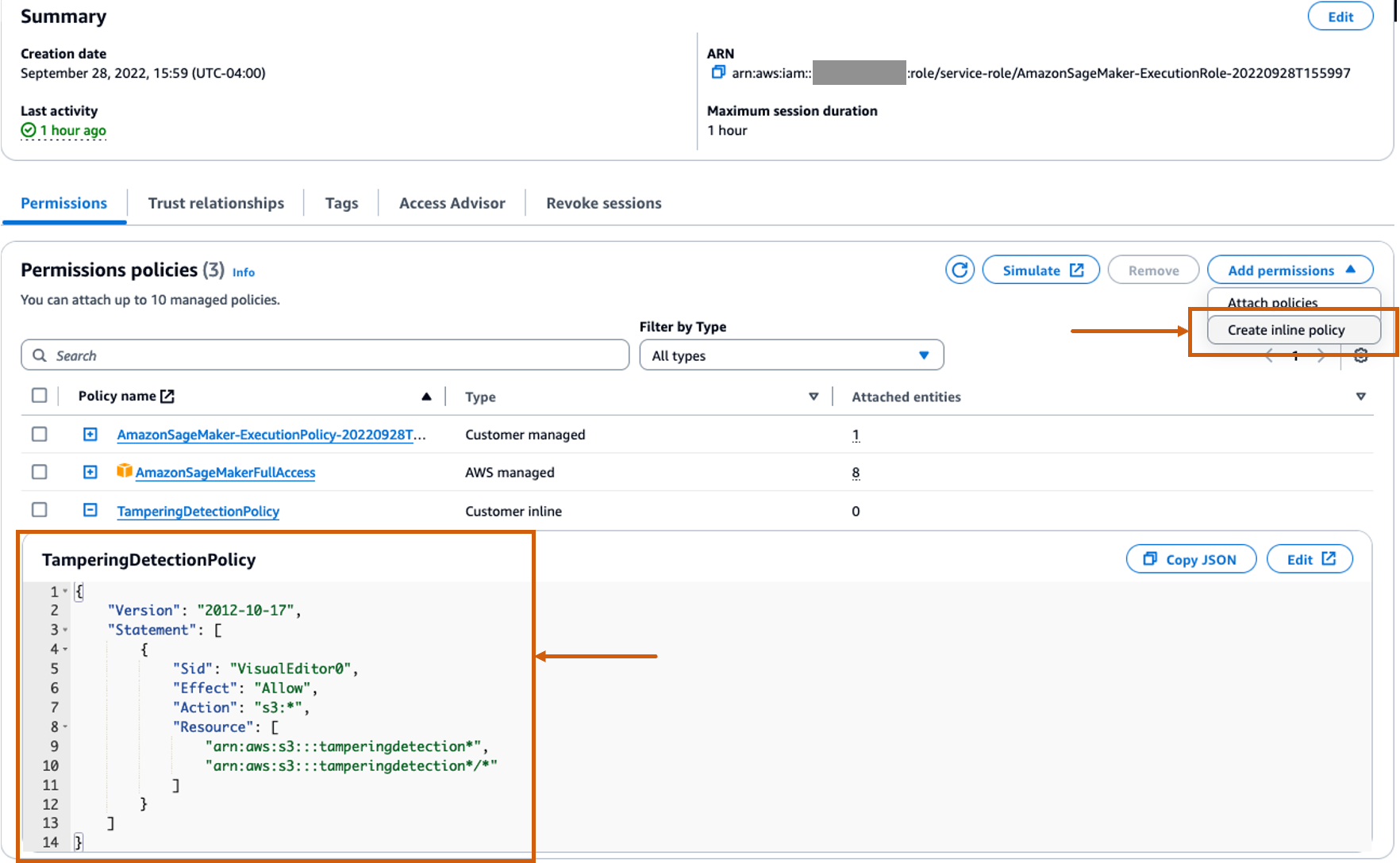
Opret en tilpasset inline-politik for SageMaker-rollen for at tillade alle Amazon S3-handlinger
AWS identitets- og adgangsstyring (IAM) rolle for SageMaker vil være i formatet AmazonSageMaker- ExecutionRole-<random numbers>. Sørg for, at du bruger den rigtige rolle. Rollenavnet kan findes under brugeroplysningerne i SageMaker-domænekonfigurationerne.

Opdater IAM-rollen til at inkludere en inline-politik, der tillader alle Amazon Simple Storage Service (Amazon S3) handlinger. Dette vil være nødvendigt for at automatisere oprettelsen og sletningen af S3-bøtter, der gemmer modelartefakter. Du kan begrænse adgangen til specifikke S3-bøtter. Bemærk, at vi brugte et jokertegn for S3-bøttenavnet i IAM-politikken (tamperingdetection*).
Kør implementeringsnotesbogen
Kør hver celle i notesbogen tampering_detection_model_deploy.ipynb i orden. Vi diskuterer nogle celler mere detaljeret i de følgende afsnit.
Opret en S3-spand
Kør cellen for at oprette en S3-spand. Spanden vil blive navngivet tamperingdetection<current date time> og i samme AWS-region som dit SageMaker Studio-miljø.

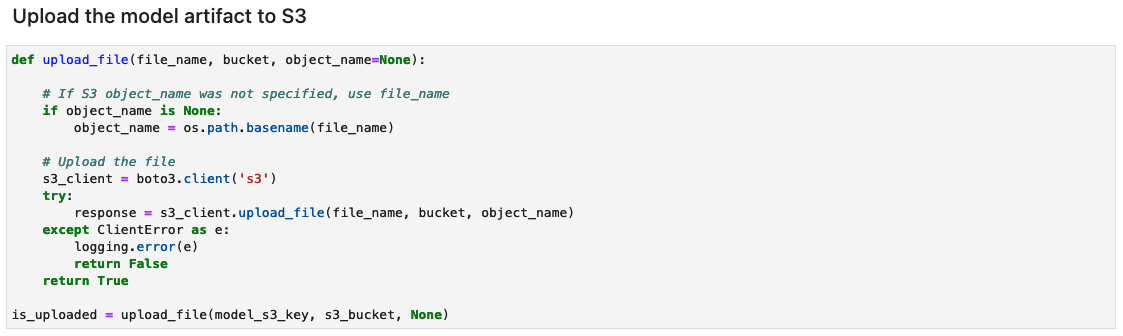
Opret modelartefaktarkivet og upload til Amazon S3
Opret en tar.gz-fil fra modelartefakter. Vi har gemt modelartefakterne som en mappe ved navn 1, der indeholder serialiserede signaturer og den tilstand, der er nødvendig for at køre dem, inklusive variable værdier og ordforråd til at implementere til SageMaker-runtime. Du kan også inkludere en brugerdefineret inferensfil kaldet inference.py i kodemappen i modelartefakten. Den brugerdefinerede slutning kan bruges til forbehandling og efterbehandling af inputbilledet.
![]()
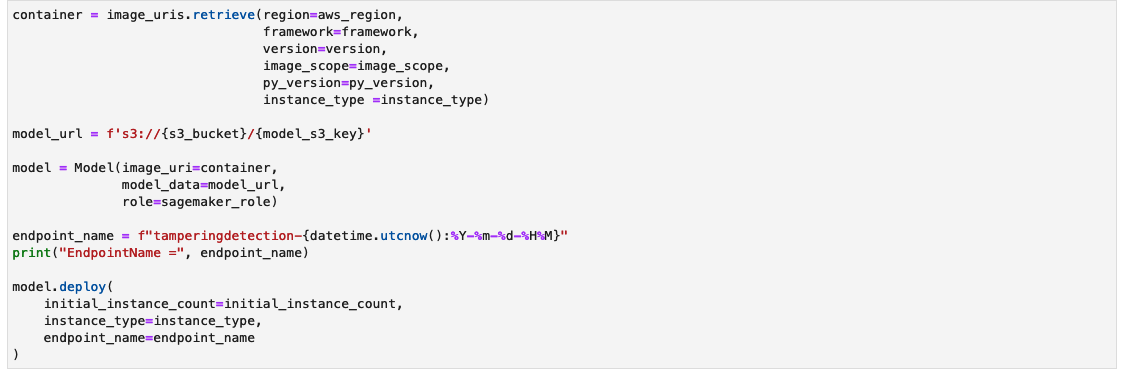
Opret et SageMaker-slutningsendepunkt
Cellen til at oprette et SageMaker-slutningsendepunkt kan tage et par minutter at fuldføre.
Test inferensendepunktet
funktionen check_image forbehandler et billede som et ELA-billede, sender det til et SageMaker-slutpunkt til slutning, henter og behandler modellens forudsigelser og udskriver resultaterne. Modellen tager et NumPy-array af inputbilledet som et ELA-billede for at give forudsigelser. Forudsigelserne udlæses som 0, der repræsenterer et billede uden manipulation, og 1, der repræsenterer et forfalsket billede.

Lad os påberåbe os modellen med et umanipuleret billede af en betalingsseddel og tjekke resultatet.

Modellen udsender klassifikationen som 0, hvilket repræsenterer et billede uden manipulation.
Lad os nu påberåbe os modellen med et manipuleret billede af en betalingsseddel og tjekke resultatet.

Modellen udskriver klassificeringen som 1, hvilket repræsenterer et forfalsket billede.
Begrænsninger
Selvom ELA er et glimrende værktøj til at hjælpe med at opdage ændringer, er der en række begrænsninger, såsom følgende:
- En enkelt pixelændring eller mindre farvejustering genererer muligvis ikke en mærkbar ændring i ELA, fordi JPEG fungerer på et gitter.
- ELA identificerer kun, hvilke regioner der har forskellige kompressionsniveauer. Hvis et billede af lavere kvalitet splejses til et billede af højere kvalitet, kan billedet af lavere kvalitet fremstå som et mørkere område.
- Skalering, omfarvning eller tilføjelse af støj til et billede vil ændre hele billedet og skabe et højere fejlniveaupotentiale.
- Hvis et billede gengemmes flere gange, kan det være helt på et minimumsfejlniveau, hvor flere genlagringer ikke ændrer billedet. I dette tilfælde vil ELA returnere et sort billede, og ingen ændringer kan identificeres ved hjælp af denne algoritme.
- Med Photoshop kan den simple handling at gemme billedet automatisk skærpe teksturer og kanter, hvilket skaber et højere fejlniveau. Denne artefakt identificerer ikke bevidst ændring; det identificerer, at et Adobe-produkt blev brugt. Teknisk set fremstår ELA som en ændring, fordi Adobe automatisk udførte en ændring, men ændringen var ikke nødvendigvis bevidst af brugeren.
Vi anbefaler at bruge ELA sammen med andre teknikker, der tidligere er diskuteret i bloggen, for at opdage en større række af billedmanipulationssager. ELA kan også tjene som et uafhængigt værktøj til visuelt at undersøge billedforskelle, især når træning af en CNN-baseret model bliver udfordrende.
Ryd op
For at fjerne de ressourcer, du har oprettet som en del af denne løsning, skal du udføre følgende trin:
- Kør notebook-cellerne under Ryd op afsnit. Dette vil slette følgende:
- SageMaker slutningspunkt – Inferensslutpunktets navn vil være
tamperingdetection-<datetime>. - Genstande i S3-spanden og selve S3-spanden – Spandens navn bliver
tamperingdetection<datetime>.
- SageMaker slutningspunkt – Inferensslutpunktets navn vil være
- Luk ned SageMaker Studios notebookressourcer.
Konklusion
I dette indlæg præsenterede vi en end-to-end-løsning til at opdage dokumentmanipulation og svindel ved hjælp af deep learning og SageMaker. Vi brugte ELA til at forbehandle billeder og identificere uoverensstemmelser i kompressionsniveauer, der kan indikere manipulation. Derefter trænede vi en CNN-model på dette behandlede datasæt til at klassificere billeder som originale eller manipulerede.
Modellen kan opnå stærk ydeevne med en nøjagtighed på over 95 % med et datasæt (smedet og originalt), der passer til dine forretningskrav. Dette indikerer, at den pålideligt kan opdage forfalskede dokumenter som lønsedler og kontoudtog. Den trænede model er implementeret til et SageMaker-endepunkt for at muliggøre inferens med lav latens i skala. Ved at integrere denne løsning i realkreditarbejdsgange kan institutioner automatisk markere mistænkelige dokumenter til yderligere undersøgelse af svindel.
Selvom det er kraftfuldt, har ELA nogle begrænsninger med hensyn til at identificere visse typer af mere subtil manipulation. Som næste trin kan modellen forbedres ved at inkorporere yderligere retsmedicinske teknikker i træning og ved at bruge større, mere forskelligartede datasæt. Samlet set viser denne løsning, hvordan du kan bruge deep learning og AWS-tjenester til at bygge effektive løsninger, der øger effektiviteten, reducerer risikoen og forhindrer svindel.
I del 3 demonstrerer vi, hvordan man implementerer løsningen på Amazon Fraud Detector.
Om forfatterne
 Anup Ravindranath er en Senior Solutions Architect hos Amazon Web Services (AWS) med base i Toronto, Canada, og arbejder med Financial Services-organisationer. Han hjælper kunder med at transformere deres forretninger og innovere på cloud.
Anup Ravindranath er en Senior Solutions Architect hos Amazon Web Services (AWS) med base i Toronto, Canada, og arbejder med Financial Services-organisationer. Han hjælper kunder med at transformere deres forretninger og innovere på cloud.
 Vinnie Saini er Senior Solutions Architect hos Amazon Web Services (AWS) baseret i Toronto, Canada. Hun har hjulpet Financial Services-kunder med at transformere sig i skyen med AI- og ML-drevne løsninger, der er lagt på stærke grundpiller i Architectural Excellence.
Vinnie Saini er Senior Solutions Architect hos Amazon Web Services (AWS) baseret i Toronto, Canada. Hun har hjulpet Financial Services-kunder med at transformere sig i skyen med AI- og ML-drevne løsninger, der er lagt på stærke grundpiller i Architectural Excellence.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- :har
- :er
- :ikke
- :hvor
- $OP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95 %
- a
- evne
- Om
- adgang
- tilgængelig
- Konto
- nøjagtighed
- præcist
- opnå
- tværs
- Lov
- aktioner
- Aktivering
- faktiske
- tilføjet
- tilføje
- Yderligere
- Tilføjer
- justere
- Justering
- Adobe
- Efter
- mod
- AI
- sigte
- algoritme
- tilpasning
- Alle
- tillade
- tillader
- næsten
- sammen
- langs med
- også
- ændret
- Amazon
- Amazon svindeldetektor
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- Amazon Web Services (AWS)
- beløb
- an
- analyse
- analysere
- analysere
- ,
- En anden
- enhver
- api
- vises
- kommer til syne
- applikationer
- anvendt
- tilgang
- cirka
- arkitektonisk
- arkitektur
- Arkiv
- ER
- OMRÅDE
- områder
- Array
- AS
- antager
- At
- automatisere
- automatisk
- tilgængelighed
- til rådighed
- AWS
- Bank
- baseret
- Basketball
- BE
- fordi
- bliver
- været
- BEDSTE
- Bedre
- mellem
- Sort
- Blog
- boost
- Bright
- bygge
- Bygning
- virksomhed
- Business Applications
- virksomheder
- men
- by
- beregnet
- kaldet
- værelse
- CAN
- Canada
- fanger
- tilfælde
- tilfælde
- brydning
- celle
- Celler
- vis
- udfordrende
- lave om
- Ændringer
- kanaler
- karakteristika
- kontrollere
- Vælg
- klasser
- klassificering
- Klassificere
- tydeligt
- Cloud
- CNN
- kode
- farve
- Kolonner
- kombination
- sammenligne
- sammenlignet
- sammenligning
- fuldføre
- fuldstændig
- kompleksitet
- komponent
- computer
- Computer Vision
- konfigurering
- forvirring
- sammenholdt
- tilsluttet
- betydelig
- konsekvent
- består
- Konsol
- konstruere
- indeholder
- konvertere
- konverteret
- indviklet neuralt netværk
- korrigere
- Koste
- kunne
- CPU
- skabe
- oprettet
- Oprettelse af
- skabelse
- Nuværende
- skøger
- skik
- Kunder
- mørkere
- data
- datalogi
- datasæt
- Dato
- faldende
- dyb
- dyb læring
- Standard
- demonstrere
- demonstrerer
- betegner
- tætte
- afhænge
- afhængig
- Afhængigt
- indsætte
- indsat
- implementering
- implementering
- detail
- detaljer
- opdage
- Detektion
- Bestem
- udvikle
- diagram
- forskel
- forskelle
- forskellige
- digital
- direkte
- diskutere
- drøftet
- displays
- skelner
- forskelligartede
- do
- dokumentet
- dokumenter
- Er ikke
- domæne
- trukket
- drevet
- i løbet af
- hver
- nemt
- Edge
- Effektiv
- effektivitet
- understrege
- anvendelse
- muliggøre
- muliggør
- ende til ende
- Endpoint
- forbedret
- ekstraudstyr
- nok
- Hele
- helt
- Miljø
- epoker
- fejl
- fejl
- især
- Ether (ETH)
- Endog
- Hver
- Undersøgelse
- eksempel
- Excellence
- fremragende
- udstille
- Udviser
- ekspansiv
- forventet
- ekspertise
- udvidelse
- øje
- faciliterende
- faktor
- få
- felt
- File (Felt)
- Filtre
- finansielle
- finansielle tjenesteydelser
- Finde
- Fornavn
- fast
- flad
- følger
- efterfulgt
- efter
- Til
- Forensic
- retsvidenskab
- smedet
- format
- fundet
- Foundation
- foundational
- fire
- bedrageri
- fra
- fuldt ud
- funktion
- yderligere
- generelt
- generere
- genererer
- generere
- gif
- Git
- godt
- GPU
- større
- Grid
- vejledning
- havde
- Håndtering
- Hård Ost
- Hardware
- Have
- have
- he
- hjælpe
- hjælpe
- hjælper
- højere
- Fremhæv
- højdepunkter
- Hit
- host
- hostede
- time
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- IAM
- identificeret
- identificerer
- identificere
- identificere
- Identity
- IEEE
- if
- ignorere
- illustrerer
- billede
- billeder
- effektfuld
- gennemføre
- vigtigt
- forbedrer
- forbedring
- in
- omfatter
- Herunder
- uoverensstemmelser
- inkorporering
- Forøg
- Stigninger
- uafhængig
- uafhængigt
- angiver
- angiver
- individuel
- oplysninger
- initial
- indlede
- innovere
- indgang
- instans
- forekomster
- institutioner
- integreret
- Integrerer
- Integration
- Forsætlig
- ind
- indføre
- Introducerer
- undersøgelse
- involverer
- spørgsmål
- IT
- iterationer
- ITS
- selv
- jpg
- Holde
- Keras
- Kend
- kendt
- etiket
- Mangel
- stor
- større
- senere
- lancere
- lag
- lag
- Leads
- LÆR
- læring
- mindre
- Niveau
- niveauer
- letvægt
- ligesom
- sandsynlighed
- Sandsynlig
- GRÆNSE
- begrænsninger
- lineær
- linjer
- Liste
- Lokalisering
- Se
- off
- lavere
- maskine
- machine learning
- lavet
- hovedsageligt
- lave
- maerker
- Making
- lykkedes
- ledelse
- Håndtering
- mange
- Match
- Matrix
- maksimal
- Kan..
- midler
- foranstaltninger
- medium
- Mød
- metode
- metoder
- mindste
- minimum
- mindre
- minutter
- ML
- MLOps
- model
- Modifikationer
- modificeret
- ændre
- mere
- Pant
- mest
- flere
- navn
- Som hedder
- nødvendigvis
- Behov
- behov
- negativ
- netværk
- net
- Neural
- neurale netværk
- Ikke desto mindre
- næste
- ingen
- Støj
- Bemærk
- notesbog
- nummer
- bedøvet
- objektiv
- Obvious
- of
- tit
- on
- ONE
- kun
- opererer
- operationelle
- optimeret
- or
- ordrer
- organisationer
- original
- oprindeligt
- Andet
- Ellers
- vores
- udfald
- output
- udgange
- i løbet af
- samlet
- parameter
- parametre
- del
- særlig
- dele
- sti
- mønstre
- per
- ydeevne
- udføres
- udfører
- udfører
- foto
- photoshop
- billede
- søjler
- pixel
- plato
- Platon Data Intelligence
- PlatoData
- grund
- politik
- del
- positiv
- mulig
- Indlæg
- potentiale
- potentialer
- vigtigste
- praksis
- forudsigelse
- Forudsigelser
- forudsigende
- Forbered
- forudsætninger
- præsentere
- forelagt
- bevaret
- forhindre
- tidligere
- udskrifter
- behandle
- bearbejdet
- Processer
- forarbejdning
- Produkt
- produktion
- progression
- give
- forudsat
- Python
- kvalitet
- Adspurgt
- hurtigere
- tilfældig
- rækkevidde
- hurtige
- Sats
- forholdet
- virkelige verden
- realtid
- rige
- årsager
- modtager
- genkende
- anbefaler
- ensrettet
- reducere
- Reduceret
- reducerer
- henvise
- region
- regioner
- genoptagelse
- stole
- fjernelse
- Fjern
- rendering
- Repository
- repræsenteret
- repræsenterer
- repræsenterer
- kræver
- påkrævet
- Krav
- Kræver
- Løsning
- Ressourcer
- REST
- begrænset
- resultere
- Resultater
- afkast
- RGB
- Risiko
- roller
- Kør
- kører
- sagemaker
- SageMaker Inference
- samme
- Eksempeldatasæt
- Gem
- gemt
- besparelse
- skalerbar
- Scale
- skalering
- scenarier
- Videnskab
- sømløs
- problemfrit
- Anden
- Sektion
- sektioner
- valgt
- udvælgelse
- sender
- senior
- Series
- tjener
- Serverless
- tjeneste
- Tjenester
- sæt
- setup
- hun
- skifte
- Skift
- bør
- Shows
- Underskrifter
- betegner
- Skilte
- lignende
- Simpelt
- forenkler
- enkelt
- Størrelse
- lille
- udjævne
- løsninger
- Løsninger
- nogle
- noget
- rumlige
- specialiserede
- specifikke
- specifikt
- specificeret
- delt
- Spot
- firkant
- firkanter
- påbegyndt
- Tilstand
- udsagn
- Trin
- Steps
- Stadig
- opbevaring
- butik
- skridtlængde
- stærk
- Studio
- Efterfølgende
- sådan
- foreslår
- sikker
- overflade
- modtagelig
- mistænksom
- hurtigt
- systemet
- skræddersyet
- Tag
- tager
- mål
- teknisk set
- teknik
- teknikker
- tensorflow
- terminal
- prøve
- Test
- end
- at
- Staten
- deres
- Them
- derefter
- Der.
- Disse
- ting
- denne
- tre
- Gennem
- tid
- gange
- til
- værktøj
- værktøjer
- toronto
- I alt
- rørt
- Tog
- uddannet
- Kurser
- Transform
- transformationer
- sand
- prøv
- to
- typen
- typer
- typisk
- under
- underliggende
- tegningsgaranti
- enestående
- enhed
- Opdatering
- på
- USD
- brug
- brug tilfælde
- anvendte
- Bruger
- bruger
- ved brug af
- validering
- værdi
- Værdier
- variabel
- forskellige
- udgave
- synlig
- vision
- Besøg
- visuel
- visuelt
- ønsker
- var
- we
- web
- webservices
- GODT
- var
- Hvad
- hvornår
- som
- bred
- vilje
- med
- inden for
- uden
- workflow
- arbejdsgange
- arbejder
- virker
- dig
- Din
- zephyrnet
- nul