Introduktion
Transformers og de store sprogmodeller har taget verden med storm, efter at de er blevet introduceret inden for Natural Language Processing (NLP). Siden deres begyndelse har feltet udviklet sig hurtigt med innovationer og forskning, der gør disse LLM'er mere effektive. Disse inkluderer LoRA (Low-Rank Adaption), Flash Attention, Quantization og den nylige Merging-tilgang af de bemærkelsesværdige LLM'er. I denne guide vil vi se på en ny tilgang til sammenlægning LLM'er (Solar 10.7B) introduceret af Upstage AI.

Læringsmål
- Forstå den unikke arkitektur i Solar 10.7B og dens innovative "dybde-opskalering"
- Udforsk modellens fortræningsproces og de forskellige data, den bruger
- Analyser de imponerende ydeevnebenchmarks for Solar 10.7B på tværs af forskellige NLP-opgaver
- Sammenlign og kontrast Solar 10.7B med andre bemærkelsesværdige LLM'er, såsom Mixtral MoE
- Lær, hvordan du får adgang til og arbejder med Solar 10.7B til dine projekter
Denne artikel blev offentliggjort som en del af Data Science Blogathon.
Indholdsfortegnelse
Hvad er SOLAR 10.7B?
Upstange AI introducerede den nye 10.7 Billion Parameter-model, SOLAR 10.7B. Denne model er et resultat af sammenlægning af to 7 Billion Parameter Models, specifikt to Llama 2 7 Billion modeller, som blev fortrænet til at skabe SOLAR 10.7B. Det unikke aspekt ved denne fusion er anvendelsen af en ny tilgang kaldet Depth Up-Scaling (DUS), i modsætning til Mixtral-metoden, hvor en blanding af eksperter er ansat.
Den nye 10.7B-model klarede sig bedre end Mistral 7B, Qwen 14B. En Instruct-version kaldet SOLAR 10.7B Instruct er blevet frigivet, og efter udgivelsen toppede den ranglisten og overgik både Qwen 72B og Mixtral 8x7B Large Language Model. På trods af at det var en 10.7 milliarder parametermodel, var SOLAR i stand til at overgå de LLM'er, der er flere gange dens størrelse
Hvad er Depth Up Scaling?
Lad os forstå, hvordan det hele begyndte, og dannelsen af SOLAR 10.7B. Det hele starter med en enkelt basismodel. The Upstage har valgt Llama 2, der indeholder 32 Transformer Layers til sin basismodel på grund af dens bredere Open Source-bidragydere. Derefter blev der oprettet en kopi af denne basismodel

Så får vi to basismodeller. Hvad angår vægtene, har Upstage taget de fortrænede vægte fra Mistral 7B, fordi den præsterede bedst på det tidspunkt. Nu starter vi den dybdegående skalering. Hver af basismodellerne indeholder 32 lag. Fra disse 32 lag fjerner vi m lag, det vil sige de sidste m lag fra den originale model og de første m lag fra kopiversionen af den. Dette tilføjer op til 24 lag i hver af dem. Så slår vi disse to modeller sammen:
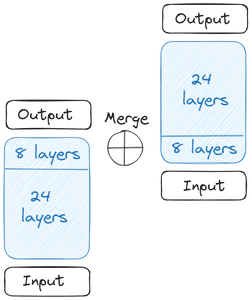
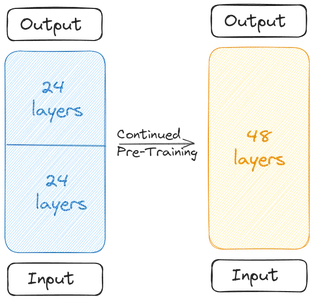
De to basismodeller er sammenkædet for at danne den skalerede model. Den skalerede model indeholder nu 48 lag. Den skalerede model klarer sig dårligt på grund af sammenlægningen. Derfor gennemgår den skalerede model fortræning. Denne dybdeskalering efterfulgt af den fortsatte fortræning sammen gør Depth Up-Scaling (DUS).
Træning af SOLAR 10.7B
Den skalerede model skal fortrænes på grund af faldet i ydeevne på grund af sammenlægning. Skaberne sagde, at præstationen er steget hurtigt med fortræning. Fortræningen/finjusteringen involverede to trin
Første fase var Instruktionsfinjustering. I denne type Fine-Tuning gennemgik modellen træning i datasæt for at tilpasse sig instruktionerne. Finjusteringsprocessen involverede arbejde med populære Open Source-datasæt såsom Alpaca-GPT4 og OpenOrca. Papiret bemærkede, at kun en delmængde af datasættet blev brugt til at finjustere den fusionerede model. Sammen med Open Source-dataene trænede Upstage det endda med nogle lukkede matematiske data.
I anden fase udføres Alignment Tuning. I Alignment Tuning tager vi scenen en finjusteret model og finjusterer den yderligere til at være mere tilpasset mennesker eller kraftfulde AI'er som GPT4. Dette blev gjort gennem DPOTrainer(Direct Preference Optimization) en RLHF(Reinforcement Learning with Human Feedback)-lignende teknik.
I Direct Preference Optimization har vi et datasæt, der indeholder tre kolonner, en prompt, en kolonne med foretrukket svar og en kolonne med afvist svar. Dette bruges derefter til at træne den skalerede model for at få den til at generere de svar, som vi har brug for den til at generere. De samme datasæt, som blev trænet til instruktions-finjustering, bruges her.
Evaluering og benchmark resultater
The Hugging Face OpenLLM Leaderboard bruger flere benchmarks til at evaluere mulighederne for Large Language Models (LLM'er). Hvert benchmark vurderer forskellige aspekter af en LLM's præstation:
- ARC (AI2 Reasoning Challenge): Dette benchmark tester en LLM's evne til at besvare videnskabelige spørgsmål på elementært niveau, hvilket giver indsigt i modellens forståelse og begrundelse for videnskabelige begreber.
- MMLU (Massive MultiTask Language Understanding): MMLU er et mangfoldigt benchmark, der dækker 57 forskellige opgaver, herunder spørgsmål relateret til grundlæggende matematik, historie, jura, datalogi og andre. Den evaluerer LLM's evne til at behandle og forstå information på tværs af flere discipliner.
- HellaSwag: Med det formål at teste en LLM's sunde ræsonnement, udfordrer HellaSwag modeller til at anvende hverdagslogik på en række scenarier og vurderer deres evne til at foretage intuitive vurderinger, der ligner menneskelige tankeprocesser.
- Winogrande: Dette benchmark, der ligner HellaSwag, fokuserer på sund fornuft, men med forskellige nuancer sammenlignet med HellaSwag. Det kræver, at LLM'er demonstrerer et sofistikeret niveau af forståelse og logisk ræsonnement.
- TruthfulQA: TruthfulQA evaluerer nøjagtigheden og pålideligheden af oplysninger leveret af LLM'er. Den inkluderer spørgsmål fra forskellige områder, herunder videnskab, jura, politik og mere, og tester modellens evne til at generere sandfærdige og faktuelle svar.
- GSM8K: Specielt designet til at teste matematiske evner, inkluderer GSM8K matematiske problemer i flere trin, der kræver logisk ræsonnement og beregningstænkning, hvilket udfordrer LLM'er til at evaluere deres problemløsningsevner i matematik.
Grundmodellen SOLAR 10.7B klarede sig bedre end modeller som Mistral 7B Instruct v0.2-modellen og Qwen 14B-modellen. Instruct-versionen af SOLAR 10.7B var i stand til endda at slå de meget store sprogmodeller som Mistral 8x7B, Qwen 72B, Falcon 180B og de andre enorme store sprogmodeller. Det var foran alle modellerne i ARC og TruthfulQA benchmark
Kom godt i gang med SOLAR 10.7B
SOLAR 10.7B-modellen er let tilgængelig i HuggingFace Hub for at arbejde med transformatorbiblioteket. Selv de kvantificerede modeller af SOLAR 10.7B er tilgængelige at arbejde med. I dette afsnit vil vi downloade den kvantificerede version og prøve at indtaste modellen med forskellige opgaver og se output genereret
For at teste med den kvantificerede version af SOLAR 10.7B vil vi arbejde med llama_cpp_python-biblioteket i Python, der lader os køre kvantiserede store sprogmodeller. Til denne demo vil vi arbejde med den gratis version af Google Colab.
Download pakken
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub- CMAKE_ARGS=”-DLLAMA_CUBLAS=til” , FORCE_CMAKE=1, vil tillade lama_cpp_python til at arbejde med Nvidia GPU, der er tilgængelig i den gratis colab-version
- Så installerer vi lama_cpp_python pakke gennem pip3
- Vi downloader endda huggingface-hub, hvormed vi vil downloade den kvantificerede SOLAR 10.7B-model
For at arbejde med SOLAR 10.7B-modellen skal vi først downloade den kvantificerede version af den. For at downloade det, kører vi følgende kode:
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
Arbejder med Hugging Face Hub
Her arbejder vi med hugging_face_hub for at downloade den kvantiserede model. Til dette importerer vi hf_hub_download der tager følgende parametre ind
- model_name: Dette er den type model, vi ønsker at downloade. Her ønsker vi at downloade SOLAR 10.7B Instruct GGUF modellen
- model_fil: Her fortæller vi hvilken kvantiseret version vi vil downloade. Her vil vi downloade den 2bit kvantificerede version af SOLAR 10.7B Instruct
- Vi videregiver derefter disse parametre til hf_hub_download, som tager disse parametre ind og downloader den angivne model. Efter download returnerer den stien, hvor modellen er downloadet
- Denne returnerede sti bliver gemt i model_path variabel
Nu kan vi indlæse denne model gennem lamaen_cpp_python bibliotek. Koden til at indlæse modellen vil være som den nedenfor
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
Importer Lama-klassen
Vi importerer Llama-klassen fra lama_cpp, som tager følgende parametre ind
- model_path: Denne variabel tager den sti, hvor vores model er gemt. Vi har fået vejen fra det forrige trin, som vi vil give her
- n_ctx: Her giver vi kontekstlængden for modellen. Indtil videre leverer vi 512 tokens til kontekstlængden
- n_tråde: Her nævner vi antallet af tråde, der skal bruges af Llama-klassen. For nu giver vi det 8, fordi vi har 4 core CPU, hvor hver kerne kan køre 2 tråde samtidigt
- n_gpu_lag: Vi giver dette, hvis vi har en kørende GPU, hvilket vi gør, fordi vi arbejder med den gratis colab. Til dette sender vi 110, som fortæller, at vi vil aflaste hele modellen i GPU'en og ikke vil have en del af den til at køre i systemets RAM
- Til sidst opretter vi et objekt fra denne Llama-klasse og giver det til variablen llm
Kørsel af denne kode vil den SOLAR 10.7B kvantiserede model indlæses på GPU'en og indstille den passende kontekstlængde. Nu er det tid til at lave nogle konklusioner om denne model. Til dette arbejder vi med nedenstående kode
output = llm(
"### User:nWho are you?nn### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
Udled modellen
For at udlede modellen videregiver vi følgende parametre til LLM'erne:
- Spørgsmål/chat-skabelon: Dette er skabelonen, der er nødvendig for at chatte med modellen. Ovennævnte skabelon(### User:n{user_prompt}?nn### Assistant:) er den, der virker til SOLAR 10.7B-modellen. I skabelonen er sætningen efter Bruger er brugerprompten, og generationen vil blive genereret efter Assistant
- max_tokens: Dette er det maksimale antal tokens, som den store sprogmodel kan udsende, når der gives en prompt. Indtil videre begrænser vi det til 512 tokens
- hold op: Dette er stop-tokenet. Stoptokenet fortæller den store sprogmodel, at den skal stoppe med at generere yderligere tokens. For SOLAR 10.7B er stoptokenet
Hvis du kører dette, lagres resultaterne i output variabel. Det genererede resultat ligner OpenAI API-kaldet. Derfor kan vi få adgang til generationen gennem den givne print-erklæring, som svarer til, hvordan vi får adgang til generationen fra OpenAI-svarene. Det genererede output kan ses nedenfor

Den genererede sætning virker god nok uden forekomsten af store grammatiske fejl. Lad os prøve den sunde fornuft del af modellen ved at give følgende prompter
output = llm(
"### User:nHow many eggs can a monkey lay in its lifetime?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:nHow many smartphones can a human eat?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Her ser vi to eksempler relateret til sund fornuft, og overraskende nok klarer SOLAR 10.7B det meget godt. Den store sprogmodel var i stand til at levere de rigtige svar med noget nyttigt indhold. Lad os prøve at teste modellens matematiske og begrundelsesevner gennem følgende prompter
output = llm(
"### User:nLook at this series: 80, 10, 70, 15, 60, ...
What number should come next?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])
output = llm(
"### User:nJohn runs faster than Ken. Magnus runs faster than John.
Does Ken run faster than Magnus?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Ud fra de givne prompter, genererede SOLAR 10.7B en god respons. Den var i stand til at besvare de givne matematiske og logiske ræsonnementer korrekt og endda spørgsmålene relateret til sund fornuft. Generelt kan vi konkludere, at SOLAR 10.7B Large Language Model genererer gode svar
SOLAR 10.7B vs Mixtral MoE
Mixtral 8x7B MoE er skabt af Mistral AI med Mixture of Experts-arkitekturen. Kort sagt, denne blanding af eksperter, Mistral beskæftiger 8 7 milliarder parametermodeller. Hver af disse modeller har nogle af sine feed-forward-netværk erstattet af andre lag kaldet eksperter. Derfor anses Mixtral 8x7B for at have 8 eksperter. Og alle modellen tager i input-prompten, vil der være en gating-mekanisme, der kun vælger 2 af disse eksperter fra de 8. De 2 eksperter tager derefter denne input-prompt ind og genererer endelige output-tokens. Så vi kan se, at der er en smule kompleksitet involveret i denne type sammenlægning, hvor vi skal erstatte feed-forward-lagene med andre lag og indføre en gating-mekanisme, der vælger mellem disse eksperter
Mens SOLAR 10.7B-modellen fra Upstage udnytter dybdeopskaleringsmetoden. I Depth Up-Scaling fjerner vi kun lige et antal af startlagene fra en basismodel og det samme antal sidste lag fra dens kopiversion. Så slår vi bare modellerne sammen ved at stable den ene oven på den anden. Og med blot nogle få epoker med finjustering kan den fusionerede model vise en hurtig vækst i ydeevne. Her erstatter vi ikke de eksisterende lag med nogle andre lag. Heller ikke her har vi en portmekanisme. Overordnet set er Depth Up-Scaling en enkel og effektiv måde at flette modeller, der ikke involverer kompleksitet.
Ved at sammenligne ydeevnerne, dybdeopskaleringen, var SOLAR 7B dog i stand til at klare sig klart bedre end Mixtral 10.7x8B, som er en langt større model i sammenligning ved blot at kombinere to 7 milliarder modeller. Dette beviser effektiviteten af en simpel fusionsmetode over en kompleks metode som Mixtral of Experts
Begrænsninger og overvejelser
- Hyperparameterudforskning: En afgørende begrænsning er den utilstrækkelige udforskning af hyperparametre i DUS-tilgangen. På grund af hardwarebegrænsninger blev 8 lag fjernet fra begge ender af basismodellen uden at verificere, om dette tal er optimalt for at få den bedste ydeevne. Fremtidigt arbejde sigter mod at udføre mere stringente eksperimenter og at lave en analyse for at løse dette.
- Beregningskrav: Modellen har brug for en enorm mængde beregningsressourcer til træning og inferens. Dette kan begrænse brugen, hovedsageligt for dem med begrænsede beregningsevner.
- Forstyrrelser i træningsdata: Som alle maskinlæringsmodeller er det modtageligt for skævheder i træningsdataene, hvilket potentielt kan føre til skæve resultater i visse scenarier.
- Miljømæssig påvirkning: Selv det energiforbrug, der er nødvendigt til træning og drift af modellen, giver anledning til miljøproblemer, hvilket understreger vigtigheden af bæredygtig AI-udvikling.
- Modellens bredere implikationer: Selvom modellen viser forbedret ydeevne ved at følge instruktionerne, kræver den stadig opgavespecifik finjustering for optimal ydeevne i specialiserede applikationer. Denne finjusteringsproces er ressourcekrævende og er muligvis ikke altid effektiv.
Konklusion
I denne guide har vi taget et kig på den nyligt udgivne SOLAR 10.7Billion Parameter-model af Upstage AI. Upstage AI har taget en ny tilgang til at fusionere og skalere modeller. Avisen brugte en ny tilgang kaldet Depth Up-Scaling til at fusionere to Llama-2 7 Billion Parameter-modeller ved at fjerne nogle af start- og sluttransformatorlagene. Bagefter finjusterede den modellen på Open Source-datasæt og testede den på OpenLLM Leaderboard, opnåede den højeste H6-score og toppede leaderboardet.
Nøgleforsøg
- SOLAR 10.7B introducerer Depth Up-Scaling, en unik fusionstilgang, der udfordrer traditionelle metoder og viser fremskridt inden for modelarkitektur
- På trods af sine 10.7 milliarder parametre overstråler SOLAR 10.7B større modeller, overgår Mistral 7B, Qwen 14B og topper endda ranglister med versioner som SOLAR 10.7B Instruct
- Den to-trins finjusteringsproces, der involverer Instruktions- og Alignment Tuning, sikrer modellens tilpasningsevne til forskellige opgaver, hvilket gør den meget god til at følge instruktioner og tilpasse sig menneskelige præferencer
- SOLAR 10.7B udmærker sig på tværs af forskellige benchmarks og viser således sin kompetence i opgaver lige fra grundlæggende matematik og sprogforståelse til sund fornuft og sandfærdighedsevaluering
- SOLAR 10.7B er let tilgængelig på HuggingFace Hub og giver udviklere og forskere et effektivt og tilgængeligt værktøj til sprogbehandlingsapplikationer
- Du kan finjustere modellen ved at bruge de almindelige metoder, der bruges til at finjustere store sprogmodeller. For eksempel kan du bruge Supervised Fine-Tune Trainer (SFTrainer) fra Hugging Face til at finjustere SOLAR 10.7B-modellen.
Ofte stillede spørgsmål
A. SOLAR 10.7B er en 10.7 milliarder parametermodel af Upstage AI, der bruger en unik sammensmeltningsteknik kaldet Depth Up-Scaling. Det udmærker sig ved at udkonkurrere større LLM'er og fremvise fremskridt inden for flettemodeller.
A. Dybdevis skalering involverer to basismodeller. Processen involverer direkte at fusionere disse to basismodeller ved at stable dem oven på hinanden. Inden sammenlægningen finder sted, fjernes de indledende lag fra den ene model og de sidste lag fra den anden model.
A. SOLAR 10.7B gennemgår en to-trins fortræningsproces. Instruktionsfinjustering involverer træning af modellen på datasæt, der lægger vægt på instruktionsfølgning. Justering tuning forfiner modellens tilpasning til menneskelige præferencer ved hjælp af en teknik kaldet Direct Preference Optimization (DPO).
A. SOLAR 10.7B udmærker sig på tværs af forskellige benchmarks, herunder ARC (AI2 Reasoning Challenge), MMLU (Massive MultiTask Language Understanding), HellaSwag, Winogrande, TruthfulQA og GSM8K. Den opnår høje scores, hvilket demonstrerer dens alsidighed til at håndtere forskellige sprogopgaver.
A. SOLAR 10.7B overgår modeller som Mistral 7B og Qwen 14B, og viser overlegen ydeevne på trods af at de har færre parametre. Instruct-versionen konkurrerer endda med og udkonkurrerer meget store modeller, inklusive Mistral 8x7B og Qwen 72B, på forskellige benchmarks.
Mediet vist i denne artikel ejes ikke af Analytics Vidhya og bruges efter forfatterens skøn.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/
- :har
- :er
- :ikke
- :hvor
- $OP
- 10
- 110
- 12
- 15 %
- 16
- 24
- 300
- 32
- 60
- 7
- 70
- 8
- 80
- 9
- a
- evner
- evne
- I stand
- adgang
- nøjagtighed
- opnår
- opnå
- tværs
- adresse
- Tilføjer
- fremskridt
- Efter
- forude
- AI
- AI2
- Rettet
- målsætninger
- tilpasse
- justeret
- justering
- tilpasning
- Alle
- tillade
- sammen
- også
- altid
- beløb
- an
- analyse
- analytics
- Analyse Vidhya
- ,
- En anden
- besvare
- svar
- api
- Anvendelse
- applikationer
- Indløs
- tilgang
- passende
- Arc
- arkitektur
- ER
- områder
- artikel
- AS
- udseende
- aspekter
- vurderer
- Vurdering
- Assistant
- At
- opmærksomhed
- til rådighed
- bund
- grundlæggende
- BE
- slå
- fordi
- været
- før
- begyndte
- være
- jf. nedenstående
- benchmark
- Benchmarks
- BEDSTE
- mellem
- fordomme
- Billion
- Bit
- blogathon
- både
- bredere
- men
- by
- ringe
- kaldet
- CAN
- kapaciteter
- vis
- udfordre
- udfordringer
- udfordrende
- chatte
- valg
- valgt
- klasse
- tydeligt
- lukket
- kode
- Kolonne
- Kolonner
- kombinerer
- Kom
- Fælles
- Common Sense
- sammenligne
- sammenlignet
- sammenligne
- sammenligning
- konkurrerer
- komplekse
- kompleksiteter
- kompleksitet
- beregningsmæssige
- computer
- Datalogi
- begreber
- Bekymringer
- konkluderer
- Adfærd
- betragtes
- forbrug
- indeholder
- indhold
- sammenhæng
- fortsatte
- kontrast
- bidragydere
- Core
- korrekt
- kunne
- dækker
- CPU
- skabe
- oprettet
- afgørende
- data
- datasæt
- falde
- levere
- krav
- Demo
- demonstrere
- demonstrerer
- dybde
- konstrueret
- Trods
- udviklere
- Udvikling
- forskellige
- direkte
- direkte
- discipliner
- diskretion
- skelner
- forskelligartede
- do
- gør
- færdig
- downloade
- downloads
- grund
- hver
- spiser
- Effektiv
- effektivitet
- effektiv
- Æg
- at understrege
- selvstændige
- beskæftiger
- ender
- energi
- Energiforbrug
- nok
- sikrer
- Hele
- miljømæssige
- miljøhensyn
- epoker
- Ether (ETH)
- evaluere
- evalueringer
- Endog
- hverdagen
- alle
- udviklende
- eksempel
- eksempler
- eksisterende
- eksperimenter
- eksperter
- udforskning
- Ansigtet
- Faktuel
- falk
- langt
- hurtigere
- tilbagemeldinger
- få
- færre
- felt
- endelige
- Fornavn
- Blink
- fokuserer
- efterfulgt
- efter
- Til
- formular
- formation
- Gratis
- fra
- yderligere
- fremtiden
- generere
- genereret
- generere
- generation
- få
- få
- Giv
- given
- Give
- godt
- fik
- GPU
- Vækst
- vejlede
- Håndterer
- Håndtering
- Hardware
- Have
- have
- dermed
- link.
- Høj
- højeste
- fremhæve
- historie
- Hvordan
- How To
- HTTPS
- Hub
- kæmpe
- KrammerFace
- menneskelig
- Mennesker
- if
- KIMOs Succeshistorier
- implikationer
- importere
- betydning
- imponerende
- forbedret
- in
- starten
- omfatter
- omfatter
- Herunder
- oplysninger
- initial
- innovationer
- innovativ
- indgang
- indsigt
- installere
- instans
- anvisninger
- ind
- indføre
- introduceret
- Introducerer
- intuitiv
- involvere
- involverede
- involverer
- involverer
- IT
- ITS
- selv
- John
- domme
- lige
- Kumar
- Sprog
- stor
- større
- Lov
- lægge
- lag
- leaderboards
- førende
- læring
- Længde
- Lets
- Niveau
- Udnytter
- Bibliotek
- levetid
- ligesom
- GRÆNSE
- begrænsning
- begrænsninger
- Limited
- Llama
- belastning
- lastning
- logik
- logisk
- Se
- maskine
- machine learning
- hovedsageligt
- større
- lave
- Makers
- maerker
- Making
- mange
- massive
- matematik
- matematiske
- matematik
- max-bredde
- maksimal
- maksimumsbeløb
- Kan..
- mekanisme
- Medier
- nævne
- Flet
- sammenlægning
- metode
- metoder
- fejl
- blanding
- model
- modeller
- mere
- mere effektiv
- flere
- navn
- nødvendig
- Behov
- behov
- behov
- net
- Ny
- næste
- NLP
- bemærkelsesværdig
- bemærkede
- nu
- nuancer
- nummer
- Nvidia
- objekt
- of
- on
- ONE
- kun
- åbent
- open source
- OpenAI
- drift
- optimal
- optimering
- or
- original
- Andet
- Andre
- vores
- ud
- udfald
- udkonkurrerer
- udkonkurrerede
- at overgå
- udkonkurrerer
- output
- i løbet af
- samlet
- ejede
- Papir
- parameter
- parametre
- del
- passerer
- sti
- udføre
- ydeevne
- forestillinger
- udføres
- udfører
- udfører
- Place
- plato
- Platon Data Intelligence
- PlatoData
- politik
- Populær
- udgør
- potentielt
- vigtigste
- præferencer
- foretrækkes
- præsentere
- tidligere
- problemløsning
- problemer
- behandle
- Processer
- prompter
- beviser
- forudsat
- giver
- leverer
- offentliggjort
- Python
- Spørgsmål
- hurtigt
- spænder
- hurtige
- let
- nylige
- for nylig
- fast
- forstærkning læring
- Afvist..
- relaterede
- frigive
- frigivet
- pålidelighed
- Fjern
- fjernet
- fjernelse
- erstatte
- udskiftes
- Kræver
- forskning
- forskere
- ressourceintensive
- Ressourcer
- svar
- reaktioner
- resultere
- Resultater
- afkast
- højre
- stringent
- Risen
- Kør
- kører
- løber
- Said
- samme
- gemt
- Scale
- skalering
- scenarier
- Videnskab
- videnskabelig
- score
- scores
- Anden
- Sektion
- se
- se
- synes
- set
- forstand
- dømme
- Series
- sæt
- flere
- bør
- Vis
- fremvisning
- viser
- vist
- Shows
- lignende
- Simpelt
- siden
- enkelt
- færdigheder
- smartphones
- So
- sol
- nogle
- sofistikeret
- Kilde
- specialiserede
- specifikt
- specificeret
- stabling
- Stage
- stå
- starte
- påbegyndt
- Starter
- starter
- Statement
- Trin
- Stadig
- Stands
- butik
- opbevaret
- Storm
- sådan
- overlegen
- overgår
- overgår
- modtagelig
- bæredygtig
- SVG
- systemet
- Tag
- taget
- tager
- opgaver
- teknik
- fortælle
- fortæller
- skabelon
- prøve
- afprøvet
- Test
- tests
- tekst
- end
- at
- verdenen
- deres
- Them
- derefter
- Der.
- Disse
- de
- Tænker
- denne
- dem
- selvom?
- tænkte
- tre
- Gennem
- Dermed
- tid
- gange
- til
- sammen
- token
- Tokens
- værktøj
- top
- toppet
- traditionelle
- Tog
- uddannet
- Kurser
- transformer
- transformers
- prøv
- to
- typen
- gennemgår
- forstå
- forståelse
- gennemgik
- enestående
- på
- us
- Brug
- brug
- anvendte
- nyttigt
- Bruger
- bruger
- ved brug af
- udnytte
- udnyttet
- Ved hjælp af
- variabel
- række
- forskellige
- verificere
- alsidighed
- udgave
- meget
- vs
- ønsker
- var
- Vej..
- we
- WebP
- GODT
- var
- Hvad
- Hvad er
- hvornår
- som
- mens
- bredere
- vilje
- med
- uden
- Arbejde
- arbejder
- virker
- world
- dig
- Din
- zephyrnet