I dette indlæg demonstrerer vi, hvordan man bruger neural arkitektursøgning (NAS) baseret strukturel beskæring til at komprimere en finjusteret BERT-model for at forbedre modellens ydeevne og reducere inferenstider. Foruddannede sprogmodeller (PLM'er) gennemgår hurtig kommerciel og virksomhedsadoption inden for områderne produktivitetsværktøjer, kundeservice, søgning og anbefalinger, automatisering af forretningsprocesser og skabelse af indhold. Implementering af PLM-inferensendepunkter er typisk forbundet med højere latenstid og højere infrastrukturomkostninger på grund af beregningskravene og reduceret beregningseffektivitet på grund af det store antal parametre. Beskæring af en PLM reducerer størrelsen og kompleksiteten af modellen, samtidig med at dens forudsigelsesevne bevares. Beskærede PLM'er opnår et mindre hukommelsesfodaftryk og lavere latenstid. Vi demonstrerer, at ved at beskære en PLM og udligne parametertælling og valideringsfejl for en specifik målopgave, og er i stand til at opnå hurtigere responstider sammenlignet med basis-PLM-modellen.
Multi-objektiv optimering er et område for beslutningstagning, der optimerer mere end én objektiv funktion, såsom hukommelsesforbrug, træningstid og computerressourcer, for at blive optimeret samtidigt. Strukturel beskæring er en teknik til at reducere størrelsen og beregningskravene til PLM ved at beskære lag eller neuroner/knuder, mens man forsøger at bevare modellens nøjagtighed. Ved at fjerne lag opnår strukturel beskæring højere kompressionshastigheder, hvilket fører til hardwarevenlig struktureret sparsitet, der reducerer køretider og responstider. Anvendelse af en strukturel beskæringsteknik på en PLM-model resulterer i en lettere model med et lavere hukommelsesfodaftryk, der, når det hostes som et slutningsendepunkt i SageMaker, giver forbedret ressourceeffektivitet og reducerede omkostninger sammenlignet med den originale finjusterede PLM.
Begreberne illustreret i dette indlæg kan anvendes på applikationer, der bruger PLM-funktioner, såsom anbefalingssystemer, sentimentanalyse og søgemaskiner. Specifikt kan du bruge denne tilgang, hvis du har dedikerede maskinlærings- (ML) og datavidenskabsteams, der finjusterer deres egne PLM-modeller ved hjælp af domænespecifikke datasæt og implementerer et stort antal inferensendepunkter ved hjælp af Amazon SageMaker. Et eksempel er en online-forhandler, der implementerer et stort antal slutningsendepunkter til tekstresumé, produktkatalogklassificering og produktfeedback-sentimentklassificering. Et andet eksempel kan være en sundhedsudbyder, der bruger PLM-slutningsendepunkter til klassificering af kliniske dokumenter, navngivne enhedsgenkendelse fra medicinske rapporter, medicinske chatbots og patientrisikostratificering.
Løsningsoversigt
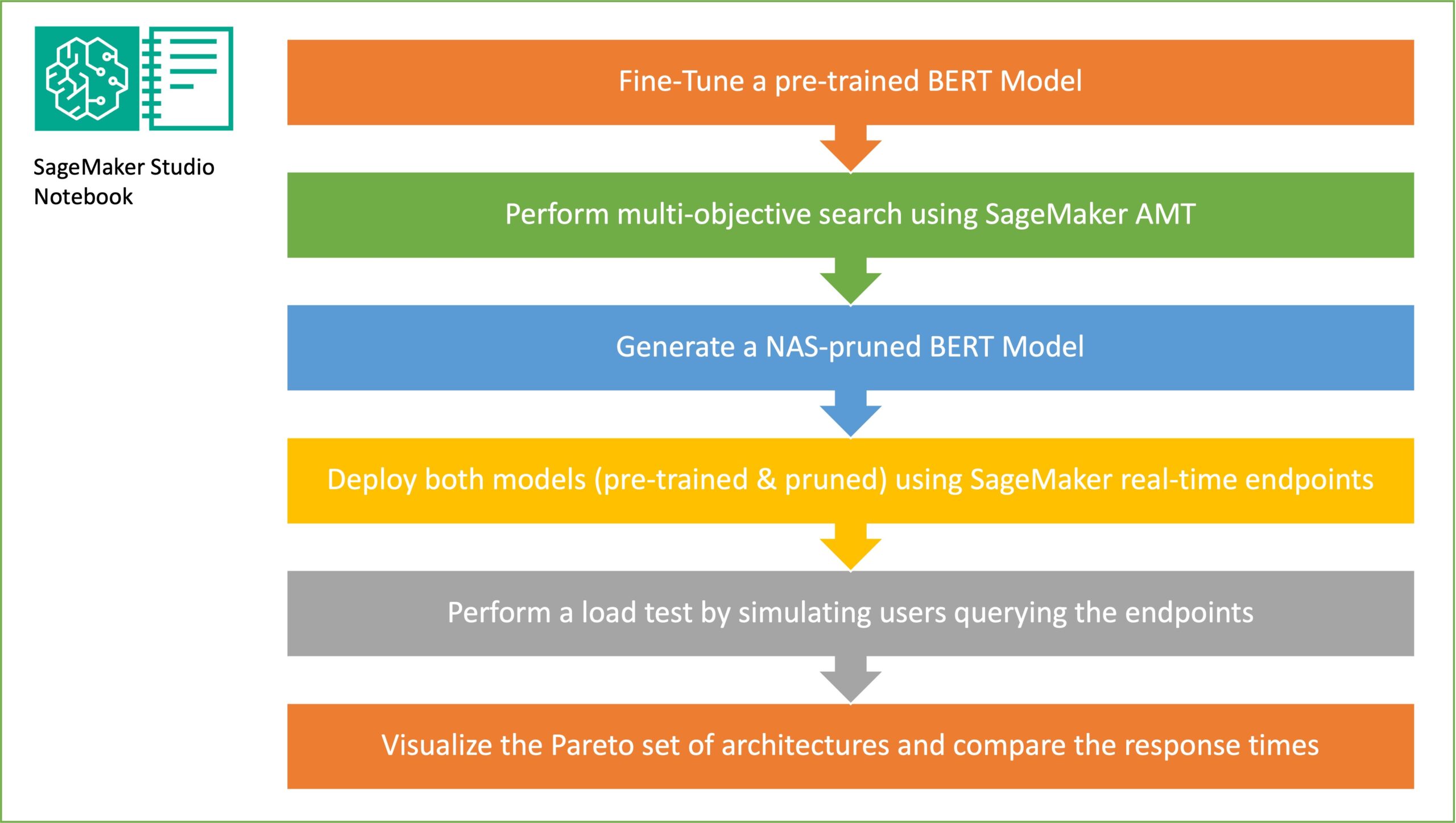
I dette afsnit præsenterer vi den overordnede arbejdsgang og forklarer tilgangen. Først bruger vi en Amazon SageMaker Studio notesbog at finjustere en forudtrænet BERT-model på en målopgave ved hjælp af et domænespecifikt datasæt. BERTI (Bidirectional Encoder Representations from Transformers) er en præ-trænet sprogmodel baseret på transformer arkitektur bruges til naturlig sprogbehandling (NLP) opgaver. Neural arkitektursøgning (NAS) er en tilgang til automatisering af design af kunstige neurale netværk og er tæt forbundet med hyperparameteroptimering, en meget brugt tilgang inden for maskinlæring. Målet med NAS er at finde den optimale arkitektur til et givent problem ved at søge over et stort sæt kandidatarkitekturer ved hjælp af teknikker som gradientfri optimering eller ved at optimere de ønskede metrics. Arkitekturens ydeevne måles typisk ved hjælp af metrics såsom valideringstab. SageMaker Automatisk Model Tuning (AMT) automatiserer den kedelige og komplekse proces med at finde de optimale kombinationer af hyperparametre i ML-modellen, der giver den bedste modelydelse. AMT bruger intelligente søgealgoritmer og iterative evalueringer ved hjælp af en række hyperparametre, som du angiver. Den vælger de hyperparameterværdier, der skaber en model, der yder bedst, målt ved præstationsmålinger såsom nøjagtighed og F-1-score.
Finjusteringstilgangen beskrevet i dette indlæg er generisk og kan anvendes på ethvert tekstbaseret datasæt. Opgaven, der er tildelt BERT PLM, kan være en tekstbaseret opgave, såsom sentimentanalyse, tekstklassificering eller Q&A. I denne demo er målopgaven et binært klassifikationsproblem, hvor BERT bruges til at identificere, ud fra et datasæt, der består af en samling af par af tekstfragmenter, om betydningen af et tekstfragment kan udledes af det andet fragment. Vi bruger Genkendelse af tekstuelle entailment-datasæt fra GLUE benchmarking suite. Vi udfører en multi-objektiv søgning ved hjælp af SageMaker AMT for at identificere de undernetværk, der tilbyder optimale afvejninger mellem parameterantal og forudsigelsesnøjagtighed for målopgaven. Når vi udfører en multi-objektiv søgning, starter vi med at definere nøjagtigheden og parameterantallet som de mål, vi sigter efter at optimere.
Inden for BERT PLM-netværket kan der være modulære, selvstændige undernetværk, der tillader modellen at have specialiserede egenskaber såsom sprogforståelse og videnrepræsentation. BERT PLM bruger et multi-headed self-attention sub-netværk og et feed-forward sub-netværk. Et flerhovedet, selvopmærksomhedslag tillader BERT at relatere forskellige positioner af en enkelt sekvens for at beregne en repræsentation af sekvensen ved at tillade flere hoveder at behandle flere kontekstsignaler. Inputtet er opdelt i flere underrum, og selvopmærksomhed påføres hver af underrummene separat. Flere hoveder i en transformer PLM gør det muligt for modellen i fællesskab at behandle information fra forskellige repræsentationsunderrum. Et feed-forward-undernetværk er et simpelt neuralt netværk, der tager outputtet fra det flerhovedede selvopmærksomhedsundernetværk, behandler dataene og returnerer de endelige indkoderrepræsentationer.
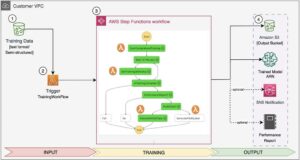
Målet med tilfældig udtagning af undernetværk er at træne mindre BERT-modeller, der kan præstere godt nok på målopgaver. Vi prøver 100 tilfældige undernetværk fra den finjusterede basis BERT-model og evaluerer 10 netværk samtidigt. De trænede undernetværk evalueres for de objektive metrics, og den endelige model vælges ud fra de afvejninger, der findes mellem de objektive metrics. Vi visualiserer Pareto foran for de samplede undernetværk, som indeholder den beskærede model, der giver den optimale afvejning mellem modelnøjagtighed og modelstørrelse. Vi vælger kandidatundernetværket (NAS-beskåret BERT-model) baseret på modelstørrelsen og modelnøjagtigheden, som vi er villige til at bytte fra. Dernæst hoster vi endepunkterne, den fortrænede BERT-basismodel og den NAS-beskærede BERT-model ved hjælp af SageMaker. Til at udføre belastningstest bruger vi Locust, et open source-belastningstestværktøj, som du kan implementere ved hjælp af Python. Vi kører belastningstest på begge endepunkter ved hjælp af Locust og visualiserer resultaterne ved hjælp af Pareto-fronten for at illustrere afvejningen mellem responstider og nøjagtighed for begge modeller. Følgende diagram giver et overblik over arbejdsgangen, der er forklaret i dette indlæg.
Forudsætninger
For denne stilling kræves følgende forudsætninger:
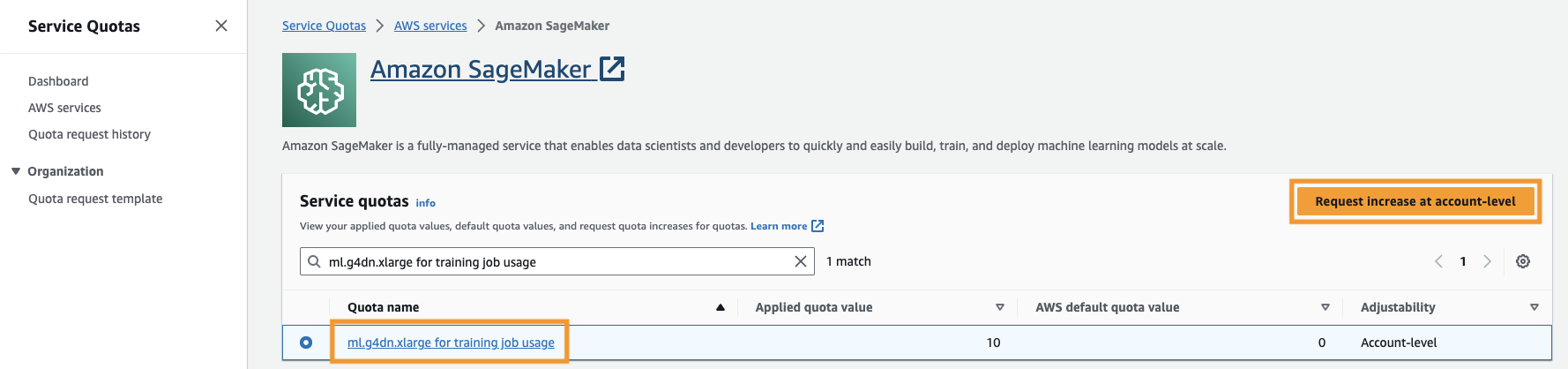
Du skal også øge servicekvote for at få adgang til mindst tre forekomster af ml.g4dn.xlarge forekomster i SageMaker. Forekomsttypen ml.g4dn.xlarge er den omkostningseffektive GPU-instans, der giver dig mulighed for at køre PyTorch native. For at øge servicekvoten skal du udføre følgende trin:
- På konsollen skal du navigere til Servicekvoter.
- Til Administrer kvoter, vælg Amazon SageMaker, Og vælg derefter Se kvoter.

- Søg efter "ml-g4dn.xlarge for træningsjobbrug", og vælg kvoteelementet.
- Vælg Anmod om forhøjelse på kontoniveau.
- Til Forøg kvoteværdien, indtast en værdi på 5 eller højere.
- Vælg Anmod om.
Den anmodede kvotegodkendelse kan tage noget tid at fuldføre afhængigt af kontotilladelserne.

- Åbn SageMaker Studio fra SageMaker-konsollen.

- Vælg Systemterminal under Hjælpeprogrammer og filer.

- Kør følgende kommando for at klone GitHub repo til SageMaker Studio-forekomsten:
- Naviger til
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Åbn filen
nas_for_llm_with_amt.ipynb. - Indstil miljøet med en
ml.g4dn.xlargeeksempel og vælg Type.

Opsæt den fortrænede BERT-model
I dette afsnit importerer vi datasættet Recognizing Textual Entailment fra datasætbiblioteket og deler datasættet op i trænings- og valideringssæt. Dette datasæt består af sætningspar. BERT PLM's opgave er at genkende, givet to tekstfragmenter, om betydningen af et tekstfragment kan udledes af det andet fragment. I det følgende eksempel kan vi udlede betydningen af den første sætning fra den anden sætning:
Vi indlæser det tekstgenkendende involveringsdatasæt fra lIM benchmarking suite via datasæt bibliotek fra Hugging Face i vores træningsscript (./training.py). Vi opdeler det originale træningsdatasæt fra GLUE i et trænings- og valideringssæt. I vores tilgang finjusterer vi basis BERT-modellen ved hjælp af træningsdatasættet, hvorefter vi udfører en multi-objektiv søgning for at identificere det sæt af undernetværk, der balancerer optimalt mellem de objektive metrics. Vi bruger udelukkende træningsdatasættet til at finjustere BERT-modellen. Vi bruger dog valideringsdata til multi-objektiv søgning ved at måle nøjagtigheden på holdout-valideringsdatasættet.
Finjuster BERT PLM ved hjælp af et domænespecifikt datasæt
De typiske use cases for en rå BERT-model inkluderer forudsigelse af næste sætning eller maskeret sprogmodellering. For at bruge basis BERT-modellen til downstream-opgaver såsom tekstgenkendelse, skal vi finjustere modellen yderligere ved hjælp af et domænespecifikt datasæt. Du kan bruge en finjusteret BERT-model til opgaver såsom sekvensklassificering, besvarelse af spørgsmål og tokenklassificering. Men til formålet med denne demo bruger vi den finjusterede model til binær klassificering. Vi finjusterer den præ-trænede BERT-model med træningsdatasættet, som vi forberedte tidligere, ved hjælp af følgende hyperparametre:
Vi gemmer modeltræningens kontrolpunkt til en Amazon Simple Storage Service (Amazon S3) spand, så modellen kan indlæses under den NAS-baserede multi-objektive søgning. Før vi træner modellen, definerer vi metrics såsom epoke, træningstab, antal parametre og valideringsfejl:
Efter at finjusteringsprocessen starter, tager træningsjobbet omkring 15 minutter at fuldføre.
Udfør en multi-objektiv søgning for at vælge undernetværk og visualisere resultaterne
I det næste trin udfører vi en multi-objektiv søgning på den finjusterede BERT-basismodel ved at udtage tilfældige undernetværk ved hjælp af SageMaker AMT. For at få adgang til et undernetværk inden for supernetværket (den finjusterede BERT-model), maskerer vi alle de komponenter i PLM'en, som ikke er en del af undernetværket. Maskering af et supernetværk for at finde undernetværk i en PLM er en teknik, der bruges til at isolere og identificere mønstre for modellens adfærd. Bemærk, at Hugging Face-transformere skal have den skjulte størrelse for at være et multiplum af antallet af hoveder. Den skjulte størrelse i en transformer PLM styrer størrelsen af det skjulte tilstandsvektorrum, hvilket påvirker modellens evne til at lære komplekse repræsentationer og mønstre i dataene. I en BERT PLM har den skjulte tilstandsvektor en fast størrelse (768). Vi kan ikke ændre den skjulte størrelse, og derfor skal antallet af hoveder være i [1, 3, 6, 12].
I modsætning til enkelt-objektiv optimering har vi i multi-målsætningen typisk ikke en enkelt løsning, der samtidig optimerer alle målsætninger. I stedet sigter vi mod at samle et sæt løsninger, der dominerer alle andre løsninger i mindst ét mål (såsom valideringsfejl). Nu kan vi starte den multi-objektive søgning gennem AMT ved at indstille de metrics, som vi ønsker at reducere (valideringsfejl og antal parametre). De tilfældige undernetværk er defineret af parameteren max_jobs og antallet af samtidige job er defineret af parameteren max_parallel_jobs. Koden til at indlæse modelkontrolpunktet og evaluere undernetværket er tilgængelig i evaluate_subnetwork.py scripts.
AMT-tuning-jobbet tager cirka 2 timer og 20 minutter at køre. Efter at AMT-tuning-jobbet er kørt med succes, analyserer vi jobbets historie og indsamler undernetværkets konfigurationer, såsom antal heads, antal lag, antal enheder og de tilsvarende metrics såsom valideringsfejl og antal parametre. Følgende skærmbillede viser oversigten over et vellykket AMT-tunerjob.
Dernæst visualiserer vi resultaterne ved hjælp af et Pareto-sæt (også kendt som Pareto-grænse eller Pareto-optimalt sæt), som hjælper os med at identificere optimale sæt af undernetværk, der dominerer alle andre undernetværk i den objektive metrik (valideringsfejl):
Først indsamler vi data fra AMT-tuning-jobbet. Så plotter vi Pareto-sættet vha matplotlob.pyplot med antal parametre i x-aksen og valideringsfejl i y-aksen. Dette indebærer, at når vi flytter fra et undernetværk af Pareto-sættet til et andet, skal vi enten ofre ydeevne eller modelstørrelse, men forbedre den anden. I sidste ende giver Pareto-sættet os fleksibiliteten til at vælge det undernetværk, der passer bedst til vores præferencer. Vi kan beslutte, hvor meget vi vil reducere størrelsen af vores netværk, og hvor meget ydeevne vi er villige til at ofre.

Implementer den finjusterede BERT-model og den NAS-optimerede undernetværksmodel ved hjælp af SageMaker
Dernæst implementerer vi den største model i vores Pareto-sæt, der fører til den mindste mængde af ydeevnedegeneration til en SageMaker slutpunkt. Den bedste model er den, der giver en optimal afvejning mellem valideringsfejlen og antallet af parametre for vores use case.
Model sammenligning
Vi tog en forudtrænet basis BERT-model, finjusterede den ved hjælp af et domænespecifikt datasæt, kørte en NAS-søgning for at identificere dominerende undernetværk baseret på de objektive målinger og implementerede den beskærede model på et SageMaker-slutpunkt. Derudover tog vi den fortrænede basis BERT-model og implementerede basismodellen på et andet SageMaker-endepunkt. Dernæst løb vi belastningstest ved at bruge Locust på begge inferensendepunkter og evaluerede ydeevnen i form af responstid.
Først importerer vi de nødvendige Locust- og Boto3-biblioteker. Derefter konstruerer vi en anmodningsmetadata og registrerer starttidspunktet, der skal bruges til belastningstest. Derefter sendes nyttelasten til SageMaker endpoint invoke API via BotoClient for at simulere rigtige brugeranmodninger. Vi bruger Locust til at afføde flere virtuelle brugere til at sende anmodninger parallelt og måle endepunktets ydeevne under belastningen. Tests køres ved at øge antallet af brugere for henholdsvis hvert af de to endepunkter. Når testene er afsluttet, udsender Locust en CSV-fil med anmodningsstatistik for hver af de installerede modeller.
Dernæst genererer vi responstidsplottene fra de CSV-filer, der er downloadet efter at have kørt testene med Locust. Formålet med at plotte responstiden vs. antallet af brugere er at analysere belastningstestresultaterne ved at visualisere effekten af responstiden for modellens endepunkter. I det følgende diagram kan vi se, at det NAS-beskærede modelendepunkt opnår en lavere responstid sammenlignet med basis BERT-modellens slutpunkt.
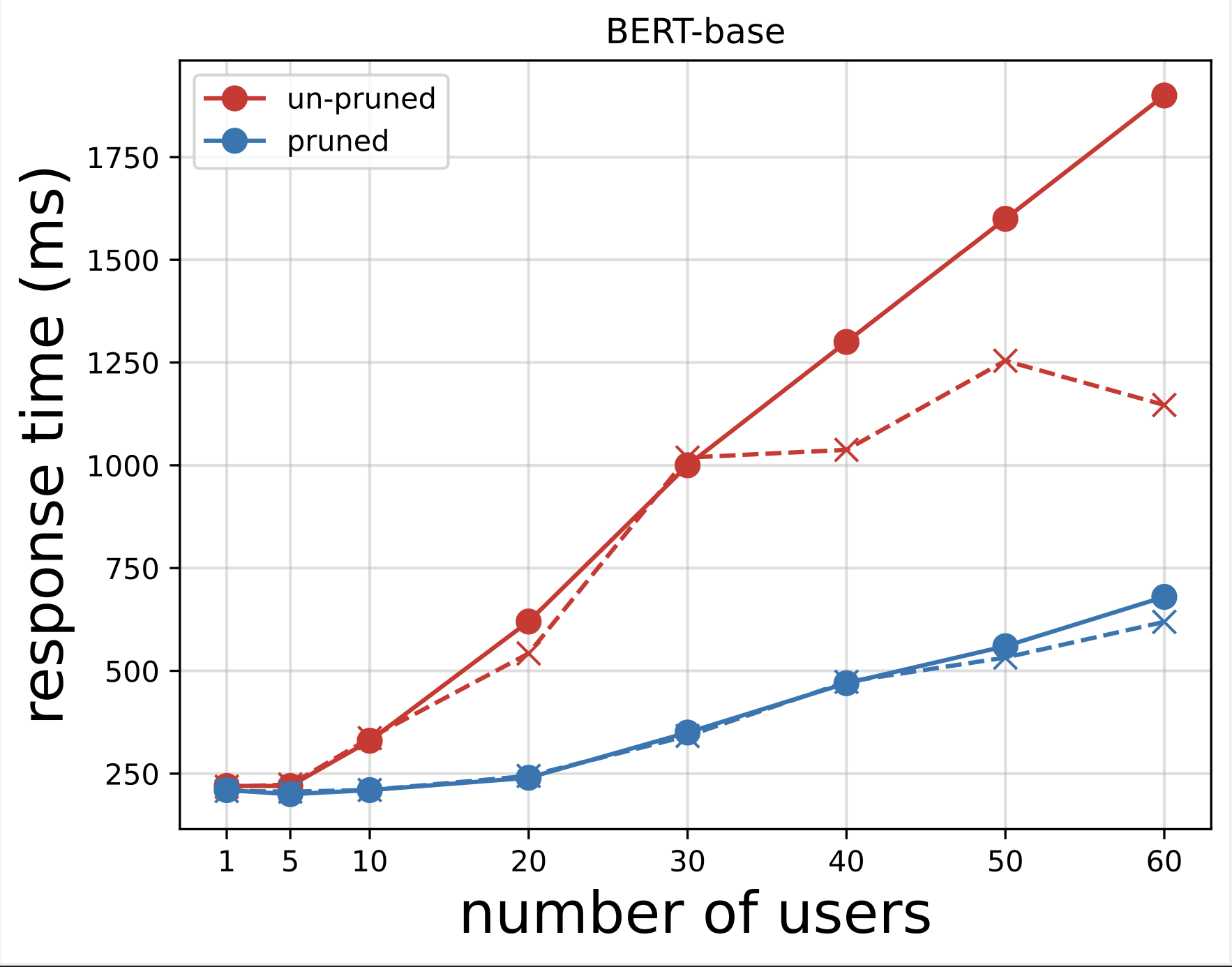
I det andet diagram, som er en udvidelse af det første diagram, observerer vi, at efter omkring 70 brugere, begynder SageMaker at drosle base BERT-modellens slutpunkt og kaster en undtagelse. Men for den NAS-beskærede modelslutpunkt sker reguleringen mellem 90-100 brugere og med en lavere responstid.

Fra de to diagrammer observerer vi, at den beskårede model har en hurtigere responstid og skalerer bedre sammenlignet med den ubeskårede model. Efterhånden som vi skalerer antallet af inferensendepunkter, som det er tilfældet med brugere, der implementerer et stort antal inferensslutpunkter til deres PLM-applikationer, begynder omkostningsfordelene og ydeevneforbedringen at blive ret betydelige.
Ryd op
For at slette SageMaker-endepunkterne for den finjusterede BERT-basismodel og den NAS-beskærede model skal du udføre følgende trin:
- Vælg på SageMaker-konsollen Inferens , Endpoints i navigationsruden.
- Vælg slutpunktet og slet det.
Alternativt kan du køre følgende kommandoer fra SageMaker Studio-notesbogen ved at angive slutpunktsnavnene:
Konklusion
I dette indlæg diskuterede vi, hvordan man bruger NAS til at beskære en finjusteret BERT-model. Vi trænede først en basis BERT-model ved hjælp af domænespecifikke data og implementerede den til et SageMaker-slutpunkt. Vi udførte en multi-objektiv søgning på den finjusterede basis BERT-model ved hjælp af SageMaker AMT til en målopgave. Vi visualiserede Pareto-fronten og valgte den Pareto-optimale NAS-beskærede BERT-model og implementerede modellen til et andet SageMaker-slutpunkt. Vi udførte belastningstest ved hjælp af Locust for at simulere brugere, der forespørger på begge endepunkter, og målte og registrerede responstiderne i en CSV-fil. Vi plottede responstiden vs. antallet af brugere for begge modeller.
Vi observerede, at den beskårede BERT-model klarede sig betydeligt bedre i både responstid og instans-drosseltærskel. Vi konkluderede, at den NAS-beskærede model var mere modstandsdygtig over for en øget belastning på endepunktet, hvilket bibeholdt en lavere responstid, selvom flere brugere stressede systemet sammenlignet med basis BERT-modellen. Du kan anvende NAS-teknikken beskrevet i dette indlæg på enhver stor sprogmodel for at finde en beskåret model, der kan udføre målopgaven med væsentligt lavere responstid. Du kan yderligere optimere tilgangen ved at bruge latens som en parameter ud over valideringstab.
Selvom vi bruger NAS i dette indlæg, er kvantisering en anden almindelig tilgang, der bruges til at optimere og komprimere PLM-modeller. Kvantisering reducerer præcisionen af vægtene og aktiveringerne i et trænet netværk fra 32-bit flydende komma til lavere bitbredder såsom 8-bit eller 16-bit heltal, hvilket resulterer i en komprimeret model, der genererer hurtigere inferens. Kvantisering reducerer ikke antallet af parametre; i stedet reducerer det præcisionen af de eksisterende parametre for at få en komprimeret model. NAS-beskæring fjerner redundante netværk i en PLM, hvilket skaber en sparsom model med færre parametre. Typisk bruges NAS-beskæring og -kvantisering sammen til at komprimere store PLM'er for at bevare modelnøjagtigheden, reducere valideringstab, samtidig med at ydeevnen forbedres og modelstørrelsen reduceres. De andre almindeligt anvendte teknikker til at reducere størrelsen af PLM'er omfatter videndestillation, matrixfaktoriseringog destillationskaskader.
Den tilgang, der foreslås i blogindlægget, er velegnet til teams, der bruger SageMaker til at træne og finjustere modellerne ved hjælp af domænespecifikke data og implementere endepunkterne for at generere inferens. Hvis du leder efter en fuldt administreret tjeneste, der tilbyder et udvalg af højtydende fundamentmodeller, der er nødvendige for at bygge generative AI-applikationer, kan du overveje at bruge Amazonas grundfjeld. Hvis du leder efter forudtrænede open source-modeller til en bred vifte af business use cases og ønsker at få adgang til løsningsskabeloner og eksempler på notesbøger, kan du overveje at bruge Amazon SageMaker JumpStart. En fortrænet version af Hugging Face BERT-basisbeklædningsmodellen, som vi brugte i dette indlæg, er også tilgængelig fra SageMaker JumpStart.
Om forfatterne
 Aparajithan Vaidyanathan er Principal Enterprise Solutions Architect hos AWS. Han er en Cloud Architect med 24+ års erfaring med at designe og udvikle enterprise, storskala og distribuerede softwaresystemer. Han har specialiseret sig i Generativ AI og Machine Learning Data Engineering. Han er en håbefuld maratonløber, og hans hobbyer omfatter vandreture, cykling og at tilbringe tid med sin kone og to drenge.
Aparajithan Vaidyanathan er Principal Enterprise Solutions Architect hos AWS. Han er en Cloud Architect med 24+ års erfaring med at designe og udvikle enterprise, storskala og distribuerede softwaresystemer. Han har specialiseret sig i Generativ AI og Machine Learning Data Engineering. Han er en håbefuld maratonløber, og hans hobbyer omfatter vandreture, cykling og at tilbringe tid med sin kone og to drenge.
 Aaron Klein er en Sr Applied Scientist hos AWS, der arbejder på automatiserede maskinlæringsmetoder til dybe neurale netværk.
Aaron Klein er en Sr Applied Scientist hos AWS, der arbejder på automatiserede maskinlæringsmetoder til dybe neurale netværk.
 Jacek Golebiowski er Sr Applied Scientist ved AWS.
Jacek Golebiowski er Sr Applied Scientist ved AWS.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :har
- :er
- :ikke
- :hvor
- ][s
- $OP
- 1
- 10
- 100
- 11
- 12
- 13
- 15 %
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- evne
- I stand
- adgang
- Konto
- nøjagtighed
- opnå
- opnår
- aktiveringer
- Desuden
- Vedtagelse
- Efter
- AI
- sigte
- sigter
- algoritmer
- Alle
- tillade
- tillade
- tillader
- også
- Amazon
- Amazon Web Services
- beløb
- an
- analyse
- analytics
- analysere
- ,
- En anden
- besvarelse
- enhver
- api
- applikationer
- anvendt
- Indløs
- Anvendelse
- tilgang
- godkendelse
- cirka
- arkitektur
- ER
- OMRÅDE
- områder
- argumenter
- omkring
- kunstig
- kunstige neurale netværk
- AS
- aspirerende
- tildelt
- forbundet
- At
- forsøger
- deltage
- Automatiseret
- automatiseret maskinindlæring
- automater
- Automatisk Ur
- Automatisering
- Automation
- til rådighed
- AWS
- Axis
- Balance
- bund
- baseret
- BE
- bliver
- før
- adfærd
- benchmarking
- fordele
- BEDSTE
- Bedre
- mellem
- Bit
- krop
- både
- bygge
- virksomhed
- Forretningsproces
- Automatisering af forretningsprocesser
- men
- by
- CAN
- kandidat
- kapaciteter
- tilfælde
- tilfælde
- katalog
- lave om
- Chart
- Diagrammer
- chatbots
- valg
- Vælg
- valgt
- klasse
- klassificering
- Klinisk
- nøje
- Cloud
- kode
- indsamler
- samling
- kombinationer
- kommerciel
- Fælles
- almindeligt
- sammenlignet
- fuldføre
- Afsluttet
- komplekse
- kompleksitet
- komponenter
- beregningsmæssige
- Compute
- begreber
- indgået
- Overvej
- består
- Konsol
- begrænsninger
- konstruere
- forbrug
- indeholder
- indhold
- indholdsskabelse
- sammenhæng
- fortsæt
- kontrast
- kontrol
- Tilsvarende
- Koste
- Omkostninger
- tælle
- skabe
- skaber
- skabelse
- kunde
- Kundeservice
- data
- datalogi
- datasæt
- dato tid
- beslutte
- Beslutningstagning
- dedikeret
- dyb
- dybe neurale netværk
- definere
- definerede
- definere
- Demo
- demonstrere
- Afhængigt
- indsætte
- indsat
- implementering
- udruller
- beskrevet
- Design
- designe
- ønskes
- udvikling
- forskellige
- drøftet
- distribueret
- dokumentet
- Er ikke
- dominerende
- dominere
- Dont
- grund
- i løbet af
- e
- hver
- effektivitet
- effektiv
- enten
- Endpoint
- endpoints
- Engineering
- Motorer
- nok
- Indtast
- Enterprise
- virksomhedens adoption
- Enterprise Solutions
- enhed
- indrejse
- Miljø
- epoke
- fejl
- Ether (ETH)
- evaluere
- evalueret
- evalueringer
- Endog
- begivenheder
- eksempel
- Undtagen
- undtagelse
- udelukkende
- eksisterende
- erfaring
- Forklar
- forklarede
- udvidelse
- Ansigtet
- falsk
- hurtigere
- Funktionalitet
- tilbagemeldinger
- færre
- felt
- File (Felt)
- Filer
- endelige
- Finde
- finde
- Fornavn
- fast
- Fleksibilitet
- flydende
- efter
- Fodspor
- Til
- fundet
- Foundation
- fra
- forsiden
- Frontier
- fuldt ud
- funktion
- yderligere
- generere
- genererer
- generative
- Generativ AI
- få
- given
- mål
- GPU
- grå
- sker
- Have
- he
- hoved
- hoveder
- sundhedspleje
- hjælper
- Skjult
- højtydende
- højere
- hiking
- hans
- historie
- Hobbyer
- host
- hostede
- HOURS
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- KrammerFace
- Hyperparameter optimering
- Tuning af hyperparameter
- i
- identificere
- IDX
- if
- illustrere
- KIMOs Succeshistorier
- Påvirkninger
- gennemføre
- importere
- Forbedre
- forbedret
- forbedring
- in
- omfatter
- Forøg
- øget
- stigende
- oplysninger
- Infrastruktur
- indgang
- instans
- forekomster
- i stedet
- Intelligent
- ind
- IT
- ITS
- Job
- Karriere
- jpg
- json
- viden
- kendt
- Sprog
- stor
- storstilet
- største
- Latency
- lag
- lag
- Leads
- LÆR
- læring
- mindst
- lad
- biblioteker
- Bibliotek
- Line (linje)
- belastning
- log
- logning
- leder
- off
- tab
- lavere
- maskine
- machine learning
- vedligeholde
- opretholdelse
- mand
- lykkedes
- Marathon
- maske
- matplotlib
- maksimal
- Kan..
- betyder
- måle
- målt
- måling
- medicinsk
- Mød
- Hukommelse
- Metadata
- metoder
- metrisk
- Metrics
- måske
- minimere
- minutter
- ML
- model
- modellering
- modeller
- modulær
- mere
- bevæge sig
- meget
- flere
- skal
- navn
- Som hedder
- navne
- ved
- Natural
- Naturligt sprog
- Natural Language Processing
- Naviger
- Navigation
- nødvendig
- Behov
- behov
- behov
- netværk
- net
- Neural
- neurale netværk
- neurale netværk
- næste
- NLP
- Ingen
- Bemærk
- notesbog
- notesbøger
- nu
- nummer
- objekt
- objektiv
- målsætninger
- observere
- observeret
- of
- off
- tilbyde
- Tilbud
- on
- ONE
- online
- online forhandler
- kun
- åbent
- open source
- optimal
- optimering
- Optimer
- optimeret
- Optimerer
- optimering
- or
- ordrer
- original
- Andet
- vores
- ud
- output
- udgange
- i løbet af
- samlet
- oversigt
- egen
- par
- brød
- Parallel
- parameter
- parametre
- Pareto
- del
- Bestået
- sti
- patient
- mønstre
- udføre
- ydeevne
- udføres
- udfører
- udfører
- Tilladelser
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- punkter
- positioner
- Indlæg
- Precision
- forudsigelse
- forudsigende
- Predictor
- præferencer
- forberedt
- forudsætninger
- præsentere
- tidligere
- Main
- Problem
- behandle
- Procesautomatisering
- Processer
- forarbejdning
- Produkt
- produktivitet
- Produktivitetsværktøjer
- foreslog
- udbyder
- giver
- leverer
- trækker
- Sweatre & trøjer
- formål
- formål
- Python
- pytorch
- Spørgsmål og svar
- spørgsmål
- helt
- tilfældig
- rækkevidde
- hurtige
- priser
- Raw
- ægte
- anerkendelse
- genkende
- anerkende
- Anbefaling
- anbefalinger
- optage
- registreres
- Rød
- reducere
- Reduceret
- reducerer
- regression
- relaterede
- fjerner
- fjernelse
- Rapporter
- repræsentation
- anmode
- anmodet
- anmodninger
- påkrævet
- Krav
- elastisk
- ressource
- Ressourcer
- henholdsvis
- svar
- Resultater
- detailhandler
- tilbageholdende
- afkast
- ridning
- Risiko
- RÆKKE
- Kør
- runner
- kører
- løber
- s
- ofre
- sagemaker
- SageMaker Inference
- Gem
- Scale
- skalaer
- Videnskab
- Videnskabsmand
- score
- script
- Søg
- Søgemaskiner
- søgning
- Anden
- Sektion
- se
- Vælg
- valgt
- SELV
- send
- dømme
- stemningen
- Sequence
- tjeneste
- Tjenester
- Session
- sæt
- sæt
- indstilling
- Shows
- signaler
- betydeligt
- Simpelt
- samtidig
- samtidigt
- enkelt
- Størrelse
- mindre
- So
- Software
- løsninger
- Løsninger
- nogle
- Kilde
- Space
- Spawn
- specialiserede
- specialiseret
- specifikke
- specifikt
- udgifterne
- delt
- starte
- starter
- Tilstand
- statistik
- Trin
- Steps
- opbevaring
- strukturel
- struktureret
- Studio
- væsentlig
- vellykket
- Succesfuld
- sådan
- egnede
- suite
- RESUMÉ
- systemet
- Systemer
- T
- Tag
- tager
- mål
- Opgaver
- opgaver
- hold
- teknik
- teknikker
- skabeloner
- vilkår
- Test
- tests
- tekst
- Tekstklassificering
- tekstmæssige
- end
- at
- deres
- derefter
- Der.
- derfor
- Disse
- denne
- tre
- tærskel
- Gennem
- tid
- gange
- til
- sammen
- token
- tog
- værktøj
- værktøjer
- handle
- Trading
- Tog
- uddannet
- Kurser
- transformer
- transformers
- sand
- prøv
- to
- typen
- typer
- typisk
- typisk
- Ultimativt
- under
- undergår
- forståelse
- enheder
- us
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- bruger
- ved brug af
- validering
- værdi
- Værdier
- udgave
- via
- Virtual
- Visualiser
- vs
- ønsker
- var
- we
- web
- webservices
- GODT
- hvornår
- hvorvidt
- som
- mens
- WHO
- bred
- Bred rækkevidde
- bredt
- kone
- Wikipedia
- vilje
- villig
- med
- inden for
- Arbejde
- workflow
- arbejder
- X
- år
- Udbytte
- dig
- Din
- zephyrnet