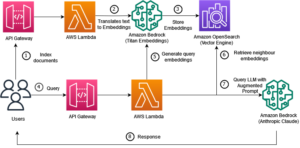
Med lanceringen af den neurale søgefunktion til Amazon OpenSearch Service i OpenSearch 2.9 er det nu nemt at integrere med AI/ML-modeller for at drive semantisk søgning og andre use cases. OpenSearch Service har understøttet både leksikalsk og vektorsøgning siden introduktionen af sin k-nearest neighbor (k-NN) funktion i 2020; konfiguration af semantisk søgning krævede dog opbygning af en ramme til at integrere maskinlæringsmodeller (ML) til at indtage og søge. Den neurale søgefunktion letter tekst-til-vektor-transformation under indtagelse og søgning. Når du bruger en neural forespørgsel under søgning, oversættes forespørgslen til en vektorindlejring, og k-NN bruges til at returnere de nærmeste vektorindlejringer fra korpuset.
For at bruge neural søgning skal du opsætte en ML-model. Vi anbefaler at konfigurere AI/ML-forbindelser til AWS AI- og ML-tjenester (såsom Amazon SageMaker or Amazonas grundfjeld) eller tredjepartsalternativer. Fra og med version 2.9 på OpenSearch Service integreres AI/ML-konnektorer med neural søgning for at forenkle og operationalisere oversættelsen af dit datakorpus og forespørgsler til vektorindlejringer og derved fjerne meget af kompleksiteten ved vektorhydrering og -søgning.
I dette indlæg demonstrerer vi, hvordan man konfigurerer AI/ML-stik til eksterne modeller gennem OpenSearch Service-konsollen.
Løsningsoversigt
Specifikt guider dette indlæg dig gennem oprettelse af forbindelse til en model i SageMaker. Derefter guider vi dig igennem at bruge connectoren til at konfigurere semantisk søgning på OpenSearch Service som et eksempel på en use case, der understøttes gennem tilslutning til en ML-model. Amazon Bedrock og SageMaker-integrationer understøttes i øjeblikket på OpenSearch Service-konsollens UI, og listen over UI-understøttede første- og tredjepartsintegrationer vil fortsætte med at vokse.
For modeller, der ikke understøttes via brugergrænsefladen, kan du i stedet konfigurere dem ved hjælp af de tilgængelige API'er og ML tegninger. For mere information, se Introduktion til OpenSearch-modeller. Du kan finde tegninger for hvert stik i ML Commons GitHub-depot.
Forudsætninger
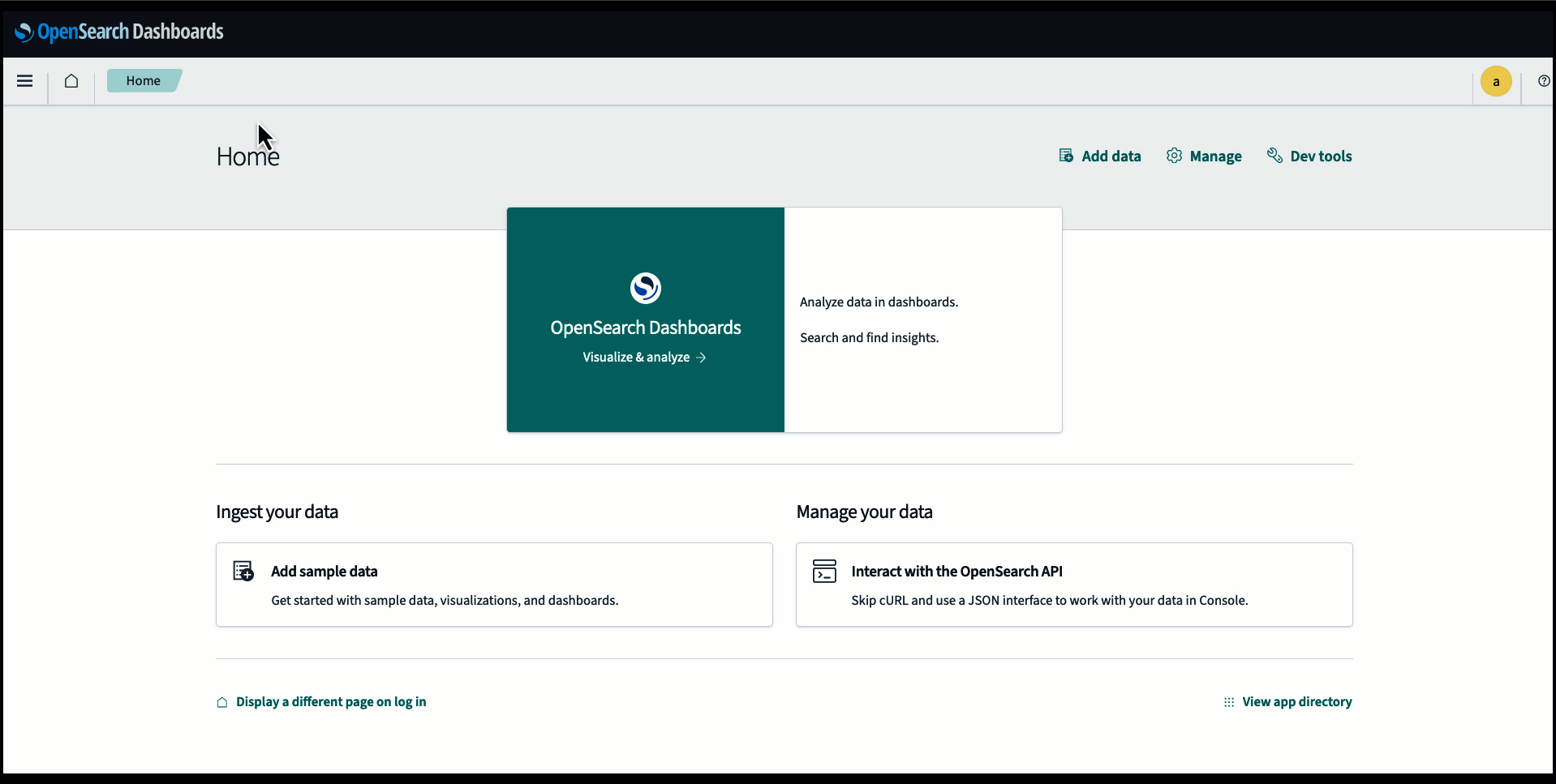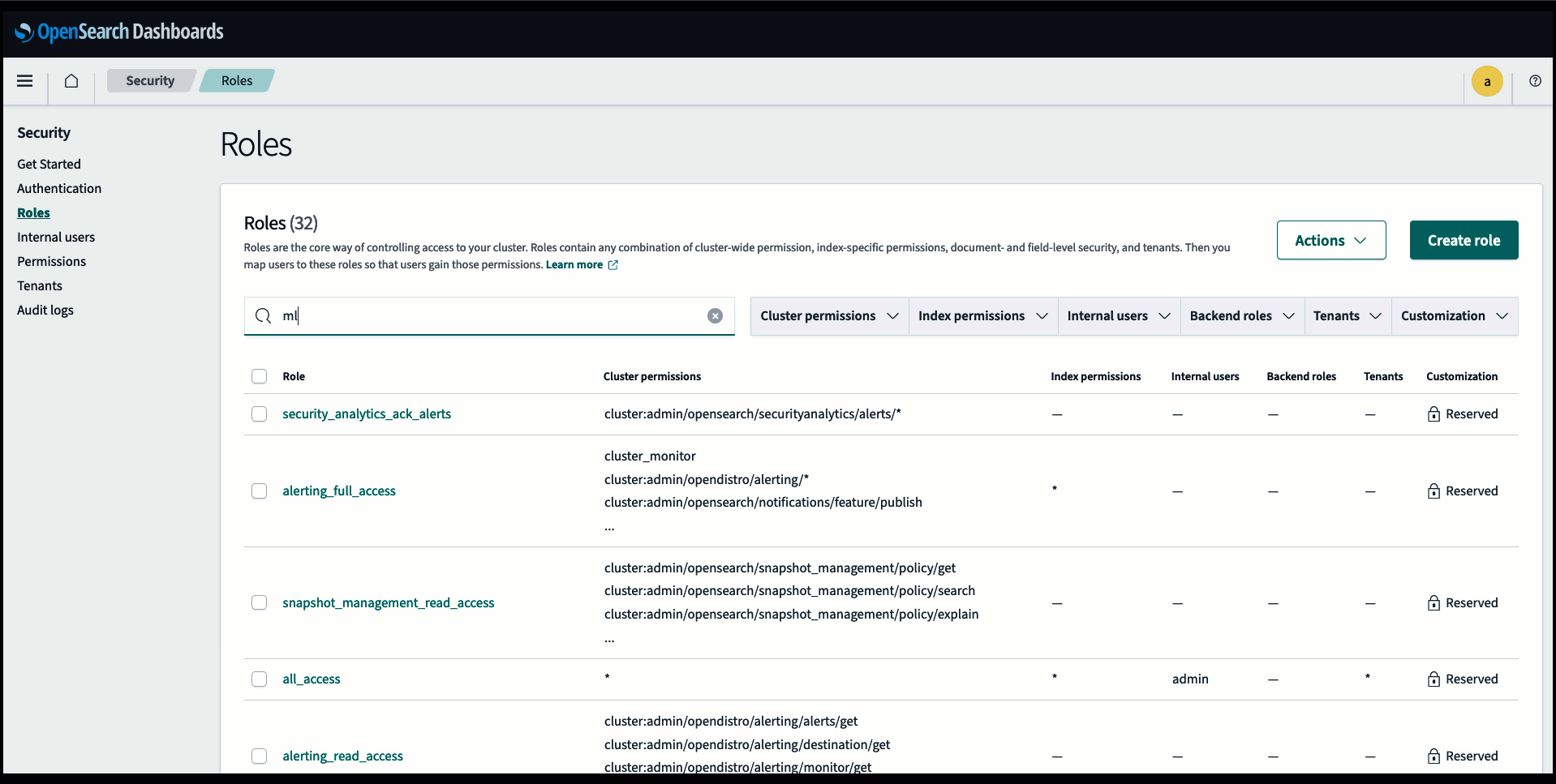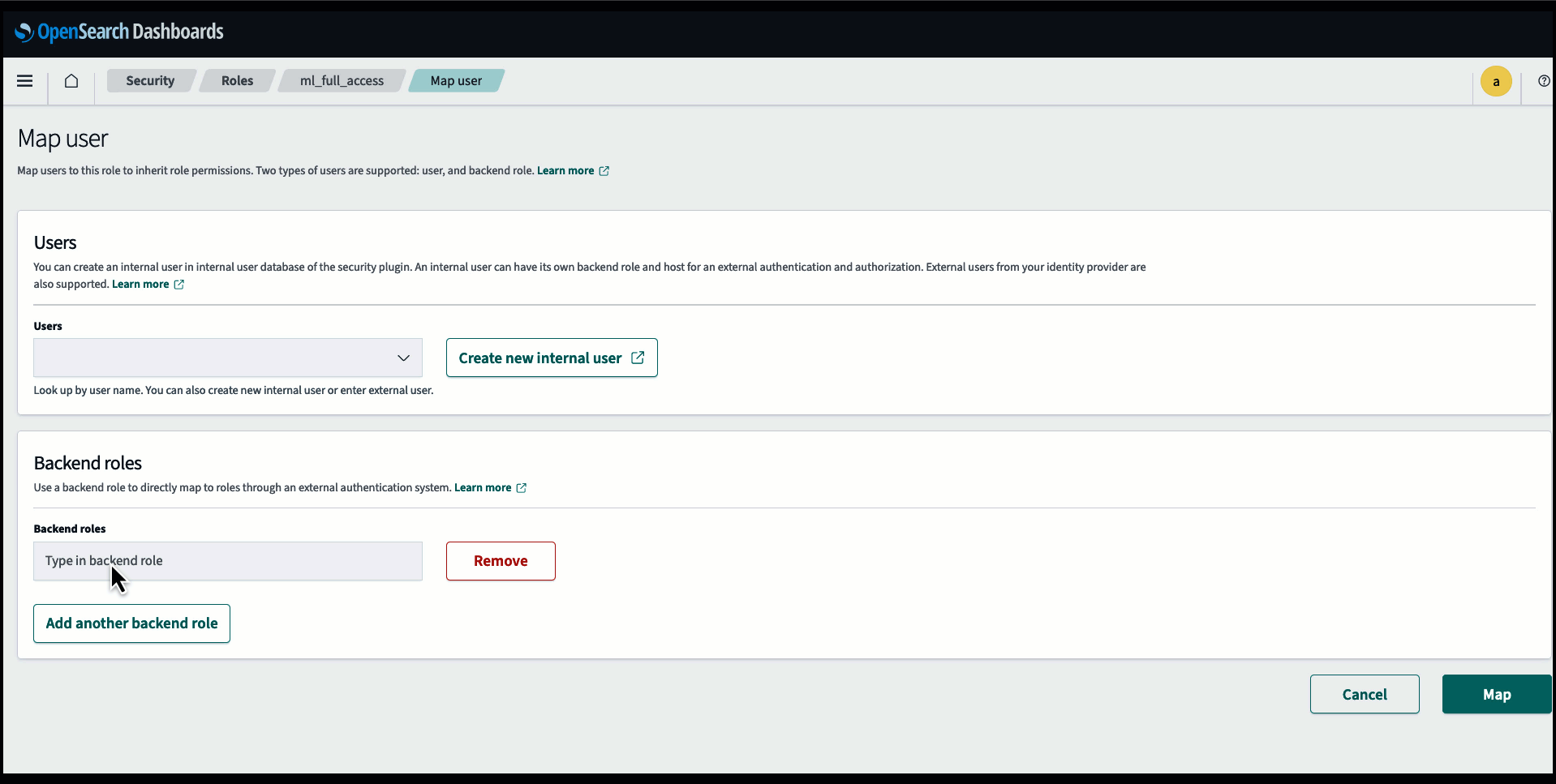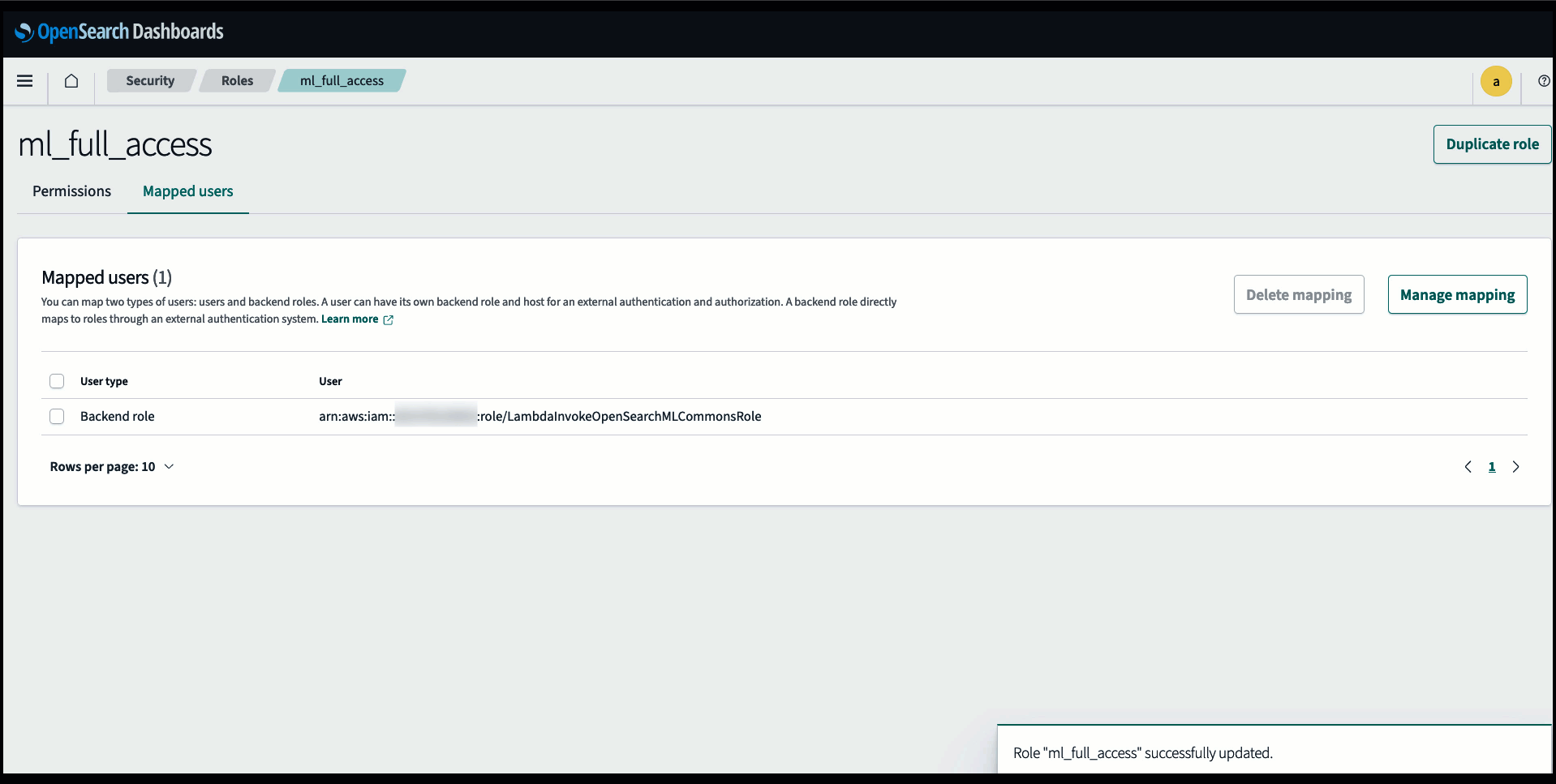
Før du forbinder modellen via OpenSearch Service-konsollen, skal du oprette et OpenSearch Service-domæne. Kort en AWS identitets- og adgangsstyring (IAM) rolle ved navn LambdaInvokeOpenSearchMLCommonsRole som backend-rolle på ml_full_access rolle ved hjælp af sikkerhedspluginnet på OpenSearch Dashboards, som vist i den følgende video. OpenSearch Service integrations workflowet er udfyldt for at bruge LambdaInvokeOpenSearchMLCommonsRole IAM-rolle som standard for at skabe forbindelsen mellem OpenSearch Service-domænet og modellen implementeret på SageMaker. Hvis du bruger en tilpasset IAM-rolle på OpenSearch Service-konsolintegreringerne, skal du sørge for, at den tilpassede rolle er kortlagt som backend-rollen med ml_full_access tilladelser før implementering af skabelonen.
Implementer modellen ved hjælp af AWS CloudFormation
Den følgende video demonstrerer trinene til at bruge OpenSearch Service-konsollen til at implementere en model inden for få minutter på Amazon SageMaker og generere model-id'et via AI-forbindelserne. Det første skridt er at vælge integrationer i navigationsruden på OpenSearch Service AWS-konsollen, som leder til en liste over tilgængelige integrationer. Integrationen sættes op gennem en brugergrænseflade, som vil bede dig om de nødvendige input.
For at konfigurere integrationen behøver du kun at angive OpenSearch Service-domæneslutpunktet og angive et modelnavn til entydigt at identificere modelforbindelsen. Som standard implementerer skabelonen Hugging Face-sætningstransformere-modellen, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Når du vælger Opret stak, bliver du dirigeret til AWS CloudFormation konsol. CloudFormation-skabelonen implementerer arkitekturen beskrevet i det følgende diagram.

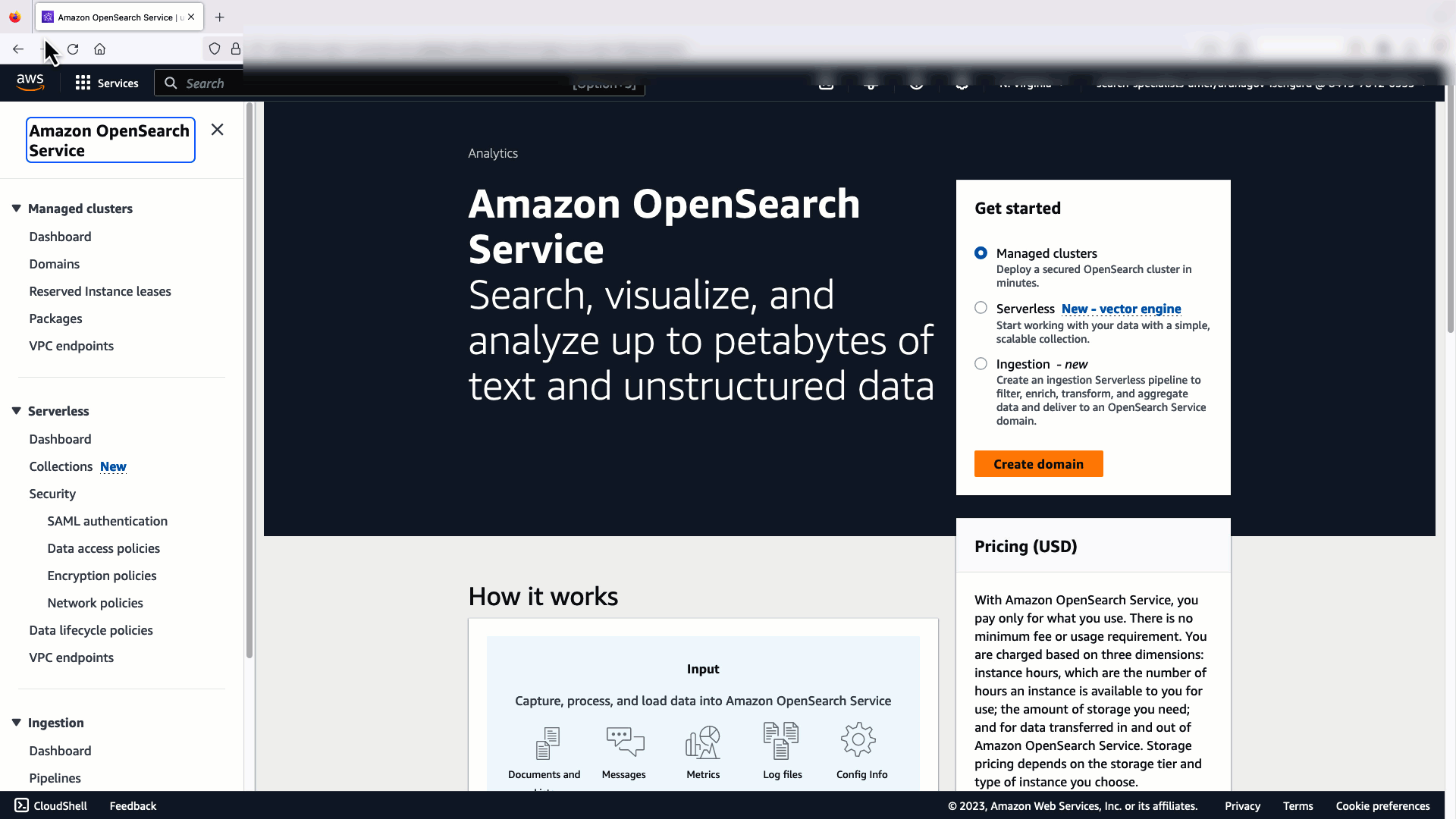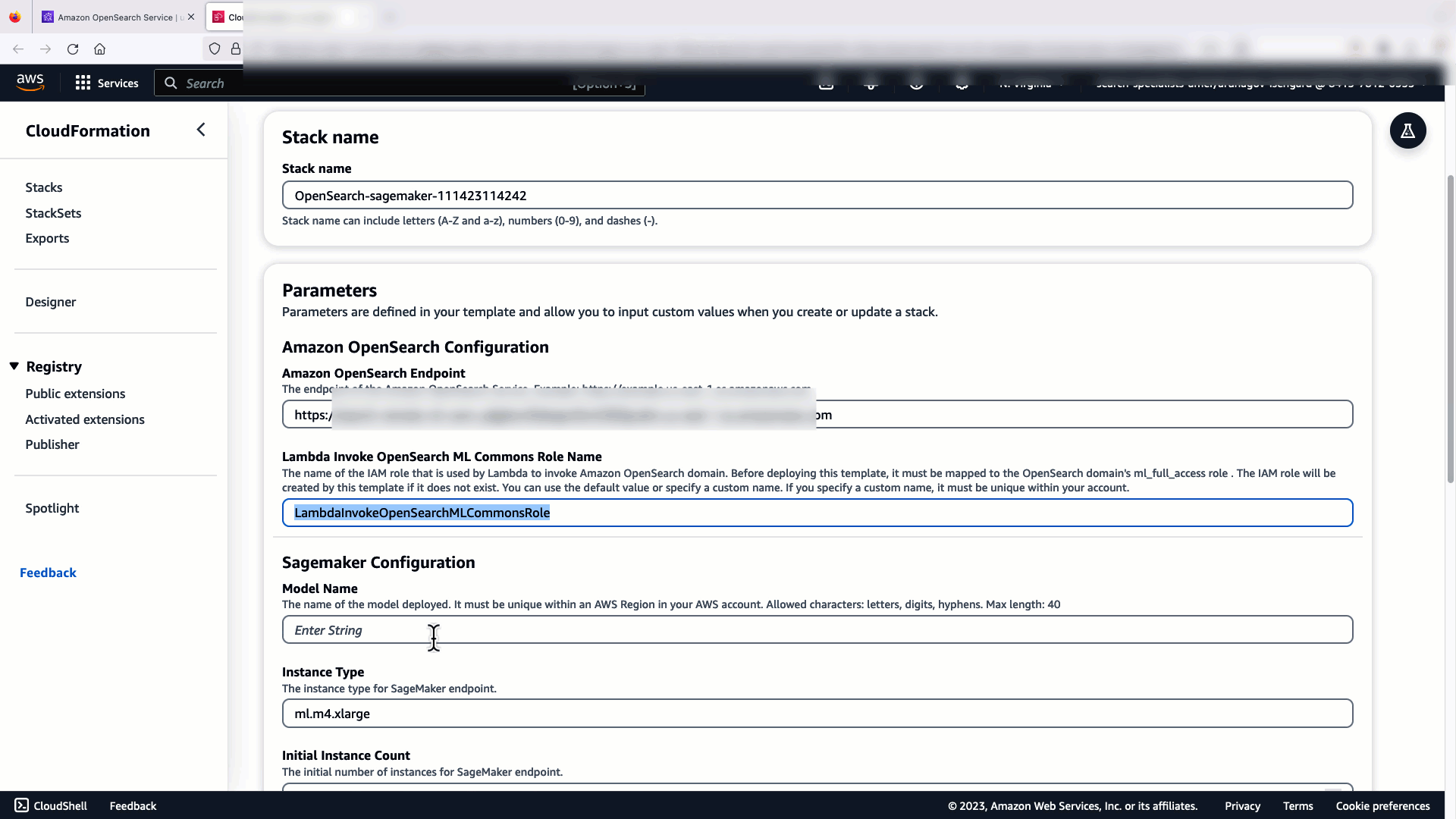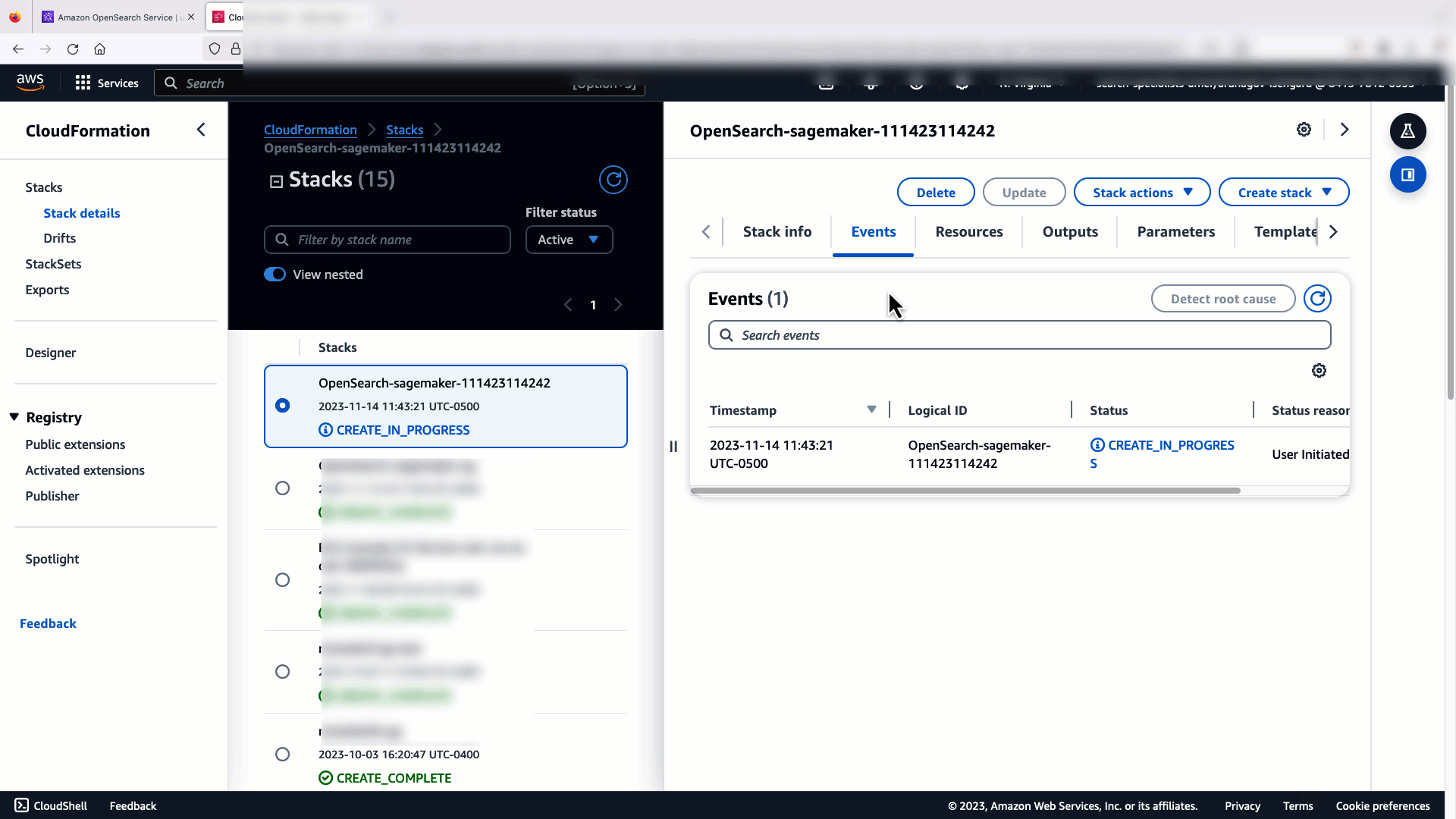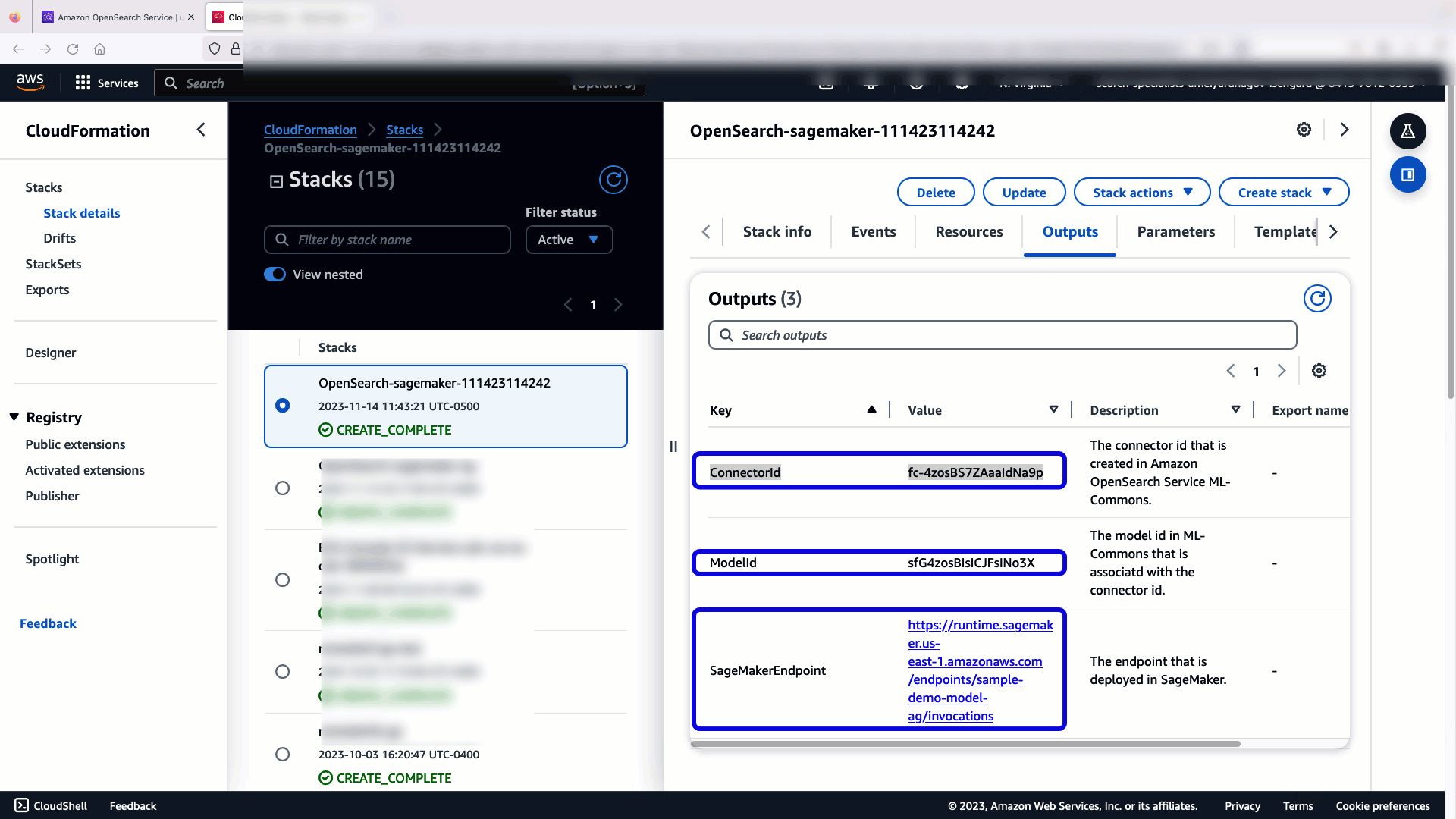
CloudFormation-stakken opretter en AWS Lambda applikation, der implementerer en model fra Amazon Simple Storage Service (Amazon S3), opretter stikket og genererer model-id'et i outputtet. Du kan derefter bruge dette model-id til at oprette et semantisk indeks.
Hvis standard all-MiniLM-L6-v2-modellen ikke tjener dit formål, kan du implementere enhver tekstindlejringsmodel efter eget valg på den valgte modelvært (SageMaker eller Amazon Bedrock) ved at levere dine modelartefakter som et tilgængeligt S3-objekt. Alternativt kan du vælge en af følgende fortrænede sprogmodeller og implementer det til SageMaker. For instruktioner til opsætning af dit slutpunkt og dine modeller, se Tilgængelige Amazon SageMaker-billeder.
SageMaker er en fuldt administreret tjeneste, der samler et bredt sæt af værktøjer til at muliggøre højtydende, lavpris ML til enhver brug, og leverer nøglefordele såsom modelovervågning, serverløs hosting og workflowautomatisering til kontinuerlig træning og implementering. SageMaker giver dig mulighed for at hoste og administrere livscyklussen for tekstindlejringsmodeller og bruge dem til at drive semantiske søgeforespørgsler i OpenSearch Service. Når du er tilsluttet, hoster SageMaker dine modeller, og OpenSearch Service bruges til at forespørge baseret på konklusioner fra SageMaker.
Se den implementerede model gennem OpenSearch Dashboards
For at bekræfte, at CloudFormation-skabelonen har implementeret modellen på OpenSearch Service-domænet og få model-id'et, kan du bruge ML Commons REST GET API gennem OpenSearch Dashboards Dev Tools.
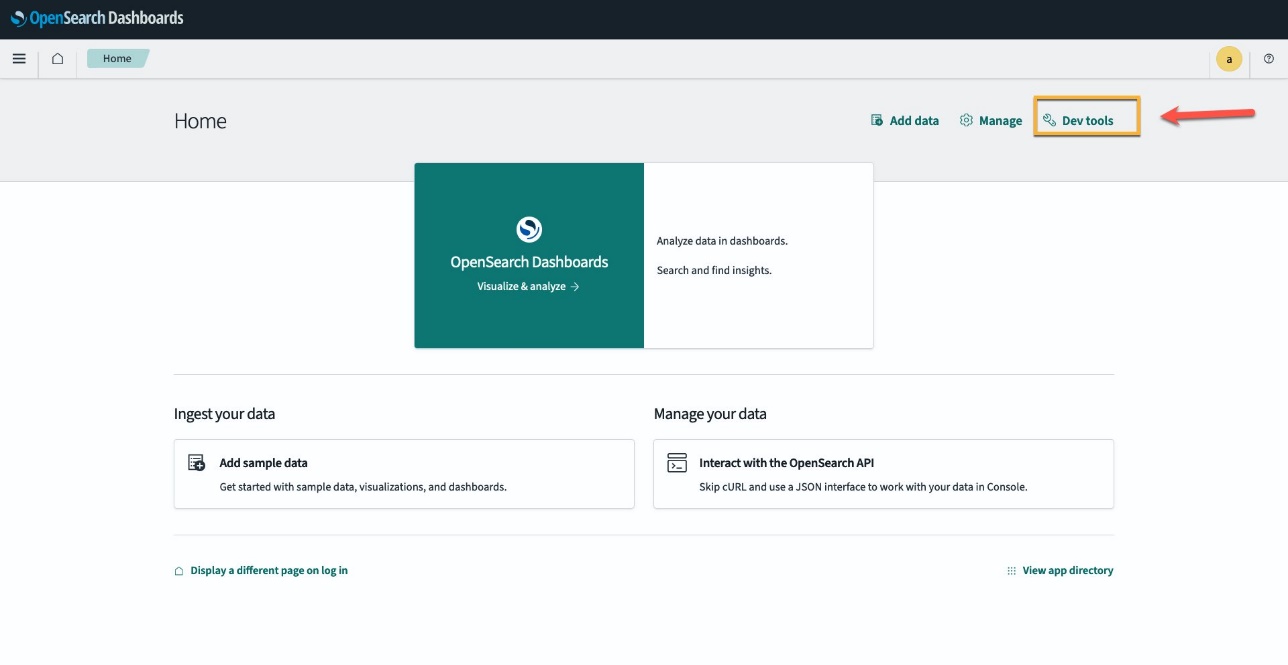
GET _plugins REST API giver nu yderligere API'er for også at se modelstatus. Følgende kommando giver dig mulighed for at se status for en ekstern model:
Som vist på det følgende skærmbillede, a DEPLOYED status i svaret angiver, at modellen er implementeret med succes på OpenSearch Service-klyngen.

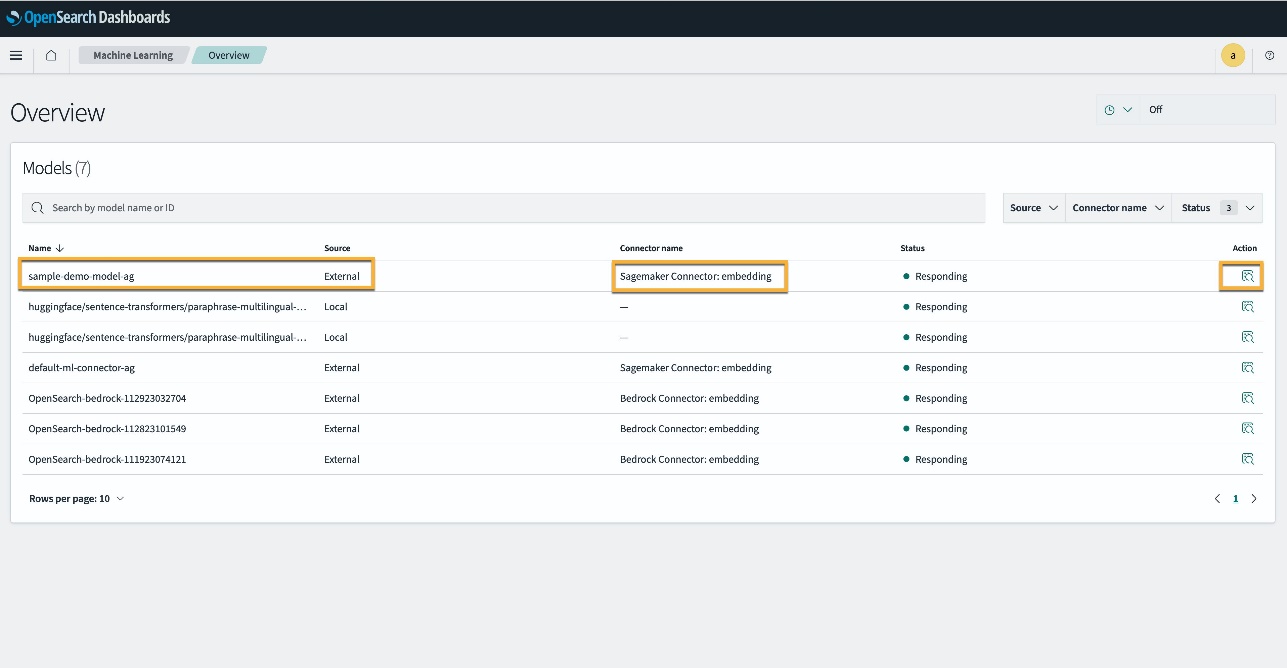
Alternativt kan du se modellen implementeret på dit OpenSearch Service-domæne ved hjælp af Maskinelæring side af OpenSearch Dashboards.

Denne side viser modeloplysningerne og statusserne for alle de installerede modeller.

Opret den neurale pipeline ved hjælp af model-id'et
Når modellens status vises som enten DEPLOYED i Dev Tools eller grøn og Reaktion i OpenSearch Dashboards kan du bruge model-id'et til at bygge din neurale indtagelsespipeline. Følgende indlæsningspipeline køres i dit domænes OpenSearch Dashboards Dev Tools. Sørg for at erstatte model-id'et med det unikke id, der er genereret for den model, der er implementeret på dit domæne.

Opret det semantiske søgeindeks ved at bruge den neurale pipeline som standardpipeline
Du kan nu definere din indekskortlægning med standardpipeline konfigureret til at bruge den nye neurale pipeline, du oprettede i det forrige trin. Sørg for, at vektorfelterne er erklæret som knn_vector og dimensionerne er passende til den model, der er implementeret på SageMaker. Hvis du har bevaret standardkonfigurationen til at implementere All-MiniLM-L6-v2-modellen på SageMaker, skal du beholde følgende indstillinger, som de er, og køre kommandoen i Dev Tools.

Indtag prøvedokumenter for at generere vektorer
Til denne demo kan du indtage prøve detaildemostore produktkatalog til den nye semantic_demostore indeks. Erstat brugernavnet, adgangskoden og domæneslutpunktet med dine domæneoplysninger, og indtag rådata i OpenSearch Service:

Valider det nye semantiske_demostore-indeks
Nu hvor du har indlæst dit datasæt til OpenSearch Service-domænet, skal du validere, om de påkrævede vektorer er genereret ved hjælp af en simpel søgning for at hente alle felter. Valider hvis felterne defineret som knn_vectors har de nødvendige vektorer.

Sammenlign leksikalsk søgning og semantisk søgning drevet af neural søgning ved hjælp af værktøjet Sammenlign søgeresultater
Værktøjet Sammenlign søgeresultater på OpenSearch Dashboards er tilgængelig for produktionsarbejdsbelastninger. Du kan navigere til Sammenlign søgeresultater side og sammenligne forespørgselsresultater mellem leksikalsk søgning og neural søgning konfigureret til at bruge det model-id, der blev genereret tidligere.

Ryd op
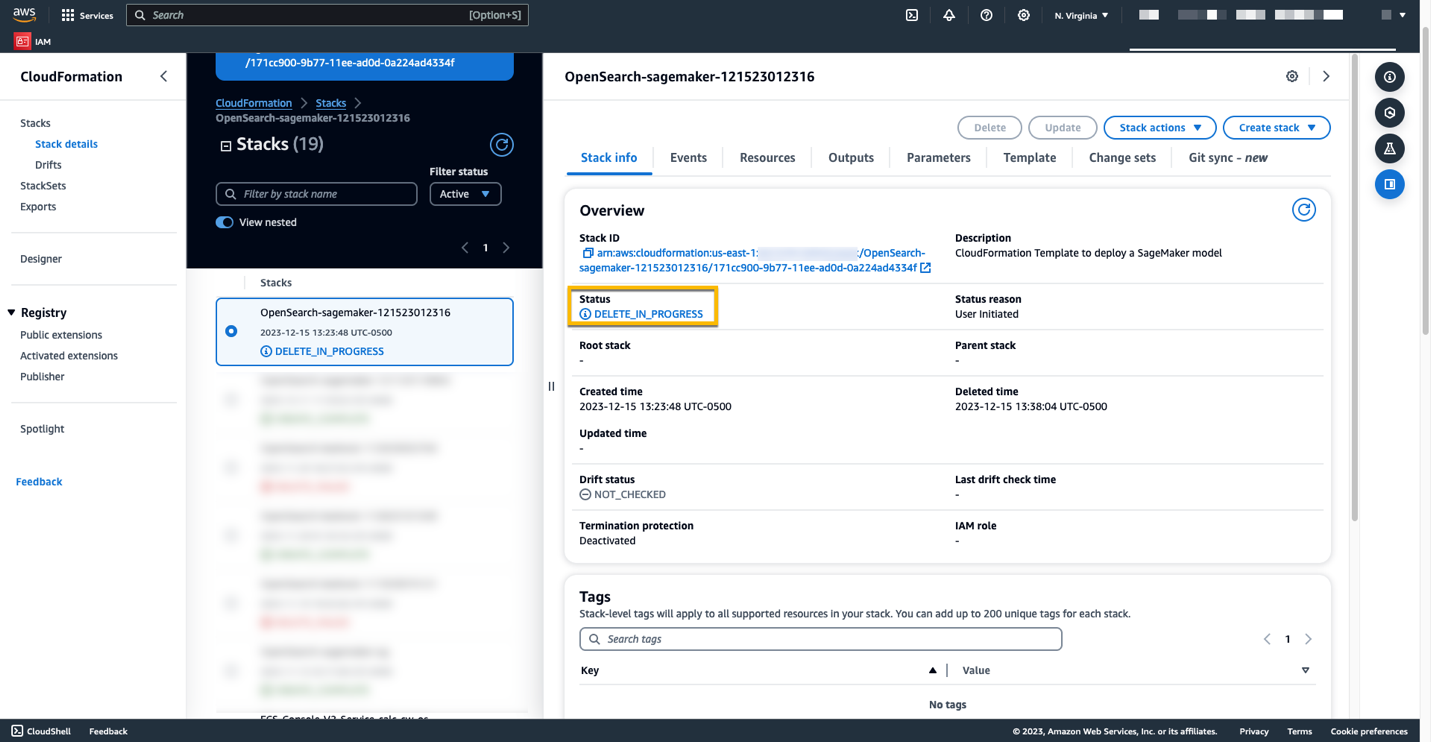
Du kan slette de ressourcer, du har oprettet ved at følge instruktionerne i dette indlæg, ved at slette CloudFormation-stakken. Dette vil slette Lambda-ressourcerne og S3-bøtten, der indeholder den model, der blev implementeret til SageMaker. Udfør følgende trin:
- På AWS CloudFormation-konsollen skal du navigere til siden med stakdetaljer.
- Vælg Slette.

- Vælg Slette at bekræfte.

Du kan overvåge stakkens sletning på AWS CloudFormation-konsollen.
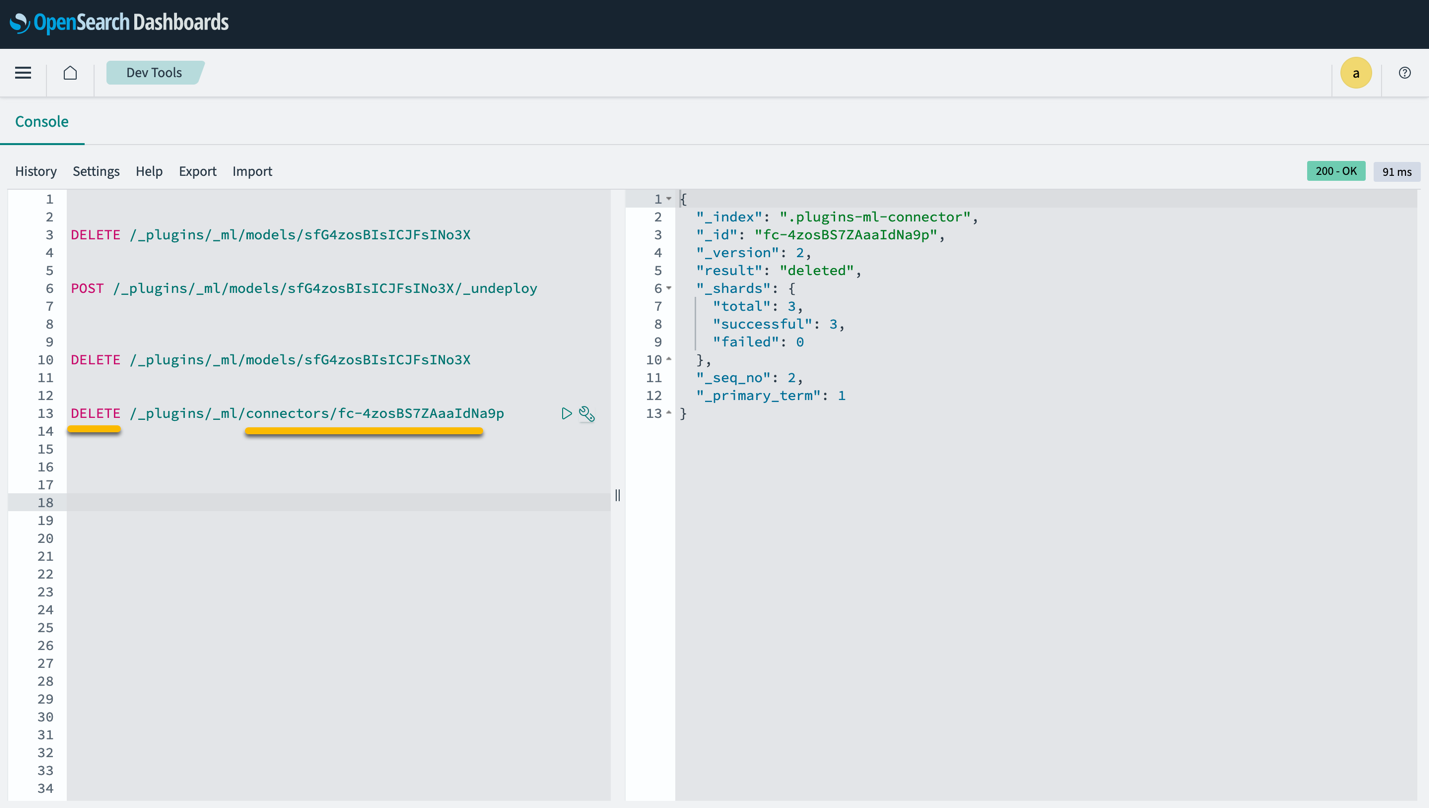
Bemærk, at sletning af CloudFormation-stakken ikke sletter den model, der er installeret på SageMaker-domænet og den oprettede AI/ML-connector. Dette skyldes, at disse modeller og stikket kan associeres med flere indekser inden for domænet. For specifikt at slette en model og dens tilknyttede forbindelse, skal du bruge model-API'erne som vist på de følgende skærmbilleder.
First, undeploy modellen fra OpenSearch Service domænehukommelsen:

Derefter kan du slette modellen fra modelindekset:

Til sidst skal du slette forbindelsen fra forbindelsesindekset:
Konklusion
I dette indlæg lærte du, hvordan du implementerer en model i SageMaker, opretter AI/ML-forbindelsen ved hjælp af OpenSearch Service-konsollen og bygger det neurale søgeindeks. Muligheden for at konfigurere AI/ML-forbindelser i OpenSearch Service forenkler vektorhydreringsprocessen ved at gøre integrationerne til eksterne modeller native. Du kan oprette et neuralt søgeindeks på få minutter ved hjælp af den neurale indtagelsespipeline og den neurale søgning, der bruger model-id'et til at generere vektorindlejring i farten under indtagelse og søgning.
For at lære mere om disse AI/ML-stik, se Amazon OpenSearch Service AI-stik til AWS-tjenester, AWS CloudFormation skabelonintegrationer til semantisk søgningog Oprettelse af connectors til tredjeparts ML-platforme.
Om forfatterne
 Aruna Govindaraju er en Amazon OpenSearch Specialist Solutions Architect og har arbejdet med mange kommercielle og open source søgemaskiner. Hun brænder for søgning, relevans og brugeroplevelse. Hendes ekspertise med at korrelere slutbrugersignaler med søgemaskineadfærd har hjulpet mange kunder med at forbedre deres søgeoplevelse.
Aruna Govindaraju er en Amazon OpenSearch Specialist Solutions Architect og har arbejdet med mange kommercielle og open source søgemaskiner. Hun brænder for søgning, relevans og brugeroplevelse. Hendes ekspertise med at korrelere slutbrugersignaler med søgemaskineadfærd har hjulpet mange kunder med at forbedre deres søgeoplevelse.
 Dagney Braun er en hovedproduktchef hos AWS med fokus på OpenSearch.
Dagney Braun er en hovedproduktchef hos AWS med fokus på OpenSearch.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :har
- :er
- :ikke
- $OP
- 1
- 100
- 12
- 15 %
- 2020
- 25
- 7
- 8
- 9
- a
- evne
- Om
- adgang
- tilgængelig
- Yderligere
- AI
- AI / ML
- Alle
- tillader
- også
- alternativer
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- ,
- enhver
- api
- API'er
- Anvendelse
- passende
- arkitektur
- ER
- AS
- forbundet
- At
- Automation
- til rådighed
- AWS
- AWS CloudFormation
- Bagende
- baseret
- BE
- fordi
- adfærd
- fordele
- mellem
- både
- Bringer
- bred
- bygge
- Bygning
- by
- CAN
- tilfælde
- tilfælde
- katalog
- valg
- Vælg
- valgt
- Cluster
- kommerciel
- Commons
- sammenligne
- fuldføre
- kompleksitet
- Konfiguration
- konfigureret
- konfigurering
- Bekræfte
- tilsluttet
- Tilslutning
- tilslutning
- Konsol
- indeholder
- fortsæt
- kontinuerlig
- korrelere
- skabe
- oprettet
- skaber
- For øjeblikket
- skik
- Kunder
- dashboards
- data
- Standard
- definere
- definerede
- leverer
- Demo
- demonstrere
- demonstrerer
- indsætte
- indsat
- implementering
- implementering
- udruller
- beskrivelse
- detaljeret
- detaljer
- dev
- Dimension
- størrelse
- dokumenter
- Er ikke
- domæne
- i løbet af
- hver
- tidligere
- nemt
- enten
- indlejring
- muliggøre
- Endpoint
- Engine (Motor)
- Motorer
- sikre
- Ether (ETH)
- eksempel
- erfaring
- ekspertise
- ekstern
- Ansigtet
- letter
- Feature
- Fields
- Finde
- Fornavn
- fokuserede
- efter
- Til
- Framework
- fra
- fuldt ud
- generere
- genereret
- genererer
- få
- gif
- GitHub
- Grøn
- Grow
- vejlede
- Have
- hjulpet
- hende
- Høj ydeevne
- host
- Hosting
- værter
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- KrammerFace
- hydrering
- IAM
- ID
- identificere
- Identity
- if
- Forbedre
- in
- indeks
- indekser
- angiver
- oplysninger
- indgange
- i stedet
- anvisninger
- integrere
- integration
- integrationer
- ind
- Introduktion
- IT
- ITS
- jpg
- json
- Holde
- Nøgle
- Sprog
- lancere
- LÆR
- lærte
- læring
- livscyklus
- Liste
- Lister
- lave omkostninger
- maskine
- machine learning
- lave
- Making
- administrere
- lykkedes
- leder
- mange
- kort
- kortlægning
- Hukommelse
- metode
- minutter
- ML
- model
- modeller
- Overvåg
- overvågning
- mere
- meget
- flere
- skal
- navn
- indfødte
- Naviger
- Navigation
- nødvendig
- Behov
- Neural
- Ny
- nu
- objekt
- of
- on
- ONE
- kun
- åbent
- open source
- or
- Andet
- output
- side
- brød
- lidenskabelige
- Adgangskode
- Tilladelser
- pipeline
- plato
- Platon Data Intelligence
- PlatoData
- plugin
- Indlæg
- magt
- strøm
- tidligere
- Main
- Forud
- behandle
- processorer
- Produkt
- produktchef
- produktion
- Progress
- egenskaber
- give
- giver
- leverer
- formål
- forespørgsler
- Raw
- rådata
- anbefaler
- henvise
- fjern
- fjernelse
- erstatte
- påkrævet
- Ressourcer
- svar
- REST
- Resultater
- detail
- bevaret
- afkast
- roller
- veje
- Kør
- sagemaker
- screenshots
- Søg
- søgemaskine
- Søgemaskiner
- sikkerhed
- se
- Vælg
- tjener
- Serverless
- tjeneste
- Tjenester
- sæt
- indstillinger
- hun
- vist
- Shows
- signaler
- Simpelt
- forenkler
- forenkle
- siden
- Løsninger
- Kilde
- specialist
- specifikt
- stable
- Starter
- Status
- Trin
- Steps
- opbevaring
- Succesfuld
- sådan
- Understøttet
- sikker
- skabelon
- tekst
- at
- deres
- Them
- derefter
- derved
- Disse
- tredjepart
- denne
- Gennem
- til
- sammen
- værktøjer
- Kurser
- Transformation
- Oversættelse
- sand
- typen
- ui
- enestående
- entydigt
- brug
- brug tilfælde
- anvendte
- Bruger
- Brugererfaring
- ved brug af
- VALIDATE
- verificere
- udgave
- via
- video
- Specifikation
- gåture
- var
- we
- web
- webservices
- hvornår
- som
- vilje
- med
- inden for
- arbejdede
- workflow
- Workflow automation
- dig
- Din
- zephyrnet