Et af de mest nyttige applikationsmønstre til generative AI-arbejdsbelastninger er Retrieval Augmented Generation (RAG). I RAG-mønsteret finder vi stykker af referenceindhold relateret til en inputprompt ved at udføre lighedssøgninger på indlejringer. Indlejringer fanger informationsindholdet i tekster, hvilket gør det muligt for NLP-modeller (natural language processing) at arbejde med sprog i en numerisk form. Indlejringer er blot vektorer af flydende kommatal, så vi kan analysere dem for at hjælpe med at besvare tre vigtige spørgsmål: Ændrer vores referencedata sig over tid? Ændrer de spørgsmål, brugerne stiller sig over tid? Og endelig, hvor godt dækker vores referencedata de spørgsmål, der stilles?
I dette indlæg lærer du om nogle af overvejelserne ved indlejring af vektoranalyse og detektering af signaler om indlejringsdrift. Fordi indlejringer er en vigtig kilde til data for NLP-modeller generelt og generative AI-løsninger i særdeleshed, har vi brug for en måde at måle, om vores indlejringer ændrer sig over tid (drift). I dette indlæg vil du se et eksempel på at udføre driftdetektion på indlejringsvektorer ved hjælp af en klyngeteknik med store sprogmodeller (LLMS) implementeret fra Amazon SageMaker JumpStart. Du vil også være i stand til at udforske disse begreber gennem to medfølgende eksempler, herunder en ende-til-ende prøveapplikation eller eventuelt en undergruppe af applikationen.
Oversigt over RAG
RAG mønster lader dig hente viden fra eksterne kilder, såsom PDF-dokumenter, wiki-artikler eller opkaldsudskrifter, og derefter bruge denne viden til at udvide instruktionsprompten, der sendes til LLM. Dette gør det muligt for LLM at henvise til mere relevant information, når den genererer et svar. For eksempel, hvis du spørger en LLM, hvordan man laver chokoladekager, kan det indeholde oplysninger fra dit eget opskriftsbibliotek. I dette mønster konverteres opskriftsteksten til indlejringsvektorer ved hjælp af en indlejringsmodel og gemmes i en vektordatabase. Indgående spørgsmål konverteres til indlejringer, og derefter kører vektordatabasen en lighedssøgning for at finde relateret indhold. Spørgsmålet og referencedataene går derefter ind i prompten til LLM.
Lad os se nærmere på de indlejringsvektorer, der bliver skabt, og hvordan man udfører driftanalyse på disse vektorer.
Analyse af indlejringsvektorer
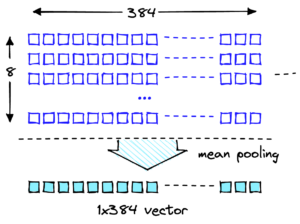
Indlejringsvektorer er numeriske repræsentationer af vores data, så analyse af disse vektorer kan give indsigt i vores referencedata, som senere kan bruges til at detektere potentielle signaler om drift. Indlejringsvektorer repræsenterer et element i n-dimensionelt rum, hvor n ofte er stort. For eksempel skaber GPT-J 6B-modellen, brugt i dette indlæg, vektorer af størrelse 4096. For at måle drift skal du antage, at vores applikation fanger indlejringsvektorer for både referencedata og indgående prompter.
Vi starter med at udføre dimensionsreduktion ved hjælp af Principal Component Analysis (PCA). PCA forsøger at reducere antallet af dimensioner og samtidig bevare det meste af variansen i dataene. I dette tilfælde forsøger vi at finde antallet af dimensioner, der bevarer 95 % af variansen, hvilket burde fange alt inden for to standardafvigelser.
Derefter bruger vi K-Means til at identificere et sæt klyngecentre. K-Means forsøger at gruppere punkter i klynger, således at hver klynge er relativt kompakt, og klyngerne er så fjerne fra hinanden som muligt.
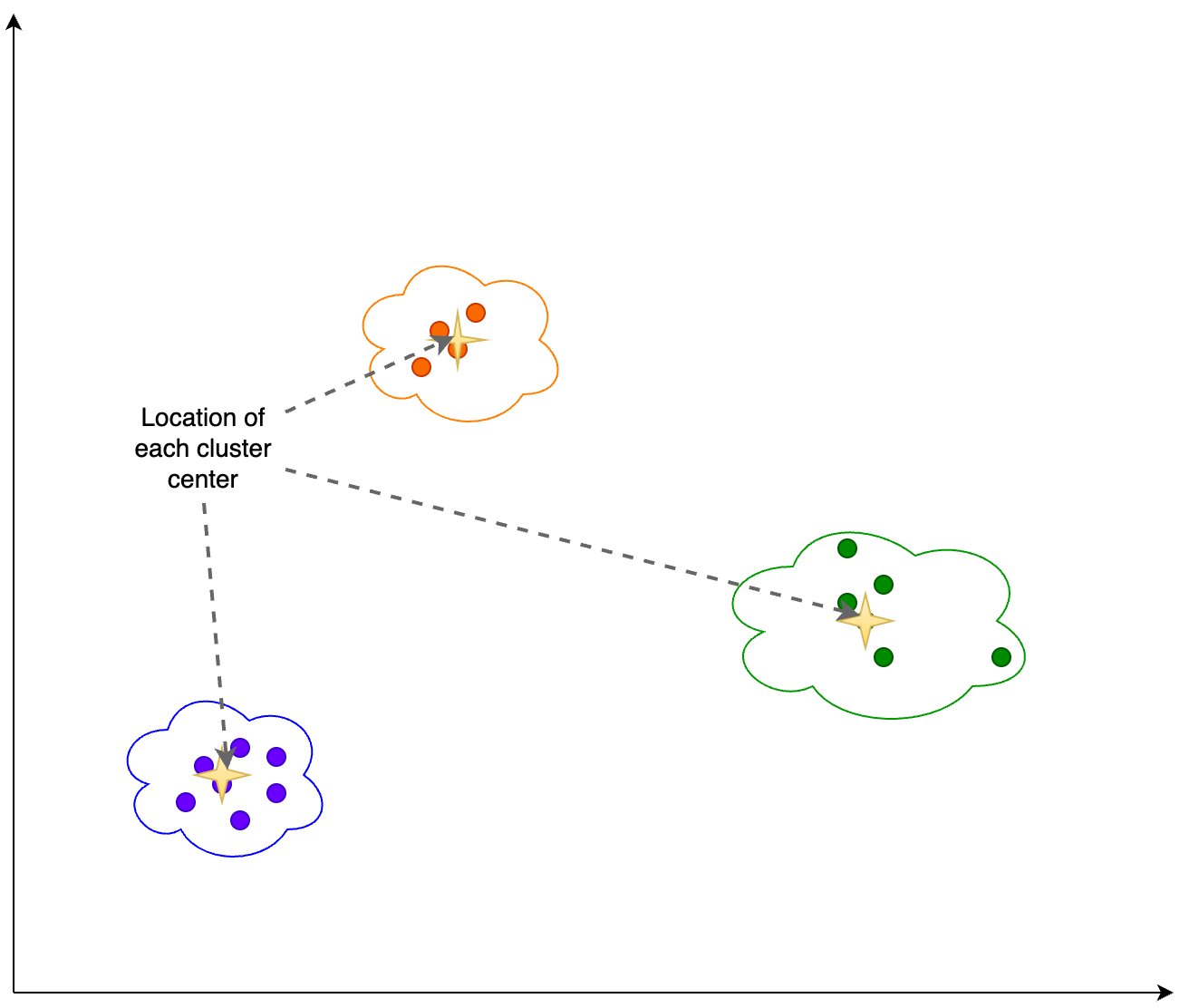
Vi beregner følgende information baseret på klyngeoutput vist i følgende figur:
- Antallet af dimensioner i PCA, der forklarer 95 % af variansen
- Placeringen af hvert klyngecenter eller tyngdepunkt
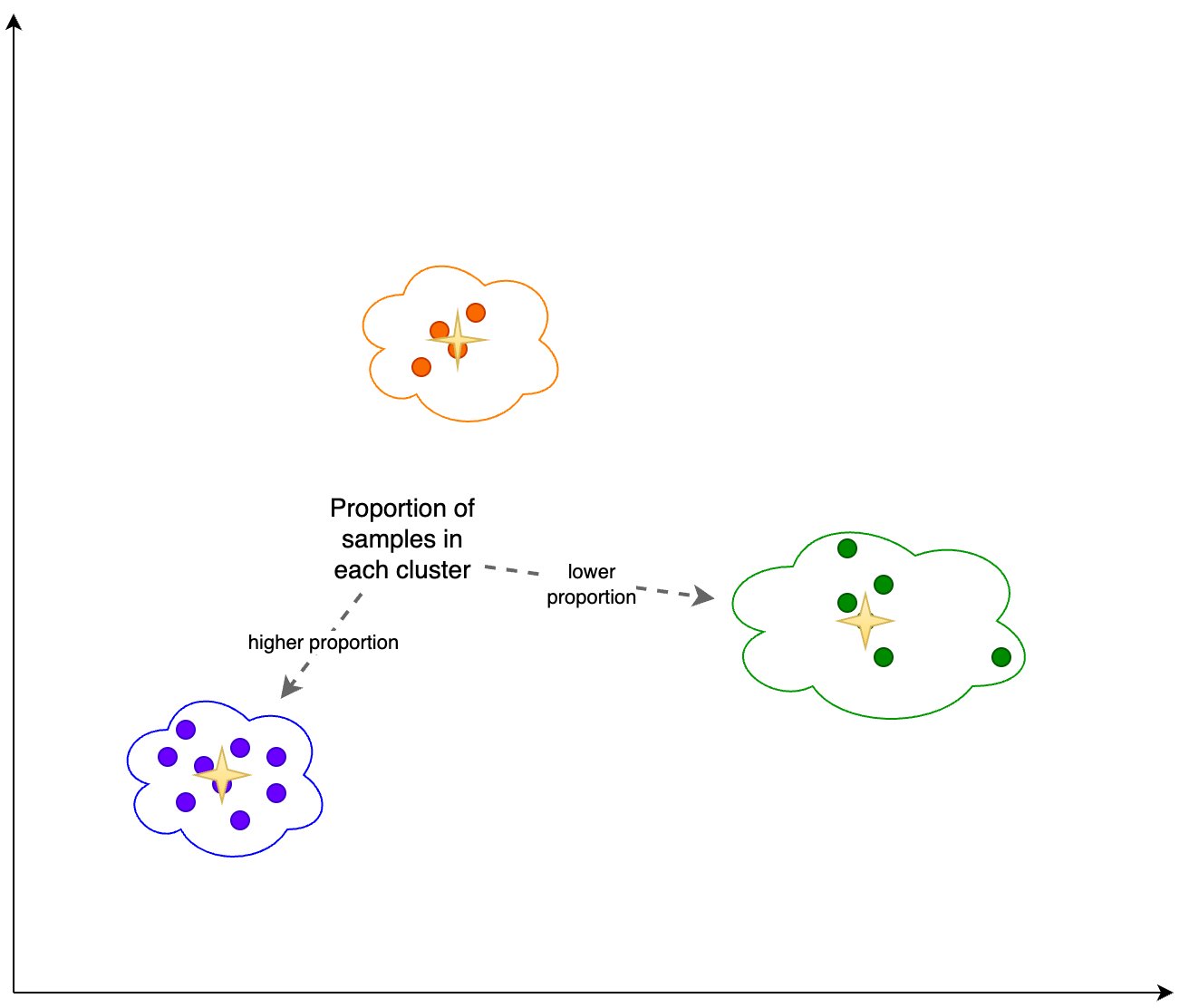
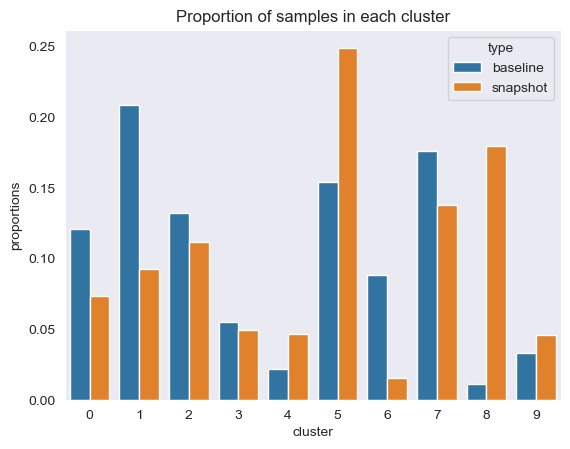
Derudover ser vi på andelen (højere eller lavere) af prøver i hver klynge, som vist i den følgende figur.
Til sidst bruger vi denne analyse til at beregne følgende:
- inerti - Inerti er summen af kvadrerede afstande til klyngecentroider, som måler, hvor godt dataene blev grupperet ved hjælp af K-Means.
- Silhouette score – Silhouette-scoren er et mål for validering af konsistensen inden for klynger og går fra -1 til 1. En værdi tæt på 1 betyder, at punkterne i en klynge er tæt på de andre punkter i samme klynge og langt fra punkter i de andre klynger. En visuel repræsentation af silhuetpartituret kan ses i den følgende figur.

Vi kan med jævne mellemrum fange disse oplysninger til snapshots af indlejringerne for både kildereferencedata og prompter. Indfangning af disse data giver os mulighed for at analysere potentielle signaler om indlejringsdrift.
Registrerer indlejringsdrift
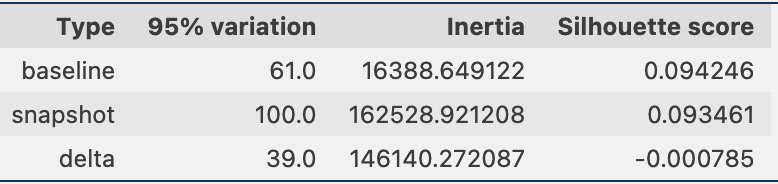
Med jævne mellemrum kan vi sammenligne klyngeinformationen gennem snapshots af dataene, som inkluderer referencedataindlejringer og promptindlejringer. Først kan vi sammenligne antallet af dimensioner, der er nødvendige for at forklare 95 % af variationen i indlejringsdata, inerti og silhuet-score fra klyngeopgaven. Som du kan se i følgende tabel, sammenlignet med en basislinje, kræver det seneste øjebliksbillede af indlejringer 39 flere dimensioner for at forklare variansen, hvilket indikerer, at vores data er mere spredt. Trægheden er steget, hvilket indikerer, at prøverne er samlet længere væk fra deres klyngecentre. Derudover er silhuetresultatet faldet, hvilket indikerer, at klyngerne ikke er så veldefinerede. For hurtige data kan det indikere, at de typer spørgsmål, der kommer ind i systemet, dækker flere emner.
Dernæst kan vi i den følgende figur se, hvordan andelen af prøver i hver klynge har ændret sig over tid. Dette kan vise os, om vores nyere referencedata stort set ligner det tidligere sæt eller dækker nye områder.
Endelig kan vi se, om klyngecentrene bevæger sig, hvilket ville vise drift i informationen i klyngene, som vist i følgende tabel.

Referencedatadækning for indgående spørgsmål
Vi kan også vurdere, hvor godt vores referencedata stemmer overens med de indkommende spørgsmål. For at gøre dette tildeler vi hver prompt-indlejring til en referencedataklynge. Vi beregner afstanden fra hver prompt til dens tilsvarende centrum og ser på middelværdien, medianen og standardafvigelsen for disse afstande. Vi kan gemme disse oplysninger og se, hvordan de ændrer sig over tid.
Følgende figur viser et eksempel på analyse af afstanden mellem promptindlejring og referencedatacentre over tid.

Som du kan se, er gennemsnits-, median- og standardafvigelsesafstandsstatistikken mellem prompt-indlejringer og referencedatacentre faldende mellem den indledende baseline og det seneste øjebliksbillede. Selvom den absolutte værdi af afstanden er svær at fortolke, kan vi bruge tendenserne til at bestemme, om det semantiske overlap mellem referencedata og indgående spørgsmål bliver bedre eller værre over tid.
Eksempel på ansøgning
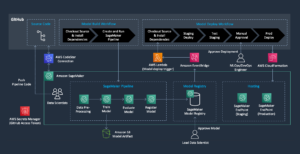
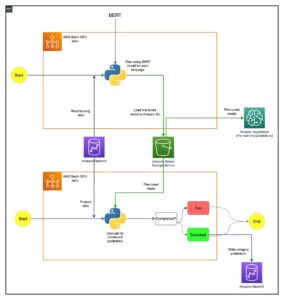
For at samle de eksperimentelle resultater, der blev diskuteret i det foregående afsnit, byggede vi en prøveapplikation, der implementerer RAG-mønsteret ved hjælp af indlejrings- og generationsmodeller implementeret gennem SageMaker JumpStart og hostet på Amazon SageMaker endepunkter i realtid.
Applikationen har tre kernekomponenter:
- Vi bruger et interaktivt flow, som inkluderer en brugergrænseflade til at fange prompter, kombineret med et RAG-orkestreringslag ved hjælp af LangChain.
- Databehandlingsflowet udtrækker data fra PDF-dokumenter og opretter indlejringer, der bliver gemt i Amazon OpenSearch Service. Vi bruger også disse i den endelige indlejringsafdriftsanalysekomponent i applikationen.
- Indlejringerne er fanget i Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose, og vi kører en kombination af AWS Lim udtrække, transformere og indlæse (ETL)-job og Jupyter-notebooks for at udføre indlejringsanalysen.
Følgende diagram illustrerer ende-til-ende-arkitekturen.
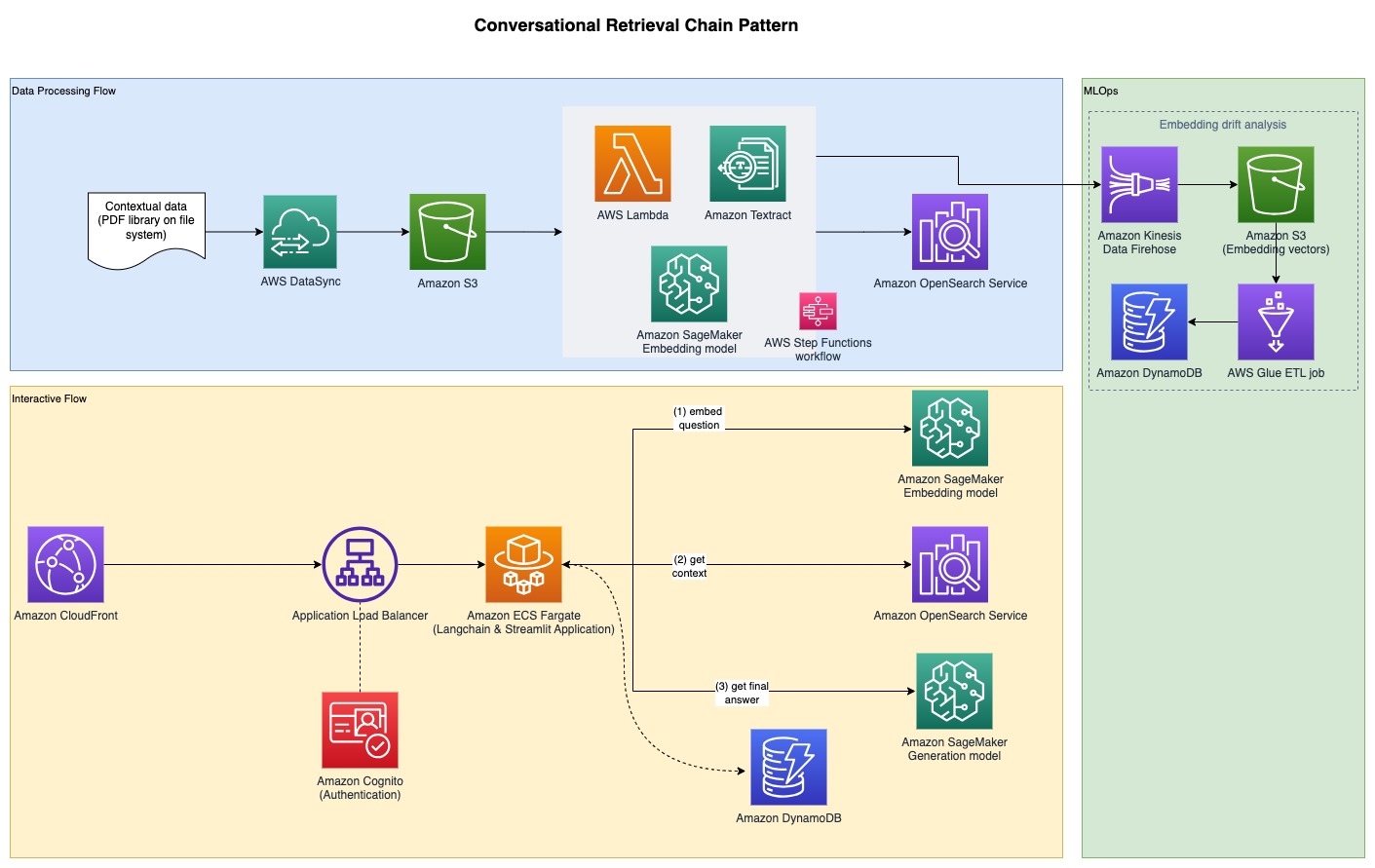
Den fulde prøvekode er tilgængelig på GitHub. Den medfølgende kode er tilgængelig i to forskellige mønstre:
- Prøv fuld stack-applikation med en Streamlit frontend – Dette giver en ende-til-ende-applikation, inklusive en brugergrænseflade, der bruger Streamlit til at fange prompter, kombineret med RAG-orkestreringslaget, ved hjælp af LangChain, der kører på Amazon Elastic Container Service (Amazon ECS) med AWS Fargate
- Backend-applikation – For dem, der ikke ønsker at implementere hele applikationsstakken, kan du valgfrit vælge kun at implementere backend AWS Cloud Development Kit (AWS CDK) stak, og brug derefter den medfølgende Jupyter-notebook til at udføre RAG-orkestrering ved hjælp af LangChain
For at skabe de medfølgende mønstre er der adskillige forudsætninger, der er beskrevet i de følgende afsnit, begyndende med implementering af de generative og tekstindlejringsmodeller og derefter videre til de yderligere forudsætninger.
Implementer modeller gennem SageMaker JumpStart
Begge mønstre forudsætter implementeringen af en indlejringsmodel og en generativ model. Til dette skal du implementere to modeller fra SageMaker JumpStart. Den første model, GPT-J 6B, bruges som indlejringsmodel, og den anden model, Falcon-40b, bruges til tekstgenerering.
Du kan implementere hver af disse modeller gennem SageMaker JumpStart fra AWS Management Console, Amazon SageMaker Studio, eller programmatisk. For mere information, se Sådan bruger du JumpStart-fundamentmodeller. For at forenkle implementeringen kan du bruge medfølgende notesbog stammer fra notesbøger, der er oprettet automatisk af SageMaker JumpStart. Denne notesbog trækker modellerne fra SageMaker JumpStart ML-hubben og implementerer dem til to separate SageMaker-endepunkter i realtid.
Eksemplet på notesbogen har også en oprydningssektion. Kør ikke den sektion endnu, fordi den vil slette de endepunkter, der netop er implementeret. Du vil fuldføre oprydningen i slutningen af gennemgangen.
Når du har bekræftet vellykket implementering af slutpunkterne, er du klar til at implementere hele prøveapplikationen. Men hvis du er mere interesseret i kun at udforske backend- og analysenotesbøgerne, kan du valgfrit kun implementere det, som er dækket i næste afsnit.
Mulighed 1: Implementer kun backend-applikationen
Dette mønster giver dig mulighed for kun at implementere backend-løsningen og interagere med løsningen ved hjælp af en Jupyter-notesbog. Brug dette mønster, hvis du ikke ønsker at bygge hele frontend-grænsefladen ud.
Forudsætninger
Du skal have følgende forudsætninger:
- Et SageMaker JumpStart-modelslutpunkt implementeret – Implementer modellerne til SageMaker-endepunkter i realtid ved hjælp af SageMaker JumpStart, som tidligere beskrevet
- Implementeringsparametre – Registrer følgende:
- Navn på tekstmodelslutpunkt – Slutpunktsnavnet på tekstgenereringsmodellen implementeret med SageMaker JumpStart
- Navn på indlejringsmodellens slutpunkt – Endpointnavnet på den indlejringsmodel, der er implementeret med SageMaker JumpStart
Implementer ressourcerne ved hjælp af AWS CDK
Brug de implementeringsparametre, der er nævnt i det foregående afsnit, til at implementere AWS CDK-stakken. For mere information om AWS CDK installation, se Kom godt i gang med AWS CDK.
Sørg for, at Docker er installeret og kører på den arbejdsstation, der skal bruges til AWS CDK-implementering. Henvise til Hent Docker for yderligere vejledning.
Alternativt kan du indtaste kontekstværdierne i en fil kaldet cdk.context.json i pattern1-rag/cdk mappe og kør cdk deploy BackendStack --exclusively.
Implementeringen vil udskrive output, hvoraf nogle vil være nødvendige for at køre notebook'en. Inden du kan begynde at stille spørgsmål og besvare, skal du integrere referencedokumenterne som vist i næste afsnit.
Integrer referencedokumenter
Til denne RAG-tilgang indlejres referencedokumenter først med en tekstindlejringsmodel og gemmes i en vektordatabase. I denne løsning er der bygget en indtagelsespipeline, der optager PDF-dokumenter.
An Amazon Elastic Compute Cloud (Amazon EC2)-instans er blevet oprettet til PDF-dokumentindtagelsen og en Amazon Elastic File System (Amazon EFS) filsystem er monteret på EC2-instansen for at gemme PDF-dokumenterne. An AWS DataSync opgaven køres hver time for at hente PDF-dokumenter fundet i EFS-filsystemstien og uploade dem til en S3-bøtte for at starte tekstindlejringsprocessen. Denne proces indlejrer referencedokumenterne og gemmer indlejringerne i OpenSearch Service. Det gemmer også et indlejringsarkiv til en S3-spand gennem Kinesis Data Firehose til senere analyse.
For at indtage referencedokumenterne skal du udføre følgende trin:
- Hent prøve-EC2-instans-id'et, der blev oprettet (se AWS CDK-output
JumpHostId) og tilslut vha Session Manager, en evne til AWS System Manager. For instruktioner, se Opret forbindelse til din Linux-instans med AWS Systems Manager Session Manager. - Gå til biblioteket
/mnt/efs/fs1, som er hvor EFS-filsystemet er monteret, og opret en mappe kaldetingest: - Tilføj dine reference PDF-dokumenter til
ingestmappe.
DataSync-opgaven er konfigureret til at uploade alle filer fundet i denne mappe til Amazon S3 for at starte indlejringsprocessen.
DataSync-opgaven kører efter en timeplan; du kan valgfrit starte opgaven manuelt for at starte indlejringsprocessen med det samme for de PDF-dokumenter, du tilføjede.
- For at starte opgaven skal du finde opgave-id'et fra AWS CDK-output
DataSyncTaskID, starte opgaven med standardindstillinger.
Efter at indlejringerne er oprettet, kan du starte RAG-spørgsmålet og svaret gennem en Jupyter-notesbog, som vist i næste afsnit.
Spørgsmål og svar ved hjælp af en Jupyter notesbog
Udfør følgende trin:
- Hent navnet på SageMaker notebook-forekomsten fra AWS CDK-output
NotebookInstanceNameog opret forbindelse til JupyterLab fra SageMaker-konsollen. - Gå til biblioteket
fmops/full-stack/pattern1-rag/notebooks/. - Åbn og kør notesbogen
query-llm.ipynbi notebook-instansen for at udføre spørgsmål og svar ved hjælp af RAG.
Sørg for at bruge conda_python3 kerne til notesbogen.
Dette mønster er nyttigt til at udforske backend-løsningen uden at skulle stille yderligere forudsætninger til rådighed, som er nødvendige for fuld-stack-applikationen. Det næste afsnit dækker implementeringen af en fuld stack-applikation, inklusive både frontend- og backend-komponenterne, for at give en brugergrænseflade til at interagere med din generative AI-applikation.
Mulighed 2: Implementer prøveapplikationen i fuld stack med en Streamlit frontend
Dette mønster giver dig mulighed for at implementere løsningen med en brugergrænseflade til spørgsmål og svar.
Forudsætninger
For at implementere eksempelapplikationen skal du have følgende forudsætninger:
- SageMaker JumpStart-modelslutpunkt implementeret – Implementer modellerne til dine SageMaker-endepunkter i realtid ved hjælp af SageMaker JumpStart, som beskrevet i det foregående afsnit, ved hjælp af de medfølgende notesbøger.
- Amazon Route 53 hostet zone - Opret en Amazonrute 53 offentlig hostet zone at bruge til denne løsning. Du kan også bruge en eksisterende Route 53 offentlig hostet zone, som f.eks
example.com. - AWS Certificate Manager-certifikat – Bestemmelse en AWS Certificate Manager (ACM) TLS-certifikat for det Route 53-hostede zonedomænenavn og dets relevante underdomæner, som f.eks.
example.com,*.example.comfor alle underdomæner. For instruktioner, se Anmodning om offentlig attest. Dette certifikat bruges til at konfigurere HTTPS til Amazon CloudFront og original load balancer. - Implementeringsparametre – Registrer følgende:
- Frontend-applikation tilpasset domænenavn – Et brugerdefineret domænenavn, der bruges til at få adgang til frontend-eksempelapplikationen. Det angivne domænenavn bruges til at oprette en Route 53 DNS-record, der peger på frontend CloudFront-distributionen; for eksempel,
app.example.com. - Load balancer oprindelse tilpasset domænenavn – Et brugerdefineret domænenavn, der bruges til CloudFront distributions load balancer-oprindelse. Det angivne domænenavn bruges til at oprette en Route 53 DNS-record, der peger på den oprindelige load balancer; for eksempel,
app-lb.example.com. - Rute 53 hostet zone ID – Route 53-hostet zone-id til at være vært for de angivne tilpassede domænenavne; for eksempel,
ZXXXXXXXXYYYYYYYYY. - Rute 53 hostet zonenavn – Navnet på den Route 53-hostede zone for at være vært for de angivne tilpassede domænenavne; for eksempel,
example.com. - ACM certifikat ARN – ARN for ACM-certifikatet, der skal bruges med det angivne tilpassede domæne.
- Navn på tekstmodelslutpunkt – Slutpunktsnavnet på tekstgenereringsmodellen implementeret med SageMaker JumpStart.
- Navn på indlejringsmodellens slutpunkt – Endpointnavnet på den indlejringsmodel, der er implementeret med SageMaker JumpStart.
- Frontend-applikation tilpasset domænenavn – Et brugerdefineret domænenavn, der bruges til at få adgang til frontend-eksempelapplikationen. Det angivne domænenavn bruges til at oprette en Route 53 DNS-record, der peger på frontend CloudFront-distributionen; for eksempel,
Implementer ressourcerne ved hjælp af AWS CDK
Brug de implementeringsparametre, du noterede i forudsætningerne for at implementere AWS CDK-stakken. For mere information, se Kom godt i gang med AWS CDK.
Sørg for, at Docker er installeret og kører på den arbejdsstation, der skal bruges til AWS CDK-implementeringen.
I den foregående kode repræsenterer -c en kontekstværdi i form af de krævede forudsætninger, der er angivet ved input. Alternativt kan du indtaste kontekstværdierne i en fil kaldet cdk.context.json i pattern1-rag/cdk mappe og kør cdk deploy --all.
Bemærk, at vi angiver regionen i filen bin/cdk.ts. Konfiguration af ALB-adgangslogfiler kræver en specificeret region. Du kan ændre denne region før implementering.
Implementeringen udskriver URL'en for at få adgang til Streamlit-applikationen. Før du kan begynde at stille spørgsmål og besvare, skal du indlejre referencedokumenterne, som vist i næste afsnit.
Integrer referencedokumenterne
For en RAG-tilgang indlejres referencedokumenter først med en tekstindlejringsmodel og gemmes i en vektordatabase. I denne løsning er der bygget en indtagelsespipeline, der optager PDF-dokumenter.
Som vi diskuterede i den første implementeringsmulighed, er der oprettet et eksempel på en EC2-instans til PDF-dokumentindtagelsen, og et EFS-filsystem er monteret på EC2-instansen for at gemme PDF-dokumenterne. En DataSync-opgave køres hver time for at hente PDF-dokumenter fundet i EFS-filsystemstien og uploade dem til en S3-bøtte for at starte tekstindlejringsprocessen. Denne proces indlejrer referencedokumenterne og gemmer indlejringerne i OpenSearch Service. Det gemmer også et indlejringsarkiv til en S3-spand gennem Kinesis Data Firehose til senere analyse.
For at indtage referencedokumenterne skal du udføre følgende trin:
- Hent prøve-EC2-instans-id'et, der blev oprettet (se AWS CDK-output
JumpHostId) og tilslut ved hjælp af Session Manager. - Gå til biblioteket
/mnt/efs/fs1, som er hvor EFS-filsystemet er monteret, og opret en mappe kaldetingest: - Tilføj dine reference PDF-dokumenter til
ingestmappe.
DataSync-opgaven er konfigureret til at uploade alle filer fundet i denne mappe til Amazon S3 for at starte indlejringsprocessen.
DataSync-opgaven kører efter en timeplan. Du kan valgfrit starte opgaven manuelt for at starte indlejringsprocessen med det samme for de PDF-dokumenter, du tilføjede.
- For at starte opgaven skal du finde opgave-id'et fra AWS CDK-output
DataSyncTaskID, starte opgaven med standardindstillinger.
Spørgsmål og svar
Efter at referencedokumenterne er blevet indlejret, kan du starte RAG-spørgsmålet og svaret ved at besøge URL'en for at få adgang til Streamlit-applikationen. An Amazon Cognito autentificeringslag bruges, så det kræver oprettelse af en brugerkonto i Amazon Cognito-brugerpuljen implementeret via AWS CDK (se AWS CDK-output for brugerpuljenavnet) for første gangs adgang til applikationen. For instruktioner om at oprette en Amazon Cognito-bruger, se Oprettelse af en ny bruger i AWS Management Console.
Integrer driftanalyse
I dette afsnit viser vi dig, hvordan du udfører afdriftsanalyse ved først at oprette en basislinje for referencedataindlejringerne og promptindlejringerne og derefter oprette et øjebliksbillede af indlejringerne over tid. Dette giver dig mulighed for at sammenligne baseline-indlejringer med snapshot-indlejringer.
Opret en indlejringsgrundlinje for referencedataene og -prompten
For at oprette en indlejring af referencedataene skal du åbne AWS Glue-konsollen og vælge ETL-jobbet embedding-drift-analysis. Indstil parametrene for ETL-jobbet som følger, og kør jobbet:
- sæt
--job_typetilBASELINE. - sæt
--out_tabletil Amazon DynamoDB tabel til referenceindlejringsdata. (Se AWS CDK-outputDriftTableReferencefor tabelnavnet.) - sæt
--centroid_tabletil DynamoDB-tabellen for reference centroid data. (Se AWS CDK-outputCentroidTableReferencefor tabelnavnet.) - sæt
--data_pathtil S3-spanden med præfikset; for eksempel,s3:///embeddingarchive/. (Se AWS CDK-outputBucketNamefor bøttenavnet.)
På samme måde ved at bruge ETL-jobbet embedding-drift-analysis, opret en indlejringsgrundlinje for meddelelserne. Indstil parametrene for ETL-jobbet som følger, og kør jobbet:
- sæt
--job_typetilBASELINE - sæt
--out_tabletil DynamoDB-tabellen for hurtig indlejring af data. (Se AWS CDK-outputDriftTablePromptsNamefor tabelnavnet.) - sæt
--centroid_tabletil DynamoDB-tabellen for prompte centroid-data. (Se AWS CDK-outputCentroidTablePromptsfor tabelnavnet.) - sæt
--data_pathtil S3-spanden med præfikset; for eksempel,s3:///promptarchive/. (Se AWS CDK-outputBucketNamefor bøttenavnet.)
Opret et indlejringsøjebliksbillede for referencedataene og -prompten
Når du har indsat yderligere oplysninger i OpenSearch Service, skal du køre ETL-jobbet embedding-drift-analysis igen for at snapshot af referencedataindlejringerne. Parametrene vil være de samme som det ETL-job, du kørte for at oprette indlejringsgrundlinjen for referencedataene som vist i det foregående afsnit, med undtagelse af indstillingen af --job_type parameter til SNAPSHOT.
På samme måde skal du køre ETL-jobbet for at få et øjebliksbillede af promptindlejringerne embedding-drift-analysis en gang til. Parametrene vil være de samme som det ETL-job, du kørte for at oprette indlejringsgrundlinjen for prompterne som vist i det foregående afsnit, med undtagelse af indstillingen af --job_type parameter til SNAPSHOT.
Sammenlign basislinjen med øjebliksbilledet
Brug den medfølgende notesbog for at sammenligne den indlejrede basislinje og snapshot for referencedata og prompter pattern1-rag/notebooks/drift-analysis.ipynb.
For at se på indlejringssammenligning for referencedata eller -prompter skal du ændre DynamoDB-tabelnavnevariablerne (tbl , c_tbl) i notesbogen til den relevante DynamoDB-tabel for hver kørsel af notesbogen.
Notebook-variablen tbl skal ændres til det relevante drifttabelnavn. Det følgende er et eksempel på, hvor variablen skal konfigureres i notesbogen.

Tabelnavnene kan hentes som følger:
- For referenceindlejringsdata skal du hente drifttabelnavnet fra AWS CDK-output
DriftTableReference - For prompt-indlejringsdata skal du hente drifttabelnavnet fra AWS CDK-output
DriftTablePromptsName
Desuden notebook-variablen c_tbl skal ændres til det relevante tyngdepunktstabelnavn. Det følgende er et eksempel på, hvor variablen skal konfigureres i notesbogen.

Tabelnavnene kan hentes som følger:
- For referenceindlejringsdata skal du hente tyngdepunktstabelnavnet fra AWS CDK-output
CentroidTableReference - For prompt indlejringsdata skal du hente tyngdepunktstabelnavnet fra AWS CDK-output
CentroidTablePrompts
Analyser promptafstanden fra referencedataene
Kør først AWS Glue-jobbet embedding-distance-analysis. Dette job vil finde ud af, hvilken klynge, fra K-Means-evalueringen af referencedataindlejringerne, som hver prompt tilhører. Den beregner derefter middelværdien, medianen og standardafvigelsen af afstanden fra hver prompt til midten af den tilsvarende klynge.
Du kan køre notesbogen pattern1-rag/notebooks/distance-analysis.ipynb at se tendenserne i afstandsmålene over tid. Dette vil give dig en fornemmelse af den overordnede tendens i fordelingen af de hurtige indlejringsafstande.
Notesbogen pattern1-rag/notebooks/prompt-distance-outliers.ipynb er en AWS Glue notesbog, der leder efter outliers, som kan hjælpe dig med at identificere, om du får flere prompter, der ikke er relateret til referencedataene.
Overvåg lighedsscore
Alle lighedsresultater fra OpenSearch Service er logget ind amazoncloudwatch under rag navneområde. Dashboardet RAG_Scores viser den gennemsnitlige score og det samlede antal indtagne scores.
Ryd op
For at undgå fremtidige gebyrer skal du slette alle de ressourcer, du har oprettet.
Slet de implementerede SageMaker-modeller
Se oprydningsafsnittet i medfølgende eksempel notesbog for at slette de implementerede SageMaker JumpStart-modeller, eller du kan slet modellerne på SageMaker-konsollen.
Slet AWS CDK-ressourcerne
Hvis du indtastede dine parametre i en cdk.context.json fil, skal du rydde op som følger:
Hvis du indtastede dine parametre på kommandolinjen og kun implementerede backend-applikationen (backend AWS CDK-stakken), skal du rydde op som følger:
Hvis du indtastede dine parametre på kommandolinjen og implementerede den fulde løsning (frontend og backend AWS CDK-stakkene), skal du rydde op som følger:
Konklusion
I dette indlæg gav vi et fungerende eksempel på en applikation, der fanger indlejringsvektorer for både referencedata og prompter i RAG-mønsteret for generativ AI. Vi viste, hvordan man udfører klyngeanalyse for at bestemme, om reference- eller promptdata glider over tid, og hvor godt referencedataene dækker de typer spørgsmål, brugerne stiller. Hvis du registrerer drift, kan det give et signal om, at miljøet har ændret sig, og din model får nye input, som den måske ikke er optimeret til at håndtere. Dette giver mulighed for proaktiv evaluering af den nuværende model mod skiftende input.
Om forfatterne
 Abdullahi Olaoye er Senior Solutions Architect hos Amazon Web Services (AWS). Abdullahi har en MSC i computernetværk fra Wichita State University og er en offentliggjort forfatter, der har haft roller på tværs af forskellige teknologidomæner såsom DevOps, modernisering af infrastruktur og AI. Han er i øjeblikket fokuseret på Generativ AI og spiller en nøglerolle i at hjælpe virksomheder med at udvikle og bygge banebrydende løsninger drevet af Generativ AI. Ud over teknologiens område finder han glæde i kunsten at udforske. Når han ikke laver AI-løsninger, nyder han at rejse med sin familie for at udforske nye steder.
Abdullahi Olaoye er Senior Solutions Architect hos Amazon Web Services (AWS). Abdullahi har en MSC i computernetværk fra Wichita State University og er en offentliggjort forfatter, der har haft roller på tværs af forskellige teknologidomæner såsom DevOps, modernisering af infrastruktur og AI. Han er i øjeblikket fokuseret på Generativ AI og spiller en nøglerolle i at hjælpe virksomheder med at udvikle og bygge banebrydende løsninger drevet af Generativ AI. Ud over teknologiens område finder han glæde i kunsten at udforske. Når han ikke laver AI-løsninger, nyder han at rejse med sin familie for at udforske nye steder.
 Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han arbejdede med computersyn til autonome køretøjer. Han har også en MBA fra Colorado State University. Randy har haft en række forskellige stillinger inden for teknologiområdet, lige fra softwareudvikling til produktstyring. In gik ind i Big Data-området i 2013 og fortsætter med at udforske dette område. Han arbejder aktivt på projekter i ML-området og har præsenteret på adskillige konferencer, herunder Strata og GlueCon.
Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han arbejdede med computersyn til autonome køretøjer. Han har også en MBA fra Colorado State University. Randy har haft en række forskellige stillinger inden for teknologiområdet, lige fra softwareudvikling til produktstyring. In gik ind i Big Data-området i 2013 og fortsætter med at udforske dette område. Han arbejder aktivt på projekter i ML-området og har præsenteret på adskillige konferencer, herunder Strata og GlueCon.
 Shelbee Eigenbrode er Principal AI og Machine Learning Specialist Solutions Architect hos Amazon Web Services (AWS). Hun har været i teknologi i 24 år, der spænder over flere industrier, teknologier og roller. Hun fokuserer i øjeblikket på at kombinere sin DevOps- og ML-baggrund i MLOps-domænet for at hjælpe kunder med at levere og administrere ML-arbejdsbelastninger i stor skala. Med over 35 patenter udstedt på tværs af forskellige teknologidomæner har hun en passion for kontinuerlig innovation og brug af data til at drive forretningsresultater. Shelbee er medskaber og underviser af den praktiske datavidenskab specialisering på Coursera. Hun er også meddirektør for Women In Big Data (WiBD), kapitel i Denver. I sin fritid kan hun lide at bruge tid sammen med sin familie, venner og overaktive hunde.
Shelbee Eigenbrode er Principal AI og Machine Learning Specialist Solutions Architect hos Amazon Web Services (AWS). Hun har været i teknologi i 24 år, der spænder over flere industrier, teknologier og roller. Hun fokuserer i øjeblikket på at kombinere sin DevOps- og ML-baggrund i MLOps-domænet for at hjælpe kunder med at levere og administrere ML-arbejdsbelastninger i stor skala. Med over 35 patenter udstedt på tværs af forskellige teknologidomæner har hun en passion for kontinuerlig innovation og brug af data til at drive forretningsresultater. Shelbee er medskaber og underviser af den praktiske datavidenskab specialisering på Coursera. Hun er også meddirektør for Women In Big Data (WiBD), kapitel i Denver. I sin fritid kan hun lide at bruge tid sammen med sin familie, venner og overaktive hunde.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35 %
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95 %
- a
- I stand
- Om
- absolutte
- adgang
- Konto
- ACM
- tværs
- aktivt
- tilføjet
- Desuden
- Yderligere
- yderligere information
- Derudover
- igen
- mod
- aggregat
- AI
- Justerer
- Alle
- tillade
- tillader
- også
- Skønt
- Amazon
- Amazon Cognito
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- analyse
- analysere
- analysere
- ,
- besvare
- besvarelse
- noget
- anvendelig
- Anvendelse
- tilgang
- passende
- arkitektur
- Arkiv
- ER
- OMRÅDE
- områder
- Kunst
- artikler
- AS
- spørg
- spørge
- bistår
- antage
- At
- forøge
- augmented
- Godkendelse
- forfatter
- automatisk
- autonom
- autonome køretøjer
- til rådighed
- gennemsnit
- undgå
- væk
- AWS
- AWS Lim
- Bagende
- baggrund
- swing
- baseret
- Baseline
- BE
- fordi
- været
- før
- være
- tilhører
- Bedre
- mellem
- Beyond
- Big
- Big data
- organer
- både
- bredt
- bygge
- bygget
- virksomhed
- by
- beregne
- beregner
- ringe
- kaldet
- CAN
- kapacitet
- fange
- fanget
- fanger
- Optagelse
- tilfælde
- CD
- center
- Centers
- certifikat
- lave om
- ændret
- Ændringer
- skiftende
- Kapitel
- afgifter
- chip
- Chokolade
- Vælg
- ren
- Luk
- tættere
- Cloud
- Cluster
- klyngedannelse
- kode
- Colorado
- kombination
- kombineret
- kombinerer
- kommer
- kompakt
- sammenligne
- sammenlignet
- sammenligning
- fuldføre
- komponent
- komponenter
- Compute
- computer
- Computer Vision
- begreber
- konferencer
- konfigureret
- konfigurering
- Tilslut
- overvejelser
- konsistens
- Konsol
- Container
- indhold
- sammenhæng
- fortsætter
- kontinuerlig
- konverteret
- cookies
- Core
- Tilsvarende
- Coursera
- dækning
- dækket
- dækker
- dækker
- skabe
- oprettet
- skaber
- Oprettelse af
- Nuværende
- For øjeblikket
- skik
- Kunder
- banebrydende
- instrumentbræt
- data
- datacentre
- databehandling
- datalogi
- Database
- faldende
- defaults
- definerede
- slette
- levere
- Denver
- indsætte
- indsat
- implementering
- implementering
- udruller
- Afledt
- ødelægge
- detaljeret
- opdage
- Detektion
- Bestem
- Udvikling
- afvigelse
- DevOps
- diagram
- forskellige
- svært
- Dimension
- størrelse
- drøftet
- spredte
- afstand
- Fjern
- fordeling
- dns
- do
- Docker
- dokumentet
- dokumenter
- Hunde
- domæne
- Domain Name
- DOMÆNENAVNE
- Domæner
- Dont
- ned
- køre
- hver
- Integrer
- indlejret
- indlejring
- ende
- ende til ende
- Endpoint
- endpoints
- Engineering
- Indtast
- indtastet
- virksomheder
- Miljø
- Ether (ETH)
- evaluere
- evaluering
- Hver
- eksempel
- eksempler
- undtagelse
- eksisterende
- eksperimenterende
- Forklar
- udforskning
- udforske
- Udforskning
- ekstern
- ekstrakt
- Uddrag
- familie
- langt
- Figur
- File (Felt)
- Filer
- endelige
- Endelig
- Finde
- fund
- Fornavn
- flydende
- flow
- fokuserede
- fokusering
- efter
- følger
- Til
- formular
- fundet
- Foundation
- venner
- fra
- frontend
- fuld
- fremtiden
- samle
- Generelt
- generere
- generation
- generative
- Generativ AI
- generativ model
- få
- få
- Giv
- Go
- gået
- bevilget
- gruppe
- vejledning
- håndtere
- Have
- he
- Held
- hjælpe
- hende
- højere
- hans
- besidder
- host
- hostede
- time
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- Hub
- ID
- identificere
- if
- illustrerer
- straks
- implementering
- redskaber
- vigtigt
- in
- omfatter
- omfatter
- Herunder
- Indgående
- angiver
- angiver
- industrier
- inerti
- oplysninger
- Infrastruktur
- initial
- Innovation
- indgang
- indgange
- indsigt
- installation
- instans
- anvisninger
- interagere
- interaktion
- interaktiv
- interesseret
- grænseflade
- ind
- IT
- ITS
- Job
- Karriere
- glæde
- jpg
- Jupyter Notebook
- lige
- Nøgle
- Kinesis Data Brandslange
- viden
- Sprog
- stor
- senere
- seneste
- lag
- LÆR
- læring
- Lets
- Bibliotek
- synes godt om
- Line (linje)
- linux
- llm
- belastning
- placering
- logget
- Se
- UDSEENDE
- lavere
- maskine
- machine learning
- lave
- administrere
- ledelse
- leder
- manuelt
- Kan..
- MBA
- betyde
- midler
- måle
- foranstaltninger
- Metrics
- Michigan
- måske
- ML
- MLOps
- model
- modeller
- modernisering
- Overvåg
- mere
- mest
- flytning
- flere
- skal
- navn
- navne
- Natural
- Naturligt sprog
- Natural Language Processing
- Behov
- behov
- behøve
- netværk
- Ny
- nyere
- næste
- NLP
- notesbog
- notesbøger
- bemærkede
- nummer
- numre
- talrige
- of
- tit
- on
- kun
- åbent
- optimeret
- Option
- or
- orkestrering
- ordrer
- Oprindelse
- Andet
- vores
- ud
- udfald
- skitseret
- output
- udgange
- i løbet af
- samlet
- overlapning
- egen
- parameter
- parametre
- særlig
- lidenskab
- Patenter
- sti
- Mønster
- mønstre
- udføre
- udfører
- stykker
- pipeline
- Steder
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Punkt
- punkter
- pool
- positioner
- mulig
- Indlæg
- potentiale
- strøm
- Praktisk
- forud
- forudsætninger
- forelagt
- konserves
- bevare
- tidligere
- tidligere
- Main
- Proaktiv
- behandle
- forarbejdning
- Produkt
- produktstyring
- projekter
- prompter
- andel
- give
- forudsat
- giver
- bestemmelse
- offentlige
- offentliggjort
- Sweatre & trøjer
- spørgsmål
- Spørgsmål
- klud
- intervaller
- spænder
- klar
- realtid
- rige
- opskrift
- optage
- reducere
- reduktion
- henvise
- henvisningen
- region
- relaterede
- relativt
- relevant
- repræsentere
- repræsentation
- repræsenterer
- påkrævet
- Kræver
- Ressourcer
- svar
- Resultater
- hentning
- roller
- roller
- R
- Kør
- kører
- løber
- sagemaker
- samme
- Gem
- Scale
- planlægge
- Videnskab
- score
- scores
- Søg
- søgninger
- Anden
- Sektion
- sektioner
- se
- set
- Vælg
- semantiske
- senior
- forstand
- sendt
- adskille
- tjeneste
- Tjenester
- Session
- sæt
- indstilling
- flere
- hun
- bør
- Vis
- viste
- vist
- Shows
- Signal
- signaler
- lignende
- Simpelt
- forenkle
- Størrelse
- Snapshot
- So
- Software
- software Engineering
- løsninger
- Løsninger
- nogle
- Kilde
- Kilder
- Space
- spænding
- specialist
- specificeret
- tilbringe
- squared
- stable
- Stakke
- standard
- starte
- påbegyndt
- Starter
- Tilstand
- statistik
- Steps
- opbevaring
- butik
- opbevaret
- vellykket
- sådan
- sum
- sikker
- systemet
- Systemer
- bord
- Tag
- Opgaver
- teknik
- Teknologier
- Teknologier
- tekst
- tekstgenerering
- at
- oplysninger
- The Source
- deres
- Them
- derefter
- Der.
- Disse
- denne
- dem
- tre
- Gennem
- tid
- TLS
- til
- sammen
- Emner
- I alt
- Transform
- Traveling
- Trend
- Tendenser
- forsøger
- prøv
- to
- typer
- under
- universitet
- University of Michigan
- URL
- us
- brug
- anvendte
- nyttigt
- Bruger
- Brugergrænseflade
- brugere
- ved brug af
- validering
- værdi
- Værdier
- variabel
- variabler
- række
- forskellige
- vektor
- vektorer
- Køretøjer
- via
- vision
- visuel
- går igennem
- ønsker
- var
- Vej..
- we
- web
- webservices
- GODT
- hvornår
- hvorvidt
- som
- mens
- vilje
- med
- inden for
- uden
- Dame
- Arbejde
- arbejdede
- arbejder
- arbejdsstation
- værre
- ville
- år
- endnu
- dig
- Din
- zephyrnet
- zone