Amazon OpenSearch Service for nylig introduceret Multi-AZ med standby, en implementeringsmulighed designet til at give virksomheder forbedret tilgængelighed og ensartet ydeevne til kritiske arbejdsbelastninger. Med denne funktion kan administrerede klynger opnå 99.99 % tilgængelighed, mens de forbliver modstandsdygtige over for zoneinfrastrukturfejl.
I dette indlæg udforsker vi, hvordan søgning og indeksering fungerer med Multi-AZ med Standby, og dykker ned i de underliggende mekanismer, der bidrager til dets pålidelighed, enkelhed og fejltolerance.
Baggrund
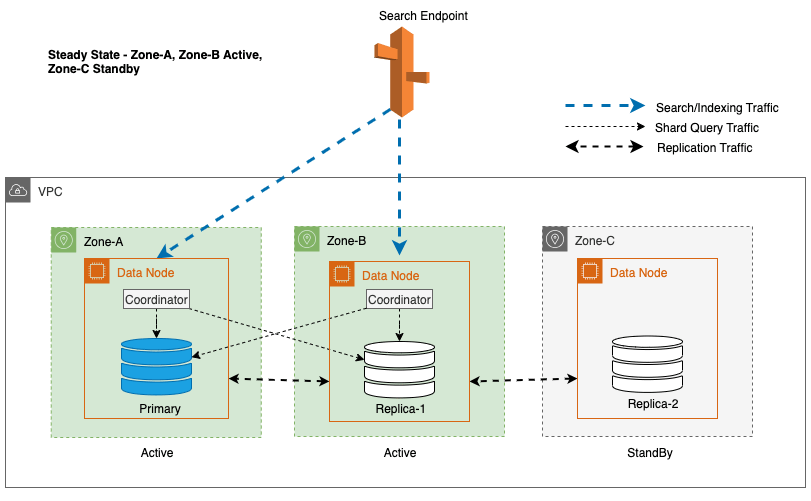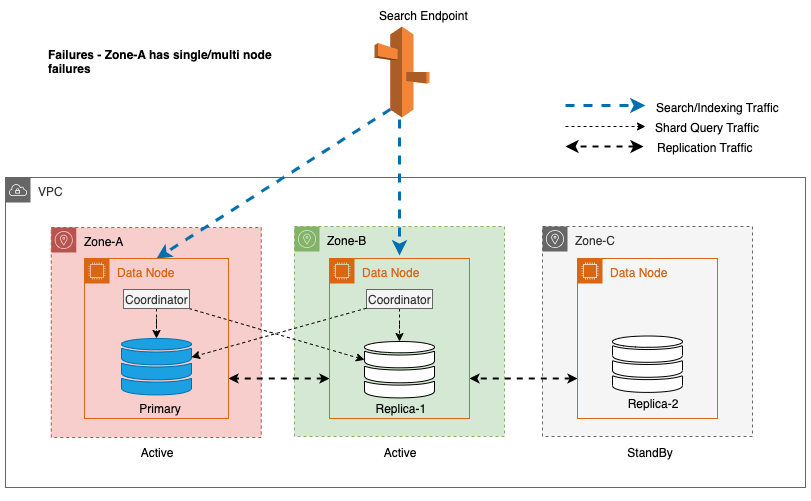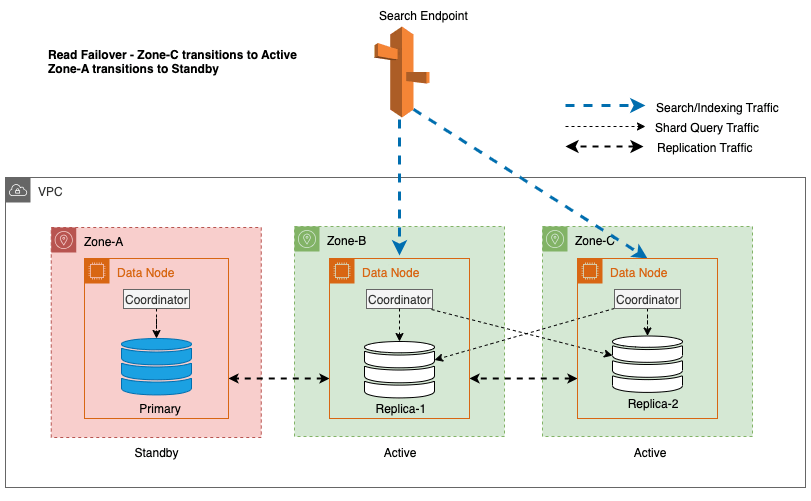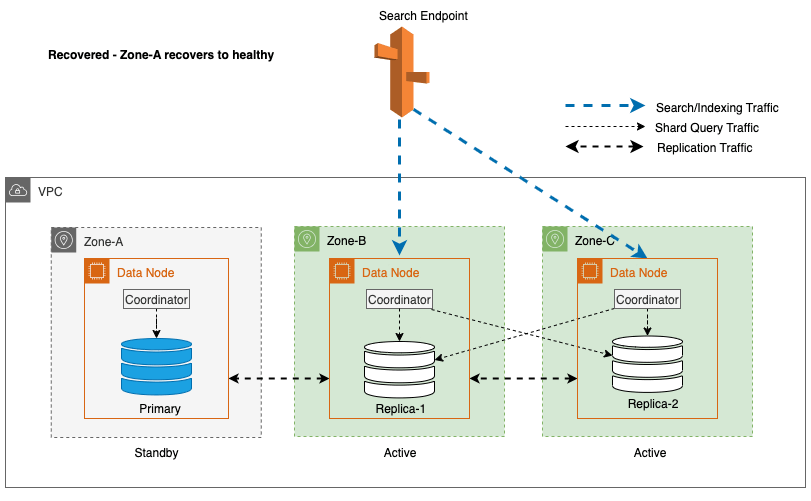
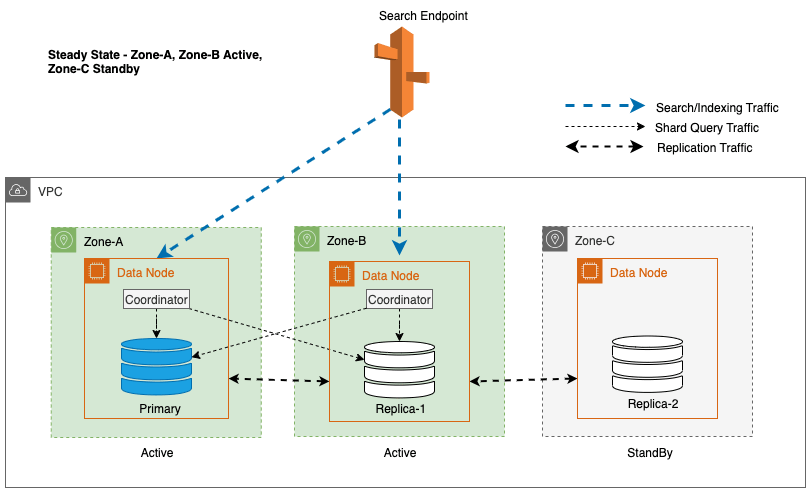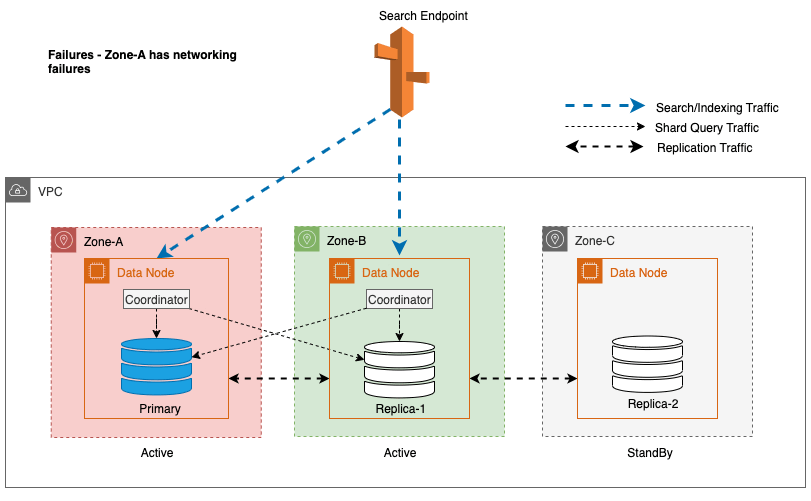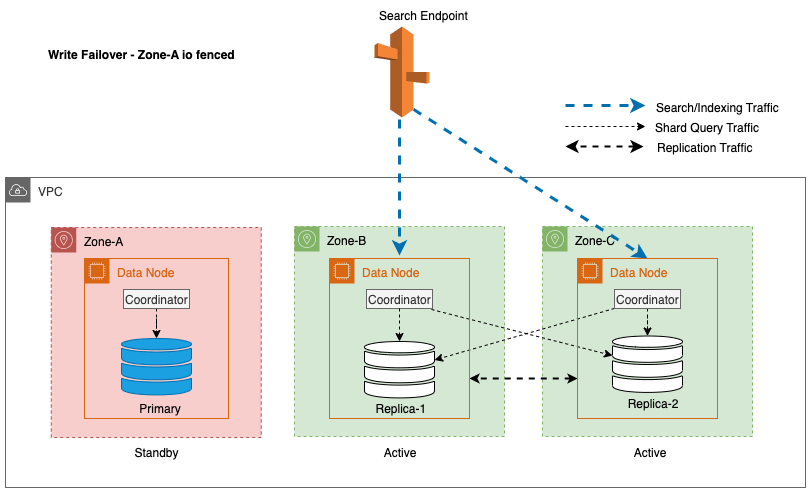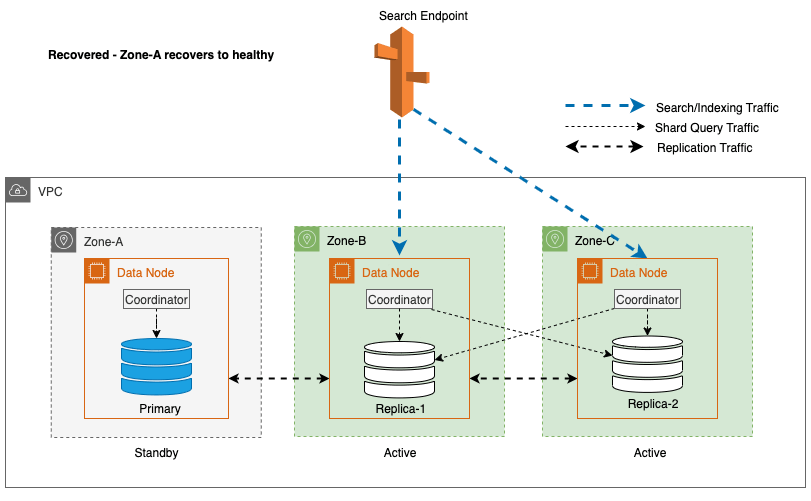
Multi-AZ med Standby implementerer OpenSearch Service-domæneforekomster på tværs af tre tilgængelighedszoner, med to zoner udpeget som aktive og én som standby. Denne konfiguration sikrer ensartet ydeevne, selv i tilfælde af zonefejl, ved at opretholde den samme kapacitet på tværs af alle zoner. Det er vigtigt, at denne standby-zone følger en statisk stabilt design, hvilket eliminerer behovet for kapacitetsforsyning eller dataflytning under fejl.
Under almindelig drift håndterer den aktive zone koordinatortrafik for både læse- og skriveanmodninger samt shard-forespørgselstrafik. Standby-zonen modtager på den anden side kun replikeringstrafik. OpenSearch Service bruger en synkron replikeringsprotokol til skriveanmodninger. Dette gør det muligt for tjenesten omgående at opgradere en standby-zone til aktiv status i tilfælde af en fejl (gennemsnitlig tid til failover <= 1 minut), kendt som en zonebestemt failover. Den tidligere aktive zone degraderes derefter til standbytilstand, og gendannelsesoperationer begynder for at genoprette dens sunde tilstand.
Søgetrafik routing og failover for at garantere høj tilgængelighed
I et OpenSearch Service-domæne, en koordinator er enhver node, der håndterer HTTP(S)-anmodninger, især indekserings- og søgeanmodninger. I et Multi-AZ med Standby-domæne fungerer dataknuderne i den aktive zone som koordinatorer for søgeanmodninger.
Under forespørgselsfasen af en søgeanmodning bestemmer koordinatoren de shards, der skal forespørges på, og sender en anmodning til den dataknude, der er vært for shard-kopien. Forespørgslen køres lokalt på hvert shard, og matchede dokumenter returneres til koordinatornoden. Koordinatorknudepunktet, som er ansvarlig for at sende anmodningen til noder, der indeholder shard kopier, kører processen i to trin. For det første opretter den en iterator, der definerer rækkefølgen, hvori noder skal forespørges efter en shard kopi, så trafikken er ensartet fordelt på tværs af shard kopier. Efterfølgende sendes anmodningen til de relevante knudepunkter.
For at oprette en ordnet liste over noder, der skal forespørges efter en shard kopi, bruger koordinatorknudepunktet forskellige algoritmer. Disse algoritmer omfatter round-robin-udvælgelse, adaptiv replika-udvælgelse, præferencebaseret shard-routing og vægtet round-robin.
For Multi-AZ med Standby bruges den vægtede round-robin-algoritme til valg af shard copy. I denne tilgang tildeles aktive zoner en vægt på 1, og standbyzonen tildeles vægten 0. Dette sikrer, at der ikke sendes læst trafik til dataknudepunkter i standby-tilgængelighedszonen.
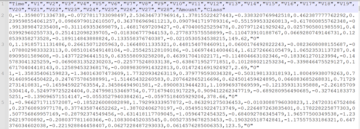
Vægtene gemmes i klyngetilstandsmetadata som et JSON-objekt:
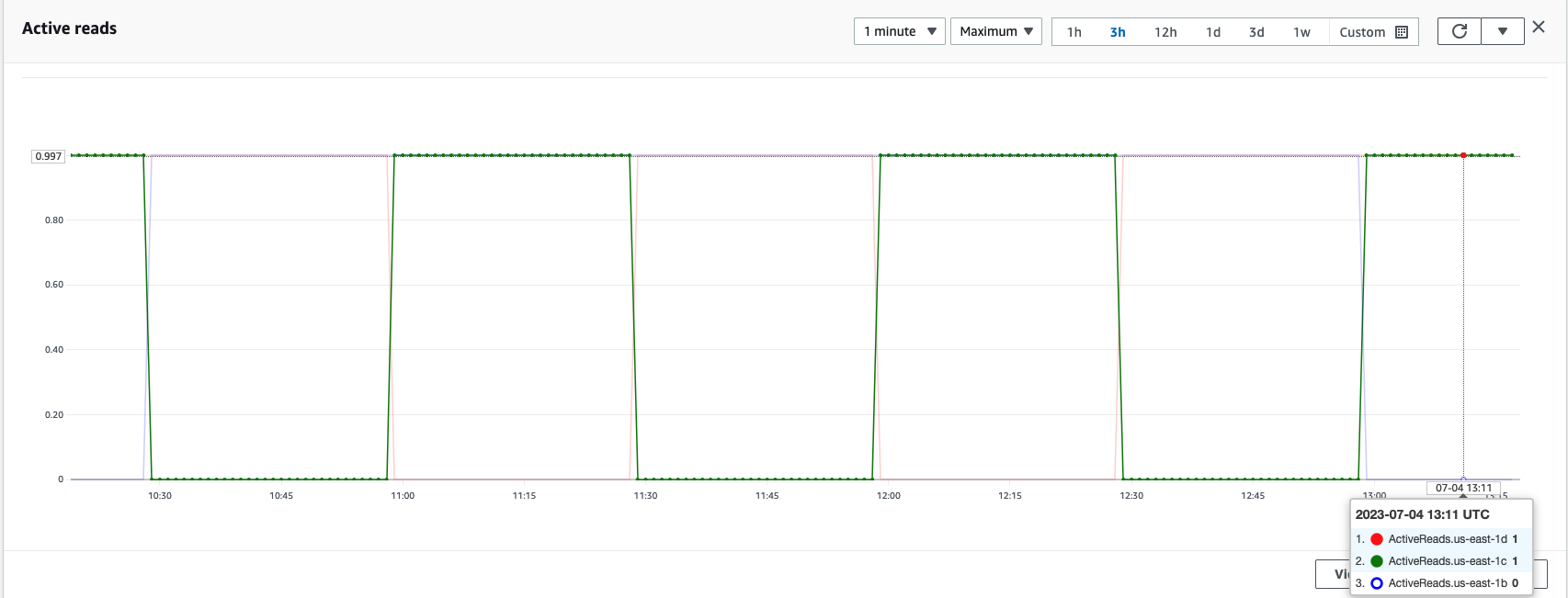
Som vist på det følgende skærmbillede us-east-1b Regionen har sin zonestatus som StandBy, hvilket indikerer, at dataknuderne i denne tilgængelighedszone er i standbytilstand og ikke modtager søge- eller indekseringsanmodninger fra belastningsbalanceren.

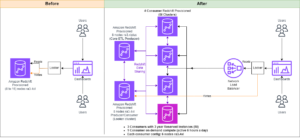
For at opretholde steady-state-drift roteres standby-tilgængelighedszonen hvert 30. minut, hvilket sikrer, at alle netværksdele er dækket på tværs af tilgængelighedszoner. Denne proaktive tilgang verificerer tilgængeligheden af læsestier, hvilket yderligere forbedrer systemets modstandsdygtighed under potentielle fejl. Følgende diagram illustrerer denne arkitektur.
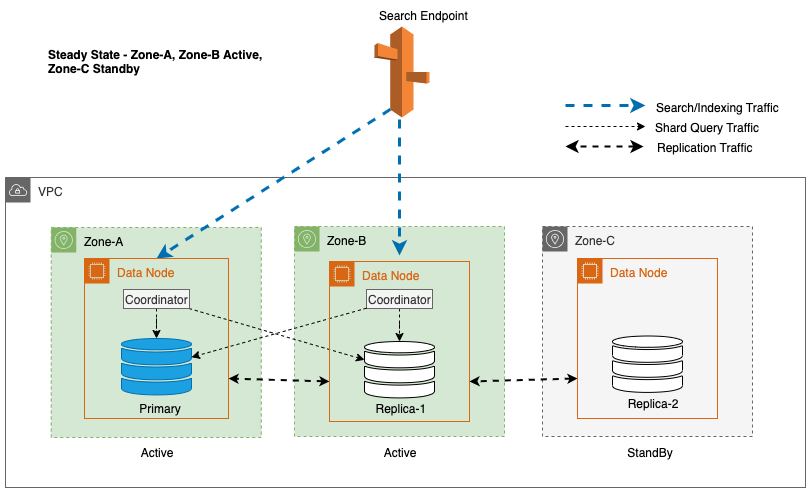
I det foregående diagram har Zone-C en vægtet round-robin vægt sat til nul. Dette sikrer, at dataknuderne i standbyzonen ikke modtager nogen indeksering eller søgetrafik. Når koordinatoren forespørger om dataknudepunkter for shard kopier, bruger den en vægtet round-robin vægt til at bestemme rækkefølgen, i hvilke noder der skal forespørges. Fordi vægten er nul for standby-tilgængelighedszonen, sendes koordinatoranmodninger ikke.
I en OpenSearch Service-klynge kan de aktive zoner og standby-zoner til enhver tid kontrolleres ved hjælp af Tilgængelighedszone-rotationsmetrikker, som vist på det følgende skærmbillede.
Under zoneafbrydelser skifter standby-tilgængelighedszonen problemfrit til fejl-åben-tilstand for søgeanmodninger. Dette betyder, at shard-forespørgselstrafikken dirigeres til alle tilgængelighedszoner, selv dem i standby, når en sund shard-kopi ikke er tilgængelig i den aktive tilgængelighedszone. Denne fejlåbne tilgang beskytter søgeanmodninger mod forstyrrelser under fejl, hvilket sikrer kontinuerlig service. Følgende diagram illustrerer denne arkitektur.
I det foregående diagram, under steady state, sendes shard-forespørgselstrafikken til dataknudepunktet i de aktive tilgængelighedszoner (Zone-A og Zone-B). På grund af knudefejl i Zone-A er standby-tilgængelighedszonen (Zone-C) ikke åben for at tage shard-forespørgselstrafik, så der ikke er nogen indvirkning på søgeanmodningerne. Til sidst opdages Zone-A som usund, og read failover skifter standby til Zone-A.
Hvordan failover sikrer høj tilgængelighed under skriveforringelse
OpenSearch Service-replikeringsmodellen følger en primær backup-model, karakteriseret ved dens synkrone karakter, hvor bekræftelse fra alle shard kopier er nødvendig, før en skriveanmodning kan bekræftes til brugeren. En bemærkelsesværdig ulempe ved denne replikeringsmodel er dens modtagelighed for opbremsninger i tilfælde af enhver forringelse af skrivestien. Disse systemer er afhængige af en aktiv lederknude til at identificere fejl eller forsinkelser og derefter udsende denne information til alle knudepunkter. Den varighed, det tager at opdage disse problemer (gennemsnitlig tid til at opdage) og efterfølgende løse dem (gennemsnitlig tid til reparation), bestemmer i høj grad, hvor længe systemet vil fungere i en svækket tilstand. Derudover kan enhver netværksbegivenhed, der påvirker inter-zone-kommunikation, betydeligt hæmme skriveanmodninger på grund af replikeringens synkrone natur.
OpenSearch Service bruger en intern node-to-node kommunikationsprotokol til at replikere skrivetrafik og koordinere metadataopdateringer gennem en valgt leder. At sætte den zone, der oplever stress i standby, ville derfor ikke effektivt løse problemet med skriveforringelse.
Zonal write failover: Afskæring af inter-zone replikeringstrafik
For Multi-AZ med Standby, for at afbøde potentielle ydeevneproblemer forårsaget under uforudsete hændelser som zonefejl og netværksbegivenheder, er zonal skrive-failover en effektiv tilgang. Denne tilgang involverer en yndefuld fjernelse af knudepunkter i den påvirkede zone fra klyngen, hvilket effektivt afskærer ind- og udgående trafik mellem zoner. Ved at afbryde replikationstrafikken mellem zoner kan virkningen af zonefejl begrænses inden for den berørte zone. Dette giver en mere forudsigelig oplevelse for kunderne og sikrer, at systemet fortsætter med at fungere pålideligt.
Yndefuld skrive-failover
Orkestreringen af en skrivefailover inden for OpenSearch Service udføres af den valgte lederknude gennem en veldefineret mekanisme. Denne mekanisme involverer en konsensusprotokol for klyngestatspublikation, der sikrer enstemmig enighed mellem alle noder om at udpege en enkelt zone (til enhver tid) til nedlukning. Det er vigtigt, at metadata relateret til den berørte zone replikeres på tværs af alle noder for at sikre dens vedholdenhed, selv under en fuld genstart i tilfælde af en udfald.
Ydermere sikrer lederknudepunktet en jævn og yndefuld overgang ved indledningsvis at placere knudepunkterne i de ramte zoner på standby i en varighed på 5 minutter, før I/O-hegn påbegyndes. Denne bevidste tilgang forhindrer ny koordinatortrafik eller shard-forespørgselstrafik i at blive dirigeret til knudepunkterne i den berørte zone. Dette giver igen disse knudepunkter mulighed for at fuldføre deres igangværende opgaver på en yndefuld måde og gradvist håndtere eventuelle anmodninger om fly, før de tages ud af drift. Følgende diagram illustrerer denne arkitektur.
I processen med at implementere en skrivefailover for en ledernode, følger OpenSearch Service disse nøgletrin:
- Leder abdikation – Hvis ledernoden tilfældigvis er placeret i en zone, der er planlagt til skrivefailover, sikrer systemet, at ledernoden frivilligt trækker sig fra sin lederrolle. Denne abdikation udføres på en kontrolleret måde, og hele processen overdrages til en anden berettiget node, som derefter tager ansvaret for de nødvendige handlinger.
- Forhindre genvalg af leder, der skal nedlægges – For at forhindre genvalg af en leder fra en zone markeret til skrivefailover, når den berettigede lederknude starter skrivefailoverhandlingen, træffer den foranstaltninger for at sikre, at eventuelle lederknudepunkter, der skal nedlægges, ikke deltager i yderligere valg. Dette opnås ved at udelukke lederknuden, der skal nedlægges, fra afstemningskonfigurationen, hvilket effektivt forhindrer den i at stemme under enhver kritisk fase af klyngens drift.
Metadata relateret til skrivefailoverzonen gemmes i klyngetilstanden, og disse oplysninger offentliggøres til alle noder i den distribuerede OpenSearch Service-klynge som følger:
Følgende skærmbillede viser, at under en netværksnedgang i en zone hjælper skrivefejl ved at genoprette tilgængeligheden.
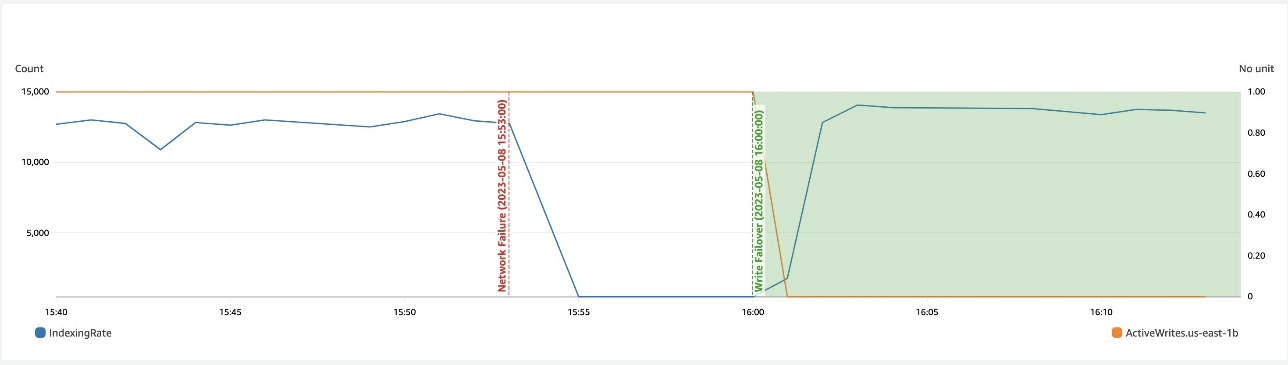
Zonal gendannelse efter skrivefejl
Processen med zonal recommissioning spiller en afgørende rolle i gendannelsesfasen efter en zonal write failover. Efter at den påvirkede zone er blevet gendannet og anses for at være stabil, vil de knudepunkter, der tidligere var nedlagt, slutte sig til klyngen igen. Denne idriftsættelse sker typisk inden for en tidsramme på 2 minutter efter, at zonen er blevet genindført.
Dette sætter dem i stand til at synkronisere med deres peer-knudepunkter og initierer gendannelsesprocessen for replika-shards, hvilket effektivt genopretter klyngen til dens ønskede tilstand.
Konklusion
Introduktionen af OpenSearch Service Multi-AZ med Standby giver virksomheder en kraftfuld løsning til at opnå høj tilgængelighed og ensartet ydeevne til kritiske arbejdsbelastninger. Med denne implementeringsmulighed kan virksomheder forbedre deres infrastrukturs modstandsdygtighed, forenkle klyngekonfiguration og -administration og håndhæve bedste praksis. Med funktioner som vægtet round-robin shard copy-valg, proaktive failover-mekanismer og fail-open standby-tilgængelighedszoner, sikrer OpenSearch Service Multi-AZ med Standby en pålidelig og effektiv søgeoplevelse til krævende virksomhedsmiljøer.
For mere information om Multi-AZ med Standby, se Amazon OpenSearch Service Under the Hood: Multi-AZ med Standby.
Om forfatteren
 Anshu Agarwal er en senior softwareingeniør, der arbejder på AWS OpenSearch hos Amazon Web Services. Hun brænder for at løse problemer relateret til at bygge skalerbare og yderst pålidelige systemer.
Anshu Agarwal er en senior softwareingeniør, der arbejder på AWS OpenSearch hos Amazon Web Services. Hun brænder for at løse problemer relateret til at bygge skalerbare og yderst pålidelige systemer.
 Rishab Nahata er en softwareingeniør, der arbejder på OpenSearch hos Amazon Web Services. Han er fascineret af at løse problemer i distribuerede systemer. Han er aktiv bidragyder til OpenSearch.
Rishab Nahata er en softwareingeniør, der arbejder på OpenSearch hos Amazon Web Services. Han er fascineret af at løse problemer i distribuerede systemer. Han er aktiv bidragyder til OpenSearch.
 Bukhtawar Khan er en Principal Engineer, der arbejder på Amazon OpenSearch Service. Han er interesseret i distribuerede og autonome systemer. Han er en aktiv bidragyder til OpenSearch.
Bukhtawar Khan er en Principal Engineer, der arbejder på Amazon OpenSearch Service. Han er interesseret i distribuerede og autonome systemer. Han er en aktiv bidragyder til OpenSearch.
 Ranjith Ramachandra er en Engineering Manager, der arbejder på Amazon OpenSearch Service hos Amazon Web Services.
Ranjith Ramachandra er en Engineering Manager, der arbejder på Amazon OpenSearch Service hos Amazon Web Services.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :har
- :er
- :ikke
- :hvor
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Om
- opnå
- opnået
- erkendte
- tværs
- Lov
- Handling
- aktioner
- aktiv
- adaptive
- Derudover
- adresse
- påvirket
- Efter
- Aftale
- algoritme
- algoritmer
- Alle
- tillade
- Amazon
- Amazon Web Services
- blandt
- an
- ,
- En anden
- enhver
- tilgang
- arkitektur
- ER
- AS
- tildelt
- At
- autonom
- autonome systemer
- tilgængelighed
- bevidsthed
- AWS
- backup
- swing
- BE
- fordi
- været
- før
- være
- BEDSTE
- bedste praksis
- mellem
- både
- udsende
- Bygning
- virksomheder
- by
- CAN
- Kapacitet
- gennemføres
- forårsagede
- kendetegnet
- afgift
- afkrydset
- Cluster
- Kommunikation
- Kommunikation
- fuldføre
- Konfiguration
- Konsensus
- følgelig
- betragtes
- konsekvent
- Konsol
- indeholdt
- fortsætter
- kontinuerlig
- bidrage
- bidragsyder
- kontrolleret
- koordinerende
- Koordinator
- koordinatorer
- kopier
- dækket
- skabe
- skaber
- kritisk
- afgørende
- Kunder
- skære
- data
- beslutte
- dyb
- dyb dykke
- definerer
- forsinkelser
- dykke
- krævende
- implementering
- udruller
- udpeget
- konstrueret
- ønskes
- opdage
- opdaget
- bestemmer
- rettet
- Forstyrrelse
- distribueret
- distribuerede systemer
- dyk
- do
- dokumenter
- domæne
- Domæner
- Dont
- ned
- grund
- varighed
- i løbet af
- hver
- Effektiv
- effektivt
- effektiv
- valgt
- Valg
- berettiget
- eliminere
- aktiveret
- muliggør
- håndhæve
- ingeniør
- Engineering
- forbedre
- forbedret
- styrke
- sikre
- sikrer
- sikring
- Enterprise
- Hele
- miljøer
- især
- Ether (ETH)
- Endog
- begivenhed
- begivenheder
- til sidst
- Hver
- Eksklusive
- erfaring
- oplever
- udforske
- mislykkes
- Manglende
- fejl
- Feature
- Funktionalitet
- hegn
- Fornavn
- efter
- følger
- Til
- FRAME
- fra
- fuld
- yderligere
- gif
- Yndefuld
- gradvist
- garanti
- hånd
- håndtere
- Håndterer
- sker
- he
- sund
- hjælper
- Høj
- stærkt
- hætte
- Hosting
- Hvordan
- http
- HTTPS
- identificere
- if
- illustrerer
- KIMOs Succeshistorier
- påvirket
- leverfunktion
- gennemføre
- vigtigere
- in
- omfatter
- angiver
- oplysninger
- Infrastruktur
- i første omgang
- Indleder
- initiere
- forekomster
- interesseret
- interne
- ind
- introduceret
- Introduktion
- involverer
- spørgsmål
- spørgsmål
- IT
- ITS
- jpg
- json
- Nøgle
- kendt
- vid udstrækning
- leder
- Leadership" (virkelig menneskelig ledelse)
- ligesom
- Liste
- belastning
- lokalt
- placeret
- Lang
- vedligeholde
- opretholdelse
- lykkedes
- ledelse
- leder
- måde
- markeret
- matchede
- betyde
- midler
- foranstaltninger
- mekanisme
- mekanismer
- Metadata
- Metrics
- minut
- minutter
- afbøde
- tilstand
- model
- mere
- bevægelse
- Natur
- nødvendig
- Behov
- netværk
- netværk
- Ny
- ingen
- node
- noder
- bemærkelsesværdig
- objekt
- of
- off
- on
- ONE
- igangværende
- kun
- åbent
- betjene
- drift
- Produktion
- Option
- or
- orkestrering
- ordrer
- Andet
- ud
- nedbrud
- udfald
- i løbet af
- deltage
- dele
- lidenskabelige
- sti
- stier
- peer
- ydeevne
- udholdenhed
- fase
- anbringelse
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Indlæg
- potentiale
- vigtigste
- praksis
- forud
- Forudsigelig
- forhindre
- forebyggelse
- forhindrer
- tidligere
- primære
- Main
- Proaktiv
- problemer
- behandle
- fremme
- protokol
- give
- giver
- Offentliggørelse
- offentliggjort
- Sætte
- forespørgsler
- Læs
- modtage
- modtager
- for nylig
- Recover
- komme sig
- opsving
- henvise
- region
- fast
- relaterede
- relevant
- pålidelighed
- pålidelig
- stole
- resterende
- fjernelse
- reparere
- svar
- replikeres
- replikation
- anmode
- anmodninger
- påkrævet
- modstandskraft
- elastisk
- løse
- ansvarlige
- genoprette
- restaureret
- genoprette
- roller
- routing
- Kør
- løber
- s
- sikkerhedsforanstaltninger
- samme
- skalerbar
- planlagt
- problemfrit
- Søg
- valg
- afsendelse
- sender
- senior
- sendt
- tjeneste
- Tjenester
- sæt
- hun
- vist
- betydeligt
- enkelhed
- forenkle
- enkelt
- Sænk farten
- opbremsninger
- udjævne
- So
- Software
- Software Engineer
- løsninger
- Løsning
- stabil
- Tilstand
- Status
- steady
- Steps
- opbevaret
- stress
- Efterfølgende
- vellykket
- modtagelighed
- systemet
- Systemer
- Tag
- taget
- tager
- opgaver
- at
- deres
- Them
- derefter
- Der.
- Disse
- denne
- dem
- tre
- Gennem
- tid
- gange
- til
- tolerance
- Trafik
- overgang
- TUR
- to
- typisk
- under
- underliggende
- uforudset
- opdateringer
- anvendte
- Bruger
- bruger
- ved brug af
- udnytter
- forskellige
- frivilligt
- Afstemningen
- we
- web
- webservices
- vægt
- GODT
- veldefinerede
- var
- hvornår
- som
- mens
- vilje
- med
- inden for
- arbejder
- virker
- skriver
- zephyrnet
- nul
- zoner