Billede af forfatter
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
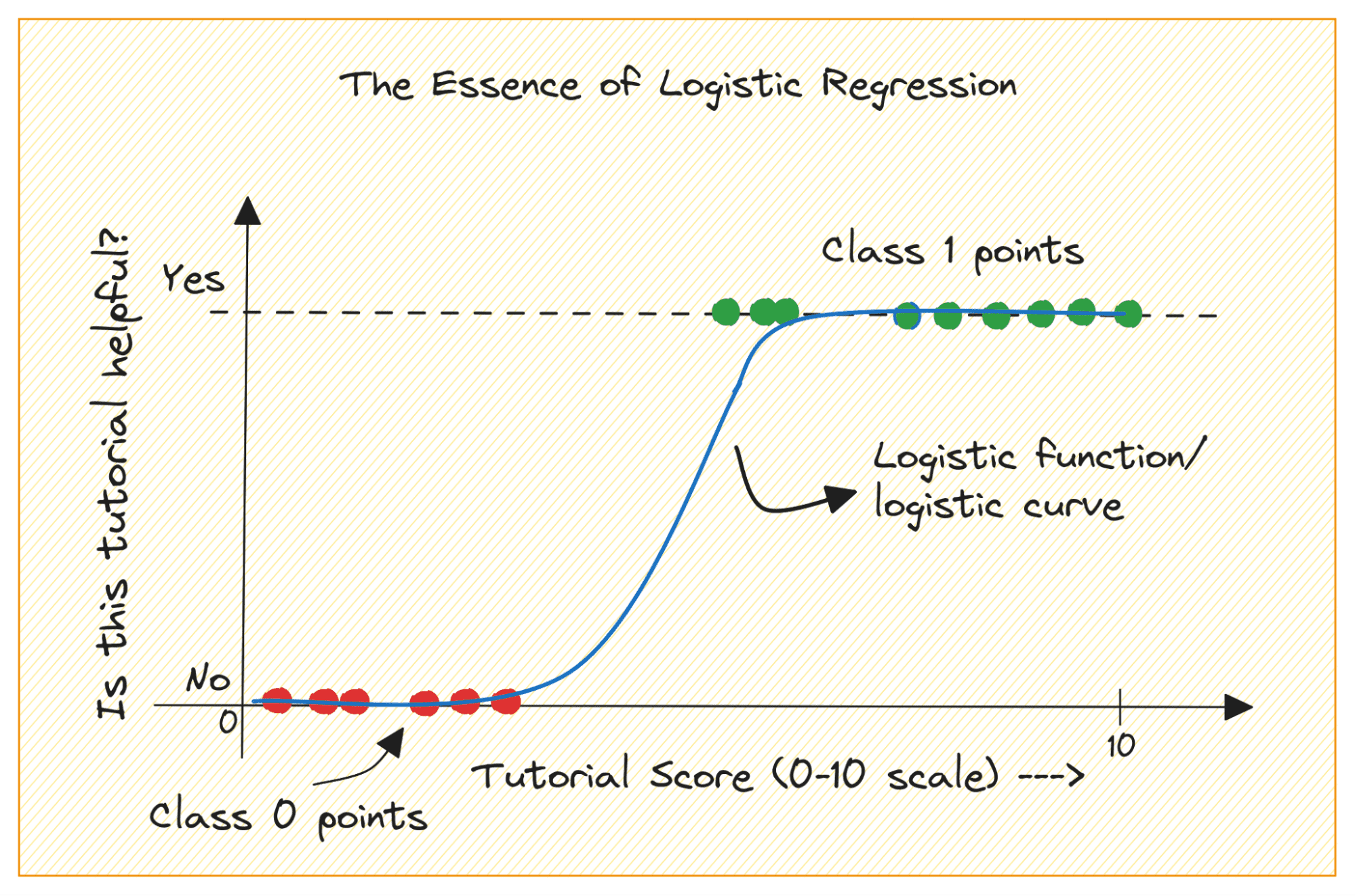
Overvej et binært klassifikationsproblem med klasse 0 og 1. Logistisk regression tilpasser en logistisk eller sigmoid-funktion til inputdataene og forudsiger sandsynligheden for, at et forespørgselsdatapunkt tilhører klasse 1. Interessant, ja?
I denne tutorial lærer vi om logistisk regression fra bunden, der dækker:
- Den logistiske (eller sigmoid) funktion
- Hvordan vi bevæger os fra lineær til logistisk regression
- Sådan fungerer logistisk regression
Til sidst bygger vi en simpel logistisk regressionsmodel til klassificere RADAR returnerer fra ionosfæren.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

Når du plotter sigmoid-funktionen, vil det se sådan ud:
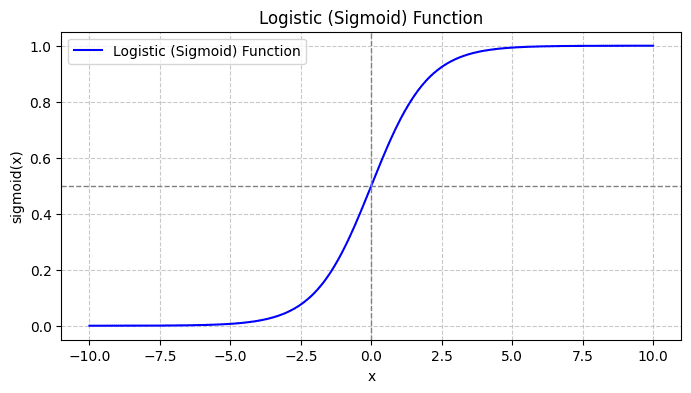
Fra plottet ser vi, at:
- Når x = 0, får σ(x) en værdi på 0.5.
- Når x nærmer sig +∞, nærmer σ(x) sig 1.
- Når x nærmer sig -∞, nærmer σ(x) sig 0.
Så for alle reelle input klemmer sigmoid-funktionen dem til at antage værdier i området [0, 1].
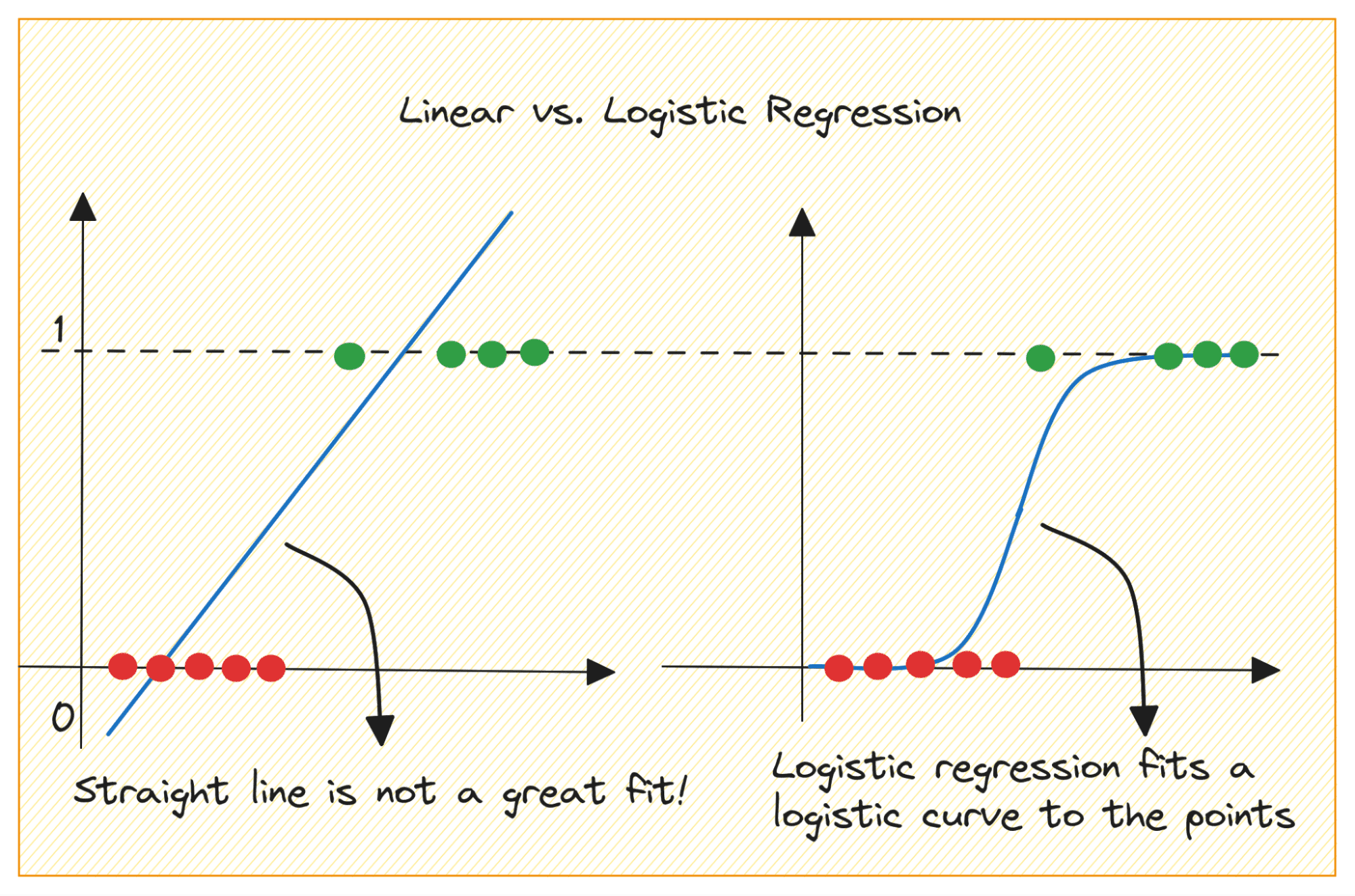
Let’s first discuss why we cannot use linear regression for a binary classification problem.
I et binært klassifikationsproblem er outputtet kategorisk etiket (0 eller 1). Fordi lineær regression forudsiger output med kontinuerlig værdi, som kan være mindre end 0 eller større end 1, giver det ikke mening for det aktuelle problem.
Desuden er en lige linje muligvis ikke den bedste pasform, når outputetiketterne tilhører en af de to kategorier.
Billede af forfatter
Så hvordan går vi fra lineær til logistisk regression? Ved lineær regression er det forudsagte output givet ved:
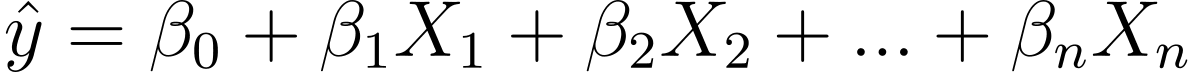
Hvor β'erne er koefficienterne og X_is er prædiktorerne (eller funktionerne).
Uden tab af generelitet, lad os antage X_0 = 1:

Så vi kan have et mere kortfattet udtryk:
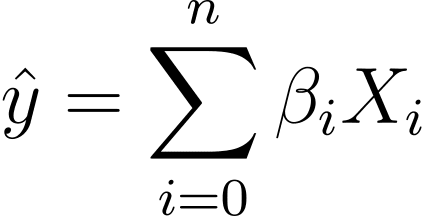
I logistisk regression har vi brug for den forudsagte sandsynlighed p_i i [0,1] intervallet. Vi ved, at den logistiske funktion klemmer input, så de antager værdier i intervallet [0,1].
Så indsætter vi dette udtryk i den logistiske funktion, har vi den forudsagte sandsynlighed som:
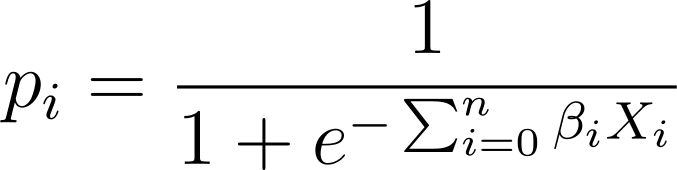
Så hvordan finder vi den logistiske kurve, der passer bedst til det givne datasæt? For at besvare dette, lad os forstå maksimal sandsynlighedsestimat.
Maximum Likelihood Estimation (MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
Nedbrydning af maksimal sandsynlighedsvurdering
Som diskuteret modellerer vi sandsynligheden for, at et binært udfald forekommer som en funktion af en eller flere prædiktorvariable (eller funktioner):
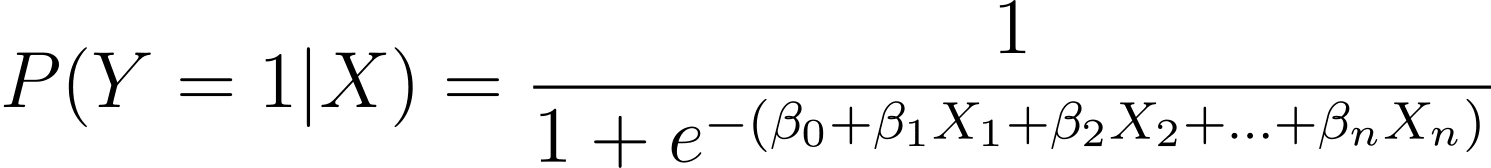
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
MLE har til formål at finde de værdier af β, der maksimerer sandsynligheden for de observerede data. Sandsynlighedsfunktionen, betegnet som L(β), repræsenterer sandsynligheden for at observere de givne udfald for de givne prædiktorværdier under den logistiske regressionsmodel.
Formulering af Log-Likelihood-funktionen
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
Log-sandsynlighedsfunktionen for logistisk regression er givet af:
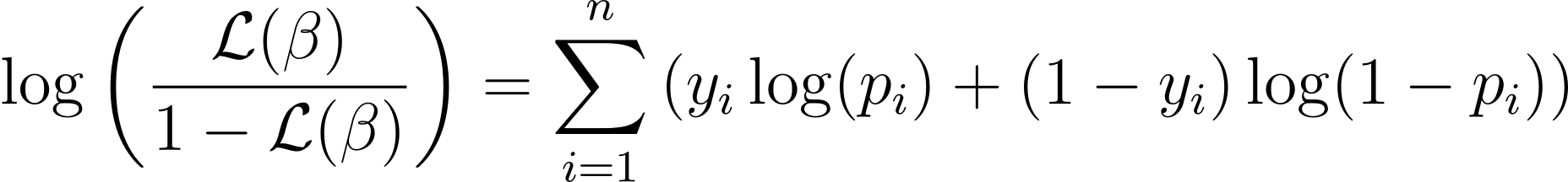
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
Omkostningsfunktion for logistisk regression
For at optimere den logistiske regressionsmodel skal vi maksimere logsandsynligheden. Så vi kan bruge den negative log-sandsynlighed som omkostningsfunktionen til at minimere under træning. Den negative log-sandsynlighed, ofte omtalt som det logistiske tab, er defineret som:
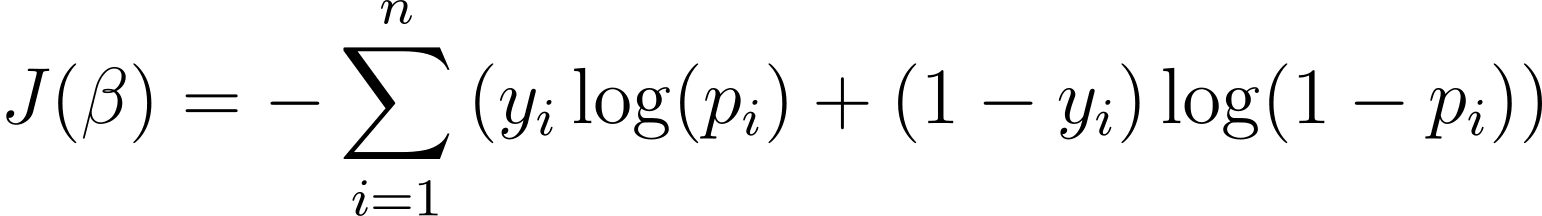
Målet med læringsalgoritmen er derfor at finde værdierne af ? som minimerer denne omkostningsfunktion. Gradient descent er en almindeligt brugt optimeringsalgoritme til at finde minimum af denne omkostningsfunktion.
Gradient Descent i logistisk regression
Gradient nedstigning er en iterativ optimeringsalgoritme, der opdaterer modelparametrene β i den modsatte retning af omkostningsfunktionens gradient i forhold til β. Opdateringsreglen i trin t+1 for logistisk regression ved brug af gradientnedstigning er som følger:
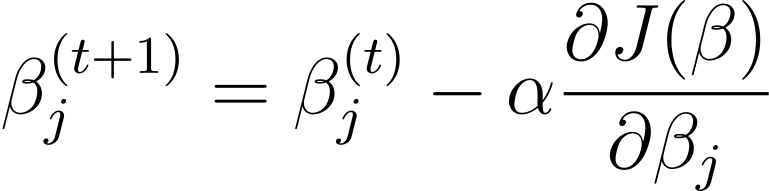
Hvor α er indlæringshastigheden.
De partielle afledte kan beregnes ved hjælp af kædereglen. Gradientnedstigning opdaterer iterativt parametrene – indtil konvergens – med det formål at minimere det logistiske tab. Når den konvergerer, finder den de optimale værdier af β, der maksimerer sandsynligheden for de observerede data.
Nu hvor du ved, hvordan logistisk regression fungerer, lad os bygge en forudsigelig model ved hjælp af scikit-learn-biblioteket.
Vi bruger ionosfære-datasæt fra UCI-maskinindlæringsarkivet til denne tutorial. Datasættet omfatter 34 numeriske funktioner. Outputtet er binært, et af 'god' eller 'dårlig' (betegnet med 'g' eller 'b'). Outputmærket 'god' refererer til RADAR-returneringer, der har opdaget en vis struktur i ionosfæren.
Trin 1 – Indlæsning af datasættet
Download først datasættet og læs det ind i en pandas dataramme:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Trin 2 – Udforskning af datasættet
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
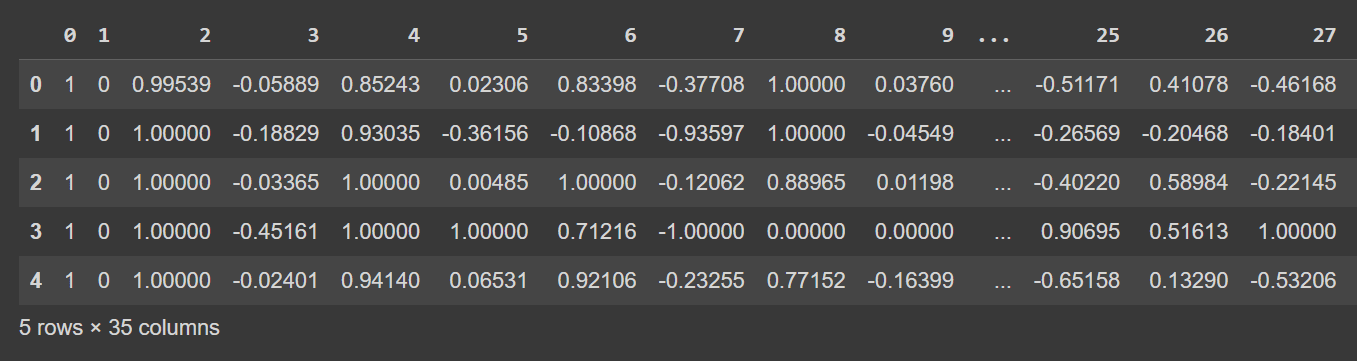
Trunkeret output af df.head()
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
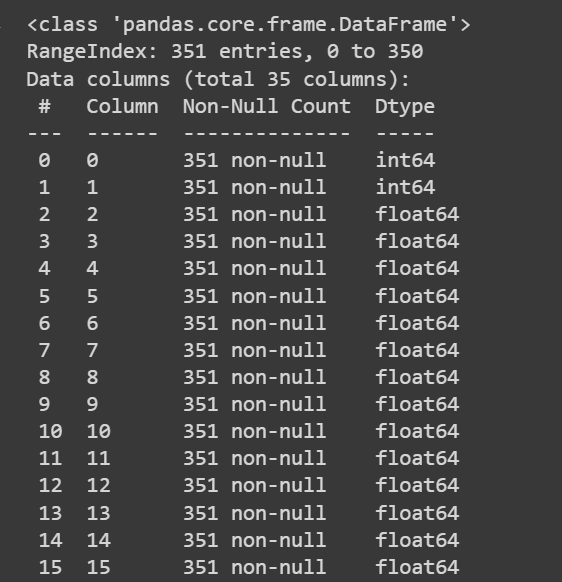 Trunkeret output af df.info()
Trunkeret output af df.info()
Fordi vi har alle numeriske funktioner, kan vi også få nogle beskrivende statistikker ved hjælp af describe() metode på datarammen:
# Get descriptive statistics of the dataset
print(df.describe())
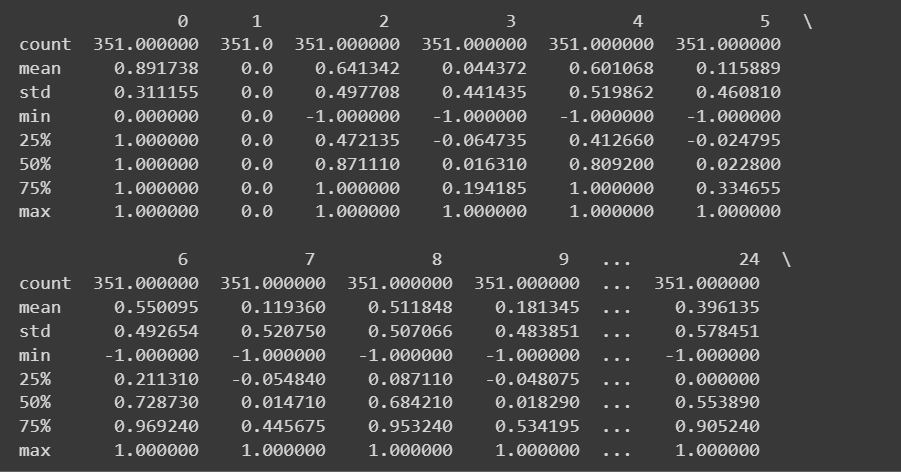
Trunkeret output af df.describe()
Kolonnenavnene er i øjeblikket 0 til 34 – inklusive etiketten. Fordi datasættet ikke giver beskrivende navne til kolonnerne, refererer det blot til dem som attribut_1 til attribut_34, hvis du vil, kan du omdøbe kolonnerne i datarammen som vist:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Bemærk: Dette trin er udelukkende valgfrit. Du kan fortsætte med standardkolonnenavnene, hvis du foretrækker det.
# Display the first few rows of the DataFrame
df.head()
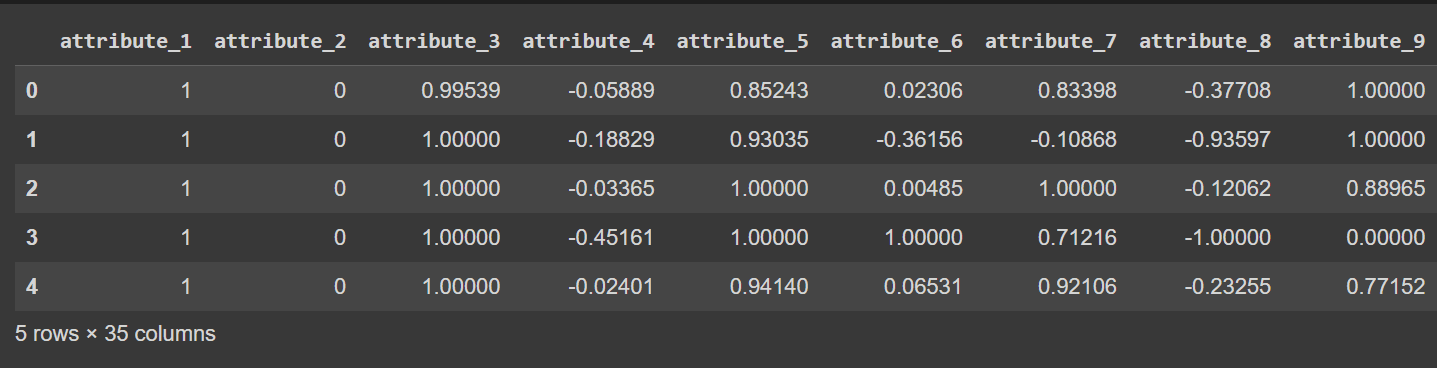
Trunkeret output af df.head() [Efter omdøbning af kolonner]
Trin 3 – Omdøbning af klasseetiketter og visualisering af klassefordeling
Fordi outputklasseetiketterne er 'g' og 'b', skal vi kortlægge dem til henholdsvis 1 og 0 . Du kan gøre det vha map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Lad os også visualisere fordelingen af klasseetiketterne:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
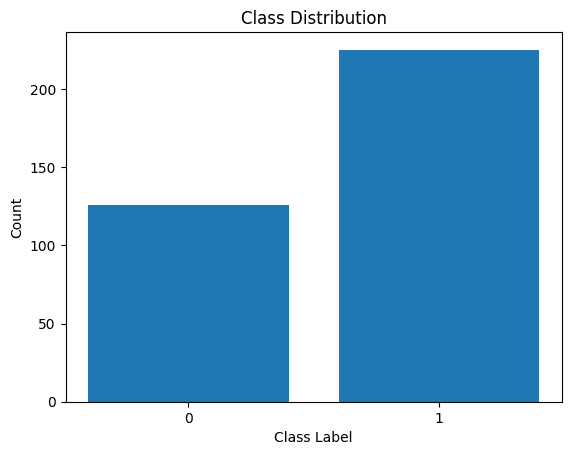
Fordeling af klasseetiketter
Vi ser, at der er ubalance i fordelingen. Der er flere poster, der tilhører klasse 1 end til klasse 0. Vi håndterer denne klasseubalance, når vi bygger den logistiske regressionsmodel.
Trin 5 – Forbehandling af datasættet
Lad os samle funktionerne og outputetiketterne som sådan:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Efter at have opdelt datasættet i tog- og testsæt, skal vi forbehandle datasættet.
Når der er mange numeriske funktioner – hver på en potentielt forskellig skala – skal vi forbehandle de numeriske funktioner. En almindelig metode er at transformere dem, så de følger en fordeling med nul middelværdi og enhedsvarians.
StandardScaler fra scikit-learns forbehandlingsmodul hjælper os med at opnå dette.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Trin 6 – Opbygning af en logistisk regressionsmodel
Nu kan vi instansiere en logistisk regressionsklassifikator. Det LogisticRegression klasse er en del af scikit-learns linear_model-modul.
Bemærk, at vi har indstillet class_weight parameter til 'balanceret'. Dette vil hjælpe os med at redegøre for klasseubalancen. Ved at tildele vægte til hver klasse - omvendt proportional med antallet af poster i klasserne.
Efter at have instansieret klassen, kan vi tilpasse modellen til træningsdatasættet:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Trin 7 – Evaluering af den logistiske regressionsmodel
Du kan ringe til predict() metode til at få modellens forudsigelser.
Ud over nøjagtighedsscoren kan vi også få en klassifikationsrapport med målinger som præcision, tilbagekaldelse og F1-score.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
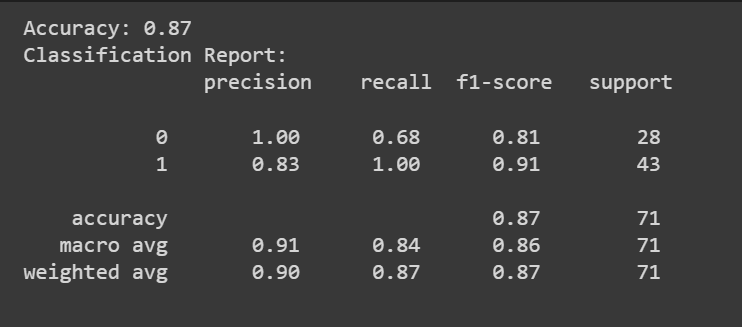
Tillykke, du har kodet din første logistiske regressionsmodel!
I denne tutorial lærte vi om logistisk regression i detaljer: fra teori og matematik til kodning af en logistisk regressionsklassifikator.
Som et næste trin kan du prøve at bygge en logistisk regressionsmodel til et passende datasæt efter eget valg.
Ionosphere-datasættet er licenseret under en Creative Commons Attribution 4.0 International (CC BY 4.0) licens:
Sigillito, V., Wing, S., Hutton, L., og Baker, K.. (1989). Ionosfære. UCI Machine Learning Repository. https://doi.org/10.24432/C5W01B.
Bala Priya C er en udvikler og teknisk skribent fra Indien. Hun kan lide at arbejde i krydsfeltet mellem matematik, programmering, datavidenskab og indholdsskabelse. Hendes interesseområder og ekspertise omfatter DevOps, datavidenskab og naturlig sprogbehandling. Hun nyder at læse, skrive, kode og kaffe! I øjeblikket arbejder hun på at lære og dele sin viden med udviklerfællesskabet ved at skrive selvstudier, vejledninger, meningsindlæg og mere.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :er
- :ikke
- $OP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Om
- Konto
- nøjagtighed
- opnå
- tilføje
- Desuden
- Efter
- målsætninger
- algoritme
- algoritmer
- Alle
- også
- an
- ,
- besvare
- tilgange
- ER
- områder
- AS
- antage
- At
- forfatter
- b
- bager
- Balanceret
- Bar
- BE
- fordi
- tilhører
- BEDSTE
- Pause
- bygge
- Bygning
- by
- ringe
- CAN
- kan ikke
- kategorier
- kæde
- valg
- klasse
- klasser
- klassificering
- kodet
- Kodning
- indsamler
- Kolonne
- Kolonner
- Fælles
- almindeligt
- Commons
- samfund
- omfatter
- kortfattet
- indhold
- indholdsskabelse
- konvertere
- Koste
- dækker
- skabe
- skabelse
- For øjeblikket
- skøger
- data
- datapunkter
- datalogi
- datasæt
- Standard
- definerede
- Derivater
- detail
- opdaget
- Udvikler
- DevOps
- forskellige
- retning
- diskutere
- drøftet
- Skærm
- fordeling
- do
- gør
- ned
- downloade
- i løbet af
- hver
- Essensen
- skøn
- evaluere
- ekspertise
- Udforskning
- udtryk
- Funktionalitet
- få
- Finde
- finde
- fund
- Fornavn
- passer
- følger
- følger
- Til
- FRAME
- fra
- funktion
- få
- få
- given
- Go
- mål
- større
- Ground
- Guides
- hånd
- håndtere
- Have
- hjælpe
- hjælper
- hende
- Hvordan
- HTTPS
- ICS
- if
- ubalance
- importere
- in
- omfatter
- indeks
- Indien
- Indeks
- oplysninger
- indgang
- indgange
- interesse
- interessant
- vejkryds
- ind
- IT
- lige
- KDnuggets
- Kend
- viden
- etiket
- Etiketter
- Sprog
- LÆR
- lærte
- læring
- mindre
- lad
- Bibliotek
- Licens
- Licenseret
- ligesom
- sandsynlighed
- synes godt om
- Line (linje)
- lastning
- log
- Se
- ligner
- off
- maskine
- machine learning
- lave
- mange
- kort
- matematik
- matplotlib
- Maksimer
- maksimere
- maksimal
- Kan..
- betyde
- metode
- Metrics
- minimere
- minimum
- model
- modeller
- modul
- mere
- bevæge sig
- navne
- Natural
- Naturligt sprog
- Natural Language Processing
- Behov
- negativ
- næste
- nummer
- observeret
- of
- tit
- on
- ONE
- Udtalelse
- modsat
- optimal
- optimering
- Optimer
- or
- Resultat
- udfald
- output
- udgange
- pandaer
- parameter
- parametre
- del
- stykker
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- punkter
- potentielt
- Precision
- forudsagde
- Forudsigelser
- forudsigende
- Predictor
- forudser
- foretrække
- sandsynlighed
- Problem
- Fortsæt
- behandle
- forarbejdning
- Produkter
- Programmering
- give
- rent
- Python
- radar
- rækkevidde
- Sats
- Læs
- Læsning
- ægte
- optegnelser
- benævnt
- refererer
- regression
- indberette
- Repository
- repræsenterer
- anmode
- respekt
- henholdsvis
- afkast
- gennemgå
- robust
- Herske
- s
- Videnskab
- scikit-lære
- score
- se
- forstand
- sæt
- sæt
- deling
- hun
- vist
- Simpelt
- forenkle
- So
- nogle
- delt
- påbegyndt
- statistik
- Trin
- lige
- struktur
- Efterfølgende
- sådan
- egnede
- beløb
- Tag
- tager
- mål
- opgaver
- Teknisk
- prøve
- Test
- end
- at
- Them
- teori
- Der.
- derfor
- de
- denne
- Gennem
- til
- Værktøjskasse
- Tog
- uddannet
- Kurser
- Transform
- transformationer
- prøv
- tutorial
- tutorials
- to
- typer
- under
- forstå
- enhed
- Opdatering
- opdateringer
- URL
- us
- amerikansk konto
- brug
- anvendte
- ved brug af
- værdi
- Værdier
- Visualiser
- we
- hvornår
- som
- hvorfor
- Wikipedia
- vilje
- Vinge
- med
- Arbejde
- arbejder
- virker
- ville
- forfatter
- skrivning
- X
- Ja
- dig
- Din
- zephyrnet
- nul







