Billede fra Pexels
Sidste vinter holdt jeg et oplæg om 'Mere forudsigelig tidsseriemodel med BQML'kl GDG DevFest Tashkent 2022 i Tasjkent, Usbekistans hovedstad.
Jeg havde tænkt mig at dele noget af materialet og koden efter DevFest, jeg brugte i præsentationen, men tiden er gået, og der er udgivet nye funktioner i BQML, som overlapper noget af indholdet.
Derfor vil jeg i stedet kort nævne de nye funktioner og nogle af de ting, der stadig er gældende.
Tidsseriedata bruges af mange organisationer til en række forskellige formål, og det er vigtigt at bemærke, at "forudsigende analytisks" handler om "fremtiden" i tid. Forudsigende analyse af tidsserier er blevet brugt på kort, mellemlang og lang sigt, og selvom den har mange unøjagtigheder og risici, er den også blevet støt forbedret.
Da "forudsigelse" ser ud til at være så nyttig, kan du blive fristet til at anvende en tidsserieforudsigelsesmodel, hvis du har tidsseriedata. Men tidsserieforudsigelsesmodeller er normalt beregningsintensive, og hvis du har mange data, vil det være mere beregningsintensivt. Så det er besværligt og svært at behandle det, indlæse det til analysemiljøet og analysere det
Hvis du bruger Google BigQuery til datahåndtering, kan du bruge BQML (BigQuery ML) til at anvende maskinlæringsalgoritmer til dine data på en enkel, nem og hurtig måde. Mange mennesker bruger BigQuery til at behandle en masse data, og mange af disse data er ofte tidsseriedata. Og BQML understøtter også tidsseriemodeller.
Grundlaget for den tidsseriemodel, der i øjeblikket understøttes af BQML, er AutoRegressive Integrated Moving Average (ARIMA) model. ARIMA-modellen forudsiger kun at bruge eksisterende tidsseriedata og er kendt for at have god kortsigtet forudsigelsesydelse, og da den kombinerer AR og MA, er det en populær model, der kan dække en bred vifte af tidsseriemodeller.
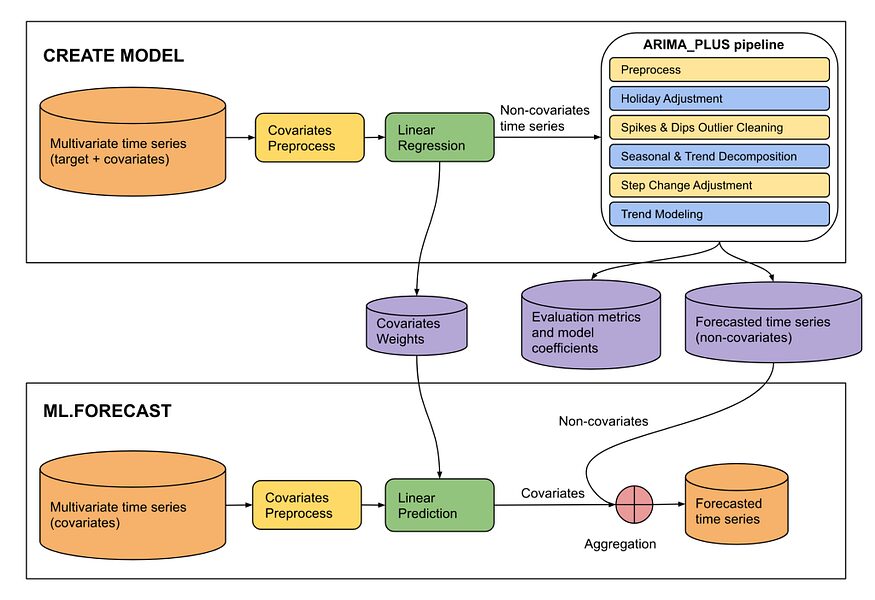
Denne model er dog samlet set beregningsintensiv, og da den kun bruger tidsseriedata med normalitet, er det svært at bruge den i tilfælde med trends eller sæsonbestemte. Derfor, ARIMA_PLUS i BQML indeholder flere ekstra funktioner som muligheder. Du kan tilføje tidsserienedbrydning, sæsonbestemte faktorer, spidser og fald, koefficientændringer og mere til din model, eller du kan gennemgå dem separat og justere modellen manuelt. Jeg kan også personligt godt lide det faktum, at du kan justere for periodicitet ved automatisk at inkorporere feriemuligheder, hvilket er en af fordelene ved at bruge en platform, der ikke kræver, at du manuelt tilføjer oplysninger relateret til datoer.
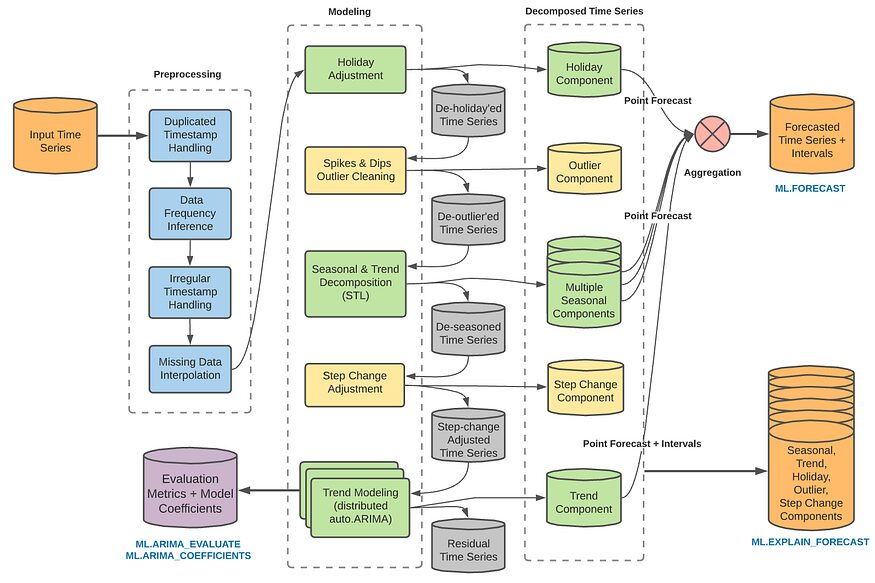
Struktur af ARIMA_PLUS (fra BQML manual)
Du kan henvise til dette side for mere information.
Men når det kommer til applikationer i den virkelige verden, er forudsigelse af tidsserier ikke så enkel som dette. Selvfølgelig har vi været i stand til at identificere flere cyklusser og tilføje indgreb til flere tidsserier med ARIMA_PLUS, men der er mange eksterne faktorer relateret til tidsseriedata, og kun meget få hændelser sker isoleret. Stationaritet kan være svær at finde i tidsseriedata.
I den originale præsentation så jeg på, hvordan man håndterer disse tidsseriedata fra den virkelige verden for at lave en forudsigelsesmodel til nedbryde disse tidsserier, ryd op i de dekomponerede data, importer dem til Python og derefter væv det med andre variabler for at skabe en multivariat tidsseriefunktion, estimere kausalitet og inkorporere den i en forudsigelsesmodel og estimere, i hvilken grad effekten varierer med ændringer i hændelser.
Og i de sidste par måneder, en ny funktion til at skabe multivariate tidsseriefunktioner med eksterne variable(ARIMA_PLUS_XREG, XREG nedenfor) er blevet en direkte funktion i BQML.
Du kan læse alt om det link.(den er i preview fra juli 2023, men jeg gætter på, at den vil være tilgængelig senere i år).
Jeg ansøger den officielle tutorial for at se, hvordan den kan sammenlignes med en traditionel univariat tidsseriemodel, og vi kan se, hvordan den fungerer.
Trinene er de samme som i selvstudiet, så jeg vil ikke duplikere dem, men her er de to modeller, jeg har lavet. Først lavede jeg en traditionel ARIMA_PLUS model og derefter en XREG model, der bruger de samme data, men tilføjer temperatur og vindhastighed på det tidspunkt.
# ARIMA_PLUS
# ARIMA_PLUS
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_plus_model
OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'pm25') AS
SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
#ARIMA_PLUS_XREG
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_xreg_model OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', time_series_data_col = 'pm25') AS
SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
En model, der bruger disse flere data, ville se sådan ud
Struktur ARIMA_PLUS_XREG (fra BQML manual)
To modeller sammenlignes med ML.Evaluate.
SELECT * FROM ML.EVALUATE ( MODEL test_dt_us.seattle_pm25_plus_model, ( SELECT date, pm25 FROM test_dt_us.seattle_air_quality_daily WHERE date > DATE('2020-12-31') ))
SELECT * FROM ML.EVALUATE ( MODEL test_dt_us.seattle_pm25_xreg_model, ( SELECT date, pm25, temperature, wind_speed FROM test_dt_us.seattle_air_quality_daily WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
Resultaterne er nedenfor.
ARIMA_PLUS

ARIMA_PLUS_XREG

Du kan se, at XREG-modellen er foran med grundlæggende præstationsmålinger såsom MAE, MSE og MAPE. (Dette er selvfølgelig ikke en perfekt løsning, dataafhængig, og vi kan bare sige, at vi har et andet nyttigt værktøj.)
Multivariat tidsserieanalyse er en tiltrængt mulighed i mange tilfælde, men den er ofte vanskelig at anvende på grund af forskellige årsager. Nu kan vi bruge det, hvis årsagerne er i data- og analysetrin. Det ser ud til, at vi har en god mulighed for det, så det er godt at vide om det, og forhåbentlig vil det være nyttigt i mange tilfælde.
JeongMin Kwon er freelance senior dataforsker med 10+ års praktisk erfaring med at udnytte maskinlæringsmodeller og datamining.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Automotive/elbiler, Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- BlockOffsets. Modernisering af miljømæssig offset-ejerskab. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/07/multivariate-timeseries-prediction-bqml.html?utm_source=rss&utm_medium=rss&utm_campaign=multivariate-time-series-prediction-with-bqml
- :har
- :er
- :ikke
- :hvor
- $OP
- 2023
- 30
- a
- I stand
- Om
- om det
- tilføje
- tilføje
- Yderligere
- Efter
- forude
- algoritmer
- Alle
- også
- an
- analyse
- analytics
- analysere
- ,
- En anden
- applikationer
- Indløs
- AR
- ER
- AS
- At
- automatisk
- til rådighed
- gennemsnit
- grundlæggende
- grundlag
- BE
- bliver
- været
- jf. nedenstående
- fordele
- mellem
- bigquery
- kortvarigt
- men
- by
- CAN
- kapital
- tilfælde
- Ændringer
- kode
- kombinerer
- kommer
- samfund
- sammenlignet
- indhold
- kursus
- dæksel
- skabe
- oprettet
- Oprettelse af
- For øjeblikket
- cykler
- data
- datastyring
- data mining
- dataforsker
- Dato
- Datoer
- deal
- Degree
- svært
- Er ikke
- grund
- let
- effekt
- Miljø
- skøn
- evaluere
- begivenheder
- eksisterende
- erfaring
- ekstern
- Faktisk
- faktorer
- FAST
- Feature
- Funktionalitet
- få
- Finde
- Fornavn
- Til
- freelance
- fra
- funktion
- funktioner
- Go
- gå
- godt
- hands-on
- ske
- Hård Ost
- Have
- link.
- Ferie
- Forhåbentlig
- horisont
- Hvordan
- How To
- HTTPS
- i
- SYG
- identificere
- if
- importere
- vigtigt
- forbedring
- in
- omfatter
- indarbejde
- inkorporering
- oplysninger
- i stedet
- integreret
- ind
- isolation
- IT
- jpg
- juli
- lige
- KDnuggets
- Kend
- kendt
- Efternavn
- senere
- læring
- løftestang
- ligesom
- belastning
- Lang
- Se
- kiggede
- UDSEENDE
- Lot
- maskine
- machine learning
- Making
- ledelse
- manuelt
- mange
- materiale
- medium
- Metrics
- måske
- Mining
- ML
- model
- modeller
- måned
- mere
- flytning
- glidende gennemsnit
- meget tiltrængt
- flere
- Ny
- ny funktion
- Nye funktioner
- nu
- of
- officiel
- tit
- on
- ONE
- kun
- Option
- Indstillinger
- or
- organisationer
- original
- Andet
- samlet
- Bestået
- Mennesker
- perfekt
- ydeevne
- Personligt
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- Forudsigelig
- forudsigelse
- Prediktiv Analytics
- forudser
- præsentation
- Eksempel
- behandle
- formål
- Python
- rækkevidde
- Læs
- virkelige verden
- årsager
- relaterede
- frigivet
- erstatte
- kræver
- risici
- samme
- siger
- Videnskabsmand
- se
- synes
- senior
- Series
- flere
- Del
- Kort
- kort sigt
- Simpelt
- siden
- So
- løsninger
- nogle
- noget
- hastighed
- spikes
- Steps
- Stadig
- sådan
- Understøttet
- Understøtter
- semester
- at
- Hovedstaden
- Them
- derefter
- Der.
- derfor
- Disse
- ting
- denne
- i år
- Gennem
- tid
- Tidsserier
- til
- værktøj
- traditionelle
- Tendenser
- sand
- tutorial
- to
- brug
- anvendte
- bruger
- ved brug af
- sædvanligvis
- udnytter
- Usbekistan
- række
- forskellige
- meget
- var
- Vej..
- we
- hvornår
- som
- mens
- bred
- Bred rækkevidde
- Wikipedia
- vilje
- blæst
- Vinter
- med
- virker
- ville
- år
- år
- dig
- Din
- zephyrnet