
Efterhånden som AI migrerer fra skyen til Edge, ser vi teknologien blive brugt i et stadigt voksende udvalg af brugssager – lige fra anomalidetektion til applikationer, herunder smart shopping, overvågning, robotteknologi og fabriksautomatisering. Derfor er der ingen ensartet løsning. Men med den hurtige vækst af kameraaktiverede enheder er AI blevet mest udbredt til at analysere videodata i realtid for at automatisere videoovervågning for at øge sikkerheden, forbedre driftseffektiviteten og give bedre kundeoplevelser, hvilket i sidste ende opnår en konkurrencefordel i deres brancher . For bedre at understøtte videoanalyse skal du forstå strategierne til optimering af systemydelsen i edge AI-implementeringer.
- Valg af computere i den rigtige størrelse for at opfylde eller overgå de påkrævede ydeevneniveauer. For en AI-applikation skal disse beregningsmotorer udføre funktionerne i hele vision-pipelinen (dvs. video-for- og efterbehandling, neural netværksinferencing).
En dedikeret AI-accelerator, uanset om den er diskret eller integreret i en SoC (i modsætning til at køre AI-inferencing på en CPU eller GPU), kan være påkrævet.
- Forstå forskellen mellem gennemløb og latens; hvorved gennemløb er den hastighed, som data kan behandles i et system, og latens måler databehandlingsforsinkelsen gennem systemet og er ofte forbundet med reaktion i realtid. For eksempel kan et system generere billeddata med 100 billeder i sekundet (gennemstrømning), men det tager 100 ms (latency) for et billede at gå gennem systemet.
- Overvejer muligheden for nemt at skalere AI-ydeevne i fremtiden for at imødekomme voksende behov, skiftende krav og udviklende teknologier (f.eks. mere avancerede AI-modeller for øget funktionalitet og nøjagtighed). Du kan opnå skalering af ydeevne ved hjælp af AI-acceleratorer i modulformat eller med yderligere AI-acceleratorchips.
De faktiske ydeevnekrav er applikationsafhængige. Typisk kan man forvente, at systemet til videoanalyse skal behandle datastrømme, der kommer ind fra kameraer med 30-60 billeder i sekundet og med en opløsning på 1080p eller 4k. Et AI-aktiveret kamera ville behandle en enkelt strøm; et kantapparat ville behandle flere strømme parallelt. I begge tilfælde skal edge AI-systemet understøtte forbehandlingsfunktionerne for at transformere kameraets sensordata til et format, der matcher inputkravene i AI-inferencingssektionen (Figur 1).
Forbehandlingsfunktioner tager de rå data ind og udfører opgaver såsom ændring af størrelse, normalisering og farverumskonvertering, før input tilføres til modellen, der kører på AI-acceleratoren. Forbehandling kan bruge effektive billedbehandlingsbiblioteker som OpenCV til at reducere forbehandlingstiderne. Efterbehandling involverer at analysere resultatet af inferensen. Den bruger opgaver såsom ikke-maksimal undertrykkelse (NMS fortolker output fra de fleste objektdetekteringsmodeller) og billedvisning til at generere handlingsorienteret indsigt, såsom afgrænsningsfelter, klasseetiketter eller konfidensresultater.

Figur 1. Til AI-modelinferencing udføres præ- og efterbehandlingsfunktionerne typisk på en applikationsprocessor.
AI-modelinferencing kan have den ekstra udfordring at behandle flere neurale netværksmodeller pr. frame, afhængigt af applikationens muligheder. Computervision-applikationer involverer normalt flere AI-opgaver, der kræver en pipeline af flere modeller. Desuden er den ene models output ofte den næste models input. Med andre ord afhænger modeller i en applikation ofte af hinanden og skal udføres sekventielt. Det nøjagtige sæt af modeller, der skal udføres, er muligvis ikke statisk og kan variere dynamisk, selv på et billede for billede.
Udfordringen med at køre flere modeller dynamisk kræver en ekstern AI-accelerator med dedikeret og tilstrækkelig stor hukommelse til at gemme modellerne. Ofte er den integrerede AI-accelerator inde i en SoC ude af stand til at styre multi-model arbejdsbyrden på grund af begrænsninger pålagt af delt hukommelsesundersystem og andre ressourcer i SoC.
For eksempel er bevægelsesforudsigelsesbaseret objektsporing afhængig af kontinuerlige detektioner for at bestemme en vektor, som bruges til at identificere det sporede objekt i en fremtidig position. Effektiviteten af denne tilgang er begrænset, fordi den mangler ægte genidentifikationsevne. Med bevægelsesforudsigelse kan et objekts spor gå tabt på grund af mistede detekteringer, okklusioner, eller at objektet forlader synsfeltet, selv kortvarigt. Når det først er tabt, er der ingen måde at tilknytte objektets spor igen. Tilføjelse af genidentifikation løser denne begrænsning, men kræver indlejring af et visuelt udseende (dvs. et billedfingeraftryk). Udseendeindlejringer kræver et andet netværk for at generere en egenskabsvektor ved at behandle billedet indeholdt i afgrænsningsrammen for objektet, der er detekteret af det første netværk. Denne indlejring kan bruges til at genidentificere objektet igen, uanset tid eller rum. Da indlejringer skal genereres for hvert objekt, der detekteres i synsfeltet, øges behandlingskravene, efterhånden som scenen bliver mere travl. Objektsporing med genidentifikation kræver omhyggelig overvejelse mellem at udføre høj nøjagtighed/høj opløsning/høj billedhastighed detektion og reservere tilstrækkelig overhead til indlejringsskalerbarhed. En måde at løse behandlingskravet på er at bruge en dedikeret AI-accelerator. Som tidligere nævnt kan SoC's AI-motor lide under manglen på delte hukommelsesressourcer. Modeloptimering kan også bruges til at sænke behandlingskravet, men det kan påvirke ydeevne og/eller nøjagtighed.
I et smart kamera eller edge-apparat henter den integrerede SoC (dvs. værtsprocessor) videobillederne og udfører de forbehandlingstrin, vi beskrev tidligere. Disse funktioner kan udføres med SoC'ens CPU-kerner eller GPU (hvis en er tilgængelig), men de kan også udføres af dedikerede hardwareacceleratorer i SoC'en (f.eks. billedsignalprocessor). Efter at disse forbehandlingstrin er afsluttet, kan AI-acceleratoren, der er integreret i SoC'en, direkte få adgang til dette kvantiserede input fra systemhukommelsen, eller i tilfælde af en diskret AI-accelerator, leveres inputtet til slutning, typisk over USB eller PCIe interface.
En integreret SoC kan indeholde en række beregningsenheder, herunder CPU'er, GPU'er, AI-accelerator, vision-processorer, videokodere/dekodere, billedsignalprocessor (ISP) og mere. Disse beregningsenheder deler alle den samme hukommelsesbus og har dermed adgang til den samme hukommelse. Desuden skal CPU'en og GPU'en muligvis også spille en rolle i slutningen, og disse enheder vil have travlt med at køre andre opgaver i et installeret system. Dette er, hvad vi mener med overhead på systemniveau (figur 2).
Mange udviklere evaluerer fejlagtigt ydeevnen af den indbyggede AI-accelerator i SoC'en uden at overveje effekten af overhead på systemniveau på den samlede ydeevne. Som et eksempel kan du overveje at køre et YOLO-benchmark på en 50 TOPS AI-accelerator integreret i en SoC, som måske kan opnå et benchmark-resultat på 100 inferenser/sekund (IPS). Men i et installeret system med alle dets andre beregningsenheder aktive, kunne disse 50 TOPS reduceres til noget i retning af 12 TOPS, og den samlede ydeevne ville kun give 25 IPS, forudsat en generøs 25% udnyttelsesfaktor. Systemoverhead er altid en faktor, hvis platformen kontinuerligt behandler videostreams. Alternativt, med en diskret AI-accelerator (f.eks. Kinara Ara-1, Hailo-8, Intel Myriad X), kunne udnyttelsen på systemniveau være større end 90 %, fordi når værts-SoC'en starter inferencingsfunktionen og overfører AI-modellens input data, kører acceleratoren autonomt ved at bruge sin dedikerede hukommelse til at få adgang til modelvægte og parametre.
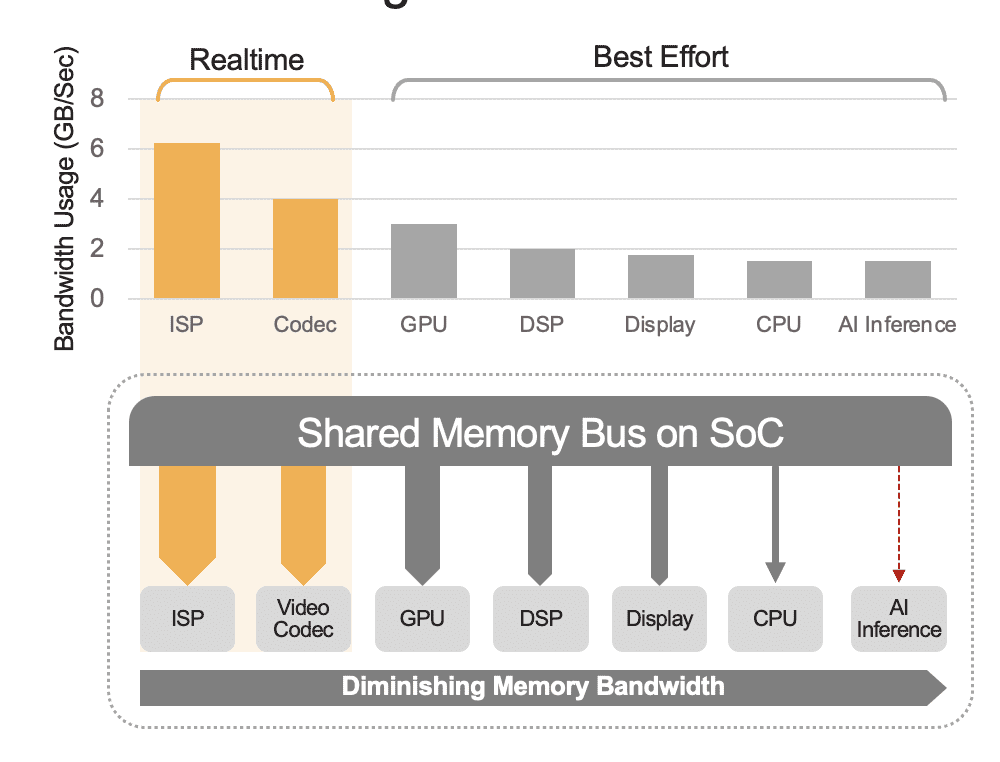
Figur 2. Den delte hukommelsesbus vil styre ydeevnen på systemniveau, vist her med estimerede værdier. Reelle værdier vil variere baseret på din applikationsbrugsmodel og SoC's beregningsenhedskonfiguration.
Indtil dette tidspunkt har vi diskuteret AI-ydeevne i form af billeder per sekund og TOPS. Men lav latenstid er et andet vigtigt krav for at levere et systems reaktionstid i realtid. For eksempel i spil er lav latenstid afgørende for en sømløs og responsiv spiloplevelse, især i bevægelseskontrollerede spil og virtual reality (VR)-systemer. I autonome køresystemer er lav latenstid afgørende for genkendelse af objekter i realtid, fodgængergenkendelse, vognbanegenkendelse og trafikskiltgenkendelse for at undgå at kompromittere sikkerheden. Autonome køresystemer kræver typisk ende-til-ende latens på mindre end 150 ms fra detektion til den faktiske handling. Tilsvarende i fremstilling er lav latens essentiel for defektdetektering i realtid, anomali-genkendelse og robotvejledning afhænger af videoanalyse med lav latens for at sikre effektiv drift og minimere produktionsnedetid.
Generelt er der tre komponenter af latenstid i en videoanalyseapplikation (figur 3):
- Datafangstforsinkelse er tiden fra kamerasensoren optager en videoramme til rammens tilgængelighed til analysesystemet til behandling. Du kan optimere denne latency ved at vælge et kamera med en hurtig sensor og lav latency-processor, vælge optimale billedhastigheder og bruge effektive videokomprimeringsformater.
- Dataoverførselsforsinkelse er den tid, hvor optagede og komprimerede videodata skal rejse fra kameraet til kanten enheder eller lokale servere. Dette inkluderer netværksbehandlingsforsinkelser, der opstår ved hvert slutpunkt.
- Databehandlingsforsinkelse refererer til den tid, som edge-enhederne har til at udføre videobehandlingsopgaver såsom frame-dekompression og analytiske algoritmer (f.eks. bevægelsesforudsigelsesbaseret objektsporing, ansigtsgenkendelse). Som påpeget tidligere, er behandlingsforsinkelse endnu vigtigere for applikationer, der skal køre flere AI-modeller for hver videoramme.
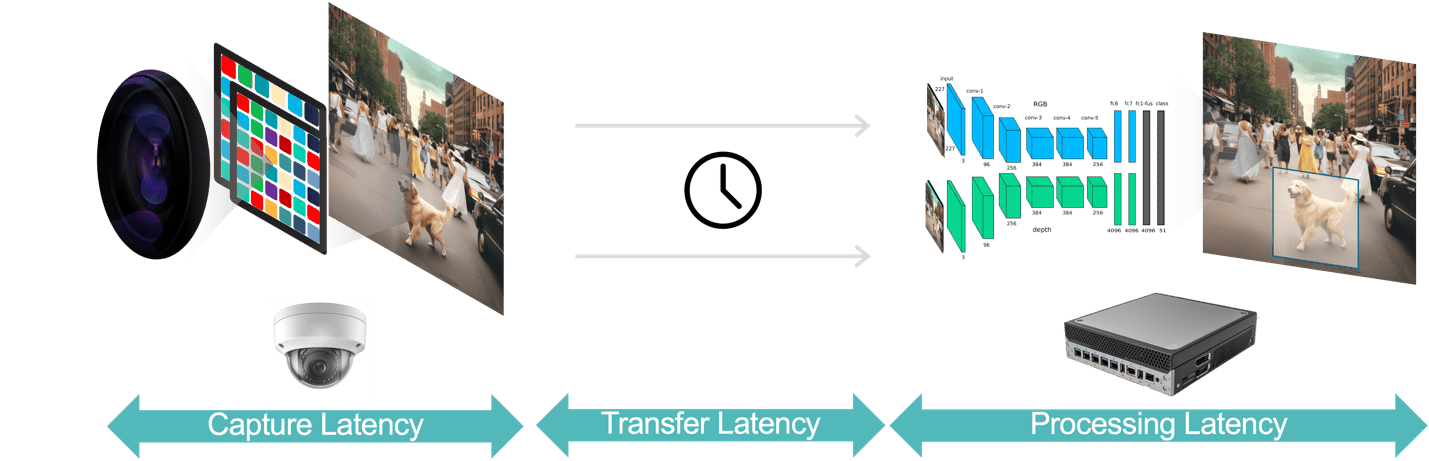
Figur 3. Videoanalysepipelinen består af datafangst, dataoverførsel og databehandling.
Databehandlingsforsinkelsen kan optimeres ved hjælp af en AI-accelerator med en arkitektur designet til at minimere databevægelser på tværs af chippen og mellem computere og forskellige niveauer af hukommelseshierarkiet. For at forbedre latensen og effektiviteten på systemniveau skal arkitekturen også understøtte nul (eller næsten nul) skifttid mellem modeller for bedre at understøtte de multimodelapplikationer, vi diskuterede tidligere. En anden faktor for både forbedret ydeevne og latenstid vedrører algoritmisk fleksibilitet. Med andre ord er nogle arkitekturer kun designet til optimal adfærd på specifikke AI-modeller, men med det hurtigt skiftende AI-miljø dukker nye modeller for højere ydeevne og bedre nøjagtighed op i, hvad der ser ud som hver anden dag. Vælg derfor en edge AI-processor uden praktiske begrænsninger på modeltopologi, operatører og størrelse.
Der er mange faktorer, der skal tages i betragtning for at maksimere ydeevnen i en edge AI-enhed, herunder krav til ydeevne og latens og systemoverhead. En vellykket strategi bør overveje en ekstern AI-accelerator for at overvinde hukommelses- og ydeevnebegrænsningerne i SoC's AI-motor.
CH Chee er en dygtig produktmarkedsførings- og ledelseschef, Chee har stor erfaring med at promovere produkter og løsninger i halvlederindustrien med fokus på vision-baseret AI, tilslutningsmuligheder og videogrænseflader til flere markeder, herunder virksomheder og forbrugere. Som iværksætter var Chee med til at stifte to video-halvleder-start-ups, der blev opkøbt af et offentligt halvlederfirma. Chee ledede produktmarketingteams og nyder at arbejde med et lille team, der fokuserer på at opnå gode resultater.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :har
- :er
- :ikke
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- evne
- accelerator
- acceleratorer
- adgang
- Adgang
- imødekomme
- udrette
- nøjagtighed
- opnå
- erhvervede
- Overtager
- tværs
- Handling
- aktiv
- faktiske
- tilføje
- Yderligere
- vedtaget
- fremskreden
- Efter
- igen
- AI
- AI motor
- AI modeller
- algoritmisk
- algoritmer
- Alle
- også
- altid
- an
- analyse
- analytics
- analysere
- ,
- afsløring af anomalier
- En anden
- Anvendelse
- applikationer
- tilgang
- arkitektur
- ER
- AS
- forbundet
- At
- automatisere
- Automation
- autonom
- autonomt
- tilgængelighed
- til rådighed
- undgå
- baseret
- grundlag
- BE
- fordi
- bliver
- været
- før
- være
- benchmark
- Bedre
- mellem
- både
- Boks
- kasser
- indbygget
- bus
- travlt
- men
- by
- værelse
- kameraer
- CAN
- kapaciteter
- kapacitet
- fange
- fanget
- Optagelse
- forsigtig
- tilfælde
- tilfælde
- udfordre
- skiftende
- chip
- Chips
- vælge
- klasse
- Cloud
- farve
- kommer
- selskab
- konkurrencedygtig
- Afsluttet
- komponenter
- at gå på kompromis
- beregning
- beregningsmæssige
- Compute
- computer
- Computer Vision
- Computer Vision applikationer
- tillid
- Konfiguration
- Connectivity
- følgelig
- Overvej
- overvejelse
- betragtes
- Overvejer
- består
- begrænsninger
- forbruger
- indeholder
- indeholdt
- kontinuerlig
- kontinuerligt
- Konvertering
- kunne
- CPU
- kritisk
- kunde
- data
- databehandling
- dag
- dedikeret
- forsinkelse
- forsinkelser
- levere
- leveret
- afhængig
- Afhængigt
- indsat
- implementeringer
- beskrevet
- konstrueret
- opdaget
- Detektion
- Bestem
- udviklere
- Enheder
- forskel
- direkte
- drøftet
- Skærm
- nedetid
- kørsel
- grund
- dynamisk
- e
- hver
- tidligere
- nemt
- Edge
- effekt
- effektivitet
- effektivitet
- effektivitet
- effektiv
- enten
- indlejring
- ende
- ende til ende
- Engine (Motor)
- Motorer
- forbedre
- sikre
- Enterprise
- Hele
- Entrepreneur
- Miljø
- væsentlig
- anslået
- evaluere
- Endog
- Hver
- udviklende
- eksempel
- overstige
- udføre
- henrettet
- udøvende
- forvente
- erfaring
- Oplevelser
- omfattende
- Omfattende oplevelse
- ekstern
- Ansigtet
- ansigtsgenkendelse
- faktor
- faktorer
- fabrik
- FAST
- Feature
- fodring
- felt
- Figur
- fingeraftryk
- Fornavn
- Fleksibilitet
- fokuserer
- fokusering
- Til
- format
- FRAME
- fra
- funktion
- funktionalitet
- funktioner
- Endvidere
- fremtiden
- vinder
- Spil
- spil
- spiloplevelse
- Generelt
- generere
- genereret
- generøse
- Go
- GPU
- GPU'er
- stor
- større
- Dyrkning
- Vækst
- vejledning
- Hardware
- Have
- dermed
- link.
- hierarki
- Høj
- højere
- host
- HTTPS
- i
- identificere
- if
- billede
- KIMOs Succeshistorier
- vigtigt
- pålagt
- Forbedre
- forbedret
- in
- I andre
- omfatter
- Herunder
- Forøg
- øget
- industrier
- industrien
- Indleder
- indgang
- indvendig
- indsigt
- integreret
- Intel
- grænseflade
- grænseflader
- ind
- involvere
- involverer
- uanset
- ISP
- IT
- ITS
- KDnuggets
- Etiketter
- Mangel
- Lane
- stor
- Latency
- forlader
- Led
- mindre
- niveauer
- biblioteker
- ligesom
- begrænsning
- begrænsninger
- Limited
- lokale
- tabte
- Lav
- lavere
- administrere
- ledelse
- Produktion
- mange
- Marketing
- Markeder
- Maksimer
- maksimere
- Kan..
- betyde
- foranstaltninger
- Mød
- Hukommelse
- nævnte
- måske
- savnet
- model
- modeller
- modul
- overvågning
- mere
- mest
- bevægelse
- bevægelse
- flere
- skal
- utal
- I nærheden af
- behov
- netværk
- Neural
- neurale netværk
- Ny
- næste
- ingen
- objekt
- Objektdetektion
- forekomme
- of
- tit
- on
- engang
- ONE
- kun
- OpenCV
- drift
- operationelle
- Operatører
- modsætning
- optimal
- optimering
- Optimer
- optimeret
- optimering
- or
- Andet
- ud
- output
- i løbet af
- samlet
- Overvind
- Parallel
- parametre
- især
- per
- udføre
- ydeevne
- udføres
- udfører
- udfører
- pipeline
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- Punkt
- position
- efterbehandling
- Praktisk
- forudsigelse
- behandle
- bearbejdet
- forarbejdning
- Processor
- processorer
- Produkt
- produktion
- Produkter
- Fremme
- give
- offentlige
- rækkevidde
- spænder
- hurtige
- hurtigt
- Sats
- priser
- Raw
- rådata
- ægte
- realtid
- Reality
- anerkendelse
- reducere
- refererer
- kræver
- påkrævet
- krav
- Krav
- Kræver
- Løsning
- Ressourcer
- lydhør
- restriktioner
- resultere
- Resultater
- robotteknik
- roller
- Kør
- kører
- løber
- Sikkerhed
- samme
- Skalerbarhed
- Scale
- skala ai
- skalering
- scene
- scores
- sømløs
- Anden
- Sektion
- se
- synes
- udvælgelse
- halvleder
- sæt
- Del
- delt
- Shopping
- bør
- vist
- underskrive
- Signal
- Tilsvarende
- siden
- enkelt
- Størrelse
- lille
- Smart
- løsninger
- Løsninger
- SOLVE
- Løser
- nogle
- noget
- Space
- specifikke
- nystartede virksomheder
- Steps
- butik
- strategier
- Strategi
- strøm
- vandløb
- vellykket
- sådan
- tilstrækkeligt
- support
- undertrykkelse
- overvågning
- systemet
- Systemer
- Tag
- tager
- opgaver
- hold
- hold
- Teknologier
- Teknologier
- vilkår
- end
- at
- Fremtiden
- deres
- derefter
- Der.
- derfor
- Disse
- de
- denne
- dem
- tre
- Gennem
- kapacitet
- tid
- gange
- til
- Toppe
- I alt
- spor
- Sporing
- Trafik
- overførsel
- overførsler
- Transform
- rejse
- sand
- to
- typisk
- Ultimativt
- ude af stand
- forstå
- enhed
- enheder
- Brug
- usb
- brug
- anvendte
- bruger
- ved brug af
- sædvanligvis
- Ved hjælp af
- Værdier
- række
- forskellige
- video
- Specifikation
- Virtual
- Virtual reality
- vision
- afgørende
- vr
- Vej..
- we
- var
- Hvad
- hvorvidt
- som
- bredt
- vilje
- med
- uden
- ord
- arbejder
- ville
- X
- Udbytte
- YOLO
- dig
- Din
- zephyrnet
- nul







