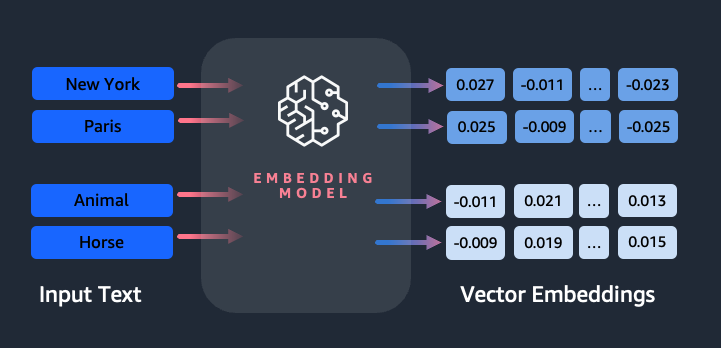
Indlejringer spiller en nøglerolle i naturlig sprogbehandling (NLP) og maskinlæring (ML). Indlejring af tekst refererer til processen med at transformere tekst til numeriske repræsentationer, der ligger i et højdimensionelt vektorrum. Denne teknik opnås gennem brug af ML-algoritmer, der muliggør forståelsen af dataens betydning og kontekst (semantiske relationer) og indlæring af komplekse relationer og mønstre inden for dataene (syntaktiske relationer). Du kan bruge de resulterende vektorrepræsentationer til en lang række applikationer, såsom informationssøgning, tekstklassificering, naturlig sprogbehandling og mange andre.
Amazon Titan-tekstindlejringer er en tekstindlejringsmodel, der konverterer tekst i naturligt sprog – der består af enkelte ord, sætninger eller endda store dokumenter – til numeriske repræsentationer, der kan bruges til kraftanvendelsestilfælde såsom søgning, personalisering og klyngedannelse baseret på semantisk lighed.
I dette indlæg diskuterer vi Amazon Titan Text Embeddings-modellen, dens funktioner og eksempler på brug.
Nogle nøglebegreber omfatter:
- Numerisk repræsentation af tekst (vektorer) fanger semantik og relationer mellem ord
- Rich indlejringer kan bruges til at sammenligne tekstligheder
- Flersproget tekstindlejring kan identificere betydning på forskellige sprog
Hvordan konverteres et stykke tekst til en vektor?
Der er flere teknikker til at konvertere en sætning til en vektor. En populær metode er at bruge ordindlejringsalgoritmer, såsom Word2Vec, GloVe eller FastText, og derefter aggregere ordindlejringerne for at danne en vektorrepræsentation på sætningsniveau.
En anden almindelig tilgang er at bruge store sprogmodeller (LLM'er), som BERT eller GPT, som kan give kontekstualiserede indlejringer til hele sætninger. Disse modeller er baseret på deep learning-arkitekturer såsom Transformers, som kan fange kontekstuelle oplysninger og relationer mellem ord i en sætning mere effektivt.
Hvorfor har vi brug for en indlejringsmodel?
Vektorindlejringer er fundamentale for, at LLM'er kan forstå sprogets semantiske grader og gør det også muligt for LLM'er at klare sig godt på downstream-NLP-opgaver som sentimentanalyse, navngiven enhedsgenkendelse og tekstklassificering.
Ud over semantisk søgning kan du bruge indlejringer til at øge dine prompter for mere præcise resultater gennem Retrieval Augmented Generation (RAG) – men for at bruge dem skal du gemme dem i en database med vektorfunktioner.
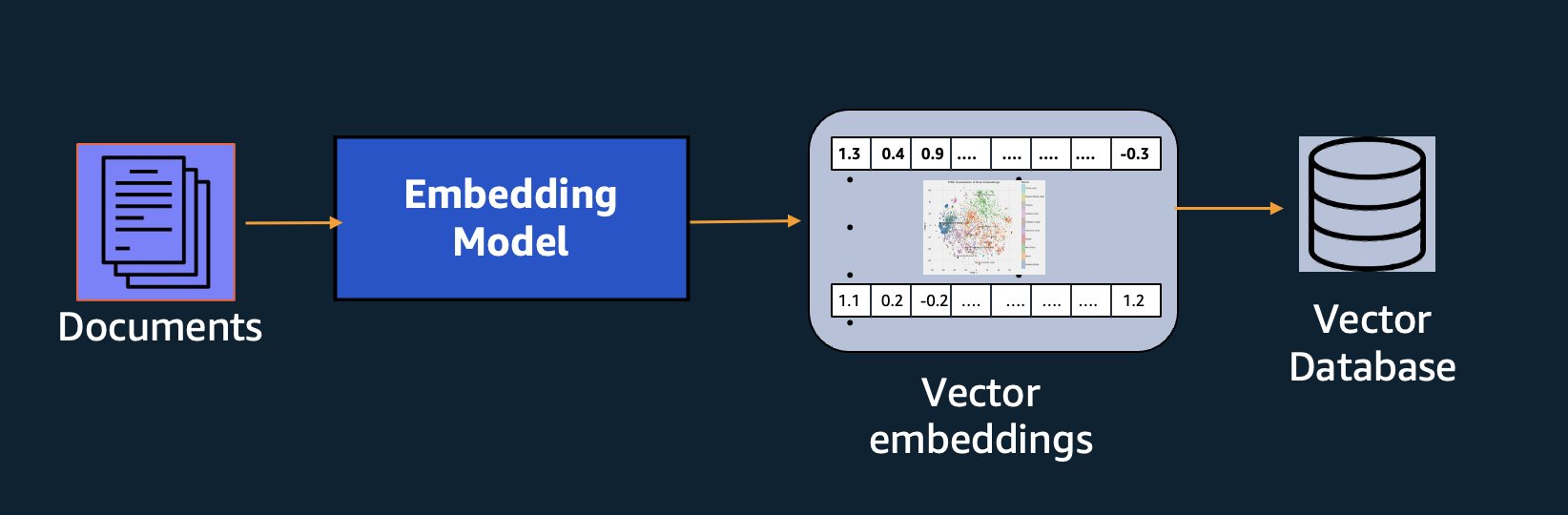
Amazon Titan Text Embeddings-modellen er optimeret til tekstgenfinding for at muliggøre RAG-brug. Det giver dig mulighed for først at konvertere dine tekstdata til numeriske repræsentationer eller vektorer og derefter bruge disse vektorer til nøjagtigt at søge efter relevante passager fra en vektordatabase, så du kan få mest muligt ud af dine proprietære data i kombination med andre fundamentmodeller.
Fordi Amazon Titan Text Embeddings er en administreret model på Amazonas grundfjeld, det tilbydes som en fuldstændig serverløs oplevelse. Du kan bruge det via enten Amazon Bedrock REST API eller AWS SDK. De nødvendige parametre er den tekst, som du gerne vil generere indlejringerne af og modelID parameter, som repræsenterer navnet på Amazon Titan Text Embeddings-modellen. Følgende kode er et eksempel, der bruger AWS SDK til Python (Boto3):
Outputtet vil se nogenlunde i stil med følgende:
Der henvises til Amazon Bedrock boto3 opsætning for flere detaljer om, hvordan du installerer de nødvendige pakker, skal du oprette forbindelse til Amazon Bedrock og påberåbe modeller.
Funktioner af Amazon Titan Text Embeddings
Med Amazon Titan Text Embeddings kan du indtaste op til 8,000 tokens, hvilket gør den velegnet til at arbejde med enkelte ord, sætninger eller hele dokumenter baseret på din brugssituation. Amazon Titan returnerer outputvektorer med dimension 1536, hvilket giver den en høj grad af nøjagtighed, samtidig med at den optimerer til omkostningseffektive resultater med lav latens.
Amazon Titan Text Embeddings understøtter oprettelse og forespørgsel om indlejringer til tekst på over 25 forskellige sprog. Det betyder, at du kan anvende modellen på dine use cases uden at skulle oprette og vedligeholde separate modeller for hvert sprog, du ønsker at understøtte.
At have en enkelt indlejringsmodel trænet i mange sprog giver følgende nøglefordele:
- Bredere rækkevidde – Ved at understøtte mere end 25 sprog direkte fra boksen, kan du udvide rækkevidden af dine applikationer til brugere og indhold på mange internationale markeder.
- Konsekvent præstation – Med en samlet model, der dækker flere sprog, får du ensartede resultater på tværs af sprog i stedet for at optimere separat pr. sprog. Modellen er trænet holistisk, så du får fordelen på tværs af sprog.
- Understøttelse af flersproget forespørgsel – Amazon Titan Text Embeddings tillader forespørgsler om tekstindlejringer på et hvilket som helst af de understøttede sprog. Dette giver fleksibilitet til at hente semantisk lignende indhold på tværs af sprog uden at være begrænset til et enkelt sprog. Du kan bygge applikationer, der forespørger og analyserer flersprogede data ved hjælp af det samme forenede indlejringsrum.
Når dette skrives, er følgende sprog understøttet:
- arabisk
- Kinesisk (forenklet)
- Kinesisk (traditionelt)
- tjekkisk
- Hollandsk
- Engelsk
- Fransk
- Tysk
- hebraisk
- Hindi
- Italiensk
- japansk
- Kannada
- koreansk
- malayalam
- Marathi
- polsk
- Portugisisk
- russisk
- Spansk
- Svensk
- filippinsk tagalog
- tamil
- telugu
- tyrkisk
Brug af Amazon Titan Text Embeddings med LangChain
Langkæde er en populær open source-ramme til at arbejde med generative AI-modeller og understøttende teknologier. Det omfatter en BedrockEmbeddings klient der bekvemt omslutter Boto3 SDK'et med et abstraktionslag. Det BedrockEmbeddings klient giver dig mulighed for at arbejde med tekst og indlejringer direkte uden at kende detaljerne i JSON-anmodningen eller svarstrukturerne. Følgende er et simpelt eksempel:
Du kan også bruge LangChain's BedrockEmbeddings klient sammen med Amazon Bedrock LLM-klienten for at forenkle implementeringen af RAG, semantisk søgning og andre indlejringsrelaterede mønstre.
Brug cases til indstøbninger
Selvom RAG i øjeblikket er den mest populære use case til at arbejde med embeddings, er der mange andre use cases, hvor embeddings kan anvendes. Følgende er nogle yderligere scenarier, hvor du kan bruge indlejringer til at løse specifikke problemer, enten på egen hånd eller i samarbejde med en LLM:
- Spørgsmål og svar – Indlejringer kan hjælpe med at understøtte spørgsmål og svar-grænseflader gennem RAG-mønsteret. Indlejringsgenerering parret med en vektordatabase giver dig mulighed for at finde tætte matches mellem spørgsmål og indhold i et videnlager.
- Personlige anbefalinger – I lighed med spørgsmål og svar kan du bruge indlejringer til at finde feriedestinationer, gymnasier, køretøjer eller andre produkter baseret på de kriterier, brugeren har angivet. Dette kan tage form af en simpel liste over matches, eller du kan derefter bruge en LLM til at behandle hver anbefaling og forklare, hvordan den opfylder brugerens kriterier. Du kan også bruge denne tilgang til at generere tilpassede "10 bedste" artikler til en bruger baseret på deres specifikke behov.
- Datastyring – Når du har datakilder, der ikke er knyttet rent til hinanden, men du har tekstindhold, der beskriver dataposten, kan du bruge indlejringer til at identificere potentielle duplikerede poster. For eksempel kan du bruge indlejringer til at identificere duplikerede kandidater, der kan bruge forskellig formatering, forkortelser eller endda have oversatte navne.
- Rationalisering af applikationsporteføljen – Når man søger at tilpasse applikationsporteføljer på tværs af et moderselskab og et opkøb, er det ikke altid indlysende, hvor man skal begynde at finde potentielt overlap. Kvaliteten af konfigurationsstyringsdata kan være en begrænsende faktor, og det kan være svært at koordinere på tværs af teams at forstå applikationslandskabet. Ved at bruge semantisk matchning med indlejringer kan vi lave en hurtig analyse på tværs af applikationsporteføljer for at identificere højpotentielle kandidatansøgninger til rationalisering.
- Indholdsgruppering – Du kan bruge indlejringer til at hjælpe med at gruppere lignende indhold i kategorier, som du måske ikke kender i forvejen. Lad os f.eks. sige, at du havde en samling af kunde-e-mails eller online produktanmeldelser. Du kan oprette indlejringer for hvert element og derefter køre disse indlejringer igennem k-betyder klyngedannelse at identificere logiske grupperinger af kundeproblemer, produktros eller klager eller andre temaer. Du kan derefter generere fokuserede opsummeringer fra disse grupperings indhold ved hjælp af en LLM.
Eksempel på semantisk søgning
I vores eksempel på GitHub, demonstrerer vi en simpel indlejringssøgningsapplikation med Amazon Titan Text Embeddings, LangChain og Streamlit.
Eksemplet matcher en brugers forespørgsel med de nærmeste poster i en vektordatabase i hukommelsen. Vi viser derefter disse matches direkte i brugergrænsefladen. Dette kan være nyttigt, hvis du vil fejlfinde en RAG-applikation eller direkte evaluere en indlejringsmodel.
For nemheds skyld bruger vi in-memory FAISS database til at gemme og søge efter indlejringsvektorer. I et scenarie i den virkelige verden vil du sandsynligvis bruge et vedvarende datalager som vektormotor til Amazon OpenSearch Serverless eller pgvektor udvidelse til PostgreSQL.
Prøv nogle få meddelelser fra webapplikationen på forskellige sprog, såsom følgende:
- Hvordan kan jeg overvåge mit forbrug?
- Hvordan kan jeg tilpasse modeller?
- Hvilke programmeringssprog kan jeg bruge?
- Kommenter mig données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- I welchen Regionen er Amazon Bedrock tilgængelig?
- 有哪些级别的支持?
Bemærk, at selvom kildematerialet var på engelsk, blev forespørgslerne på andre sprog matchet med relevante poster.
Konklusion
Tekstgenereringsmulighederne i fundamentmodeller er meget spændende, men det er vigtigt at huske, at forståelse af tekst, at finde relevant indhold fra en mængde viden og skabe forbindelser mellem passager er afgørende for at opnå den fulde værdi af generativ AI. Vi vil fortsat se nye og interessante use cases for indlejringer dukke op i løbet af de næste år, efterhånden som disse modeller fortsætter med at forbedre sig.
Næste skridt
Du kan finde yderligere eksempler på indlejringer som notesbøger eller demoapplikationer i følgende workshops:
Om forfatterne
 Jason Stehle er Senior Solutions Architect hos AWS med base i New England-området. Han arbejder med kunder for at tilpasse AWS-kapaciteter til deres største forretningsmæssige udfordringer. Uden for arbejdet bruger han sin tid på at bygge ting og se tegneseriefilm med sin familie.
Jason Stehle er Senior Solutions Architect hos AWS med base i New England-området. Han arbejder med kunder for at tilpasse AWS-kapaciteter til deres største forretningsmæssige udfordringer. Uden for arbejdet bruger han sin tid på at bygge ting og se tegneseriefilm med sin familie.
 Nitin Eusebius er Sr. Enterprise Solutions Architect hos AWS, erfaren i Software Engineering, Enterprise Architecture og AI/ML. Han er dybt passioneret omkring at udforske mulighederne for generativ AI. Han samarbejder med kunder for at hjælpe dem med at bygge veldesignede applikationer på AWS-platformen og er dedikeret til at løse teknologiske udfordringer og hjælpe med deres cloud-rejse.
Nitin Eusebius er Sr. Enterprise Solutions Architect hos AWS, erfaren i Software Engineering, Enterprise Architecture og AI/ML. Han er dybt passioneret omkring at udforske mulighederne for generativ AI. Han samarbejder med kunder for at hjælpe dem med at bygge veldesignede applikationer på AWS-platformen og er dedikeret til at løse teknologiske udfordringer og hjælpe med deres cloud-rejse.
 Raj Pathak er en hovedløsningsarkitekt og teknisk rådgiver for store Fortune 50-virksomheder og mellemstore finansielle serviceinstitutioner (FSI) på tværs af Canada og USA. Han har specialiseret sig i maskinlæringsapplikationer såsom generativ AI, naturlig sprogbehandling, intelligent dokumentbehandling og MLOps.
Raj Pathak er en hovedløsningsarkitekt og teknisk rådgiver for store Fortune 50-virksomheder og mellemstore finansielle serviceinstitutioner (FSI) på tværs af Canada og USA. Han har specialiseret sig i maskinlæringsapplikationer såsom generativ AI, naturlig sprogbehandling, intelligent dokumentbehandling og MLOps.
 Mani Khanuja er en Tech Lead – Generative AI Specialists, forfatter til bogen – Applied Machine Learning and High Performance Computing på AWS, og medlem af bestyrelsen for Women in Manufacturing Education Foundation Board. Hun leder maskinlæringsprojekter (ML) inden for forskellige domæner såsom computervision, naturlig sprogbehandling og generativ AI. Hun hjælper kunder med at bygge, træne og implementere store maskinlæringsmodeller i stor skala. Hun taler i interne og eksterne konferencer såsom re:Invent, Women in Manufacturing West, YouTube-webinarer og GHC 23. I sin fritid kan hun godt lide at gå lange løbeture langs stranden.
Mani Khanuja er en Tech Lead – Generative AI Specialists, forfatter til bogen – Applied Machine Learning and High Performance Computing på AWS, og medlem af bestyrelsen for Women in Manufacturing Education Foundation Board. Hun leder maskinlæringsprojekter (ML) inden for forskellige domæner såsom computervision, naturlig sprogbehandling og generativ AI. Hun hjælper kunder med at bygge, træne og implementere store maskinlæringsmodeller i stor skala. Hun taler i interne og eksterne konferencer såsom re:Invent, Women in Manufacturing West, YouTube-webinarer og GHC 23. I sin fritid kan hun godt lide at gå lange løbeture langs stranden.
 Mark Roy er en Principal Machine Learning Architect for AWS, der hjælper kunder med at designe og bygge AI/ML-løsninger. Marks arbejde dækker en bred vifte af ML use cases med en primær interesse i computervision, deep learning og skalering af ML på tværs af virksomheden. Han har hjulpet virksomheder i mange brancher, herunder forsikring, finansielle tjenesteydelser, medier og underholdning, sundhedspleje, forsyningsselskaber og fremstilling. Mark har seks AWS-certificeringer, inklusive ML Specialty Certification. Før han kom til AWS, var Mark arkitekt, udvikler og teknologileder i over 25 år, heraf 19 år inden for finansielle tjenesteydelser.
Mark Roy er en Principal Machine Learning Architect for AWS, der hjælper kunder med at designe og bygge AI/ML-løsninger. Marks arbejde dækker en bred vifte af ML use cases med en primær interesse i computervision, deep learning og skalering af ML på tværs af virksomheden. Han har hjulpet virksomheder i mange brancher, herunder forsikring, finansielle tjenesteydelser, medier og underholdning, sundhedspleje, forsyningsselskaber og fremstilling. Mark har seks AWS-certificeringer, inklusive ML Specialty Certification. Før han kom til AWS, var Mark arkitekt, udvikler og teknologileder i over 25 år, heraf 19 år inden for finansielle tjenesteydelser.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Om
- abstraktion
- Acceptere
- nøjagtighed
- præcis
- præcist
- opnået
- opnå
- erhvervelse
- tværs
- Desuden
- Yderligere
- Fordel
- rådgiver
- forude
- AI
- AI modeller
- AI / ML
- algoritmer
- tilpasse
- Alle
- tillade
- tillade
- tillader
- sammen
- langs med
- også
- altid
- Amazon
- Amazon Web Services
- an
- analyse
- analysere
- ,
- besvare
- enhver
- Anvendelse
- applikationer
- anvendt
- Indløs
- tilgang
- arkitektur
- arkitekturer
- ER
- OMRÅDE
- artikler
- AS
- bistår
- At
- forøge
- augmented
- forfatter
- til rådighed
- AWS
- baseret
- BE
- Beach
- være
- fordele
- mellem
- board
- bestyrelse
- krop
- bog
- Boks
- bygge
- Bygning
- virksomhed
- men
- by
- CAN
- Canada
- kandidat
- kandidater
- kapaciteter
- fange
- fanger
- tilfælde
- tilfælde
- kategorier
- Certificering
- certificeringer
- udfordringer
- klassificering
- kunde
- Luk
- Cloud
- klyngedannelse
- kode
- samling
- Colleges
- kombination
- Fælles
- Virksomheder
- selskab
- sammenligne
- klager
- komplekse
- computer
- Computer Vision
- computing
- begreber
- Bekymringer
- konferencer
- Konfiguration
- Tilslut
- tilslutning
- Tilslutninger
- konsekvent
- indhold
- sammenhæng
- kontekstuelle
- fortsæt
- bekvemt
- konvertere
- konverteret
- samarbejde
- koordinerende
- omkostningseffektiv
- kunne
- dækker
- dækker
- skabe
- Oprettelse af
- kriterier
- afgørende
- For øjeblikket
- skik
- kunde
- Kunder
- tilpasse
- data
- Database
- de
- dedikeret
- dyb
- dyb læring
- dybt
- definere
- Degree
- Demo
- demonstrere
- indsætte
- beskriver
- Design
- destinationer
- detaljer
- Udvikler
- forskellige
- svært
- Dimension
- direkte
- direktører
- diskutere
- Skærm
- do
- dokumentet
- dokumenter
- Domæner
- Dont
- hver
- Uddannelse
- effektivt
- enten
- emails
- indlejring
- emerge
- muliggøre
- muliggør
- Engine (Motor)
- Engineering
- England
- Engelsk
- Enterprise
- Enterprise Solutions
- Underholdning
- Hele
- helt
- enhed
- Ether (ETH)
- evaluere
- Endog
- eksempel
- eksempler
- spændende
- Udvid
- erfaring
- erfarne
- Forklar
- Udforskning
- udvidelse
- ekstern
- lette
- faktor
- familie
- Funktionalitet
- få
- finansielle
- finansielle tjenesteydelser
- Finde
- finde
- Fornavn
- Fleksibilitet
- fokuserede
- efter
- Til
- formular
- rigdom
- Foundation
- Framework
- Gratis
- fra
- fuld
- fundamental
- generere
- generation
- generative
- Generativ AI
- få
- få
- Give
- handske
- Go
- størst
- havde
- Have
- he
- sundhedspleje
- hjælpe
- hjulpet
- hjælpe
- hjælper
- hende
- Høj
- High Performance Computing
- hans
- besidder
- Hvordan
- How To
- HTML
- HTTPS
- i
- identificere
- if
- gennemføre
- importere
- vigtigt
- Forbedre
- in
- I andre
- omfatter
- omfatter
- Herunder
- industrier
- oplysninger
- indgang
- installere
- i stedet
- institutioner
- forsikring
- Intelligent
- Intelligent dokumentbehandling
- interesse
- interessant
- grænseflade
- grænseflader
- interne
- internationalt
- ind
- IT
- ITS
- sammenføjning
- rejse
- jpg
- json
- Nøgle
- Kend
- Kendskab til
- viden
- landskab
- Sprog
- Sprog
- stor
- lag
- føre
- leder
- Leads
- læring
- lad
- ligesom
- Sandsynlig
- synes godt om
- begrænsende
- Liste
- llm
- logisk
- Lang
- Se
- leder
- maskine
- machine learning
- vedligeholde
- lave
- Making
- lykkedes
- ledelse
- Produktion
- mange
- kort
- markere
- Mark's
- Markeder
- matchede
- tændstikker
- matchende
- materiale
- me
- betyder
- midler
- Medier
- medlem
- metode
- måske
- ML
- ML algoritmer
- MLOps
- model
- modeller
- Overvåg
- mere
- mest
- Mest Populære
- Film
- flere
- my
- navn
- Som hedder
- navne
- Natural
- Naturligt sprog
- Natural Language Processing
- Behov
- behøve
- behov
- Ny
- næste
- NLP
- notesbøger
- Obvious
- of
- tilbydes
- on
- ONE
- online
- åbent
- open source
- optimeret
- optimering
- or
- ordrer
- Andet
- Andre
- vores
- ud
- output
- uden for
- i løbet af
- egen
- pakker
- parret
- parameter
- parametre
- moderselskab
- passager
- lidenskabelige
- Mønster
- mønstre
- per
- udføre
- ydeevne
- Personalisering
- sætninger
- stykke
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- Vær venlig
- Populær
- BY
- portefølje
- porteføljer
- muligheder
- Indlæg
- postgresql
- potentiale
- magt
- primære
- Main
- Forud
- problemer
- behandle
- forarbejdning
- Produkt
- Produkt Anmeldelser
- Produkter
- Programmering
- programmeringssprog
- projekter
- prompter
- proprietære
- give
- forudsat
- giver
- Python
- kvalitet
- forespørgsler
- query
- spørgsmål
- Spørgsmål
- Hurtig
- klud
- rækkevidde
- RE
- nå
- virkelige verden
- anerkendelse
- Anbefaling
- anbefalinger
- optage
- optegnelser
- refererer
- Relationer
- relevant
- huske
- Repository
- repræsentation
- repræsenterer
- anmode
- påkrævet
- svar
- REST
- begrænset
- resulterer
- Resultater
- hentning
- afkast
- Anmeldelser
- roller
- Kør
- løber
- s
- samme
- siger
- Scale
- skalering
- scenarie
- scenarier
- SDK
- Søg
- se
- semantiske
- semantik
- senior
- dømme
- stemningen
- adskille
- Serverless
- Tjenester
- hun
- lignende
- Simpelt
- enkelhed
- forenklet
- forenkle
- enkelt
- SIX
- So
- Software
- software Engineering
- Løsninger
- SOLVE
- Løsning
- nogle
- noget
- Kilde
- Kilder
- Space
- Taler
- specialister
- specialiseret
- Specialty
- specifikke
- starte
- påbegyndt
- Stater
- butik
- strukturer
- sådan
- support
- Understøttet
- Støtte
- Understøtter
- Tag
- opgaver
- hold
- tech
- Teknisk
- teknik
- teknikker
- Teknologier
- Teknologier
- fortælle
- tekst
- Tekstklassificering
- tekstgenerering
- at
- The Source
- deres
- Them
- temaer
- derefter
- Der.
- Disse
- ting
- denne
- dem
- selvom?
- Gennem
- tid
- titan
- til
- Tokens
- traditionelle
- Tog
- uddannet
- transformers
- omdanne
- forstå
- forståelse
- forenet
- Forenet
- Forenede Stater
- Brug
- brug
- brug tilfælde
- anvendte
- nyttigt
- Bruger
- Brugergrænseflade
- brugere
- ved brug af
- forsyningsselskaber
- ferie
- værdi
- forskellige
- Køretøjer
- meget
- via
- vision
- ønsker
- var
- ser
- we
- web
- Webapplikation
- webservices
- Webinarer
- GODT
- var
- Vest
- hvornår
- som
- mens
- bred
- Bred rækkevidde
- vilje
- med
- inden for
- uden
- Dame
- ord
- ord
- Arbejde
- arbejder
- virker
- workshops
- ville
- skriver
- skrivning
- år
- dig
- Din
- youtube
- zephyrnet