Organisationer over hele verden – både profit og nonprofit – ser på at udnytte dataanalyse til forbedret virksomhedspræstation. Resultater fra en McKinsey undersøgelse indikerer, at datadrevne organisationer er 23 gange mere tilbøjelige til at erhverve kunder, seks gange så tilbøjelige til at fastholde kunder og 19 gange mere profitable [1]. Forskning ved MIT fandt, at digitalt modne virksomheder er 26 % mere profitable end deres jævnaldrende [2]. Men mange virksomheder kæmper, på trods af at de er rige på data, med at implementere dataanalyse på grund af de modstridende prioriteter mellem forretningsbehov, tilgængelige kapaciteter og ressourcer. Forskning af Gartner fandt, at over 85 % af data- og analyseprojekter mislykkedes [3] og en fælles rapport fra IBM og Carnegie Melon viser, at 90% af data i en organisation aldrig bliver brugt med succes til noget strategisk formål [4].
Med denne baggrund introducerer vi "data analytics fabric (DAF)"-konceptet som et økosystem eller en struktur, der gør det muligt for dataanalyse at fungere effektivt baseret på (a) forretningsbehov eller -mål, (b) tilgængelige kapaciteter såsom mennesker/færdigheder , processer, kultur, teknologier, indsigt, beslutningskompetencer og mere, og (c) ressourcer (dvs. komponenter, som en virksomhed har brug for for at drive virksomheden).
Vores primære mål med at introducere dataanalysestrukturen er at besvare dette grundlæggende spørgsmål: "Hvad kræves der for effektivt at bygge et beslutningsmuliggørende system fra data, Science algoritmer til at måle og forbedre virksomhedens ydeevne?" Dataanalysestrukturen og dens fem nøglemanifestationer er vist og diskuteret nedenfor.
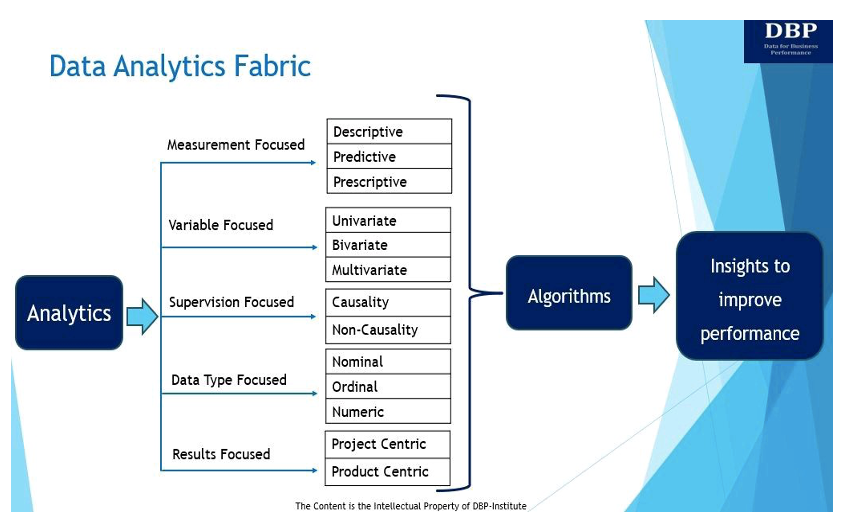
1. Målefokuseret
I sin kerne handler analyse om at bruge data til at udlede indsigt, måle og forbedre virksomhedens ydeevne [5]. Der er tre hovedtyper af analyser til at måle og forbedre virksomhedens ydeevne:
- Beskrivende analyse stiller spørgsmålet "Hvad skete der?" Deskriptiv analyse bruges til at analysere historiske data for at identificere mønstre, tendenser og sammenhænge ved hjælp af undersøgende, associative og inferentielle dataanalyseteknikker. Udforskende dataanalyseteknikker analyserer og opsummerer datasæt. Associativ deskriptiv analyse forklarer sammenhængen mellem variabler. Inferentiel beskrivende dataanalyse bruges til at udlede eller konkludere tendenser om en større population baseret på stikprøvedatasættet.
- Forudsigelig analyse ser på svaret på spørgsmålet "Hvad vil der ske?" Grundlæggende er prædiktiv analyse processen med at bruge data til at forudsige fremtidige tendenser og begivenheder. Prædiktiv analyse kan udføres manuelt (almindeligvis kendt som analytikerdrevet prædiktiv analyse) eller vha. maskinlæringsalgoritmer (også kendt som datadrevet prædiktiv analyse). Uanset hvad, bruges de historiske data til at lave fremtidige forudsigelser.
- Præskriptiv analyse hjælper med at besvare spørgsmålet "Hvordan kan vi få det til at ske?" Grundlæggende anbefaler præskriptive analyser den bedste fremgangsmåde til at komme videre ved brug af optimerings- og simuleringsteknikker. Typisk går forudsigende analyse og præskriptiv analyse sammen, fordi prædiktiv analyse hjælper med at finde potentielle resultater, mens præskriptiv analyse ser på disse resultater og finder flere muligheder.
2. Variabel-fokuseret
Data kan også analyseres baseret på antallet af tilgængelige variabler. I denne henseende, baseret på antallet af variable, kan dataanalyseteknikkerne være univariate, bivariate eller multivariate.
- Univariat analyse: Univariat analyse involverer at analysere mønsteret til stede i en enkelt variabel ved hjælp af mål for centralitet (middelværdi, median, tilstand og så videre) og variation (standardafvigelse, standardfejl, varians og så videre).
- Bivariat analyse: Der er to variabler, hvor analysen er relateret til årsag og forholdet mellem de to variable. Disse to variabler kan være afhængige eller uafhængige af hinanden. Korrelationsteknikken er den mest anvendte bivariate analyseteknik.
- Multivariat analyse: Denne teknik bruges til at analysere mere end to variabler. I en multivariat indstilling opererer vi typisk i den forudsigelige analysearena, og de fleste af de velkendte maskinlæringsalgoritmer (ML) såsom lineær regression, logistisk regression, regressionstræer, støttevektormaskiner og neurale netværk anvendes typisk på en multivariat indstilling.
3. Supervisionsfokuseret
Den tredje type dataanalysestruktur omhandler træning af inputdata eller uafhængige variable data, der er blevet mærket for et bestemt output (dvs. den afhængige variabel). Grundlæggende er den uafhængige variabel den, som forsøgslederen kontrollerer. Den afhængige variabel er den variabel, der ændrer sig som reaktion på den uafhængige variabel. Den overvågningsfokuserede DAF kunne være en af to typer.
- Kausalitet: Mærkede data, uanset om de genereres automatisk eller manuelt, er afgørende for overvåget læring. Mærkede data gør det muligt klart at definere en afhængig variabel, og så er det et spørgsmål om den prædiktive analytiske algoritme at bygge et AI/ML-værktøj, der ville bygge et forhold mellem etiketten (afhængig variabel) og sættet af uafhængige variable. Det faktum, at vi har en distinkt afgrænsning mellem begrebet en afhængig variabel og et sæt af uafhængige variable, tillader vi os at introducere begrebet "kausalitet" for bedst at forklare sammenhængen.
- Ikke-kausalitet: Når vi angiver "supervisionsfokuseret" som vores dimension, mener vi også "fraværet af supervision", og det bringer de ikke-kausale modeller til diskussionen. De ikke-kausale modeller fortjener omtale, fordi de ikke kræver mærkede data. Den grundlæggende teknik her er clustering, og de mest populære metoder er k-Means og Hierarchical Clustering.
4. Datatypefokuseret
Denne dimension eller manifestation af dataanalysestrukturen fokuserer på de tre forskellige typer datavariabler relateret til både de uafhængige og afhængige variabler, der bruges i dataanalyseteknikkerne til at udlede indsigt.
- Nominelle data bruges til at mærke eller kategorisere data. Det involverer ikke en numerisk værdi, og derfor er ingen statistiske beregninger mulige med nominelle data. Eksempler på nominelle data er køn, produktbeskrivelse, kundeadresse og lignende.
- Ordinale eller rangerede data er rækkefølgen af værdierne, men forskellene mellem hver enkelt er ikke rigtig kendt. Almindelige eksempler her er rangordning af virksomheder baseret på markedsværdi, leverandørbetalingsbetingelser, kundetilfredshedsscore, leveringsprioritet og så videre.
- Numeriske data behøver ingen introduktion og er numerisk i værdi. Disse variabler er de mest fundamentale datatyper, der kan bruges til at modellere alle typer algoritmer.
5. Resultatfokuseret
Denne type dataanalysestruktur ser på de måder, hvorpå forretningsværdi kan leveres ud fra den indsigt, der er afledt af analyser. Der er to måder, hvorpå forretningsværdi kan drives af analyser, og det er gennem produkter eller projekter. Mens produkterne muligvis skal løse yderligere konsekvenser omkring brugeroplevelse og softwareudvikling, vil modelleringsøvelsen, der udføres for at udlede modellen, være ens i både projektet og produktet.
- A dataanalyse produkt er et genanvendeligt dataaktiv til at tjene virksomhedens langsigtede behov. Det indsamler data fra relevante datakilder, sikrer datakvalitet, behandler det og gør det tilgængeligt for alle, der har brug for det. Produkter er typisk designet til personas og har flere livscyklusstadier eller iterationer, hvor produktværdien realiseres.
- A dataanalyseprojekt er designet til at imødekomme et bestemt eller unikt forretningsbehov og har en defineret eller snæver brugerbase eller formål. Grundlæggende er et projekt en midlertidig bestræbelse, der skal levere løsningen til et defineret omfang, inden for budget og til tiden.
Verdens økonomi vil ændre sig dramatisk i de kommende år, efterhånden som organisationer i stigende grad vil bruge data og analyser til at opnå indsigt og træffe beslutninger for at måle og forbedre virksomhedens ydeevne. McKinsey fundet, at virksomheder, der er indsigtsdrevne, rapporterer EBITDA (indtjening før renter, skat, afskrivninger og amortiseringer) stigninger på op til 25 % [5]. Mange organisationer har dog ikke succes med at udnytte data og analyser til at forbedre forretningsresultater. Men der er ikke én standard måde eller tilgang til at levere dataanalyse. Implementeringen eller implementeringen af dataanalyseløsninger afhænger af forretningsmål, kapaciteter og ressourcer. DAF og dets fem manifestationer, der diskuteres her, kan gøre det muligt at implementere analyser effektivt baseret på forretningsbehov, tilgængelige kapaciteter og ressourcer.
Referencer
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-end-deres-peers/
- gartner.com/da/newsroom/press-releases/2018-02-13-gartner-siger-næsten-halvdelen-af-cios-planlægger-at-udrulle-kunstig-intelligens
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, "Analytics Best Practices", Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Automotive/elbiler, Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- ChartPrime. Løft dit handelsspil med ChartPrime. Adgang her.
- BlockOffsets. Modernisering af miljømæssig offset-ejerskab. Adgang her.
- Kilde: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :har
- :er
- :ikke
- $OP
- 1
- 19
- 23
- a
- Om
- tilgængelig
- erhverve
- Handling
- Yderligere
- adresse
- AI / ML
- algoritme
- algoritmer
- Alle
- tillade
- tillader
- også
- amortisering
- an
- analyse
- analytics
- analysere
- analyseret
- analysere
- ,
- besvare
- enhver
- nogen
- anvendt
- tilgang
- ER
- Arena
- omkring
- AS
- aktiv
- At
- automatisk
- til rådighed
- b
- bagtæppe
- bund
- baseret
- grundlæggende
- I bund og grund
- BE
- fordi
- været
- før
- være
- jf. nedenstående
- BEDSTE
- mellem
- både
- Bringer
- budget
- bygge
- virksomhed
- forretningsresultater
- men
- by
- CAN
- kapaciteter
- kapitalisering
- kategorisere
- Årsag
- Centrale
- Ændringer
- tydeligt
- klyngedannelse
- indsamler
- KOM
- kommer
- Fælles
- almindeligt
- Virksomheder
- komponenter
- Konceptet
- konkluderer
- gennemført
- Modstridende
- kontrol
- Core
- Korrelation
- kunne
- kursus
- Medarbejder kultur
- kunde
- Kundetilfredshed
- Kunder
- data
- dataanalyse
- Dataanalyse
- datakvalitet
- datasæt
- datasæt
- datastyret
- DATAVERSITET
- Tilbud
- Beslutningstagning
- afgørelser
- definere
- definerede
- levere
- leveret
- levering
- afhængig
- afhænger
- indsat
- implementering
- afskrivninger
- Afledt
- beskrivelse
- fortjener
- konstrueret
- Trods
- afvigelse
- forskelle
- forskellige
- digitalt
- Dimension
- drøftet
- diskussion
- distinkt
- do
- gør
- færdig
- dramatisk
- drevet
- grund
- e
- hver
- Indtjening
- EBITDA
- økonomi
- økosystem
- effektivt
- enten
- muliggøre
- muliggør
- bestræbe sig
- Engineering
- sikrer
- fejl
- væsentlig
- begivenheder
- eksempler
- Dyrke motion
- erfaring
- Forklar
- Forklarer
- Udforskende dataanalyse
- stof
- Faktisk
- FAIL
- Finde
- fund
- fund
- firmaer
- fem
- fokuserer
- Til
- Forbes
- Forecast
- Videresend
- fundet
- fra
- funktion
- fundamental
- fremtiden
- Gartner
- Køn
- genereret
- Go
- mål
- ske
- skete
- Have
- hjælper
- dermed
- link.
- historisk
- Men
- HTTPS
- i
- IBM
- identificere
- gennemføre
- implementering
- Forbedre
- forbedret
- forbedring
- in
- Stigninger
- stigende
- uafhængig
- angiver
- indgang
- indsigt
- beregnet
- interesse
- indføre
- indføre
- Introduktion
- involvere
- involverer
- IT
- iterationer
- ITS
- Nøgle
- kendt
- etiket
- mærkning
- større
- læring
- løftestang
- livscyklus
- ligesom
- Sandsynlig
- langsigtet
- leder
- UDSEENDE
- maskine
- machine learning
- Maskiner
- Main
- lave
- maerker
- manuelt
- mange
- Marked
- Markedsbogstaver
- Matter
- modne
- max-bredde
- Kan..
- McKinsey
- betyde
- måle
- foranstaltninger
- nævne
- metoder
- MIT
- ML
- tilstand
- model
- modellering
- modeller
- mere
- mest
- Mest Populære
- flytning
- flere
- Behov
- behov
- net
- Neural
- neurale netværk
- aldrig
- ingen
- nonprofit
- Begreb
- nummer
- målsætninger
- of
- on
- ONE
- betjene
- optimering
- Indstillinger
- or
- ordrer
- organisation
- organisationer
- Andet
- vores
- os selv
- udfald
- output
- i løbet af
- særlig
- Mønster
- mønstre
- betaling
- ydeevne
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- befolkning
- mulig
- potentiale
- Forudsigelser
- forudsigende
- Forudsigelig analyse
- Prediktiv Analytics
- præsentere
- primære
- prioritet
- behandle
- Processer
- Produkt
- Produkter
- Profit
- rentabel
- projekt
- projekter
- formål
- kvalitet
- spørgsmål
- forgreninger
- rangeret
- Ranking
- gik op for
- virkelig
- anbefaler
- betragte
- regression
- relaterede
- forhold
- Relationer
- relevant
- indberette
- kræver
- påkrævet
- Ressourcer
- svar
- tilbageholde
- genanvendelige
- tilfredshed
- rækkevidde
- scores
- tjener
- sæt
- sæt
- indstilling
- vist
- Shows
- lignende
- simulation
- enkelt
- SIX
- So
- Software
- software Engineering
- løsninger
- Løsninger
- Kilde
- Kilder
- etaper
- standard
- statistiske
- Strategisk
- struktur
- Kamp
- vellykket
- Succesfuld
- sådan
- opsummere
- overvåget læring
- tilsyn
- support
- systemet
- Skatter
- teknikker
- Teknologier
- midlertidig
- semester
- vilkår
- end
- at
- verdenen
- deres
- derefter
- Der.
- Disse
- de
- Tredje
- denne
- dem
- tre
- Gennem
- tid
- gange
- til
- sammen
- værktøj
- Kurser
- Transform
- Træer
- Tendenser
- to
- typen
- typer
- typisk
- enestående
- brug
- anvendte
- Bruger
- Brugererfaring
- ved brug af
- værdi
- Værdier
- variabel
- sælger
- Vej..
- måder
- we
- Kendt
- hvornår
- hvorvidt
- som
- mens
- WHO
- vilje
- med
- inden for
- world
- Verdens
- ville
- år
- zephyrnet