
September 20, 2023
Grundlæggende modeller (FM'er) markerer begyndelsen på en ny æra i maskinlæring (ML) , kunstig intelligens (AI), hvilket fører til hurtigere udvikling af kunstig intelligens, der kan tilpasses til en bred vifte af downstream-opgaver og finjusteres til en række applikationer.
Med den stigende betydning af at behandle data, hvor der udføres arbejde, muliggør betjening af AI-modeller på virksomhedens kant forudsigelser i næsten realtid, samtidig med at de overholder datasuverænitets- og privatlivskrav. Ved at kombinere IBM watsonx data- og AI-platformskapaciteter til FM'er med edge computing, kan virksomheder køre AI-arbejdsbelastninger til FM-finjustering og inferencing på den operationelle kant. Dette gør det muligt for virksomheder at skalere AI-implementeringer på kanten, hvilket reducerer tiden og omkostningerne ved at implementere med hurtigere responstider.
Sørg for at tjekke alle afdragene i denne serie af blogindlæg om edge computing:
Hvad er grundlæggende modeller?
Grundlæggende modeller (FM'er), som er trænet på et bredt sæt af umærkede data i stor skala, driver state-of-the-art kunstig intelligens (AI) applikationer. De kan tilpasses til en bred vifte af downstream-opgaver og finjusteres til en række applikationer. Moderne AI-modeller, som udfører specifikke opgaver i et enkelt domæne, viger for FM'er, fordi de lærer mere generelt og arbejder på tværs af domæner og problemer. Som navnet antyder, kan en FM være grundlaget for mange anvendelser af AI-modellen.
FM'er adresserer to nøgleudfordringer, der har afholdt virksomheder fra at skalere AI-adoption. For det første producerer virksomheder en stor mængde umærkede data, hvoraf kun en brøkdel er mærket til AI-modeltræning. For det andet er denne mærknings- og anmærkningsopgave ekstremt menneskeintensiv, og den kræver ofte flere hundrede timer af en emneeksperts (SME) tid. Dette gør det uoverkommeligt at skalere på tværs af use cases, da det ville kræve hære af SMV'er og dataeksperter. Ved at indtage enorme mængder umærkede data og bruge selvovervågede teknikker til modeltræning har FM'er fjernet disse flaskehalse og åbnet muligheden for bred indførelse af AI på tværs af virksomheden. Disse enorme mængder data, der findes i enhver virksomhed, venter på at blive frigivet for at skabe indsigt.
Hvad er store sprogmodeller?
Store sprogmodeller (LLM'er) er en klasse af grundlæggende modeller (FM), der består af lag af neurale netværk der er blevet trænet i disse enorme mængder umærkede data. De bruger selvovervågede læringsalgoritmer til at udføre en række forskellige naturlig sprogbehandling (NLP) opgaver på måder, der ligner, hvordan mennesker bruger sproget (se figur 1).
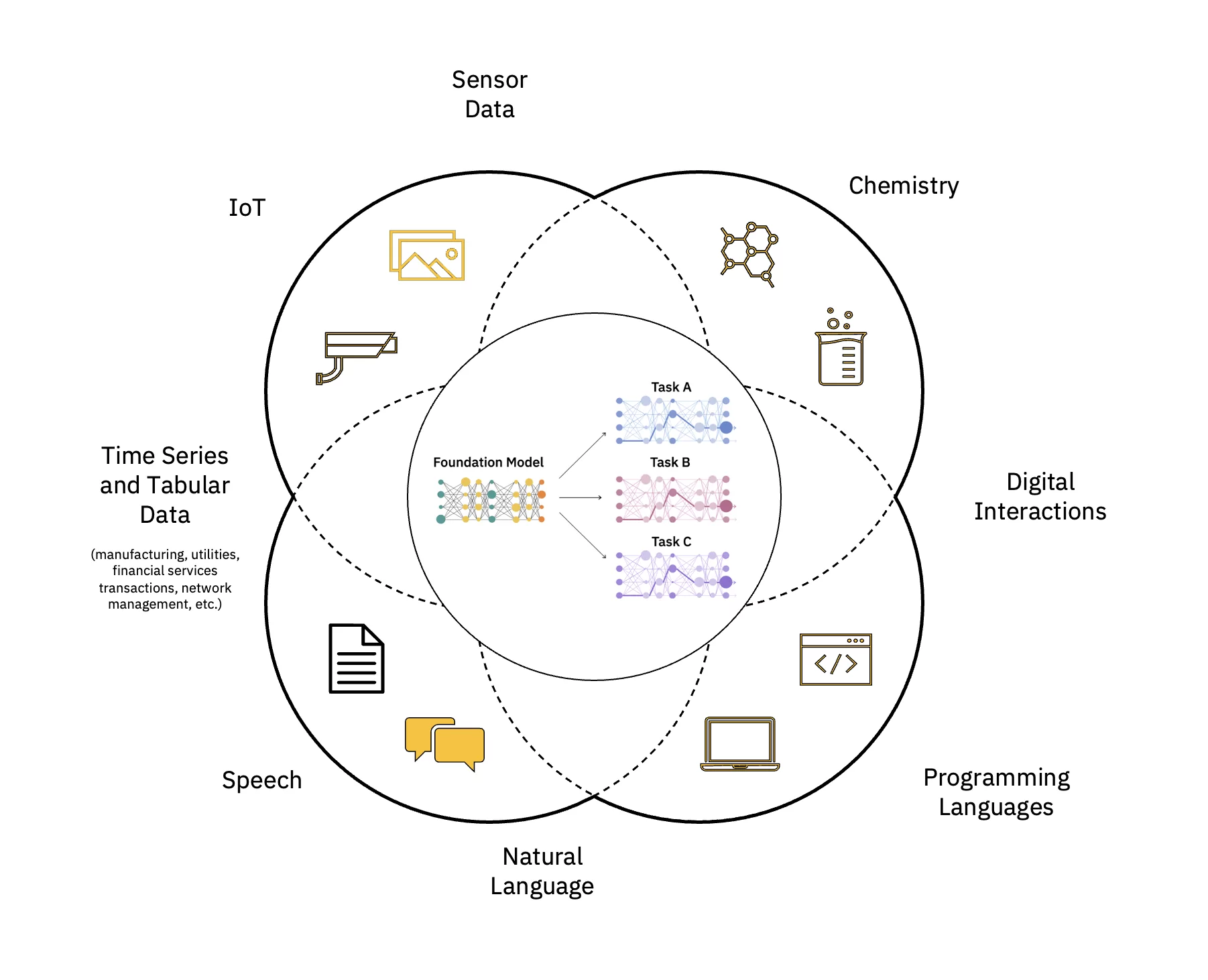
Skaler og accelerer virkningen af AI
Der er flere trin til opbygning og implementering af en grundlæggende model (FM). Disse omfatter dataindtagelse, dataudvælgelse, dataforbehandling, FM-fortræning, modeltuning til en eller flere downstream-opgaver, inferensservering og data- og AI-modelstyring og livscyklusstyring – som alle kan beskrives som FMOps.
For at hjælpe med alt dette tilbyder IBM virksomheder de nødvendige værktøjer og kapaciteter til at udnytte kraften i disse FM'er via IBM watsonx, en virksomhedsklar AI- og dataplatform designet til at multiplicere virkningen af AI på tværs af en virksomhed. IBM watsonx består af følgende:
- IBM watsonx.ai bringer nyt generativ AI funktioner – drevet af FM'er og traditionel maskinlæring (ML) – i et kraftfuldt studie, der spænder over AI-livscyklussen.
- IBM watsonx.data er et datalager, der passer til formålet, bygget på en åben lakehouse-arkitektur for at skalere AI-arbejdsbelastninger for alle dine data, hvor som helst.
- IBM watsonx.governance er et ende-til-ende automatiseret AI-livscyklusstyringsværktøj, der er bygget til at muliggøre ansvarlige, gennemsigtige og forklarelige AI-arbejdsgange.
En anden nøglevektor er den stigende betydning af databehandling på virksomhedskanten, såsom industrielle lokationer, produktionsgulve, detailbutikker, telco edge sites osv. Mere specifikt muliggør AI på virksomhedens kant behandling af data, hvor der udføres arbejde for næsten realtidsanalyse. Virksomhedsfordelen er, hvor store mængder virksomhedsdata genereres, og hvor AI kan give værdifuld, rettidig og handlingsegnet forretningsindsigt.
At betjene AI-modeller på kanten muliggør forudsigelser i næsten realtid, mens de overholder datasuverænitets- og privatlivskrav. Dette reducerer den forsinkelse, der ofte er forbundet med indsamling, transmission, transformation og behandling af inspektionsdata, markant. At arbejde på kanten giver os mulighed for at beskytte følsomme virksomhedsdata og reducere omkostningerne til dataoverførsel med hurtigere svartider.
At skalere AI-implementeringer på kanten er dog ikke en nem opgave midt i data (heterogenitet, volumen og regulatoriske) og begrænsede ressourcer (computere, netværksforbindelse, lagring og endda IT-færdigheder) relaterede udfordringer. Disse kan bredt beskrives i to kategorier:
- Tid/omkostninger at implementere: Hver implementering består af flere lag af hardware og software, der skal installeres, konfigureres og testes før implementeringen. I dag kan en servicemedarbejder tage op til en uge eller to til installation på hvert sted, begrænser kraftigt, hvor hurtigt og omkostningseffektivt virksomheder kan opskalere implementeringer på tværs af deres organisation.
- Dag 2 ledelse: Det store antal implementerede edges og den geografiske placering af hver implementering kan ofte gøre det uoverkommeligt dyrt at levere lokal it-support på hver lokation for at overvåge, vedligeholde og opdatere disse implementeringer.
Edge AI-implementeringer
IBM udviklede en edge-arkitektur, der løser disse udfordringer ved at bringe en integreret hardware/software (HW/SW) enhedsmodel til edge AI-implementeringer. Den består af flere nøgleparadigmer, der hjælper med skalerbarheden af AI-implementeringer:
- Politikbaseret, nul-touch-provisionering af den fulde softwarestak.
- Kontinuerlig overvågning af kantsystemets sundhed
- Muligheder til at administrere og skubbe software-/sikkerheds-/konfigurationsopdateringer til adskillige kantplaceringer – alt fra en central skybaseret placering til dag-2-administration.
En distribueret hub-and-spoke-arkitektur kan bruges til at skalere enterprise AI-implementeringer på kanten, hvor en central cloud eller virksomhedsdatacenter fungerer som en hub, og edge-in-a-box-enheden fungerer som en eger på en kantplacering. Denne hub- og egermodel, der strækker sig på tværs af hybride cloud- og edge-miljøer, illustrerer bedst den balance, der er nødvendig for optimalt at udnytte de nødvendige ressourcer til FM-drift (se figur 2).
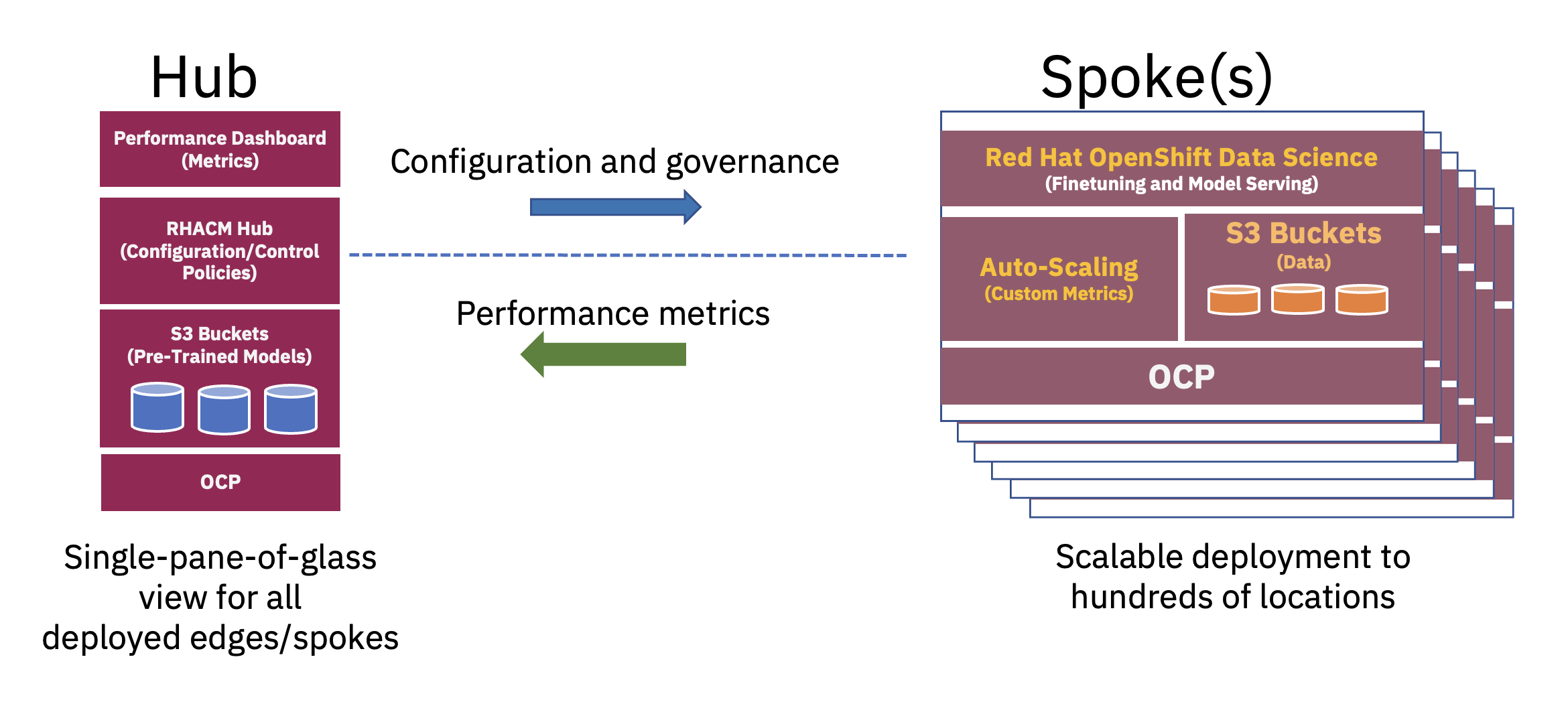
Fortræning af disse basale store sprogmodeller (LLM'er) og andre typer fundamentmodeller ved hjælp af selvovervågede teknikker på store umærkede datasæt kræver ofte betydelige databehandlingsressourcer (GPU) og udføres bedst i en hub. De praktisk talt ubegrænsede computerressourcer og store databunker, der ofte er lagret i skyen, giver mulighed for fortræning af store parametermodeller og løbende forbedring af nøjagtigheden af disse basisfundamentmodeller.
På den anden side kan tuning af disse basis-FM'er til downstream-opgaver - som kun kræver nogle få tiere eller hundredvis af mærkede dataeksempler og inferensservering - udføres med kun nogle få GPU'er på virksomhedens kant. Dette giver mulighed for, at følsomme mærkede data (eller virksomhedens kronjuveldata) sikkert forbliver i virksomhedens driftsmiljø, samtidig med at omkostningerne til dataoverførsel reduceres.
Ved at bruge en full-stack-tilgang til implementering af applikationer til kanten kan en dataforsker udføre finjustering, test og implementering af modellerne. Dette kan opnås i et enkelt miljø, samtidig med at udviklingslivscyklussen for visning af nye AI-modeller for slutbrugerne mindskes. Platforme som Red Hat OpenShift Data Science (RHODS) og den nyligt annoncerede Red Hat OpenShift AI giver værktøjer til hurtigt at udvikle og implementere produktionsklare AI-modeller i distribueret sky og kantmiljøer.
Endelig reducerer betjeningen af den finjusterede AI-model på virksomhedens kant betydeligt den forsinkelse, der ofte er forbundet med anskaffelse, transmission, transformation og behandling af data. Afkobling af fortræningen i skyen fra finjustering og inferencing på kanten sænker de overordnede driftsomkostninger ved at reducere den nødvendige tid og omkostninger til dataflytning forbundet med enhver slutningsopgave (se figur 3).
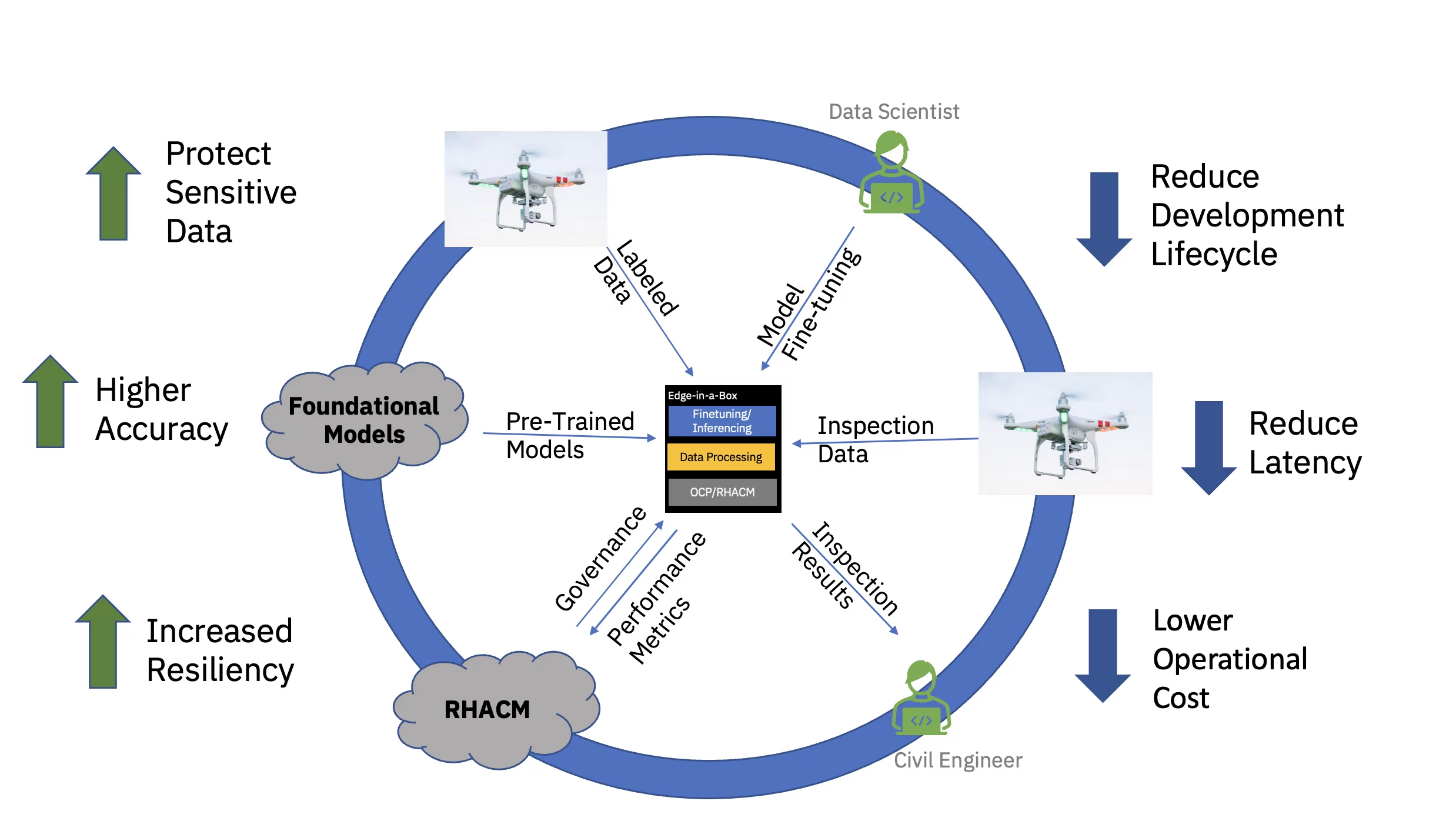
For at demonstrere dette værdiforslag ende-til-ende, blev en eksemplarisk vision-transformer-baseret fundamentmodel for civil infrastruktur (foruddannet ved hjælp af offentlige og brugerdefinerede branchespecifikke datasæt) finjusteret og implementeret til inferens på en kant med tre knudepunkter (talte) klynge. Softwarestakken inkluderede Red Hat OpenShift Container Platform og Red Hat OpenShift Data Science. Denne kantklynge var også forbundet til en forekomst af Red Hat Advanced Cluster Management for Kubernetes (RHACM) hub, der kørte i skyen.
Zero-touch klargøring
Politikbaseret, nul-touch-klargøring blev udført med Red Hat Advanced Cluster Management for Kubernetes (RHACM) via politikker og placeringstags, som binder specifikke edge-klynger til et sæt softwarekomponenter og konfigurationer. Disse softwarekomponenter – der strækker sig over hele stakken og dækker computer, lagring, netværk og AI-arbejdsbyrden – blev installeret ved hjælp af forskellige OpenShift-operatører, levering af nødvendige applikationstjenester og S3 Bucket (lagring).
Den forudtrænede fundamentmodel (FM) for civil infrastruktur blev finjusteret via en Jupyter Notebook i Red Hat OpenShift Data Science (RHODS) ved hjælp af mærkede data til at klassificere seks typer af defekter fundet på betonbroer. Inferensservering af denne finjusterede FM blev også demonstreret ved hjælp af en Triton-server. Ydermere blev overvågning af sundheden for dette kantsystem muliggjort ved at aggregere observerbarhedsmetrikker fra hardware- og softwarekomponenterne via Prometheus til det centrale RHACM-dashboard i skyen. Civile infrastrukturvirksomheder kan implementere disse FM'er ved deres kantplaceringer og bruge dronebilleder til at detektere defekter i næsten realtid - hvilket fremskynder tiden til indsigt og reducerer omkostningerne ved at flytte store mængder high-definition data til og fra skyen.
Resumé
Ved at kombinere IBM watsonx data- og AI-platformskapaciteter til fundamentmodeller (FM'er) med en edge-in-a-box-enhed giver virksomheder mulighed for at køre AI-arbejdsbelastninger til FM-finjustering og inferencing på den operationelle kant. Denne enhed kan håndtere komplekse use cases ud af boksen, og den bygger hub-and-spoke-rammen for centraliseret styring, automatisering og selvbetjening. Edge FM-implementeringer kan reduceres fra uger til timer med gentagelig succes, højere modstandsdygtighed og sikkerhed.
Lær mere om grundlæggende modeller
Sørg for at tjekke alle afdragene i denne serie af blogindlæg om edge computing:
Mere fra Cloud




- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :har
- :er
- :ikke
- :hvor
- $OP
- 08
- 1
- 10
- 13
- 15 %
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Om
- fremskynde
- adgang
- gennemført
- nøjagtighed
- erhvervelse
- tværs
- handlinger
- tilpasset
- Derudover
- adresse
- adresser
- Vedtagelse
- fremskreden
- fremskridt
- Reklame
- AI
- AI adoption
- AI modeller
- AI platform
- Støtte
- algoritmer
- Alle
- tillade
- tillader
- også
- Midt
- beløb
- beløb
- amp
- an
- analyse
- analytics
- ,
- annoncerede
- enhver
- overalt
- Anvendelse
- applikationer
- tilgang
- arkitektur
- ER
- Array
- artikel
- kunstig
- kunstig intelligens
- Kunstig intelligens (AI)
- AS
- forbundet
- At
- forfatter
- Automatiseret
- Automation
- til rådighed
- Avenue
- tilbage
- Balance
- Bank
- Banker
- bund
- BE
- fordi
- bliver
- blive
- været
- Begyndelse
- være
- Tro
- BEDSTE
- binde
- Blog
- Blogindlæg
- blogs
- både
- Boks
- broer
- Bringe
- Bringer
- bred
- bredt
- Bygning
- bygger
- bygget
- virksomhed
- by
- CAN
- kapaciteter
- kapital
- Optagelse
- kulstof
- kort
- Kort
- tilfælde
- KAT
- kategorier
- Årsag
- center
- central
- Centralbank
- centralbankers digitale valutaer
- centraliseret
- kæde
- udfordringer
- lave om
- skiftende
- kontrollere
- valg
- kredse
- CIS
- civile
- klasse
- Klassificere
- klar
- kunder
- nøje
- Cloud
- Cluster
- farve
- farverige
- kombinerer
- konkurrencedygtig
- komplekse
- kompleksitet
- Compliance
- komponenter
- Compute
- computing
- Konfiguration
- konfigureret
- tilsluttet
- Connectivity
- består
- Container
- fortsæt
- kontrol
- Koste
- Omkostninger
- kunne
- dækker
- cryptocurrency
- CSS
- valutaer
- skik
- kunde
- Kundeoplevelse
- Kunder
- instrumentbræt
- data
- Data Center
- Dataplatform
- datalogi
- dataforsker
- datasæt
- Dato
- dedikeret
- Standard
- definitioner
- levere
- demonstrere
- demonstreret
- indsætte
- indsat
- implementering
- implementering
- implementeringer
- beskrevet
- beskrivelse
- konstrueret
- udvikle
- udviklet
- Udvikling
- digital
- digitale valutaer
- digitalisering
- Forstyrrelse
- forstyrrende
- Disruptors
- distribueret
- distrikt
- domæne
- Domæner
- færdig
- køre
- kørsel
- drone
- hver
- let
- økosystem
- Edge
- kant computing
- OPHØJE
- forhøjet
- muliggøre
- muliggør
- ende
- ende til ende
- ingeniør
- Engineering
- Indtast
- Enterprise
- virksomheder
- indkommende
- Miljø
- miljøer
- Era
- især
- etc.
- Ether (ETH)
- Endog
- begivenheder
- Hver
- udviklet sig
- Undersøgelse
- eksempler
- udføre
- eksisterer
- Udgang
- dyrt
- erfaring
- eksperter
- Forklarelig AI
- forklarer
- strækker
- ekstremt
- faktorer
- FAST
- hurtigere
- få
- felt
- Figur
- finansielle
- Finansielle institutioner
- finansiering
- Fornavn
- gulve
- følger
- efter
- skrifttyper
- Til
- forkant
- fundet
- Foundation
- fraktion
- Framework
- fra
- fuld
- Fuld stak
- Endvidere
- generelt
- genereret
- generator
- geografisk
- geopolitik
- Give
- Global
- global handel
- regeringsførelse
- GPU
- GPU'er
- Grid
- hånd
- håndtere
- Hardware
- hat
- Have
- Helse
- højde
- hjælpe
- hjælpe
- hjælper
- høj opløsning
- højere
- stærkt
- historie
- host
- HOURS
- Hvordan
- How To
- Men
- HTTPS
- Hub
- Mennesker
- Hundreder
- Hybrid
- Hybrid sky
- IBM
- IBM Cloud
- ICO
- ICON
- illustrerer
- billede
- KIMOs Succeshistorier
- betydning
- in
- omfatter
- medtaget
- stigende
- stigende
- indeks
- industrielle
- industrier
- industrien
- industri-specifikke
- inflation
- bøjning
- Bøjningspunkt
- påvirket
- Infrastruktur
- initiativ
- Innovation
- innovativ
- indgange
- indsigt
- instans
- institutioner
- integreret
- Intelligens
- iboende
- indføre
- IT
- IT Support
- Journeys
- jpg
- hoppe
- Jupyter Notebook
- lige
- bare en
- holdt
- Nøgle
- Kubernetes
- mærkning
- Sprog
- stor
- vid udstrækning
- Latency
- seneste
- lag
- førende
- LÆR
- læring
- Leverage
- livscyklus
- ligesom
- grænseløs
- linux
- lokale
- Local
- placering
- placeringer
- Lang
- Se
- maskine
- machine learning
- lavet
- vedligeholde
- lave
- maerker
- administrere
- ledelse
- Produktion
- mange
- mærkning
- massive
- Master
- Matter
- max-bredde
- mekanismer
- metoder
- Metrics
- minut
- minimering
- minutter
- ML
- Mobil
- model
- modeller
- Moderne
- modernisering
- modernisere
- Overvåg
- overvågning
- mere
- bevægelse
- flytning
- navn
- Navigation
- I nærheden af
- nødvendig
- Behov
- behov
- behov
- netværk
- Ny
- næste
- NLP
- notesbog
- intet
- nu
- nummer
- talrige
- of
- tilbyde
- tit
- on
- ONE
- kun
- åbent
- åbnet
- operationelle
- Produktion
- Operatører
- optimeret
- or
- organisation
- Andet
- vores
- ud
- samlet
- pakker
- side
- parameter
- betaling
- betalingsmetoder
- betalinger
- udføre
- udføres
- PHP
- placering
- perron
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- plugin
- Punkt
- politikker
- politik
- position
- mulig
- Indlæg
- Indlæg
- potentiale
- magt
- vigtigste
- Forudsigelser
- Forud
- Beskyttelse af personlige oplysninger
- private
- problemer
- forarbejdning
- producere
- professionel
- proposition
- give
- offentlige
- Skub ud
- rækkevidde
- hurtigt
- Læsning
- realtid
- for nylig
- optage
- optagelse
- Rød
- Red Hat
- reducere
- Reduceret
- reducerer
- reducere
- regler
- Regulators
- lovgivningsmæssige
- relaterede
- fjernet
- gentagelig
- kræver
- påkrævet
- Krav
- krævet
- forskning
- Ressourcer
- svar
- ansvarlige
- lydhør
- detail
- Rise
- robotter
- Kør
- kører
- sikkert
- samme
- Skalerbarhed
- Scale
- skala ai
- skalering
- Videnskab
- Videnskabsmand
- Skærm
- scripts
- Anden
- sikkert
- sikkerhed
- se
- se
- valg
- Selvbetjening
- følsom
- SEO
- september
- Series
- server
- tjeneste
- Tjenester
- servering
- Session
- sessioner
- sæt
- flere
- Del
- Vis
- signifikant
- betydeligt
- lignende
- siden
- Singapore
- enkelt
- enkelt miljø
- websted
- Websteder
- SIX
- færdigheder
- lille
- EMS
- SMV'er
- Software
- software komponenter
- løsninger
- suverænitet
- Space
- spænding
- specifikke
- specifikt
- Sponsoreret
- stable
- starte
- state-of-the-art
- forblive
- Steps
- opbevaring
- butik
- opbevaret
- forhandler
- Storm
- Studio
- emne
- succes
- sådan
- foreslår
- forsyne
- forsyningskæde
- support
- sikker
- systemet
- Tag
- taget
- Opgaver
- opgaver
- teknikker
- Teknologier
- Telco
- Temenos
- tiere
- terraform
- afprøvet
- Test
- at
- deres
- tema
- Der.
- Disse
- de
- denne
- Gennem
- tid
- rettidig
- gange
- Titel
- til
- i dag
- sammen
- toolkit
- værktøjer
- top
- handle
- traditionelle
- Tog
- uddannet
- Kurser
- overførsel
- Transform
- Transformation
- transformationer
- gennemsigtig
- Triton
- to
- typen
- typer
- unleashed
- Opdatering
- opdateringer
- URL
- us
- brug
- anvendte
- brugere
- ved brug af
- udnytte
- udnyttet
- Værdifuld
- værdi
- værdiforslag
- række
- forskellige
- Vast
- via
- Specifikation
- næsten
- bind
- mængder
- W
- Venter
- tegnebog
- var
- Wave
- Vej..
- måder
- we
- uge
- uger
- Hvad
- Hvad er
- hvornår
- som
- mens
- WHO
- hvorfor
- bred
- Bred rækkevidde
- med
- inden for
- kvinde
- WordPress
- Arbejde
- arbejdsgange
- arbejder
- ville
- skriftlig
- Din
- zephyrnet











