Store sprogmodeller (LLM'er) bliver mere og mere populære, og nye use cases bliver konstant udforsket. Generelt kan du bygge applikationer drevet af LLM'er ved at inkorporere prompt engineering i din kode. Der er dog tilfælde, hvor tilskyndelse til en eksisterende LLM kommer til kort. Det er her, model finjustering kan hjælpe. Prompt engineering handler om at vejlede modellens output ved at lave input-prompter, hvorimod finjustering handler om at træne modellen på brugerdefinerede datasæt for at gøre den bedre egnet til specifikke opgaver eller domæner.
Før du kan finjustere en model, skal du finde et opgavespecifikt datasæt. Et datasæt, der er almindeligt anvendt, er Fælles Crawl-datasæt. Common Crawl-korpuset indeholder petabytes af data, der er indsamlet regelmæssigt siden 2008, og indeholder rå websidedata, metadataudtræk og tekstudtræk. Udover at bestemme hvilket datasæt der skal bruges, kræves rensning og bearbejdning af data til finjusteringens specifikke behov.
Vi har for nylig arbejdet med en kunde, der ønskede at forbehandle en delmængde af det seneste Common Crawl-datasæt og derefter finjustere deres LLM med rensede data. Kunden ledte efter, hvordan de kunne opnå dette på den mest omkostningseffektive måde på AWS. Efter at have diskuteret kravene, anbefalede vi at bruge Amazon EMR-serverløs som deres platform for dataforbehandling. EMR Serverless er velegnet til databehandling i stor skala og eliminerer behovet for vedligeholdelse af infrastrukturen. Med hensyn til omkostninger opkræver det kun baseret på de ressourcer og varighed, der bruges til hvert job. Kunden var i stand til at forbehandle hundredvis af TB'er af data inden for en uge ved hjælp af EMR Serverless. Efter at de havde forbehandlet dataene, brugte de Amazon SageMaker at finjustere LLM.
I dette indlæg guider vi dig igennem kundens use case og den anvendte arkitektur.
I de følgende afsnit introducerer vi først Common Crawl-datasættet, og hvordan man udforsker og filtrerer de data, vi har brug for. Amazonas Athena opkræver kun for den datastørrelse, den scanner og bruges til at udforske og filtrere dataene hurtigt, samtidig med at det er omkostningseffektivt. EMR Serverless giver en omkostningseffektiv og vedligeholdelsesfri mulighed for Spark-databehandling og bruges til at behandle de filtrerede data. Dernæst bruger vi Amazon SageMaker JumpStart at finjustere Lama 2 model med det forbehandlede datasæt. SageMaker JumpStart giver et sæt løsninger til de mest almindelige brugssager, der kan implementeres med blot et par klik. Du behøver ikke at skrive nogen kode for at finjustere en LLM såsom Llama 2. Til sidst implementerer vi den finjusterede model vha. Amazon SageMaker og sammenlign forskellene i tekstoutput for det samme spørgsmål mellem de originale og finjusterede Llama 2-modeller.
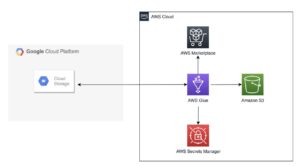
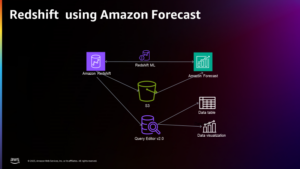
Følgende diagram illustrerer arkitekturen af denne løsning.
Før du dykker dybt ned i løsningsdetaljerne, skal du udføre følgende forudsætningstrin:
Common Crawl er et åbent korpusdatasæt opnået ved at crawle over 50 milliarder websider. Det inkluderer enorme mængder af ustrukturerede data på flere sprog, startende fra 2008 og når petabyte-niveauet. Den opdateres løbende.
I træningen af GPT-3 tegner Common Crawl-datasættet sig for 60 % af dets træningsdata, som vist i følgende diagram (kilde: Sprogmodeller er få-skudte elever).
Et andet vigtigt datasæt, der er værd at nævne, er C4 datasæt. C4, forkortelse for Colossal Clean Crawled Corpus, er et datasæt, der stammer fra efterbehandling af Common Crawl-datasættet. I Metas LLaMA-papir skitserede de de anvendte datasæt, hvor Common Crawl tegnede sig for 67 % (ved at bruge 3.3 TB data) og C4 for 15 % (ved at bruge 783 GB data). Artiklen understreger betydningen af at inkorporere forskelligt forbehandlede data for at forbedre modellens ydeevne. På trods af at de originale C4-data er en del af Common Crawl, valgte Meta den genbehandlede version af disse data.
I dette afsnit dækker vi almindelige måder at interagere, filtrere og behandle Common Crawl-datasættet på.
Common Crawl-rådatasættet omfatter tre typer datafiler: rå websidedata (WARC), metadata (WAT) og tekstudtræk (WET).
Data indsamlet efter 2013 gemmes i WARC-format og inkluderer tilsvarende metadata (WAT) og tekstudtræksdata (WET). Datasættet er placeret i Amazon S3, opdateret på månedsbasis og kan tilgås direkte via AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzCommon Crawl-datasættet indeholder også en indekstabel til filtrering af data, som kaldes cc-index-table.
cc-indeks-tabellen er et indeks over de eksisterende data, der giver et tabelbaseret indeks over WARC-filer. Det giver mulighed for let opslag af information, såsom hvilken WARC-fil, der svarer til en bestemt URL.
For eksempel kan du oprette en Athena-tabel for at kortlægge cc-indeksdata med følgende kode:
De foregående SQL-sætninger viser, hvordan man opretter en Athena-tabel, tilføjer partitioner og kører en forespørgsel.
Filtrer data fra Common Crawl-datasættet
Som du kan se fra SQL-sætningen opret tabel, er der flere felter, der kan hjælpe med at filtrere dataene. For eksempel, hvis du ønsker at få antallet af kinesiske dokumenter i en bestemt periode, kan SQL-sætningen være som følger:
Hvis du vil foretage yderligere behandling, kan du gemme resultaterne i en anden S3-spand.
Analyser de filtrerede data
Fælles Crawl GitHub-lager giver flere PySpark-eksempler til behandling af rådata.
Lad os se på et eksempel på løb server_count.py (eksempel script leveret af Common Crawl GitHub repo) på dataene placeret i s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Først skal du have et Spark-miljø, såsom EMR Spark. For eksempel kan du starte en Amazon EMR på EC2-klynge i us-east-1 (fordi datasættet er inde us-east-1). Brug af en EMR på EC2-klynge kan hjælpe dig med at udføre test, før du sender job til produktionsmiljøet.
Efter at have lanceret en EMR på EC2-klyngen, skal du lave et SSH-login til klyngens primære node. Pak derefter Python-miljøet og indsend scriptet (se Conda dokumentation for at installere Miniconda):
Det kan tage tid at behandle alle referencer i warc.path. Til demoformål kan du forbedre behandlingstiden med følgende strategier:
- Download filen
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gztil din lokale maskine, pak den ud, og upload den derefter til HDFS eller Amazon S3. Dette skyldes, at .gzip-filen ikke kan opdeles. Du skal udpakke den for at behandle denne fil parallelt. - Rediger
warc.pathfil, slet de fleste af dens linjer og behold kun to linjer for at få jobbet til at køre meget hurtigere.
Når jobbet er færdigt, kan du se resultatet i s3://xxxx-common-crawl/output/, i parketformat.
Implementer tilpasset besiddelse af logik
Common Crawl GitHub-repoen giver en fælles tilgang til at behandle WARC-filer. Generelt kan du forlænge CCSparkJob at tilsidesætte en enkelt metode (process_record), hvilket er tilstrækkeligt i mange tilfælde.
Lad os se på et eksempel for at få IMDB-anmeldelser af de seneste film. Først skal du filtrere filer fra IMDB-webstedet:
Så kan du få WARC-fillister, der indeholder IMDB-gennemgangsdata, og gemme WARC-filnavnene som en liste i en tekstfil.
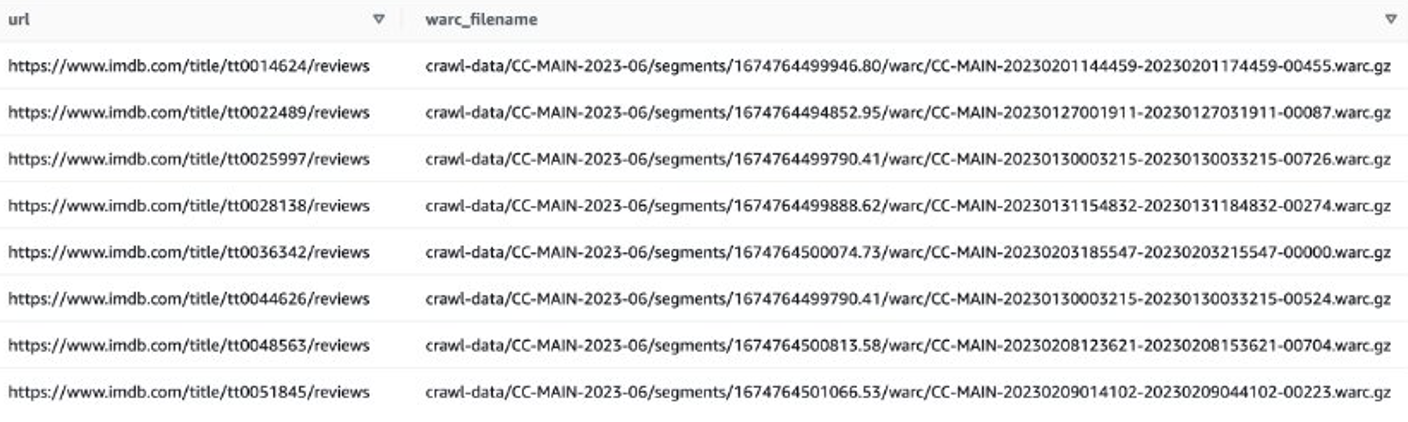
Alternativt kan du bruge EMR Spark til at hente WARC-fillisten og gemme den i Amazon S3. For eksempel:
Outputfilen skal ligne s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Det næste trin er at udtrække brugeranmeldelser fra disse WARC-filer. Du kan forlænge CCSparkJob at tilsidesætte process_record() metode:
Du kan gemme det foregående script som imdb_extractor.py, som du skal bruge i de følgende trin. Når du har forberedt data og scripts, kan du bruge EMR Serverless til at behandle de filtrerede data.
EMR-serverløs
EMR Serverless er en serverløs implementeringsmulighed til at køre big data analytics-applikationer ved hjælp af open source frameworks som Apache Spark og Hive uden at konfigurere, administrere og skalere klynger eller servere.
Med EMR Serverless kan du køre analytiske arbejdsbelastninger i enhver skala med automatisk skalering, der ændrer størrelse på ressourcer på få sekunder for at imødekomme skiftende datamængder og behandlingskrav. EMR Serverless skalerer automatisk ressourcer op og ned for at give den rigtige mængde kapacitet til din applikation, og du betaler kun for det, du bruger.
Behandling af Common Crawl-datasættet er generelt en engangsbehandlingsopgave, hvilket gør det velegnet til EMR-serverløse arbejdsbelastninger.
Opret en EMR-serverløs applikation
Du kan oprette en EMR-serverløs applikation på EMR Studio-konsollen. Udfør følgende trin:
- På EMR Studio-konsollen skal du vælge Applikationer under Serverless i navigationsruden.
- Vælg Opret applikation.

- Angiv et navn til applikationen, og vælg en Amazon EMR-version.

- Hvis der kræves adgang til VPC-ressourcer, skal du tilføje en tilpasset netværksindstilling.

- Vælg Opret applikation.
Dit Spark serverløse miljø vil derefter være klar.
Før du kan indsende et job til EMR Spark Serverless, skal du stadig oprette en eksekveringsrolle. Henvise til Kom godt i gang med Amazon EMR Serverless for flere detaljer.
Behandl Common Crawl-data med EMR Serverless
Når din EMR Spark Serverless-applikation er klar, skal du udføre følgende trin for at behandle dataene:
- Forbered et Conda-miljø og upload det til Amazon S3, som vil blive brugt som miljøet i EMR Spark Serverless.
- Upload de scripts, der skal køres til en S3-bøtte. I det følgende eksempel er der to scripts:
- imbd_extractor.py – Tilpasset logik til at udtrække indhold fra datasættet. Indholdet kan findes tidligere i dette indlæg.
- cc-pyspark/sparkcc.py – Eksemplet PySpark framework fra Fælles Crawl GitHub-repo, som er nødvendig for at være med.
- Send PySpark-jobbet til EMR Serverless Spark. Definer følgende parametre for at køre dette eksempel i dit miljø:
- applikations-id – Applikations-id'et for din EMR Serverless-applikation.
- udførelse-rolle-arn – Din EMR-serverløse eksekveringsrolle. For at oprette det, se Opret en jobruntime-rolle.
- WARC-filplacering – Placeringen af dine WARC-filer.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtindeholder den filtrerede WARC-filliste, som du har fået tidligere i dette indlæg. - spark.sql.warehouse.dir – Standardlagerets placering (brug dit S3-bibliotek).
- gnist.arkiver – S3-placeringen af det forberedte Conda-miljø.
- spark.submit.pyFiles – Det forberedte PySpark-script sparkcc.py.
Se følgende kode:
Når jobbet er fuldført, gemmes de udpakkede anmeldelser i Amazon S3. For at kontrollere indholdet kan du bruge Amazon S3 Select, som vist på det følgende skærmbillede.
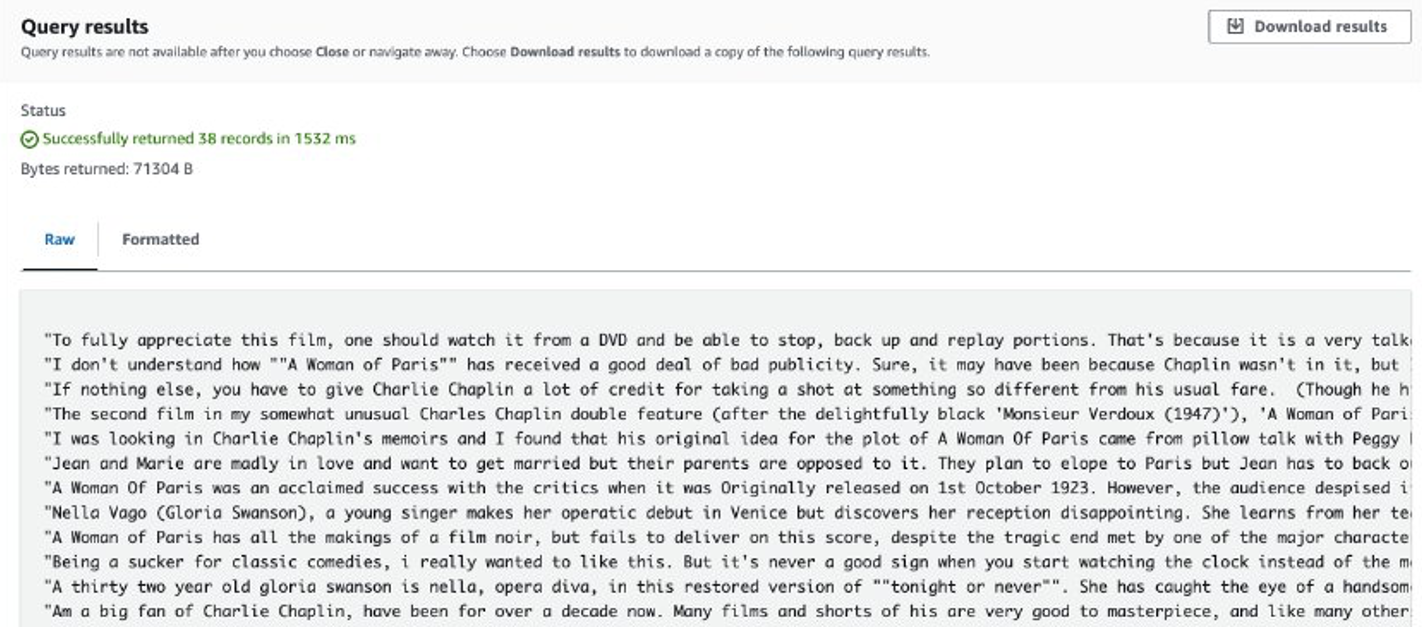
Overvejelser
Følgende er de punkter, du skal overveje, når du håndterer enorme mængder data med tilpasset kode:
- Nogle tredjeparts Python-biblioteker er muligvis ikke tilgængelige i Conda. I sådanne tilfælde kan du skifte til et virtuelt Python-miljø for at bygge PySpark-runtime-miljøet.
- Hvis der er en enorm mængde data, der skal behandles, så prøv at oprette og bruge flere EMR Serverless Spark-applikationer til at parallelisere dem. Hver applikation omhandler et undersæt af fillister.
- Du kan støde på et opbremsningsproblem med Amazon S3, når du filtrerer eller behandler Common Crawl-data. Dette skyldes, at S3-bøtten, der gemmer dataene, er offentligt tilgængelig, og andre brugere kan få adgang til dataene på samme tid. For at afhjælpe dette problem kan du tilføje en genforsøgsmekanisme eller synkronisere specifikke data fra Common Crawl S3-bøtten til din egen bøtte.
Finjuster Llama 2 med SageMaker
Når dataene er forberedt, kan du finjustere en Llama 2-model med den. Du kan gøre det ved at bruge SageMaker JumpStart uden at skrive nogen kode. For mere information, se Finjuster Llama 2 til tekstgenerering på Amazon SageMaker JumpStart.
I dette scenarie udfører du en finjustering af domænetilpasning. Med dette datasæt består input af en CSV-, JSON- eller TXT-fil. Du skal lægge alle anmeldelsesdata i en TXT-fil. For at gøre det kan du sende et enkelt Spark-job til EMR Spark Serverless. Se følgende eksempelkodestykke:
Når du har forberedt træningsdataene, skal du indtaste dataplaceringen for Træningsdatasæt, Og vælg derefter Tog.
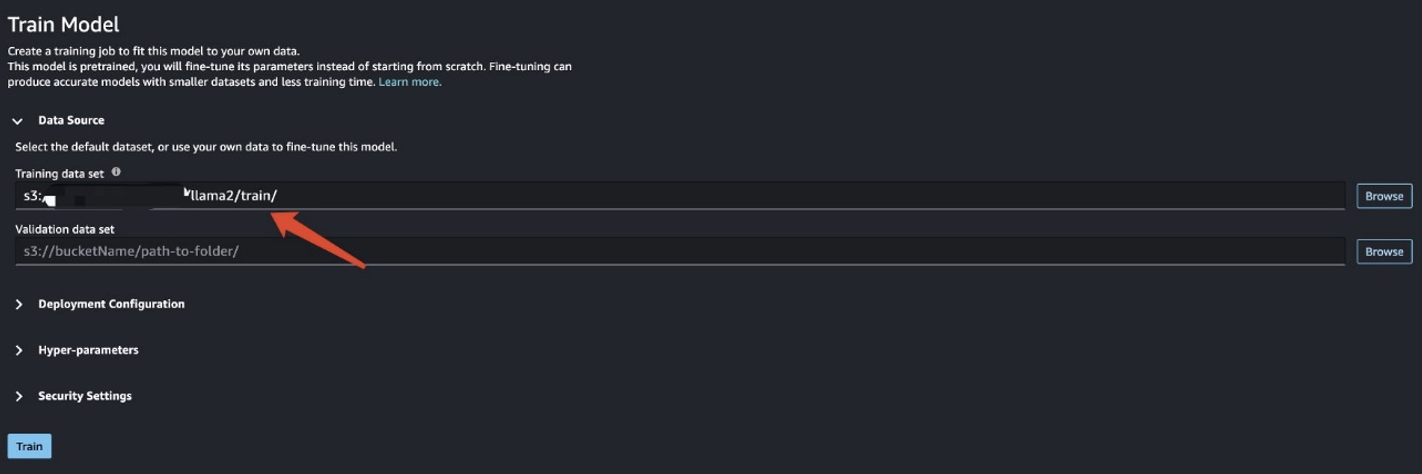
Du kan spore træningsjobstatus.
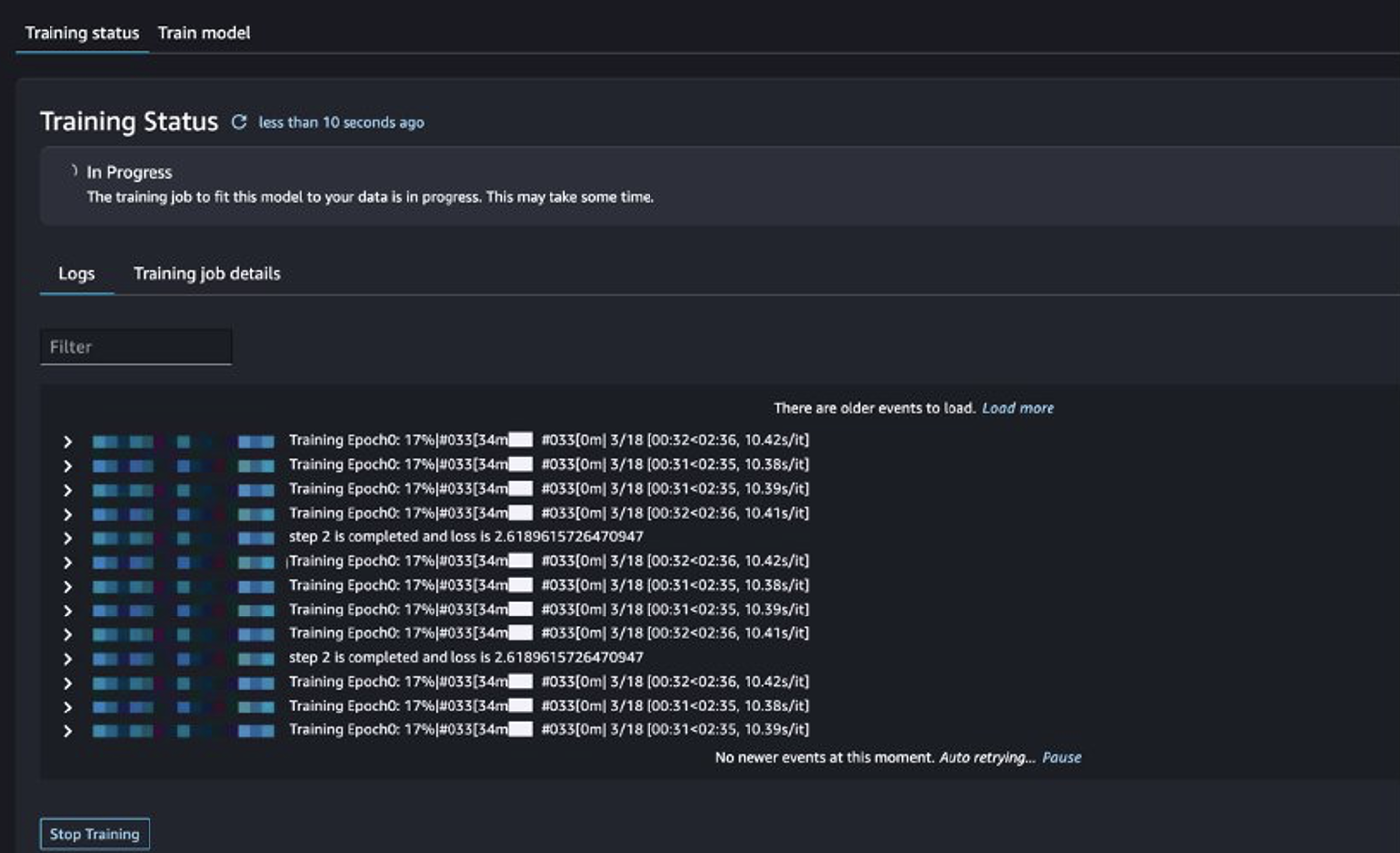
Evaluer den finjusterede model
Når træningen er færdig, skal du vælge Implementer i SageMaker JumpStart for at implementere din finjusterede model.

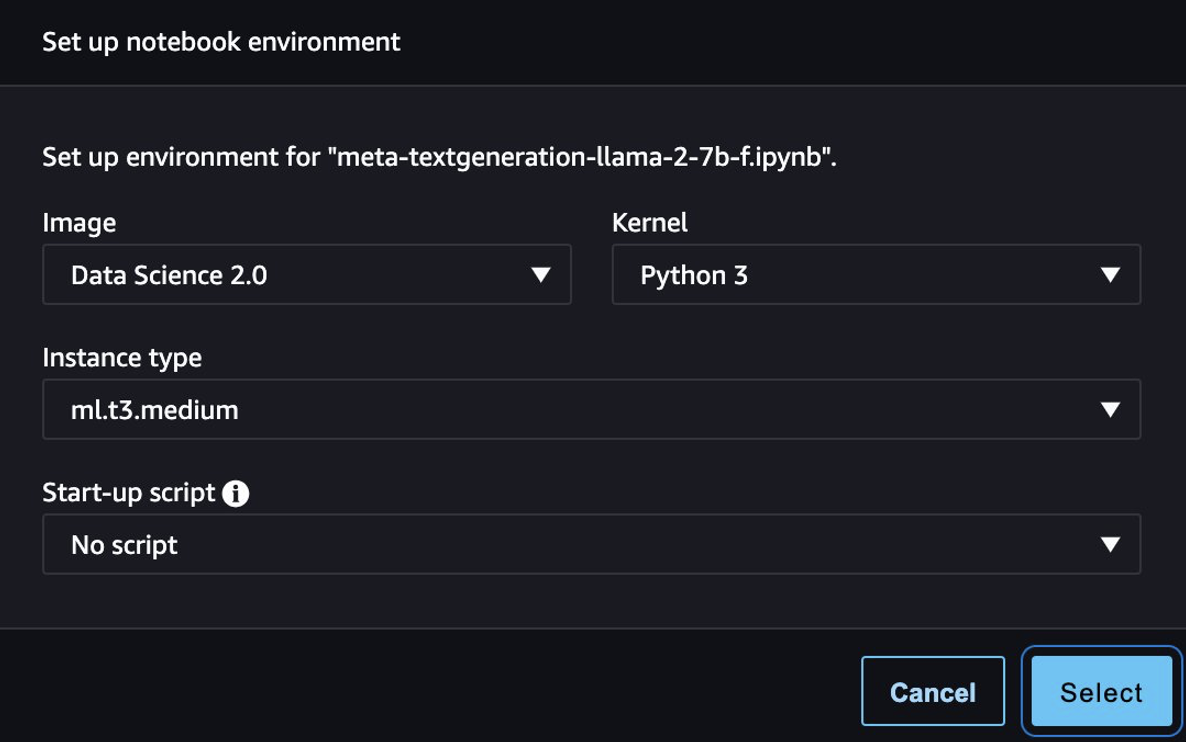
Når modellen er implementeret, skal du vælge Åbn Notesbog, som omdirigerer dig til en forberedt Jupyter-notesbog, hvor du kan køre din Python-kode.

Du kan bruge billedet Data Science 2.0 og Python 3-kernen til notesbogen.
Derefter kan du evaluere den finjusterede model og den originale model i denne notesbog.
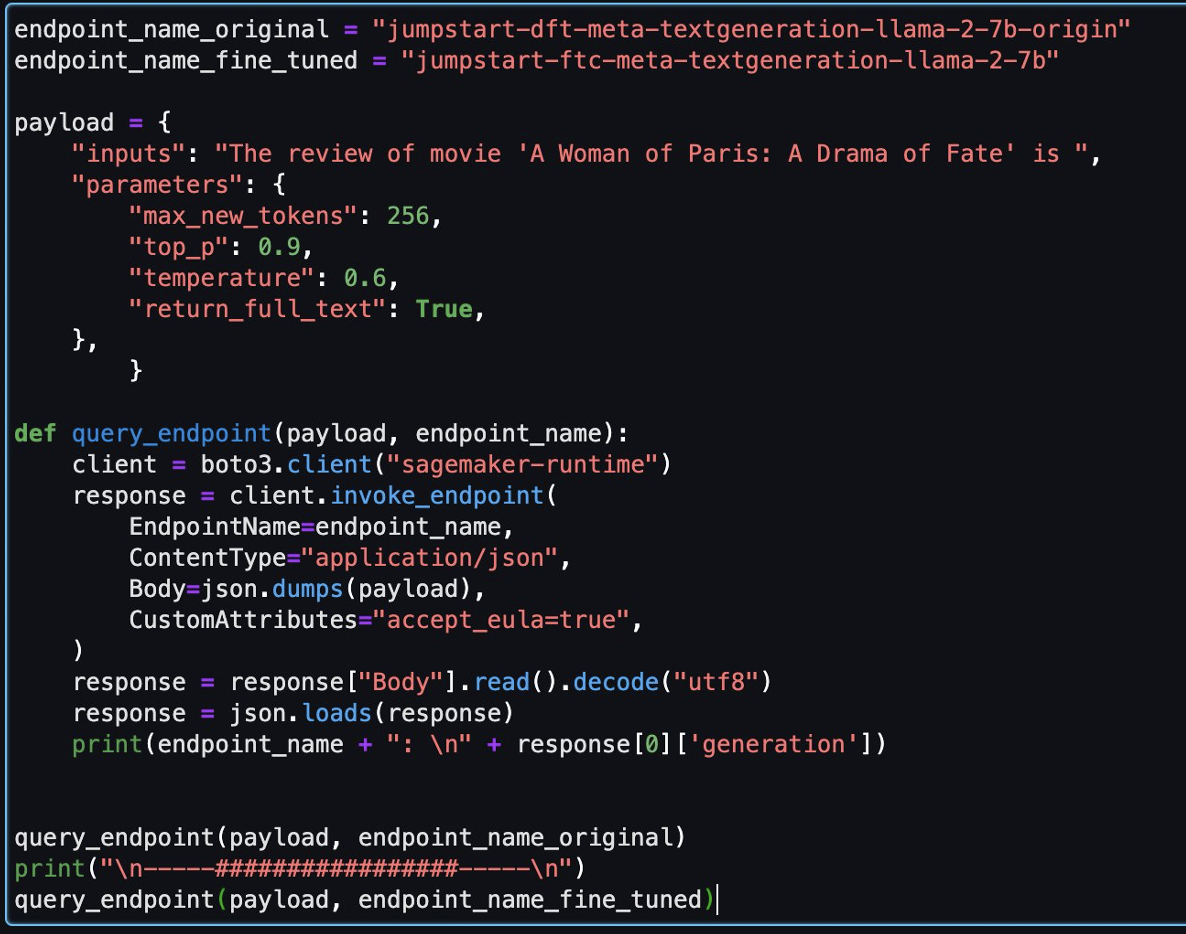
Følgende er to svar returneret af den originale model og finjusterede model for det samme spørgsmål.

Vi forsynede begge modeller med den samme sætning: "Anmeldelsen af filmen 'A Woman of Paris: A Drama of Fate' er" og lod dem fuldføre sætningen.
Den originale model udsender meningsløse sætninger:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
I modsætning hertil er den finjusterede models output mere som en filmanmeldelse:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Det er klart, at den finjusterede model klarer sig bedre i dette specifikke scenarie.
Ryd op
Når du er færdig med denne øvelse, skal du udføre følgende trin for at rydde op i dine ressourcer:
- Slet S3-bøtten der gemmer det rensede datasæt.
- Stop det EMR-serverløse miljø.
- Slet SageMaker-slutpunktet der er vært for LLM-modellen.
- Slet SageMaker-domænet der kører dine notesbøger.
Den applikation, du oprettede, skulle som standard stoppe automatisk efter 15 minutters inaktivitet.
Generelt behøver du ikke at rydde op i Athena-miljøet, fordi der ikke er nogen gebyrer, når du ikke bruger det.
Konklusion
I dette indlæg introducerede vi Common Crawl-datasættet og hvordan man bruger EMR Serverless til at behandle dataene til LLM-finjustering. Derefter demonstrerede vi, hvordan man bruger SageMaker JumpStart til at finjustere LLM og implementere det uden nogen kode. For flere brugssager af EMR Serverless, se Amazon EMR-serverløs. For mere information om hosting og finjustering af modeller på Amazon SageMaker JumpStart, se Sagemaker JumpStart dokumentation.
Om forfatterne
 Shijian Tang er en Analytics Specialist Solution Architect hos Amazon Web Services.
Shijian Tang er en Analytics Specialist Solution Architect hos Amazon Web Services.
 Matthew Liem er Senior Solution Architecture Manager hos Amazon Web Services.
Matthew Liem er Senior Solution Architecture Manager hos Amazon Web Services.
 Dalei Xu er en Analytics Specialist Solution Architect hos Amazon Web Services.
Dalei Xu er en Analytics Specialist Solution Architect hos Amazon Web Services.
 Yuanjun Xiao er Senior Solution Architect hos Amazon Web Services.
Yuanjun Xiao er Senior Solution Architect hos Amazon Web Services.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :er
- :ikke
- :hvor
- $OP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15 %
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- I stand
- Om
- adgang
- af udleverede
- tilgængelig
- Bogføring og administration
- Konti
- opnå
- aktivere
- tilføje
- Desuden
- afrika
- Efter
- Alle
- tillader
- også
- forbløffende
- Amazon
- Amazon EMR
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- beløb
- beløb
- an
- analytics
- ,
- En anden
- enhver
- Apache
- Apache Spark
- Anvendelse
- applikationer
- tilgang
- arkitektur
- ER
- AS
- At
- australsk
- Automatisk Ur
- automatisk
- til rådighed
- AWS
- baggrund
- baseret
- grundlag
- BE
- smuk
- fordi
- blive
- før
- begynde
- være
- Bedre
- mellem
- Big
- Big data
- Billion
- krop
- både
- bygge
- by
- kaldet
- CAN
- Kan få
- Kapacitet
- bære
- tilfælde
- tilfælde
- skiftende
- karakter
- afgifter
- kontrollere
- kinesisk
- Vælg
- klasse
- ren
- kunde
- Cluster
- kode
- KOM
- Fælles
- almindeligt
- sammenligne
- fuldføre
- konfigurering
- Overvej
- består
- Konsol
- konstant
- indeholder
- indeholder
- indhold
- kontinuerligt
- kontrast
- Tilsvarende
- svarer
- Koste
- omkostningseffektiv
- kunne
- tælle
- dæksel
- skabe
- oprettet
- skik
- kunde
- tilpassede
- data
- Dataanalyse
- databehandling
- datalogi
- datasæt
- Davis
- beskæftiger
- Tilbud
- dyb
- Standard
- definere
- Demo
- demonstrere
- demonstreret
- indsætte
- indsat
- implementering
- Afledt
- Trods
- detaljer
- bestemmelse
- diagram
- forskelle
- forskelligt
- rettet
- direkte
- diskuterer
- dyk
- do
- dokumenter
- domæne
- Domæner
- donald
- Dont
- ned
- Drama
- driver
- varighed
- i løbet af
- hver
- tidligere
- let
- eliminerer
- understreger
- møde
- Engineering
- styrke
- Indtast
- Miljø
- Ether (ETH)
- evaluere
- eksempel
- eksempler
- udførelse
- Dyrke motion
- eksisterende
- eksisterer
- udforske
- udforsket
- udvide
- ekstern
- ekstrakt
- udvinding
- Uddrag
- Falls
- falsk
- hurtigere
- skæbne
- featured
- få
- Fields
- File (Felt)
- Filer
- filtrere
- filtrering
- Endelig
- Finde
- slut
- Fornavn
- efter
- følger
- Til
- format
- fundet
- Framework
- rammer
- fra
- yderligere
- Generelt
- generelt
- generere
- generation
- få
- Git
- GitHub
- vejledende
- Have
- hjælpe
- Hive
- Hosting
- værter
- Hvordan
- How To
- Men
- HTML
- HTTPS
- Hundreder
- i
- IAM
- ID
- if
- illustrerer
- billede
- importere
- vigtigt
- Forbedre
- in
- medtaget
- omfatter
- inkorporering
- stigende
- indeks
- oplysninger
- Infrastruktur
- indgang
- indgange
- installere
- interagere
- ind
- indføre
- introduceret
- spørgsmål
- IT
- ITS
- Jack
- Job
- Karriere
- json
- Jupyter Notebook
- lige
- Holde
- Nøgle
- Sprog
- Sprog
- storstilet
- seneste
- lancere
- lancering
- føre
- lad
- Niveau
- biblioteker
- ligesom
- GRÆNSE
- linjer
- Liste
- Lister
- Llama
- llm
- lokale
- placeret
- placering
- logik
- Logge på
- Se
- leder
- kig op
- maskine
- vedligeholdelse
- lave
- Making
- leder
- styring
- mange
- kort
- massive
- Kan..
- mekanisme
- Mød
- opfylder
- nævne
- Meta
- Metadata
- metode
- minutter
- afbøde
- model
- modeller
- månedligt
- mere
- mest
- film
- Film
- meget
- flere
- navn
- navne
- Navigation
- nødvendig
- Behov
- netværk
- Ny
- næste
- ingen
- node
- notesbog
- notesbøger
- opnået
- oktober
- of
- on
- ONE
- kun
- åbent
- open source
- Option
- or
- original
- Andet
- ud
- skitseret
- output
- udgange
- i løbet af
- overstyring
- egen
- Pack
- pakke
- brød
- Papir
- Parallel
- parametre
- Paris
- del
- sti
- stier
- Betal
- Mennesker
- ydeevne
- forestillinger
- udfører
- periode
- petabytes
- Peter
- fotograf
- perron
- plato
- Platon Data Intelligence
- PlatoData
- grund
- punkter
- Populær
- Indlæg
- strøm
- præ
- forud
- Forbered
- forberedt
- primære
- behandle
- bearbejdet
- forarbejdning
- produktion
- prompter
- give
- forudsat
- giver
- leverer
- offentligt
- formål
- sætte
- Python
- query
- spørgsmål
- hurtigt
- Raw
- rådata
- nå
- Læs
- klar
- nylige
- for nylig
- anbefales
- optage
- henvise
- referencer
- regelmæssigt
- forhold
- frigivet
- reparere
- erstatte
- anmodninger
- påkrævet
- Krav
- Ressourcer
- svar
- reaktioner
- resultere
- Resultater
- gennemgå
- Anmeldelser
- højre
- roller
- rory
- Kør
- kører
- løber
- sagemaker
- samme
- Gem
- Scale
- skalaer
- skalering
- scanninger
- scenarie
- Videnskab
- script
- scripts
- sekunder
- Sektion
- sektioner
- se
- segment
- Vælg
- SELV
- senior
- dømme
- Serverless
- servere
- Tjenester
- sæt
- indstilling
- flere
- hun
- Kort
- bør
- vist
- betydning
- lignende
- siden
- enkelt
- websted
- Størrelse
- Sænk farten
- uddrag
- So
- løsninger
- Løsninger
- suppe
- Kilde
- Spark
- specialist
- specifikke
- SQL
- ssh
- påbegyndt
- Starter
- Statement
- udsagn
- Status
- Trin
- Steps
- Stadig
- Stands
- butik
- opbevaret
- forhandler
- Story
- ligetil
- strategier
- String
- Studio
- indsende
- indsendelse
- Succesfuld
- sådan
- tilstrækkeligt
- egnede
- Kontakt
- synkronisere.
- bord
- Tag
- mål
- Opgaver
- opgaver
- tensorflow
- vilkår
- tests
- tekst
- tekstgenerering
- at
- deres
- Them
- derefter
- Der.
- Disse
- de
- tredjepart
- denne
- tre
- Gennem
- tid
- tidsstempel
- til
- spor
- Kurser
- rejser
- sand
- prøv
- to
- typer
- under
- ustruktureret
- opdateret
- URL
- brug
- brug tilfælde
- anvendte
- Bruger
- brugeranmeldelser
- brugere
- ved brug af
- Ved hjælp af
- udgave
- Virtual
- mængder
- gå
- ønsker
- ønskede
- Warehouse
- var
- Vej..
- måder
- we
- web
- webservices
- uge
- GODT
- Hvad
- hvornår
- ud fra følgende betragtninger
- som
- mens
- WHO
- Wildlife
- vilje
- william
- med
- inden for
- uden
- kvinde
- arbejdede
- værd
- skriver
- skrivning
- Udbytte
- dig
- Din
- zephyrnet