Vi indså for nylig, at vi ikke havde bragt dig nogen datavidenskabs-cheatsheets i et stykke tid. Og det er ikke for deres manglende tilgængelighed; datavidenskabscheatsheets er overalt, lige fra introduktion til avanceret, der dækker emner fra algoritmer, til statistik, til interviewtips og mere.
Men hvad gør et godt cheatsheet? Hvad gør et cheatsheet værdigt til at blive udpeget som et særligt godt? Det er svært at sætte fingeren på præcist Det, der gør et godt snydeark, men naturligvis et, der formidler væsentlig information kortfattet - uanset om denne information er af en specifik af generel karakter - er bestemt en god start. Og det er det, der gør vores kandidater i dag bemærkelsesværdige. Så læs videre for fire kuraterede supplerende snydeark til at hjælpe dig med din læring eller anmeldelse af datavidenskab.
Første op er Aaron Wangs Data Science Cheatsheet 2.0, en fire siders samling af statistiske abstraktioner, grundlæggende maskinlæringsalgoritmer og deep learning-emner og -koncepter. Det er ikke meningen, at det skal være udtømmende, men derimod en hurtig reference til situationer som interviewforberedelse og eksamensgennemgange og alt andet, der kræver et tilsvarende niveau af gennemgangsdybde. Forfatteren bemærker, at mens de med en grundlæggende forståelse af statistik og lineær algebra ville finde denne ressource til størst gavn, bør begyndere også være i stand til at hente nyttig information fra dens indhold.

Skærmbillede fra Aaron Wangs Data Science Cheatsheet 2.0
Vores næste cheatsheet-tilbud i dag er det, som Aaron Wangs ressource er baseret på, Maverick Lin's Data Science Cheatsheet (Wangs henvisning til sin egen som 2.0 er et direkte nik til Lins "original"). Vi kan tænke på Lins snydeark som mere dybdegående end Wangs (selvom Wangs beslutning om at gøre hans mindre dybdegående virker bevidst og et nyttigt alternativ), der dækker mere fundamentale datavidenskabelige begreber såsom datarensning, ideen om modellering, at lave " big data" med Hadoop, SQL og endda det grundlæggende i Python.
Dette vil klart appellere til dem, der er mere fast i "begynder"-lejren, og gør et godt stykke arbejde med at vække appetit og gøre læserne opmærksomme på det brede felt af datavidenskab og mange af de forskellige begreber, som det omfatter. Dette er bestemt endnu en solid ressource, især hvis læseren er nybegynder inden for datavidenskab.

Skærmbillede fra Maverick Lin's Data Science Snydeark
Efterhånden som vi bevæger os længere tilbage i tiden – søger inspiration til Lins snydeark – støder vi på William Chens sandsynlighed snydeark 2.0. Chens cheatsheet har høstet meget opmærksomhed og ros gennem årene, og så du er måske stødt på det på et tidspunkt. Chens cheatsheet er tydeligvis med et andet fokus (givet dets navn), et lynkursus om eller dybtgående gennemgang af sandsynlighedsbegreber, herunder en række fordelinger, kovarians og transformationer, betinget forventning, Markov-kæder, forskellige formler af betydning, og meget mere.
På 10 sider burde du være i stand til at forestille dig bredden af sandsynlighedsemner, der dækkes her. Men lad det ikke afskrække dig; Chens evne til at koge koncepter ned til deres væsentlige punktopstillinger og forklare på almindeligt engelsk uden at ofre sig på det væsentlige er bemærkelsesværdig. Den er også rig på forklarende visualiseringer, noget ganske nyttigt, når pladsen er begrænset, og ønsket om at være kortfattet er stærkt.
Ikke alene er Chens kompilering af høj kvalitet og værdig til din tid, som nybegynder eller en person, der er interesseret i en fuldstændig anmeldelse, ville jeg arbejde i omvendt rækkefølge af, hvordan disse ressourcer blev præsenteret - fra Chens snydeark, til Lins og til sidst til Wangs, bygge oven på koncepter, mens du går.
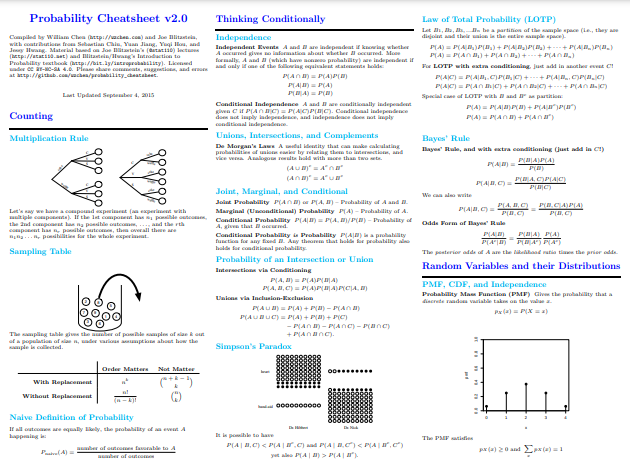
Skærmbillede fra William Chen's Sandsynlighed Cheatsheet 2.0
En sidste ressource, jeg medtager her, men ikke teknisk set et snydeark, er Rishabh Anands Machine Learning Bites. Anand har faktureret sig selv som "[en] interviewguide om almindelige Machine Learning-koncepter, bedste praksis, definitioner og teori" og har samlet en bred samling af videns-"bites", hvis nytte absolut overstiger den oprindeligt tilsigtede interviewforberedelse. Emner dækket inden for inkluderer:
- Modelscoremålinger
- Parameterdeling
- k-fold krydsvalidering
- Python datatyper
- Forbedring af modellens ydeevne
- Computer Vision modeller
- Attention og dens varianter
- Håndtering af klasseubalance
- Computer Vision Ordliste
- Vanilje tilbageformering
- Regularisering
- Referencer

Skærmbillede fra Machine Learning Bites
Mens maskinlæring "koncepter, bedste praksis, definitioner og teori" bliver berørt, som lovet i ressourcens beskrivelse af sig selv, er disse "bid" bestemt rettet mod det praktiske, hvilket gør webstedet komplementært til meget af det materiale, der er dækket i de tre tidligere nævnte cheatsheets. Hvis jeg søgte at dække alt materialet i alle fire ressourcer i dette indlæg, ville jeg bestemt se på dette efter de tre andre.
Så der har du fire cheatsheets (eller tre cheatsheets og en cheatsheet-tilstødende ressource) til at bruge til din læring eller anmeldelse. Forhåbentlig er noget her nyttigt for dig, og jeg inviterer alle til at dele de cheatsheets, de har fundet nyttige, i kommentarerne nedenfor.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Aaron
- evne
- I stand
- tværs
- fremskreden
- Efter
- algoritmer
- Alle
- alternativ
- ,
- En anden
- nogen
- anke
- opmærksomhed
- forfatter
- tilgængelighed
- tilbage
- baseret
- grundlæggende
- Grundlæggende
- begyndere
- være
- jf. nedenstående
- gavner det dig
- BEDSTE
- bedste praksis
- Beyond
- Big
- Big data
- fakturerings- og
- bredde
- bred
- bragte
- Bygning
- Camp
- kandidater
- sikkert
- kæder
- chen
- klasse
- Rengøring
- tydeligt
- samling
- Kom
- kommentarer
- Fælles
- komplementære
- begreber
- indhold
- kursus
- dæksel
- dækket
- dækker
- Crash
- Cross
- kurateret
- data
- datalogi
- beslutning
- dyb
- dyb dykke
- dyb læring
- definitivt
- dybde
- beskrivelse
- forskellige
- svært
- direkte
- Distributioner
- gør
- ned
- vedrører generelt
- Engelsk
- især
- væsentlig
- essentials
- Ether (ETH)
- Endog
- eksamen
- forventning
- Forklar
- felt
- Figur
- endelige
- Endelig
- Finde
- fast
- Fokus
- fundet
- fra
- fuld
- fundamental
- yderligere
- gearet
- Generelt
- given
- Go
- godt
- godt arbejde
- vejlede
- link.
- Forhåbentlig
- Hvordan
- HTTPS
- idé
- ubalance
- betydning
- in
- dybdegående
- omfatter
- Herunder
- oplysninger
- Inspiration
- i stedet
- Forsætlig
- interesseret
- Interview
- indledende
- invitere
- IT
- selv
- Job
- viden
- Mangel
- læring
- Niveau
- Limited
- Se
- leder
- maskine
- machine learning
- lave
- maerker
- Making
- mange
- materiale
- maverick
- nævnte
- Metrics
- model
- modeller
- mere
- mest
- bevæge sig
- navn
- Natur
- næste
- Noter
- bemærkelsesværdigt
- Begreb
- tilbyde
- ONE
- ordrer
- original
- oprindeligt
- Andet
- egen
- især
- ydeevne
- Almindeligt
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- punkter
- Indlæg
- Praktisk
- praksis
- forelagt
- tidligere
- lovede
- sætte
- Python
- kvalitet
- Hurtig
- spænder
- Læs
- Læser
- læsere
- gik op for
- for nylig
- ressource
- Ressourcer
- vende
- gennemgå
- Anmeldelser
- Rich
- at ofre
- Videnskab
- scoring
- søger
- synes
- Del
- deling
- bør
- lignende
- websted
- situationer
- So
- solid
- nogle
- Nogen
- noget
- Space
- specifikke
- starte
- statistiske
- statistik
- stærk
- sådan
- Grundlæggende
- deres
- tre
- tid
- tips
- til
- i dag
- top
- Emner
- mod
- transformationer
- typer
- forståelse
- brug
- validering
- række
- forskellige
- vision
- Hvad
- hvorvidt
- som
- mens
- WHO
- bred
- vilje
- inden for
- Arbejde
- ville
- år
- Din
- zephyrnet




