Billede af forfatter
Der er mange kurser og ressourcer tilgængelige om maskinlæring og datavidenskab, men meget få om datateknik. Dette rejser nogle spørgsmål. Er det et svært felt? Giver det lav løn? Anses det ikke for lige så spændende som andre tech-roller? Virkeligheden er dog, at mange virksomheder aktivt søger dataingeniørtalent og tilbyder betydelige lønninger, nogle gange over $200,000 USD. Dataingeniører spiller en afgørende rolle som arkitekterne bag dataplatforme, der designer og bygger de grundlæggende systemer, der gør det muligt for dataforskere og maskinlæringseksperter at fungere effektivt.
DataTalkClub har indført en transformativ og gratis bootcamp for at afhjælpe denne industrikløft, "Data Engineering Zoomcamp“. Dette kursus er designet til at styrke begyndere eller professionelle, der ønsker at skifte karriere, med væsentlige færdigheder og praktisk erfaring inden for datateknik.
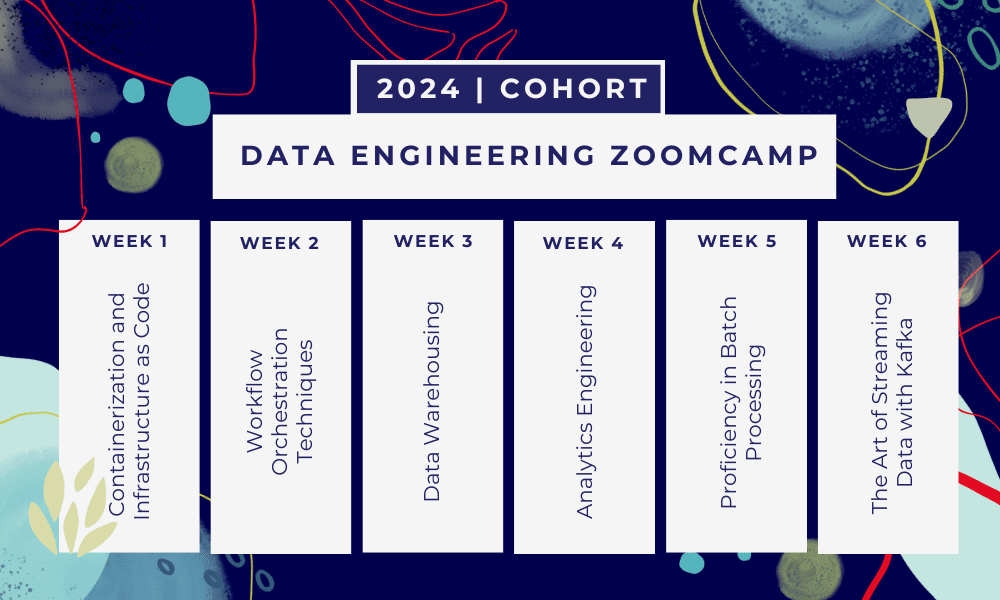
Dette er et 6 ugers bootcamp hvor du lærer gennem flere kurser, læsematerialer, workshops og projekter. I slutningen af hvert modul får du hjemmearbejde for at øve dig på det, du har lært.
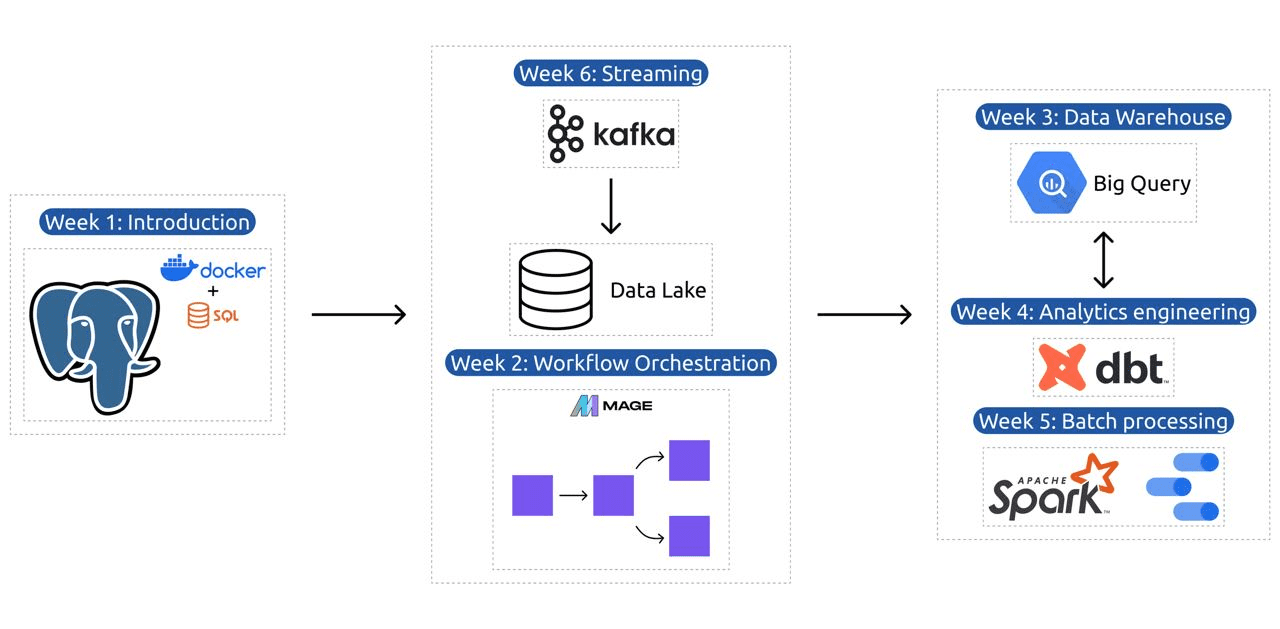
- Uge 1: Introduktion til GCP, Docker, Postgres, Terraform og miljøopsætning.
- Uge 2: Workflow-orkestrering med Mage.
- Uge 3: Data warehousing med BigQuery og maskinlæring med BigQuery.
- Uge 4: Analytisk ingeniør med dbt, Google Data Studio og Metabase.
- Uge 5: Batchbehandling med Spark.
- Uge 6: Streaming med Kafka.
Billede fra DataTalksClub/data-engineering-zoomcamp
Pensum indeholder 6 moduler, 2 workshops og et projekt, der dækker alt, hvad der skal til for at blive professionel dataingeniør.
Modul 1: Mestring af containerisering og infrastruktur som kode
I dette modul lærer du om Docker og Postgres, begyndende med det grundlæggende og videre gennem detaljerede tutorials om at skabe datapipelines, køre Postgres med Docker og mere.
Modulet dækker også vigtige værktøjer som pgAdmin, Docker-compose og SQL genopfriskningsemner med valgfrit indhold på Docker-netværk og en særlig gennemgang for Windows-undersystem Linux-brugere. I sidste ende introducerer kurset dig til GCP og Terraform, hvilket giver en holistisk forståelse af containerisering og infrastruktur som en kode, der er essentiel for moderne cloud-baserede miljøer.
Modul 2: Workflow Orchestration Teknikker
Modulet tilbyder en dybdegående udforskning af Mage, en innovativ open source hybridramme til datatransformation og integration. Dette modul begynder med det grundlæggende i workflow-orkestrering og går videre til praktiske øvelser med Mage, herunder opsætning af det via Docker og opbygning af ETL-pipelines fra API til Postgres og Google Cloud Storage (GCS) og derefter til BigQuery.
Modulets blanding af videoer, ressourcer og praktiske opgaver sikrer en omfattende læringsoplevelse, der udstyrer eleverne med færdigheder til at administrere sofistikerede data-workflows ved hjælp af Mage.
Workshop 1: Dataindtagelsesstrategier
I den første workshop vil du mestre at bygge effektive dataindtagelsespipelines. Workshoppen fokuserer på væsentlige færdigheder som at udtrække data fra API'er og filer, normalisering og indlæsning af data og inkrementelle indlæsningsteknikker. Efter at have gennemført denne workshop, vil du være i stand til at skabe effektive datapipelines som en senior dataingeniør.
Modul 3: Data warehousing
Modulet er en dybdegående udforskning af datalagring og -analyse med fokus på Data Warehousing ved hjælp af BigQuery. Den dækker nøglebegreber som partitionering og klyngedannelse og dykker ned i BigQuerys bedste praksis. Modulet udvikler sig til avancerede emner, især integrationen af Machine Learning (ML) med BigQuery, der fremhæver brugen af SQL til ML og giver ressourcer til justering af hyperparameter, forbehandling af funktioner og modelimplementering.
Modul 4: Analytics Engineering
Det analytiske ingeniørmodul fokuserer på at bygge et projekt ved hjælp af dbt (Data Build Tool) med et eksisterende datavarehus, enten BigQuery eller PostgreSQL.
Modulet dækker opsætning af dbt i både cloud og lokale miljøer, introduktion af analytiske ingeniørkoncepter, ETL vs ELT og datamodellering. Det dækker også avancerede dbt-funktioner såsom inkrementelle modeller, tags, hooks og snapshots.
Til sidst introducerer modulet teknikker til visualisering af transformerede data ved hjælp af værktøjer som Google Data Studio og Metabase, og det giver ressourcer til fejlfinding og effektiv dataindlæsning.
Modul 5: Færdighed i batchbehandling
Dette modul dækker batchbehandling ved hjælp af Apache Spark, startende med introduktioner til batchbehandling og Spark, sammen med installationsinstruktioner til Windows, Linux og MacOS.
Det omfatter udforskning af Spark SQL og DataFrames, forberedelse af data, udførelse af SQL-handlinger og forståelse af Spark internals. Til sidst afsluttes det med at køre Spark i skyen og integrere Spark med BigQuery.
Modul 6: Kunsten at streame data med Kafka
Modulet begynder med en introduktion til strømbehandlingskoncepter, efterfulgt af en dybdegående udforskning af Kafka, herunder dets grundlæggende principper, integration med Confluent Cloud og praktiske applikationer, der involverer producenter og forbrugere.
Modulet dækker også Kafka-konfiguration og -streams, og behandler emner som stream joins, test, windowing og brugen af Kafka ksqldb & Connect. Derudover udvider det sit fokus til Python- og JVM-miljøer, med Faust til Python-strømbehandling, Pyspark – Structured Streaming og Scala-eksempler til Kafka Streams.
Workshop 2: Stream Processing med SQL
Du lærer at behandle og administrere streamingdata med RisingWave, som giver en omkostningseffektiv løsning med en PostgreSQL-lignende oplevelse for at styrke dine streambehandlingsapplikationer.
Projekt: Real-World Data Engineering Application
Målet med dette projekt er at implementere alle de koncepter, vi har lært i dette kursus, for at konstruere en ende-til-ende datapipeline. Du vil oprette for at oprette et dashboard bestående af to fliser ved at vælge et datasæt, bygge en pipeline til at behandle dataene og gemme dem i en datasø, bygge en pipeline til at overføre de behandlede data fra datasøen til et datavarehus, transformere dataene i datavarehuset og forberede dem til dashboardet, og til sidst bygge et dashboard til at præsentere dataene visuelt.
2024 Kohortedetaljer
- Tilmelding: Tilmeld dig nu
- Startdato: 15. januar 2024 kl. 17:00 CET
- Læring i eget tempo med guidet støtte
- Kohorte mappe med lektier og deadlines
- Interactive Slap Fællesskabet til peer learning
Forudsætninger
- Grundlæggende kodning og kommandolinjefærdigheder
- Foundation i SQL
- Python: gavnligt, men ikke obligatorisk
Erfarne instruktører, der leder din rejse
- Ankush Khanna
- Victoria Perez Mola
- Alexey Grigorev
- Matt Palmer
- Luis Oliveira
- Michael Skomager
Tilmeld dig vores 2024-kohorte og begynd at lære med et fantastisk dataingeniørfællesskab. Med ekspertstyret træning, praktisk erfaring og et læseplan skræddersyet til branchens behov, udstyrer denne bootcamp dig ikke kun med de nødvendige færdigheder, men placerer dig også på forkant med en lukrativ og efterspurgt karrierevej. Tilmeld dig i dag og forvandl dine forventninger til virkelighed!
Abid Ali Awan (@1abidaliawan) er en certificeret dataforsker, der elsker at bygge maskinlæringsmodeller. I øjeblikket fokuserer han på indholdsskabelse og skriver tekniske blogs om maskinlæring og datavidenskabsteknologier. Abid har en kandidatgrad i teknologiledelse og en bachelorgrad i telekommunikationsingeniør. Hans vision er at bygge et AI-produkt ved hjælp af et grafisk neuralt netværk til studerende, der kæmper med psykisk sygdom.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 1
- 15 %
- 17
- 2024
- a
- I stand
- Om
- aktivt
- Derudover
- adressering
- fremskreden
- fremrykkende
- Efter
- AI
- Alle
- sammen
- også
- forbløffende
- an
- analyse
- Analytisk
- analytics
- ,
- og infrastruktur
- Apache
- Apache Spark
- api
- API'er
- applikationer
- arkitekter
- ER
- Kunst
- AS
- At
- til rådighed
- Grundlæggende
- BE
- bliver
- blive
- begyndere
- gavnlig
- BEDSTE
- bedste praksis
- bigquery
- Blanding
- blogs
- både
- bygge
- Bygning
- men
- by
- Karriere
- karriere
- Certificeret
- Cloud
- Cloud Storage
- klyngedannelse
- kode
- Kodning
- kohorte
- samfund
- Virksomheder
- færdiggøre
- omfattende
- begreber
- konkluderer
- Konfiguration
- krydset
- Tilslut
- betragtes
- Bestående
- konstruere
- Forbrugere
- indeholder
- indhold
- indholdsskabelse
- kursus
- kurser
- dækker
- skabe
- Oprettelse af
- skabelse
- afgørende
- For øjeblikket
- Curriculum
- instrumentbræt
- data
- dataingeniør
- Data Lake
- datalogi
- dataforsker
- data opbevaring
- datalager
- Dato
- Degree
- implementering
- konstrueret
- designe
- detaljeret
- svært
- Docker
- hver
- effektivt
- effektiv
- enten
- bemyndige
- muliggøre
- ende
- ende til ende
- ingeniør
- Engineering
- Ingeniører
- tilmelde
- sikrer
- Miljø
- miljøer
- væsentlig
- Ether (ETH)
- at alt
- eksempler
- spændende
- eksisterende
- erfaring
- eksperter
- udforskning
- Udforskning
- udvider
- Feature
- Funktionalitet
- Med
- få
- felt
- Filer
- Endelig
- Fornavn
- Fokus
- fokuserer
- fokusering
- efterfulgt
- Til
- forkant
- foundational
- Framework
- Gratis
- fra
- funktion
- Fundamentals
- kløft
- GCP
- given
- Google Cloud
- graf
- Graf neuralt netværk
- guidet
- hands-on
- Have
- he
- fremhæve
- hans
- besidder
- holistisk
- hjemmearbejde
- Kroge
- Men
- HTTPS
- Hybrid
- Tuning af hyperparameter
- sygdom
- gennemføre
- in
- dybdegående
- omfatter
- Herunder
- inkremental
- industrien
- Infrastruktur
- innovativ
- installation
- anvisninger
- Integration
- integration
- ind
- introduceret
- Introducerer
- indføre
- Introduktion
- introduktioner
- involverer
- IT
- ITS
- januar
- Sammenføjninger
- Kafka
- KDnuggets
- Nøgle
- sø
- førende
- LÆR
- lærte
- elever
- læring
- ligesom
- Line (linje)
- linux
- lastning
- lokale
- leder
- elsker
- Lav
- lukrative
- maskine
- machine learning
- MacOS
- administrere
- ledelse
- obligatorisk
- mange
- Master
- mastering
- materialer
- mentale
- Psykisk sygdom
- ML
- model
- modellering
- modeller
- Moderne
- modul
- Moduler
- mere
- flere
- nødvendig
- Behov
- behov
- behov
- netværk
- netværk
- Neural
- neurale netværk
- objektiv
- of
- tilbyde
- Tilbud
- on
- kun
- open source
- Produktion
- or
- orkestrering
- Andet
- vores
- Palmer
- især
- sti
- Betal
- peer
- udfører
- pipeline
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- positioner
- postgresql
- Praktisk
- Praktiske anvendelser
- praksis
- praksis
- forberede
- præsentere
- behandle
- bearbejdet
- forarbejdning
- Producenter
- Produkt
- professionel
- professionelle partnere
- skrider frem
- projekt
- projekter
- giver
- leverer
- Python
- Spørgsmål
- rejser
- Læsning
- virkelige verden
- Reality
- Ressourcer
- roller
- roller
- kører
- s
- lønninger
- Scala
- Videnskab
- Videnskabsmand
- forskere
- søger
- udvælgelse
- senior
- indstilling
- setup
- færdigheder
- slæk
- løsninger
- nogle
- sommetider
- sofistikeret
- Spark
- særligt
- SQL
- starte
- Starter
- opbevaring
- strøm
- streaming
- vandløb
- struktureret
- Kæmper
- Studerende
- Studio
- væsentlig
- sådan
- support
- Kontakt
- Systemer
- skræddersyet
- Talent
- opgaver
- tech
- Teknisk
- teknikker
- Teknologier
- Teknologier
- telekommunikation
- terraform
- Test
- at
- Grundlæggende
- derefter
- denne
- Gennem
- til
- i dag
- værktøj
- værktøjer
- Emner
- Kurser
- Overførsel
- Transform
- Transformation
- transformative
- omdannet
- omdanne
- tutorials
- to
- forståelse
- USD
- brug
- brugere
- ved brug af
- Ve
- meget
- via
- Videoer
- vision
- visuelt
- vs
- Warehouse
- Warehousing
- we
- Hvad
- som
- WHO
- vilje
- vinduer
- med
- workflow
- arbejdsgange
- værksted
- workshops
- skrivning
- dig
- Din
- zephyrnet










