Billede af redaktør
Det er 2023, hvilket betyder, at de fleste virksomheder i de fleste brancher indsamler indsigt og træffer smartere beslutninger ved hjælp af big data. Dette kommer ikke som meget af en overraskelse i disse dage - evnen til at indsamle, kategorisere og analysere store datasæt er umådelig nyttig, når det kommer til at tage datadrevne forretningsbeslutninger.
Og efterhånden som et stigende antal organisationer omfavner digitalisering, vil evnen til at forstå og stole på dataanalyses anvendelighed kun fortsætte med at vokse.
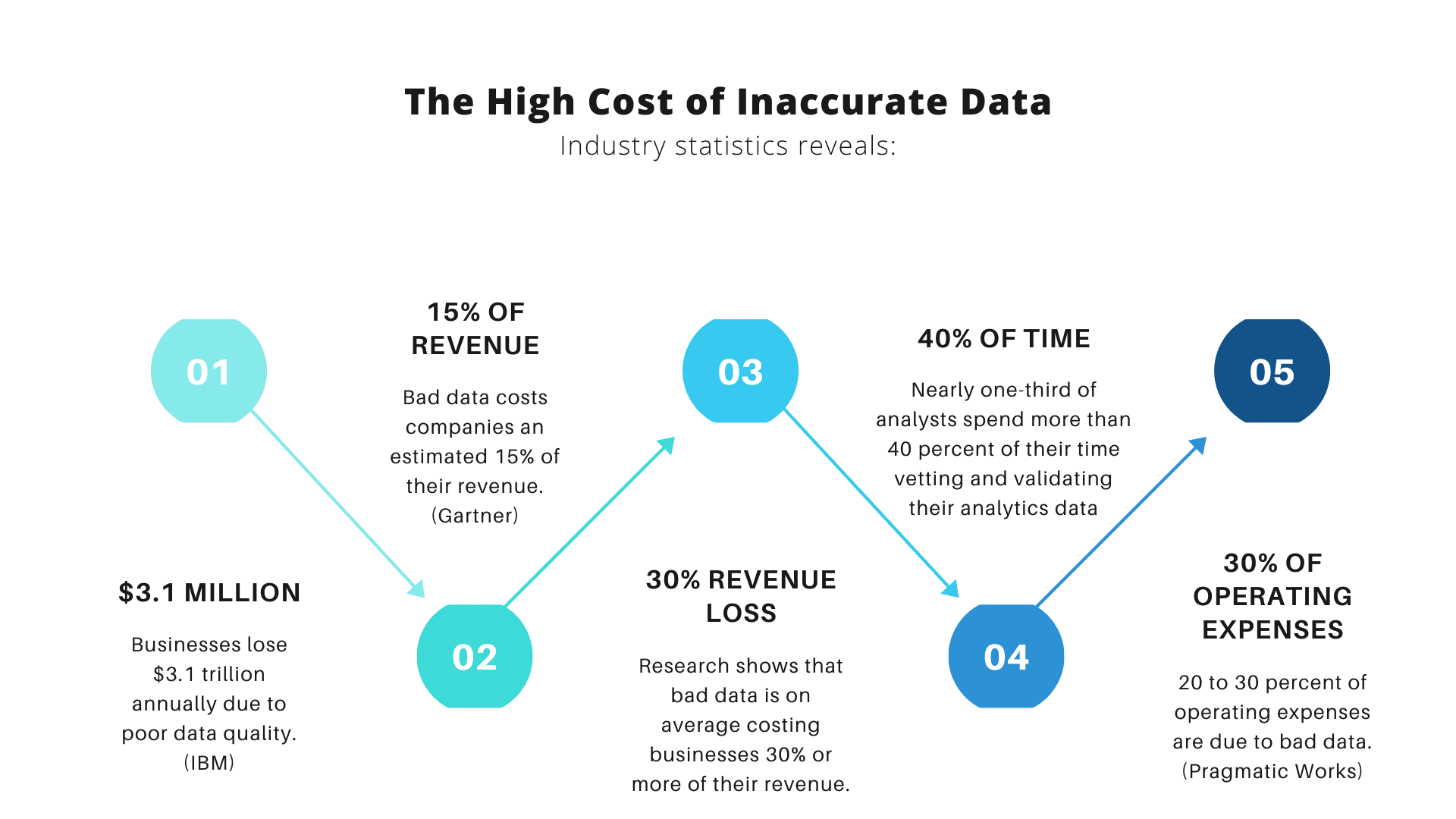
Her er det dog med big data: efterhånden som flere organisationer kommer til at stole på det, jo større er chancen for, at flere af dem vil bruge big data forkert. Hvorfor? Fordi big data og den indsigt, den giver, kun er nyttig, hvis organisationer analyserer deres data nøjagtigt.
Billede fra datastige
Lad os derfor sørge for, at du undgår nogle almindelige fejl, som ofte påvirker nøjagtigheden af dataanalyse. Læs videre for at lære om disse problemer, og hvordan du kan undgå dem.
Før vi peger fingre, er vi nødt til at indrømme, at de fleste sæt data har deres rimelige andel af fejl, og disse fejl gør ingen tjeneste, når det er tid til at analysere data. Uanset om det er slåfejl, mærkelige navnekonventioner eller redundanser, forvirrer fejl i datasæt nøjagtigheden af dataanalysen.
Så før du bliver alt for begejstret for at dykke dybt ind i dataanalyse-kaninhullet, skal du først sikre dig, at datarensning er øverst på din huskeliste, og at du altid renser dine datasæt ordentligt. Du siger måske, "hey, datarensning er for tidskrævende for mig at besvære mig med", hvortil vi nikker med hovedet med sympati.
Heldigvis for dig kan du investere i løsninger som f.eks. augmented analytics. Dette udnytter maskinlæringsalgoritmer til at accelerere den hastighed, hvormed du udfører din dataanalyse (og det forbedrer også nøjagtigheden af din analyse).
Den nederste linje: Lige meget hvilken løsning du bruger til at automatisere og forbedre din datarensning, skal du stadig udføre selve rensningen - hvis du ikke gør det, vil du aldrig have det rigtige grundlag at basere nøjagtig dataanalyse på.
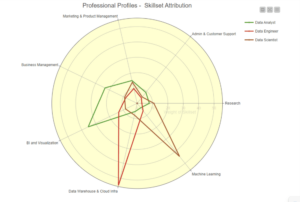
Som det er tilfældet med datasæt, er de fleste algoritmer ikke hundrede procent perfekte; de fleste af dem har deres rimelige andel af fejl og fungerer simpelthen ikke, som du gerne vil have dem til, hver gang du bruger dem. Algoritmer med en masse ufuldkommenheder kan endda ignorere data, der er afgørende for din analyse, eller de kan fokusere på den forkerte slags data, som faktisk ikke er så vigtige.
Det er ingen hemmelighed, at de største navne inden for teknologi er undersøger konstant deres algoritmer og justere dem så tæt på perfektion som muligt, og det er fordi så få algoritmer faktisk er fejlfrie. Jo mere nøjagtig din algoritme er, jo større er garantien for, at dine programmer når deres mål og gør, hvad du har brug for, at de skal gøre.
Derudover, hvis din organisation bemander blot et par datavidenskabsmænd, bør den sørge for, at disse dataforskere regelmæssigt opdaterer de algoritmer, som deres dataanalyse programmerer - det kan endda være umagen værd at etablere en tidsplan, der holder teams ansvarlige for at vedligeholde og opdatering af deres dataanalysealgoritmer efter en aftalt tidsplan.
Endnu bedre end det kan være at etablere en strategi, der udnytter AI/ML-baserede algoritmer, som burde kunne opdatere sig selv automatisk.
For det meste forståeligt nok, er mange virksomhedsledere, som ikke er direkte engageret i deres dataanalysehold, ikke klar over, at algoritmer og modeller er ikke de samme ting. Hvis DU heller ikke var klar over, så husk, at algoritmer er de metoder, vi bruger til at analysere data; modeller er de beregninger, der bliver skabt ved at udnytte en algoritmes output.
Algoritmer kan knuse data hele dagen lang, men hvis deres output ikke går gennem modeller, der er designet til at kontrollere den efterfølgende analyse, så vil du ikke have nogen brugbar eller brugbar indsigt.
Tænk på det sådan her: Hvis du har fancy algoritmer, der knuser data, men ikke har nogen indsigt at vise til det, vil du ikke tage datadrevne beslutninger bedre, end du var før du havde disse algoritmer; det ville være som at ville bygge brugerforskning ind i dit produktkøreplan, men ignorere det faktum, at for eksempel markedsundersøgelsesindustrien genererede $ 76.4 mia i omsætning i 2021, hvilket repræsenterer en stigning på 100 % siden 2008.
Dine intentioner kan være beundringsværdige, men du er nødt til at bruge de moderne værktøjer og viden, du har til rådighed, for at indsamle disse indsigter eller bygge brugerforskningen ind i din køreplan efter bedste evne.
Det er uheldigt, at suboptimale modeller er en sikker måde at lave rod i dine algoritmers output, uanset hvor sofistikerede disse algoritmer er. Det er derfor vigtigt, at virksomhedsledere og tekniske ledere i højere grad inddrager deres dataanalyseeksperter for at skabe modeller, der hverken er for komplicerede eller for simple.
Og afhængigt af hvor meget data de arbejder med, kan virksomhedsledere vælge at gennemgå et par forskellige modeller, før de beslutter sig for en, der bedst passer til den mængde og type data, de skal håndtere.
I sidste ende, hvis du vil sikre dig, at din dataanalyse ikke er konsekvent forkert, skal du også huske at aldrig blive offer for partiskhed. Bias er desværre en af de største forhindringer, der skal overvindes, når det kommer til at opretholde nøjagtigheden af dataanalyse.
Uanset om de påvirker den type data, der indsamles eller påvirker måden virksomhedsledere fortolker data på, er skævheder varierede og ofte svære at fastlægge - ledere skal gøre deres bedste for at identificere deres skævheder og give afkald på dem for at kunne drage fordel af konsekvent nøjagtige dataanalyser.
Data er kraftfulde: Når de bruges korrekt, kan de give virksomhedsledere og deres organisationer enormt nyttig indsigt, der kan transformere, hvordan de udvikler og leverer deres produkter til deres kunder. Bare sørg for, at du gør alt, hvad der står i din magt for at sikre, at dine dataanalyser er nøjagtige og ikke lider under de let undgåelige fejl, som vi har beskrevet i denne artikel.
Nahla Davies er softwareudvikler og teknologiskribent. Før hun helligede sit arbejde på fuld tid til teknisk skrivning, nåede hun – blandt andet spændende – at fungere som en ledende programmør hos en Inc. 5,000 erfaringsbaseret branding-organisation, hvis kunder omfatter Samsung, Time Warner, Netflix og Sony.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/03/3-mistakes-could-affecting-accuracy-data-analytics.html?utm_source=rss&utm_medium=rss&utm_campaign=3-mistakes-that-could-be-affecting-the-accuracy-of-your-data-analytics
- :er
- 000
- 2021
- 2023
- a
- evner
- evne
- I stand
- Om
- fremskynde
- udrette
- nøjagtighed
- præcis
- præcist
- faktisk
- beundringsværdig
- indrømme
- påvirke
- påvirker
- algoritme
- algoritmer
- Alle
- altid
- blandt
- analyse
- analytics
- analysere
- analysere
- ,
- nogen
- ER
- artikel
- AS
- At
- augmented
- automatisere
- automatisk
- til rådighed
- undgå
- bund
- BE
- fordi
- bliver
- før
- være
- gavner det dig
- BEDSTE
- Bedre
- skævhed
- Big
- Big data
- større
- Største
- Bund
- branding
- bygge
- Bunch
- virksomhed
- virksomheder
- by
- CAN
- tilfælde
- chance
- kontrollere
- Vælg
- kunder
- Luk
- nøje
- Codecademy
- Indsamling
- Kom
- Fælles
- kompliceret
- beregninger
- fortsæt
- Konventioner
- kunne
- Par
- skabe
- oprettet
- stykket
- Kunder
- data
- dataanalyse
- Dataanalyse
- datasæt
- datastyret
- dag
- Dage
- afgørelser
- dyb
- levere
- Afhængigt
- konstrueret
- udvikle
- Udvikler
- forskellige
- svært
- digitalisering
- direkte
- gør
- ned
- kørsel
- nemt
- enten
- omfavne
- engagere
- beskæftiget
- sikre
- fejl
- væsentlig
- etablere
- oprettelse
- Endog
- Hver
- at alt
- eksempel
- ophidset
- ledere
- erfaringsbaseret
- eksperter
- retfærdig
- Fall
- favoriserer
- få
- Fornavn
- fejl
- Fokus
- efter
- Til
- Foundation
- fra
- fuld
- få
- Go
- Mål
- gå
- indrømme
- forståelse
- større
- størst
- Grow
- Dyrkning
- garanti
- håndtere
- Have
- hoveder
- hjælpe
- besidder
- Hvordan
- HTML
- http
- HTTPS
- Hurdles
- identificere
- uhyre
- vigtigt
- Forbedre
- forbedrer
- in
- Inc.
- omfatter
- forkert
- Forøg
- industrier
- industrien
- påvirke
- indsigt
- intentioner
- Invest
- spørgsmål
- IT
- jpg
- KDnuggets
- Venlig
- viden
- føre
- ledere
- LÆR
- læring
- Udnytter
- løftestang
- ligesom
- Line (linje)
- Liste
- Lang
- Lot
- maskine
- machine learning
- lave
- Making
- lykkedes
- Marked
- markedsundersøgelse
- Matter
- midler
- metoder
- fejl
- modeller
- Moderne
- mere
- mest
- navne
- navngivning
- Behov
- Ingen
- Netflix
- nummer
- of
- Tilbud
- on
- ONE
- ordrer
- organisation
- organisationer
- Andet
- skitseret
- output
- Overvind
- procent
- perfekt
- udføre
- PEWRESEARCH
- plato
- Platon Data Intelligence
- PlatoData
- mulig
- magt
- vigtigste
- Produkt
- Produkter
- programmør
- Programmer
- passende
- korrekt
- Kanin
- Sats
- RE
- Læs
- indse
- regelmæssigt
- huske
- repræsenterer
- forskning
- indtægter
- køreplan
- s
- samme
- Samsung
- planlægge
- forskere
- Secret
- tjener
- sæt
- bilægge
- Del
- bør
- Vis
- Simpelt
- ganske enkelt
- siden
- smartere
- So
- Software
- løsninger
- Løsninger
- nogle
- Sony
- sofistikeret
- Stadig
- Strategi
- efterfølgende
- sådan
- lidelse
- overraskelse
- hold
- tech
- Teknisk
- at
- deres
- Them
- selv
- derfor
- Disse
- ting
- ting
- Gennem
- tid
- tidskrævende
- til
- også
- værktøjer
- top
- Transform
- tweaking
- Forståeligt nok
- uheldig
- Opdatering
- opdateringer
- opdatering
- brugbar
- brug
- Bruger
- Ve
- Victim
- bind
- ønsker
- Warner
- Vej..
- Hvad
- hvorvidt
- som
- WHO
- vilje
- med
- Arbejde
- arbejder
- værd
- forfatter
- skrivning
- Forkert
- Din
- zephyrnet