Billede af Freepik
Conversational AI refererer til virtuelle agenter og chatbots, der efterligner menneskelige interaktioner og kan engagere mennesker i samtale. Brug af konversations-AI er hurtigt ved at blive en livsstil - fra at spørge Alexa til "find den nærmeste restaurant” at bede Siri om at "oprette en påmindelse," virtuelle assistenter og chatbots bruges ofte til at besvare forbrugernes spørgsmål, løse klager, foretage reservationer og meget mere.
At udvikle disse virtuelle assistenter kræver en betydelig indsats. Forståelse og håndtering af de vigtigste udfordringer kan imidlertid strømline udviklingsprocessen. Jeg har brugt min førstehåndserfaring med at skabe en moden chatbot til en rekrutteringsplatform som referencepunkt til at forklare centrale udfordringer og deres tilsvarende løsninger.
For at bygge en samtale-AI-chatbot kan udviklere bruge rammer som RASA, Amazons Lex eller Googles Dialogflow til at bygge chatbots. De fleste foretrækker RASA, når de planlægger brugerdefinerede ændringer, eller botten er i moden fase, da det er en open source-ramme. Andre rammer er også velegnede som udgangspunkt.
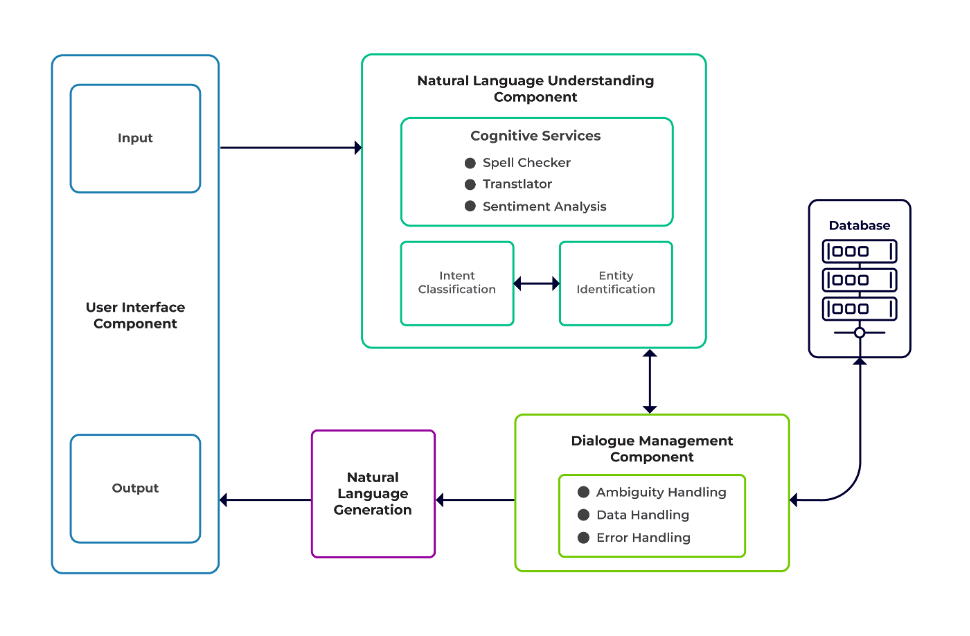
Udfordringerne kan klassificeres som tre hovedkomponenter i en chatbot.
Naturlig sprogforståelse (NLU) er en bots evne til at forstå menneskelig dialog. Den udfører hensigtsklassificering, enhedsudtrækning og henter svar.
Dialog leder er ansvarlig for et sæt handlinger, der skal udføres baseret på det aktuelle og tidligere sæt af brugerinput. Den tager hensigt og entiteter som input (som en del af den forrige samtale) og identificerer det næste svar.
Natural Language Generation (NLG) er processen med at generere skrevne eller talte sætninger ud fra givne data. Det rammer svaret, som derefter præsenteres for brugeren.
Billede fra Talentica Software
Utilstrækkelige data
Når udviklere erstatter ofte stillede spørgsmål eller andre supportsystemer med en chatbot, får de en anstændig mængde træningsdata. Men det samme sker ikke, når de opretter botten fra bunden. I sådanne tilfælde genererer udviklere træningsdata syntetisk.
Hvad skal jeg gøre?
En skabelonbaseret datagenerator kan generere en anstændig mængde brugerforespørgsler til træning. Når chatbotten er klar, kan projektejere udsætte den for et begrænset antal brugere for at forbedre træningsdata og opgradere den over en periode.
Upassende modelvalg
Passende modelvalg og træningsdata er afgørende for at få de bedste hensigts- og enhedsudtrækningsresultater. Udviklere træner normalt chatbots på et specifikt sprog og domæne, og de fleste af de tilgængelige præ-trænede modeller er ofte domænespecifikke og trænet på et enkelt sprog.
Der kan også være tilfælde af blandede sprog, hvor folk er polyglot. De kan indtaste forespørgsler på et blandet sprog. For eksempel, i en fransk-domineret region, kan folk bruge en type engelsk, der er en blanding af både fransk og engelsk.
Hvad skal jeg gøre?
Brug af modeller trænet på flere sprog kan reducere problemet. En præ-trænet model som LaBSE (Language-agnostic Bert sætning indlejring) kan være nyttig i sådanne tilfælde. LaBSE er uddannet i mere end 109 sprog i en sætningsopgave. Modellen kender allerede lignende ord på et andet sprog. I vores projekt fungerede det rigtig godt.
Ukorrekt enhedsudtrækning
Chatbots kræver, at enheder identificerer, hvilken slags data brugeren søger. Disse entiteter inkluderer tid, sted, person, vare, dato osv. Bots kan dog undlade at identificere en enhed fra naturligt sprog:
Samme kontekst, men forskellige enheder. For eksempel kan bots forveksle et sted som en enhed, når en bruger skriver "Navn på studerende fra IIT Delhi" og derefter "Navn på studerende fra Bengaluru."
Scenarier, hvor entiteterne er misforudset med lav tillid. For eksempel kan en bot identificere IIT Delhi som en by med lav selvtillid.
Delvis enhedsudtrækning ved maskinlæringsmodel. Hvis en bruger skriver "studerende fra IIT Delhi", kan modellen kun identificere "IIT" kun som en enhed i stedet for "IIT Delhi."
Enkeltordsinput uden kontekst kan forvirre maskinlæringsmodellerne. For eksempel kan et ord som "Rishikesh" betyde både navnet på en person såvel som en by.
Hvad skal jeg gøre?
Tilføjelse af flere træningseksempler kunne være en løsning. Men der er en grænse, hvorefter tilføjelse af flere ikke ville hjælpe. Desuden er det en uendelig proces. En anden løsning kunne være at definere regex-mønstre ved hjælp af foruddefinerede ord for at hjælpe med at udtrække enheder med et kendt sæt mulige værdier, som by, land osv.
Modeller deler lavere tillid, når de ikke er sikre på entitetsforudsigelse. Udviklere kan bruge dette som en trigger til at kalde en brugerdefineret komponent, der kan rette op på enheden med lav selvtillid. Lad os overveje ovenstående eksempel. Hvis IIT Delhi er forudsagt som en by med lav selvtillid, så kan brugeren altid søge efter den i databasen. Efter at have undladt at finde den forudsagte enhed i By tabellen, ville modellen fortsætte til andre tabeller og til sidst finde den i Institut tabel, hvilket resulterer i entitetskorrektion.
Forkert hensigtsklassificering
Hver brugermeddelelse har en hensigt forbundet med den. Da hensigter udleder en bots næste handlingsforløb, er korrekt klassificering af brugerforespørgsler med hensigt afgørende. Udviklere skal dog identificere hensigter med minimal forvirring på tværs af hensigter. Ellers kan der opstå sager, der er ramt af forvirring. For eksempel, "Vis mig ledige stillinger” vs. "Vis mig ledige stillingskandidater”.
Hvad skal jeg gøre?
Der er to måder at skelne mellem forvirrende forespørgsler på. For det første kan en udvikler indføre sub-hensigt. For det andet kan modeller håndtere forespørgsler baseret på identificerede enheder.
En domænespecifik chatbot skal være et lukket system, hvor den klart skal identificere, hvad den er i stand til, og hvad den ikke er. Udviklere skal udføre udviklingen i faser, mens de planlægger for domænespecifikke chatbots. I hver fase kan de identificere chatbottens ikke-understøttede funktioner (via ikke-understøttet hensigt).
De kan også identificere, hvad chatbotten ikke kan håndtere i hensigten "uden for scope". Men der kan være tilfælde, hvor botten er forvirret uden støtte og hensigt uden for rammerne. For sådanne scenarier bør der være en reservemekanisme på plads, hvor modellen, hvis hensigtstilliden er under en tærskel, kan arbejde elegant med en reservemekanisme til at håndtere forvirringssager.
Når botten identificerer hensigten med en brugers besked, skal den sende et svar tilbage. Bot bestemmer svaret baseret på et bestemt sæt definerede regler og historier. For eksempel kan en regel være så simpel som fuldstændig "god morgen" når brugeren hilser "Hej". Men oftest omfatter samtaler med chatbots opfølgende interaktion, og deres svar afhænger af den overordnede kontekst af samtalen.
Hvad skal jeg gøre?
For at håndtere dette fodres chatbots med rigtige samtaleeksempler kaldet Stories. Brugere interagerer dog ikke altid efter hensigten. En moden chatbot bør håndtere alle sådanne afvigelser med ynde. Designere og udviklere kan garantere dette, hvis de ikke bare fokuserer på en lykkelig vej, mens de skriver historier, men også arbejder på ulykkelige veje.
Brugerengagement med chatbots afhænger i høj grad af chatbot-svarene. Brugere kan miste interessen, hvis svarene er for robotagtige eller for velkendte. For eksempel kan en bruger ikke lide et svar som "Du har skrevet en forkert forespørgsel" for et forkert input, selvom svaret er korrekt. Svaret her stemmer ikke overens med en assistents persona.
Hvad skal jeg gøre?
Chatbotten fungerer som en assistent og bør have en specifik persona og tone i stemmen. De skal være imødekommende og ydmyge, og udviklere bør designe samtaler og ytringer derefter. Svarene bør ikke lyde robotiske eller mekaniske. For eksempel kunne botten sige, "Beklager, det ser ud til, at jeg ikke har nogen detaljer. Kan du venligst skrive din forespørgsel igen?" at adressere et forkert input.
LLM (Large Language Model) baserede chatbots som ChatGPT og Bard er spilskiftende innovationer og har forbedret mulighederne for samtale AI'er. De er ikke kun gode til at lave åbne menneskelignende samtaler, men kan udføre forskellige opgaver som tekstresumé, afsnitsskrivning osv., som tidligere kun kunne opnås ved hjælp af specifikke modeller.
En af udfordringerne med traditionelle chatbot-systemer er at kategorisere hver sætning i hensigter og beslutte svaret i overensstemmelse hermed. Denne tilgang er ikke praktisk. Svar som "Undskyld, jeg kunne ikke få dig" er ofte irriterende. Intentionsløse chatbot-systemer er vejen frem, og LLM'er kan gøre dette til en realitet.
LLM'er kan nemt opnå state-of-the-art resultater i generel navngivne enhedsgenkendelse, bortset fra visse domænespecifikke enhedsgenkendelser. En blandet tilgang til at bruge LLM'er med enhver chatbot-ramme kan inspirere til et mere modent og robust chatbot-system.
Med de seneste fremskridt og kontinuerlig forskning i konversations-AI bliver chatbots bedre hver dag. Områder som at håndtere komplekse opgaver med flere hensigter, såsom "Bestil et fly til Mumbai og arrangere en taxa til Dadar," får meget opmærksomhed.
Snart vil personlige samtaler finde sted baseret på brugerens karakteristika for at holde brugeren engageret. For eksempel, hvis en bot finder, at brugeren er utilfreds, omdirigerer den samtalen til en rigtig agent. Derudover kan deep learning-teknikker som ChatGPT med stadigt stigende chatbotdata automatisk generere svar på forespørgsler ved hjælp af en videnbase.
Suman Saurav er dataforsker hos Talentica Software, et softwareproduktudviklingsfirma. Han er en alumnus fra NIT Agartala med over 8 års erfaring med at designe og implementere revolutionerende AI-løsninger ved hjælp af NLP, Conversational AI og Generative AI.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :har
- :er
- :ikke
- :hvor
- 8
- a
- evne
- Om
- over
- derfor
- opnå
- opnået
- tværs
- aktioner
- tilføje
- Derudover
- adresse
- adressering
- fremskridt
- Efter
- Agent
- midler
- AI
- AI chatbot
- Alexa
- Alle
- allerede
- også
- alumne
- altid
- beløb
- an
- ,
- En anden
- besvare
- enhver
- tilgang
- ER
- områder
- AS
- spørge
- Assistant
- assistenter
- forbundet
- At
- opmærksomhed
- automatisk
- til rådighed
- undgå
- tilbage
- bund
- baseret
- BE
- blive
- væsener
- jf. nedenstående
- BEDSTE
- Bedre
- Bot
- både
- bots
- bygge
- men
- by
- ringe
- kaldet
- CAN
- kan ikke
- kapaciteter
- stand
- tilfælde
- kategorisere
- vis
- udfordringer
- Ændringer
- karakteristika
- chatbot
- chatbots
- ChatGPT
- By
- klassificering
- klassificeret
- tydeligt
- lukket
- selskab
- klager
- komplekse
- komponent
- komponenter
- forstå
- tillid
- forvirret
- forvirrende
- forvirring
- Overvej
- sammenhæng
- kontinuerlig
- Samtale
- konversation
- samtale AI
- samtaler
- korrigere
- korrekt
- Tilsvarende
- kunne
- land
- kursus
- skabe
- Oprettelse af
- afgørende
- Nuværende
- skik
- data
- dataforsker
- Database
- Dato
- dag
- anstændig
- Beslutter
- dyb
- dyb læring
- definere
- definerede
- Delhi
- afhænge
- udlede
- Design
- designere
- designe
- detaljer
- Udvikler
- udviklere
- Udvikling
- dialogflow
- Dialog
- forskellige
- differentiere
- do
- Er ikke
- domæne
- Dont
- hver
- tidligere
- nemt
- indsats
- indlejring
- Endless
- engagere
- beskæftiget
- engagement
- Engelsk
- forbedre
- Indtast
- enheder
- enhed
- etc.
- Endog
- til sidst
- stadigt stigende
- Hver
- hver dag
- eksempel
- eksempler
- erfaring
- Forklar
- ekstrakt
- udvinding
- FAIL
- svigtende
- bekendt
- FAST
- Funktionalitet
- Fed
- Finde
- fund
- fly
- Fokus
- Til
- Videresend
- Framework
- rammer
- Fransk
- fra
- Generelt
- generere
- generere
- generation
- generative
- Generativ AI
- generator
- få
- få
- given
- godt
- Googles
- garanti
- håndtere
- Håndtering
- ske
- Gem
- Have
- have
- he
- stærkt
- hjælpe
- hjælpsom
- link.
- Hvordan
- How To
- Men
- HTTPS
- menneskelig
- ydmyg
- i
- identificeret
- identificerer
- identificere
- if
- gennemføre
- forbedret
- in
- omfatter
- innovationer
- indgang
- indgange
- inspirere
- instans
- i stedet
- beregnet
- hensigt
- interagere
- interaktion
- interaktioner
- interesse
- ind
- indføre
- IT
- jpg
- lige
- KDnuggets
- Holde
- Nøgle
- Venlig
- viden
- kendt
- kender
- Sprog
- Sprog
- stor
- seneste
- læring
- Livet
- ligesom
- GRÆNSE
- Limited
- taber
- Lav
- lavere
- maskine
- machine learning
- større
- lave
- Making
- Match
- modne
- Kan..
- me
- betyde
- mekanisk
- mekanisme
- besked
- måske
- mindste
- blande
- blandet
- model
- modeller
- mere
- Desuden
- mest
- meget
- flere
- Mumbai
- skal
- my
- navn
- Som hedder
- Natural
- Naturligt sprog
- næste
- NLG
- NLP
- nlu
- ingen
- nummer
- of
- tit
- on
- engang
- kun
- åbent
- open source
- or
- Andet
- Ellers
- vores
- i løbet af
- samlet
- ejere
- del
- sti
- stier
- mønstre
- Mennesker
- udføre
- udføres
- udfører
- periode
- person,
- Personlig
- fase
- faser
- Place
- fly
- planlægning
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- Punkt
- position
- have
- mulig
- Praktisk
- forudsagde
- forudsigelse
- foretrække
- forelagt
- tidligere
- Problem
- Fortsæt
- behandle
- Produkt
- produktudvikling
- projekt
- forespørgsler
- Spørgsmål
- R
- rasa
- klar
- ægte
- Reality
- virkelig
- anerkendelse
- rekruttering
- reducere
- henvisningen
- refererer
- region
- stole
- påmindelse
- erstatte
- kræver
- Kræver
- forskning
- løse
- svar
- reaktioner
- ansvarlige
- resulterer
- Resultater
- revolutionerende
- robust
- Herske
- regler
- samme
- siger
- scenarier
- Videnskabsmand
- ridse
- Søg
- søgning
- synes
- valg
- send
- dømme
- tjener
- sæt
- Del
- bør
- lignende
- Simpelt
- siden
- enkelt
- siri
- Software
- løsninger
- Løsninger
- nogle
- Lyd
- specifikke
- talt
- Stage
- Starter
- state-of-the-art
- Historier
- strømline
- Studerende
- væsentlig
- sådan
- egnede
- support
- Support-systemer
- sikker
- syntetisk
- systemet
- Systemer
- T
- bord
- Tag
- tager
- Opgaver
- opgaver
- teknikker
- tekst
- end
- at
- deres
- Them
- derefter
- Der.
- Disse
- de
- denne
- selvom?
- tre
- tærskel
- tid
- til
- TONE
- Toneleje
- også
- traditionelle
- Tog
- uddannet
- Kurser
- udløse
- to
- typen
- typer
- forståelse
- opgradering
- brug
- anvendte
- Bruger
- brugere
- ved brug af
- sædvanligvis
- Værdier
- via
- Virtual
- Voice
- vs
- W
- Vej..
- måder
- indbydende
- GODT
- Hvad
- hvornår
- når
- som
- mens
- vilje
- med
- ord
- ord
- Arbejde
- arbejdede
- ville
- skrivning
- skriftlig
- Forkert
- år
- dig
- Din
- zephyrnet