Download ekspertens guide til dokumentindeksering.
Mange virksomheder, der har skiftet fra papir- til computerbaserede arkiveringsprocedurer, har forstået, at digitale filer kan være lige så uorganiserede og rodede som analoge. Imidlertid, digitalisering af dokumenter sparer mange kræfter og tid i det lange løb; det fungerer kun, hvis det gøres korrekt. Det er her dokumentindeksering ankommer.
Dokumentindeksering er en glimrende måde at gøre det muligt for din virksomhed at få organiseret dine digitale filer og gemme fremtidige filer. Det vedrører også filer involveret i procedurer på tværs af din institution, fra debitorer og gældsforpligtelser til indkøb til at betale.
Hvad er dokumentindeksering?

Dokumentindeksering organiserer dokumenter med de rigtige tags eller attributter for bedre synlighed, mens du søger eller henter dokumenter i fremtiden.
For eksempel kan en virksomhed indeksere dokumenter efter kundenummer, kundenavn, medarbejdernavn, dato eller andre vitale egenskaber, der senere kan relateres. Det er en væsentlig del af det grundlag, som en organisations netværk til dokumenthåndtering er bygget.
Lad os tage et eksempel på en ordbog. En ordbog omfatter en bred vifte af ord og deres betydninger. Hvis du skal opdage et bestemt værk fra ordbogen, vil det tage timer at kigge på hver side.
Men ved at bruge indekset, krymper din jagt til kun minutter eller sekunder. Dokumentindeksering regulerer en lignende hypotese. Ved at knytte bestemte tags til en digitalt dokument, kan du bruge termerne i disse tags til mere ubesværet at finde den information, du har brug for, i stedet for manuelt at analysere gennem et bjerg af filer.
Dokumentindekseringskoncepter
Man kan forstå og kende til dokumentindeksering i flere begreber. Lad os kort besøge dem:
- Database: En database er en elektronisk indsamling af dokumenter opbevaret ét sted og gjort tilgængelige for mange brugere til mange forskellige formål. Det kan også være en organiseret samling af dokumenter eller data gemt på en computer, som et program kan bruge til at diskutere og give hurtige, fleksible svar på forespørgsler.
- RDBMS: Udtrykket "RDBMS" (Relational Database Management System) henviser til et databasestyringssystem, hvor data og relationerne mellem dataene vedligeholdes i tabeller.
- Nøglefelter—indeksfelter—er databasefelter, der bruges til at kategorisere og arrangere dokumenter. De er typisk defineret af brugeren og kan bruges til at scanne og hente dokumenter. Eksempler omfatter fakturanummer, kundens navn, dato og adresse.
- Match, flet og udfyld indeksering områder med indeksdata, der allerede findes i andre systemer, som f.eks regnskabssystemer. Det giver dig mulighed for at indeksere et eller flere felter og automatisk udfylde de resterende felter med data fra et tabelopslag eller tekstfil leveret af et andet netværk, såsom et regnskabs- eller personalesystem, der matcher.
Indekser dokumenter automatisk med arbejdsgange uden kode på 15 minutter. Se hvordan det virker med en gratis produktdemo, hvor vi sætter arbejdsgange for dig.
Få en gratis produktrundvisning or Start din gratis prøveperiode.
Hvorfor er dokumentindeksering vigtig?
Dokumentindeksering muliggør mere end blot hurtig dokumenthentning. Der er mange fordele ved dokumentindeksering, herunder følgende:
Forbedret dokumentorganisation
Medarbejdere kan spare tid på at søge efter det rigtige dokument med det rigtige dokumentindekseringssystem.
Lettere overholdelse af revision
Du kan nemt undvære kapløbet om at samle papirer i tide til en revision, hvis dokumenterne allerede er indekseret og organiseret i henhold til regnskabsåret og andre relevante målinger.
Sparer tid
Men hvis du og dit team har de rigtige dokumentindekseringsprotokoller, kan du bruge den tid, du bruger på at søge efter produktivt arbejde.
Typer af dokumentindeksering
Ud over de mange fordele ved dokumentindeksering er der mange forskellige indekseringstilgange, så du kan vælge den (eller en kombination af måder) der passer bedst til din dokument arbejdsgang. Disse strategier består af følgende:
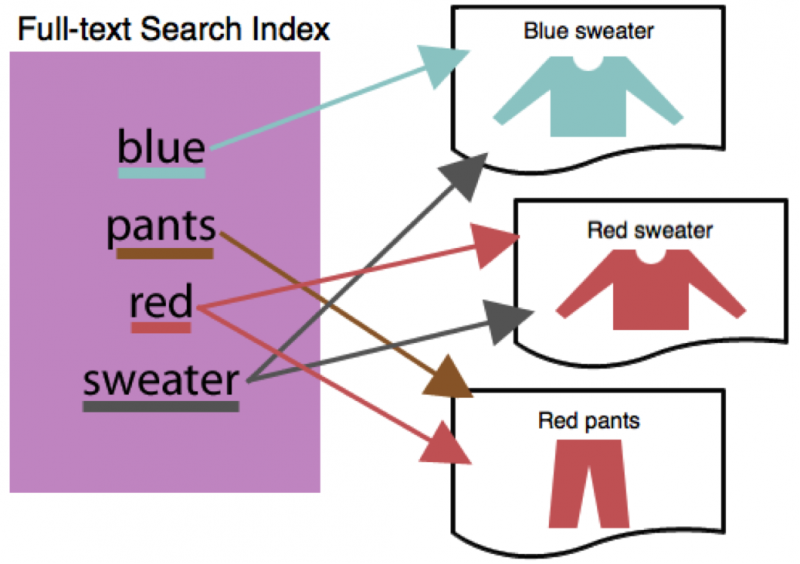
Indeksering af fuld tekst
Med fuldtekstindeksering scannes hele indholdet af et dokument, så du kan søge hvor som helst i teksten efter sætninger eller nøgleord.
Det er identisk med værktøjet "Find" (Ctrl+F eller Kommando+F), der er inkluderet i de fleste tekstbehandlingsprogrammer og webbrowsere. Den brugervenlige karakter af denne indekseringstype gør den til den nemmeste, men den kræver meget lagerplads.
Du kan gøre dokumenter søgbare ved hjælp af Nanonets. Se hvordan.
Automatiseret indeksering
Automatiseret indeksering, også kendt som variabel opslagsindeksering, indekserer selektivt væsentlige dele af et dokument, der matcher en database, såsom kundenumre eller navne, i stedet for at indeksere hele siden.
Denne procedure bruger dokumentindekseringssoftware. Alligevel kan det være en fordel for virksomheder at indeksere dokumenter som regninger, der altid indeholder felter, der match data i databaser.
Se, hvordan du kan automatisere dokumentindeksering med Nanonets.
Metadataindeksering
"Data om data" er et udtryk, der ofte bruges til at referere til metadata, men det er meget detaljeret. Et eksempel på dette kunne være, mens du tager billeder for at lave en pdf-fil; det fanger tidspunktet, hvor det er taget.
Desuden giver det dig også mulighed for at tilføje yderligere "tags", kendt som PDF metadata. Metadata, såsom tags og anden information, du vil bruge til senere søgninger, kan bruges under digitalisering eller scanning af et dokument. Når det så kommer til at få et dokument, scanner den metadataene i stedet for at bruge dit dokumenthentningsprogram til at scanne hele dokumenter.
Automatiseret indeksering ved hjælp af feltdata
Feltbaseret indeksering refererer til forskellige datakilder i en database, også kendt som felter. Det er konceptuelt identisk med metadataindeksering. For eksempel kan du bruge feltbaseret indeksering til at søge i din database efter poster med samme navn i kundekolonnen.
Dokumentindeksering er ikke vanskelig. Brug alle ovenstående metoder til at indeksere dokumenter på autopilot.
Book et opkald for at se, hvordan du kan automatisere dokumentindeksering med Nanonets på <15 minutter.
Få en gratis produktrundvisning or Start din gratis prøveperiode.
Hvordan fungerer dokumentindeksering?
Hvilken dokumentindeksering der er bedst for dig, afhænger af, hvordan hver af de involverede parter har til hensigt at bruge de dokumenter, du indekserer. De oplysninger, som medarbejderne er mest tilbøjelige til at slå op på nettet, og de søgetermer, de med størst sandsynlighed vil bruge for at finde dem, skal være bekendt med dig. At forstå medarbejdernes behov er den eneste måde at sikre, at du indekserer på en måde, der gør hurtig dokumenthentning mulig.
Det er nemt at indeksere dokumenterne, når du først forstår, hvordan dine indekserede papirer vil blive brugt, og hvilken type indeksering, der giver mest mening for din organisation. Indekseringsprocessen indebærer scanning og kategorisering af digitaliseret og scannet materiale for at lokalisere forudbestemte nøglesætninger manuelt eller automatisk. En forklaring af indekseringsprocessen mere dybdegående er givet nedenfor:
Forstå dokumentindekseringsbrug
Den type indeksering, du skal bruge, afhænger af de dokumenter, du indekserer, om det er personaleregistreringer, fakturaer eller noget andet; Det er også vigtigt at vide, hvem der skal hente disse dokumenter og hvorfor.
Afslut den type dokumentindeksering, du vil bruge
Det er muligt, at nogle typer papirer nemt kan findes uden at skulle indeksere så meget information. For eksempel kan du kun have brug for de grundlæggende oplysninger fra fakturaer, såsom kontonummer eller leverandørnavn.
Indeks de relevante data
Du kan indeksere dataene manuelt eller helst stole på softwaren, der kunne indeksere dataene efter at have bestemt, hvilken form for indeksering der giver mening.
Dobbeltnøglemetoden er den mest effektive indekseringsteknik, når den udføres manuelt. To personer mærker hvert scannet dokument ved hjælp af denne metode med de nødvendige indekseringssætninger ved at indtaste de oplysninger, de ser, i de relevante metadatafelter for filen. Dette gør det muligt for en krydssammenligning at finde eventuelle fejl. Dobbelttasten sparer en masse tid og skærer drastisk ned på fejl.
Du skal angive retningslinjerne for, hvilke dele af dokumentet softwaren skal tage fra, hvis du er afhængig af software. For eksempel samarbejder den rigtige dokumentindekseringssoftware med OCR teknologi at lade computeren læse tekst fra billeder, hvilket er afgørende for indeksering af relevante data og digitalisering af fysiske kopier af dokumenter.
Nanonetter - Den bedste dokumentindekseringssoftware
Nanonetter er en AI-baseret dokumenthåndteringssystem der tillader brugere med en no-code platform til ende-til-ende dokumenthåndtering. Nanonets automatiserer alle dokumentprocesser som f.eks
Og mere. Nanonets har en indbygget OCR-software, der bruger nøgleordsudtræk til at identificere dokumenter og indeksere dem i overensstemmelse hermed til de respektive databaser. Nanonets AI-algoritme lærer med tiden og håndterer nemt ustrukturerede, semistrukturerede eller brugerdefinerede dokumenter.
30,000+ fagfolk fra 500+ virksomheder stoler på, at Nanonets kan administrere dokumenter effektivt.
Brug af Nanonets kan medføre en række fordele, herunder omkostningsbesparelser, forbedret overholdelse og forbedret produktivitet. Her er nogle unikke fordele, der adskiller Nanonets:
- Ingen kodning kræves
- Fungerer med alle dokumenttyper
- Brugerdefinerede AI-modeller
- Der kræves ingen efterbehandling eller forbehandling.
- Håndterer flersprogede dokumenter
- Genkender 200+ sprog
- 1-dags opsætning
- 5000+ integrationer med API og Zapier
- 24x7 live support
- Gennemsigtige prismuligheder
- Hvid etiketopløsning
- On-premise & Cloud Hosting
Her er et øjebliksbillede af den præstation, der forventes fra Nanonets.

Nanonets er højt bedømt på peer-to-peer-kundeevalueringswebsteder som vist nedenfor.

Se, hvordan du kan automatisere din dokumentindekseringsproces med Nanonets på 15 minutter.
Få en gratis produktrundvisning or prøv det selv.
Hvordan bruger man Nanonets til dokumentindeksering?
Trin 1: Opret en konto på nanonetter (Start gratis nu) og log ind.
Trin 2: Vælg dokumentklassificeringsmodellen fra hovedskærmen.
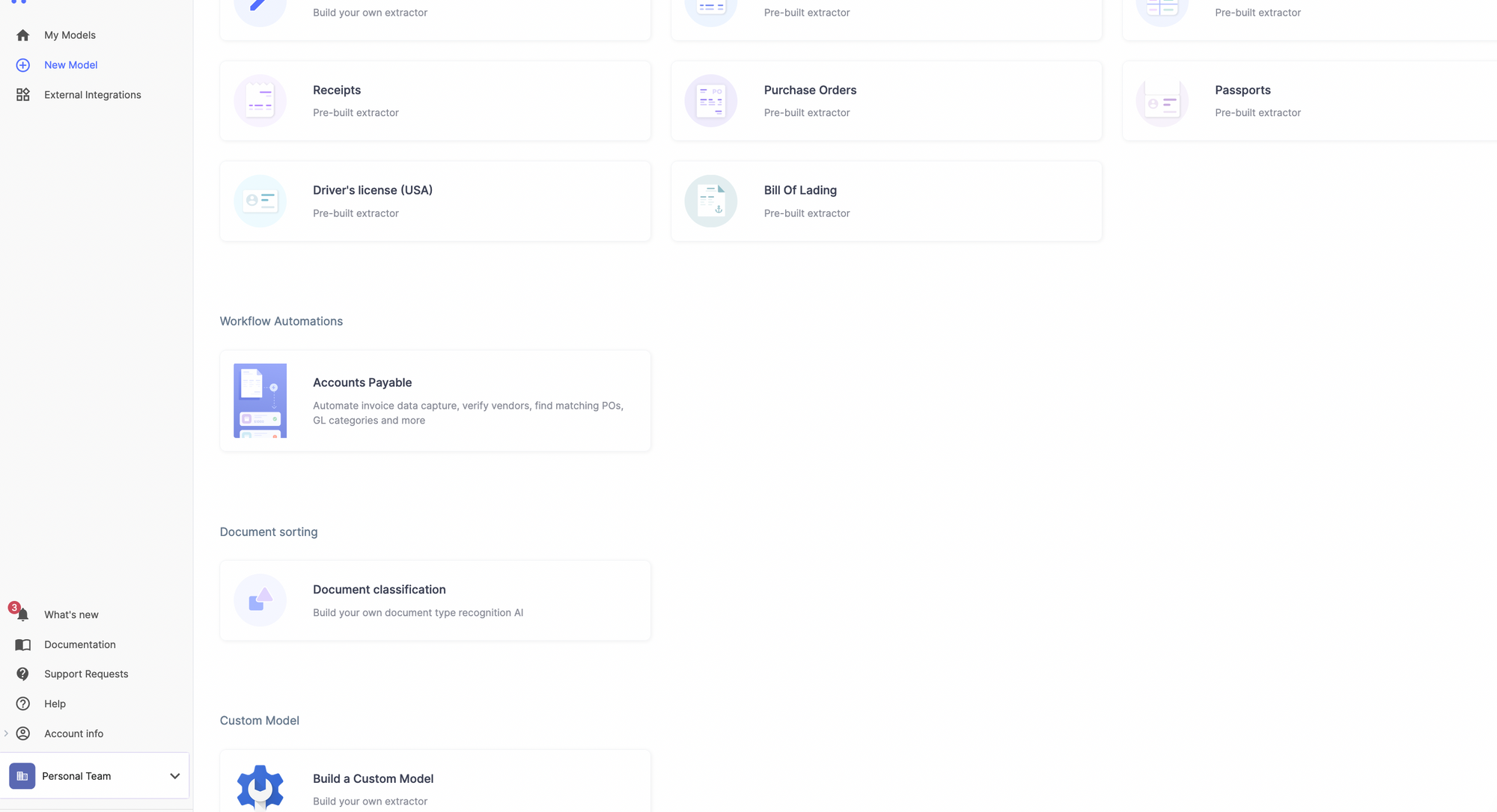
Trin 3: Vælg de dokumentmærker, du vil inkludere.

Trin 4: Nanonets AI-algoritmen behøver kun 25 dokumenter for at træne AI-modellen til at genkende din dokumenttype. Upload 25 dokumenter for hvert dokumentmærke, og lad modellen træne.
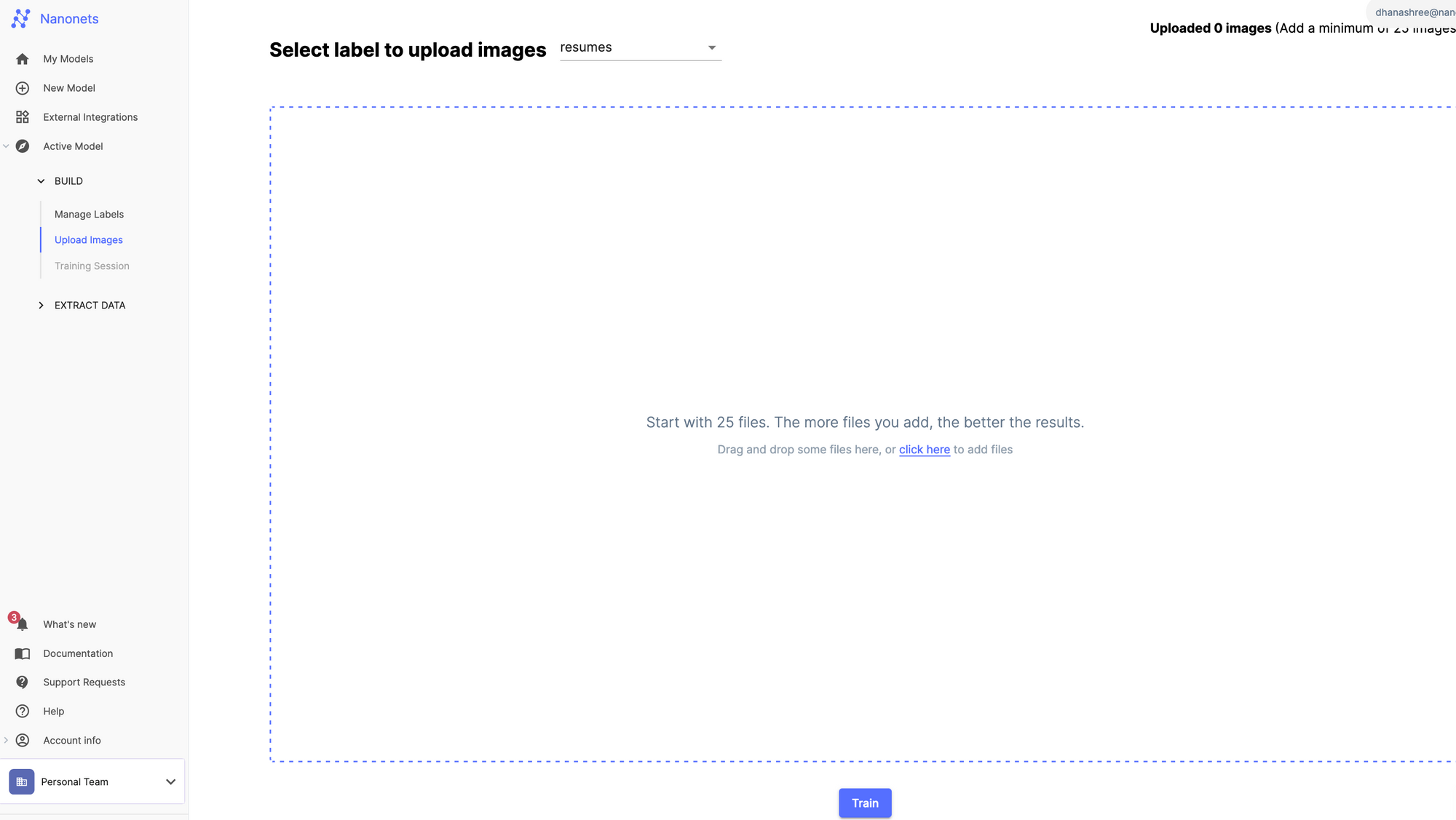
Trin 5: Når du er færdig, kan du bruge dokumentarbejdsgangen til automatisk at sende dokumenter, indeksere dem og sende dem til databasen efter behov. Du kan bruge dokumentarbejdsgange til at udtrække data fra dokumenter, behandle dokumenter eller sende dem gennem en godkendelsesproces. Din fantasi er begrænsningen.
Dokumentindeksering med Nanonets er let.
Start din gratis prøveperiode og gør det selv. Hvis du har brug for hjælp, så planlæg et 10-minutters opkald med vores automationseksperter for at lade os opsætte arbejdsgange for dig.
Få en gratis produktrundvisning or Start din gratis prøveperiode.
Hvordan hjælper det dig med at finde dokumenter?
Dokumentindeksering er et grundlæggende element i enhver forretningsdokumenthåndteringsteknik og er en fantastisk måde at opbygge mere effektive arbejdsgange på. Med tilstrækkelig indeksering er ethvert dokument, dine medarbejdere har brug for, nemt at søge efter og hente med kun et begrænset tastetryk. Men det kan være kompliceret at implementere kraftfuld dokumentindeksering, hvis du ikke har tilstrækkelige værktøjer.
Konklusion
Dokumentindeksering er en kraftfuld tilgang til senere hentning af dokumenter fra enorme arkiver, herunder tusindvis af dokumenter. Dokumenter kan indekseres efter deres fuldtekstindhold (som ethvert ord i dataene kan tilgås) eller efter information relateret til dokumentet, såsom en produktionsdag, en unik identifikator eller dokumentets centrale tema.
Læs mere om dokumenthåndtering:
FAQ
Hvilke data bruges til at indeksere dokumenter?
En vigtig beslutning for at få mest muligt ud af de nye digitale filer er at vælge, hvilke indekseringsstandarder der skal bruges. Nogle forekomster af data brugt til indeksering omfatter:
- Bestillingsnummer
- Adresser
- Datoer
- For- og efternavne
- Telefonnumre
- Faktura nummer
- Kundenumre
- Kontonumre
- Søgeordsbeskrivelser
Hvad er formålet med indeksering?
Det grundlæggende formål med indeksering er at have kapaciteten til hurtigt at scanne efter og hente information inkluderet i dine scannede papirer. Det kan også forbedre dit kontors effektivitet ved at gøre det muligt for dine medarbejdere at søge efter information uden manuelt at køre gennem kasser med filer.
Hvad er egenskaberne ved god indeksering?
Slutmålet med et indekseringsprojekt er at bygge et system, hvor brugerne effektivt kan hente data. Dette opnås gennem:
- Tilknyt slutbrugere (afdelingsledere, ledere, medarbejdere) for at få deres meninger.
- Et nemt system, der er nemt at bruge.
- Herunder et valg om at søge efter bestemte felter på et dokument og fuld tekst.
- Inddragelse af dygtige indekseringsprofessionelle til at hjælpe med at guide og rådgive dig gennem processen.
Hvordan varierer det fra den ene branche til den anden?
En af de væsentlige faktorer ved udvælgelsen af indekseringsudtryk er, hvordan dokumenter skal undersøges. I en række personalekartoteker vil hovedsageligt for- og efternavne og ansættelsesdatoer være populære måder at søge på
Omvendt kan lægeerklæringer referere til parsing af fødselsdatoer eller forsikringspolicnumre. Inkludering af almindeligt anvendte søgetermer under dokumentindeksering vil give bedre resultater.
Hvordan fungerer dokumentindeksering?
Dokumentindeksering fungerer ved at tilskrive visse oplysninger til scannede dokumenter, hvilket muliggør effektiv og hurtig genfinding. Der er forskellige metoder til dokumentindeksering, hver med sine unikke fordele.
Hvad er din bedste dokumentindekseringsmulighed?
Dokumentindeksering skaber problemfri søgning og genfinding af enorme mængder dokumenter, når de anvendes korrekt. Ikke desto mindre er den korrekte indekseringsprocedure ikke én størrelse, der passer til alle. Uanset om dokumenter er indekseret efter hele teksten, organiseret efter områder eller suppleret med gode metadata, driver denne mulighed succesen for hele systemet. En dygtig partner kan sætte dit hold i stand til at vælge de rigtige indekseringsteknikker, der passer til dit holds unikke øvelser.
Brug en kodefri platform til at indeksere alle dine dokumenter på autopilot med arbejdsgange uden kode. Interesseret?
Få en gratis produktrundvisning or Start din gratis prøveperiode.
8. februar 2023: Denne blog blev oprindeligt udgivet i juni 2022 og blev opdateret den 8. februar 2023 med opdateret indhold.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://nanonets.com/blog/document-indexing/
- 1
- 10
- 2022
- 2023
- a
- Om
- over
- af udleverede
- tilgængelig
- gennemført
- Ifølge
- derfor
- Konto
- Bogføring og administration
- Konti
- tværs
- Desuden
- Yderligere
- adresse
- fordele
- Efter
- AI
- algoritme
- Alle
- tillade
- tillader
- allerede
- altid
- analysere
- ,
- En anden
- svar
- overalt
- fra hinanden
- api
- anvendelig
- anvendt
- tilgang
- tilgange
- passende
- passende
- godkendelse
- områder
- Ankommer
- attributter
- revision
- automatisere
- automater
- automatisk
- Automation
- autopilot
- grundlæggende
- jf. nedenstående
- gavnlig
- fordele
- BEDSTE
- Bedre
- mellem
- Sedler
- Blog
- kasser
- kortvarigt
- bringe
- bred
- browsere
- bygge
- bygget
- virksomhed
- virksomheder
- ringe
- Kapacitet
- fanger
- Optagelse
- tilfælde
- kategorisere
- central
- vis
- certifikater
- valg
- Vælg
- citeret
- klassificering
- kunde
- Cloud
- Kodning
- samling
- Kolonne
- kombination
- almindeligt
- Compliance
- kompliceret
- computer
- begreber
- Begrebsmæssigt
- konklusion
- indhold
- indhold
- kopier
- VIRKSOMHED
- Selskaber
- Koste
- omkostningsbesparelser
- Sofa sofa
- kunne
- skaber
- afgørende
- skik
- kunde
- nedskæringer
- data
- Database
- databaser
- Dato
- Datoer
- dag
- beslutning
- definerede
- endelige
- Demo
- Afdeling
- pålidelig
- dybde
- detaljeret
- bestemmelse
- forskellige
- digital
- digitaliseret
- digitalisering
- digitalisering af fysisk
- opdage
- diskutere
- dokumentet
- dokumenthåndtering
- dokumenter
- fordoble
- ned
- drastisk
- i løbet af
- hver
- nemmeste
- nemt
- Effektiv
- effektivitet
- effektiv
- effektivt
- indsats
- indlejret
- Medarbejder
- medarbejdere
- beskæftigelse
- muliggøre
- muliggør
- muliggør
- forbedret
- sikre
- virksomheder
- Hele
- fejl
- væsentlig
- Ether (ETH)
- Hver
- eksempel
- eksempler
- fremragende
- eksisterende
- forventet
- ekspert
- eksperter
- forklaring
- ekstrakt
- udvinding
- faktorer
- FAQ
- FAST
- felt
- Fields
- File (Felt)
- Filer
- Arkivering
- udfylde
- Finde
- Firm
- Fornavn
- Fiscal
- passer
- fleksibel
- efter
- formular
- fundet
- Foundation
- Gratis
- gratis prøveversion
- hyppigt
- fra
- fuld
- funktion
- funktioner
- fundamental
- fremtiden
- få
- Giv
- godt
- vejlede
- retningslinjer
- Håndterer
- hoveder
- hjælpe
- hjælpe
- link.
- stærkt
- host
- HOURS
- Hvordan
- Men
- HTTPS
- kæmpe
- menneskelig
- Human Resources
- identisk
- identifikator
- identificere
- billeder
- fantasi
- gennemføre
- vigtigt
- forbedret
- in
- I andre
- omfatter
- medtaget
- Herunder
- indeks
- indekser
- enkeltpersoner
- industrien
- info
- oplysninger
- instans
- i stedet
- Institution
- forsikring
- integrationer
- hensigt
- involverede
- involvering
- IT
- Karriere
- Nøgle
- Kend
- Kendskab til
- kendt
- etiket
- Efternavn
- Sandsynlig
- begrænsning
- Limited
- leve
- Lang
- Se
- leder
- kig op
- Lot
- lavet
- Main
- lave
- maerker
- administrere
- ledelse
- styringssystem
- Ledere
- manuelt
- mange
- Match
- materialer
- midler
- medicinsk
- Flet
- Metadata
- metode
- metoder
- Metrics
- måske
- minutter
- fejl
- model
- mere
- mere effektiv
- mest
- Bjerg
- navn
- navne
- Natur
- nødvendig
- Behov
- behøve
- behov
- netværk
- Ny
- nummer
- numre
- objektiv
- opnå
- OCR
- OCR-software
- Office
- ONE
- online
- Udtalelser
- Option
- organisation
- Organiseret
- organiserer
- oprindeligt
- Andet
- Papir
- papirer
- del
- særlig
- parter
- partner
- dele
- peer to peer
- ydeevne
- Personale
- sætninger
- fysisk
- Place
- perron
- plato
- Platon Data Intelligence
- PlatoData
- politik
- Populær
- mulig
- vigtigste
- prissætning
- procedurer
- behandle
- Processer
- processorer
- Produkt
- produktion
- produktiv
- produktivitet
- professionelle partnere
- Program
- projekt
- passende
- protokoller
- give
- forudsat
- offentliggjort
- formål
- formål
- kvaliteter
- Hurtig
- hurtigt
- rækkevidde
- Læs
- genkende
- optegnelser
- refererer
- relaterede
- Relationer
- resterende
- kræver
- påkrævet
- Kræver
- Ressourcer
- dem
- Resultater
- gennemgå
- Kør
- kører
- samme
- Gem
- Besparelser
- scanne
- scanning
- planlægge
- Skærm
- sømløs
- Søg
- søgning
- sekunder
- udvælgelse
- forstand
- Series
- sæt
- flere
- bør
- vist
- signifikant
- lignende
- Simpelt
- faglært
- Snapshot
- So
- Software
- nogle
- noget
- Kilder
- Space
- tilbringe
- standarder
- Stadig
- opbevaring
- opbevaret
- strategier
- succes
- sådan
- adspurgte
- systemet
- Systemer
- bord
- TAG
- Tag
- hold
- teknikker
- vilkår
- Fremtiden
- oplysninger
- deres
- tema
- tusinder
- Gennem
- tid
- til
- værktøj
- værktøjer
- Tog
- enorm
- retssag
- Stol
- typer
- typisk
- forstå
- forståelse
- forstået
- forenet
- enestående
- opdateret
- us
- brug
- Bruger
- brugervenlig
- brugere
- udnytte
- Ved hjælp af
- forskellige
- Vast
- sælger
- Verifikation
- synlighed
- afgørende
- måder
- web
- Webbrowsere
- websites
- Hvad
- hvorvidt
- som
- mens
- WHO
- vilje
- inden for
- uden
- ord
- ord
- Arbejde
- arbejdere
- workflow
- arbejdsgange
- virker
- ville
- år
- Din
- dig selv
- youtube
- zephyrnet