Dette er et gæsteindlæg, som er skrevet af Alex Naumov, Principal Data Architect hos smava.
smava GmbH er en af de førende finansielle servicevirksomheder i Tyskland, der gør personlige lån gennemsigtige, retfærdige og overkommelige for forbrugerne. Med udgangspunkt i digitale processer sammenligner smava lånetilbud fra mere end 20 banker. På denne måde kan låntagere på en hurtig, digitaliseret og effektiv måde vælge de tilbud, der er mest fordelagtige for dem.
smava tror på og udnytter datadrevne beslutninger for at blive markedsleder. Dataplatformsteamet er ansvarligt for at understøtte datadrevne beslutninger hos smava ved at levere dataprodukter på tværs af alle afdelinger og grene af virksomheden. Afdelingerne omfatter teams fra teknik til salg og marketing. Filialer spænder efter produkter, nemlig B2C lån, B2B lån og tidligere også B2C realkreditlån. De dataprodukter, der bruges i virksomheden, omfatter blandt andet indsigt fra brugerrejser, driftsrapporter og marketingkampagneresultater. Dataplatformen betjener i gennemsnit 60 tusinde forespørgsler om dagen. Datamængden er i tocifrede TB'er med konstant vækst i takt med, at forretning og datakilder udvikler sig.
smavas Data Platform-team stod over for udfordringen med at levere data til interessenter med forskellige SLA'er, samtidig med at fleksibiliteten til at skalere op og ned og samtidig forblive omkostningseffektiv bevares. Det tog op til 3 timer at generere daglig rapportering, hvilket påvirkede virksomhedens beslutningstagning, når der skulle foretages omberegninger i løbet af dagen. For at fremskynde selvbetjeningsanalysen og fremme innovation baseret på data var der behov for en løsning til at give ethvert team mulighed for at skabe dataprodukter på egen hånd på en decentral måde. Til at oprette og administrere dataprodukterne, bruger smava Amazon rødforskydning, et datavarehus i skyen.
I dette indlæg viser vi, hvordan smava optimerede deres dataplatform ved at bruge Amazon Redshift Serverløs , Amazon Redshift datadeling at overvinde udfordringer i den rigtige størrelse for uforudsigelige arbejdsbelastninger og yderligere forbedre prisydelsen. Gennem optimeringerne opnåede smava op til 50 % omkostningsbesparelser og op til tre gange hurtigere rapportgenerering sammenlignet med den tidligere analyseinfrastruktur.
Oversigt over løsning
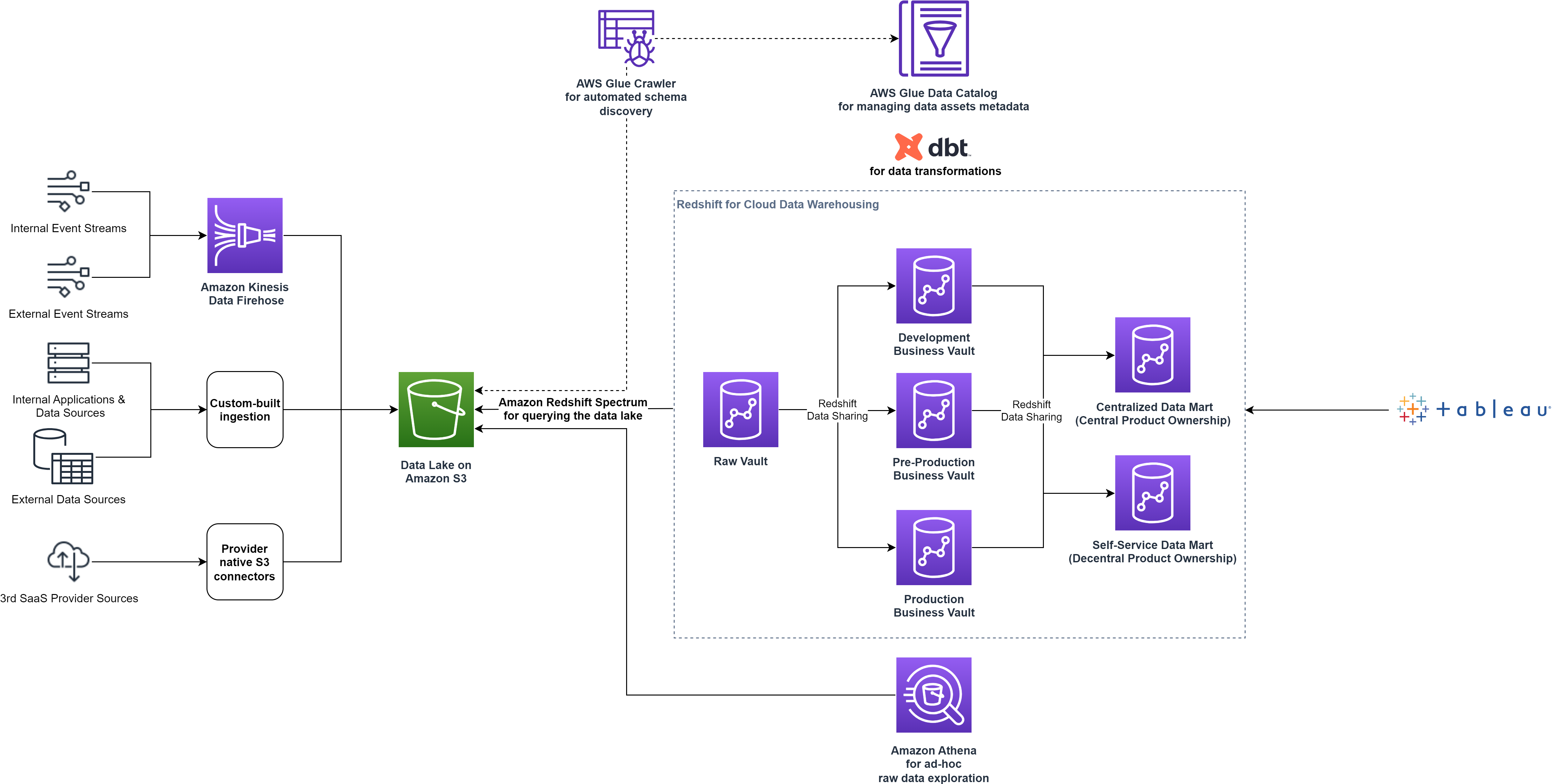
Som en datadrevet virksomhed er smava afhængig af AWS Cloud til at drive deres analytics use cases. For at give deres kunder de bedste tilbud og brugeroplevelse, følger smava moderne dataarkitektur principper med en datasø som et skalerbart, holdbart datalager og specialbyggede datalagre til analytisk behandling og dataforbrug.
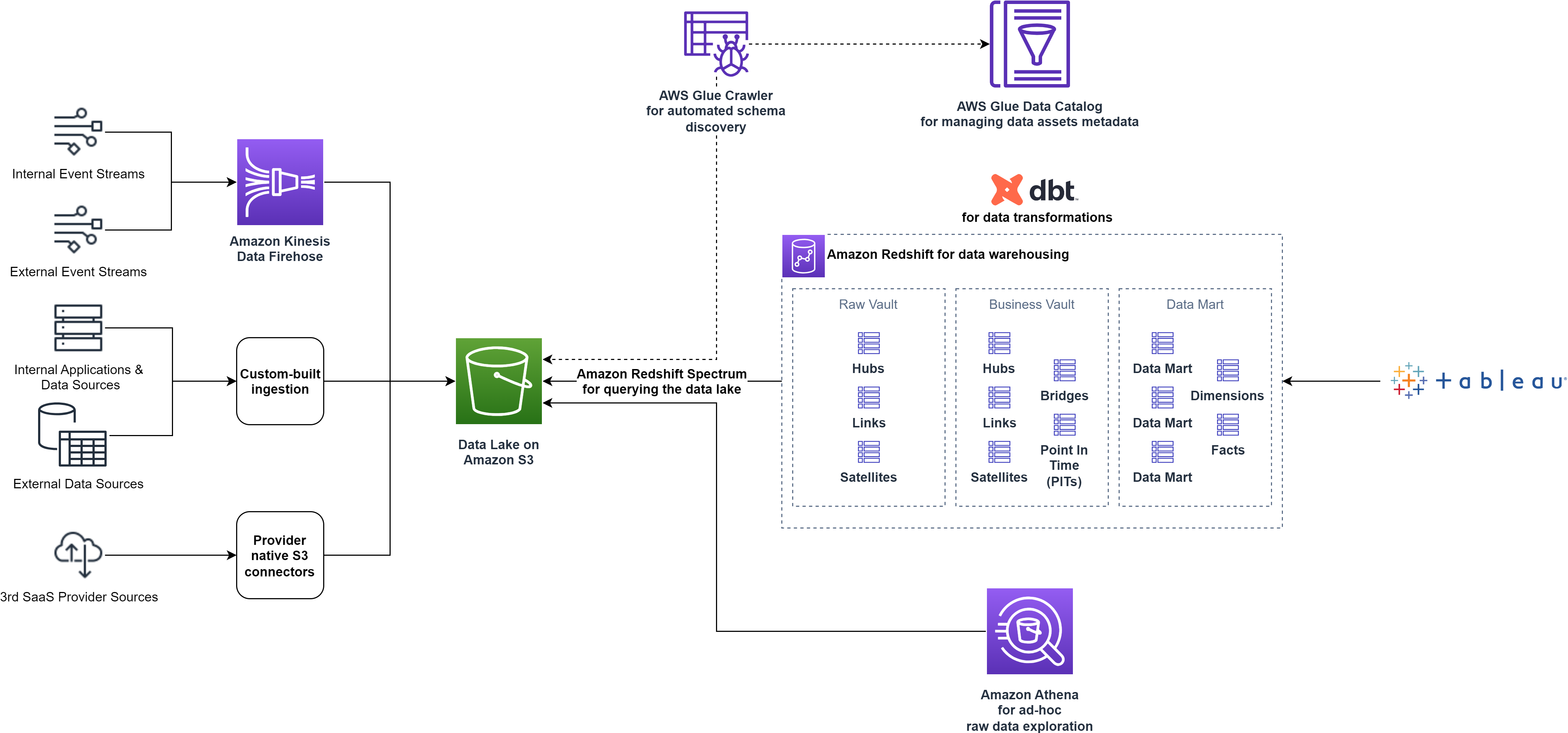
smava indtager data fra forskellige eksterne og interne datakilder til et landingssted på datasøen baseret på Amazon Simple Storage Service (Amazon S3). For at indtage dataene bruger smava et sæt populære tredjeparts kundedataplatforme suppleret med brugerdefinerede scripts.
Efter at dataene lander i Amazon S3, bruger smava AWS Lim Datakatalog og crawlere til automatisk at katalogisere de tilgængelige data, fange metadataene og levere en grænseflade, der gør det muligt at forespørge alle dataaktiver.
Dataanalytikere, der kræver adgang til de rå aktiver på datasøen, bruger Amazonas Athena, en serverløs, interaktiv analysetjeneste til udforskning med ad hoc-forespørgsler. Til downstream-forbruget af alle afdelinger på tværs af organisationen, udarbejder smavas Data Platform-team kuraterede dataprodukter efter udtrække, indlæse og transformere (ELT) mønster. smava bruger Amazon Redshift som deres cloud-datavarehus til at transformere, gemme og analysere data og anvendelser Amazon Redshift Spectrum til effektivt at forespørge og hente strukturerede og semistrukturerede data fra datasøen ved hjælp af SQL.
smava følger datahvælvingsmodellering metode med Raw Vault-, Business Vault- og Data Mart-stadierne for at forberede dataprodukterne til slutforbrugere. Raw Vault beskriver objekter indlæst direkte fra datakilderne og repræsenterer en kopi af landingsstadiet i datasøen. Business Vault er udfyldt med data hentet fra Raw Vault og transformeret i henhold til forretningsreglerne. Til sidst aggregeres dataene i specifikke dataprodukter orienteret til en specifik forretningslinje. Dette er Data Mart scene. Dataprodukterne fra Business Vault- og Data Mart-stadierne er nu tilgængelige for forbrugerne. smava besluttede at bruge Tableau til business intelligence, datavisualisering og yderligere analyser. Datatransformationerne styres med DBT for at forenkle arbejdsgangens styring og teamsamarbejde.
Følgende diagram viser dataplatformsarkitekturen på højt niveau før optimeringerne.
Udvikling af kravene til dataplatformen
smava startede med en enkelt Redshift-klynge til at være vært for alle tre datastadier. De valgte klargjorte klynge noder af RA3 type med Reserverede forekomster (RI'er) til omkostningsoptimering. Da datamængderne voksede 53 % år over år, steg kompleksiteten og kravene fra forskellige analytiske arbejdsbelastninger også.
smava adresserede hurtigt de voksende datamængder ved at tilpasse klyngen i den rigtige størrelse og bruge Amazon Redshift samtidighedsskalering for spidsbelastninger. Ydermere ønskede smava at give alle teams mulighed for at skabe deres egne dataprodukter på en selvbetjeningsmåde for at øge innovationstempoet. For at undgå enhver interferens med de centralt administrerede dataprodukter skulle de decentraliserede produktudviklingsmiljøer være strengt isolerede. Det samme krav blev også anvendt til isolering af forskellige produktstadier, kurateret af Data Platform-teamet.
Optimering af arkitekturen med datadeling og Redshift Serverless
For at opfylde de udviklede krav besluttede smava at adskille arbejdsbyrden ved at opdele den enkelte klargjorte Redshift-klynge i flere datavarehuse, hvor hvert varehus betjener en anden fase. Derudover tilføjede smava nye iscenesættelsesmiljøer i Business Vault for at udvikle nye dataprodukter uden risiko for at forstyrre eksisterende produktpipelines. For at undgå enhver interferens med de centralt administrerede dataprodukter fra Data Platform-teamet, introducerede smava en ekstra Redshift-klynge, der isolerede de decentraliserede arbejdsbelastninger.
smava ledte efter en out-of-the-box løsning til at opnå arbejdsbelastningsisolering uden at administrere en kompleks datareplikeringspipeline.
Lige efter lanceringen af Redshift datadeling kapaciteter i 2021, erkendte Data Platform-teamet, at dette var den løsning, de havde ledt efter. smava brugte datadelingsfunktionen for at have data fra producentklynger tilgængelige for læseadgang på forskellige forbrugerklynger, hvor hver af disse forbrugerklynger tjener en anden fase.
Redshift-datadeling muliggør øjeblikkelig, detaljeret og hurtig dataadgang på tværs af Redshift-klynger uden behov for at kopiere data. Det giver live adgang til data, så brugerne altid ser den mest opdaterede og konsistente information, når den opdateres i datavarehuset. Med datadeling kan du sikkert dele live-data med Redshift-klynger i den samme eller forskellige AWS-konti og på tværs af regioner.
Med Redshift-datadeling var smava i stand til at optimere dataarkitekturen ved at adskille dataarbejdsbelastningerne til individuelle forbrugerklynger uden at skulle replikere dataene. Følgende diagram illustrerer dataplatformsarkitekturen på højt niveau efter opdeling af den enkelte Redshift-klynge i flere klynger.
Ved at levere en selvbetjeningsdatamart øgede smava datademokratiseringen ved at give brugerne adgang til alle aspekter af dataene. De forsynede også teams med et sæt tilpassede værktøjer til dataopdagelse, ad hoc-analyse, prototyping og drift af modne dataprodukters fulde livscyklus.
Efter at have indsamlet driftsdata fra de individuelle klynger identificerede Data Platform-teamet yderligere potentielle optimeringer: Raw Vault-klyngen var under konstant belastning 24/7, men Business Vault-klyngerne blev kun opdateret hver nat. For at optimere omkostningerne brugte smava pause og genoptag funktioner af Redshift-klargjorte klynger. Disse funktioner er nyttige for klynger, der skal være tilgængelige på bestemte tidspunkter. Mens klyngen er sat på pause, suspenderes on-demand-fakturering. Kun klyngens lager pålægges gebyrer.
Pause og genoptag-funktionen hjalp smava med at optimere omkostningerne, men det krævede yderligere driftsomkostninger for at udløse klyngedriften. Derudover forblev udviklingsklyngerne underlagt ledige tider i arbejdstiden. Disse udfordringer blev endelig løst ved at adoptere Redshift Serverless i 2022. Data Platform-teamet besluttede at flytte Business Data Vault-faseklyngerne til Redshift Serverless, hvilket giver dem mulighed for kun at betale for datavarehuset, når det er i brug, pålideligt og effektivt.
Redshift Serverless er ideel til tilfælde, hvor det er svært at forudsige beregningsbehov såsom variable arbejdsbelastninger, periodiske arbejdsbelastninger med inaktiv tid og steady-state arbejdsbelastninger med spidser. Derudover, efterhånden som brugsefterspørgslen udvikler sig med nye arbejdsbelastninger og flere samtidige brugere, leverer Redshift Serverless automatisk de rigtige computerressourcer, og datavarehuset skaleres problemfrit og automatisk uden behov for manuel indgriben. Datadeling er understøttet i begge retninger mellem Redshift Serverless og klargjorte Redshift-klynger med RA3-noder, så ingen ændringer i smava-arkitekturen var nødvendige. Følgende diagram viser arkitekturopsætningen på højt niveau efter flytningen til Redshift Serverless.
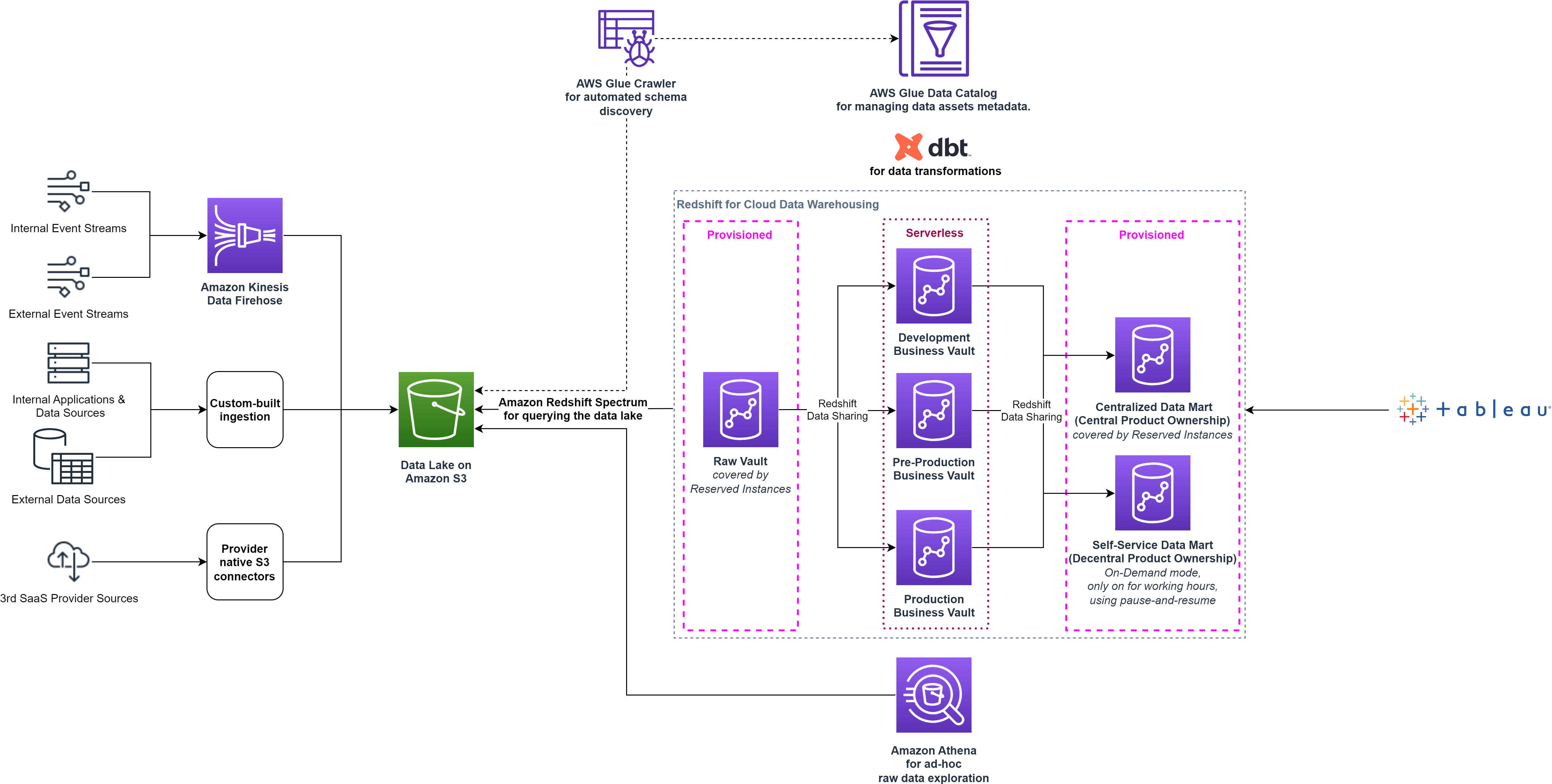
smava kombinerede fordelene ved Redshift Serverless og dbt gennem en sømløs CI/CD-pipeline ved at vedtage en trunk-baseret udviklingsmetodologi. Ændringer på Git-lageret implementeres automatisk til et teststadie og valideres ved hjælp af automatiserede integrationstests. Denne tilgang øgede udviklernes effektivitet og reducerede den gennemsnitlige tid til produktion fra dage til minutter.
smava adopterede en arkitektur, der bruger både klargjorte og serverløse Redshift-datavarehuse sammen med datadelingskapaciteten til at isolere arbejdsbelastningerne. Ved at vælge de rigtige arkitektoniske mønstre til deres behov, var smava i stand til at opnå følgende:
- Forenkle datapipelines og reducere driftsomkostninger
- Reducer frigivelsestiden for funktioner fra dage til minutter
- Forøg prisydelsen ved at reducere inaktive tider og tilpasse arbejdsbyrden i den rigtige størrelse
- Opnå op til tre gange hurtigere rapportgenerering (hurtigere beregninger og højere parallelisering) til 50 % af de oprindelige opsætningsomkostninger
- Øg smidigheden i alle afdelinger og understøtte datadrevet beslutningstagning ved at demokratisere adgangen til data
- Øg innovationshastigheden ved at eksponere selvbetjeningsdatakapaciteter for teams på tværs af alle afdelinger og styrkelse af A/B-testkapaciteterne for at dække hele kunderejsen
Nu bruger alle afdelinger hos smava de tilgængelige dataprodukter til at træffe datadrevne, præcise og agile beslutninger.
Fremtidsvision
For fremtiden planlægger smava at fortsætte med at optimere dataplatformen baseret på operationelle målinger. De overvejer at skifte flere klargjorte klynger som Self-Service Data Mart-klyngen til serverløse. Derudover optimerer smava ELT-orkestreringsværktøjskæden for at øge antallet af parallelle datapipelines, der skal køres. Dette vil øge udnyttelsen af klargjorte Redshift-ressourcer og give mulighed for omkostningsreduktioner.
Med introduktionen af den decentraliserede, selvbetjening til oprettelse af dataprodukter tog smava et skridt fremad mod en data mesh arkitektur. I fremtiden planlægger Data Platform-teamet yderligere at evaluere behovene hos deres servicebrugere og etablere yderligere datamesh-principper såsom fødereret datastyring.
Konklusion
I dette indlæg viste vi, hvordan smava optimerede deres dataplatform ved at isolere miljøer og arbejdsbelastninger ved hjælp af Redshift Serverless og datadelingsfunktioner. Disse Redshift-miljøer er godt integreret med deres infrastruktur, fleksible i skalering efter behov og meget tilgængelige, og de kræver minimal administrationsindsats. Samlet set har smava øget ydeevnen med tre gange, mens den har reduceret de samlede platformsomkostninger med 50 %. Derudover reducerede de driftsomkostningerne til et minimum, mens de bibeholdt de eksisterende SLA'er for rapportgenereringstider. Ydermere har smava styrket innovationskulturen ved at levere selvbetjeningsdataproduktkapaciteter for at fremskynde deres time-to-market.
Hvis du er interesseret i at lære mere om Amazon Redshift-funktioner, anbefaler vi at se den seneste Hvad er nyt med Amazon Redshift-session i AWS Events-kanalen for at få et overblik over de funktioner, der for nylig er tilføjet til tjenesten. Du kan også udforske selvbetjening, praktiske Amazon Redshift-laboratorier at eksperimentere med vigtige Amazon Redshift-funktioner på en guidet måde.
Du kan også dykke dybere ned i Redshift Serverless use cases , brugssager for datadeling. Tjek desuden bedste praksis for datadeling og opdag hvordan andre kunder optimeret til omkostninger og ydeevne med Redshift-datadeling at blive inspireret til dine egne arbejdsopgaver.
Hvis du foretrækker bøger, så tjek ud Amazon Redshift: The Definitive Guide af O'Reilly, hvor forfatterne detaljerer Amazon Redshifts muligheder og giver dig indsigt i tilsvarende mønstre og teknikker.
Om forfatterne
 Alex Naumov er Principal Data Architect hos smava GmbH, og leder transformationsprojekterne i Dataafdelingen. Alex har tidligere arbejdet 10 år som konsulent og data-/løsningsarkitekt inden for en bred vifte af domæner, såsom telekommunikation, bank, energi og finans, ved hjælp af forskellige teknologiske stakke og i mange forskellige lande. Han har en stor passion for data og at transformere organisationer til at blive datadrevne og de bedste i det, de laver.
Alex Naumov er Principal Data Architect hos smava GmbH, og leder transformationsprojekterne i Dataafdelingen. Alex har tidligere arbejdet 10 år som konsulent og data-/løsningsarkitekt inden for en bred vifte af domæner, såsom telekommunikation, bank, energi og finans, ved hjælp af forskellige teknologiske stakke og i mange forskellige lande. Han har en stor passion for data og at transformere organisationer til at blive datadrevne og de bedste i det, de laver.
 Lingli Zheng arbejder som Business Development Manager i AWS verdensomspændende specialistorganisation og støtter kunder i DACH-regionen med at få den bedste værdi ud af Amazons analysetjenester. Med over 12 års erfaring inden for energi, automatisering og softwareindustrien med fokus på dataanalyse, AI og ML, er hun dedikeret til at hjælpe kunder med at opnå håndgribelige forretningsresultater gennem digital transformation.
Lingli Zheng arbejder som Business Development Manager i AWS verdensomspændende specialistorganisation og støtter kunder i DACH-regionen med at få den bedste værdi ud af Amazons analysetjenester. Med over 12 års erfaring inden for energi, automatisering og softwareindustrien med fokus på dataanalyse, AI og ML, er hun dedikeret til at hjælpe kunder med at opnå håndgribelige forretningsresultater gennem digital transformation.
 Alexander Spivak er Senior Startup Solutions Architect hos AWS, med fokus på B2B ISV-kunder på tværs af EMEA North. Før AWS arbejdede Alexander som konsulent i finansielle tjenesteydelser, herunder forskellige roller inden for softwareudvikling og arkitektur. Han brænder for dataanalyse, serverløse arkitekturer og at skabe effektive organisationer.
Alexander Spivak er Senior Startup Solutions Architect hos AWS, med fokus på B2B ISV-kunder på tværs af EMEA North. Før AWS arbejdede Alexander som konsulent i finansielle tjenesteydelser, herunder forskellige roller inden for softwareudvikling og arkitektur. Han brænder for dataanalyse, serverløse arkitekturer og at skabe effektive organisationer.
Dette indlæg blev gennemgået for teknisk nøjagtighed af David Greenshtein, Senior Analytics Solutions Architect.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/how-smava-makes-loans-transparent-and-affordable-using-amazon-redshift-serverless/
- :har
- :er
- :hvor
- $OP
- 10
- 100
- 12
- 125
- 20
- 2021
- 2022
- 60
- a
- I stand
- Om
- adgang
- Adgang til data
- udrette
- Ifølge
- Konti
- nøjagtighed
- præcis
- opnå
- opnået
- tværs
- Ad
- tilføjet
- Desuden
- Yderligere
- Derudover
- rettet
- administration
- vedtaget
- Vedtagelsen
- Fordel
- overkommelige
- Efter
- adræt
- AI
- alex
- Alexander
- Alle
- tillade
- tillader
- også
- altid
- Amazon
- Amazon Web Services
- blandt
- an
- analyse
- Analytikere
- Analytisk
- Analytisk
- analytics
- analysere
- ,
- enhver
- anvendt
- tilgang
- arkitektonisk
- arkitektur
- ER
- AS
- aspekter
- Aktiver
- At
- forfatter
- forfattere
- Automatiseret
- automatisk
- Automation
- til rådighed
- gennemsnit
- undgå
- AWS
- B2B
- B2C
- Bank
- Banker
- baseret
- BE
- bliver
- været
- før
- mener
- fordele
- BEDSTE
- mellem
- fakturerings- og
- Blog
- Bøger
- låntagere
- både
- grene
- bringe
- virksomhed
- forretningsudvikling
- business intelligence
- men
- by
- Kampagne
- CAN
- kapaciteter
- kapacitet
- fange
- tilfælde
- katalog
- udfordre
- udfordringer
- Ændringer
- afgifter
- kontrollere
- Vælg
- vælge
- valgte
- Cloud
- Cluster
- samarbejde
- Indsamling
- kombineret
- Virksomheder
- selskab
- sammenlignet
- fuldføre
- komplekse
- kompleksitet
- Compute
- konkurrent
- Overvejer
- konsekvent
- konsulent
- forbruger
- Forbrugere
- forbrug
- fortsæt
- Tilsvarende
- Koste
- omkostningsbesparelser
- Omkostninger
- lande
- dæksel
- skabe
- Oprettelse af
- skabelse
- Medarbejder kultur
- kurateret
- skik
- kunde
- kundedata
- Kunder
- dagligt
- data
- dataadgang
- Dataanalyse
- Data Lake
- Dataplatform
- datadeling
- datavisualisering
- datalager
- datavarehuse
- datastyret
- David
- dag
- Dage
- Tilbud
- decentral
- besluttede
- Beslutningstagning
- afgørelser
- er faldet
- dedikeret
- dybere
- endelige
- levere
- Efterspørgsel
- demokratisering
- demokratisering
- Afdeling
- afdelinger
- indsat
- detail
- udvikle
- udviklere
- Udvikling
- DID
- forskellige
- svært
- digital
- Digital Transformation
- retninger
- direkte
- opdage
- opdagelse
- dyk
- do
- Domæner
- ned
- i løbet af
- hver
- effektivitet
- effektiv
- effektivt
- indsats
- EMEA
- muliggør
- ende
- energi
- engagementer
- Engineering
- miljøer
- etablere
- Ether (ETH)
- evaluere
- begivenheder
- udvikle sig
- udviklet sig
- udvikler
- eksisterende
- erfaring
- eksperiment
- udforskning
- udforske
- ekstern
- konfronteret
- retfærdig
- FAST
- hurtigere
- gunstig
- Feature
- Funktionalitet
- Endelig
- finansiere
- finansielle
- finansielle tjenesteydelser
- Fleksibilitet
- fleksibel
- Fokus
- fokusering
- efter
- følger
- Til
- For forbrugere
- tidligere
- Videresend
- Foster
- fra
- fuld
- funktionaliteter
- yderligere
- Endvidere
- fremtiden
- generere
- generation
- Tyskland
- få
- Git
- Giv
- GmBH
- regeringsførelse
- stor
- voksede
- Dyrkning
- Vækst
- Gæst
- gæst Indlæg
- vejlede
- guidet
- havde
- hands-on
- ske
- Have
- have
- he
- hjulpet
- hjælpe
- højt niveau
- højere
- stærkt
- host
- HOURS
- Hvordan
- HTML
- HTTPS
- ideal
- identificeret
- tomgang
- illustrerer
- påvirket
- Forbedre
- in
- omfatter
- Herunder
- Forøg
- øget
- individuel
- industrien
- oplysninger
- Infrastruktur
- Innovation
- indvendig
- indsigt
- inspirerede
- forekomster
- øjeblikkelig
- integreret
- integration
- Intelligens
- interaktiv
- interesseret
- grænseflade
- interferens
- at blande sig
- interne
- indgriben
- ind
- introduceret
- indføre
- Introduktion
- isolerede
- isolation
- ISV
- IT
- Journeys
- Nøgle
- sø
- landing
- lander
- lancere
- leder
- førende
- Leads
- læring
- livscyklus
- ligesom
- Line (linje)
- leve
- live data
- belastning
- lån
- Lån
- leder
- lavet
- opretholdelse
- lave
- maerker
- Making
- administrere
- lykkedes
- leder
- styring
- måde
- manuel
- mange
- Marked
- Markedsleder
- Marketing
- modne
- Mød
- mesh
- Metadata
- Metode
- Metrics
- minimum
- minutter
- ML
- mere
- Desuden
- Realkreditlån
- mest
- bevæge sig
- flere
- nemlig
- Behov
- behov
- behov
- Ny
- ingen
- noder
- Nord
- nu
- nummer
- objekter
- of
- Tilbud
- on
- On-Demand
- ONE
- kun
- drift
- operationelle
- Produktion
- optimering
- Optimer
- optimeret
- optimering
- Option
- or
- orkestrering
- ordrer
- organisation
- organisationer
- original
- Andet
- Andre
- ud
- i løbet af
- samlet
- Overvind
- oversigt
- egen
- Tempo
- Parallel
- lidenskab
- lidenskabelige
- Mønster
- mønstre
- pause
- sat på pause
- Betal
- Peak
- per
- ydeevne
- periodisk
- personale
- Personlige lån
- pipeline
- planer
- perron
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- befolkede
- Indlæg
- potentiale
- magt
- forudsige
- foretrække
- Forbered
- Forbereder
- tidligere
- tidligere
- Main
- principper
- Forud
- Processer
- forarbejdning
- producent
- Produkt
- produktudvikling
- produktion
- Produkter
- projekter
- prototyping
- give
- forudsat
- giver
- leverer
- forespørgsler
- hurtigt
- rækkevidde
- Raw
- Læs
- nylige
- for nylig
- anerkendt
- anbefaler
- reducere
- Reduceret
- reducere
- reduktioner
- region
- regioner
- frigive
- forblevet
- replikation
- indberette
- Rapportering
- Rapporter
- Repository
- repræsenterer
- kræver
- påkrævet
- krav
- Krav
- Ressourcer
- ansvarlige
- Resultater
- Genoptag
- revideret
- højre
- Risiko
- roller
- regler
- Kør
- salg
- Salg og Marketing
- samme
- Besparelser
- skalerbar
- Scale
- skalaer
- skalering
- scripts
- sømløs
- problemfrit
- sikkert
- se
- Selvbetjening
- senior
- adskille
- adskille
- Serverless
- tjener
- tjeneste
- Tjenester
- servering
- Session
- sæt
- setup
- Del
- deling
- hun
- Vis
- viste
- Shows
- Simpelt
- forenkle
- enkelt
- So
- Software
- softwareudvikling
- løsninger
- Løsninger
- løst
- indkøbt
- Kilder
- specialist
- specifikke
- hastighed
- spikes
- SQL
- Stakke
- Stage
- etaper
- iscenesættelse
- interessenter
- påbegyndt
- opstart
- opholder
- steady
- Trin
- opbevaring
- butik
- forhandler
- styrket
- styrkelse
- struktureret
- emne
- sådan
- support
- Understøttet
- Støtte
- suspenderet
- Tableau
- tager
- materielle
- hold
- hold
- tech
- Teknisk
- teknikker
- telekommunikation
- prøve
- tests
- end
- at
- Fremtiden
- deres
- Them
- Disse
- de
- tredjepart
- denne
- dem
- tusinde
- tre
- Gennem
- tid
- gange
- til
- sammen
- tog
- værktøjer
- I alt
- mod
- Transform
- Transformation
- transformationer
- omdannet
- omdanne
- gennemsigtig
- udløse
- under
- uforudsigelige
- up-to-date
- opdateret
- Brug
- brug
- anvendte
- Bruger
- Brugererfaring
- brugere
- bruger
- ved brug af
- udnytter
- valideret
- værdi
- variabel
- række
- forskellige
- Vault
- visualisering
- bind
- mængder
- ønskede
- Warehouse
- var
- ser
- Vej..
- måder
- we
- web
- webservices
- GODT
- var
- Hvad
- hvornår
- som
- mens
- WHO
- bred
- Wikipedia
- vilje
- med
- uden
- arbejdede
- workflow
- arbejder
- Arbejdstimer
- virker
- workshops
- verdensplan
- år
- år
- dig
- Din
- youtube
- zephyrnet