Mens OpenAI ChatGPT suger al ilten op af den 24-timers nyhedscyklus, har Google stille og roligt afsløret en ny AI-model, der kan generere videoer, når de får video-, billed- og tekstinput. Den nye Google Dreamix AI videoeditor bringer nu genereret video tættere på virkeligheden.
Ifølge forskningen offentliggjort på GitHub, redigerer Dreamix videoen baseret på en video og en tekstprompt. Den resulterende video bevarer sin troskab til farve, kropsholdning, objektstørrelse og kameraposition, hvilket resulterer i en tidsmæssigt konsistent video. I øjeblikket kan Dreamix ikke generere videoer fra kun en prompt, men den kan tage eksisterende materiale og ændre videoen ved hjælp af tekstprompter.
Google bruger videodiffusionsmodeller til Dreamix, en tilgang, der med succes er blevet anvendt til det meste af den videobilledredigering, vi ser i billed-AI'er som DALL-E2 eller open source Stable Diffusion.
Fremgangsmåden involverer kraftigt at reducere input-videoen, tilføje kunstig støj og derefter behandle den i en videodiffusionsmodel, som derefter bruger en tekstprompt til at generere en ny video fra den, der bevarer nogle egenskaber fra den originale video og gengiver andre iht. til tekstinputtet.
Videodiffusionsmodellen tilbyder en lovende fremtid, der kan indlede en ny æra for arbejde med videoer.

For eksempel, i videoen nedenfor, forvandler Dreamix den spisende abe (venstre) til en dansende bjørn (højre) givet prompten "En bjørn danser og hopper til optimistisk musik og bevæger hele sin krop."
I et andet eksempel nedenfor bruger Dreamix et enkelt foto som skabelon (som i billede-til-video), og et objekt animeres derefter fra det i en video via en prompt. Kamerabevægelser er også mulige i den nye scene eller en efterfølgende time-lapse-optagelse.
I et andet eksempel forvandler Dreamix orangutangen i en vandpøl (venstre) til en orangutang med orange hår, der bader i et smukt badeværelse.
“Mens diffusionsmodeller er blevet anvendt med succes til billedredigering, har meget få værker gjort det til videoredigering. Vi præsenterer den første diffusionsbaserede metode, der er i stand til at udføre tekstbaseret bevægelses- og udseenderedigering af generelle videoer."
Ifølge Google-forskningspapiret bruger Dreamix en videodiffusionsmodel til på inferenstidspunkt at kombinere den rumlige rumlige information i lav opløsning fra den originale video med ny information i høj opløsning, som den syntetiserede for at tilpasse sig den vejledende tekstprompt."
Google sagde, at det tog denne tilgang, fordi "at opnå high-fidelity til den originale video kræver at bevare nogle af dens højopløsningsoplysninger, vi tilføjer et indledende trin til at finjustere modellen på den originale video, hvilket øger troværdigheden betydeligt."
Nedenfor er en videooversigt over, hvordan Dreamix virker.
[Indlejret indhold]
Sådan fungerer Dreamix-videodiffusionsmodeller
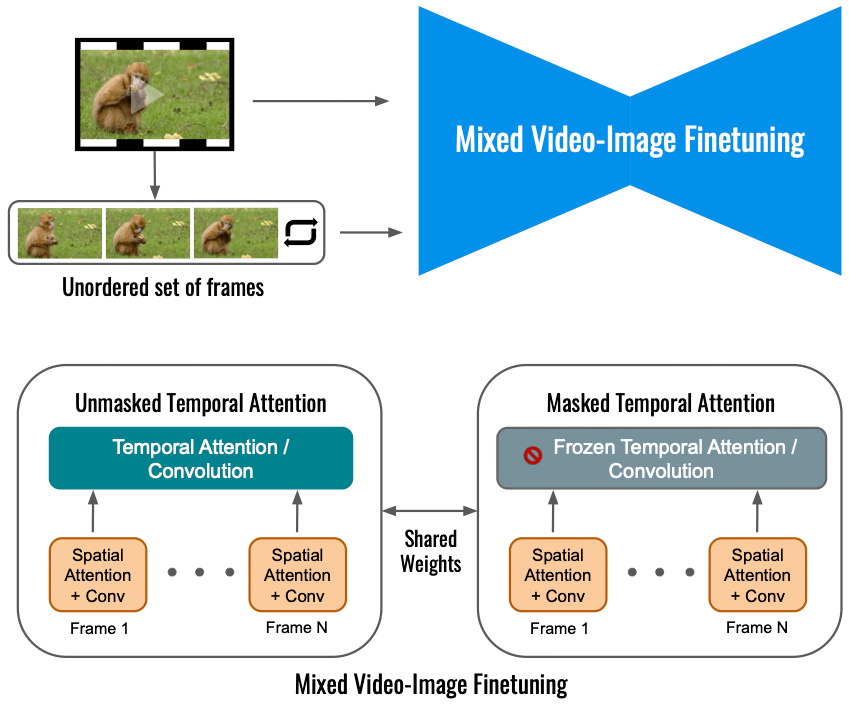
Ifølge Google begrænser finjustering af videodiffusionsmodellen for Dreamix alene på inputvideoen omfanget af bevægelsesændringer. I stedet bruger vi et blandet objektiv, der udover det originale objektiv (nederst til venstre) også finjusterer på det uordnede sæt rammer. Dette gøres ved at bruge "maskeret tidsmæssig opmærksomhed", hvilket forhindrer den tidsmæssige opmærksomhed og foldning i at blive finjusteret (nederst til højre). Dette gør det muligt at tilføje bevægelse til en statisk video.
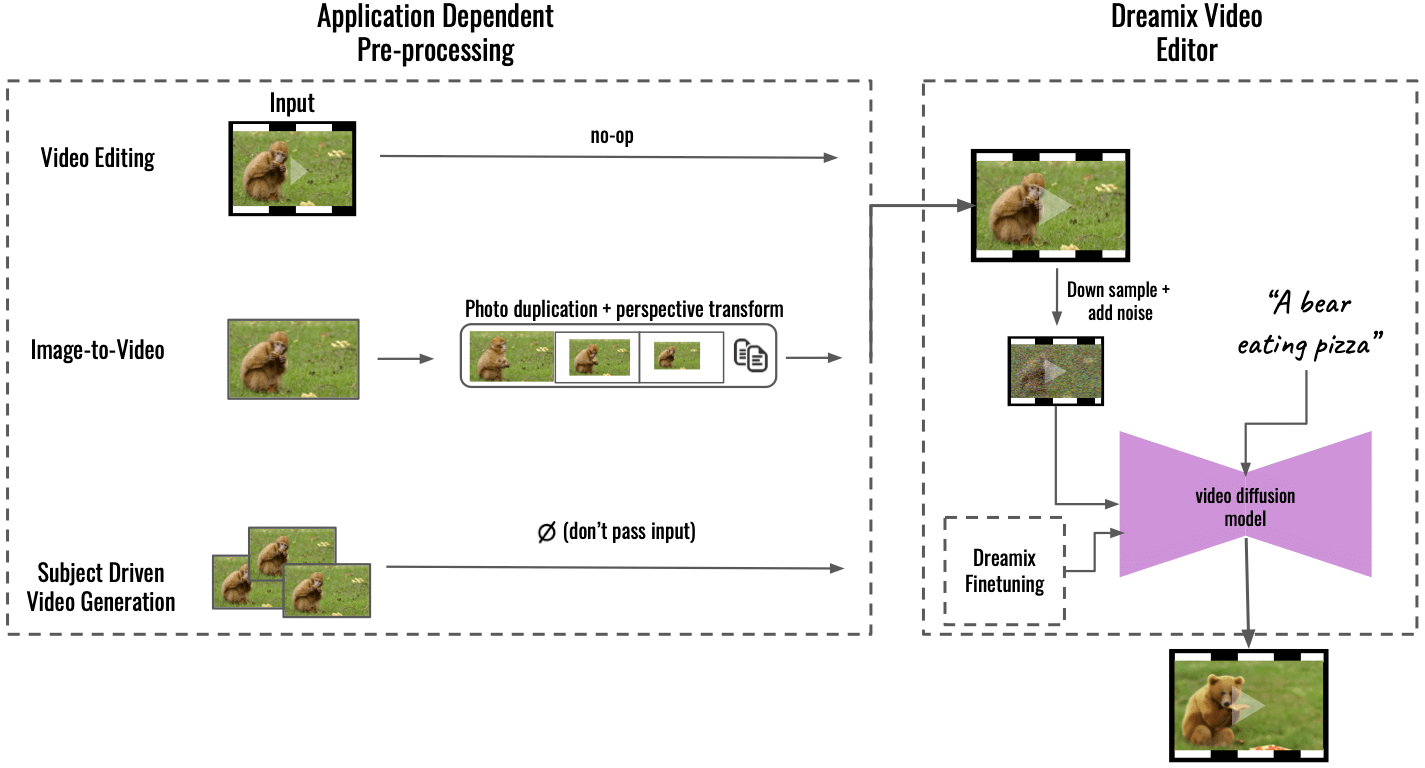
"Vores metode understøtter flere applikationer ved applikationsafhængig forbehandling (venstre), der konverterer inputindholdet til et ensartet videoformat. For billede-til-video bliver inputbilledet duplikeret og transformeret ved hjælp af perspektivtransformationer, der syntetiserer en grov video med nogle kamerabevægelser. For motivdrevet videogenerering er input udeladt - finjustering alene sørger for troskaben. Denne grove video redigeres derefter ved hjælp af vores generelle "Dreamix Video Editor" (højre): vi korrumperer først videoen ved at nedsample efterfulgt af tilføjelse af støj. Vi anvender derefter den finjusterede tekst-guidede videodiffusionsmodel, som opskalerer videoen til den endelige rumlige opløsning," skrev Dream på GitHub.
Du kan læse forskningspapiret nedenfor.
Google Dreamix- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- I stand
- Ifølge
- AI
- ai video
- AI-drevne
- Alle
- tillader
- alene
- ,
- En anden
- applikationer
- anvendt
- Indløs
- tilgang
- kunstig
- opmærksomhed
- baseret
- Husk
- smuk
- fordi
- være
- jf. nedenstående
- krop
- fremme
- Bund
- Bringer
- værelse
- kan ikke
- hvilken
- lave om
- ChatGPT
- tættere
- farve
- kombinerer
- konsekvent
- indhold
- Oprettelse af
- cyklus
- Dancing
- Broadcasting
- drøm
- editor
- indlejret
- Era
- eksempel
- eksisterende
- få
- troskab
- endelige
- Fornavn
- efterfulgt
- format
- fra
- fremtiden
- Generelt
- generere
- genereret
- generation
- gif
- GitHub
- given
- Hår
- stærkt
- høj opløsning
- Hvordan
- Men
- HTTPS
- billede
- billeder
- in
- oplysninger
- indgang
- i stedet
- IT
- lanceringer
- grænser
- fastholder
- materiale
- max
- metode
- blandet
- model
- modeller
- ændre
- øjeblik
- mest
- bevægelse
- bevægelser
- flytning
- flere
- Musik
- Ny
- nyheder
- Støj
- objekt
- objektiv
- Tilbud
- open source
- OpenAI
- Orange
- original
- Andre
- oversigt
- Oxygen
- Papir
- udføre
- perspektiv
- plato
- Platon Data Intelligence
- PlatoData
- pool
- mulig
- præsentere
- forebyggelse
- forarbejdning
- lovende
- egenskaber
- offentliggjort
- roligt
- Læs
- Reality
- optagelse
- reducere
- Kræver
- forskning
- Løsning
- resulterer
- tilbageholdende
- Said
- scene
- sæt
- betydeligt
- enkelt
- Størrelse
- So
- nogle
- stabil
- Stage
- efterfølgende
- Succesfuld
- sådan
- Understøtter
- Tag
- skabelon
- tid
- til
- transformationer
- omdannet
- afsløret
- brug
- via
- video
- Videoer
- Vand
- som
- arbejder
- virker
- youtube
- zephyrnet











