Data er livline for alle online-virksomheder og måden, vi interagerer på.
Hver dag skaber vi nogenlunde 2.5 kvintillion bytes af data. Det er en del. Men det, der er overraskende, er det 90 % af disse data er ustruktureret.
Den har ikke nogen særlig struktur. Så for at give mening med dataene, skal vi virkelig forstå, hvordan vi håndterer ustrukturerede data.
Lad os dykke dybt ned i ustrukturerede data uden videre.
Hvad er ustrukturerede data?
Alt i denne digitale verden er sammensat af data. Data kan have to formater, enten kan de følge en ordentlig struktur, eller også ville de ikke.
Enhver information, der ikke er arrangeret i nogen sekvens eller skema eller nogen specifik struktur, der gør det let at læse for andre, kaldes ustrukturerede data.
Ustrukturerede data har ingen struktur eller format for at gøre dem let genkendelige. Ustrukturerede data er meget tekstbaserede som data, fakta, åbne undersøgelsessvar, men de kan også være ikke-tekstuelle som billeder, lyd eller video.
Læs mere: Hvordan udtrækker man data fra PDF?
Hvad er eksemplerne på ustrukturerede data?
Når du tænker på data, så tænk på enhver form for data, der ikke har et gentaget eller genkendeligt mønster, og det ville være ustrukturerede data. Det kan være tekstmæssigt, ikke-tekstuelt, menneskeligt eller maskingenereret. Her er nogle eksempler på ustrukturerede data:
Tekstdata
De data, der er tilgængelige i en e-mail eller skriftlig form, kaldes tekstdata. Tekstbeskeder, skrevne dokumenter, word, PDF'er og andre filer, af dem, er et eksempel på ustrukturerede data.
Multimediebeskeder
En type ustrukturerede data er multimediebeskeder. Multimediedata omfatter billeder (JPEG, PNG, GIF), lyd- eller videoformat. Multimediebeskeder er en blanding af kompleks kode, der ikke har et lignende mønster.
Alle billeder, videoer eller lydfiler kan være krypterede binære koder, som ikke følger noget mønster og derfor er ustrukturerede data. Hvad ser du her?

Nå, det er faktisk et billede af en rød bil.

Billederne og billederne har brug for observation for at forstå, og deres data er ikke fuldstændig sammensat, det er derfor, dette kaldes de ustrukturerede data.
Indhold på webstedet
Alle websteder er fyldt med enhver information, der er tilgængelig i form af lange afsnit, spredte og uorganiserede formularer. Dette er en slags data med værdifuld information, men alligevel er det ikke værdigt, fordi den korrekte sammensætning af data er påkrævet.
Sensordata - IoT-enheder
Internet of things er en fysisk enhed, der indsamler information om sine omgivelser og sender dataene tilbage til skyen. IoT-enheder sender følsomme sensordata tilbage, som kan være ustrukturerede. Eksempler på IoT-enheder, der sender senordata, kunne være trafikovervågningsenheder, musikenheder som Alexa, Google Home osv.
E-mail er meget brugt af virksomheder som en af de primære kanaler til at kommunikere. E-mails kan klassificeres som semistrukturerede eller ustrukturerede. Der er mange tilgængelige parsingværktøjer, der skraber e-mailoplysningerne for at forstå detaljerne.
Erhvervsdokumenter
Virksomheder håndterer dokumenter af forskellige typer, såsom PDF'er, e-mails, fakturaer, ordrer og mere. Alle dokumenter har forskellige strukturer. For at udtrække data fra PDF-filer, og andre papirbaserede dokumenter, virksomheder kan bruge intelligent dokumentbehandlingssoftware ligesom nanonetter.
10,000+ brugere bruger Nanonets til at konvertere ustrukturerede data til strukturerede data med 98 %+ nøjagtighed. Give det en chance?
Hvad er forskellen mellem strukturerede og ustrukturerede data?
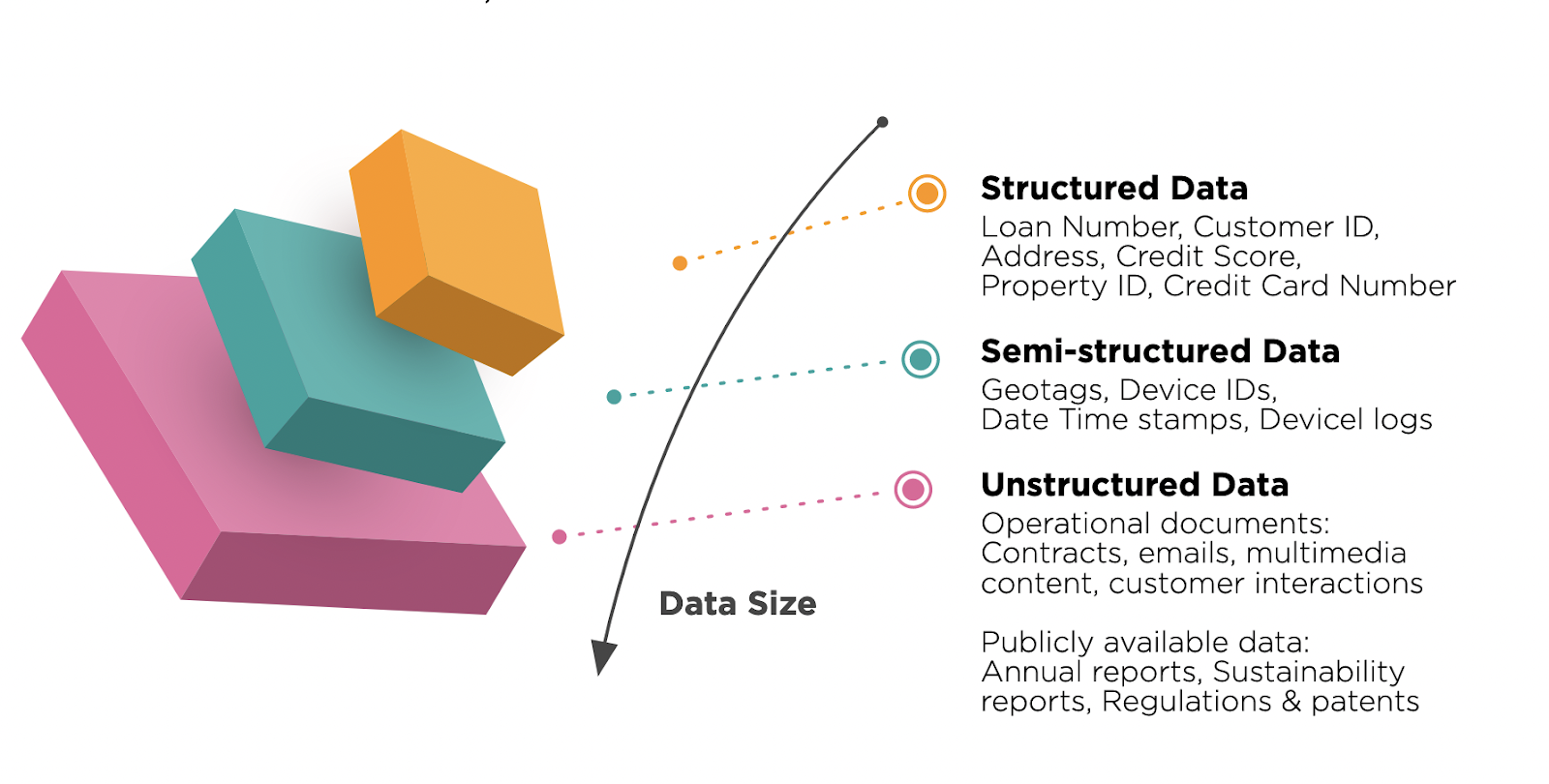
Big data omfatter strukturerede, semistrukturerede og ustrukturerede data. Alle disse typer data har meget at byde på. Lad os se nærmere på deres forskelle.
Strukturerede data er en anden slags data, der følger et bestemt mønster og er let at genkende. Denne form for data er tilgængelig i RDBMS og har mange applikationer. Der er en kort tabel med beskrivelser mellem både strukturerede og ustrukturerede data:
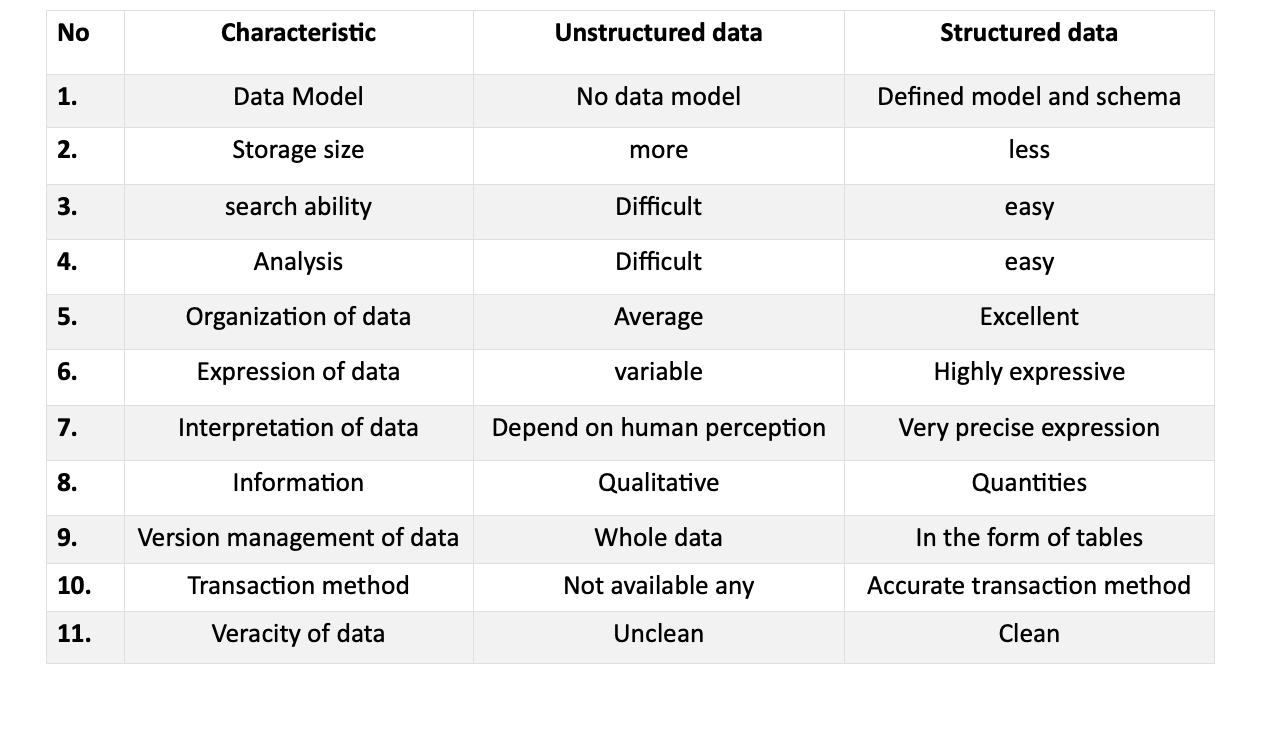
Datamodel
- Ustrukturerede data kommer ofte i form af store pdf'er, tekst eller multimediefiler, mens strukturerede data er præcise og organiserede.
- Den definerede model for strukturerede data gør det nemt og pålideligt at studere og få adgang til.
- Store filer kræver betydelig lagerkapacitet, hvilket gør strukturerede data mere ønskværdige på grund af dens justerbare filstørrelse, ofte i et tabelformat.
Dataanalyse
- Analysen bestemmer dataens relevans og nøjagtighed.
- Ustrukturerede data kan indeholde upålidelig eller tvetydig viden, i modsætning til strukturerede data, som er organiseret og justeret.
- Strukturerede data foretrækkes på grund af den nemme analyse sammenlignet med ustrukturerede data.
Søgbarhed
- Ustruktureret dataudtræk kan være kaotisk, hvilket gør søgningen efter vigtige punkter tidskrævende.
- Strukturerede data er let søgbare på grund af dens organisation.
- Ustrukturerede data kan være svære at forstå og søge på grund af deres størrelse og format.
Visionær analyse
- Den fokuserede analyse af ustrukturerede data kan afsløre værdifuld indsigt.
- Data i et kort, opdateret format tiltrækker mere interesse end lange afsnit.
- Strukturerede data giver mulighed for hurtigere godkendelse af information, hvilket sparer brugere tid.
Hvad er udfordringerne ved at arbejde med ustrukturerede data?
De ustrukturerede data kommer i meget lang form, og det er derfor, ustruktureret dataudtræk er nødvendig. Det arbejdende personale står over for mange udfordringer, mens de arbejder med ustrukturerede data. Først og fremmest er denne type data tilgængelig i en massetekst af enhver anden form, og det er derfor, det tager for lang tid at gøre med disse data. For det andet, hvis data er tilgængelige i store filer, som de fleste sandsynligvis ustrukturerede data præsenterer, tager det for meget lagerplads. Kvaliteten af de strukturerede data er, at de præsenteres i meget præcise og tabelformede former, hvorfor udtræk af data er meget let.
Kompromitteret relevans
Det ses, at ustrukturerede data indeholder meget information, der ikke er værdifuld og meget unøjagtig og irrelevant. Nøjagtigheden af dataene skal vedligeholdes på den bedst mulige måde, derfor er den største udfordring ved ustruktureret dataudtræk at bevare kvaliteten af relevante og nøjagtige data intakt.
Opbevaring
Siden digitaliseringen af verden i det 20. århundrede, kommer datasucces med at optage mindre lagerplads og mere information. Tidligere blev data gemt i mange store filer, de ustrukturerede data tager for meget lagerplads, at det nu er blevet en udfordring at håndtere alle disse ændringer.
Det tager meget tid at håndtere ustrukturerede data. Det tog for lang tid at udtrække information fra ustrukturerede data, når det kommer til, hvor meget dataene haster. Det er derfor, dataene tog for lang tid, og i hastende tilfælde er det meget svært at udtrække al viden fra dataene.
Siden digitaliseringens start er der kommet mange værktøjer til at håndtere udfordringerne ved ustruktureret dataudtræk. For at spare tid er den ustrukturerede dataudtrækning via AI-forbedret dataudtræksværktøjer ligesom Nanonets er meget pålidelig, fordi den giver grundig og helt relevant information til data. Dataens relevans er meget vigtig, fordi det er et vigtigt tidsbesparende værktøj for det arbejdende personale og analytikere. Med disse datastrategier kan man nemt fortolke værdifuld information fra dataene.
Hvordan kan du bruge Nanonets til at konvertere ustrukturerede data til indsigt?
Nanonets er en platform, der anvender AI-, ML- og NLP-teknikker til at hjælpe brugere med at få indsigt fra ustrukturerede data. Her er en forenklet trin-for-trin guide til, hvordan du opnår dette:
- Dataindsamling: Saml dine ustrukturerede data. Dette kan være i form af billeder, tekstfiler, PDF'er, videoer eller lydfiler.
- Upload til Nanonets: Upload dine ustrukturerede data til Nanonets-platformen ved hjælp af din konto. Du kan opret din her. Dette kan gøres direkte eller via API'er i appen.
- Vælg eller træne en model: Vælg nu en OCR-model baseret på det dokument, du uploader. Nanonets leverer fortrænede modeller til mange dokumenttyper. . Vælg en model, der passer til din datatype og målsætning. Hvis ingen af de fortrænede modeller passer til dine behov, kan du træne en tilpasset OCR-model ved hjælp af dine data.
- Anvend model til data: Når din model er klar, skal du anvende den på dine dokumenter. Modellen vil udtrække data fra dine dokumenter og konvertere dem til et struktureret format som tabel, excel, csv, som er lettere at læse.
- Gennemgå og juster: Tjek resultaterne fra modellens analyse. Hvis de ikke er nøjagtige nok, kan du finjustere modellen ved at bruge Nanonets træk og slip platform, indtil resultaterne opfylder dine behov.
- Uddrag indsigt: Brug endelig de strukturerede data til at udlede indsigt. Du kan eksportere dataene og udføre dataanalyse for at opnå indsigt.
Husk, at de specifikke trin kan variere baseret på den specifikke type ustrukturerede data og den indsigt, du ønsker at opnå. Nanonets kan automatisere processen med automatiserede arbejdsgange, kraftfuld OCR-software og kodefri brugergrænseflade.
Vi lever i en transformativ æra, hvor digitalisering forenkler virksomhedsvækst og beslutningstagning. Ustruktureret dataudtræk har strømlinet forskellige processer på grund af dens tidsbesparende og hurtige drift.
Ustrukturerede data, hovedsagelig råmateriale, behandles for at udtrække værdifuld information til nem opbevaring. Dens tabelform forbedrer tilgængeligheden. Dataforespørgsler er organiseret i brugervenlige, velstrukturerede former, blottet for tvetydighed, hvilket gør dem nemme at læse. Blandt de forskellige tilgængelige dataudtræksværktøjer bidrager hver især til systemeffektivitet og miljøforbedringer.
Ustruktureret dataudvinding er afgørende på tværs af brancher, og opretholder dataægtheden. For eksempel bruger banksektoren disse værktøjer til forretningsvækst.
I videnskabelig forskning kondenserer ustrukturerede dataekstraktionsværktøjer data til en mere præcis form, uanset om det er menneske- eller maskingenereret, hvilket giver værdifuld indsigt.
Virksomheder på tværs af brancher bruger ustrukturerede dataudtræksteknikker til at give mening i deres forretningsdokumenter og tilføje et ekstra lag af intelligens til deres analyser. Nedenstående figur viser fremkomsten af brugen af ustrukturerede data i forskellige brancher.
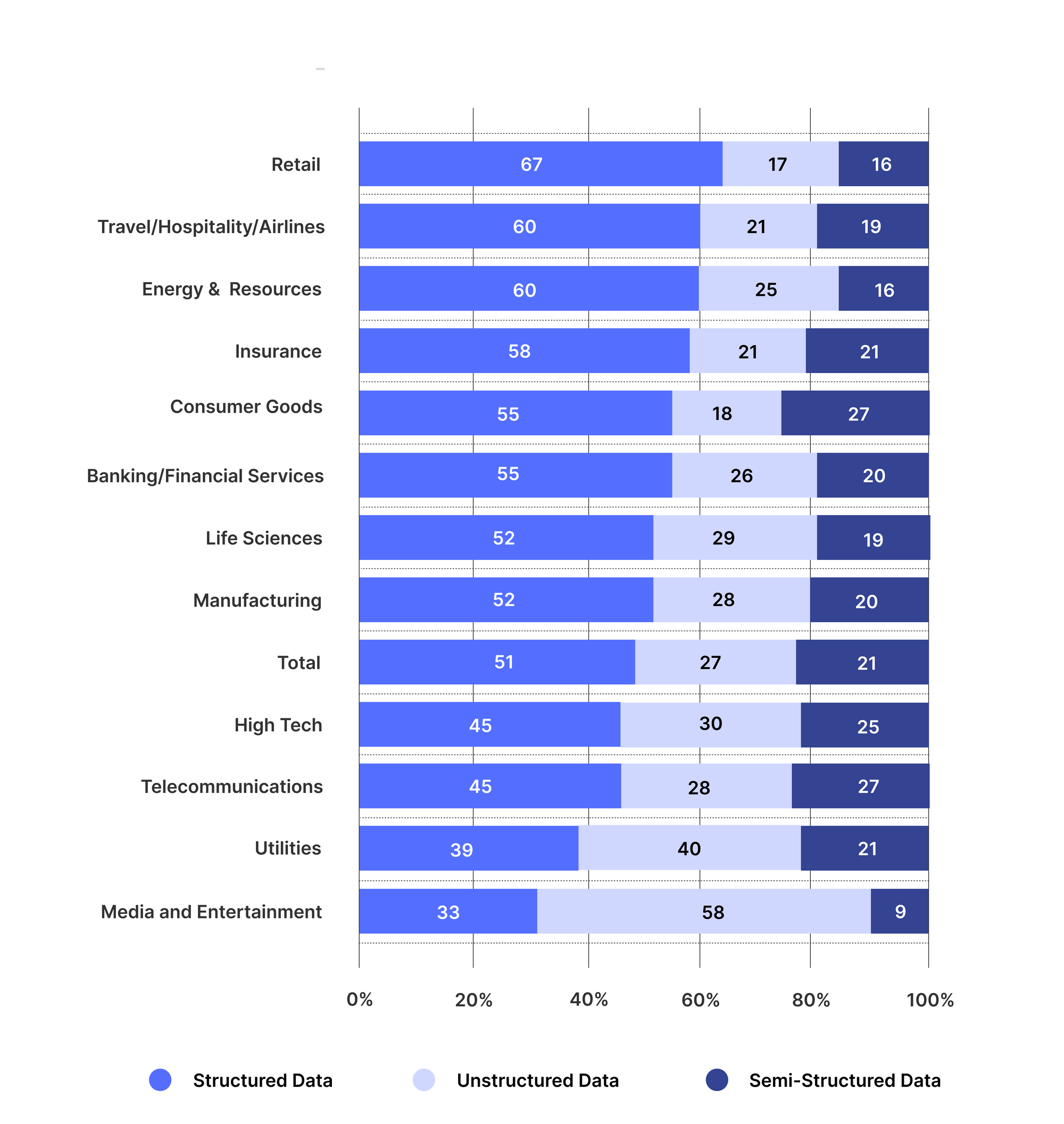
[Kilde: TCS undersøgelse]
Her er nogle eksempler på, hvordan forskellige industrier bruger intelligente dokumentbehandlingsplatforme som Nanonets til ustruktureret dataudtræk og forbedring af deres produktivitet.
Banker
Banker bruger IDP platforme at udtrække indsigt fra ustrukturerede datakilder som krav, kundeformularer, KYC-dokumenter, opkaldsregistre, økonomiske rapporter og mere.
Læs mere: RPA i bank , Bankautomatisering
Forsikring
Forsikring er en stærkt reguleret branche. Det skal udføre dokumentbekræftelse og identitetsbekræftelse ved hvert trin af forsikringskravsprocesser. Forsikringsselskaber bruger automatiserede dokumentbehandlingsplatforme til at automatisere skadesprocesser, risikostyring og andre funktioner, som er regelbaserede. Forsikringsskadeprocessen indeholder en masse ustrukturerede data. Ustruktureret dataudtræk ved at bruge AI-forbedrede platforme som Nanonets gør forsikringsskadeprocessen nem, da den giver mulighed for selektiv dataudtrækning fra billeder, PDF'er, videoer, lydfiler osv.
Læs mere: Forsikringsautomatisering, Forsikring OCRog RPA i forsikring
Helse
At levere exceptionel patientoplevelse handler om at yde bedre service, reducere patientens ventetider og sikre, at personalet ikke overanstrenges. Ved brug af IDP platform at udtrække indsigt fra ustrukturerede datakilder som stemme fra kundedata, patientundersøgelser, EPJ'er, kundeklager, lovgivningswebsteder og litteraturgennemgang hjælper Healthcare med at sikre en bedre patientoplevelse.
Læs mere: Sundhedsautomatisering , AI i sundhedsvæsenet
real Estate
Ejendomsselskaber beskæftiger sig med flere mennesker på samme tid som kunder, bygherrer, lejere, sælgere, konkurrenter og ejendomsejere. Brug af automatiseret dokumentbehandlingssoftware kan hjælpe ejendomsinstitutioner med at skabe rige profiler af nævnte interessenter og strømline dataudtræk fra ustrukturerede datakilder som lejekontrakter, kontrakter, ejendomsvurderingspapirer osv.
Konklusion
Data er den nye olie. Den virksomhed, der mestrer ustruktureret dataudtræk, kan frigøre det fulde potentiale af virksomhedsdata. Nanonetter giver virksomheder mulighed for at automatisere deres dokumentbehandling og kan smart udtrække data fra enhver form for dokumenter.
Nanonetter online OCR & OCR API har mange interessante brug sager that kunne optimere din virksomheds ydeevne, spare omkostninger og øge væksten. Finde ud af hvordan Nanonets' use cases kan gælde for dit produkt.
FAQ
Hvad er fordelene ved at bruge ustrukturerede data?
Ustrukturerede data er svære at forstå, fortolke og bruge direkte, men det er ikke det eneste ved det. Der er mange fordele ved at bruge ustrukturerede data, som nævnt nedenfor:
Intet fast format
Ustrukturerede data understøtter data i alle formater og størrelser. Enhver form for data, der ikke har en ordentlig rækkefølge, kan klassificeres som ustrukturerede data. Det kan være nyttigt at udvide horisonten for typer af data.
Intet skema
Som diskuteret ovenfor har ustrukturerede data ingen fast sekvens, og de har heller ikke noget fast skema. Det er det, der gør ustruktureret dataudtræk vanskelig for de fleste dele.
Fleksibilitet
Da ustrukturerede data ikke har nogen struktur, kan de have et hvilket som helst format. Dette gør det flydende med hensyn til struktur.
Bærbar og skalerbar
Ustrukturerede data er mere bærbare og skalerbare sammenlignet med semistrukturerede og strukturerede data.
Masser af forretningsapplikationer
I betragtning af at 80% af virksomhedens data er ustrukturerede, er der mange applikationer til disse data. Ustrukturerede virksomhedsdata bruges til en række forskellige forretningsanalyser. Eksempelvis præsentationer, virksomhedsvideoer, forståelse af kundeprofiler mv.
Hvordan konverterer man ustrukturerede data til strukturerede data?
Det kan være en hektisk opgave at arbejde med store og omfangsrige data. For at spare tid og for at bevare dataenes originalitet og nøjagtighed, bør den forkortes i en sådan grad, at der kun er den nødvendige information tilbage. Den ustrukturerede dataudtrækning har forskellige metoder, og dens betydning fremgår i høj grad af alle oplysningerne ovenfor. Forskellen mellem det strukturerede og ustrukturerede giver vigtige fingerpeg om dataene. Du kan bruge følgende trin til at konvertere ustrukturerede data til strukturerede data.
Trin 1: Hav et klart mål i tankerne
Intet projekt bør nogensinde starte uden at have et sæt målbare mål. Med en klar idé om slutmålet for, hvilken indsigt du ønsker at opnå, bliver det lettere at færdiggøre de næste trin.
Trin 2: Færdiggør datakilderne
Data er overalt. Men for at starte med konverteringen skal du identificere datakilderne for at tegne dine ustrukturerede data. Dataudtræksstrategier ville være forskellige for forskellige datakilder. Nanonetter giver brugerne mulighed for at indsamle data fra flere kilder som Gmail, drop box, outlook, desktop osv.
Dataene kan udtrækkes fra de store pdf-filer, billeder og andre tekstformer.
Trin 3: Standardisering af data
Det tredje trin er at vide, hvad man skal gøre med ustruktureret dataudtræk. Analytikeren bør have en idé om det endelige resultat af de ustrukturerede data.
Hvis du har valgt dataene, er næste trin at færdiggøre resultatet af dataene. Hvis dataene er i en variabel form, skal analytikeren standardisere dem, før nogen analyse kan udføres. Dette særlige trin involverer rensning og standardisering af dataformaterne til de næste trin.
Trin 4: Valg af dataekstraktionsteknologi:
Efter at have forstået datakilderne og metoden til standardisering af dataene, er det vigtigt at færdiggøre den software, du vil bruge til at implementere disse trin. IDP-platforme som Nanonets hjælper organisationer med at forbinde, udtrække data og standardisere dem til yderligere analyse.
Dataene vil blive taget af forskellig software, næste skridt er at finde den teknologi, som dataene vil blive overført til softwaren. Til dette formål anvendes et rationelt databasestyringssystem (RDBMS). Denne software og teknologi hjælper med at få let teknologibrug.
Trin 5: Valg af datalagringssystem
Datalagringssystemet vælges baseret på den type teknologi, du leder efter, det skal have høj tilgængelighed, højhastighedstid og andre funktioner. Alle disse funktioner sammen med lagringskapaciteten i realtid gør det høje lagringssystem.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://nanonets.com/blog/unstructured-data-extraction/
- :har
- :er
- :ikke
- :hvor
- 1
- 12
- 24
- 50
- 7
- a
- Om
- om det
- over
- adgang
- tilgængelighed
- Konto
- nøjagtighed
- præcis
- opnå
- tværs
- faktisk
- tilføje
- justerbar
- Justeret
- fordele
- advent
- AI
- Alexa
- Alle
- tillade
- tillader
- sammen
- også
- helt
- tvetydigheden
- blandt
- an
- analyse
- analytiker
- Analytikere
- analytics
- ,
- En anden
- enhver
- API'er
- app
- applikationer
- Indløs
- ER
- omkring
- anbragt
- AS
- At
- tiltrækker
- lyd
- Godkendelse
- ægthed
- automatisere
- Automatiseret
- tilgængelighed
- til rådighed
- tilbage
- Bank
- banksektoren
- Banker
- baseret
- BE
- fordi
- bliver
- bliver
- før
- være
- jf. nedenstående
- BEDSTE
- Bedre
- mellem
- Big
- Største
- boost
- både
- Boks
- bygherrer
- virksomhed
- forretningsresultater
- virksomheder
- men
- by
- ringe
- kaldet
- CAN
- Kapacitet
- bil
- tilfælde
- Århundrede
- udfordre
- udfordringer
- Ændringer
- kanaler
- kontrollere
- Vælg
- fordringer
- klassificeret
- Rengøring
- klar
- Luk
- Cloud
- kode
- indsamler
- indsamler
- KOM
- Kom
- kommer
- kommunikere
- Virksomheder
- selskab
- sammenlignet
- konkurrenter
- klager
- fuldstændig
- komplekse
- sammensat
- omfatter
- konklusion
- Tilslut
- indeholder
- kontrakter
- Konvertering
- konvertere
- Omkostninger
- kunne
- skabe
- afgørende
- skik
- kunde
- kundedata
- Kunder
- data
- Dataanalyse
- data opbevaring
- Database
- dag
- deal
- Beslutningstagning
- dyb
- dyb dykke
- definerede
- desktop
- detail
- detaljer
- bestemmer
- enhed
- Enheder
- forskel
- forskelle
- forskellige
- svært
- digital
- digital verden
- digitalisering
- direkte
- drøftet
- do
- dokumentet
- dokumenter
- gør
- færdig
- tegne
- Drop
- grund
- hver
- lette
- lettere
- nemt
- let
- effektivitet
- enten
- emails
- beskæftiger
- krypteret
- ende
- Forbedrer
- styrke
- nok
- sikre
- sikring
- Enterprise
- virksomheder
- miljømæssige
- Era
- væsentlige
- ejendom
- etc.
- Ether (ETH)
- NOGENSINDE
- Hver
- eksempel
- eksempler
- Excel
- enestående
- Udvid
- erfaring
- eksport
- ekstra
- ekstrakt
- udvinding
- konfronteret
- fakta
- FAST
- Funktionalitet
- Figur
- File (Felt)
- Filer
- fyldt
- endelige
- færdiggøre
- Endelig
- finansielle
- Finde
- firmaer
- Fornavn
- fast
- væske
- fokuserede
- følger
- efter
- følger
- Til
- Forbes
- formular
- format
- formularer
- fra
- fuld
- funktioner
- yderligere
- samle
- generere
- få
- gif
- Giv
- gmail
- mål
- Mål
- Google Startside
- Vækst
- vejlede
- Hård Ost
- Have
- have
- Helse
- sundhedspleje
- stærkt
- hjælpe
- hjælper
- link.
- Høj
- stærkt
- Home
- horisont
- Hvordan
- How To
- http
- HTTPS
- menneskelig
- idé
- identificere
- Identity
- Identitetsbekræftelse
- if
- billede
- billeder
- gennemføre
- vigtigt
- in
- forkert
- industrier
- industrien
- oplysninger
- indsigt
- instans
- institutioner
- forsikring
- Intelligens
- Intelligent
- Intelligent dokumentbehandling
- interagere
- interesse
- interessant
- grænseflade
- Internet
- tingenes internet
- ind
- tingenes internet
- iot-enheder
- uanset
- IT
- ITS
- Venlig
- Kend
- viden
- KYC
- stor
- lag
- til venstre
- mindre
- ligesom
- litteratur
- levende
- Lang
- Se
- leder
- Lot
- vedligeholde
- større
- lave
- maerker
- Making
- ledelse
- styringssystem
- mange
- materiale
- Mød
- nævnte
- beskeder
- metode
- metoder
- måske
- ML
- model
- modeller
- overvågning
- mere
- mest
- meget
- multimedie
- flere
- Musik
- nødvendig
- Behov
- behov
- Ny
- næste
- NLP
- ingen
- nu
- objektiv
- opnå
- OCR
- OCR-software
- of
- tilbyde
- tit
- Olie
- on
- engang
- ONE
- online
- Online virksomheder
- kun
- drift
- Optimer
- or
- ordrer
- ordrer
- organisation
- organisationer
- Organiseret
- originalitet
- Andet
- Andre
- Resultat
- Outlook
- ejere
- papirbaseret
- papirer
- særlig
- dele
- forbi
- patient
- Mønster
- Mennesker
- udføre
- ydeevne
- fysisk
- Billeder
- perron
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- punkter
- mulig
- potentiale
- vigtigste
- brug
- foretrækkes
- præsentere
- Præsentationer
- gaver
- primære
- sandsynligvis
- behandle
- Processer
- forarbejdning
- Produkt
- produktivitet
- Profiler
- projekt
- passende
- ejendom
- forudsat
- giver
- leverer
- formål
- kvalitet
- forespørgsler
- hurtigere
- quintillion
- rationel
- Raw
- RE
- Læs
- klar
- ægte
- fast ejendom
- realtid
- virkelig
- genkende
- optegnelser
- Rød
- reducere
- fast
- reguleret
- lovgivningsmæssige
- relevans
- relevant
- pålidelig
- resterne
- Lej
- Rapporter
- kræver
- påkrævet
- forskning
- reaktioner
- resultere
- Resultater
- afsløre
- gennemgå
- Rich
- Risiko
- risikostyring
- groft
- s
- samme
- Gem
- besparelse
- skalerbar
- spredt
- Ordningen
- Videnskabelig undersøgelse
- Søg
- Anden
- sektor
- se
- set
- valgt
- udvælgelse
- selektiv
- send
- afsendelse
- sender
- forstand
- følsom
- Sequence
- tjeneste
- sæt
- Kort
- forkortes
- bør
- vist
- Shows
- betydning
- signifikant
- lignende
- forenklet
- Størrelse
- størrelser
- So
- Software
- nogle
- Kilde
- Kilder
- specifikke
- Personale
- interessenter
- standardisering
- starte
- Trin
- Steps
- Stadig
- opbevaring
- ligetil
- strategier
- strømline
- strømlinet
- struktur
- struktureret
- strukturerede og ustrukturerede data
- Studere
- succes
- sådan
- Dragt
- Understøtter
- overraskende
- Omkringliggende
- Kortlægge
- systemet
- bord
- Tag
- tager
- tager
- Opgaver
- teknikker
- Teknologier
- vilkår
- end
- at
- oplysninger
- verdenen
- deres
- Them
- Der.
- derfor
- Disse
- de
- ting
- ting
- tror
- Tredje
- denne
- hele
- tid
- tidskrævende
- gange
- til
- også
- tog
- værktøj
- værktøjer
- Trafik
- Tog
- overført
- transformative
- prøv
- to
- typen
- typer
- forstå
- forståelse
- I modsætning til
- låse
- indtil
- up-to-date
- Uploading
- haster
- brug
- anvendte
- Bruger
- Brugergrænseflade
- brugervenlig
- brugere
- ved brug af
- udnytter
- Værdifuld
- Værdifuld information
- Værdiansættelse
- række
- forskellige
- leverandører
- Verifikation
- meget
- via
- video
- Videoer
- Voice
- vente
- ønsker
- var
- Vej..
- we
- websites
- Hvad
- Hvad er
- hvornår
- hvorvidt
- som
- mens
- hvorfor
- bredt
- vilje
- med
- uden
- ord
- arbejdsgange
- arbejder
- world
- ville
- skriftlig
- dig
- Din
- zephyrnet