Automatiseret dataanalyse (ADA) på AWS er en AWS-løsning, der gør dig i stand til at udlede meningsfuld indsigt fra data på få minutter gennem en enkel og intuitiv brugergrænseflade. ADA tilbyder en AWS-native dataanalyseplatform, der er klar til brug ud af boksen af dataanalytikere til en række forskellige use cases. Med ADA kan teams indtage, transformere, styre og forespørge på forskellige datasæt fra en række datakilder uden at kræve specialtekniske færdigheder. ADA giver et sæt af forudbyggede stik at indtage data fra en lang række kilder, herunder Amazon Simple Storage Service (Amazon S3), Amazon Kinesis datastrømme, amazoncloudwatch, Amazon CloudTrailog Amazon DynamoDB samt mange andre.
ADA leverer en grundlæggende platform, der kan bruges af dataanalytikere i en række forskellige brugssager, herunder IT, økonomi, marketing, salg og sikkerhed. ADA's out-of-the-box CloudWatch-dataconnector tillader dataindtagelse fra CloudWatch-logfiler på den samme AWS-konto, som ADA er blevet implementeret på, eller fra en anden AWS-konto.
I dette indlæg demonstrerer vi, hvordan en applikationsudvikler eller applikationstester er i stand til at bruge ADA til at udlede operationel indsigt i applikationer, der kører i AWS. Vi demonstrerer også, hvordan du kan bruge ADA-løsningen til at oprette forbindelse til forskellige datakilder i AWS. Vi først implementere ADA-løsningen ind på en AWS-konto og opsætte ADA-løsningen ved at oprette dataprodukter ved hjælp af datastik. Vi bruger derefter ADA Query Workbench til at forbinde de separate datasæt og forespørge de korrelerede data ved hjælp af velkendte Structured Query Language (SQL), for at få indsigt. Vi demonstrerer også, hvordan ADA kan integreres med business intelligence (BI) værktøjer såsom Tableau for at visualisere dataene og til at opbygge rapporter.
Løsningsoversigt
I dette afsnit præsenterer vi løsningsarkitekturen for demoen og forklarer arbejdsgangen. Med henblik på demonstration simuleres den skræddersyede applikation ved hjælp af en AWS Lambda funktion, der udsender logs ind Apache-logformat med et forudindstillet interval vha Amazon Eventbridge. Dette standardformat kan produceres af mange forskellige webservere og læses af mange loganalyseprogrammer. Applikationsloggene (Lambda-funktion) sendes til en CloudWatch-loggruppe. De historiske applikationslogfiler gemmes i en S3-bøtte til reference og til forespørgselsformål. En opslagstabel med en liste over HTTP-statuskoder sammen med beskrivelserne er gemt i en DynamoDB-tabel. Disse tre tjener som kilder, hvorfra data indlæses i ADA til korrelation, forespørgsel og analyse. Vi implementere ADA-løsningen ind på en AWS-konto og opsætte ADA. Så skaber vi dataprodukter inden for ADA for CloudWatch-loggruppe, S3 spandog DynamoDB. Efterhånden som dataprodukterne konfigureres, sørger ADA for datapipelines for at indtage dataene fra kilderne. Med ADA Query Workbench kan du forespørge de indlæste data ved hjælp af almindelig SQL til applikationsfejlfinding eller problemdiagnose.
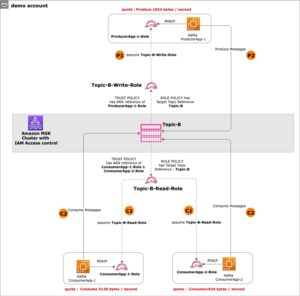
Følgende diagram giver et overblik over arkitekturen og arbejdsgangen ved at bruge ADA til at få indsigt i applikationslogfiler.
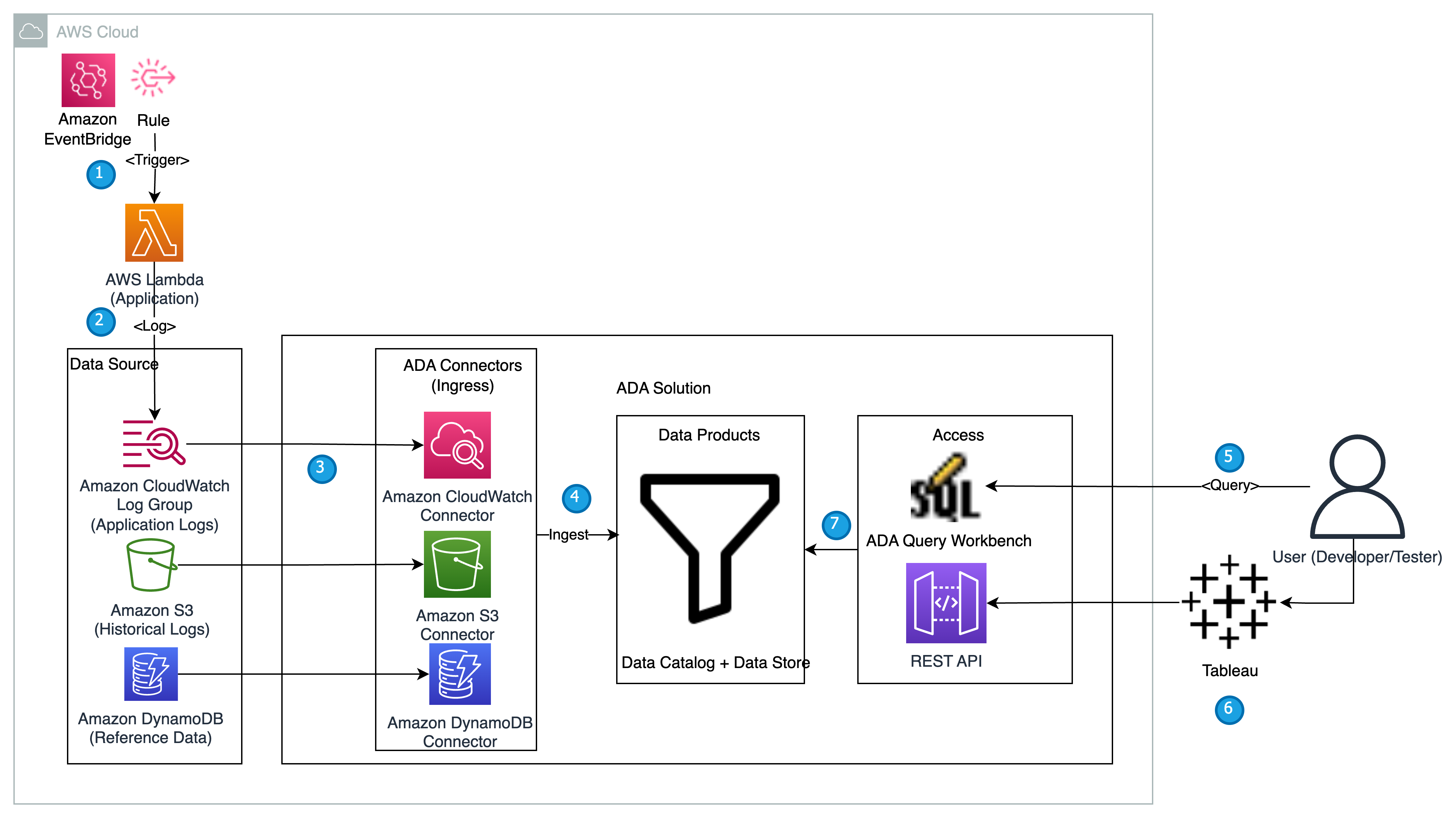
Arbejdsgangen omfatter følgende trin:
- En Lambda-funktion er planlagt til at blive udløst med 2-minutters intervaller ved hjælp af EventBridge.
- Lambda-funktionen udsender logfiler, der er gemt i en specificeret CloudWatch-loggruppe under
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Applikationslogfilerne genereres ved hjælp af Apache Log Format-skemaet, men gemmes i CloudWatch-loggruppen i JSON-format. - Dataprodukterne til CloudWatch, Amazon S3 og DynamoDB er oprettet i ADA. CloudWatch-dataproduktet forbinder til CloudWatch-loggruppen, hvor applikationsloggene (Lambda-funktion) gemmes. Amazon S3-stikket forbindes til en S3-bøttemappe, hvor de historiske logfiler er gemt. DynamoDB-stikket opretter forbindelse til en DynamoDB-tabel, hvor de statuskoder, der henvises til af applikationen, og historiske logfiler gemmes.
- For hvert af dataprodukterne implementerer ADA datapipeline-infrastrukturen for at indlæse data fra kilderne. Når dataindlæsningen er fuldført, kan du skrive forespørgsler ved hjælp af SQL via ADA Query Workbench.
- Du kan logge ind på ADA-portalen og komponere SQL-forespørgsler fra Query Workbench for at få indsigt i applikationsloggene. Du kan valgfrit gemme forespørgslen og dele forespørgslen med andre ADA-brugere på samme domæne. ADA-forespørgselsfunktionen er drevet af Amazonas Athena, som er en serverløs, interaktiv analysetjeneste, der giver en forenklet, fleksibel måde at analysere petabytes af data på.
- Tableau er konfigureret til at få adgang til ADA-dataprodukterne via ADA-udgående slutpunkter. Du opretter derefter et dashboard med to diagrammer. Det første diagram er et varmekort, der viser forekomsten af HTTP-fejlkoder korreleret med applikationens API-endepunkter. Det andet diagram er et søjlediagram, der viser de 10 bedste applikations-API'er med et samlet antal HTTP-fejlkoder fra de historiske data.
Forudsætninger
For dette indlæg skal du opfylde følgende forudsætninger:
- Installer AWS kommandolinjegrænseflade (AWS CLI), AWS Cloud Development Kit (AWS CDK) forudsætninger, TypeScript-specifik forudsætningerog git.
- Implementer ADA-løsningen på din AWS-konto i
us-east-1Område.- Angiv en administrator-e-mail, mens du starter ADA AWS CloudFormation stak. Dette er nødvendigt for at ADA kan sende root-brugeradgangskoden. Der kræves et admin-telefonnummer for at modtage en engangsadgangskodebesked, hvis multi-factor authentication (MFA) er aktiveret. For denne demo er MFA ikke aktiveret.
- Byg og implementer eksempelapplikationen (tilgængelig på GitHub repo) løsning, så følgende ressourcer kan leveres på din konto i
us-east-1Region:- En Lambda-funktion, der simulerer logningsapplikationen, og en EventBridge-regel, der aktiverer applikationsfunktionen med 2 minutters intervaller.
- En S3-bucket med de relevante bucket-politikker og en CSV-fil, der indeholder de historiske applikationslogfiler.
- En DynamoDB-tabel med opslagsdataene.
- Relevant AWS identitets- og adgangsstyring (IAM) roller og tilladelser, der kræves for tjenesterne.
- Installer eventuelt Tableau skrivebord, en tredjeparts BI-udbyder. Til dette indlæg bruger vi Tableau Desktop version 2021.2. Der er en omkostning involveret i at bruge en licenseret version af Tableau Desktop-applikationen. For yderligere detaljer henvises til Tableau licensering information.
Implementer og opsæt ADA
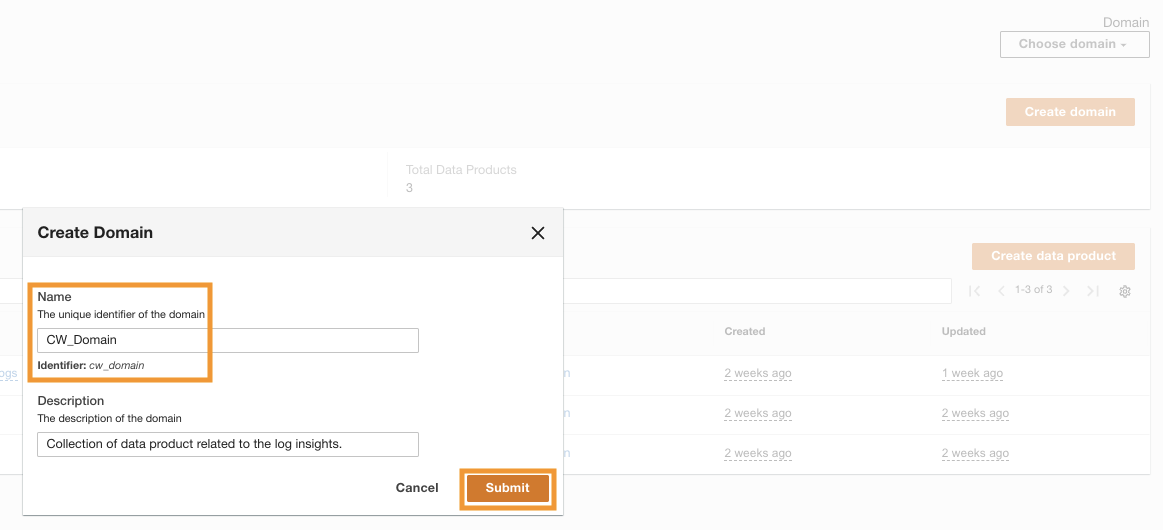
Når ADA er implementeret med succes, kan du logge ind ved hjælp af den admin-e-mail, der blev angivet under installationen. Du opretter derefter en domæne som hedder CW_Domain. Et domæne er en brugerdefineret samling af dataprodukter. Et domæne kan for eksempel være et team eller et projekt. Domæner giver en struktureret måde for brugere at organisere deres dataprodukter og administrere adgangstilladelser.
- På ADA-konsollen skal du vælge domæner i navigationsruden.
- Vælg Opret domæne.
- Indtast et navn (
CW_Domain) og beskrivelse, og vælg derefter Indsend.
Konfigurer prøveapplikationsinfrastrukturen ved hjælp af AWS CDK
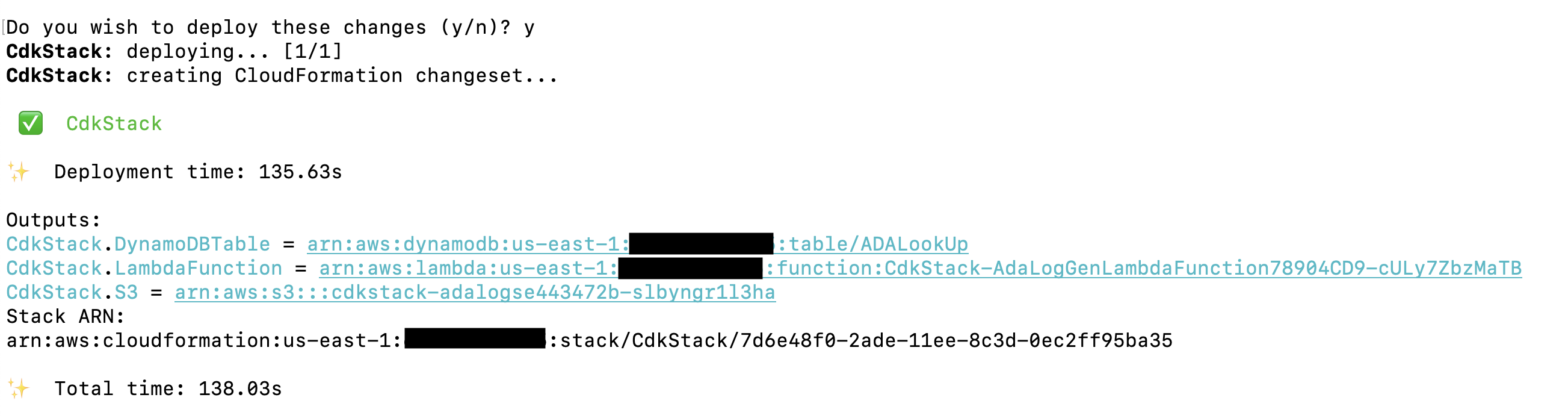
AWS CDK-løsningen, der implementerer demoapplikationen, er hostet på GitHub. Trinene til at klone repoen og konfigurere AWS CDK-projektet er beskrevet i dette afsnit. Før du kører disse kommandoer, skal du sørge for at konfigurere dine AWS-legitimationsoplysninger. Opret en mappe, åbn terminalen, og naviger til den mappe, hvor AWS CDK-løsningen skal installeres. Kør følgende kode:
Disse trin udfører følgende handlinger:
- Installer biblioteksafhængighederne
- Byg projektet
- Generer en gyldig CloudFormation-skabelon
- Implementer stakken ved hjælp af AWS CloudFormation på din AWS-konto
Implementeringen tager omkring 1-2 minutter og opretter DynamoDB-opslagstabellen, Lambda-funktionen og S3-bøtten, der indeholder de historiske logfiler som output. Kopier disse værdier til et tekstredigeringsprogram, såsom Notesblok.
Opret ADA-dataprodukter
Vi opretter tre forskellige dataprodukter til denne demo, et for hver datakilde, som du vil forespørge på for at få operationel indsigt. Et dataprodukt er et datasæt (en samling af data såsom en tabel eller en CSV-fil), som er blevet importeret til ADA, og som kan forespørges.
Opret et CloudWatch-dataprodukt
Først opretter vi et dataprodukt til applikationsloggene ved at konfigurere ADA til at indtage CloudWatch-loggruppen for prøveapplikationen (Lambda-funktion). Brug CdkStack.LambdaFunction output for at få Lambda-funktionen ARN og finde den tilsvarende CloudWatch-loggruppe ARN på CloudWatch-konsollen.
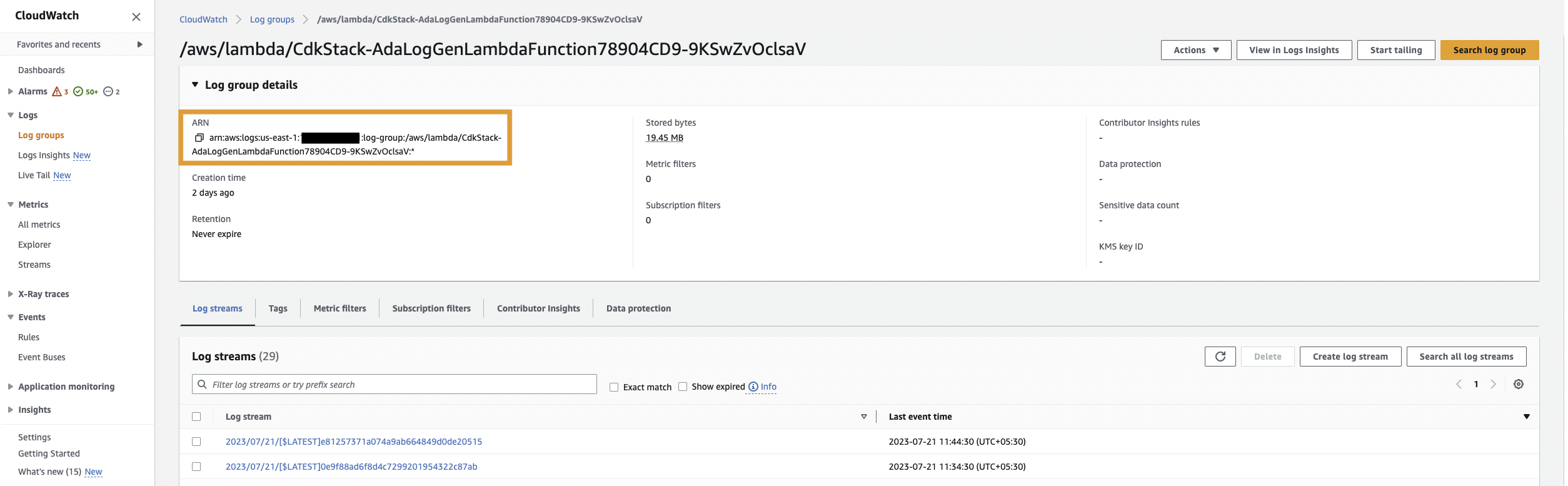
Udfør derefter følgende trin:
- På ADA-konsollen skal du navigere til ADA-domænet og oprette et CloudWatch-dataprodukt.
- Til Navn¸ indtast et navn.
- Til Kildetype, vælge amazoncloudwatch.
- Deaktiver Automatisk PII.
ADA har en funktion, der automatisk registrerer personligt identificerbare oplysninger (PII) data under import, som er aktiveret som standard. For denne demo deaktiverer vi denne mulighed for dataproduktet, fordi opdagelsen af PII-data ikke er inden for rammerne af denne demo.
- Vælg Næste.
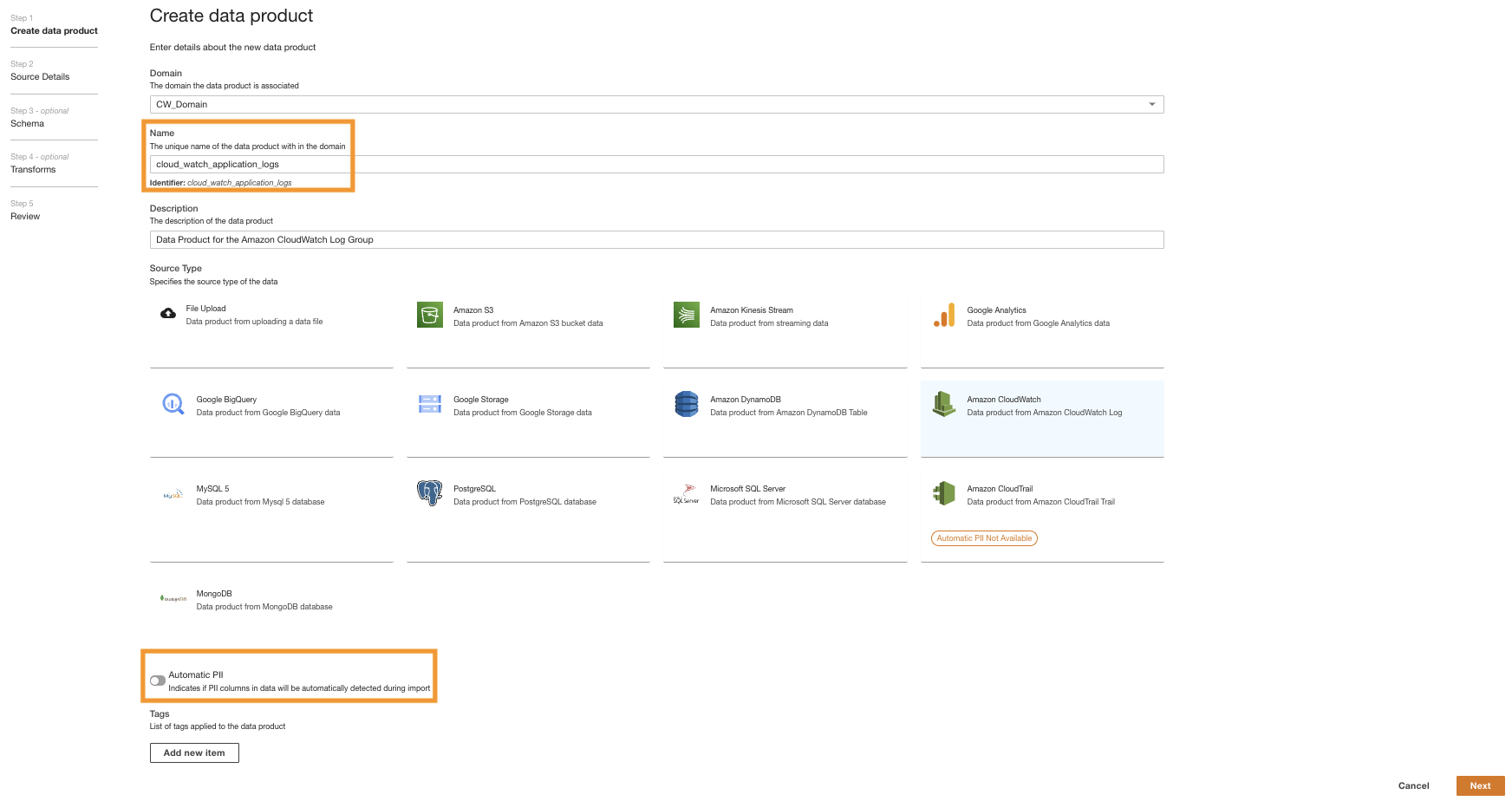
- Søg efter og vælg CloudWatch-loggruppen ARN, der er kopieret fra det forrige trin.

- Kopier loggruppen ARN.
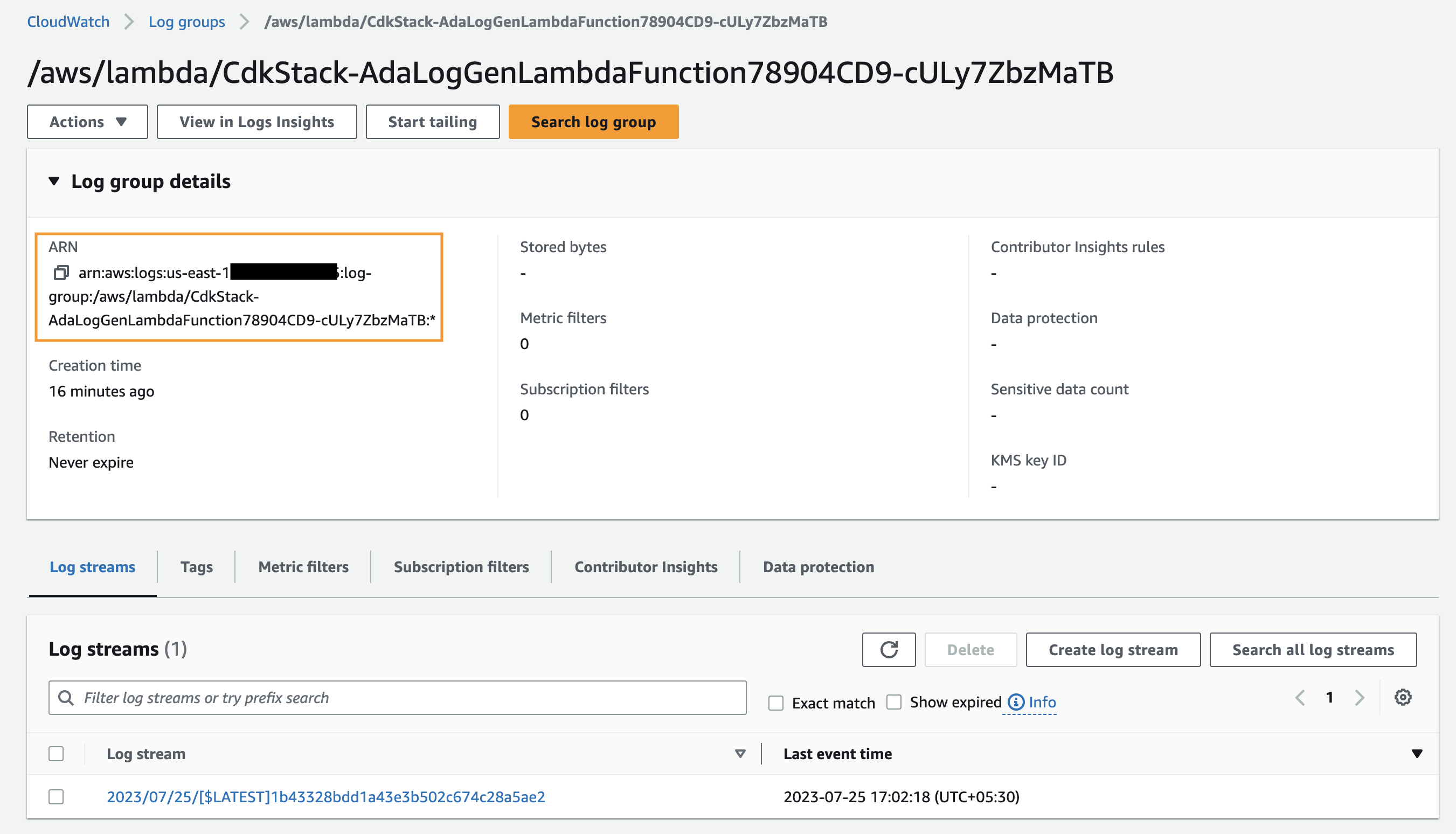
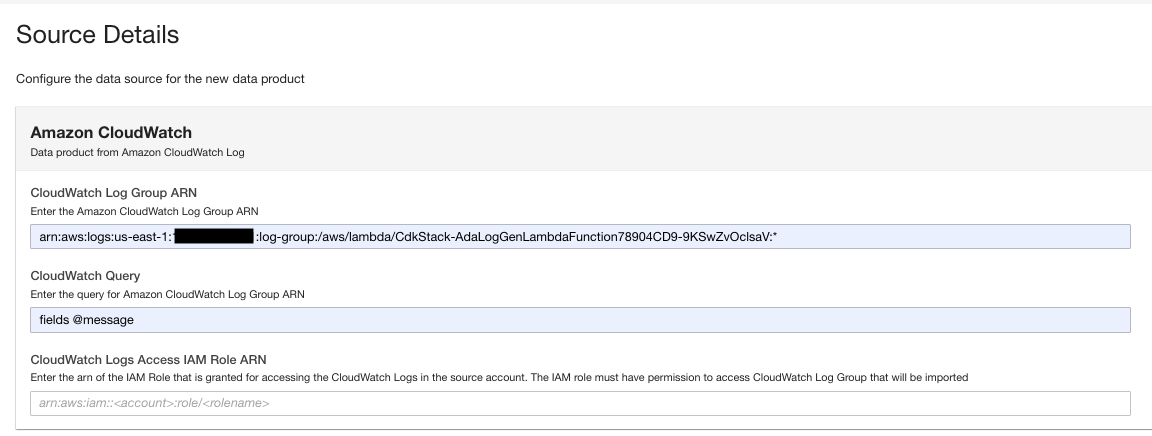
- Indtast loggruppen ARN på dataproduktsiden.
- Til CloudWatch-forespørgsel, indtast en forespørgsel, som du ønsker, at ADA skal hente fra loggruppen.
I denne demo forespørger vi i @message-feltet, fordi vi er interesserede i at få applikationslogfilerne fra loggruppen.
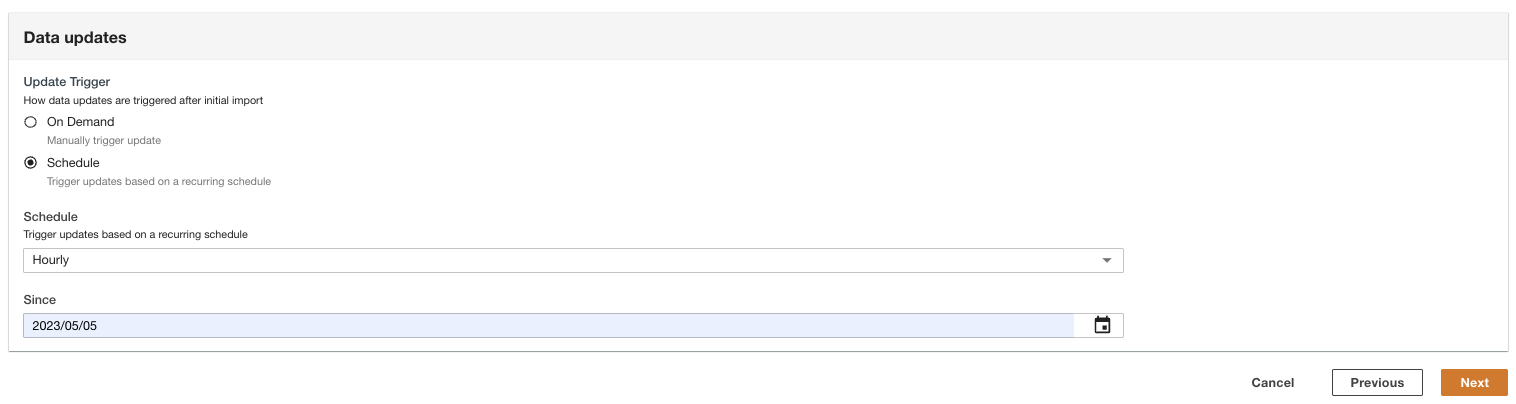
- Vælg, hvordan dataopdateringerne udløses efter den første import.
ADA kan konfigureres til at indtage data fra kilden med fleksible intervaller (op til 15 minutter eller senere) eller efter behov. Til demoen indstiller vi dataopdateringerne til at køre hver time.
- Vælg Næste.
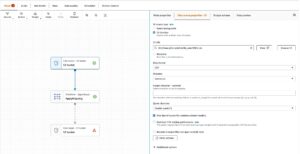
Dernæst vil ADA oprette forbindelse til loggruppen og forespørge efter skemaet. Fordi logfilerne er i Apache Log Format, omdanner vi logfilerne til separate felter, så vi kan køre forespørgsler på de specifikke logfelter. ADA giver fire standard transformationer og understøtter tilpasset transformation gennem et Python-script. I denne demo kører vi et brugerdefineret Python-script for at transformere JSON-meddelelsesfeltet til Apache-logformatfelter.
- Vælg Transformer skema.
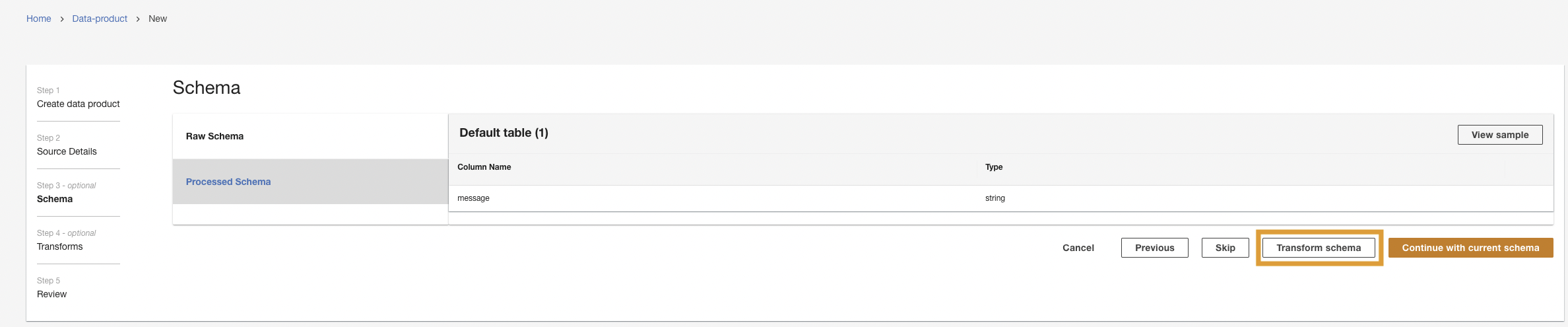
- Vælg Opret ny transformation.
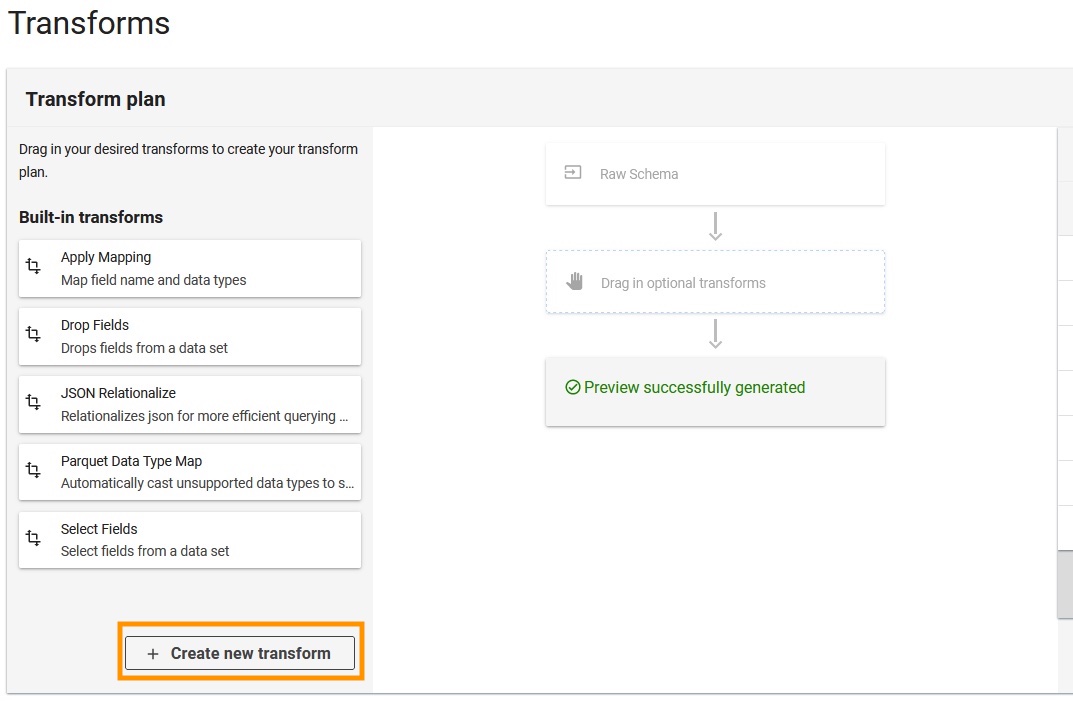
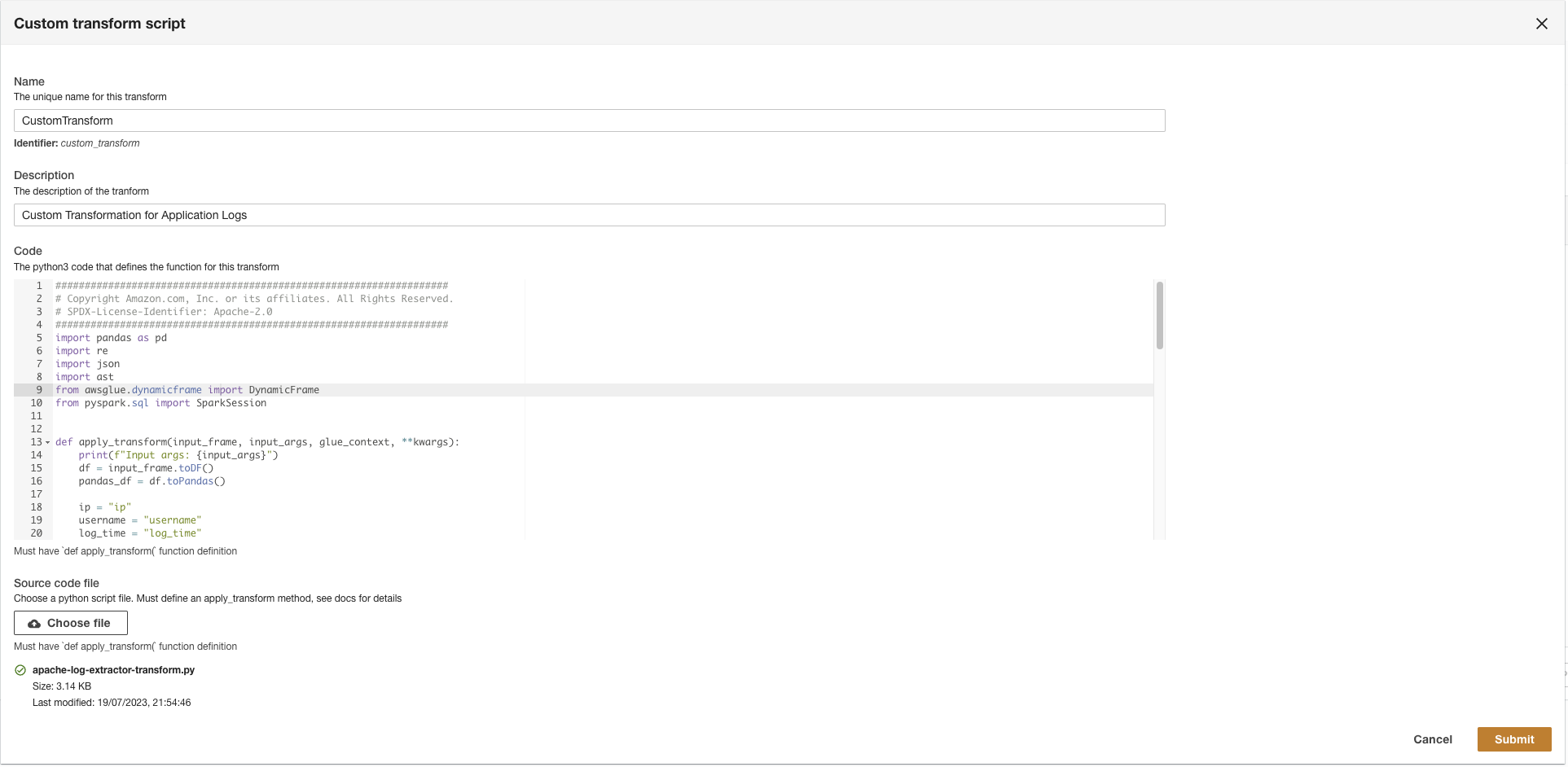
- Upload
apache-log-extractor-transform.pymanuskript fra/asset/transform_logs/mappe. - Vælg Indsend.
ADA vil transformere CloudWatch-logfilerne ved hjælp af scriptet og præsentere det behandlede skema.
- Vælg Næste.
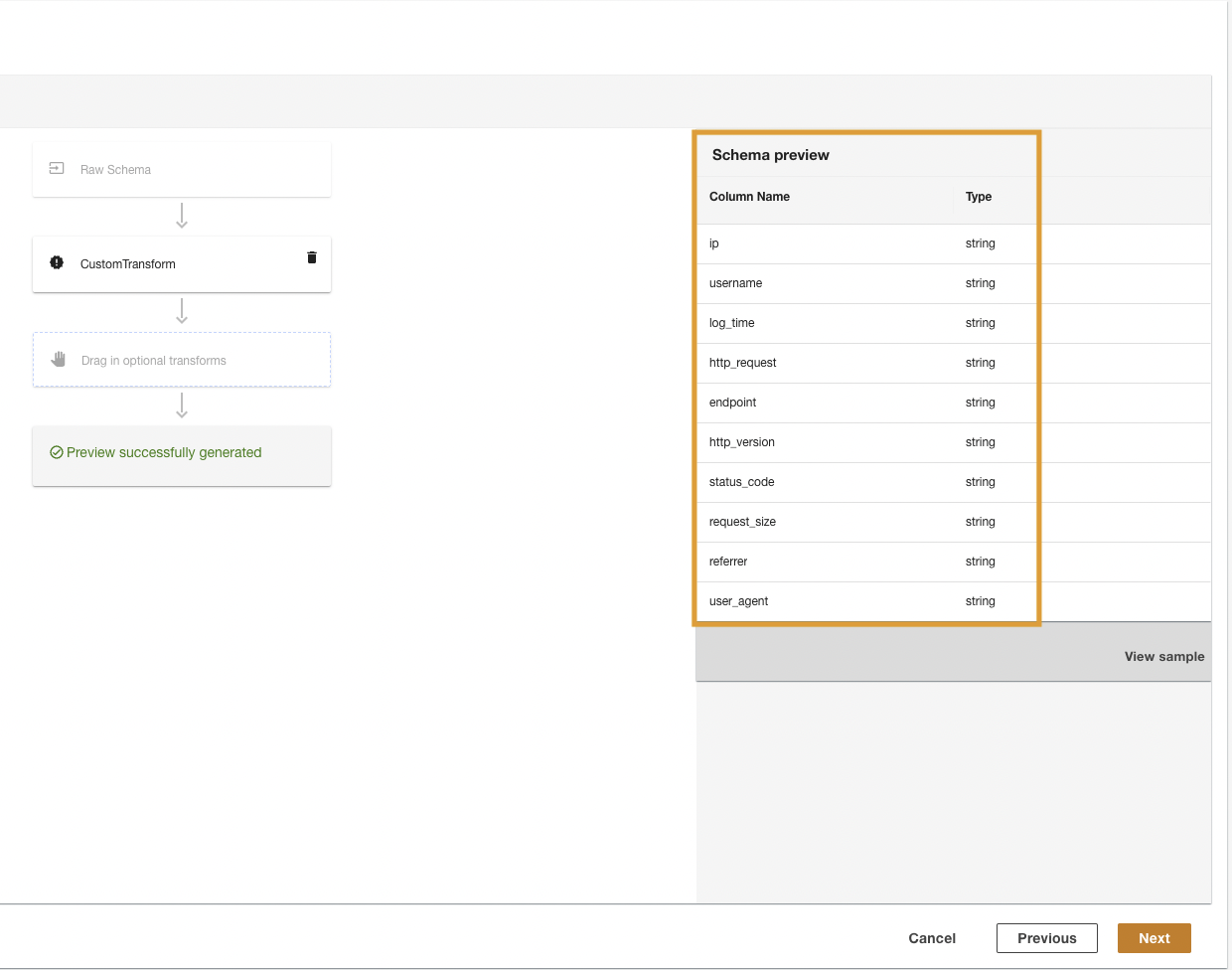
- I det sidste trin skal du gennemgå trinene og vælge Indsend.
ADA vil starte databehandlingen, oprette datapipelines og forberede CloudWatch-loggrupperne til at blive forespurgt fra Query Workbench. Denne proces vil tage et par minutter at fuldføre og vil blive vist på ADA-konsollen under Dataprodukter.
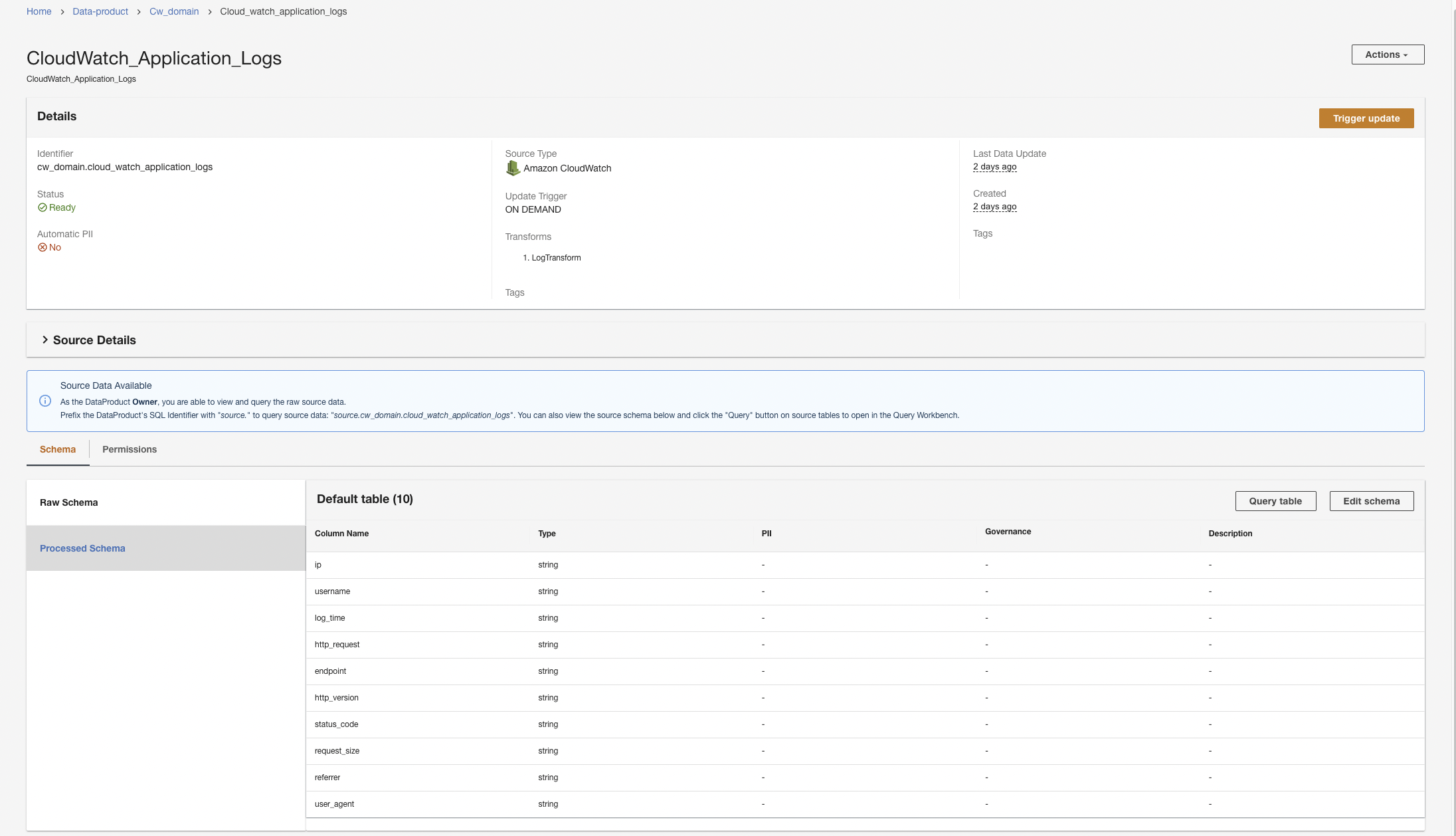
Opret et Amazon S3-dataprodukt
Vi gentager trinene for at tilføje de historiske logfiler fra Amazon S3-datakilden og slå referencedata op fra DynamoDB-tabellen. For disse to datakilder opretter vi ikke tilpassede transformationer, fordi dataformaterne er i CSV (for historiske logfiler) og nøgleattributter (til referenceopslagsdata).
- Opret et nyt dataprodukt på ADA-konsollen.
- Indtast et navn (
hist_logs) og vælg Amazon S3.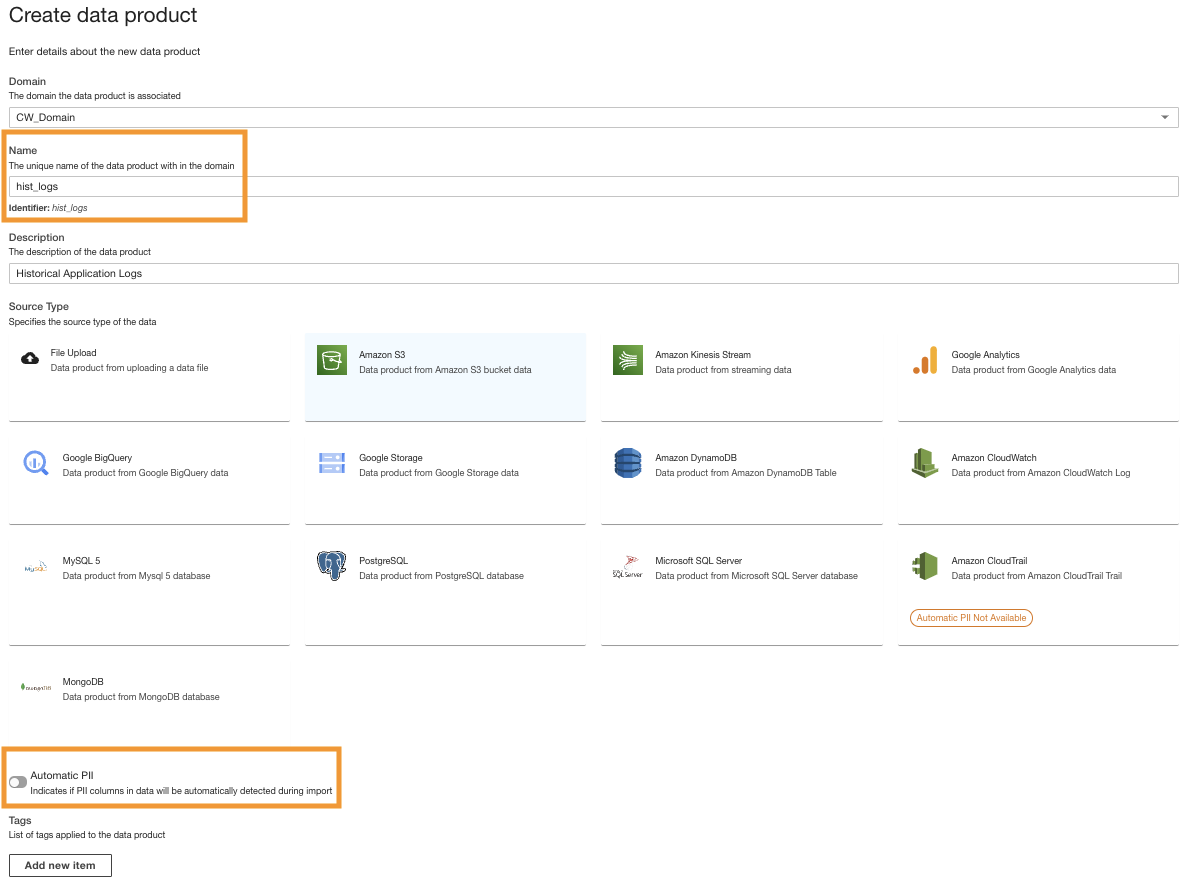
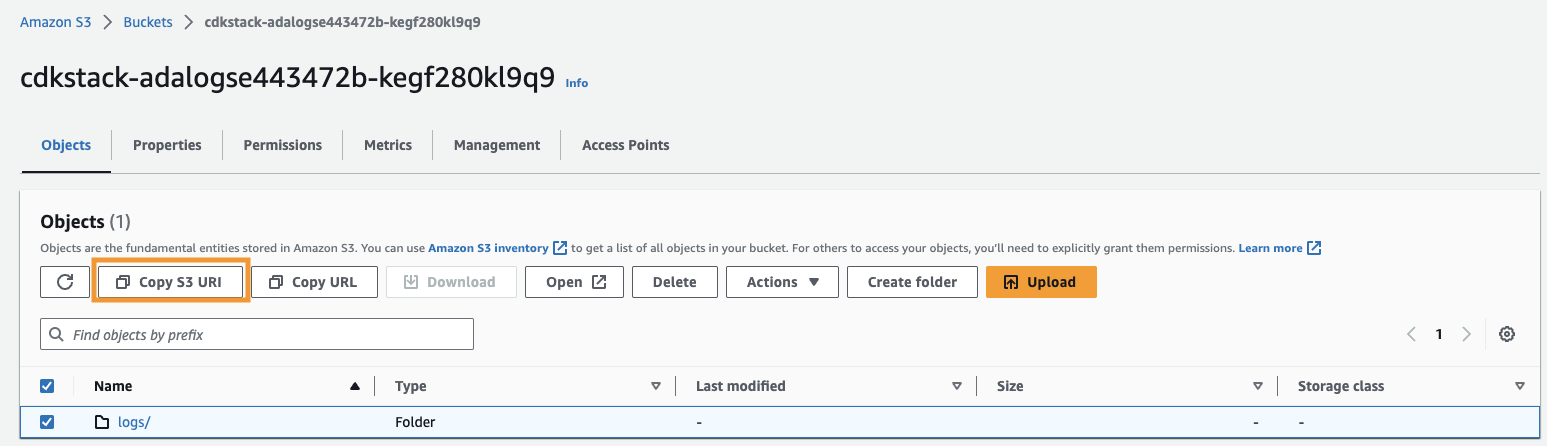
- Kopier Amazon S3 URI (teksten efter
arn:aws:s3:::) FraCdkStack.S3outputvariabel og naviger til Amazon S3-konsollen. - Indtast den kopierede tekst i søgefeltet, åbn S3-bøtten, vælg
/logsmappe, og vælg Kopier S3 URI.
De historiske logfiler er gemt i denne sti.
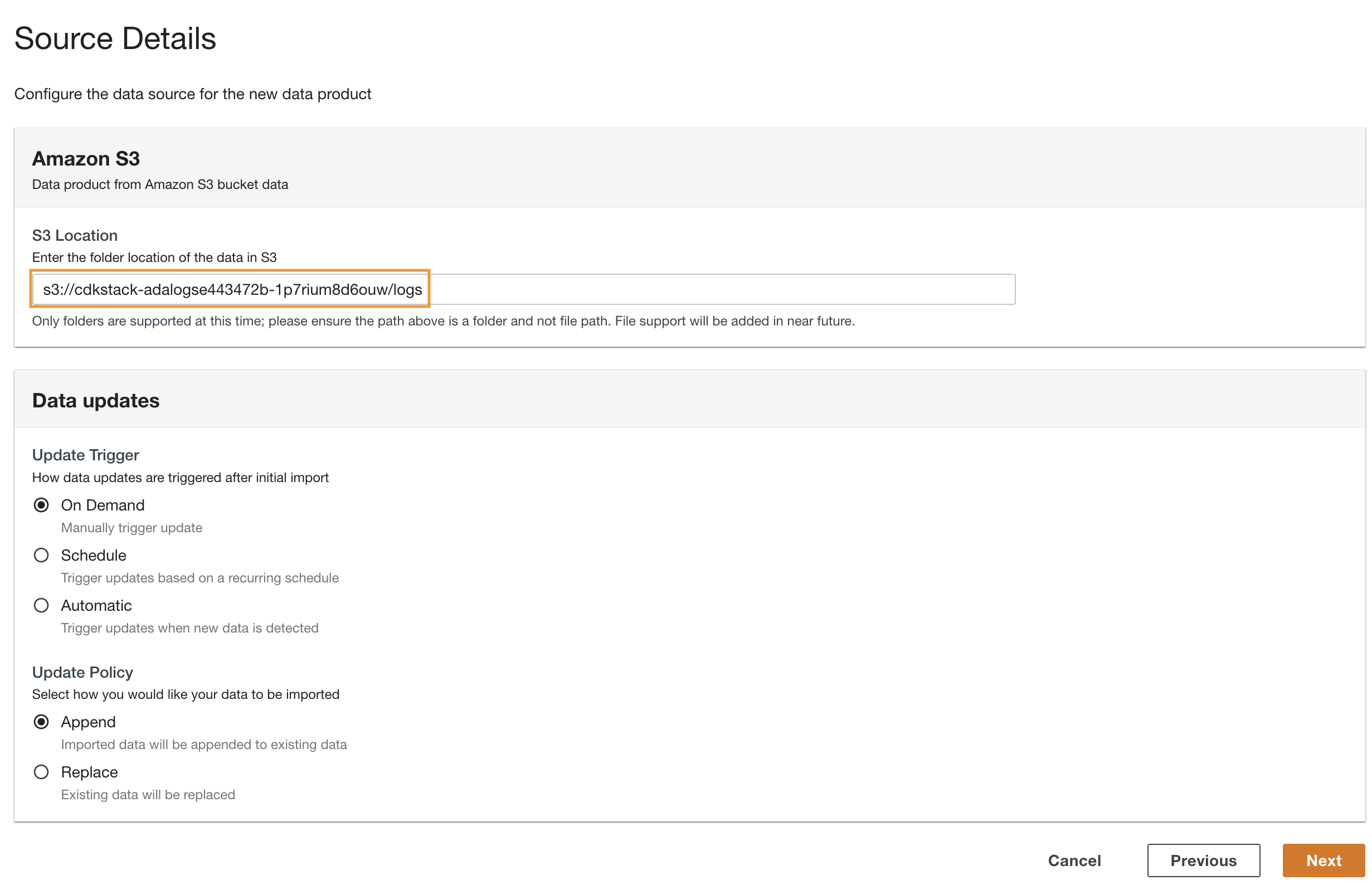
- Naviger tilbage til ADA-konsollen og indtast den kopierede S3 URI for S3 placering.
- Til Opdater trigger, Vælg On demand fordi de historiske logfiler opdateres med en uspecificeret frekvens.
- Til Opdater politik, Vælg Tilføj for at tilføje nyligt importerede data til de eksisterende data.
- Vælg Næste.
ADA behandler skemaet for filerne i den valgte mappesti. Fordi logfilerne er i CSV-format, er ADA i stand til at læse kolonnenavnene uden at kræve yderligere transformationer. Dog kolonnerne status_code , request_size udledes som lang type af ADA. Vi ønsker at holde kolonnedatatyperne konsistente blandt dataprodukterne, så vi kan tilslutte datatabellerne og forespørge dataene. Kolonnen status_code vil blive brugt til at oprette joinforbindelser på tværs af datatabellerne.
- Vælg Transformer skema for at ændre datatyperne for de to kolonner til strengdatatype.
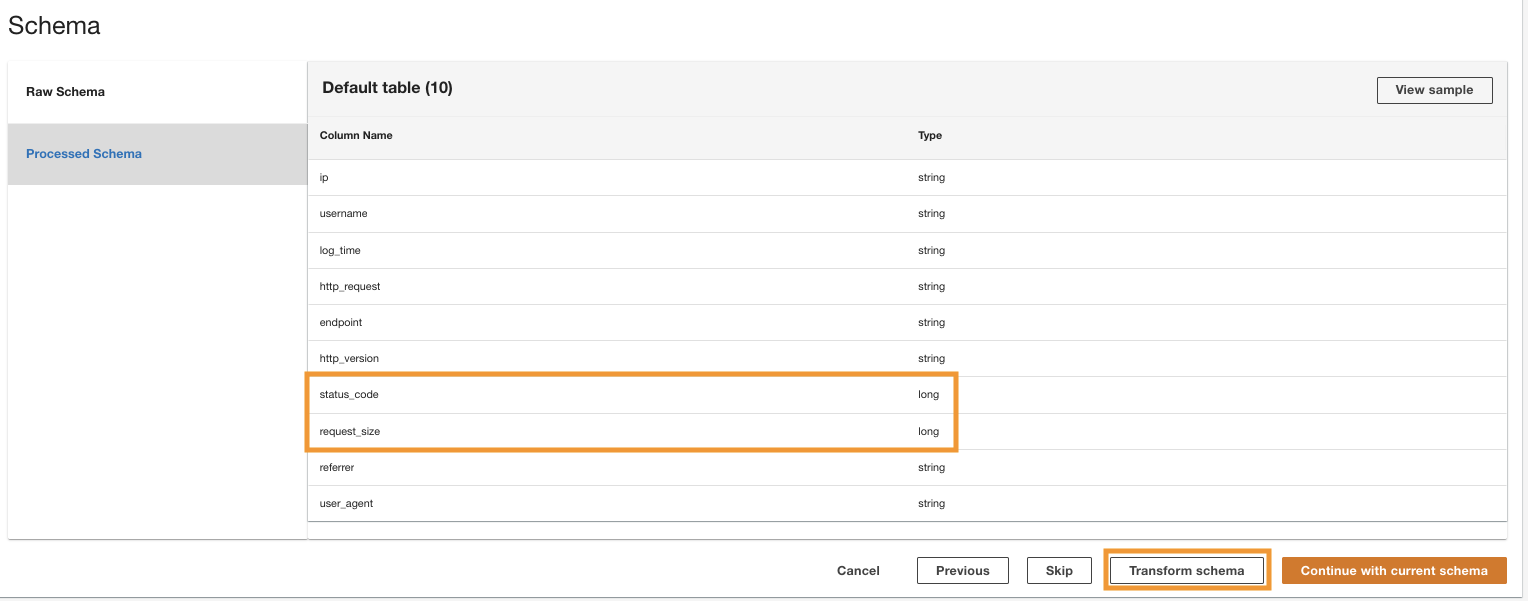
Bemærk de fremhævede kolonnenavne i Skema forhåndsvisning ruden, før du anvender datatypetransformationerne.
- I Transformere plan rude, under Indbyggede transformationer, vælg Anvend kortlægning.
Denne indstilling giver dig mulighed for at ændre datatypen fra en type til en anden.
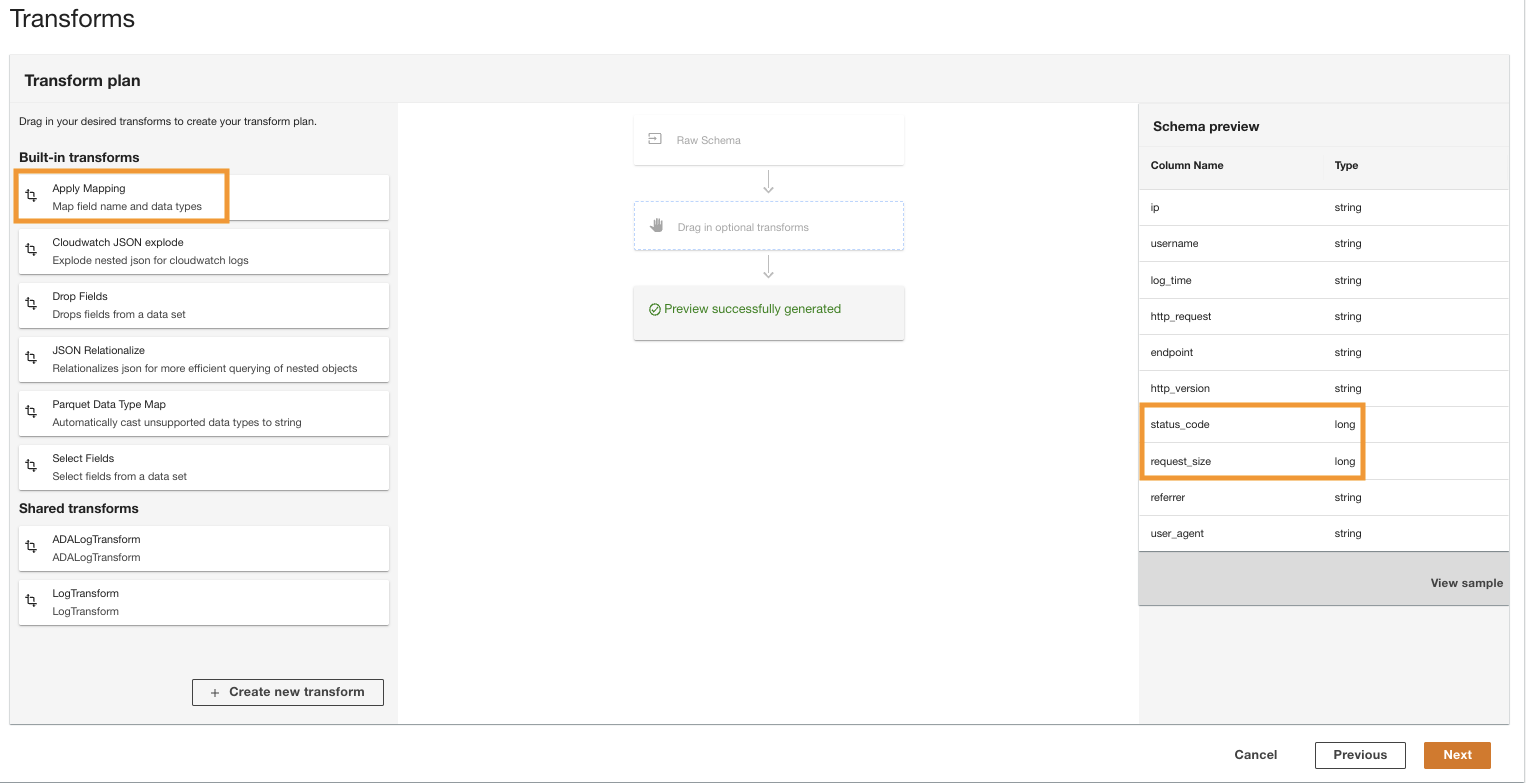
- I Anvend kortlægning sektion, fravælg Drop andre felter.
Hvis denne mulighed ikke er deaktiveret, vil kun de transformerede kolonner blive bevaret, og alle andre kolonner vil blive slettet. Fordi vi ønsker at beholde alle kolonnerne, deaktiverer vi denne mulighed.
- Under Markkortlægningertil Gamle navn , Nyt navn, gå ind
status_codeog for Ny type, gå indstring.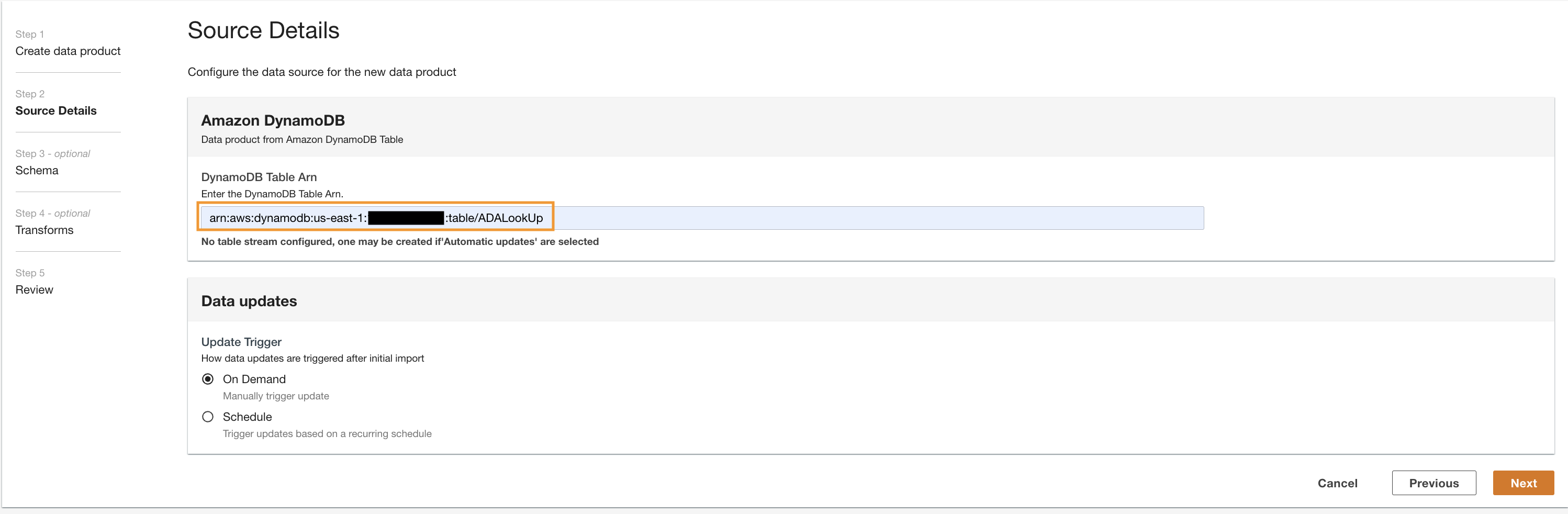
- Vælg Tilføj produkt.
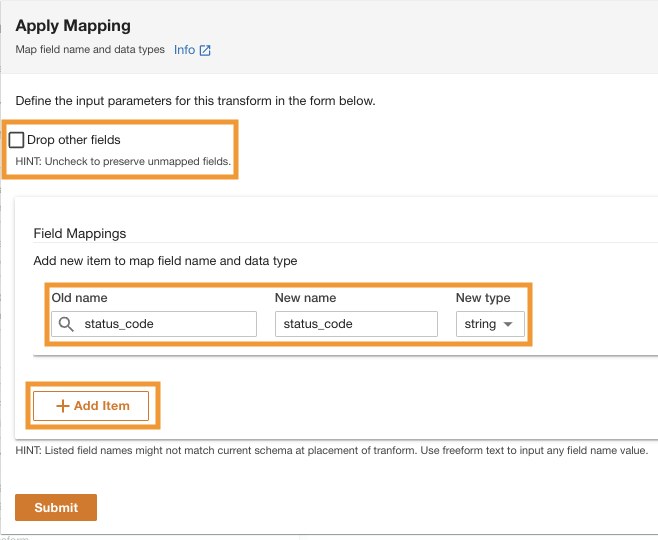
- Til Gamle navn , Nyt navn¸ indtast request_size og for Ny datatype, indtast streng.
- Vælg Indsend.
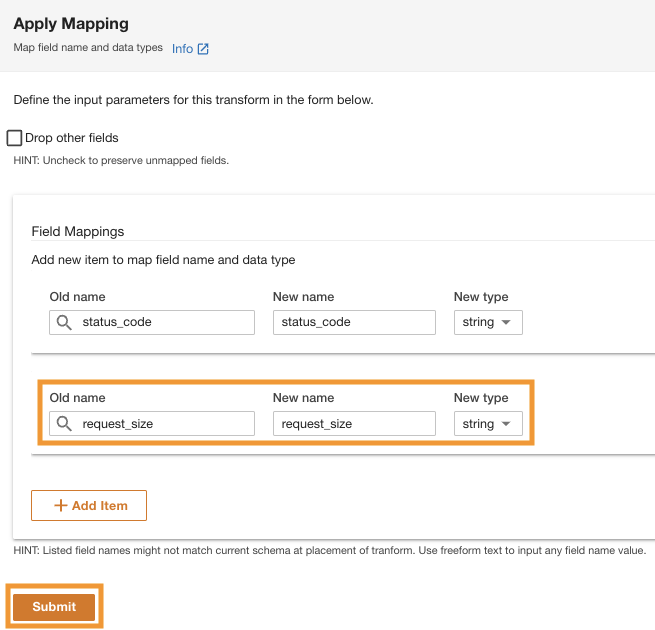
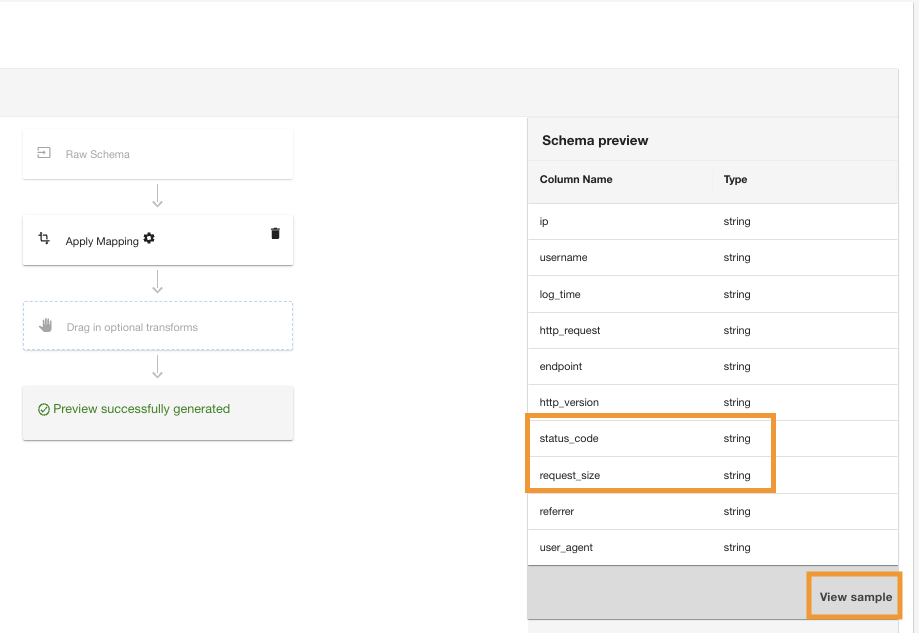
ADA vil anvende kortlægningstransformationen på Amazon S3-datakilden. Bemærk kolonnetyperne i Skema forhåndsvisning rude.
- Vælg Se prøve for at få vist dataene med transformationen anvendt.
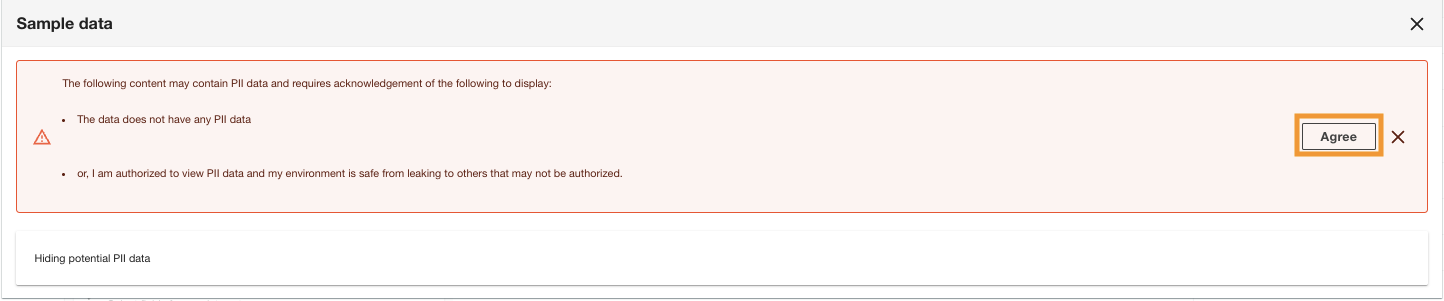
ADA viser PII-databekræftelsen for at sikre, at enten kun autoriserede brugere kan se dataene, eller at datasættet ikke indeholder nogen PII-data.
- Vælg Enig for at fortsætte med at se eksempeldataene.
Bemærk, at skemaet er identisk med CloudWatch-loggruppeskemaet, fordi både den aktuelle applikation og historiske applikationslogfiler er i Apache-logformat.
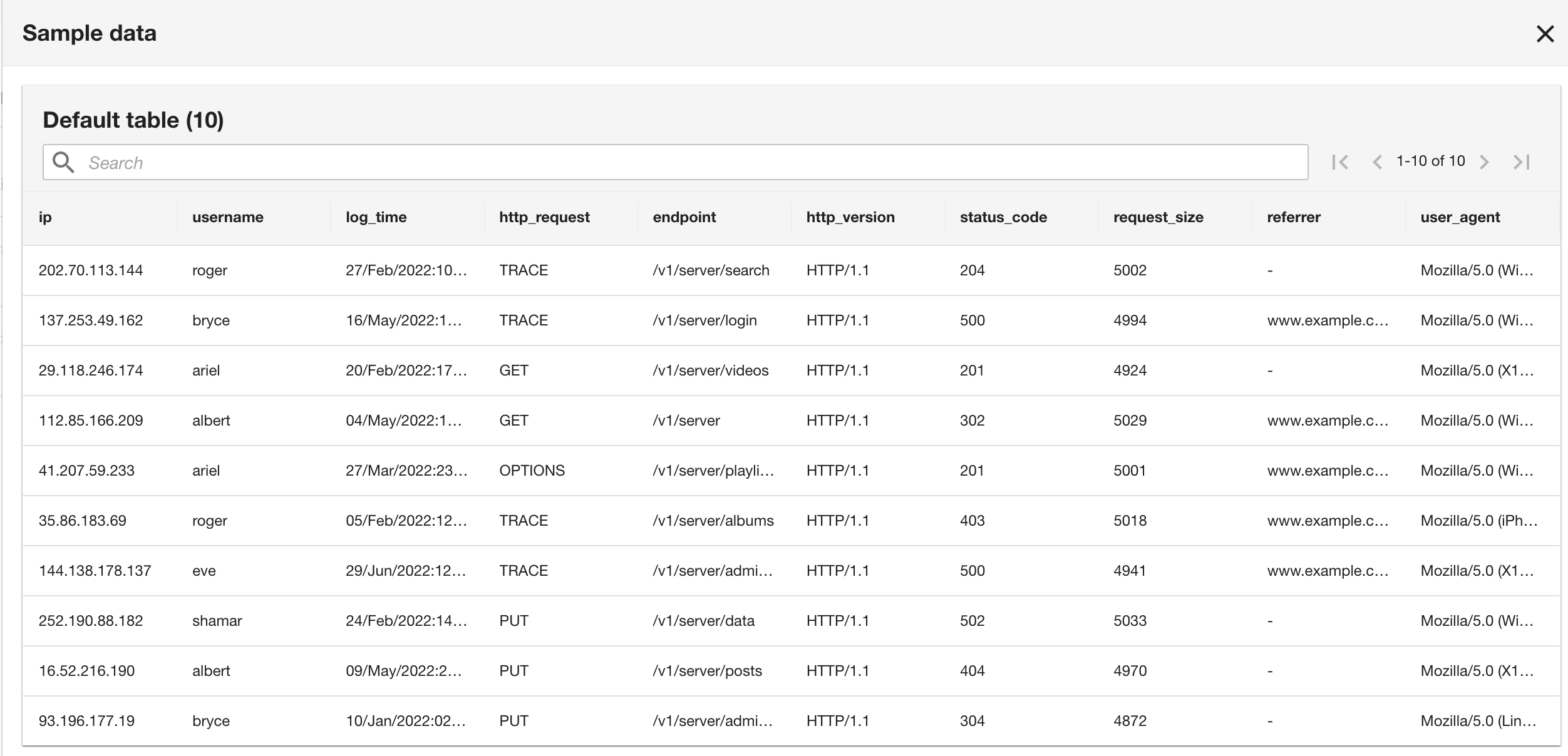
- I det sidste trin skal du gennemgå konfigurationen og vælge Indsend.
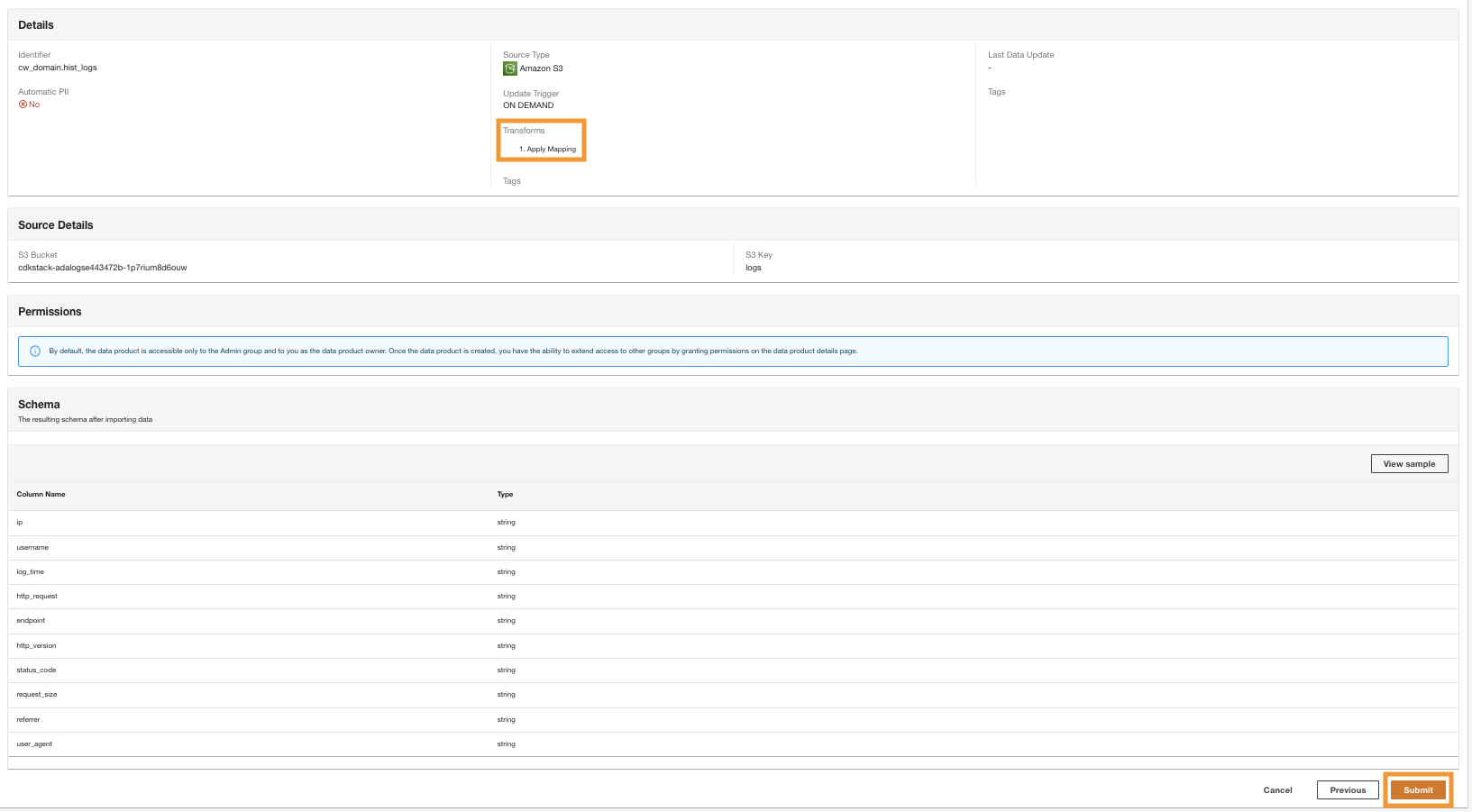
ADA begynder at behandle dataene fra Amazon S3-kilden, opretter backend-infrastrukturen og forbereder dataproduktet. Denne proces tager et par minutter afhængigt af størrelsen af dataene.
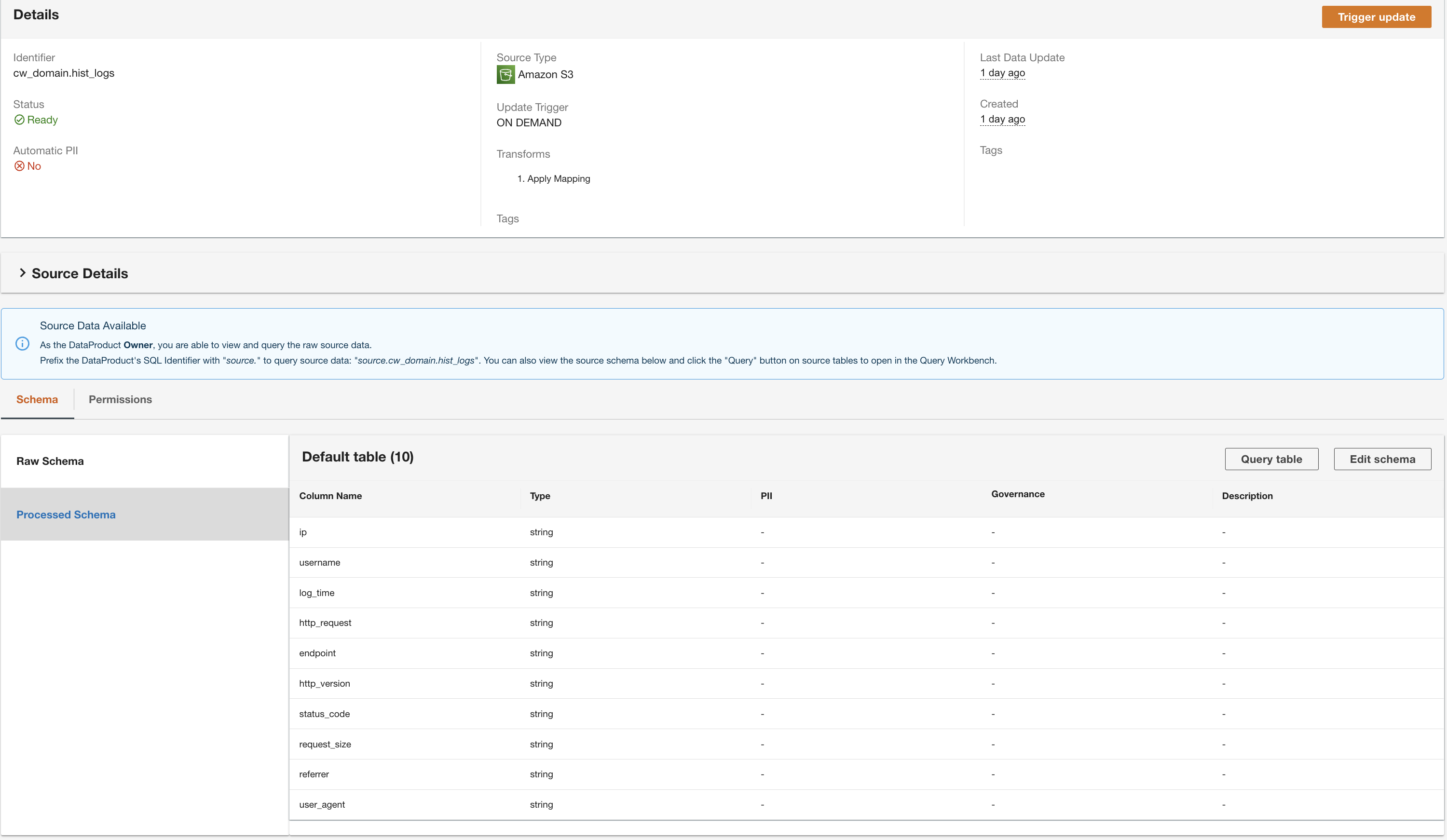
Opret et DynamoDB-dataprodukt
Til sidst opretter vi et DynamoDB-dataprodukt. Udfør følgende trin:
- Opret et nyt dataprodukt på ADA-konsollen.
- Indtast et navn (
lookup) og vælg Amazon DynamoDB.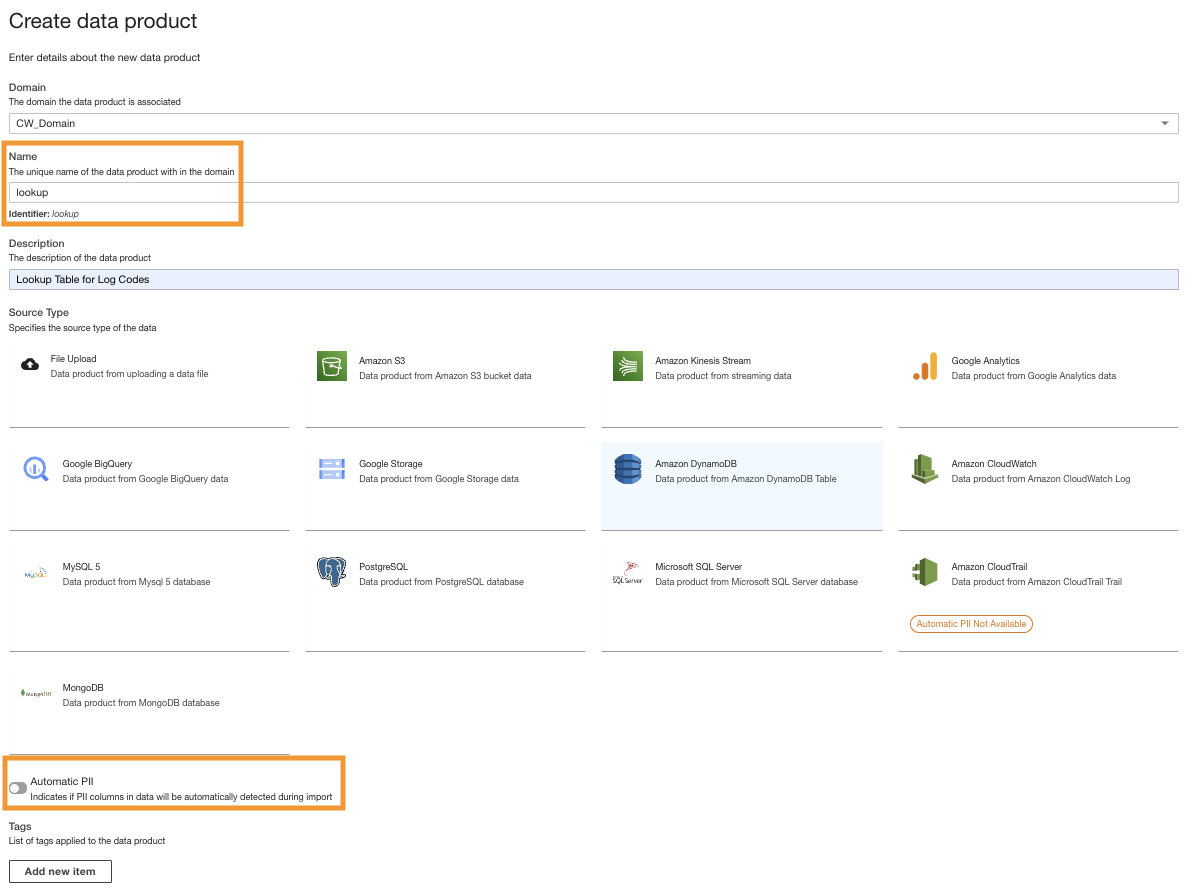
- Indtast
Cdk.DynamoDBTableoutputvariabel for DynamoDB Tabel ARN.
Denne tabel indeholder nøgleattributter, der vil blive brugt som en opslagstabel i denne demo. Til opslagsdata bruger vi HTTP-koderne og lange og korte beskrivelser af koderne. Du kan også bruge PostgreSQL, MySQL eller en CSV-filkilde som et alternativ.
- Til Opdater trigger, Vælg On-Demand.
Opdateringerne vil være på efterspørgsel, fordi opslaget for det meste er til referenceformål under forespørgsler, og eventuelle opdateringer til opslagsdataene kan opdateres i ADA ved hjælp af on-demand-udløsere.
- Vælg Næste.
ADA læser skemaet fra det underliggende DynamoDB-skema og præsenterer kolonnenavnet og typen til valgfri transformation. Vi fortsætter med standardskemavalget, fordi kolonnetyperne er i overensstemmelse med typerne fra CloudWatch-loggruppen og Amazon S3 CSV-datakilden. At have datatyper, der er konsistente på tværs af datakilderne, giver os mulighed for at skrive forespørgsler for at hente poster ved at forbinde tabellerne ved hjælp af kolonnefelterne. For eksempel kolonnen key i DynamoDB-skemaet svarer til status_code i Amazon S3- og CloudWatch-dataprodukterne. Vi kan skrive forespørgsler, der kan forbinde de tre tabeller ved hjælp af kolonnenavnet key. Et eksempel er vist i næste afsnit.
- Vælg Fortsæt med det nuværende skema.
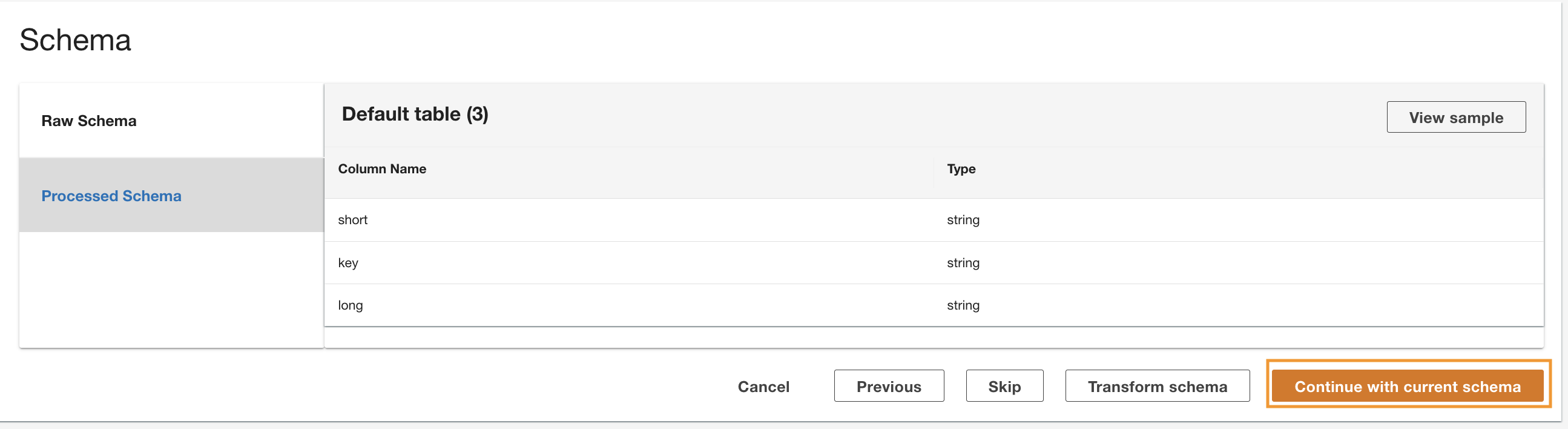
- Gennemgå konfigurationen og vælg Indsend.
ADA behandler dataene fra DynamoDB-tabeldatakilden og forbereder dataproduktet. Afhængigt af størrelsen af dataene tager denne proces et par minutter.
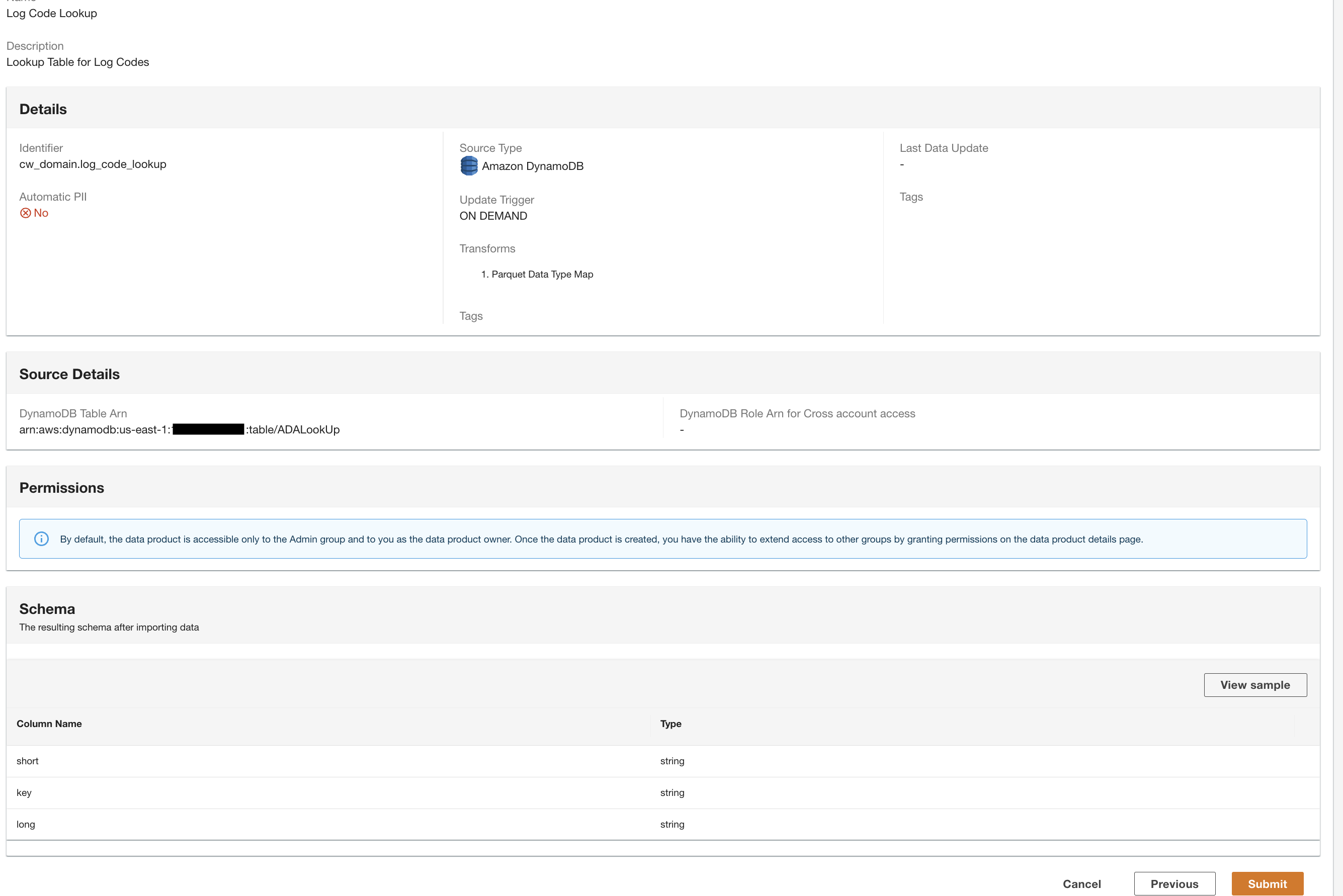
Nu har vi alle de tre dataprodukter behandlet af ADA og tilgængelige for dig til at køre forespørgsler.

Brug Query Workbench til at forespørge dataene
ADA giver dig mulighed for at køre forespørgsler mod dataprodukterne, mens du abstraherer datakilden og gør den tilgængelig ved hjælp af SQL (Structured Query Language). Du kan skrive forespørgsler og forbinde tabellerne, ligesom du ville forespørge mod tabeller i en relationsdatabase. Vi demonstrerer ADA's forespørgselsevne via to brugerscenarier. I begge scenarier forbinder vi et programlogdatasæt til fejlkodeopslagstabellen. I det første tilfælde forespørger vi de aktuelle applikationslogfiler for at identificere de 10 mest tilgåede applikationsslutpunkter sammen med de tilsvarende HTTP-statuskoder:
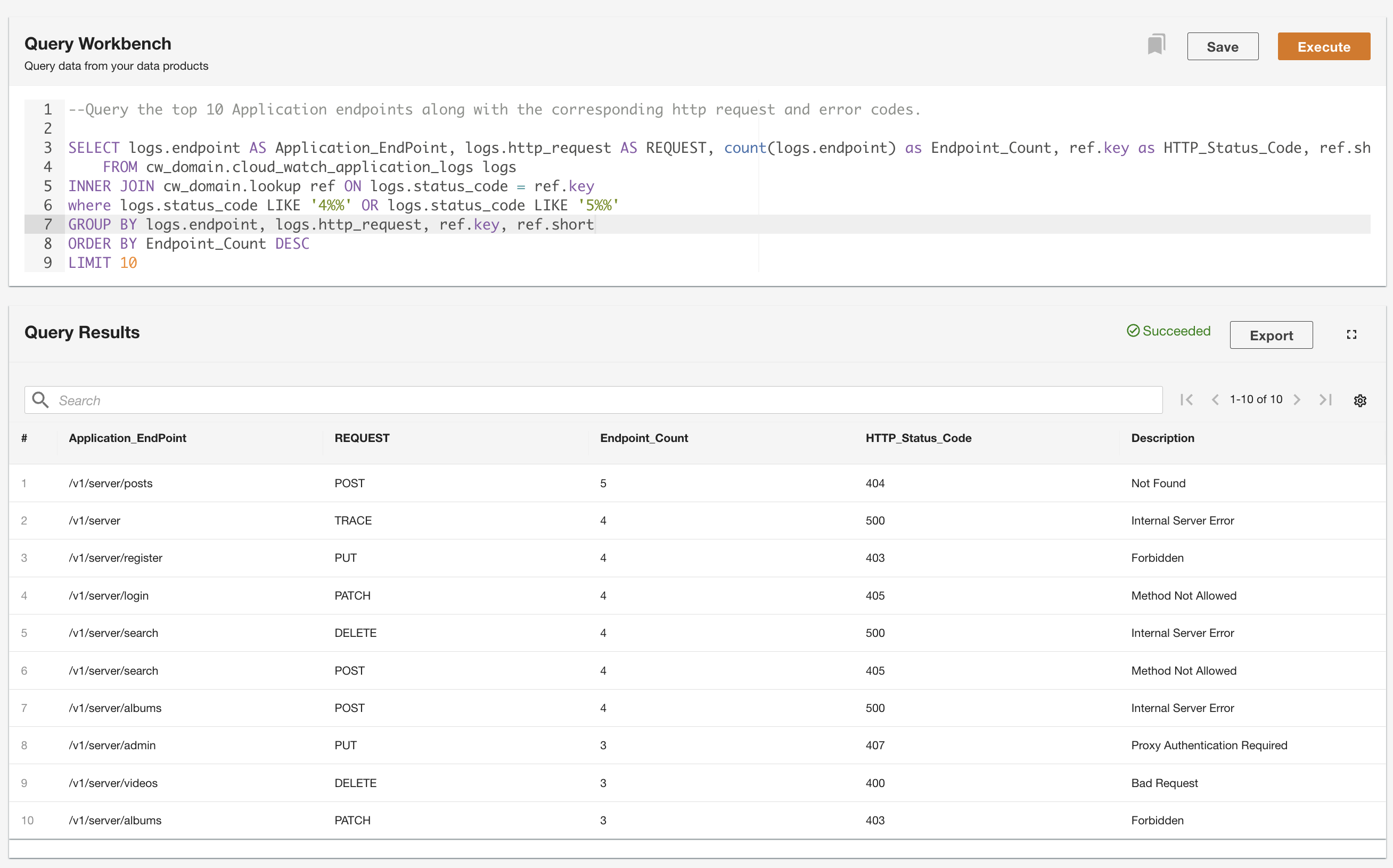
I det andet eksempel forespørger vi tabellen med historiske logfiler for at få de 10 bedste applikationsendepunkter med flest fejl for at forstå endepunktkaldsmønsteret:
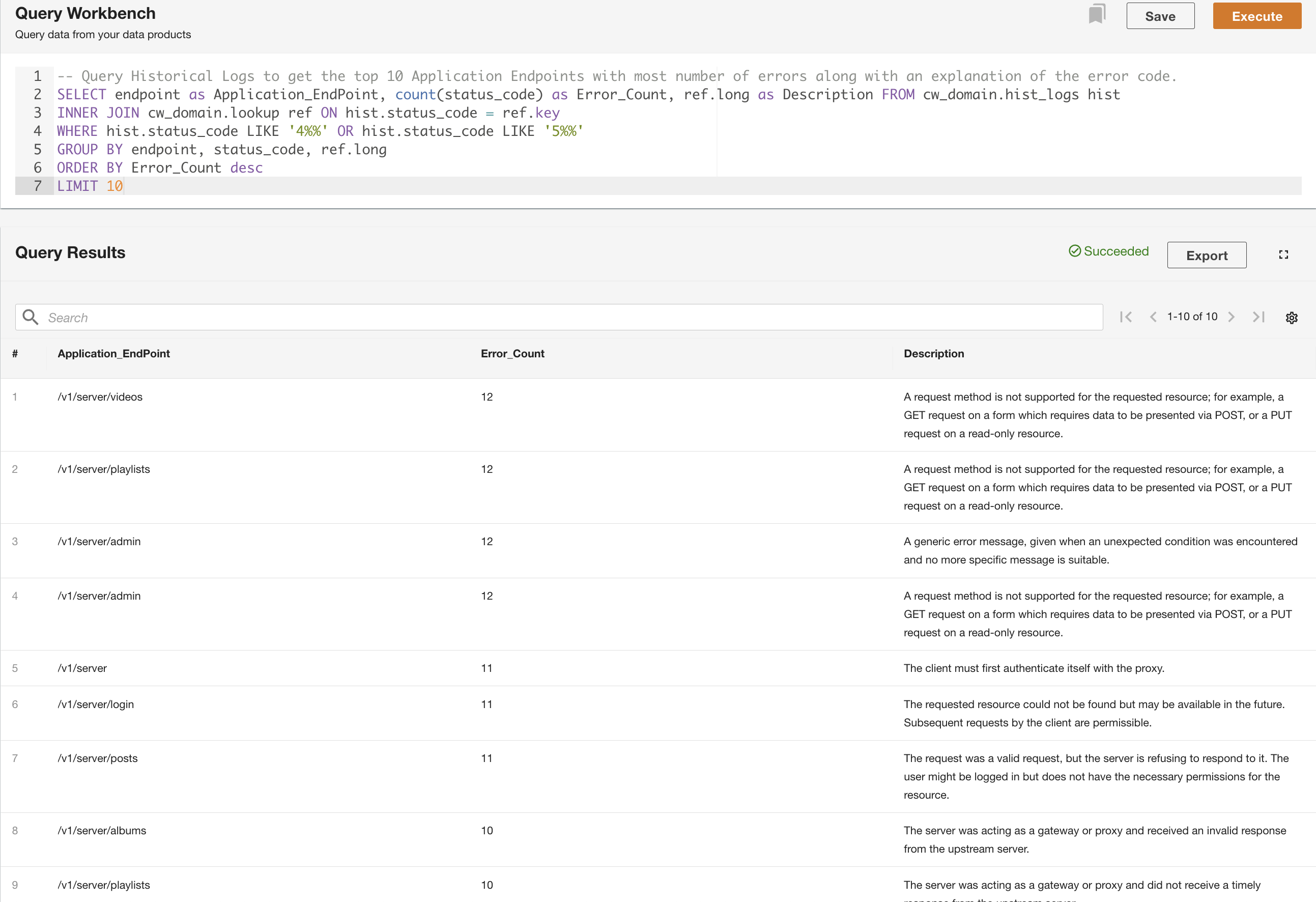
Ud over at forespørge, kan du valgfrit gemme forespørgslen og dele den gemte forespørgsel med andre brugere på samme domæne. De delte forespørgsler er tilgængelige direkte fra Query Workbench. Forespørgselsresultaterne kan også eksporteres til CSV-format.
Visualiser ADA-dataprodukter i Tableau
ADA giver mulighed for at connect til tredjeparts BI-værktøjer for at visualisere data og oprette rapporter fra ADA-dataprodukterne. I denne demo bruger vi ADAs native integration med Tableau til at visualisere dataene fra de tre dataprodukter, vi konfigurerede tidligere. Brug af Tableaus Athena-stik og følg trinene i Tableau konfiguration, kan du konfigurere ADA som en datakilde i Tableau. Efter at der er etableret en vellykket forbindelse mellem Tableau og ADA, vil Tableau udfylde de tre dataprodukter under Tableau-kataloget cw_domain.
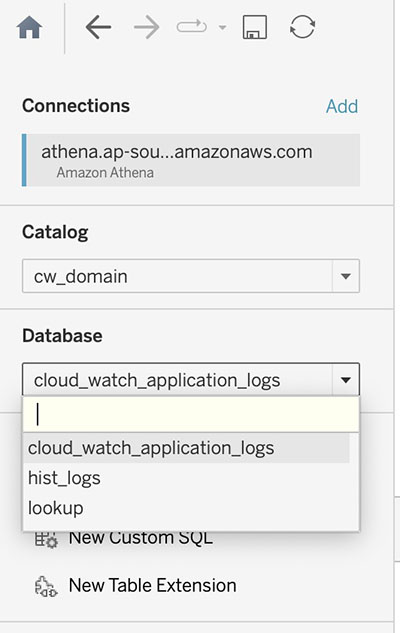
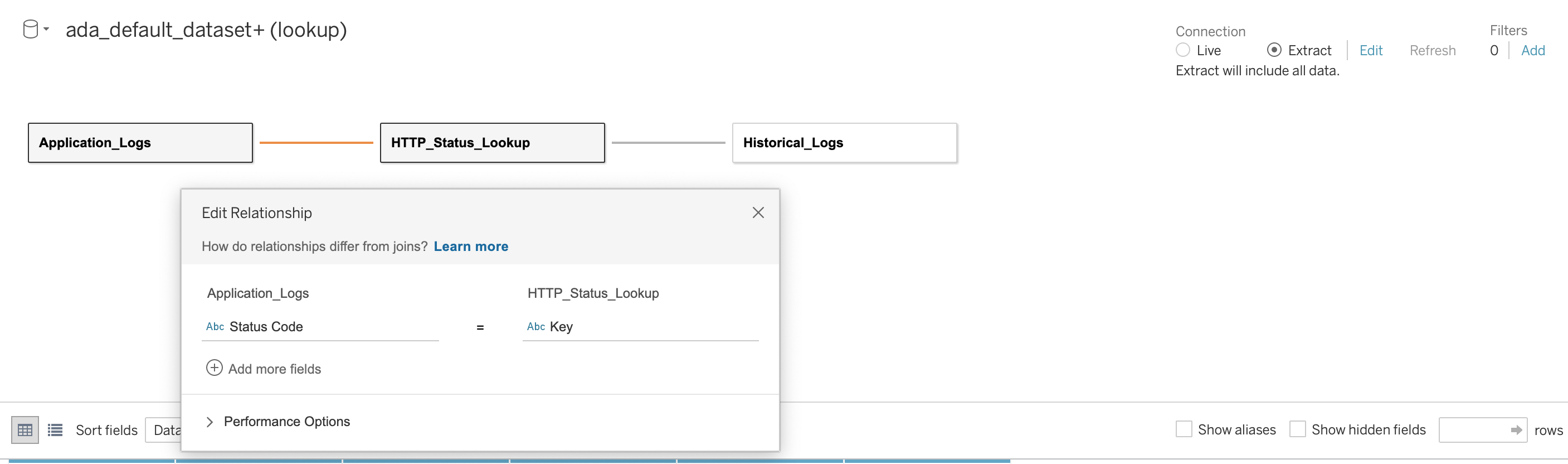
Vi etablerer derefter en relation på tværs af de tre databaser ved hjælp af HTTP-statuskoden som sammenføjningskolonnen, som vist på det følgende skærmbillede. Tableau giver os mulighed for at arbejde online og offline med datakilderne. I onlinetilstand vil Tableau oprette forbindelse til ADA og forespørge dataprodukterne live. I offline-tilstand kan vi bruge Uddrag mulighed for at udtrække dataene fra ADA og importere dataene til Tableau. I denne demo importerer vi dataene til Tableau for at gøre forespørgslen mere responsiv. Vi gemmer derefter Tableau-arbejdsbogen. Vi kan inspicere data fra datakilderne ved at vælge databasen og Opdater nu.
Med datakildekonfigurationerne på plads i Tableau kan vi oprette tilpassede rapporter, diagrammer og visualiseringer på ADA-dataprodukterne. Lad os overveje to use cases for visualiseringer.
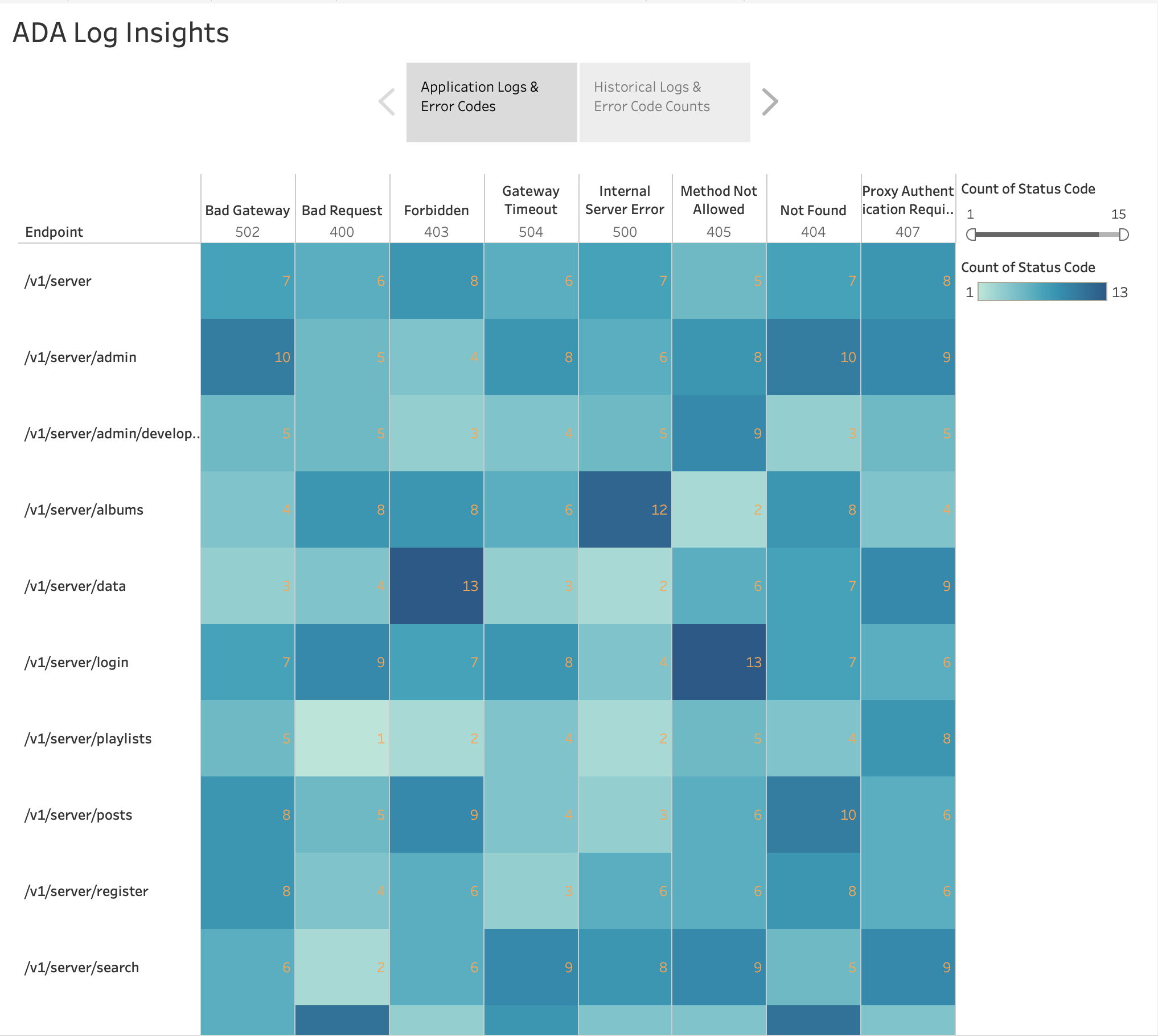
Som vist i den følgende figur, visualiserede vi hyppigheden af HTTP-fejl efter applikationsslutpunkter ved hjælp af Tableaus indbyggede varmekort diagram. Vi frafiltrerede HTTP-statuskoderne til kun at inkludere fejlkoder i 4xx- og 5xx-intervallet.
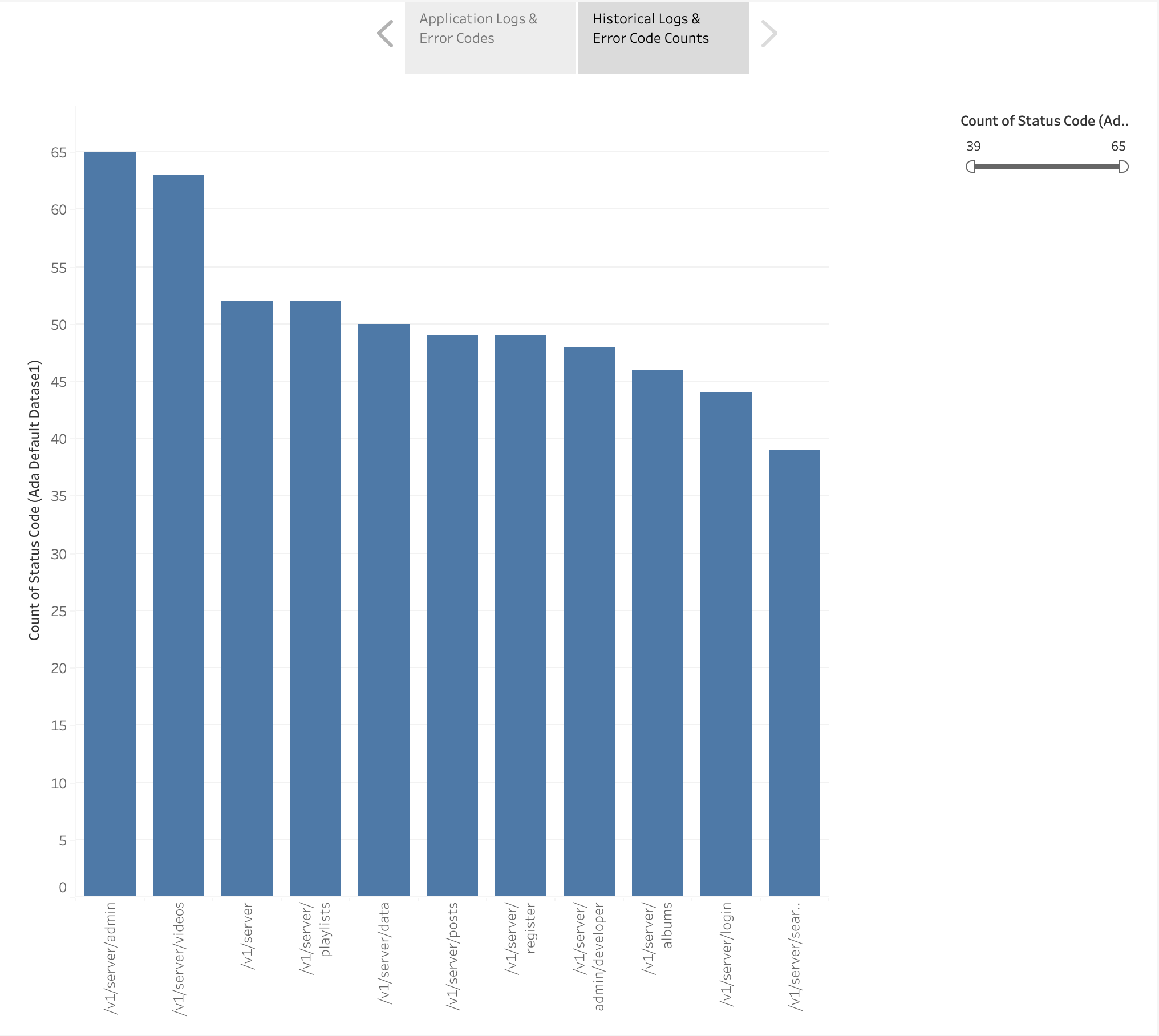
Vi har også oprettet et søjlediagram til at afbilde applikationens slutpunkter fra de historiske logfiler sorteret efter antallet af HTTP-fejlkoder. I dette diagram kan vi se, at /v1/server/admin endpoint har genereret flest HTTP-fejlstatuskoder.
Ryd op
Oprydning af prøveapplikationsinfrastrukturen er en to-trins proces. Først, for at fjerne den infrastruktur, der er klargjort til formålet med denne demo, skal du køre følgende kommando i terminalen:
For det følgende spørgsmål skal du indtaste y og AWS CDK vil slette de ressourcer, der er implementeret til demoen:
Alternativt kan du fjerne ressourcerne via AWS CloudFormation-konsollen ved at navigere til CdkStack-stakken og vælge Slette.
Det andet trin er at afinstallere ADA. For instruktioner, se Afinstaller løsningen.
Konklusion
I dette indlæg demonstrerede vi, hvordan man bruger ADA-løsningen til at udlede indsigt fra applikationslogfiler, der er gemt på tværs af to forskellige datakilder. Vi demonstrerede, hvordan man installerer ADA på en AWS-konto og implementerer demokomponenterne ved hjælp af AWS CDK. Vi oprettede dataprodukter i ADA og konfigurerede dataprodukterne med de respektive datakilder ved hjælp af ADA's indbyggede dataconnectors. Vi demonstrerede, hvordan man forespørger dataprodukterne ved hjælp af standard SQL-forespørgsler og genererer indsigt i logdataene. Vi tilsluttede også Tableau Desktop-klienten, et tredjeparts BI-produkt, til ADA og demonstrerede, hvordan man opbygger visualiseringer mod dataprodukterne.
ADA automatiserer processen med at indtage, transformere, styre og forespørge på forskellige datasæt og forenkle livscyklusstyringen af data. ADAs forudbyggede stik giver dig mulighed for at indtage data fra forskellige datakilder. Softwareteams med grundlæggende viden om AWS-produkter og -tjenester vil være i stand til at opsætte en operationel dataanalyseplatform på få timer og give sikker adgang til dataene. Dataene kan derefter nemt og hurtigt forespørges ved hjælp af en intuitiv og selvstændig webbrugergrænseflade.
Prøv ADA i dag for nemt at administrere og få indsigt fra data.
Om forfatterne
 Aparajithan Vaidyanathan er Principal Enterprise Solutions Architect hos AWS. Han understøtter virksomhedskunder med at migrere og modernisere deres arbejdsbelastninger på AWS-skyen. Han er en Cloud Architect med 23+ års erfaring med at designe og udvikle enterprise, storstilede og distribuerede softwaresystemer. Han har specialiseret sig i Machine Learning & Data Analytics med fokus på Data og Feature Engineering domæne. Han er en håbefuld maratonløber, og hans hobbyer omfatter vandreture, cykling og at tilbringe tid med sin kone og to drenge.
Aparajithan Vaidyanathan er Principal Enterprise Solutions Architect hos AWS. Han understøtter virksomhedskunder med at migrere og modernisere deres arbejdsbelastninger på AWS-skyen. Han er en Cloud Architect med 23+ års erfaring med at designe og udvikle enterprise, storstilede og distribuerede softwaresystemer. Han har specialiseret sig i Machine Learning & Data Analytics med fokus på Data og Feature Engineering domæne. Han er en håbefuld maratonløber, og hans hobbyer omfatter vandreture, cykling og at tilbringe tid med sin kone og to drenge.
 Rashim Rahman er en softwareudvikler baseret i Sydney, Australien med 10+ års erfaring i softwareudvikling og -arkitektur. Han arbejder primært med at bygge store open source AWS-løsninger til almindelige kundetilfælde og forretningsproblemer. I sin fritid nyder han sport og at tilbringe tid med venner og familie.
Rashim Rahman er en softwareudvikler baseret i Sydney, Australien med 10+ års erfaring i softwareudvikling og -arkitektur. Han arbejder primært med at bygge store open source AWS-løsninger til almindelige kundetilfælde og forretningsproblemer. I sin fritid nyder han sport og at tilbringe tid med venner og familie.
 Hafiz Saadullah er en Principal Technical Product Manager hos Amazon Web Services. Hafiz fokuserer på AWS-løsninger, designet til at hjælpe kunder ved at løse almindelige forretningsproblemer og use cases.
Hafiz Saadullah er en Principal Technical Product Manager hos Amazon Web Services. Hafiz fokuserer på AWS-løsninger, designet til at hjælpe kunder ved at løse almindelige forretningsproblemer og use cases.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Automotive/elbiler, Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- ChartPrime. Løft dit handelsspil med ChartPrime. Adgang her.
- BlockOffsets. Modernisering af miljømæssig offset-ejerskab. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :har
- :er
- :ikke
- :hvor
- $OP
- 10
- 11
- 12
- 14
- 15 %
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- evne
- I stand
- Om
- adgang
- af udleverede
- tilgængelig
- Konto
- tværs
- aktioner
- ADA
- tilføje
- Desuden
- Yderligere
- adressering
- admin
- Efter
- mod
- Alle
- tillade
- tillader
- sammen
- også
- alternativ
- Amazon
- Amazon Web Services
- blandt
- an
- analyse
- Analytikere
- analytics
- analysere
- ,
- En anden
- enhver
- Apache
- api
- API'er
- Anvendelse
- applikationer
- anvendt
- Indløs
- Anvendelse
- arkitektur
- ER
- AS
- aspirerende
- At
- attributter
- Australien
- Godkendelse
- autoriseret
- Automatiseret
- automater
- automatisk
- til rådighed
- AWS
- AWS CloudFormation
- tilbage
- Bagende
- Bar
- baseret
- grundlæggende
- BE
- fordi
- været
- før
- skræddersyet
- mellem
- både
- Boks
- bygge
- Bygning
- indbygget
- virksomhed
- business intelligence
- men
- by
- ringe
- CAN
- kapacitet
- tilfælde
- tilfælde
- katalog
- CD
- lave om
- Chart
- Diagrammer
- Vælg
- vælge
- kunde
- Cloud
- kode
- koder
- samling
- Kolonne
- Kolonner
- Fælles
- fuldføre
- komponenter
- Konfiguration
- konfigureret
- Tilslut
- tilsluttet
- tilslutning
- forbinder
- Overvej
- konsekvent
- Konsol
- indeholder
- fortsæt
- korreleret
- Korrelation
- Tilsvarende
- svarer
- Koste
- skabe
- oprettet
- skaber
- Oprettelse af
- Legitimationsoplysninger
- Nuværende
- skik
- kunde
- Kunder
- instrumentbræt
- data
- Dataanalyse
- databehandling
- Database
- databaser
- datasæt
- Standard
- Efterspørgsel
- Demo
- demonstrere
- demonstreret
- Afhængigt
- indsætte
- indsat
- implementering
- udruller
- beskrivelse
- konstrueret
- designe
- desktop
- detaljeret
- detaljer
- Udvikler
- udvikling
- Udvikling
- diagnose
- forskellige
- direkte
- deaktiveret
- opdagelse
- Skærm
- distribueret
- forskelligartede
- Er ikke
- domæne
- Domæner
- Dont
- droppet
- i løbet af
- hver
- tidligere
- nemt
- redigering
- enten
- aktiveret
- muliggør
- Endpoint
- endpoints
- Engineering
- sikre
- Indtast
- Enterprise
- virksomhedskunder
- Enterprise Solutions
- fejl
- fejl
- etablere
- etableret
- Ether (ETH)
- eksempel
- eksisterende
- erfaring
- Forklar
- forklaring
- ekstrakt
- udtrække dataene
- bekendt
- familie
- Feature
- få
- felt
- Fields
- Figur
- File (Felt)
- Filer
- endelige
- finansiere
- Fornavn
- fleksibel
- Fokus
- fokuserer
- efter
- Til
- format
- fire
- Frekvens
- venner
- fra
- funktion
- Gevinst
- generere
- genereret
- få
- få
- styrende
- gruppe
- Gruppens
- Have
- have
- he
- hjælpe
- Fremhævet
- hiking
- hans
- historisk
- Hobbyer
- hostede
- HOURS
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- IAM
- identisk
- identificere
- Identity
- if
- importere
- in
- omfatter
- omfatter
- Herunder
- oplysninger
- Infrastruktur
- initial
- indsigt
- installere
- installation
- anvisninger
- integreret
- integration
- Intelligens
- interaktiv
- interesseret
- grænseflade
- ind
- intuitiv
- påberåber sig
- involverede
- spørgsmål
- IT
- deltage
- sammenføjning
- Sammenføjninger
- jpg
- json
- lige
- Holde
- Nøgle
- viden
- Sprog
- stor
- storstilet
- Efternavn
- senere
- lancering
- læring
- Bibliotek
- Licenseret
- livscyklus
- ligesom
- GRÆNSE
- Line (linje)
- Liste
- leve
- log
- logning
- Lang
- Se
- kig op
- maskine
- machine learning
- lave
- Making
- administrere
- ledelse
- leder
- mange
- kort
- kortlægning
- Marathon
- Marketing
- Matter
- meningsfuld
- besked
- MFA
- måske
- migrere
- minutter
- tilstand
- modernisere
- mere
- mest
- for det meste
- Mozilla
- multi-faktor autentificering
- MySQL
- navn
- Som hedder
- navne
- indfødte
- Naviger
- navigering
- Navigation
- Behov
- behov
- behov
- Ny
- nyligt
- næste
- nummer
- of
- Tilbud
- offline
- Gammel
- on
- On-Demand
- ONE
- online
- kun
- åbent
- open source
- operationelle
- Option
- or
- ordrer
- Andet
- Andre
- ud
- output
- oversigt
- side
- brød
- Adgangskode
- sti
- Mønster
- udføre
- Tilladelser
- Personligt
- telefon
- PIO
- pipeline
- Place
- Almindeligt
- fly
- perron
- plato
- Platon Data Intelligence
- PlatoData
- politikker
- Portal
- Indlæg
- postgresql
- strøm
- Forbered
- Forbereder
- forudsætninger
- præsentere
- gaver
- Eksempel
- tidligere
- primært
- Main
- Forud
- problemer
- Fortsæt
- behandle
- bearbejdet
- Processer
- forarbejdning
- produceret
- Produkt
- produktchef
- Produkter
- Produkter og services
- Programmer
- projekt
- give
- forudsat
- udbyder
- giver
- formål
- formål
- Python
- forespørgsler
- spørgsmål
- hurtigt
- rækkevidde
- Læs
- klar
- modtage
- optegnelser
- benævnt
- region
- forhold
- relevant
- Fjern
- gentag
- Rapporter
- anmode
- påkrævet
- Ressourcer
- dem
- lydhør
- Resultater
- tilbageholde
- gennemgå
- ridning
- roller
- rod
- Herske
- Kør
- runner
- kører
- salg
- samme
- Gem
- Scale
- scenarier
- planlagt
- rækkevidde
- Søg
- Anden
- Sektion
- sikker
- sikkerhed
- se
- valgt
- valg
- send
- sendt
- adskille
- tjener
- Serverless
- tjeneste
- Tjenester
- sæt
- indstilling
- Del
- delt
- Kort
- vist
- Shows
- Simpelt
- forenklet
- forenkle
- Størrelse
- færdigheder
- So
- Software
- softwareudvikling
- løsninger
- Løsninger
- Kilde
- Kilder
- specialist
- specialiseret
- specifikke
- specificeret
- udgifterne
- Sport
- SQL
- stable
- standalone
- standard
- starte
- starter
- Status
- Trin
- Steps
- opbevaring
- opbevaret
- String
- struktureret
- vellykket
- Succesfuld
- sådan
- Understøtter
- sikker
- sydney
- Systemer
- bord
- Tableau
- Tag
- tager
- hold
- hold
- Teknisk
- tekniske færdigheder
- terminal
- at
- The Source
- deres
- derefter
- Der.
- Disse
- tredjepart
- denne
- tre
- Gennem
- tid
- til
- i dag
- værktøjer
- top
- Top 10
- I alt
- Transform
- Transformation
- transformationer
- omdannet
- omdanne
- transformationer
- udløst
- to
- typen
- typer
- under
- underliggende
- forstå
- opdateret
- opdateringer
- på
- URI
- us
- brug
- brug tilfælde
- anvendte
- Bruger
- Brugergrænseflade
- brugere
- ved brug af
- Værdier
- variabel
- række
- udgave
- via
- Specifikation
- ønsker
- Vej..
- we
- web
- webservices
- GODT
- hvornår
- som
- mens
- bred
- Bred rækkevidde
- kone
- vilje
- med
- inden for
- uden
- Arbejde
- workflow
- virker
- ville
- skriver
- år
- dig
- Din
- zephyrnet