Finansielle servicekunder bruger data fra forskellige kilder, der stammer fra forskellige frekvenser, som inkluderer realtids-, batch- og arkiverede datasæt. Derudover har de brug for streaming-arkitekturer til at håndtere voksende handelsvolumener, markedsvolatilitet og regulatoriske krav. Følgende er nogle af de vigtigste business use cases, der fremhæver dette behov:
- Handelsrapportering – Siden den globale finanskrise i 2007-2008 har regulatorer øget deres krav og kontrol med regulatorisk rapportering. Regulatorer har sat et øget fokus på både at beskytte forbrugeren gennem transaktionsrapportering (typisk T+1, hvilket betyder 1 hverdag efter handelsdatoen) og øge gennemsigtigheden til markeder via handelsrapporteringskrav i næsten realtid.
- Risikostyring – Efterhånden som kapitalmarkederne bliver mere komplekse, og regulatorer lancerer nye risikorammer, som f.eks Grundlæggende gennemgang af handelsbogen (FRTB) og Basel III, søger finansielle institutioner at øge hyppigheden af beregninger for overordnet markedsrisiko, likviditetsrisiko, modpartsrisiko og andre risikomålinger og ønsker at komme så tæt på realtidsberegninger som muligt.
- Handelskvalitet og optimering – For at overvåge og optimere handelskvaliteten skal du løbende evaluere markedskarakteristika såsom volumen, retning, markedsdybde, fyldningsgrad og andre benchmarks relateret til gennemførelsen af handler. Handelskvalitet er ikke kun relateret til mæglerens ydeevne, men er også et krav fra regulatorer, startende med MiFID II.
Udfordringen er at komme med en løsning, der kan håndtere disse forskellige kilder, varierede frekvenser og forbrugskrav med lav latens. Løsningen skal være skalerbar, omkostningseffektiv og ligetil at implementere og betjene. Amazon rødforskydning funktioner som streamingindtagelse, Amazon Aurora nul-ETL integration, og datadeling med AWS dataudveksling muliggør nær-realtidsbehandling til handelsrapportering, risikostyring og handelsoptimering.
I dette indlæg giver vi en løsningsarkitektur, der beskriver, hvordan du kan behandle data fra tre forskellige typer kilder – streaming, transaktions- og tredjepartsreferencedata – og samle dem i Amazon Redshift til rapportering om business intelligence (BI).
Løsningsoversigt
Denne løsningsarkitektur er skabt ved at prioritere en lav kode/ingen kode tilgang med følgende vejledende principper:
- Brugervenlighed – Det burde være mindre komplekst at implementere og betjene med intuitive brugergrænseflader
- Skalerbar – Du bør være i stand til problemfrit at øge og reducere kapaciteten efter behov
- Indfødt integration – Komponenter skal integreres uden yderligere stik eller software
- Omkostningseffektiv – Det skal levere afbalanceret pris/ydelse
- Lav vedligeholdelse – Det burde kræve mindre ledelses- og driftsomkostninger
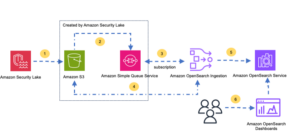
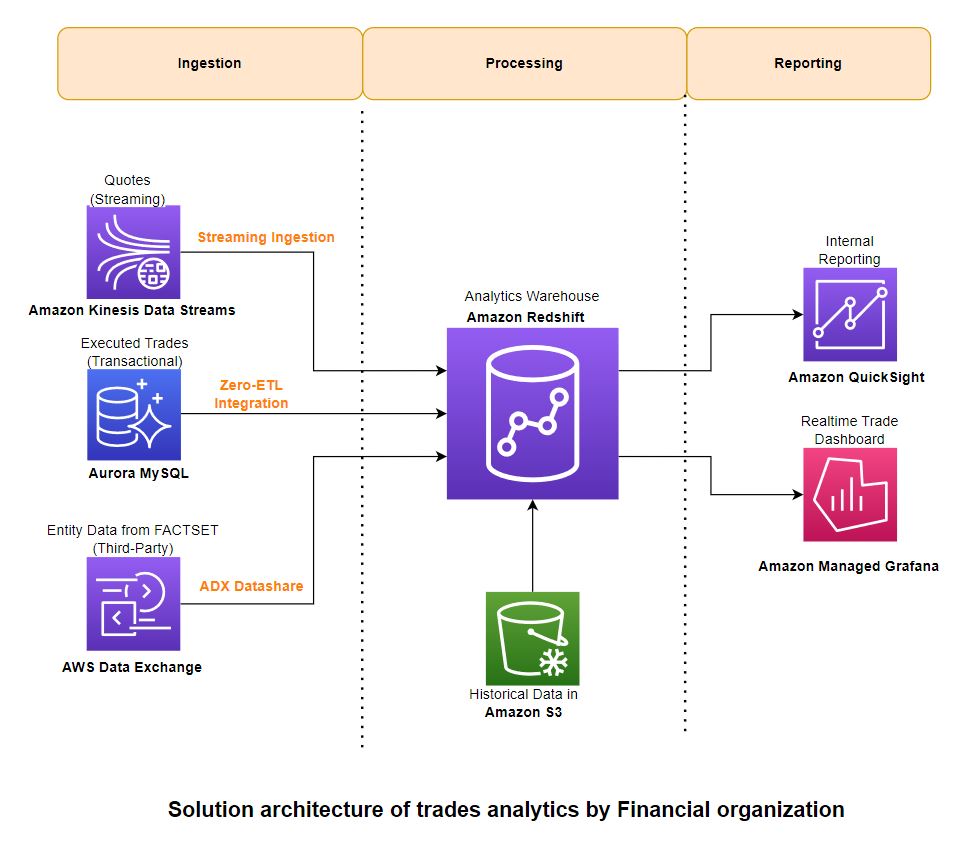
Følgende diagram illustrerer løsningsarkitekturen og hvordan disse vejledende principper blev anvendt på indtagelses-, aggregerings- og rapporteringskomponenterne.
![]()
Implementer løsningen
Du kan bruge følgende AWS CloudFormation skabelon til at implementere løsningen.
![]()
Denne stak opretter følgende ressourcer og nødvendige tilladelser til at integrere tjenesterne:
Indtagelse
For at indtage data, bruger du Amazon Redshift Streaming Indtagelse for at indlæse streamingdata fra Kinesis-datastrømmen. Til transaktionsdata bruger du Redshift nul-ETL integration med Amazon Aurora MySQL. For tredjeparts referencedata drager du fordel af AWS Data Exchange-dataandele. Disse funktioner giver dig mulighed for hurtigt at bygge skalerbare datapipelines, fordi du kan øge kapaciteten af Kinesis Data Streams-shards, beregne for nul-ETL-kilder og -mål og Redshift-beregne for datadeling, når dine data vokser. Redshift-streaming-indtagelse og nul-ETL-integration er lav-kode/ingen kode-løsninger, som du kan bygge med simple SQL'er uden at investere betydelig tid og penge i at udvikle kompleks tilpasset kode.
For de data, der blev brugt til at skabe denne løsning, samarbejdede vi med FactSet, en førende udbyder af finansielle data, analyser og åben teknologi. FactSet har flere datasæt tilgængelig på AWS Data Exchange-markedspladsen, som vi brugte til referencedata. Vi brugte også FactSets markedsdataløsninger for historiske og streaming markedskurser og handler.
Behandles
Data behandles i Amazon Redshift under overholdelse af en ekstraktions-, indlæsnings- og transformationsmetode (ELT). Med praktisk talt ubegrænset skala og arbejdsbelastningsisolering er ELT mere velegnet til cloud-data warehouse-løsninger.
Du bruger Redshift-streaming-indtagelse til realtids-indtagelse af streaming-citater (bud/spørg) fra Kinesis-datastrømmen direkte til en streaming-materialiseret visning og behandler dataene i det næste trin ved hjælp af PartiQL til at parse datastrømmens input. Bemærk, at streaming af materialiserede visninger adskiller sig fra almindelige materialiserede visninger med hensyn til, hvordan automatisk opdatering fungerer, og de anvendte SQL-kommandoer for datastyring. Henvise til Overvejelser om streamingindtagelse for yderligere oplysninger.
Du bruger nul-ETL Aurora-integrationen til at indlæse transaktionsdata (handler) fra OLTP-kilder. Henvise til Arbejder med nul-ETL integrationer for aktuelt understøttede kilder. Du kan kombinere data fra alle disse kilder ved hjælp af visninger og bruge lagrede procedurer til at implementere forretningstransformationsregler som at beregne vægtede gennemsnit på tværs af sektorer og børser.
Historiske handels- og prisdatamængder er enorme og ofte forespørges ikke ofte. Du kan bruge Amazon Redshift Spectrum for at få adgang til disse data på plads uden at indlæse dem i Amazon Redshift. Du opretter eksterne tabeller, der peger på data ind Amazon Simple Storage Service (Amazon S3) og forespørg på samme måde, som du forespørger på enhver anden lokal tabel i Amazon Redshift. Flere Redshift-datavarehuse kan samtidigt forespørge på de samme datasæt i Amazon S3 uden behov for at lave kopier af dataene for hvert datavarehus. Denne funktion forenkler adgangen til eksterne data uden at skrive komplekse ETL-processer og øger brugervenligheden af den overordnede løsning.
Lad os gennemgå et par eksempler på forespørgsler, der bruges til at analysere tilbud og handler. Vi bruger følgende tabeller i eksempelforespørgslerne:
- dt_hist_quote – Historiske kursdata, der indeholder budpris og volumen, udbudspris og volumen samt børser og sektorer. Du bør bruge relevante datasæt i din organisation, der indeholder disse dataattributter.
- dt_hist_trades – Historiske handelsdata, der indeholder handlet pris, volumen, sektor og børsdetaljer. Du bør bruge relevante datasæt i din organisation, der indeholder disse dataattributter.
- faktasæt_sektorkort – Kortlægning mellem sektorer og børser. Du kan få dette hos FactSet Fundamentals ADX-datasæt.
Eksempelforespørgsel til analyse af historiske citater
Du kan bruge følgende forespørgsel til at finde vægtede gennemsnitlige spreads på citater:
Eksempelforespørgsel til analyse af historiske handler
Du kan bruge følgende forespørgsel til at finde $-volume på handler efter detaljeret børs, efter sektor og efter større børs (NYSE og Nasdaq):
Rapportering
Du kan bruge Amazon QuickSight , Amazon administrerede Grafana til henholdsvis BI og realtidsrapportering. Disse tjenester integreres naturligt med Amazon Redshift uden behov for at bruge yderligere stik eller software imellem.
Du kan køre en direkte forespørgsel fra QuickSight til BI-rapportering og dashboards. Med QuickSight kan du også lokalt gemme data i SPICE-cachen med automatisk opdatering for lav latenstid. Henvise til Godkendelse af forbindelser fra Amazon QuickSight til Amazon Redshift-klynger for omfattende detaljer om, hvordan du integrerer QuickSight med Amazon Redshift.
Du kan bruge Amazon Managed Grafana til handelsdashboards i næsten realtid, der opdateres med få sekunders mellemrum. Dashboards i realtid til overvågning af handelsindtagelsesforsinkelser oprettes ved hjælp af Grafana, og dataene stammer fra systemvisninger i Amazon Redshift. Henvise til Brug af Amazon Redshift-datakilden for at lære om, hvordan du konfigurerer Amazon Redshift som en datakilde for Grafana.
De brugere, der interagerer med regulatoriske rapporteringssystemer, omfatter analytikere, risikomanagere, operatører og andre personer, der understøtter forretnings- og teknologidrift. Ud over at generere regulatoriske rapporter kræver disse teams synlighed i rapporteringssystemernes tilstand.
Analyse af historiske citater
I dette afsnit udforsker vi nogle eksempler på historiske citater fra Amazon QuickSight instrumentbræt.
Vægtet gennemsnitsspredning på sektorer
Følgende diagram viser den daglige aggregering efter sektor af de vægtede gennemsnitlige bid-ask-spænd for alle de individuelle handler på NASDAQ og NYSE i 3 måneder. For at beregne det gennemsnitlige daglige spænd vægtes hvert spænd med summen af buddet og salgsvolumenet i dollar. Forespørgslen til at generere dette diagram behandler 103 milliarder datapunkter i alt, forbinder hver handel med sektorreferencetabellen og kører på mindre end 10 sekunder.
![]()
Vægtet gennemsnitsspænd på børser
Følgende diagram viser den daglige sammenlægning af de vægtede gennemsnitlige bud-ask-spænd for alle de individuelle handler på NASDAQ og NYSE i 3 måneder. Beregningsmetoden og forespørgselsydeevnemålingerne ligner dem i det foregående diagram.
![]()
Historisk brancheanalyse
I dette afsnit udforsker vi nogle eksempler på historiske handelsanalyser fra Amazon QuickSight instrumentbræt.
Handelsmængder fordelt på sektor
Følgende diagram viser den daglige sammenlægning efter sektor af alle de individuelle handler på NASDAQ og NYSE i 3 måneder. Forespørgslen til at generere dette diagram behandler 3.6 milliarder handler i alt, forbinder hver handel med sektorreferencetabellen og kører på under 5 sekunder.
![]()
Handelsvolumener for større børser
Følgende diagram viser den daglige sammenlægning efter børsgruppe for alle de individuelle handler i 3 måneder. Forespørgslen til at generere dette diagram har lignende præstationsmålinger som det foregående diagram.
![]()
Dashboards i realtid
Overvågning og observerbarhed er et vigtigt krav for enhver kritisk forretningsapplikation, såsom handelsrapportering, risikostyring og handelsstyringssystemer. Ud over målinger på systemniveau er det også vigtigt at overvåge nøglepræstationsindikatorer i realtid, så operatører kan blive advaret og reagere så hurtigt som muligt på forretningspåvirkende begivenheder. Til denne demonstration har vi bygget dashboards i Grafana, der overvåger forsinkelsen af tilbuds- og handelsdata fra henholdsvis Kinesis-datastrømmen og Aurora.
Dashboardet for forsinkelse af tilbudsoptagelsesforsinkelse viser den tid, det tager for hver tilbudspost at blive optaget fra datastrømmen og være tilgængelig for forespørgsler i Amazon Redshift.
![]()
Dashboardet for handelsindtagelsesforsinkelse viser den tid, det tager for en transaktion i Aurora at blive tilgængelig i Amazon Redshift til forespørgsel.
![]()
Ryd op
For at rydde op i dine ressourcer skal du slette den stak, du implementerede ved hjælp af AWS CloudFormation. For instruktioner, se Sletning af en stak på AWS CloudFormation-konsollen.
Konklusion
Stigende mængder af handelsaktivitet, mere kompleks risikostyring og forbedrede regulatoriske krav får kapitalmarkedsvirksomheder til at omfavne databehandling i realtid og næsten-realtid, selv i midt- og backoffice-platforme, hvor dags- og nattens behandling var standarden. I dette indlæg demonstrerede vi, hvordan du kan bruge Amazon Redshift-funktioner til brugervenlighed, lav vedligeholdelse og omkostningseffektivitet. Vi diskuterede også integrationer på tværs af tjenester for at indtage streaming af markedsdata, behandle opdateringer fra OLTP-databaser og bruge tredjeparts referencedata uden at skulle udføre kompleks og dyr ETL- eller ELT-behandling, før dataene blev tilgængelige for analyse og rapportering.
Kontakt os venligst, hvis du har brug for vejledning i implementeringen af denne løsning. Henvise til Realtidsanalyse med Amazon Redshift-streamingindtagelse, Kom godt i gang-guide til operationsanalyse i næsten realtid ved hjælp af Amazon Aurora nul-ETL-integration med Amazon Redshiftog Arbejde med AWS Data Exchange-dataandele som producent for mere information.
Om forfatterne
![]() Satesh Sonti er en Sr. Analytics Specialist Solutions Architect baseret i Atlanta, specialiseret i at bygge virksomhedsdataplatforme, data warehousing og analyseløsninger. Han har over 18 års erfaring med at bygge dataaktiver og lede komplekse dataplatformsprogrammer til bank- og forsikringskunder over hele kloden.
Satesh Sonti er en Sr. Analytics Specialist Solutions Architect baseret i Atlanta, specialiseret i at bygge virksomhedsdataplatforme, data warehousing og analyseløsninger. Han har over 18 års erfaring med at bygge dataaktiver og lede komplekse dataplatformsprogrammer til bank- og forsikringskunder over hele kloden.
![]() Alket Memushaj arbejder som Principal Architect i Financial Services Market Development-teamet hos AWS. Alket er ansvarlig for den tekniske strategi for kapitalmarkederne og arbejder sammen med partnere og kunder for at implementere applikationer på tværs af handelslivscyklussen til AWS Cloud, herunder markedsforbindelse, handelssystemer og analyse- og forskningsplatforme før og efter handel.
Alket Memushaj arbejder som Principal Architect i Financial Services Market Development-teamet hos AWS. Alket er ansvarlig for den tekniske strategi for kapitalmarkederne og arbejder sammen med partnere og kunder for at implementere applikationer på tværs af handelslivscyklussen til AWS Cloud, herunder markedsforbindelse, handelssystemer og analyse- og forskningsplatforme før og efter handel.
![]() Ruben Falk er en kapitalmarkedsspecialist med fokus på kunstig intelligens og data og analyser. Ruben rådfører sig med kapitalmarkedsdeltagere om moderne dataarkitektur og systematiske investeringsprocesser. Han kom til AWS fra S&P Global Market Intelligence, hvor han var Global Head of Investment Management Solutions.
Ruben Falk er en kapitalmarkedsspecialist med fokus på kunstig intelligens og data og analyser. Ruben rådfører sig med kapitalmarkedsdeltagere om moderne dataarkitektur og systematiske investeringsprocesser. Han kom til AWS fra S&P Global Market Intelligence, hvor han var Global Head of Investment Management Solutions.
![]() jeff wilson er en verdensomspændende Go-to-market Specialist med 15 års erfaring med at arbejde med analytiske platforme. Hans nuværende fokus er at dele fordelene ved at bruge Amazon Redshift, Amazons native cloud data warehouse. Jeff er baseret i Florida og har været hos AWS siden 2019.
jeff wilson er en verdensomspændende Go-to-market Specialist med 15 års erfaring med at arbejde med analytiske platforme. Hans nuværende fokus er at dele fordelene ved at bruge Amazon Redshift, Amazons native cloud data warehouse. Jeff er baseret i Florida og har været hos AWS siden 2019.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/combine-transactional-streaming-and-third-party-data-on-amazon-redshift-for-financial-services/
- :har
- :er
- :ikke
- :hvor
- ][s
- $OP
- 1
- 10
- 100
- 130
- 15 år
- 15 %
- 150
- 16
- 20
- 2019
- 27
- 30
- a
- I stand
- Om
- adgang
- Adgang
- tværs
- aktivitet
- Yderligere
- Derudover
- klæber
- vedtage
- Fordel
- adx
- Efter
- aggregat
- aggregering
- AI
- Alle
- tillade
- også
- Amazon
- Amazon administrerede Grafana
- Amazon QuickSight
- Amazon Web Services
- beløb
- an
- analyse
- Analytikere
- Analytisk
- analytics
- analysere
- ,
- enhver
- fra hinanden
- Anvendelse
- applikationer
- anvendt
- tilgang
- arkitektur
- arkitekturer
- ER
- AS
- spørg
- Aktiver
- At
- Atlanta
- attributter
- Aurora
- auto
- til rådighed
- gennemsnit
- AWS
- AWS CloudFormation
- b
- Balanceret
- Bank
- baseret
- BE
- fordi
- bliver
- været
- før
- Benchmarks
- fordele
- mellem
- bud
- Billion
- til
- både
- mægler
- bygge
- Bygning
- bygget
- virksomhed
- business intelligence
- Forretningstransformation
- men
- by
- cache
- beregne
- beregning
- beregning
- CAN
- kapaciteter
- Kapacitet
- kapital
- Kapitalmarkeder
- tilfælde
- tilfælde
- CBOE
- udfordre
- karakteristika
- Chart
- ren
- kunder
- Luk
- Cloud
- kode
- kombinerer
- Kom
- færdiggørelse
- komplekse
- komponenter
- omfattende
- Compute
- Tilslutninger
- Connectivity
- forbruger
- forbrug
- indeholder
- løbende
- kopier
- skabe
- oprettet
- skaber
- krise
- kritisk
- Nuværende
- For øjeblikket
- skik
- Kunder
- dagligt
- instrumentbræt
- dashboards
- data
- Dataudveksling
- datastyring
- Dataplatform
- datapunkter
- databehandling
- datadeling
- datalager
- datavarehuse
- databaser
- datasæt
- Dato
- dag
- falde
- forsinkelse
- levere
- krav
- demonstreret
- indsætte
- indsat
- dybde
- beskriver
- detaljeret
- detaljer
- udvikling
- Udvikling
- udviklingsteam
- diagram
- forskellige
- direkte
- retning
- direkte
- drøftet
- dårskab
- Dollar
- hver
- lette
- brugervenlighed
- omfavne
- muliggøre
- ende
- forbedret
- Forbedrer
- Enterprise
- Ether (ETH)
- evaluere
- Endog
- begivenheder
- Hver
- eksempler
- udveksling
- Udvekslinger
- dyrt
- erfaring
- udforske
- ekstern
- ekstrakt
- Feature
- Funktionalitet
- få
- udfylde
- finansielle
- finanskrise
- finansielle data
- Finansielle institutioner
- finansielle tjenesteydelser
- Finde
- firmaer
- florida
- Fokus
- fokuserede
- efter
- Til
- rammer
- Frekvens
- hyppigt
- fra
- Fundamentals
- generere
- generere
- få
- Global
- globale finansielle
- Global Financial Crisis
- globale marked
- kloden
- Gå-på-marked
- gruppe
- Dyrkning
- Vokser
- vejledning
- vejlede
- vejledende
- håndtere
- Have
- have
- he
- hoved
- Helse
- Fremhæv
- hans
- historisk
- Hvordan
- How To
- HTML
- http
- HTTPS
- kæmpe
- if
- illustrerer
- gennemføre
- gennemføre
- vigtigt
- in
- omfatter
- omfatter
- Herunder
- Forøg
- øget
- Indikatorer
- individuel
- oplysninger
- indgange
- institutioner
- anvisninger
- forsikring
- integrere
- integration
- integrationer
- Intelligens
- interagere
- ind
- intuitiv
- investere
- investering
- isolation
- IT
- deltage
- sluttede
- Sammenføjninger
- jpg
- Nøgle
- Kinesis datastrømme
- Latency
- lancere
- førende
- LÆR
- mindre
- livscyklus
- ligesom
- Likviditet
- belastning
- lastning
- lokale
- lokalt
- leder
- Lav
- vedligeholdelse
- større
- lave
- Making
- lykkedes
- ledelse
- Ledere
- kortlægning
- Marked
- Markedsdata
- Markedsvolatilitet
- markedsplads
- Markeder
- betyder
- målinger
- Metode
- Metrics
- Moderne
- penge
- Overvåg
- overvågning
- måned
- mere
- flere
- MySQL
- Nasdaq
- indfødte
- indbygget
- nødvendig
- Behov
- Ny
- New York
- New York Stock Exchange
- næste
- Bemærk
- NYSE
- opnå
- of
- tit
- on
- kun
- åbent
- betjene
- operationelle
- Produktion
- Operatører
- optimering
- Optimer
- or
- ordrer
- organisation
- Andet
- ud
- i løbet af
- samlet
- overnight
- deltagere
- partnerskab
- partnere
- udføre
- ydeevne
- Tilladelser
- Place
- placeret
- perron
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- punkter
- mulig
- Indlæg
- efter handel
- forud
- pris
- Main
- principper
- prioritering
- procedurer
- behandle
- bearbejdet
- Processer
- forarbejdning
- Programmer
- beskytte
- give
- udbyder
- kvalitet
- forespørgsler
- query
- hurtigt
- citere
- citater
- Sats
- nå
- ægte
- realtid
- optage
- henvise
- henvisningen
- fast
- Regulators
- lovgivningsmæssige
- relaterede
- relevant
- Rapportering
- Rapporter
- kræver
- krav
- Krav
- forskning
- Ressourcer
- henholdsvis
- Svar
- ansvarlige
- gennemgå
- Risiko
- risikostyring
- regler
- Kør
- løber
- S & P
- S&P Global
- samme
- skalerbar
- Scale
- kontrol
- problemfrit
- sekunder
- Sektion
- sektor
- Sektorer
- Vælg
- Tjenester
- flere
- Aktier
- deling
- bør
- Shows
- signifikant
- lignende
- Tilsvarende
- Simpelt
- forenkler
- siden
- So
- Software
- løsninger
- Løsninger
- nogle
- Snart
- Kilde
- indkøbt
- Kilder
- specialist
- specialiserede
- krydderi
- spredes
- Spreads
- SQL
- stable
- standard
- påbegyndt
- Starter
- Trin
- bestand
- Børs
- opbevaring
- butik
- opbevaret
- ligetil
- Strategi
- strøm
- streaming
- vandløb
- sådan
- sum
- support
- Understøttet
- systemet
- Systemer
- bord
- Tag
- tager
- mål
- hold
- hold
- Teknisk
- Teknologier
- skabelon
- vilkår
- end
- at
- deres
- Them
- derefter
- Disse
- de
- tredjepart
- tredjepartsdata
- denne
- dem
- tre
- Gennem
- tid
- til
- I alt
- handle
- handles
- handler
- Trading
- transaktion
- transaktionsbeslutning
- Transform
- Transformation
- Gennemsigtighed
- typer
- typisk
- under
- ubegrænset
- opdateringer
- us
- brug
- anvendte
- Bruger
- brugere
- ved brug af
- via
- Specifikation
- visninger
- næsten
- synlighed
- Volatilitet
- bind
- mængder
- ønsker
- Warehouse
- Warehousing
- var
- we
- web
- webservices
- vægt
- var
- hvornår
- som
- WHO
- med
- uden
- arbejder
- virker
- skrivning
- yaml
- år
- york
- dig
- Din
- zephyrnet