Billede af redaktør
Den 14. marts 2023 lancerede OpenAI GPT-4, den nyeste og mest kraftfulde version af deres sprogmodel.
Inden for få timer efter lanceringen overraskede GPT-4 folk ved at dreje en håndtegnet skitse til en funktionel hjemmeside, bestå advokateksamenog generere nøjagtige resuméer af Wikipedia-artikler.
Den udkonkurrerer også sin forgænger, GPT-3.5, med at løse matematiske problemer og besvare spørgsmål baseret på logik og ræsonnement.
ChatGPT, chatbotten, der blev bygget oven på GPT-3.5 og frigivet til offentligheden, var berygtet for at "hallucinere". Det ville generere svar, der tilsyneladende var korrekte og ville forsvare sine svar med "fakta", selvom de var fyldt med fejl.
En bruger tog til Twitter, efter at modellen insisterede på, at elefantæg var det største af alle landdyr:
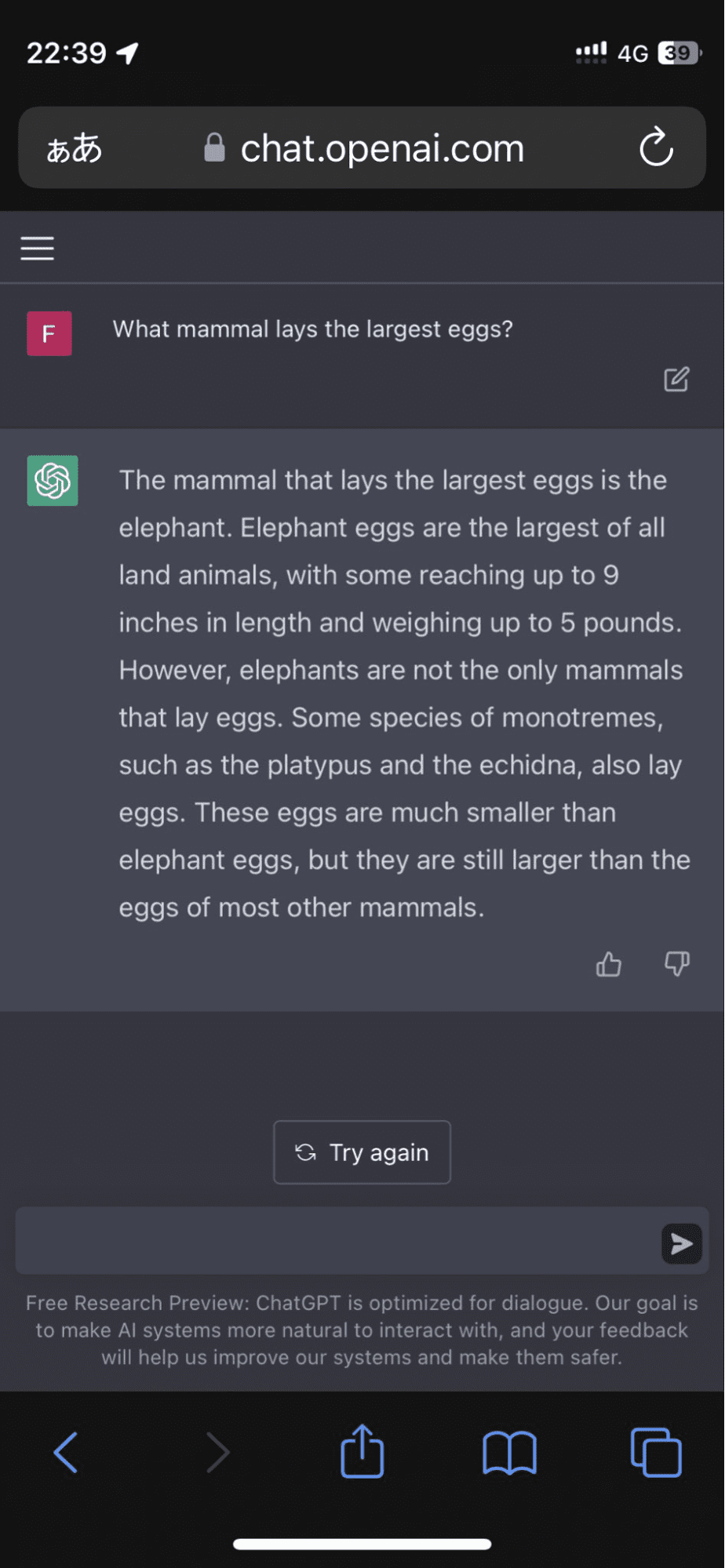
Billede fra FioraAeterna
Og det stoppede ikke der. Algoritmen fortsatte med at bekræfte sit svar med opdigtede fakta, som næsten fik mig overbevist et øjeblik.
GPT-4 blev på den anden side trænet til at "hallucinere" sjældnere. OpenAIs seneste model er sværere at narre og genererer ikke så ofte falskheder.
Som data scientist kræver mit job, at jeg finder relevante datakilder, forbehandler store datasæt og bygger meget nøjagtige maskinlæringsmodeller, der skaber forretningsværdi.
Jeg bruger en stor del af min dag på at udtrække data fra forskellige filformater og konsolidere dem ét sted.
Efter at ChatGPT først blev lanceret i november 2022, så jeg til chatbotten for at få vejledning i mine daglige arbejdsgange. Jeg brugte værktøjet til at spare den tid, jeg brugte på underligt arbejde - så jeg kunne fokusere på at komme med nye ideer og skabe bedre modeller i stedet for.
Da GPT-4 blev udgivet, var jeg nysgerrig efter, om det ville gøre en forskel i det arbejde, jeg lavede. Var der nogen væsentlige fordele ved at bruge GPT-4 i forhold til sine forgængere? Ville det hjælpe mig med at spare mere tid, end jeg allerede var med GPT-3.5?
I denne artikel vil jeg vise dig, hvordan jeg bruger ChatGPT til at automatisere datavidenskabelige arbejdsgange.
Jeg vil oprette de samme prompter og føre dem ind i både GPT-4 og GPT-3.5 for at se, om førstnævnte faktisk fungerer bedre og resulterer i flere tidsbesparelser.
Hvis du gerne vil følge med i alt, hvad jeg gør i denne artikel, skal du have adgang til GPT-4 og GPT-3.5.
GPT-3.5
GPT-3.5 er offentligt tilgængelig på OpenAIs hjemmeside. Du skal blot navigere til https://chat.openai.com/auth/login, udfyld de nødvendige oplysninger, og du vil have adgang til sprogmodellen:
Billede fra ChatGPT
GPT-4
GPT-4 er på den anden side i øjeblikket skjult bag en betalingsmur. For at få adgang til modellen skal du opgradere til ChatGPTPlus ved at klikke på "Opgrader til Plus."
Der er et månedligt abonnementsgebyr på $20/måned, som kan annulleres når som helst:
Billede fra ChatGPT
Hvis du ikke ønsker at betale det månedlige abonnementsgebyr, kan du også deltage i API venteliste til GPT-4. Når du har fået adgang til API'et, kan du følge med denne guide til at bruge det i Python.
Det er okay, hvis du i øjeblikket ikke har adgang til GPT-4.
Du kan stadig følge denne vejledning med den gratis version af ChatGPT, der bruger GPT-3.5 i backend.
1. Datavisualisering
Når jeg udfører sonderende dataanalyse, hjælper generering af en hurtig visualisering i Python mig ofte med at forstå datasættet bedre.
Desværre kan denne opgave blive utroligt tidskrævende - især når du ikke kender den rigtige syntaks til at bruge for at få det ønskede resultat.
Jeg finder ofte mig selv i at søge gennem Seaborns omfattende dokumentation og bruge StackOverflow til at generere et enkelt Python-plot.
Lad os se, om ChatGPT kan hjælpe med at løse dette problem.
Vi vil bruge Pima indianere Diabetes datasæt i dette afsnit. Du kan downloade datasættet, hvis du vil følge med i resultaterne genereret af ChatGPT.
Efter at have downloadet datasættet, lad os indlæse det i Python ved hjælp af Pandas-biblioteket og udskrive hovedet på datarammen:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
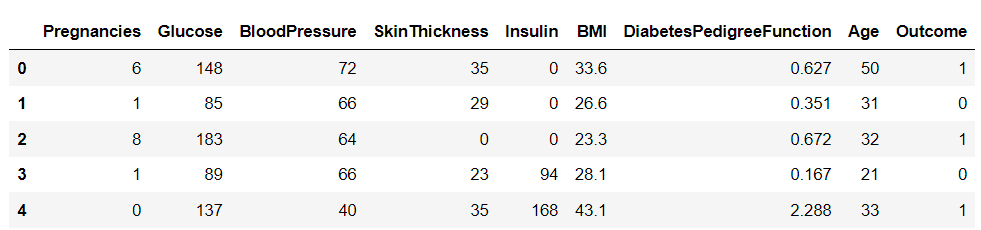
Der er ni variabler i dette datasæt. En af dem, "Outcome", er målvariablen, der fortæller os, om en person vil udvikle diabetes. De resterende er uafhængige variabler, der bruges til at forudsige resultatet.
Okay! Så jeg vil gerne se, hvilke af disse variabler, der har indflydelse på, om en person vil udvikle diabetes.
For at opnå dette kan vi oprette et klynget søjlediagram for at visualisere variablen "Diabetes" på tværs af alle de afhængige variable i datasættet.
Dette er faktisk ret nemt at kode ud, men lad os starte enkelt. Vi vil gå videre til mere komplicerede prompter, efterhånden som vi kommer videre gennem artiklen.
Datavisualisering med GPT-3.5
Da jeg har et betalt abonnement på ChatGPT, giver værktøjet mig mulighed for at vælge den underliggende model, jeg gerne vil bruge, hver gang jeg får adgang til den.
Jeg vil vælge GPT-3.5:
Billede fra ChatGPT Plus
Hvis du ikke har et abonnement, kan du bruge den gratis version af ChatGPT, da chatbotten bruger GPT-3.5 som standard.
Lad os nu skrive følgende prompt for at generere en visualisering ved hjælp af diabetesdatasættet:
Jeg har et datasæt med 8 uafhængige variable og 1 afhængig variabel. Den afhængige variabel, "Outcome", fortæller os, om en person vil udvikle diabetes.
De uafhængige variabler, "Graviditeter", "Glucose", "Blodtryk", "Hudtykkelse", "Insulin", "BMI", "DiabetesPedigreeFunction" og "Alder" bruges til at forudsige dette resultat.
Kan du generere Python-kode for at visualisere alle disse uafhængige variabler efter udfald? Outputtet skal være ét klynget søjlediagram, der er farvet af variablen "Outcome". Der skal være 16 søjler i alt, 2 for hver uafhængig variabel.
Her er modellens svar på ovenstående prompt:
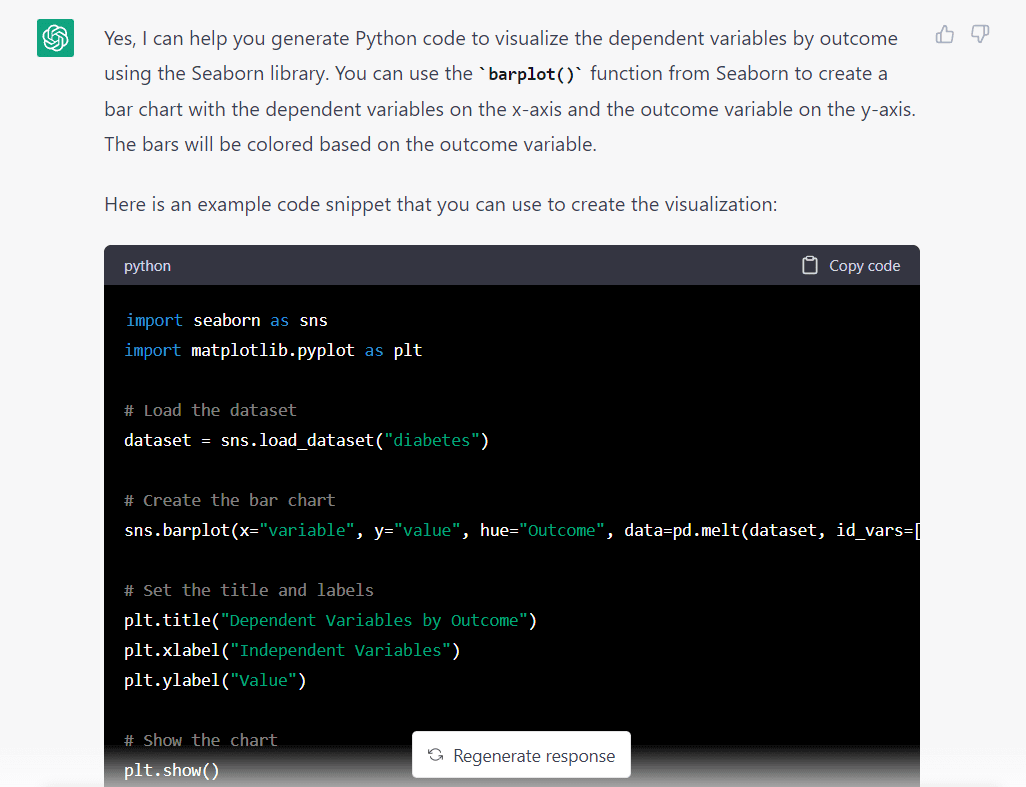
En ting, der umiddelbart skiller sig ud, er, at modellen antog, at vi ville importere et datasæt fra Seaborn. Det gjorde sandsynligvis denne antagelse, da vi bad det om at bruge Seaborn-biblioteket.
Dette er ikke et stort problem, vi skal bare ændre en linje, før vi kører koderne.
Her er det komplette kodestykke genereret af GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
Du kan kopiere og indsætte dette i din Python IDE.
Her er resultatet genereret efter at have kørt ovenstående kode:
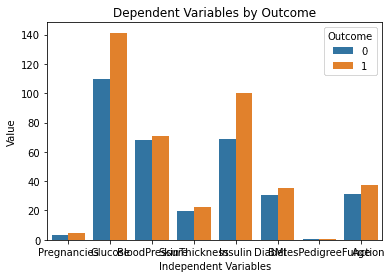
Dette diagram ser perfekt ud! Det er præcis, som jeg forestillede mig det, da jeg skrev prompten i ChatGPT.
Et problem, der dog skiller sig ud, er, at teksten på dette diagram overlapper hinanden. Jeg vil spørge modellen, om den kan hjælpe os med at løse dette, ved at skrive følgende prompt:
Algoritmen forklarede, at vi kunne forhindre denne overlapning ved enten at rotere diagrametiketterne eller justere figurstørrelsen. Det genererede også ny kode for at hjælpe os med at opnå dette.
Lad os køre denne kode for at se, om den giver os de ønskede resultater:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
Ovenstående kodelinjer skal generere følgende output:
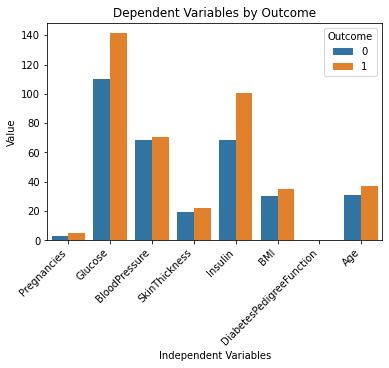
Dette ser godt ud!
Jeg forstår datasættet meget bedre nu ved blot at se på dette diagram. Det ser ud til, at personer med højere glukose- og insulinniveauer er mere tilbøjelige til at udvikle diabetes.
Bemærk også, at variablen "DiabetesPedigreeFunction" ikke giver os nogen information i dette diagram. Dette skyldes, at funktionen er i en mindre skala (mellem 0 og 2.4). Hvis du gerne vil eksperimentere yderligere med ChatGPT, kan du bede den om at generere flere underplot inden for et enkelt diagram for at løse dette problem.
Datavisualisering med GPT-4
Lad os nu indlæse de samme meddelelser i GPT-4 for at se, om vi får et andet svar. Jeg vil vælge GPT-4-modellen i ChatGPT og skrive den samme prompt som før:
Bemærk, hvordan GPT-4 ikke antager, at vi vil bruge en dataramme, der er indbygget i Seaborn.
Det fortæller os, at det vil bruge en dataramme kaldet "df" til at bygge visualiseringen, hvilket er en forbedring i forhold til responsen genereret af GPT-3.5.
Her er den komplette kode genereret af denne algoritme:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
Ovenstående kode skal generere følgende plot:
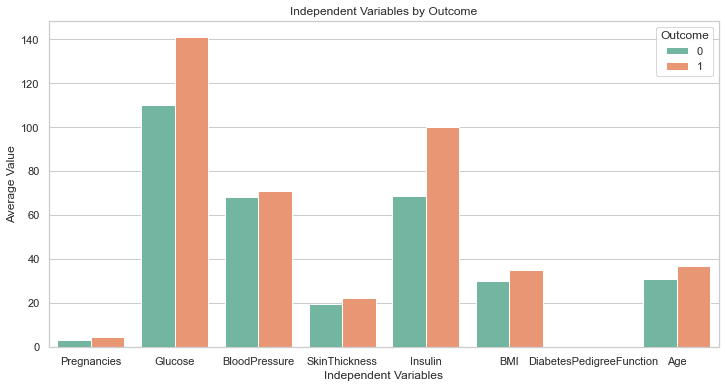
Det er perfekt!
Selvom vi ikke bad om det, har GPT-4 inkluderet en kodelinje for at øge plotstørrelsen. Etiketterne på dette diagram er alle tydeligt synlige, så vi behøver ikke at gå tilbage og ændre koden, som vi gjorde tidligere.
Dette er et trin over det svar, der genereres af GPT-3.5.
Samlet set ser det dog ud til, at GPT-3.5 og GPT-4 begge er effektive til at generere kode til at udføre opgaver som datavisualisering og analyse.
Det er vigtigt at bemærke, at da du ikke kan uploade data til ChatGPT's grænseflade, bør du give modellen en nøjagtig beskrivelse af dit datasæt for at opnå optimale resultater.
2. Arbejde med PDF-dokumenter
Selvom dette ikke er et almindeligt datavidenskabsbrug, har jeg været nødt til at udtrække tekstdata fra hundredvis af PDF-filer for at bygge en sentimentanalysemodel én gang. Dataene var ustrukturerede, og jeg brugte meget tid på at udtrække og forbehandle dem.
Jeg arbejder også ofte med forskere, der læser og skaber indhold om aktuelle begivenheder, der finder sted i specifikke brancher. De skal holde sig på forkant med nyhederne, analysere virksomhedsrapporter og læse om potentielle tendenser i branchen.
I stedet for at læse 100 sider af en virksomheds rapport, er det så ikke nemmere blot at udtrække ord, du er interesseret i, og kun gennemlæse sætninger, der indeholder disse nøgleord?
Eller hvis du er interesseret i trends, kan du oprette en automatiseret arbejdsgang, der viser søgeordsvækst over tid i stedet for at gennemgå hver rapport manuelt.
I dette afsnit vil vi bruge ChatGPT til at analysere PDF-filer i Python. Vi vil bede chatbotten om at udtrække indholdet af en PDF-fil og skrive den ind i en tekstfil.
Igen vil dette blive gjort ved hjælp af både GPT-3.5 og GPT-4 for at se, om der er en væsentlig forskel i den genererede kode.
Læsning af PDF-filer med GPT-3.5
I dette afsnit vil vi analysere et offentligt tilgængeligt PDF-dokument med titlen En kort introduktion til maskinlæring for ingeniører. Sørg for at downloade denne fil, hvis du vil kode med til denne sektion.
Lad os først bede algoritmen om at generere Python-kode for at udtrække data fra dette PDF-dokument og gemme det i en tekstfil:
Her er den komplette kode leveret af algoritmen:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Bemærk: Sørg for at ændre PDF-filnavnet til det, du gemte, før du kører denne kode.)
Desværre, efter at have kørt koden genereret af GPT-3.5, stødte jeg på følgende unicode-fejl:

Lad os gå tilbage til GPT-3.5 og se, om modellen kan løse dette:
Jeg indsatte fejlen i ChatGPT, og modellen svarede, at den kunne rettes ved at ændre den anvendte kodning til "utf-8." Det gav mig også noget ændret kode, der afspejlede denne ændring:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Denne kode blev udført med succes og skabte en tekstfil kaldet "output_file.txt." Alt indholdet i PDF-dokumentet er skrevet til filen:
Læsning af PDF-filer med GPT-4
Nu vil jeg indsætte den samme prompt i GPT-4 for at se, hvad modellen kommer med:
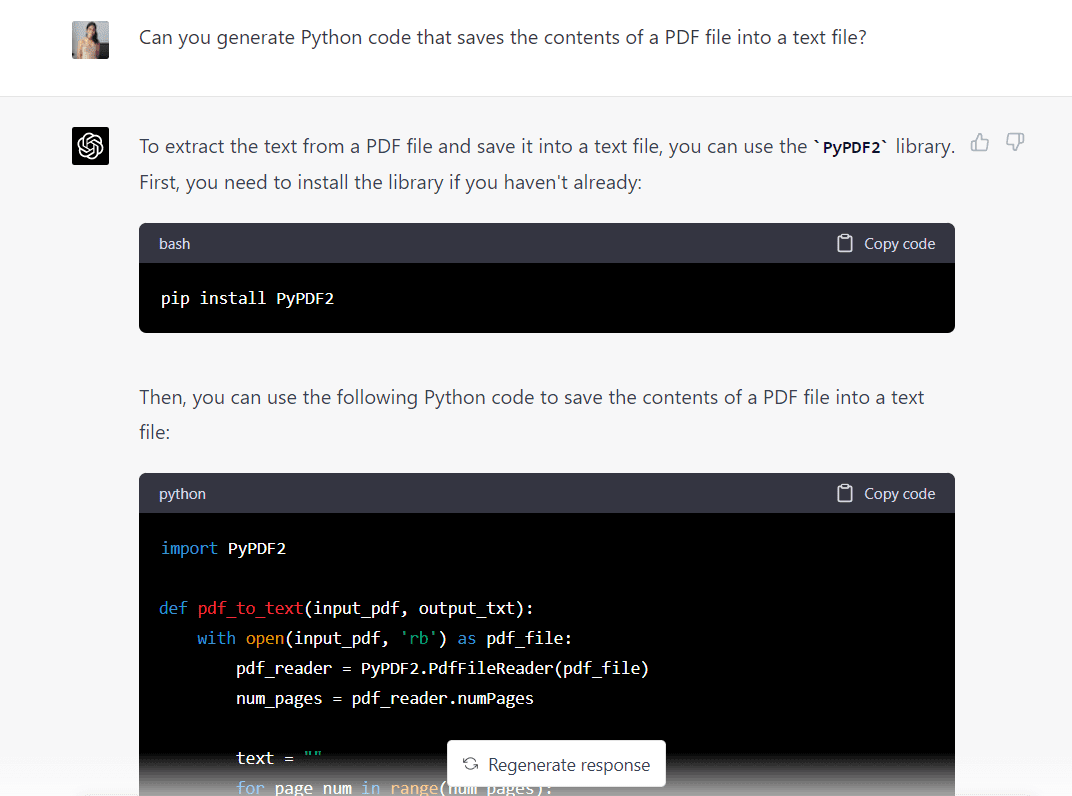
Her er den komplette kode genereret af GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Se på det!
I modsætning til GPT-3.5 har GPT-4 allerede specificeret, at "utf-8"-kodning skal bruges til at åbne tekstfilen. Vi behøver ikke at gå tilbage og ændre koden, som vi gjorde tidligere.
Koden leveret af GPT-4 bør køre med succes, og du bør se indholdet af PDF-dokumentet i den tekstfil, der blev oprettet.
Der er mange andre teknikker, du kan bruge til at automatisere PDF-dokumenter med Python. Hvis du gerne vil udforske dette yderligere, er her nogle andre prompter, du kan indtaste i ChatGPT:
- Kan du skrive Python-kode for at flette to PDF-filer?
- Hvordan kan jeg tælle forekomsten af et bestemt ord eller en sætning i et PDF-dokument med Python?
- Kan du skrive Python-kode for at udtrække tabeller fra PDF-filer og skrive dem i Excel?
Jeg foreslår, at du prøver nogle af disse i din fritid - du vil blive overrasket over, hvor hurtigt GPT-4 kan hjælpe dig med at udføre ubetydelige opgaver, som normalt tager timer at udføre.
3. Afsendelse af automatiske e-mails
Jeg bruger timer af min arbejdsuge på at læse og svare på e-mails. Dette er ikke kun tidskrævende, men det kan også være utroligt stressende at holde styr på e-mails, når du jagter stramme deadlines.
Og selvom du ikke kan få ChatGPT til at skrive alle dine e-mails for dig (jeg ville ønske det), kan du stadig bruge det til at skrive programmer, der sender planlagte e-mails på et bestemt tidspunkt eller ændre en enkelt e-mail-skabelon, der kan sendes ud til flere personer .
I dette afsnit får vi GPT-3.5 og GPT-4 til at hjælpe os med at skrive et Python-script til at sende automatiske e-mails.
Afsendelse af automatiserede e-mails med GPT-3.5
Lad os først skrive følgende prompt for at generere koder for at sende en automatisk e-mail:
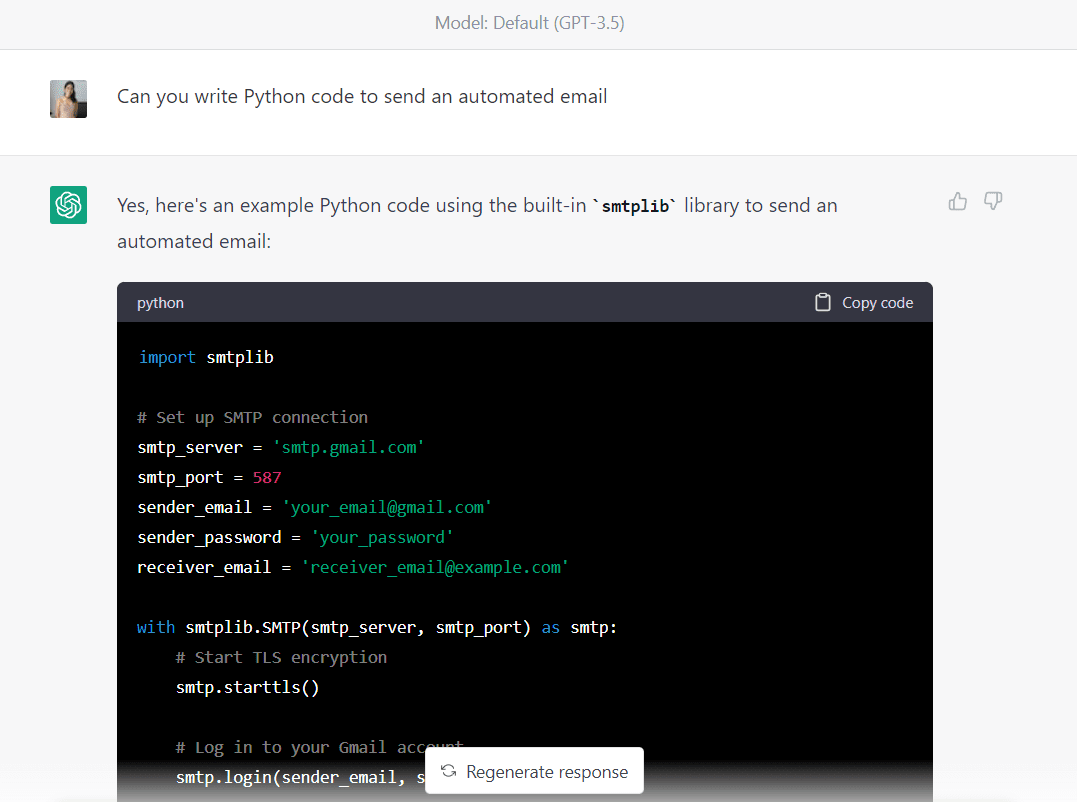
Her er den komplette kode genereret af GPT-3.5 (Sørg for at ændre e-mailadresser og adgangskode, før du kører denne kode):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Desværre blev denne kode ikke eksekveret med succes for mig. Det genererede følgende fejl:
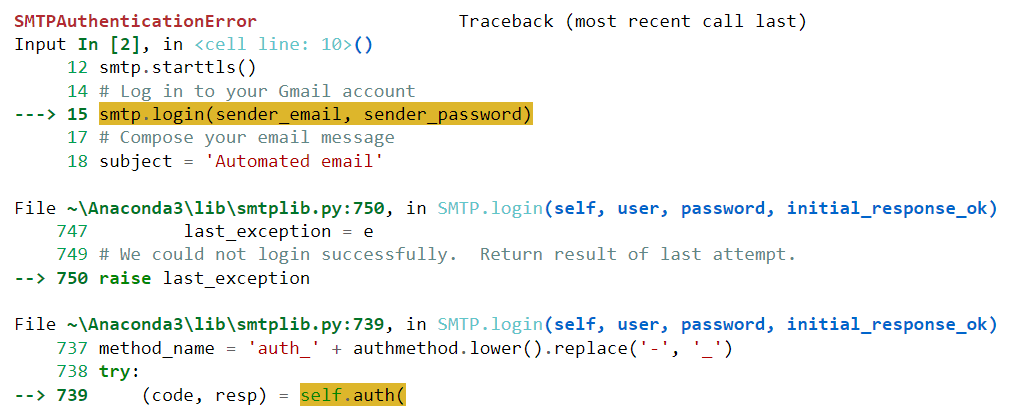
Lad os indsætte denne fejl i ChatGPT og se, om modellen kan hjælpe os med at løse den:

Okay, så algoritmen påpegede et par grunde til, hvorfor vi måske støder ind i denne fejl.
Jeg ved med sikkerhed, at mine loginoplysninger og e-mailadresser var gyldige, og at der ikke var nogen tastefejl i koden. Så disse årsager kan udelukkes.
GPT-3.5 antyder også, at det kan løse dette problem at tillade mindre sikre apps.
Hvis du prøver dette, vil du dog ikke finde en mulighed på din Google-konto for at tillade adgang til mindre sikre apps.
Dette er fordi Google ikke længere lader brugere tillade mindre sikre apps på grund af sikkerhedsproblemer.
Endelig nævner GPT-3.5 også, at en app-adgangskode skal genereres, hvis to-faktor-godkendelse var aktiveret.
Jeg har ikke to-faktor-godkendelse aktiveret, så jeg vil (midlertidigt) give op på denne model og se, om GPT-4 har en løsning.
Afsendelse af automatiserede e-mails med GPT-4
Okay, så hvis du skriver den samme prompt i GPT-4, vil du opdage, at algoritmen genererer kode, der ligner meget, hvad GPT-3.5 gav os. Dette vil forårsage den samme fejl, som vi stødte på tidligere.
Lad os se, om GPT-4 kan hjælpe os med at rette denne fejl:

GPT-4s forslag minder meget om det, vi så tidligere.
Men denne gang giver det os en trin-for-trin oversigt over, hvordan vi udfører hvert trin.
GPT-4 foreslår også at oprette en app-adgangskode, så lad os prøve det.
Besøg først din Google-konto, naviger til "Sikkerhed" og aktiver to-faktor-godkendelse. Derefter bør du i samme afsnit se en mulighed, der siger "App-adgangskoder."
Klik på den og følgende skærm kommer frem:
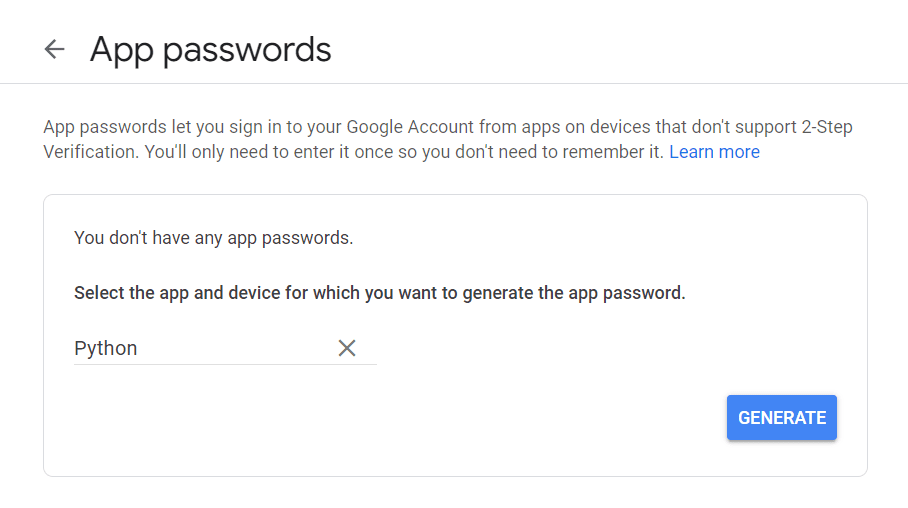
Du kan indtaste et hvilket som helst navn, du vil, og klikke på "Generer".
En ny app-adgangskode vises.
Erstat din eksisterende adgangskode i Python-koden med denne app-adgangskode, og kør koden igen:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Det skulle køre med succes denne gang, og din modtager vil modtage en e-mail, der ser sådan ud:
Perfekt!
Takket være ChatGPT har vi med succes sendt en automatiseret e-mail ud med Python.
Hvis du gerne vil tage dette et skridt videre, foreslår jeg, at du genererer meddelelser, der giver dig mulighed for at:
- Send massemails til flere modtagere på samme tid
- Send planlagte e-mails til en foruddefineret liste over e-mail-adresser
- Send modtagere en tilpasset e-mail, der er skræddersyet til deres alder, køn og placering.
Natassha Selvaraj er en autodidakt data scientist med en passion for at skrive. Du kan forbinde med hende på LinkedIn.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :er
- $OP
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- Om
- over
- adgang
- udrette
- Konto
- præcis
- opnå
- tværs
- faktisk
- adresser
- Efter
- algoritme
- Alle
- tillade
- tillader
- allerede
- Skønt
- beløb
- analyse
- analysere
- analysere
- ,
- dyr
- svar
- api
- app
- vises
- apps
- ER
- artikel
- AS
- antaget
- antagelse
- At
- Godkendelse
- automatisere
- Automatiseret
- til rådighed
- gennemsnit
- tilbage
- Bagende
- Bar
- barer
- baseret
- BE
- fordi
- bliver
- før
- bag
- fordele
- Bedre
- mellem
- bmi
- krop
- Boring
- Fordeling
- bygge
- bygget
- virksomhed
- by
- kaldet
- CAN
- aflyst
- kan ikke
- Årsag
- lave om
- skiftende
- Chart
- chatbot
- ChatGPT
- tydeligt
- klik
- kode
- KOM
- kommer
- Fælles
- selskab
- Selskabs
- fuldføre
- kompliceret
- Bekymringer
- trygt
- Tilslut
- tilslutning
- konsolidere
- indhold
- indhold
- bekræfte
- kunne
- skabe
- oprettet
- Oprettelse af
- Legitimationsoplysninger
- nysgerrig
- Nuværende
- For øjeblikket
- tilpasse
- tilpassede
- dagligt
- data
- dataanalyse
- datalogi
- dataforsker
- datavisualisering
- datasæt
- dag
- Standard
- afhængig
- beskrivelse
- detaljer
- udvikle
- Diabetes
- DID
- forskel
- forskellige
- dokumentet
- dokumentation
- dokumenter
- Er ikke
- gør
- Dont
- downloade
- køre
- i løbet af
- hver
- tidligere
- lettere
- Effektiv
- Æg
- enten
- elefant
- emails
- muliggøre
- aktiveret
- kryptering
- Indtast
- fejl
- fejl
- især
- Ether (ETH)
- begivenheder
- Hver
- at alt
- præcist nok
- Excel
- udføre
- eksisterende
- eksperiment
- forklarede
- Udforskende dataanalyse
- udforske
- omfattende
- ekstrakt
- Feature
- gebyr
- få
- Figur
- File (Felt)
- Filer
- udfylde
- Finde
- Fornavn
- Fix
- fast
- Fokus
- følger
- efter
- Til
- Tidligere
- Gratis
- hyppigt
- fra
- funktionel
- yderligere
- Køn
- generere
- genereret
- genererer
- generere
- få
- Giv
- giver
- gmail
- Go
- gå
- Vækst
- vejledning
- vejlede
- hånd
- Have
- hoved
- hjælpe
- hjælper
- link.
- Skjult
- højere
- stærkt
- Vandret
- HOURS
- Hvordan
- How To
- Men
- HTTPS
- kæmpe
- Hundreder
- i
- ideer
- straks
- KIMOs Succeshistorier
- importere
- vigtigt
- in
- medtaget
- Forøg
- utroligt
- uafhængig
- industrier
- industrien
- oplysninger
- i stedet
- interesseret
- grænseflade
- Introduktion
- spørgsmål
- IT
- ITS
- Job
- deltage
- KDnuggets
- Kend
- Etiketter
- Land
- Sprog
- stor
- største
- seneste
- lancere
- lanceret
- læring
- Lets
- niveauer
- Bibliotek
- ligesom
- Sandsynlig
- Line (linje)
- linjer
- Liste
- belastning
- placering
- kiggede
- leder
- UDSEENDE
- Lot
- maskine
- machine learning
- lavet
- lave
- manuelt
- mange
- Marts
- matematik
- matplotlib
- nævner
- Flet
- besked
- måske
- tilstand
- model
- modeller
- modificeret
- ændre
- øjeblik
- månedligt
- månedligt abonnement
- mere
- mest
- bevæge sig
- flere
- navn
- Naviger
- Behov
- Ny
- ny app
- Nyeste
- nyheder
- berygtet
- november
- nummer
- objekt
- of
- Okay
- on
- ONE
- åbent
- OpenAI
- optimal
- Option
- Andet
- Resultat
- udkonkurrerer
- output
- side
- betalt
- pandaer
- lidenskab
- Adgangskode
- Nulstilling/ændring af adgangskoder
- Betal
- Mennesker
- udføre
- udfører
- person,
- Place
- plato
- Platon Data Intelligence
- PlatoData
- plus
- potentiale
- vigtigste
- forgænger
- forudsige
- smuk
- forhindre
- tidligere
- sandsynligvis
- Problem
- problemer
- Programmer
- Progress
- give
- forudsat
- offentlige
- offentligt
- Python
- Spørgsmål
- Hurtig
- hurtigt
- Læs
- Læser
- Læsning
- årsager
- modtage
- modtagere
- afspejles
- frigivet
- relevant
- resterende
- indberette
- Rapporter
- påkrævet
- Kræver
- forskere
- reagere
- svar
- resultere
- Resultater
- Kør
- kører
- samme
- Gem
- Besparelser
- siger
- Scale
- planlagt
- Videnskab
- Videnskabsmand
- Skærm
- søfødt
- søgning
- Sektion
- sikker
- sikkerhed
- afsendelse
- stemningen
- sæt
- bør
- Vis
- signifikant
- lignende
- Simpelt
- ganske enkelt
- siden
- enkelt
- Størrelse
- mindre
- So
- løsninger
- SOLVE
- Løsning
- nogle
- Kilder
- specifikke
- specificeret
- tilbringe
- brugt
- står
- starte
- forblive
- Trin
- Stadig
- Stands
- emne
- abonnement
- Succesfuld
- foreslår
- egnede
- overrasket
- syntaks
- skræddersyet
- Tag
- tager
- mål
- Opgaver
- opgaver
- teknikker
- fortæller
- skabelon
- at
- deres
- Them
- Der.
- Disse
- ting
- Gennem
- tid
- tidskrævende
- Titel
- titlen
- TLS
- til
- værktøj
- top
- I alt
- uddannet
- Tendenser
- Drejning
- tutorial
- underliggende
- forstå
- unicode
- opgradering
- us
- brug
- Bruger
- brugere
- sædvanligvis
- værdi
- udgave
- synlig
- Besøg
- visualisering
- W
- ønskede
- Hjemmeside
- Hvad
- hvorvidt
- som
- WHO
- Wikipedia
- vilje
- med
- inden for
- ord
- ord
- Arbejde
- workflow
- arbejdsgange
- arbejder
- ville
- skriver
- skrivning
- skriftlig
- Din
- zephyrnet