AWS-চালিত ডেটা লেক, এর অতুলনীয় প্রাপ্যতা দ্বারা সমর্থিত আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3), বিভিন্ন ডেটা এবং বিশ্লেষণ পদ্ধতি একত্রিত করার জন্য প্রয়োজনীয় স্কেল, তত্পরতা এবং নমনীয়তা পরিচালনা করতে পারে। যেহেতু ডেটা হ্রদ আকারে বেড়েছে এবং ব্যবহারে পরিপক্ক হয়েছে, তাই ব্যবসায়িক ইভেন্টগুলির সাথে ডেটা সামঞ্জস্য রেখে একটি উল্লেখযোগ্য পরিমাণ প্রচেষ্টা ব্যয় করা যেতে পারে। ফাইলগুলিকে লেনদেনগতভাবে সামঞ্জস্যপূর্ণভাবে আপডেট করা হয়েছে তা নিশ্চিত করতে, ক্রমবর্ধমান সংখ্যক গ্রাহক ওপেন-সোর্স লেনদেনের টেবিল ফর্ম্যাট ব্যবহার করছেন যেমন অ্যাপাচি আইসবার্গ, অ্যাপাচি হুদি, এবং লিনাক্স ফাউন্ডেশন ডেল্টা লেক যা আপনাকে উচ্চ কম্প্রেশন রেট সহ ডেটা সঞ্চয় করতে সাহায্য করে, আপনার অ্যাপ্লিকেশন এবং ফ্রেমওয়ার্কগুলির সাথে নেটিভ ইন্টারফেস করতে এবং Amazon S3-তে নির্মিত ডেটা লেকে ক্রমবর্ধমান ডেটা প্রক্রিয়াকরণকে সহজ করে। এই ফর্ম্যাটগুলি ACID (পরমাণু, সামঞ্জস্য, বিচ্ছিন্নতা, স্থায়িত্ব) লেনদেন, আপসার্ট এবং মুছে ফেলা এবং উন্নত বৈশিষ্ট্যগুলি যেমন সময় ভ্রমণ এবং স্ন্যাপশটগুলিকে সক্ষম করে যা আগে শুধুমাত্র ডেটা গুদামে উপলব্ধ ছিল৷ প্রতিটি স্টোরেজ ফরম্যাট এই কার্যকারিতাকে কিছুটা ভিন্ন উপায়ে প্রয়োগ করে; তুলনার জন্য, পড়ুন AWS-এ আপনার লেনদেন সংক্রান্ত ডেটা লেকের জন্য একটি খোলা টেবিল বিন্যাস নির্বাচন করা হচ্ছে.
2023 সালে AWS সাধারণ প্রাপ্যতা ঘোষণা করেছে Apache Iceberg, Apache Hudi এবং Linux ফাউন্ডেশন ডেল্টা লেকের জন্য Apache Spark এর জন্য Amazon Athena, যা একটি পৃথক সংযোগকারী বা সম্পর্কিত নির্ভরতা ইনস্টল করার এবং সংস্করণগুলি পরিচালনা করার প্রয়োজনীয়তাকে সরিয়ে দেয় এবং এই কাঠামোগুলি ব্যবহার করার জন্য প্রয়োজনীয় কনফিগারেশন পদক্ষেপগুলিকে সরল করে।
এই পোস্টে, আমরা আপনাকে দেখাই কিভাবে স্পার্ক এসকিউএল ব্যবহার করতে হয় অ্যামাজন অ্যাথেনা নোটবুক এবং আইসবার্গ, হুডি এবং ডেল্টা লেক টেবিল ফর্ম্যাটের সাথে কাজ করুন। আমরা সাধারণ ক্রিয়াকলাপগুলি প্রদর্শন করি যেমন ডাটাবেস এবং টেবিল তৈরি করা, টেবিলে ডেটা সন্নিবেশ করা, ডেটা অনুসন্ধান করা এবং অ্যাথেনায় স্পার্ক SQL ব্যবহার করে Amazon S3-এ টেবিলের স্ন্যাপশট দেখা।
পূর্বশর্ত
নিম্নলিখিত পূর্বশর্তগুলি সম্পূর্ণ করুন:
Amazon S3 থেকে উদাহরণ নোটবুক ডাউনলোড এবং আমদানি করুন
অনুসরণ করতে, এই পোস্টে আলোচনা করা নোটবুকগুলি নিম্নলিখিত অবস্থান থেকে ডাউনলোড করুন:
আপনি নোটবুকগুলি ডাউনলোড করার পরে, সেগুলি অনুসরণ করে আপনার এথেনা স্পার্ক পরিবেশে আমদানি করুন৷ একটি নোটবুক আমদানি করতে বিভাগে নোটবুক ফাইল পরিচালনা.
নির্দিষ্ট ওপেন টেবিল ফরম্যাট বিভাগে নেভিগেট করুন
আপনি যদি আইসবার্গ টেবিল বিন্যাসে আগ্রহী হন তবে নেভিগেট করুন অ্যাপাচি আইসবার্গ টেবিলের সাথে কাজ করা অধ্যায়.
আপনি যদি হুডি টেবিল ফরম্যাটে আগ্রহী হন, সেখানে নেভিগেট করুন Apache Hudi টেবিলের সাথে কাজ করা অধ্যায়.
আপনি যদি ডেল্টা লেক টেবিল বিন্যাসে আগ্রহী হন, নেভিগেট করুন লিনাক্স ফাউন্ডেশন ডেল্টা লেক টেবিলের সাথে কাজ করা অধ্যায়.
অ্যাপাচি আইসবার্গ টেবিলের সাথে কাজ করা
এথেনায় স্পার্ক নোটবুক ব্যবহার করার সময়, আপনি PySpark ব্যবহার না করেই সরাসরি SQL প্রশ্ন চালাতে পারেন। আমরা সেল ম্যাজিক ব্যবহার করে এটি করি, যা একটি নোটবুক সেলে বিশেষ শিরোনাম যা কোষের আচরণ পরিবর্তন করে। এসকিউএল-এর জন্য, আমরা যোগ করতে পারি %%sql ম্যাজিক, যা অ্যাথেনায় চালানোর জন্য একটি এসকিউএল স্টেটমেন্ট হিসাবে সমগ্র ঘরের বিষয়বস্তুকে ব্যাখ্যা করবে।
এই বিভাগে, আমরা দেখাই কিভাবে আপনি Apache Spark-এ Athena-এর জন্য Apache Iceberg টেবিল তৈরি, বিশ্লেষণ এবং পরিচালনা করতে ব্যবহার করতে পারেন।
একটি নোটবুক সেশন সেট আপ করুন
এথেনায় Apache Iceberg ব্যবহার করার জন্য, একটি সেশন তৈরি বা সম্পাদনা করার সময়, নির্বাচন করুন অ্যাপাচি আইসবার্গ প্রসারিত করে বিকল্প অ্যাপাচি স্পার্ক বৈশিষ্ট্য অধ্যায়. এটি নিম্নলিখিত স্ক্রিনশটে দেখানো বৈশিষ্ট্যগুলিকে প্রাক-পপুলেট করবে।
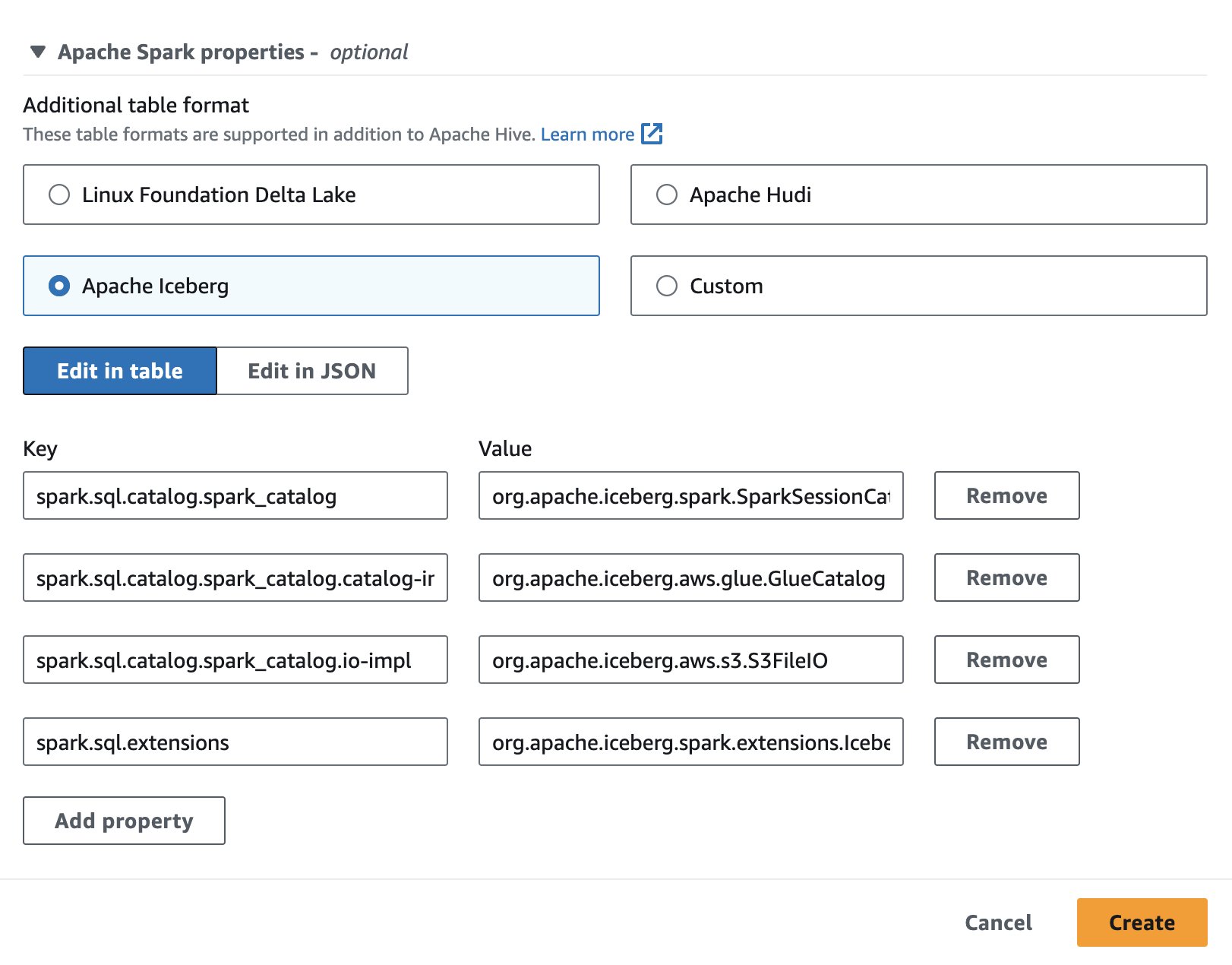
পদক্ষেপের জন্য, দেখুন সেশনের বিবরণ সম্পাদনা করা হচ্ছে or আপনার নিজের নোটবুক তৈরি করা.
এই বিভাগে ব্যবহৃত কোড পাওয়া যায় SparkSQL_iceberg.ipynb অনুসরণ করার জন্য ফাইল।
একটি ডাটাবেস এবং আইসবার্গ টেবিল তৈরি করুন
প্রথমত, আমরা AWS Glue Data Catalog এ একটি ডাটাবেস তৈরি করি। নিম্নলিখিত এসকিউএল দিয়ে, আমরা একটি ডাটাবেস তৈরি করতে পারি যার নাম icebergdb:
পরবর্তী, ডাটাবেসে icebergdb, আমরা নামক একটি আইসবার্গ টেবিল তৈরি করি noaa_iceberg Amazon S3-এর একটি অবস্থানের দিকে নির্দেশ করছি যেখানে আমরা ডেটা লোড করব। নিম্নলিখিত বিবৃতিটি চালান এবং অবস্থানটি প্রতিস্থাপন করুন s3://<your-S3-bucket>/<prefix>/ আপনার S3 বালতি এবং উপসর্গ সহ:
টেবিলে তথ্য সন্নিবেশ করান
জনবহুল করতে noaa_iceberg আইসবার্গ টেবিল, আমরা Parquet টেবিল থেকে তথ্য সন্নিবেশ sparkblogdb.noaa_pq যেটি পূর্বশর্তের অংশ হিসাবে তৈরি করা হয়েছিল। আপনি একটি ব্যবহার করে এটি করতে পারেন দ্রন স্পার্কের বিবৃতি:
বিকল্পভাবে, আপনি ব্যবহার করতে পারেন সিলেক্ট হিসাবে টেবিল তৈরি করুন একটি আইসবার্গ টেবিল তৈরি করতে আইসবার্গ ক্লজ ব্যবহার করুন এবং এক ধাপে একটি উত্স টেবিল থেকে ডেটা সন্নিবেশ করুন:
আইসবার্গ টেবিল জিজ্ঞাসা
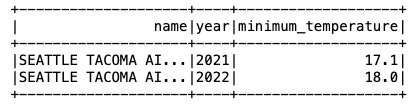
এখন যে ডেটা আইসবার্গ টেবিলে ঢোকানো হয়েছে, আমরা এটি বিশ্লেষণ শুরু করতে পারি। এর জন্য বছরের সর্বনিম্ন রেকর্ড করা তাপমাত্রা খুঁজে পেতে একটি স্পার্ক এসকিউএল চালাই 'SEATTLE TACOMA AIRPORT, WA US' অবস্থান:
আমরা নিম্নলিখিত আউটপুট পেতে.
আইসবার্গ টেবিলে ডেটা আপডেট করুন
আমাদের টেবিলে কিভাবে ডেটা আপডেট করা যায় তা দেখা যাক। আমরা স্টেশনের নাম আপডেট করতে চাই 'SEATTLE TACOMA AIRPORT, WA US' থেকে 'Sea-Tac'. স্পার্ক এসকিউএল ব্যবহার করে, আমরা একটি চালাতে পারি হালনাগাদ আইসবার্গ টেবিলের বিরুদ্ধে বিবৃতি:
তারপরে আমরা ন্যূনতম রেকর্ড করা তাপমাত্রা খুঁজে পেতে পূর্ববর্তী SELECT ক্যোয়ারী চালাতে পারি 'Sea-Tac' অবস্থান:
আমরা নিম্নলিখিত আউটপুট পেতে.

কমপ্যাক্ট ডেটা ফাইল
আইসবার্গের মতো ওপেন টেবিল ফরম্যাটগুলি ফাইল স্টোরেজে ডেল্টা পরিবর্তন তৈরি করে এবং ম্যানিফেস্ট ফাইলগুলির মাধ্যমে সারিগুলির সংস্করণগুলি ট্র্যাক করে কাজ করে৷ আরও ডেটা ফাইলগুলি ম্যানিফেস্ট ফাইলগুলিতে আরও মেটাডেটা সংরক্ষণের দিকে পরিচালিত করে এবং ছোট ডেটা ফাইলগুলি প্রায়শই অপ্রয়োজনীয় পরিমাণে মেটাডেটা সৃষ্টি করে, যার ফলে কম দক্ষ অনুসন্ধান এবং উচ্চ Amazon S3 অ্যাক্সেস খরচ হয়। চলমান আইসবার্গ এর rewrite_data_files অ্যাথেনার জন্য স্পার্কের পদ্ধতিটি ডেটা ফাইলগুলিকে কম্প্যাক্ট করবে, অনেকগুলি ছোট ডেল্টা পরিবর্তন ফাইলগুলিকে রিড-অপ্টিমাইজ করা Parquet ফাইলগুলির একটি ছোট সেটে একত্রিত করবে৷ প্রশ্ন করা হলে ফাইলগুলিকে কম্প্যাক্ট করা পঠন ক্রিয়াকে গতি দেয়৷ আমাদের টেবিলে কমপ্যাকশন চালানোর জন্য, নিম্নলিখিত স্পার্ক এসকিউএল চালান:
rewrite_data_files বিকল্পগুলি অফার করে আপনার সাজানোর কৌশল নির্দিষ্ট করতে, যা ডেটা পুনর্গঠন এবং কম্প্যাক্ট করতে সাহায্য করতে পারে।
তালিকা টেবিল স্ন্যাপশট
একটি আইসবার্গ টেবিলের প্রতিটি লেখা, আপডেট, মুছে ফেলা, আপসার্ট এবং কমপ্যাকশন অপারেশন একটি টেবিলের একটি নতুন স্ন্যাপশট তৈরি করে যখন স্ন্যাপশট বিচ্ছিন্নতা এবং সময় ভ্রমণের জন্য পুরানো ডেটা এবং মেটাডেটা চারপাশে রাখে৷ একটি আইসবার্গ টেবিলের স্ন্যাপশট তালিকাভুক্ত করতে, নিম্নলিখিত স্পার্ক এসকিউএল বিবৃতিটি চালান:
পুরানো স্ন্যাপশট মেয়াদ শেষ
আর প্রয়োজন নেই এমন ডেটা ফাইল মুছে ফেলার জন্য এবং টেবিলের মেটাডেটার আকার ছোট রাখার জন্য নিয়মিত মেয়াদ শেষ হওয়া স্ন্যাপশটগুলি সুপারিশ করা হয়৷ এটি কখনই এমন ফাইলগুলিকে মুছে ফেলবে না যা এখনও মেয়াদোত্তীর্ণ স্ন্যাপশটের জন্য প্রয়োজনীয়। এথেনার জন্য স্পার্ক-এ, টেবিলের স্ন্যাপশটগুলির মেয়াদ শেষ করতে নিম্নলিখিত SQL চালান icebergdb.noaa_iceberg যেগুলি একটি নির্দিষ্ট টাইমস্ট্যাম্পের চেয়ে পুরানো:
নোট করুন যে টাইমস্ট্যাম্প মান বিন্যাসে একটি স্ট্রিং হিসাবে নির্দিষ্ট করা হয়েছে yyyy-MM-dd HH:mm:ss.fff. আউটপুট ডেটা এবং মেটাডেটা ফাইল মুছে ফেলার সংখ্যার একটি গণনা দেবে।
টেবিল এবং ডাটাবেস ফেলে দিন
আপনি এই অনুশীলন থেকে Amazon S3 এ আইসবার্গ টেবিল এবং সংশ্লিষ্ট ডেটা পরিষ্কার করতে নিম্নলিখিত স্পার্ক এসকিউএল চালাতে পারেন:
ডাটাবেস আইসবার্গডিবি অপসারণ করতে নিম্নলিখিত স্পার্ক এসকিউএল চালান:
অ্যাথেনার জন্য স্পার্ক ব্যবহার করে আপনি আইসবার্গ টেবিলে যে সমস্ত অপারেশন করতে পারেন সে সম্পর্কে আরও জানতে, পড়ুন স্পার্ক কোয়েরি এবং স্পার্ক পদ্ধতি আইসবার্গ ডকুমেন্টেশনে।
Apache Hudi টেবিলের সাথে কাজ করা
এর পরে, আমরা দেখাব কিভাবে আপনি Apache Hudi টেবিল তৈরি, বিশ্লেষণ এবং পরিচালনার জন্য Spark-এ এসকিউএল ব্যবহার করতে পারেন।
একটি নোটবুক সেশন সেট আপ করুন
এথেনায় Apache Hudi ব্যবহার করার জন্য, একটি সেশন তৈরি বা সম্পাদনা করার সময়, নির্বাচন করুন অ্যাপাচি হুদি প্রসারিত করে বিকল্প অ্যাপাচি স্পার্ক বৈশিষ্ট্য অধ্যায়.
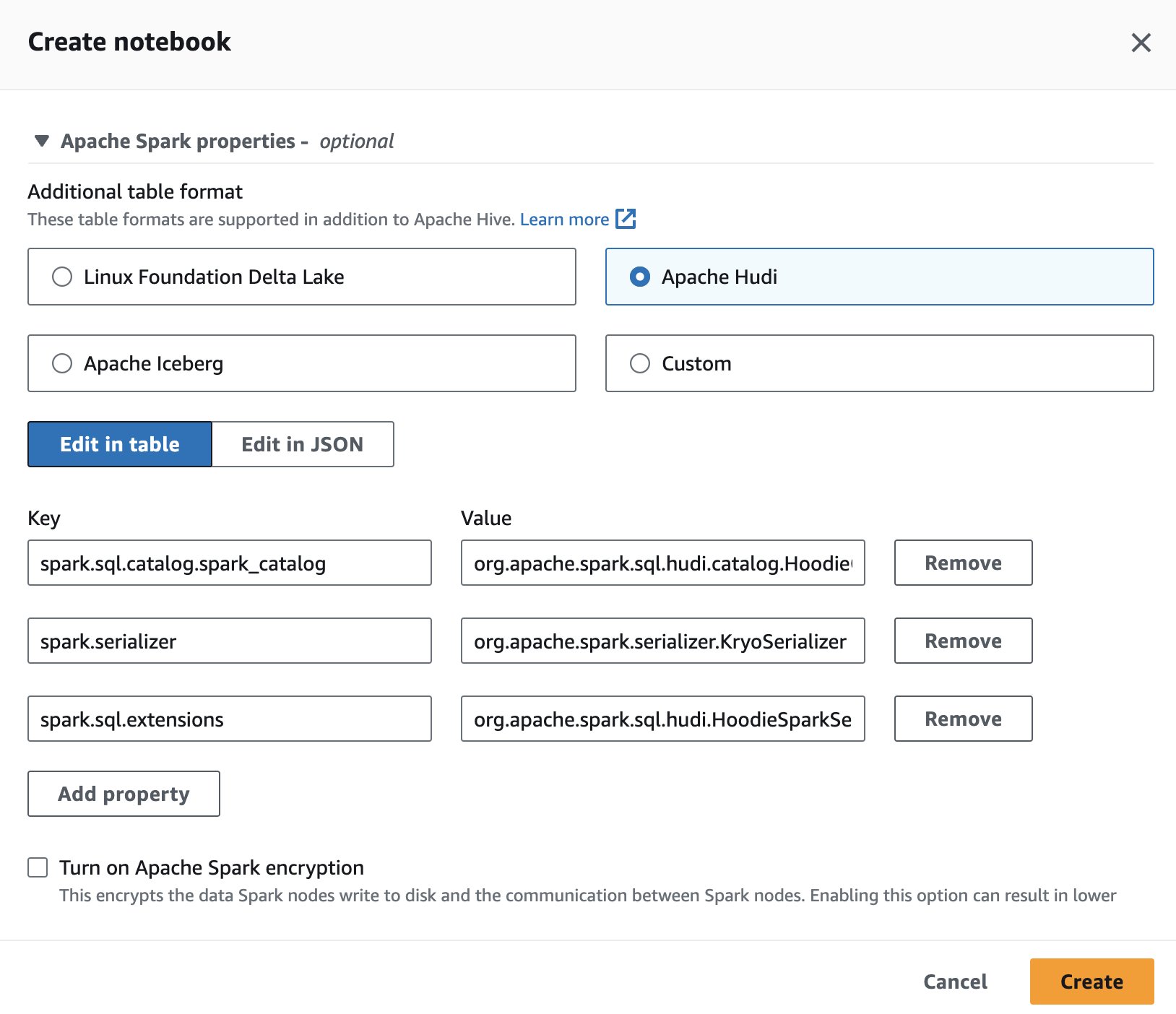
পদক্ষেপের জন্য, দেখুন সেশনের বিবরণ সম্পাদনা করা হচ্ছে or আপনার নিজের নোটবুক তৈরি করা.
এই বিভাগে ব্যবহৃত কোড পাওয়া উচিত SparkSQL_hudi.ipynb অনুসরণ করার জন্য ফাইল।
একটি ডাটাবেস এবং হুডি টেবিল তৈরি করুন
প্রথমত, আমরা নামক একটি ডাটাবেস তৈরি করি hudidb যেটি AWS Glue Data Catalog-এ সংরক্ষিত হবে তারপর Hudi টেবিল তৈরি করা হবে:
আমরা Amazon S3-এ একটি অবস্থান নির্দেশ করে একটি হুডি টেবিল তৈরি করি যেখানে আমরা ডেটা লোড করব। উল্লেখ্য যে টেবিলটি এর অনুরূপ লিখ টাইপ এটি দ্বারা সংজ্ঞায়িত করা হয় type= 'cow' টেবিলে DDL. আমরা স্টেশন এবং তারিখকে একাধিক প্রাথমিক কী এবং প্রি-কম্বাইন্ডফিল্ডকে বছর হিসাবে সংজ্ঞায়িত করেছি। এছাড়াও, টেবিলটি বছরে বিভাজন করা হয়। নিম্নলিখিত বিবৃতিটি চালান এবং অবস্থানটি প্রতিস্থাপন করুন s3://<your-S3-bucket>/<prefix>/ আপনার S3 বালতি এবং উপসর্গ সহ:
টেবিলে তথ্য সন্নিবেশ করান
আইসবার্গের মতো, আমরা ব্যবহার করি দ্রন বিবৃতি থেকে ডেটা পড়ে টেবিলটি পূরণ করতে sparkblogdb.noaa_pq পূর্ববর্তী পোস্টে তৈরি টেবিল:
হুদি টেবিলে প্রশ্ন করুন
এখন টেবিলটি তৈরি করা হয়েছে, এর জন্য সর্বোচ্চ রেকর্ড করা তাপমাত্রা খুঁজে পেতে একটি ক্যোয়ারী চালানো যাক 'SEATTLE TACOMA AIRPORT, WA US' অবস্থান:
হুদি টেবিলে ডেটা আপডেট করুন
স্টেশনের নাম পরিবর্তন করা যাক 'SEATTLE TACOMA AIRPORT, WA US' থেকে 'Sea–Tac'. আমরা এথেনার জন্য স্পার্ক-এ একটি আপডেট বিবৃতি চালাতে পারি আপডেটের এর রেকর্ড noaa_hudi টেবিল:
এর জন্য সর্বোচ্চ রেকর্ড করা তাপমাত্রা খুঁজে পেতে আমরা পূর্ববর্তী SELECT ক্যোয়ারী চালাই 'Sea-Tac' অবস্থান:
সময় ভ্রমণ প্রশ্ন চালান
অতীতের ডেটা স্ন্যাপশটগুলি বিশ্লেষণ করতে আমরা অ্যাথেনাতে SQL-এ সময় ভ্রমণের প্রশ্নগুলি ব্যবহার করতে পারি। উদাহরণ স্বরূপ:
এই প্রশ্নটি অতীতে একটি নির্দিষ্ট সময়ের হিসাবে সিয়াটেল বিমানবন্দরের তাপমাত্রার ডেটা পরীক্ষা করে। টাইমস্ট্যাম্প ক্লজ আমাদের বর্তমান ডেটা পরিবর্তন না করেই ফিরে যেতে দেয়। নোট করুন যে টাইমস্ট্যাম্প মান বিন্যাসে একটি স্ট্রিং হিসাবে নির্দিষ্ট করা হয়েছে yyyy-MM-dd HH:mm:ss.fff.
ক্লাস্টারিংয়ের সাথে কোয়েরির গতি অপ্টিমাইজ করুন
ক্যোয়ারী কর্মক্ষমতা উন্নত করতে, আপনি সম্পাদন করতে পারেন থলোথলো এথেনার জন্য স্পার্ক-এ SQL ব্যবহার করে হুডি টেবিলে:
কম্প্যাক্ট টেবিল
কমপ্যাকশন হল একটি টেবিল পরিষেবা যা হুডি দ্বারা বিশেষভাবে মার্জ অন রিড (এমওআর) টেবিলে নিযুক্ত করে বেস ফাইলের একটি নতুন সংস্করণ তৈরি করার জন্য সারি-ভিত্তিক লগ ফাইলগুলি থেকে সংশ্লিষ্ট কলাম-ভিত্তিক বেস ফাইলে আপডেটগুলিকে একত্রিত করতে। কম্প্যাকশন কপি অন রাইটে (COW) টেবিলে প্রযোজ্য নয় এবং শুধুমাত্র MOR টেবিলের ক্ষেত্রে প্রযোজ্য। এমওআর টেবিলে কমপ্যাকশন করার জন্য আপনি এথেনার জন্য স্পার্ক-এ নিম্নলিখিত ক্যোয়ারী চালাতে পারেন:
টেবিল এবং ডাটাবেস ফেলে দিন
Amazon S3 অবস্থান থেকে আপনার তৈরি করা হুডি টেবিল এবং সংশ্লিষ্ট ডেটা সরাতে নিম্নলিখিত স্পার্ক SQL চালান:
ডাটাবেস অপসারণ করতে নিম্নলিখিত স্পার্ক এসকিউএল চালান hudidb:
এথেনার জন্য স্পার্ক ব্যবহার করে আপনি হুডি টেবিলে যে সমস্ত অপারেশন করতে পারেন সে সম্পর্কে জানতে, পড়ুন এসকিউএল ডিডিএল এবং <u><strong>পদ্ধতি</strong></u> হুদি ডকুমেন্টেশনে।
লিনাক্স ফাউন্ডেশন ডেল্টা লেক টেবিলের সাথে কাজ করা
এর পরে, আমরা দেখাব কিভাবে আপনি ডেল্টা লেক টেবিল তৈরি, বিশ্লেষণ এবং পরিচালনা করতে এথেনার জন্য স্পার্ক-এ SQL ব্যবহার করতে পারেন।
একটি নোটবুক সেশন সেট আপ করুন
অ্যাথেনার জন্য স্পার্কের ডেল্টা লেক ব্যবহার করার জন্য, একটি সেশন তৈরি বা সম্পাদনা করার সময়, নির্বাচন করুন লিনাক্স ফাউন্ডেশন ডেল্টা লেক প্রসারিত করে অ্যাপাচি স্পার্ক বৈশিষ্ট্য অধ্যায়.
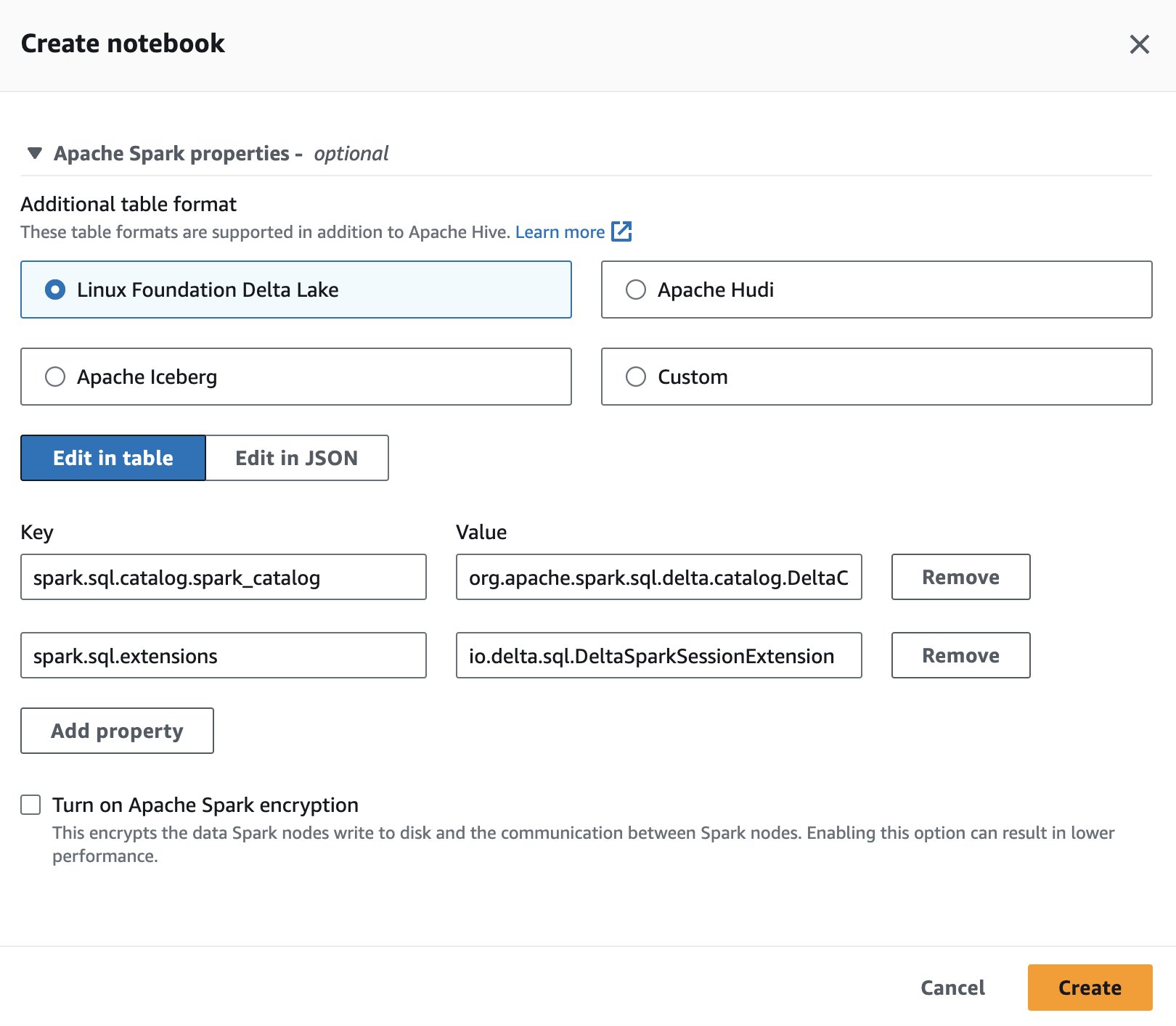
পদক্ষেপের জন্য, দেখুন সেশনের বিবরণ সম্পাদনা করা হচ্ছে or আপনার নিজের নোটবুক তৈরি করা.
এই বিভাগে ব্যবহৃত কোড পাওয়া উচিত SparkSQL_delta.ipynb অনুসরণ করার জন্য ফাইল।
একটি ডাটাবেস এবং ডেল্টা লেক টেবিল তৈরি করুন
এই বিভাগে, আমরা AWS গ্লু ডেটা ক্যাটালগে একটি ডাটাবেস তৈরি করি। নিম্নলিখিত এসকিউএল ব্যবহার করে, আমরা নামক একটি ডাটাবেস তৈরি করতে পারি deltalakedb:
পরবর্তী, ডাটাবেসে deltalakedb, আমরা একটি ডেল্টা লেক টেবিল নামক তৈরি noaa_delta Amazon S3-এর একটি অবস্থানের দিকে নির্দেশ করছি যেখানে আমরা ডেটা লোড করব। নিম্নলিখিত বিবৃতিটি চালান এবং অবস্থানটি প্রতিস্থাপন করুন s3://<your-S3-bucket>/<prefix>/ আপনার S3 বালতি এবং উপসর্গ সহ:
টেবিলে তথ্য সন্নিবেশ করান
আমরা একটি ব্যবহার দ্রন বিবৃতি থেকে ডেটা পড়ে টেবিলটি পূরণ করতে sparkblogdb.noaa_pq পূর্ববর্তী পোস্টে তৈরি টেবিল:
আপনি একটি ডেল্টা লেক টেবিল তৈরি করতে এবং একটি ক্যোয়ারীতে একটি উৎস টেবিল থেকে ডেটা সন্নিবেশ করতে SELECT হিসাবে তৈরি করুন টেবিল ব্যবহার করতে পারেন।
ডেল্টা লেক টেবিলে প্রশ্ন করুন
এখন যেহেতু ডেটা ডেল্টা লেক টেবিলে ঢোকানো হয়েছে, আমরা এটি বিশ্লেষণ শুরু করতে পারি। এর জন্য সর্বনিম্ন রেকর্ড করা তাপমাত্রা খুঁজে পেতে একটি স্পার্ক এসকিউএল চালাই 'SEATTLE TACOMA AIRPORT, WA US' অবস্থান:
ডেল্টা লেক টেবিলে ডেটা আপডেট করুন
স্টেশনের নাম পরিবর্তন করা যাক 'SEATTLE TACOMA AIRPORT, WA US' থেকে 'Sea–Tac'. আমরা একটি চালাতে পারেন হালনাগাদ এথেনার রেকর্ড আপডেট করার জন্য স্পার্কের বিবৃতি noaa_delta টেবিল:
আমরা ন্যূনতম রেকর্ড করা তাপমাত্রা খুঁজে পেতে পূর্ববর্তী SELECT ক্যোয়ারী চালাতে পারি 'Sea-Tac' অবস্থান, এবং ফলাফল আগের মতই হওয়া উচিত:
কমপ্যাক্ট ডেটা ফাইল
এথেনার জন্য স্পার্ক-এ, আপনি ডেল্টা লেক টেবিলে অপ্টিমাইজ চালাতে পারেন, যা ছোট ফাইলগুলিকে বড় ফাইলগুলিতে কম্প্যাক্ট করবে, যাতে ছোট ফাইল ওভারহেড দ্বারা প্রশ্নগুলি বোঝা না যায়৷ কম্প্যাকশন অপারেশন সঞ্চালনের জন্য, নিম্নলিখিত ক্যোয়ারী চালান:
নির্দেশ করে নিখুঁতকরণ অপ্টিমাইজ চালানোর সময় উপলব্ধ বিভিন্ন বিকল্পের জন্য ডেল্টা লেক ডকুমেন্টেশনে।
ডেল্টা লেক টেবিলের দ্বারা আর উল্লেখ করা ফাইলগুলি সরান
আপনি অ্যামাজন S3-এ সঞ্চিত ফাইলগুলিকে সরিয়ে ফেলতে পারেন যেগুলি ডেল্টা লেক টেবিলের দ্বারা আর উল্লেখ করা হয় না এবং অ্যাথেনার জন্য স্পার্ক ব্যবহার করে টেবিলে VACCUM কমান্ড চালিয়ে ধরে রাখার থ্রেশহোল্ডের চেয়ে পুরানো:
নির্দেশ করে ডেল্টা টেবিলের দ্বারা আর উল্লেখ করা ফাইলগুলি সরান ভ্যাকুয়ামের সাথে উপলব্ধ বিকল্পগুলির জন্য ডেল্টা লেক ডকুমেন্টেশনে।
টেবিল এবং ডাটাবেস ফেলে দিন
আপনার তৈরি ডেল্টা লেক টেবিলটি সরাতে নিম্নলিখিত স্পার্ক এসকিউএল চালান:
ডাটাবেস অপসারণ করতে নিম্নলিখিত স্পার্ক এসকিউএল চালান deltalakedb:
ডেল্টা লেক টেবিল এবং ডাটাবেসে DROP TABLE DDL চালানোর ফলে এই বস্তুর মেটাডেটা মুছে যায়, কিন্তু স্বয়ংক্রিয়ভাবে Amazon S3-এর ডেটা ফাইল মুছে যায় না। S3 অবস্থান থেকে ডেটা মুছে ফেলার জন্য আপনি নোটবুকের ঘরে নিম্নলিখিত পাইথন কোডটি চালাতে পারেন:
এথেনার জন্য স্পার্ক ব্যবহার করে আপনি ডেল্টা লেকের টেবিলে চালাতে পারেন এমন SQL বিবৃতি সম্পর্কে আরও জানতে, দেখুন দ্রুতশুরু ডেল্টা লেক ডকুমেন্টেশনে।
উপসংহার
এই পোস্টে দেখানো হয়েছে যে কীভাবে এথেনা নোটবুকে স্পার্ক এসকিউএল ব্যবহার করে ডাটাবেস এবং টেবিল তৈরি করতে হয়, ডেটা সন্নিবেশ করতে এবং অনুসন্ধান করতে হয় এবং হুডি, ডেল্টা লেক এবং আইসবার্গ টেবিলে আপডেট, কমপ্যাকশন এবং সময় ভ্রমণের মতো সাধারণ ক্রিয়াকলাপগুলি সম্পাদন করতে হয়। ওপেন টেবিল ফরম্যাটগুলি কাঁচা অবজেক্ট স্টোরেজের সীমাবদ্ধতা অতিক্রম করে ডেটা লেকে ACID লেনদেন, আপসার্ট এবং ডিলিট যোগ করে। পৃথক সংযোগকারী ইনস্টল করার প্রয়োজনীয়তা দূর করে, অ্যাথেনার বিল্ট-ইন ইন্টিগ্রেশনে স্পার্ক অ্যামাজন S3-তে নির্ভরযোগ্য ডেটা লেক তৈরির জন্য এই জনপ্রিয় ফ্রেমওয়ার্কগুলি ব্যবহার করার সময় কনফিগারেশন পদক্ষেপ এবং ব্যবস্থাপনা ওভারহেড হ্রাস করে। আপনার ডেটা লেক ওয়ার্কলোডের জন্য একটি খোলা টেবিল বিন্যাস নির্বাচন করার বিষয়ে আরও জানতে, পড়ুন AWS-এ আপনার লেনদেন সংক্রান্ত ডেটা লেকের জন্য একটি খোলা টেবিল বিন্যাস নির্বাচন করা হচ্ছে.
লেখক সম্পর্কে
![]() পথিক শাহ অ্যামাজন অ্যাথেনার একজন সিনিয়র অ্যানালিটিক্স আর্কিটেক্ট। তিনি 2015 সালে AWS-এ যোগদান করেন এবং তারপর থেকে বড় ডেটা অ্যানালিটিক্স স্পেসে ফোকাস করছেন, গ্রাহকদের AWS অ্যানালিটিক্স পরিষেবাগুলি ব্যবহার করে মাপযোগ্য এবং শক্তিশালী সমাধান তৈরি করতে সহায়তা করে৷
পথিক শাহ অ্যামাজন অ্যাথেনার একজন সিনিয়র অ্যানালিটিক্স আর্কিটেক্ট। তিনি 2015 সালে AWS-এ যোগদান করেন এবং তারপর থেকে বড় ডেটা অ্যানালিটিক্স স্পেসে ফোকাস করছেন, গ্রাহকদের AWS অ্যানালিটিক্স পরিষেবাগুলি ব্যবহার করে মাপযোগ্য এবং শক্তিশালী সমাধান তৈরি করতে সহায়তা করে৷
![]() রাজ দেবনাথ Amazon Athena-এ AWS-এর একজন প্রোডাক্ট ম্যানেজার। তিনি গ্রাহকদের পছন্দের পণ্য তৈরি করতে এবং গ্রাহকদের তাদের ডেটা থেকে মূল্য বের করতে সহায়তা করার বিষয়ে উত্সাহী। তার পটভূমি হল ফিনান্স, খুচরা, স্মার্ট বিল্ডিং, হোম অটোমেশন, এবং ডেটা কমিউনিকেশন সিস্টেমের মতো একাধিক শেষ বাজারের সমাধান প্রদান করা।
রাজ দেবনাথ Amazon Athena-এ AWS-এর একজন প্রোডাক্ট ম্যানেজার। তিনি গ্রাহকদের পছন্দের পণ্য তৈরি করতে এবং গ্রাহকদের তাদের ডেটা থেকে মূল্য বের করতে সহায়তা করার বিষয়ে উত্সাহী। তার পটভূমি হল ফিনান্স, খুচরা, স্মার্ট বিল্ডিং, হোম অটোমেশন, এবং ডেটা কমিউনিকেশন সিস্টেমের মতো একাধিক শেষ বাজারের সমাধান প্রদান করা।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- : আছে
- : হয়
- :না
- :কোথায়
- $ ইউপি
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- সম্পর্কে
- প্রবেশ
- যোগ
- অগ্রসর
- বিরুদ্ধে
- বিমানবন্দর
- সব
- বরাবর
- এছাড়াও
- মর্দানী স্ত্রীলোক
- অ্যামাজন অ্যাথেনা
- অ্যামাজন ওয়েব সার্ভিসেস
- পরিমাণ
- an
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ করা
- বিশ্লেষণ
- এবং
- ঘোষিত
- এ্যাপাচি
- আপা স্পার্ক
- প্রাসঙ্গিক
- অ্যাপ্লিকেশন
- প্রযোজ্য
- পন্থা
- রয়েছি
- কাছাকাছি
- AS
- যুক্ত
- At
- স্বয়ংক্রিয়ভাবে
- স্বয়ংক্রিয়তা
- উপস্থিতি
- সহজলভ্য
- ডেস্কটপ AWS
- এডাব্লুএস আঠালো
- পিছনে
- পটভূমি
- ভিত্তি
- BE
- হয়েছে
- আচরণ
- বিশাল
- বড় ডেটা
- নির্মাণ করা
- ভবন
- নির্মিত
- বিল্ট-ইন
- ব্যবসায়
- কিন্তু
- by
- কল
- নামক
- CAN
- তালিকা
- কারণ
- কোষ
- পরিবর্তন
- পরিবর্তন
- চেক
- পরিষ্কার
- কোড
- মেশা
- মিশ্রন
- সাধারণ
- যোগাযোগ
- যোগাযোগ ব্যবস্থা
- নিচ্ছিদ্র
- তুলনা
- কনফিগারেশন
- সঙ্গত
- সুখী
- অনুরূপ
- খরচ
- গণনা
- সৃষ্টি
- নির্মিত
- সৃষ্টি
- তৈরি করা হচ্ছে
- সৃষ্টি
- বর্তমান
- গ্রাহকদের
- উপাত্ত
- ডেটা বিশ্লেষণ
- ডেটা লেক
- তথ্য প্রক্রিয়াজাতকরণ
- তথ্য গুদাম
- ডেটাবেস
- ডাটাবেস
- তারিখ
- সংজ্ঞায়িত
- প্রদান
- ব-দ্বীপ
- প্রদর্শন
- প্রদর্শিত
- নির্ভরতা
- বিভিন্ন
- সরাসরি
- আলোচনা
- do
- ডকুমেন্টেশন
- না
- ডাউনলোড
- ড্রপ
- স্থায়িত্ব
- প্রতি
- পূর্বে
- সম্পাদনা
- দক্ষ
- প্রচেষ্টা
- নিযুক্ত
- সক্ষম করা
- শেষ
- নিশ্চিত করা
- সমগ্র
- পরিবেশ
- থার (eth)
- ঘটনাবলী
- উদাহরণ
- ব্যায়াম
- বিস্তৃত
- নির্যাস
- বৈশিষ্ট্য
- ফাইল
- নথি পত্র
- অর্থ
- আবিষ্কার
- প্রথম
- নমনীয়তা
- মনোযোগ
- অনুসরণ করা
- অনুসৃত
- অনুসরণ
- জন্য
- বিন্যাস
- ভিত
- অবকাঠামো
- থেকে
- কার্যকারিতা
- সাধারণ
- পাওয়া
- দাও
- গ্রুপ
- ক্রমবর্ধমান
- উত্থিত
- হাতল
- আছে
- জমিদারি
- he
- হেডার
- সাহায্য
- সাহায্য
- hh
- উচ্চ
- ঊর্ধ্বতন
- তার
- হোম
- অধিবাস স্বয়ংক্রিয়তা
- কিভাবে
- কিভাবে
- এইচটিএমএল
- HTTP
- HTTPS দ্বারা
- ভাবমূর্তি
- সরঁজাম
- আমদানি
- উন্নত করা
- in
- ক্রমবর্ধমান
- ইনস্টল
- ইন্টিগ্রেশন
- আগ্রহী
- ইন্টারফেস
- মধ্যে
- বিচ্ছিন্নতা
- IT
- যোগদান
- JPG
- রাখা
- পালন
- কী
- হ্রদ
- হ্রদ
- বৃহত্তর
- অক্ষাংশ
- বিশালাকার
- শিখতে
- কম
- যাক
- মত
- সীমাবদ্ধতা
- লিনাক্স
- লিনাক্স ফাউন্ডেশন
- তালিকা
- বোঝা
- অবস্থান
- অবস্থানগুলি
- লগ ইন করুন
- আর
- দেখুন
- খুঁজছি
- ভালবাসা
- জাদু
- পরিচালনা করা
- ব্যবস্থাপনা
- পরিচালক
- পদ্ধতি
- অনেক
- বাজার
- সর্বোচ্চ
- সর্বাধিক
- মার্জ
- মেটাডাটা
- মিনিট
- সর্বনিম্ন
- অধিক
- বহু
- নাম
- নেটিভ
- নেভিগেট করুন
- প্রয়োজন
- প্রয়োজন
- না
- নতুন
- না।
- বিঃদ্রঃ
- নোটবই
- নোটবুক
- সংখ্যা
- লক্ষ্য
- বস্তু সংগ্রহস্থল
- বস্তু
- of
- অফার
- প্রায়ই
- পুরাতন
- পুরোনো
- on
- ONE
- কেবল
- OP
- খোলা
- ওপেন সোর্স
- অপারেশন
- অপারেশনস
- অপ্টিমিজ
- পছন্দ
- অপশন সমূহ
- or
- ক্রম
- আমাদের
- আউটপুট
- অভিভূতকারী
- নিজের
- অংশ
- কামুক
- গত
- সম্পাদন করা
- কর্মক্ষমতা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- জনপ্রিয়
- পোস্ট
- পূর্বশর্ত
- আগে
- পূর্বে
- প্রাথমিক
- কার্যপ্রণালী
- প্রক্রিয়াজাতকরণ
- উৎপাদন করা
- পণ্য
- পণ্য ব্যবস্থাপক
- পণ্য
- বৈশিষ্ট্য
- পাইথন
- প্রশ্নের
- হার
- কাঁচা
- পড়া
- পড়া
- সুপারিশ করা
- নথিভুক্ত
- রেকর্ড
- হ্রাস
- পড়ুন
- রেফারেন্সড
- বিশ্বাসযোগ্য
- অপসারণ
- অপসারণ
- সরানোর
- প্রতিস্থাপন করা
- প্রয়োজনীয়
- ফল
- ফলে এবং
- খুচরা
- স্মৃতিশক্তি
- শক্তসমর্থ
- চালান
- দৌড়
- একই
- মাপযোগ্য
- স্কেল
- সিয়াটেল
- দ্বিতীয়
- অধ্যায়
- দেখ
- নির্বাচন করা
- নির্বাচন
- আলাদা
- সেবা
- সেবা
- সেশন
- সেট
- উচিত
- প্রদর্শনী
- প্রদর্শিত
- শো
- গুরুত্বপূর্ণ
- সহজ
- সরলীকৃত
- সহজতর করা
- থেকে
- আয়তন
- কিছুটা ভিন্ন
- SLP
- ছোট
- ক্ষুদ্রতর
- স্মার্ট
- স্ন্যাপশট
- So
- সলিউশন
- উৎস
- স্থান
- স্ফুলিঙ্গ
- প্রশিক্ষণ
- নির্দিষ্ট
- বিশেষভাবে
- নিদিষ্ট
- স্পীড
- গতি
- অতিবাহিত
- এসকিউএল
- শুরু
- বিবৃতি
- বিবৃতি
- স্টেশন
- ধাপ
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- এখনো
- স্টোরেজ
- দোকান
- সঞ্চিত
- কৌশল
- স্ট্রিং
- এমন
- সমর্থিত
- পদ্ধতি
- সিস্টেম
- টেবিল
- টাকোমা
- চেয়ে
- যে
- সার্জারির
- তাদের
- তাহাদিগকে
- তারপর
- এইগুলো
- এই
- গোবরাট
- দ্বারা
- সময়
- সময় ভ্রমণ
- টাইমস্ট্যাম্প
- থেকে
- অনুসরণকরণ
- লেনদেনের
- লেনদেন
- ভ্রমণ
- আদর্শ
- প্রতিদ্বন্দ্বিহীন
- আপডেট
- আপডেট
- আপডেট
- us
- ব্যবহার
- ব্যবহার
- ব্যবহৃত
- ব্যবহার
- শূন্যস্থান
- মূল্য
- সংস্করণ
- সংস্করণ
- প্রয়োজন
- ছিল
- উপায়
- we
- ওয়েব
- ওয়েব সার্ভিস
- ছিল
- কখন
- যে
- যখন
- ইচ্ছা
- সঙ্গে
- ছাড়া
- হয়া যাই ?
- লেখা
- বছর
- আপনি
- আপনার
- zephyrnet