বৃহৎ ভাষার মডেল (এলএলএম) ক্রমবর্ধমান জনপ্রিয় হয়ে উঠছে, নতুন ব্যবহারের ক্ষেত্রে ক্রমাগত অনুসন্ধান করা হচ্ছে। সাধারণভাবে, আপনি আপনার কোডে প্রম্পট ইঞ্জিনিয়ারিং অন্তর্ভুক্ত করে এলএলএম দ্বারা চালিত অ্যাপ্লিকেশন তৈরি করতে পারেন। যাইহোক, এমন কিছু ক্ষেত্রে রয়েছে যেখানে একটি বিদ্যমান এলএলএম প্রম্পট করা কম হয়। এখানেই মডেল ফাইন-টিউনিং সাহায্য করতে পারে। প্রম্পট ইঞ্জিনিয়ারিং হল ইনপুট প্রম্পট তৈরি করে মডেলের আউটপুটকে গাইড করা, যেখানে ফাইন-টিউনিং হল কাস্টম ডেটাসেটে মডেলটিকে নির্দিষ্ট কাজ বা ডোমেনের জন্য আরও উপযুক্ত করে তোলার প্রশিক্ষণ দেওয়া।
আপনি একটি মডেল ফাইন-টিউন করার আগে, আপনাকে একটি টাস্ক-নির্দিষ্ট ডেটাসেট খুঁজে বের করতে হবে। একটি ডেটাসেট যা সাধারণত ব্যবহৃত হয় সাধারণ ক্রল ডেটাসেট. কমন ক্রল কর্পাসে পেটাবাইট ডেটা রয়েছে, যা 2008 সাল থেকে নিয়মিত সংগ্রহ করা হয় এবং এতে কাঁচা ওয়েবপেজ ডেটা, মেটাডেটা এক্সট্রাক্ট এবং টেক্সট এক্সট্রাক্ট থাকে। কোন ডেটাসেট ব্যবহার করা উচিত তা নির্ধারণের পাশাপাশি, ফাইন-টিউনিংয়ের নির্দিষ্ট প্রয়োজনে ডেটা পরিষ্কার এবং প্রক্রিয়াকরণ প্রয়োজন।
আমরা সম্প্রতি এমন একজন গ্রাহকের সাথে কাজ করেছি যিনি লেটেস্ট কমন ক্রল ডেটাসেটের একটি উপসেট প্রিপ্রসেস করতে চেয়েছিলেন এবং তারপরে পরিষ্কার করা ডেটা দিয়ে তাদের LLM টিউন করতে চেয়েছিলেন। গ্রাহক খুঁজছিলেন কিভাবে তারা AWS-এ সবচেয়ে সাশ্রয়ী উপায়ে এটি অর্জন করতে পারে। প্রয়োজনীয়তা আলোচনা করার পরে, আমরা ব্যবহার করার সুপারিশ আমাজন ইএমআর সার্ভারহীন ডেটা প্রিপ্রসেসিংয়ের জন্য তাদের প্ল্যাটফর্ম হিসাবে। EMR সার্ভারলেস বড় আকারের ডেটা প্রক্রিয়াকরণের জন্য উপযুক্ত এবং অবকাঠামো রক্ষণাবেক্ষণের প্রয়োজনীয়তা দূর করে। খরচের পরিপ্রেক্ষিতে, এটি শুধুমাত্র প্রতিটি কাজের জন্য ব্যবহৃত সম্পদ এবং সময়কালের উপর ভিত্তি করে চার্জ করে। গ্রাহক ইএমআর সার্ভারলেস ব্যবহার করে এক সপ্তাহের মধ্যে শত শত টিবি ডেটা প্রিপ্রসেস করতে সক্ষম হয়েছিল। তারা ডেটা প্রিপ্রসেস করার পরে, তারা ব্যবহার করেছিল আমাজন সেজমেকার এলএলএম ঠিক করতে।
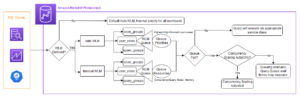
এই পোস্টে, আমরা আপনাকে গ্রাহকের ব্যবহারের কেস এবং ব্যবহৃত আর্কিটেকচারের মাধ্যমে নিয়ে চলেছি।
নিম্নলিখিত বিভাগগুলিতে, আমরা প্রথমে সাধারণ ক্রল ডেটাসেট এবং কীভাবে আমাদের প্রয়োজনীয় ডেটা অন্বেষণ এবং ফিল্টার করতে হয় তা উপস্থাপন করি৷ অ্যামাজন অ্যাথেনা এটি স্ক্যান করা ডেটার আকারের জন্য শুধুমাত্র চার্জ করে এবং খরচ-কার্যকর হওয়া সত্ত্বেও দ্রুত ডেটা অন্বেষণ এবং ফিল্টার করতে ব্যবহৃত হয়। EMR সার্ভারলেস স্পার্ক ডেটা প্রক্রিয়াকরণের জন্য একটি ব্যয়-দক্ষ এবং নো-রক্ষণাবেক্ষণ বিকল্প সরবরাহ করে এবং ফিল্টার করা ডেটা প্রক্রিয়া করতে ব্যবহৃত হয়। পরবর্তী, আমরা ব্যবহার করি আমাজন সেজমেকার জাম্পস্টার্ট ফাইন-টিউন লামা 2 মডেল প্রি-প্রসেসড ডেটাসেট সহ। সেজমেকার জাম্পস্টার্ট সবচেয়ে সাধারণ ব্যবহারের ক্ষেত্রে সমাধানের একটি সেট সরবরাহ করে যা মাত্র কয়েকটি ক্লিকে স্থাপন করা যেতে পারে। LLM যেমন Llama 2 ফাইন-টিউন করার জন্য আপনাকে কোন কোড লিখতে হবে না। অবশেষে, আমরা ব্যবহার করে ফাইন-টিউনড মডেল স্থাপন করি আমাজন সেজমেকার এবং মূল এবং ফাইন-টিউনড লামা 2 মডেলের মধ্যে একই প্রশ্নের জন্য পাঠ্য আউটপুটের পার্থক্যগুলি তুলনা করুন।
নিচের চিত্রটি এই সমাধানের স্থাপত্যকে ব্যাখ্যা করে।
সমাধানের বিশদ বিবরণের গভীরে ডুব দেওয়ার আগে, নিম্নলিখিত পূর্বশর্ত পদক্ষেপগুলি সম্পূর্ণ করুন:
কমন ক্রল হল একটি ওপেন কর্পাস ডেটাসেট যা 50 বিলিয়ন ওয়েবপেজ ক্রল করে প্রাপ্ত হয়। এটি 2008 থেকে শুরু করে পেটাবাইট স্তরে পৌঁছে একাধিক ভাষায় প্রচুর পরিমাণে অসংগঠিত ডেটা অন্তর্ভুক্ত করে। এটা ক্রমাগত আপডেট করা হয়.
GPT-3-এর প্রশিক্ষণে, সাধারণ ক্রল ডেটাসেট এর প্রশিক্ষণ ডেটার 60% জন্য দায়ী, যেমনটি নিম্নলিখিত চিত্রে দেখানো হয়েছে (উৎস: ভাষার মডেলগুলি অল্প-শট লার্নার্স).
উল্লেখ যোগ্য আরেকটি গুরুত্বপূর্ণ ডেটাসেট হল C4 ডেটাসেট. C4, Colossal Clean Crawled Corpus-এর সংক্ষিপ্ত, একটি ডেটাসেট যা সাধারণ ক্রল ডেটাসেট পোস্টপ্রসেসিং থেকে প্রাপ্ত। মেটার LLaMA পেপারে, তারা ব্যবহৃত ডেটাসেটের রূপরেখা দিয়েছে, যার মধ্যে কমন ক্রল অ্যাকাউন্টিং 67% (3.3 TB ডেটা ব্যবহার করে) এবং C4 15% (783 GB ডেটা ব্যবহার করে)। কাগজটি মডেলের কর্মক্ষমতা বাড়ানোর জন্য আলাদাভাবে প্রিপ্রসেসড ডেটা অন্তর্ভুক্ত করার তাত্পর্যকে জোর দেয়। মূল C4 ডেটা কমন ক্রলের অংশ হওয়া সত্ত্বেও, মেটা এই ডেটার পুনঃপ্রসেস করা সংস্করণ বেছে নিয়েছে।
এই বিভাগে, আমরা সাধারণ ক্রল ডেটাসেট ইন্টারঅ্যাক্ট, ফিল্টার এবং প্রক্রিয়া করার সাধারণ উপায়গুলি কভার করি৷
কমন ক্রল কাঁচা ডেটাসেটে তিন ধরনের ডেটা ফাইল রয়েছে: কাঁচা ওয়েবপেজ ডেটা (WARC), মেটাডেটা (WAT), এবং টেক্সট এক্সট্রাকশন (WET)।
2013 সালের পরে সংগৃহীত ডেটা WARC ফরম্যাটে সংরক্ষণ করা হয় এবং এতে সংশ্লিষ্ট মেটাডেটা (WAT) এবং পাঠ্য নিষ্কাশন ডেটা (WET) অন্তর্ভুক্ত থাকে। ডেটাসেটটি Amazon S3 এ অবস্থিত, মাসিক ভিত্তিতে আপডেট করা হয়েছে এবং সরাসরি এর মাধ্যমে অ্যাক্সেস করা যেতে পারে AWS মার্কেটপ্লেস.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzসাধারণ ক্রল ডেটাসেট ডেটা ফিল্টার করার জন্য একটি সূচক টেবিলও প্রদান করে, যাকে cc-index-table বলা হয়।
cc-index-table হল বিদ্যমান ডেটার একটি সূচক, যা WARC ফাইলগুলির একটি টেবিল-ভিত্তিক সূচী প্রদান করে। এটি তথ্যের সহজ সন্ধানের অনুমতি দেয়, যেমন কোন WARC ফাইলটি একটি নির্দিষ্ট URL এর সাথে মিলে যায়৷
উদাহরণস্বরূপ, আপনি নিম্নলিখিত কোড সহ cc-index ডেটা ম্যাপ করতে একটি এথেনা টেবিল তৈরি করতে পারেন:
পূর্ববর্তী SQL স্টেটমেন্টগুলি দেখায় কিভাবে একটি এথেনা টেবিল তৈরি করতে হয়, পার্টিশন যোগ করতে হয় এবং একটি ক্যোয়ারী চালাতে হয়।
সাধারণ ক্রল ডেটাসেট থেকে ডেটা ফিল্টার করুন
আপনি তৈরি টেবিল এসকিউএল স্টেটমেন্ট থেকে দেখতে পাচ্ছেন, অনেকগুলি ক্ষেত্র রয়েছে যা ডেটা ফিল্টার করতে সহায়তা করতে পারে। উদাহরণস্বরূপ, যদি আপনি একটি নির্দিষ্ট সময়ের মধ্যে চীনা নথির গণনা পেতে চান, তাহলে SQL বিবৃতিটি নিম্নরূপ হতে পারে:
আপনি যদি আরও প্রক্রিয়াকরণ করতে চান, আপনি ফলাফলগুলি অন্য S3 বালতিতে সংরক্ষণ করতে পারেন।
ফিল্টার করা তথ্য বিশ্লেষণ করুন
সার্জারির সাধারণ ক্রল GitHub সংগ্রহস্থল কাঁচা ডেটা প্রক্রিয়াকরণের জন্য বেশ কয়েকটি PySpark উদাহরণ প্রদান করে।
চলুন দৌড়ের একটি উদাহরণ দেখি server_count.py (কমন ক্রল গিটহাব রেপো দ্বারা প্রদত্ত উদাহরণ স্ক্রিপ্ট) মধ্যে অবস্থিত ডেটাতে s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
প্রথমত, আপনার একটি স্পার্ক পরিবেশ প্রয়োজন, যেমন EMR স্পার্ক। উদাহরণস্বরূপ, আপনি EC2 ক্লাস্টারে একটি Amazon EMR চালু করতে পারেন us-east-1 (কারণ ডেটাসেট আছে us-east-1) EC2 ক্লাস্টারে একটি EMR ব্যবহার করা আপনাকে উৎপাদন পরিবেশে চাকরি জমা দেওয়ার আগে পরীক্ষা করতে সাহায্য করতে পারে।
EC2 ক্লাস্টারে একটি EMR চালু করার পরে, আপনাকে ক্লাস্টারের প্রাথমিক নোডে একটি SSH লগইন করতে হবে। তারপর, পাইথন এনভায়রনমেন্ট প্যাকেজ করুন এবং স্ক্রিপ্ট জমা দিন (দেখুন কনডা ডকুমেন্টেশন মিনিকোন্ডা ইনস্টল করতে):
warc.path-এ সমস্ত রেফারেন্স প্রক্রিয়া করতে সময় লাগতে পারে। ডেমো উদ্দেশ্যে, আপনি নিম্নলিখিত কৌশলগুলির সাথে প্রক্রিয়াকরণের সময় উন্নত করতে পারেন:
- ফাইল ডাউনলোড করুন
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzআপনার স্থানীয় মেশিনে, এটি আনজিপ করুন এবং তারপর এটি HDFS বা Amazon S3 এ আপলোড করুন। এর কারণ .gzip ফাইলটি বিভক্ত নয়। এই ফাইলটিকে সমান্তরালভাবে প্রক্রিয়া করার জন্য আপনাকে এটি আনজিপ করতে হবে। - পরিবর্তন করুন
warc.pathফাইল, এর বেশিরভাগ লাইন মুছে ফেলুন এবং কাজটি আরও দ্রুত চালানোর জন্য শুধুমাত্র দুটি লাইন রাখুন।
কাজ শেষ হওয়ার পরে, আপনি ফলাফল দেখতে পারেন s3://xxxx-common-crawl/output/, Parquet বিন্যাসে.
কাস্টমাইজড অধিকারী যুক্তি প্রয়োগ করুন
কমন ক্রল গিটহাব রেপো WARC ফাইলগুলি প্রক্রিয়া করার জন্য একটি সাধারণ পদ্ধতি প্রদান করে। সাধারণত, আপনি প্রসারিত করতে পারেন CCSparkJob একটি একক পদ্ধতি ওভাররাইড করতে (process_record), যা অনেক ক্ষেত্রেই যথেষ্ট।
সাম্প্রতিক মুভিগুলোর IMDB রিভিউ পেতে একটি উদাহরণ দেখি। প্রথমে, আপনাকে IMDB সাইটে ফাইলগুলি ফিল্টার করতে হবে:
তারপরে আপনি WARC ফাইলের তালিকা পেতে পারেন যাতে IMDB পর্যালোচনা ডেটা রয়েছে এবং WARC ফাইলের নামগুলি একটি পাঠ্য ফাইলে তালিকা হিসাবে সংরক্ষণ করতে পারেন৷
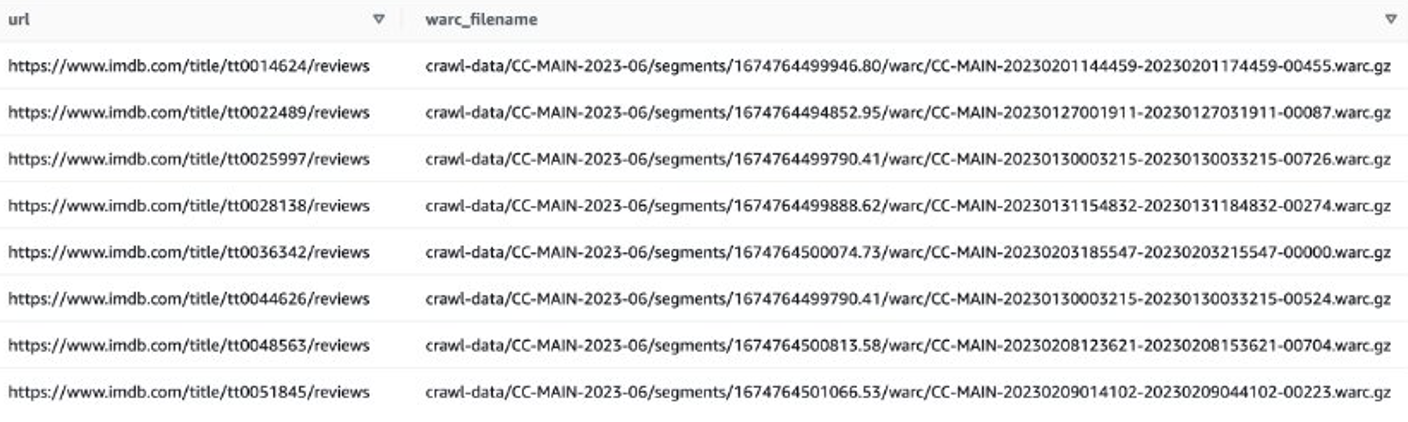
বিকল্পভাবে, আপনি WARC ফাইলের তালিকা পেতে EMR স্পার্ক ব্যবহার করতে পারেন এবং এটি Amazon S3 এ সংরক্ষণ করতে পারেন। উদাহরণ স্বরূপ:
আউটপুট ফাইলের মতো দেখতে হবে s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
পরবর্তী ধাপ হল এই WARC ফাইলগুলি থেকে ব্যবহারকারীর পর্যালোচনাগুলি বের করা৷ আপনি প্রসারিত করতে পারেন CCSparkJob ওভাররাইড করতে process_record() পদ্ধতি:
আপনি পূর্বের স্ক্রিপ্টটিকে imdb_extractor.py হিসাবে সংরক্ষণ করতে পারেন, যা আপনি নিম্নলিখিত ধাপে ব্যবহার করবেন। আপনি ডেটা এবং স্ক্রিপ্ট প্রস্তুত করার পরে, আপনি ফিল্টার করা ডেটা প্রক্রিয়া করতে EMR সার্ভারলেস ব্যবহার করতে পারেন।
EMR সার্ভারহীন
ইএমআর সার্ভারলেস হল একটি সার্ভারহীন স্থাপনার বিকল্প যা অ্যাপাচি স্পার্ক এবং হাইভের মতো ওপেন সোর্স ফ্রেমওয়ার্ক ব্যবহার করে ক্লাস্টার বা সার্ভারগুলিকে কনফিগার, পরিচালনা এবং স্কেলিং ছাড়াই বড় ডেটা অ্যানালিটিক্স অ্যাপ্লিকেশন চালানোর জন্য।
EMR সার্ভারলেস এর সাথে, আপনি স্বয়ংক্রিয় স্কেলিং সহ যেকোনো স্কেলে অ্যানালিটিক্স ওয়ার্কলোড চালাতে পারেন যা ডেটা ভলিউম এবং প্রক্রিয়াকরণের প্রয়োজনীয়তাগুলি পরিবর্তন করতে সেকেন্ডের মধ্যে সম্পদের আকার পরিবর্তন করে। ইএমআর সার্ভারলেস স্বয়ংক্রিয়ভাবে আপনার অ্যাপ্লিকেশনের জন্য সঠিক পরিমাণে ক্ষমতা প্রদানের জন্য সংস্থানগুলি উপরে এবং নীচে স্কেল করে এবং আপনি যা ব্যবহার করেন তার জন্যই আপনি অর্থ প্রদান করেন।
সাধারণ ক্রল ডেটাসেট প্রক্রিয়াকরণ সাধারণত একটি এককালীন প্রক্রিয়াকরণ কাজ, এটি EMR সার্ভারহীন কাজের চাপের জন্য উপযুক্ত করে তোলে।
একটি EMR সার্ভারহীন অ্যাপ্লিকেশন তৈরি করুন
আপনি EMR স্টুডিও কনসোলে একটি EMR সার্ভারহীন অ্যাপ্লিকেশন তৈরি করতে পারেন। নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- EMR স্টুডিও কনসোলে, নির্বাচন করুন অ্যাপ্লিকেশন অধীনে Serverless নেভিগেশন ফলকে।
- বেছে নিন অ্যাপ্লিকেশন তৈরি করুন.

- অ্যাপ্লিকেশনটির জন্য একটি নাম প্রদান করুন এবং একটি Amazon EMR সংস্করণ চয়ন করুন৷

- যদি VPC সংস্থানগুলিতে অ্যাক্সেসের প্রয়োজন হয়, একটি কাস্টমাইজড নেটওয়ার্ক সেটিং যোগ করুন।

- বেছে নিন অ্যাপ্লিকেশন তৈরি করুন.
আপনার স্পার্ক সার্ভারহীন পরিবেশ তখন প্রস্তুত হবে।
আপনি EMR স্পার্ক সার্ভারলেস একটি চাকরি জমা দেওয়ার আগে, আপনাকে এখনও একটি কার্যকর ভূমিকা তৈরি করতে হবে। নির্দেশ করে Amazon EMR সার্ভারলেস দিয়ে শুরু করা আরো বিস্তারিত জানার জন্য.
EMR সার্ভারলেস সহ সাধারণ ক্রল ডেটা প্রক্রিয়া করুন
আপনার EMR স্পার্ক সার্ভারলেস অ্যাপ্লিকেশন প্রস্তুত হওয়ার পরে, ডেটা প্রক্রিয়া করার জন্য নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- একটি Conda পরিবেশ প্রস্তুত করুন এবং এটি Amazon S3 এ আপলোড করুন, যা EMR স্পার্ক সার্ভারলেস পরিবেশ হিসাবে ব্যবহার করা হবে।
- একটি S3 বালতিতে চালানোর জন্য স্ক্রিপ্টগুলি আপলোড করুন৷ নিম্নলিখিত উদাহরণে, দুটি স্ক্রিপ্ট আছে:
- imbd_extractor.py - ডেটাসেট থেকে বিষয়বস্তু বের করতে কাস্টমাইজড লজিক। বিষয়বস্তু এই পোস্টে আগে পাওয়া যাবে.
- cc-pyspark/sparkcc.py – থেকে PySpark ফ্রেমওয়ার্কের উদাহরণ সাধারণ ক্রল গিটহাব রেপো, যা অন্তর্ভুক্ত করা আবশ্যক.
- PySpark কাজটি EMR সার্ভারলেস স্পার্ক-এ জমা দিন। আপনার পরিবেশে এই উদাহরণটি চালানোর জন্য নিম্নলিখিত পরামিতিগুলি সংজ্ঞায়িত করুন:
- আবেদন আইডি - আপনার EMR সার্ভারহীন অ্যাপ্লিকেশনের অ্যাপ্লিকেশন আইডি।
- মৃত্যুদন্ড-ভূমিকা-আর্ন - আপনার EMR সার্ভারলেস এক্সিকিউশন ভূমিকা। এটি তৈরি করতে, পড়ুন একটি কাজের রানটাইম ভূমিকা তৈরি করুন.
- WARC ফাইলের অবস্থান - আপনার WARC ফাইলের অবস্থান।
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtফিল্টার করা WARC ফাইল তালিকা রয়েছে, যা আপনি এই পোস্টে আগে পেয়েছিলেন। - spark.sql.warehouse.dir - ডিফল্ট গুদাম অবস্থান (আপনার S3 ডিরেক্টরি ব্যবহার করুন)।
- spark.archives - প্রস্তুত কন্ডা পরিবেশের S3 অবস্থান।
- spark.submit.pyFiles - প্রস্তুতকৃত PySpark স্ক্রিপ্ট sparkcc.py।
নিম্নলিখিত কোডটি দেখুন:
কাজ শেষ হওয়ার পরে, নিষ্কাশিত পর্যালোচনাগুলি Amazon S3 এ সংরক্ষণ করা হয়। বিষয়বস্তু পরীক্ষা করতে, আপনি Amazon S3 নির্বাচন ব্যবহার করতে পারেন, যেমনটি নিম্নলিখিত স্ক্রিনশটে দেখানো হয়েছে।
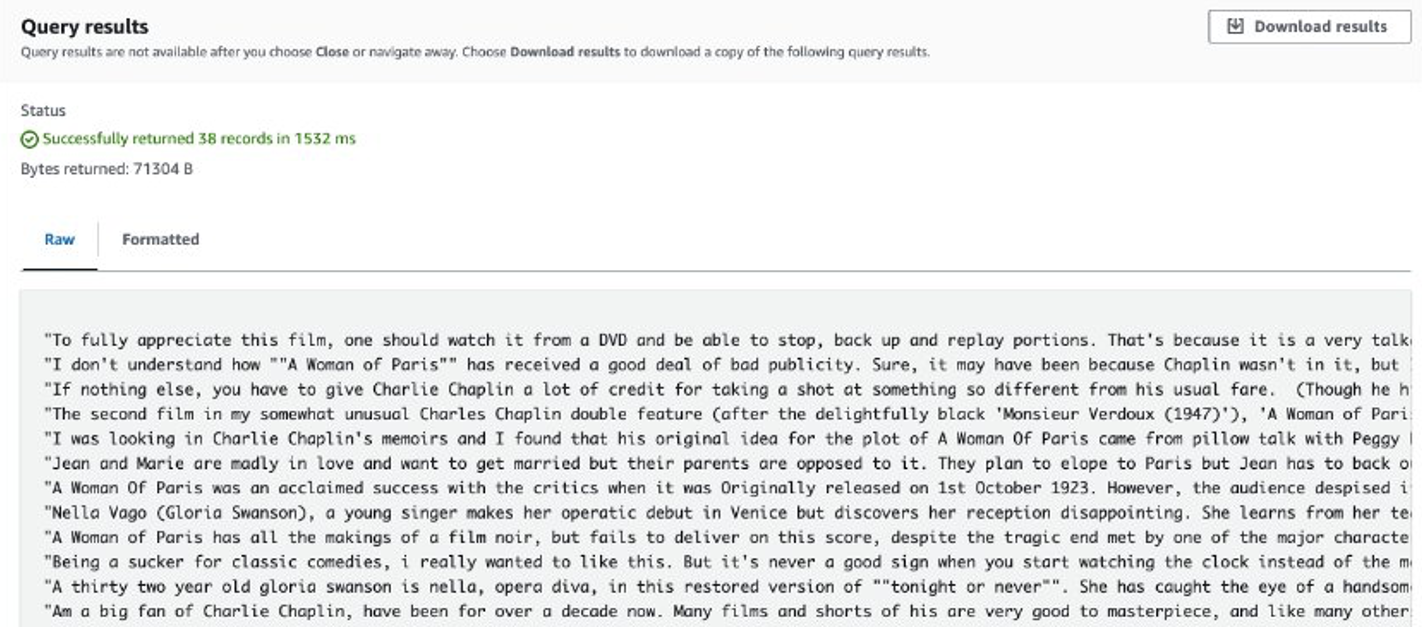
বিবেচ্য বিষয়
কাস্টমাইজড কোড সহ বিপুল পরিমাণ ডেটা নিয়ে কাজ করার সময় নিম্নলিখিত বিষয়গুলি বিবেচনা করতে হবে:
- কিছু তৃতীয় পক্ষের পাইথন লাইব্রেরি Conda-এ উপলব্ধ নাও হতে পারে। এই ধরনের ক্ষেত্রে, আপনি PySpark রানটাইম পরিবেশ তৈরি করতে একটি পাইথন ভার্চুয়াল পরিবেশে স্যুইচ করতে পারেন।
- যদি প্রচুর পরিমাণে ডেটা প্রসেস করা হয়, তবে এটিকে সমান্তরাল করতে একাধিক EMR সার্ভারলেস স্পার্ক অ্যাপ্লিকেশন তৈরি এবং ব্যবহার করার চেষ্টা করুন। প্রতিটি অ্যাপ্লিকেশন ফাইল তালিকার একটি উপসেট নিয়ে কাজ করে।
- সাধারণ ক্রল ডেটা ফিল্টার বা প্রক্রিয়া করার সময় আপনি Amazon S3 এর সাথে একটি মন্থর সমস্যার সম্মুখীন হতে পারেন। এই কারণে যে S3 বালতি ডেটা সংরক্ষণ করে সর্বজনীনভাবে অ্যাক্সেসযোগ্য, এবং অন্যান্য ব্যবহারকারীরা একই সময়ে ডেটা অ্যাক্সেস করতে পারে। এই সমস্যাটি প্রশমিত করার জন্য, আপনি একটি পুনরায় চেষ্টা করার পদ্ধতি যোগ করতে পারেন বা কমন ক্রল S3 বাকেট থেকে আপনার নিজের বালতিতে নির্দিষ্ট ডেটা সিঙ্ক করতে পারেন।
সেজমেকারের সাথে ফাইন-টিউন লামা 2
ডেটা প্রস্তুত হওয়ার পরে, আপনি এটির সাথে একটি Llama 2 মডেলকে সূক্ষ্ম-টিউন করতে পারেন। আপনি কোন কোড না লিখে SageMaker JumpStart ব্যবহার করে তা করতে পারেন। আরো তথ্যের জন্য, পড়ুন Amazon SageMaker JumpStart-এ টেক্সট জেনারেশনের জন্য ফাইন-টিউন লামা 2.
এই পরিস্থিতিতে, আপনি একটি ডোমেন অভিযোজন ফাইন-টিউনিং চালান। এই ডেটাসেটের সাথে, ইনপুট একটি CSV, JSON, বা TXT ফাইল নিয়ে গঠিত। আপনাকে একটি TXT ফাইলে সমস্ত পর্যালোচনা ডেটা রাখতে হবে। এটি করার জন্য, আপনি EMR স্পার্ক সার্ভারলেস একটি সহজবোধ্য স্পার্ক কাজ জমা দিতে পারেন। নিম্নলিখিত নমুনা কোড স্নিপেট দেখুন:
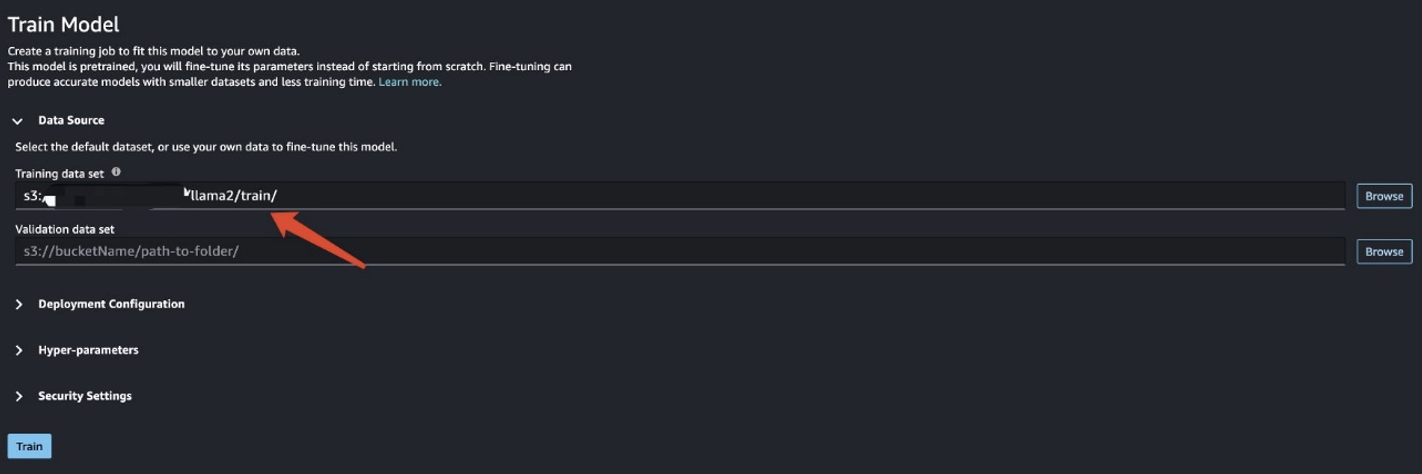
আপনি প্রশিক্ষণের ডেটা প্রস্তুত করার পরে, এর জন্য ডেটা অবস্থান লিখুন প্রশিক্ষণ তথ্য সেট, তাহলে বেছে নাও রেলগাড়ি.
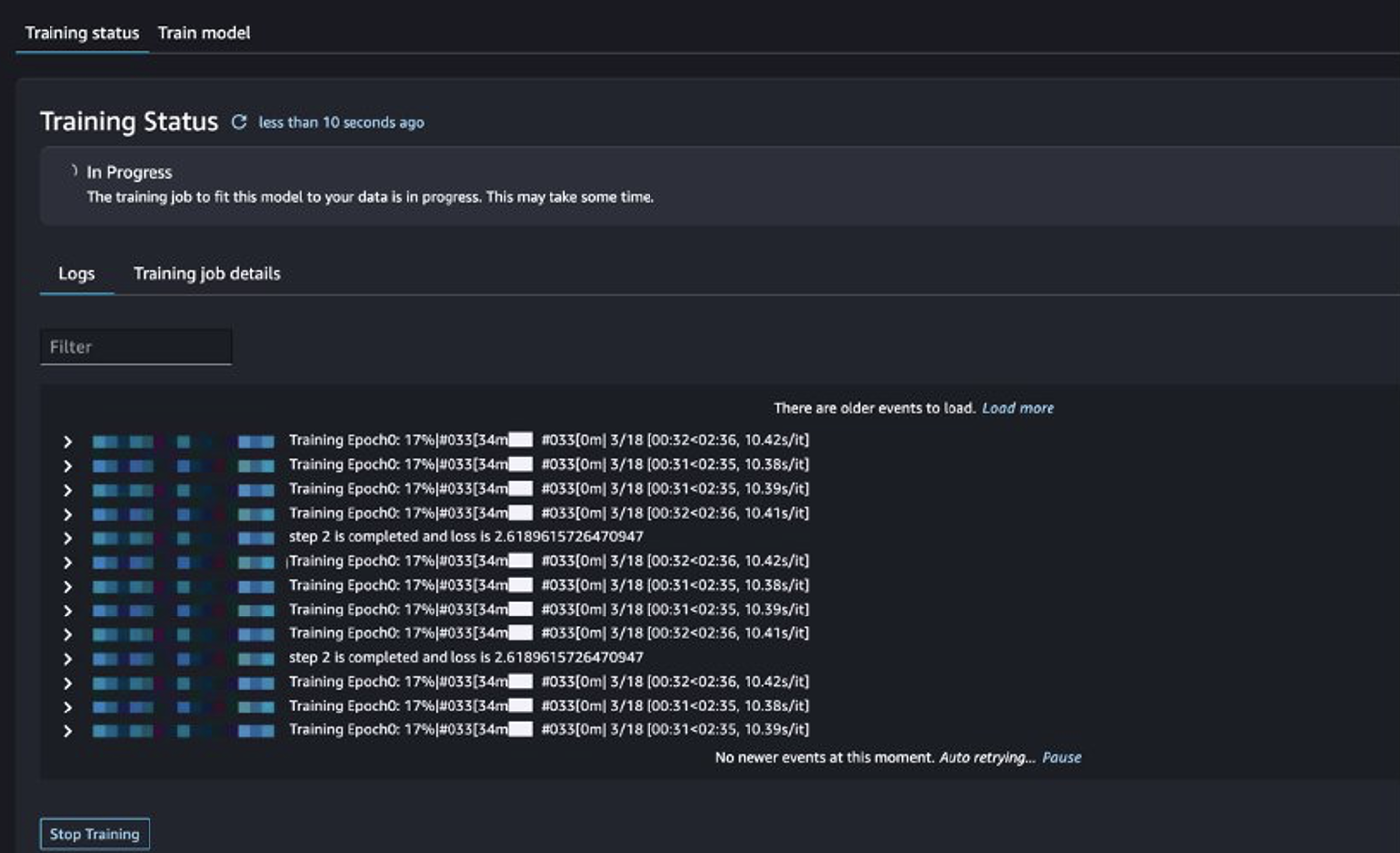
আপনি প্রশিক্ষণ কাজের অবস্থা ট্র্যাক করতে পারেন.
সূক্ষ্ম সুর করা মডেলের মূল্যায়ন করুন
প্রশিক্ষণ শেষ হওয়ার পরে, নির্বাচন করুন স্থাপন করুন SageMaker JumpStart-এ আপনার সূক্ষ্ম-টিউনড মডেল স্থাপন করতে।

মডেল সফলভাবে স্থাপন করা হয় পরে, নির্বাচন করুন নোটবুক খুলুন, যা আপনাকে একটি প্রস্তুত জুপিটার নোটবুকে পুনঃনির্দেশ করে যেখানে আপনি আপনার পাইথন কোড চালাতে পারেন।

আপনি নোটবুকের জন্য চিত্র ডেটা সায়েন্স 2.0 এবং পাইথন 3 কার্নেল ব্যবহার করতে পারেন।
তারপর, আপনি এই নোটবুকে সূক্ষ্ম-টিউন করা মডেল এবং আসল মডেলটি মূল্যায়ন করতে পারেন।
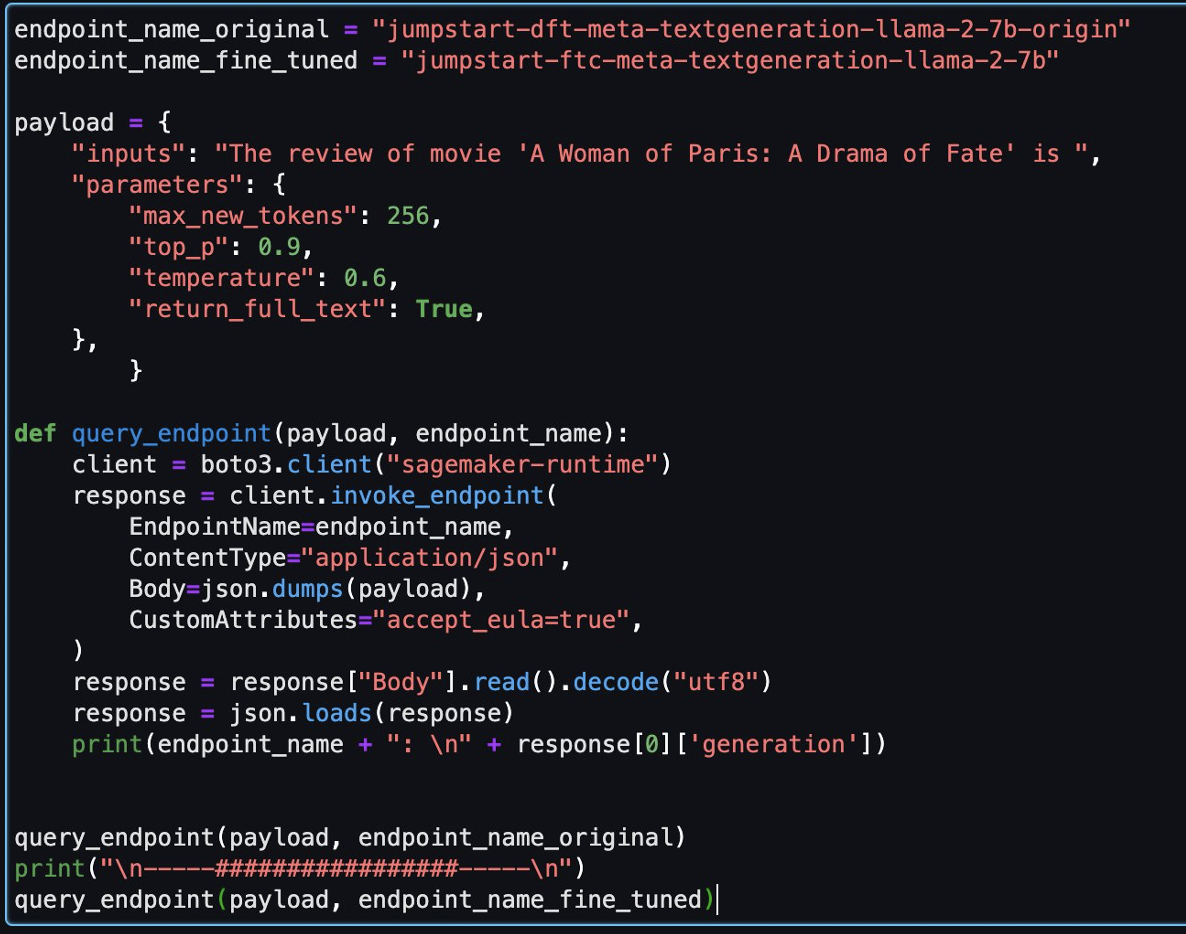
নিম্নলিখিত দুটি উত্তর একই প্রশ্নের জন্য মূল মডেল এবং সূক্ষ্ম-টিউনড মডেল দ্বারা প্রত্যাবর্তন করা হয়েছে৷

আমরা উভয় মডেলকে একই বাক্য দিয়ে সরবরাহ করেছি: "'এ ওম্যান অফ প্যারিস: এ ড্রামা অফ ফেট' চলচ্চিত্রের পর্যালোচনা" এবং তাদের বাক্যটি সম্পূর্ণ করতে দিন।
মূল মডেল অর্থহীন বাক্য আউটপুট:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
বিপরীতে, সূক্ষ্ম-টিউন করা মডেলের আউটপুটগুলি আরও একটি মুভি পর্যালোচনার মতো:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
স্পষ্টতই, সূক্ষ্ম সুর করা মডেল এই নির্দিষ্ট পরিস্থিতিতে আরও ভাল পারফর্ম করে।
পরিষ্কার কর
আপনি এই অনুশীলনটি শেষ করার পরে, আপনার সংস্থানগুলি পরিষ্কার করতে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- S3 বালতি মুছুন যা পরিষ্কার করা ডেটাসেট সংরক্ষণ করে।
- EMR সার্ভারহীন পরিবেশ বন্ধ করুন.
- সেজমেকার এন্ডপয়েন্ট মুছুন যেটি এলএলএম মডেল হোস্ট করে।
- SageMaker ডোমেন মুছুন যে আপনার নোটবুক চালায়.
আপনার তৈরি করা অ্যাপ্লিকেশনটি ডিফল্টরূপে নিষ্ক্রিয়তার 15 মিনিটের পরে স্বয়ংক্রিয়ভাবে বন্ধ হওয়া উচিত।
সাধারণত, আপনাকে অ্যাথেনা পরিবেশ পরিষ্কার করার দরকার নেই কারণ আপনি যখন এটি ব্যবহার করছেন না তখন কোনও চার্জ নেই৷
উপসংহার
এই পোস্টে, আমরা সাধারণ ক্রল ডেটাসেট এবং এলএলএম ফাইন-টিউনিংয়ের জন্য ডেটা প্রক্রিয়া করার জন্য কীভাবে ইএমআর সার্ভারলেস ব্যবহার করতে হয় তা উপস্থাপন করেছি। তারপরে আমরা দেখিয়েছি যে কীভাবে সেজমেকার জাম্পস্টার্ট ব্যবহার করতে হয় এলএলএমকে সূক্ষ্ম-টিউন করতে এবং কোনও কোড ছাড়াই এটি স্থাপন করতে হয়। EMR সার্ভারলেস এর আরও ব্যবহারের ক্ষেত্রে, পড়ুন আমাজন ইএমআর সার্ভারহীন। Amazon SageMaker JumpStart-এ হোস্টিং এবং ফাইন-টিউনিং মডেল সম্পর্কে আরও তথ্যের জন্য, দেখুন সেজমেকার জাম্পস্টার্ট ডকুমেন্টেশন.
লেখক সম্পর্কে
 শিজিয়ান তাং অ্যামাজন ওয়েব সার্ভিসেসের একজন অ্যানালিটিক্স বিশেষজ্ঞ সলিউশন আর্কিটেক্ট।
শিজিয়ান তাং অ্যামাজন ওয়েব সার্ভিসেসের একজন অ্যানালিটিক্স বিশেষজ্ঞ সলিউশন আর্কিটেক্ট।
 ম্যাথু লিম অ্যামাজন ওয়েব সার্ভিসেসের একজন সিনিয়র সলিউশন আর্কিটেকচার ম্যানেজার।
ম্যাথু লিম অ্যামাজন ওয়েব সার্ভিসেসের একজন সিনিয়র সলিউশন আর্কিটেকচার ম্যানেজার।
 ডালেই জু অ্যামাজন ওয়েব সার্ভিসেসের একজন অ্যানালিটিক্স বিশেষজ্ঞ সলিউশন আর্কিটেক্ট।
ডালেই জু অ্যামাজন ওয়েব সার্ভিসেসের একজন অ্যানালিটিক্স বিশেষজ্ঞ সলিউশন আর্কিটেক্ট।
 ইউয়ানজুন জিয়াও অ্যামাজন ওয়েব সার্ভিসেসের একজন সিনিয়র সলিউশন আর্কিটেক্ট।
ইউয়ানজুন জিয়াও অ্যামাজন ওয়েব সার্ভিসেসের একজন সিনিয়র সলিউশন আর্কিটেক্ট।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- : হয়
- :না
- :কোথায়
- $ ইউপি
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- সক্ষম
- সম্পর্কে
- প্রবেশ
- অ্যাক্সেসড
- প্রবেশযোগ্য
- হিসাবরক্ষণ
- অ্যাকাউন্টস
- অর্জন করা
- সক্রিয় করা
- যোগ
- যোগ
- আফ্রিকা
- পর
- সব
- অনুমতি
- এছাড়াও
- আশ্চর্যজনক
- মর্দানী স্ত্রীলোক
- আমাজন ইএমআর
- আমাজন সেজমেকার
- আমাজন সেজমেকার জাম্পস্টার্ট
- অ্যামাজন ওয়েব সার্ভিসেস
- পরিমাণ
- পরিমাণে
- an
- বৈশ্লেষিক ন্যায়
- এবং
- অন্য
- কোন
- এ্যাপাচি
- আপা স্পার্ক
- আবেদন
- অ্যাপ্লিকেশন
- অভিগমন
- স্থাপত্য
- রয়েছি
- AS
- At
- অস্ট্রেলিয়ান
- স্বয়ংক্রিয়
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- ডেস্কটপ AWS
- পটভূমি
- ভিত্তি
- ভিত্তি
- BE
- সুন্দর
- কারণ
- মানানসই
- আগে
- শুরু করা
- হচ্ছে
- উত্তম
- মধ্যে
- বিশাল
- বড় ডেটা
- বিলিয়ন
- শরীর
- উভয়
- নির্মাণ করা
- by
- নামক
- CAN
- পেতে পারি
- ধারণক্ষমতা
- বহন
- কেস
- মামলা
- পরিবর্তন
- চরিত্র
- চার্জ
- চেক
- চীনা
- বেছে নিন
- শ্রেণী
- পরিষ্কার
- মক্কেল
- গুচ্ছ
- কোড
- এর COM
- সাধারণ
- সাধারণভাবে
- তুলনা করা
- সম্পূর্ণ
- কনফিগার করার
- বিবেচনা
- গঠিত
- কনসোল
- প্রতিনিয়ত
- ধারণ করা
- ধারণ
- সুখী
- একটানা
- বিপরীত হত্তয়া
- অনুরূপ
- অনুরূপ
- মূল্য
- সাশ্রয়ের
- পারা
- গণনা
- আবরণ
- সৃষ্টি
- নির্মিত
- প্রথা
- ক্রেতা
- কাস্টমাইজড
- উপাত্ত
- ডেটা বিশ্লেষণ
- তথ্য প্রক্রিয়াজাতকরণ
- তথ্য বিজ্ঞান
- ডেটাসেট
- ডেভিস
- ডিলিং
- প্রতিষ্ঠান
- গভীর
- ডিফল্ট
- নির্ধারণ করা
- ডেমো
- প্রদর্শন
- প্রদর্শিত
- স্থাপন
- মোতায়েন
- বিস্তৃতি
- উদ্ভূত
- সত্ত্বেও
- বিস্তারিত
- নির্ণয়
- নকশা
- পার্থক্য
- ভিন্নভাবে
- পরিচালিত
- সরাসরি
- আলোচনা
- ডুব
- do
- কাগজপত্র
- ডোমেইন
- ডোমেইনের
- ডোনাল্ড
- Dont
- নিচে
- নাটক
- চালক
- স্থিতিকাল
- সময়
- প্রতি
- পূর্বে
- সহজ
- ঘটিয়েছে
- জোর দেয়
- সাক্ষাৎ
- প্রকৌশল
- বর্ধনশীল
- প্রবেশ করান
- পরিবেশ
- থার (eth)
- মূল্যায়ন
- উদাহরণ
- উদাহরণ
- ফাঁসি
- ব্যায়াম
- বিদ্যমান
- বিদ্যমান
- অন্বেষণ করুণ
- অন্বেষণ করা
- প্রসারিত করা
- বহিরাগত
- নির্যাস
- নিষ্কাশন
- চায়ের
- ঝরনা
- মিথ্যা
- দ্রুত
- ভাগ্য
- সুগঠনবিশিষ্ট
- কয়েক
- ক্ষেত্রসমূহ
- ফাইল
- নথি পত্র
- ছাঁকনি
- ফিল্টারিং
- পরিশেষে
- আবিষ্কার
- শেষ
- প্রথম
- অনুসরণ
- অনুসরণ
- জন্য
- বিন্যাস
- পাওয়া
- ফ্রেমওয়ার্ক
- অবকাঠামো
- থেকে
- অধিকতর
- সাধারণ
- সাধারণত
- উৎপাদিত
- প্রজন্ম
- পাওয়া
- git
- GitHub
- পথনির্দেশক
- আছে
- সাহায্য
- মধুচক্র
- হোস্টিং
- হোস্ট
- কিভাবে
- কিভাবে
- যাহোক
- এইচটিএমএল
- HTTPS দ্বারা
- শত শত
- i
- আমি
- ID
- if
- প্রকাশ
- ভাবমূর্তি
- আমদানি
- গুরুত্বপূর্ণ
- উন্নত করা
- in
- অন্তর্ভুক্ত
- অন্তর্ভুক্ত
- একত্রিত
- ক্রমবর্ধমান
- সূচক
- তথ্য
- পরিকাঠামো
- ইনপুট
- ইনপুট
- ইনস্টল
- গর্ভনাটিকা
- মধ্যে
- প্রবর্তন করা
- উপস্থাপিত
- সমস্যা
- IT
- এর
- নাবিক
- কাজ
- জবস
- JSON
- Jupyter নোটবুক
- মাত্র
- রাখা
- চাবি
- ভাষা
- ভাষাসমূহ
- বড় আকারের
- সর্বশেষ
- শুরু করা
- চালু করা
- নেতৃত্ব
- দিন
- উচ্চতা
- লাইব্রেরি
- মত
- LIMIT টি
- লাইন
- তালিকা
- পাখি
- শিখা
- এলএলএম
- স্থানীয়
- অবস্থিত
- অবস্থান
- যুক্তিবিদ্যা
- লগইন
- দেখুন
- খুঁজছি
- খুঁজে দেখো
- মেশিন
- রক্ষণাবেক্ষণ
- করা
- মেকিং
- পরিচালক
- পরিচালক
- অনেক
- মানচিত্র
- বৃহদায়তন
- মে..
- পদ্ধতি
- সম্মেলন
- পূরণ
- উল্লেখ
- মেটা
- মেটাডাটা
- পদ্ধতি
- মিনিট
- প্রশমিত করা
- মডেল
- মডেল
- মাসিক
- অধিক
- সেতু
- চলচ্চিত্র
- চলচ্চিত্র
- অনেক
- বহু
- নাম
- নাম
- ন্যাভিগেশন
- প্রয়োজনীয়
- প্রয়োজন
- নেটওয়ার্ক
- নতুন
- পরবর্তী
- না।
- নোড
- নোটবই
- নোটবুক
- প্রাপ্ত
- অক্টোবর
- of
- on
- ONE
- কেবল
- খোলা
- ওপেন সোর্স
- পছন্দ
- or
- মূল
- অন্যান্য
- বাইরে
- রূপরেখা
- আউটপুট
- আউটপুট
- শেষ
- অগ্রাহ্য করা
- নিজের
- প্যাক
- প্যাকেজ
- শার্সি
- কাগজ
- সমান্তরাল
- পরামিতি
- প্যারী
- অংশ
- পথ
- পাথ
- বেতন
- পিডিএফ
- সম্প্রদায়
- কর্মক্ষমতা
- ক্রিয়াকাণ্ড
- সঞ্চালিত
- কাল
- পেটবাইট
- পিটার
- ফটোগ্রাফার
- মাচা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- চক্রান্ত
- পয়েন্ট
- জনপ্রিয়
- পোস্ট
- চালিত
- প্রাক
- পূর্ববর্তী
- প্রস্তুত করা
- প্রস্তুত
- প্রাথমিক
- প্রক্রিয়া
- প্রক্রিয়াজাত
- প্রক্রিয়াজাতকরণ
- উত্পাদনের
- অনুরোধ জানানো
- প্রদান
- প্রদত্ত
- উপলব্ধ
- প্রদানের
- প্রকাশ্যে
- উদ্দেশ্য
- করা
- পাইথন
- প্রশ্ন
- প্রশ্ন
- দ্রুত
- কাঁচা
- মূল তথ্য
- পৌঁছনো
- পড়া
- প্রস্তুত
- সাম্প্রতিক
- সম্প্রতি
- সুপারিশ করা
- নথি
- পড়ুন
- রেফারেন্স
- নিয়মিতভাবে
- সম্পর্ক
- মুক্ত
- মেরামত
- প্রতিস্থাপন করা
- অনুরোধ
- প্রয়োজনীয়
- আবশ্যকতা
- Resources
- প্রতিক্রিয়া
- প্রতিক্রিয়া
- ফল
- ফলাফল
- এখানে ক্লিক করুন
- পর্যালোচনা
- অধিকার
- ভূমিকা
- ররি
- চালান
- দৌড়
- রান
- ঋষি নির্মাতা
- একই
- সংরক্ষণ করুন
- স্কেল
- দাঁড়িপাল্লা
- আরোহী
- স্ক্যান
- দৃশ্যকল্প
- বিজ্ঞান
- লিপি
- স্ক্রিপ্ট
- সেকেন্ড
- অধ্যায়
- বিভাগে
- দেখ
- রেখাংশ
- নির্বাচন করা
- আত্ম
- জ্যেষ্ঠ
- বাক্য
- Serverless
- সার্ভার
- সেবা
- সেট
- বিন্যাস
- বিভিন্ন
- সে
- সংক্ষিপ্ত
- উচিত
- প্রদর্শিত
- তাত্পর্য
- অনুরূপ
- থেকে
- একক
- সাইট
- আয়তন
- আস্তে আস্তে
- টুকিটাকি
- So
- সমাধান
- সলিউশন
- সুপ
- উৎস
- স্ফুলিঙ্গ
- বিশেষজ্ঞ
- নির্দিষ্ট
- এসকিউএল
- SSH
- শুরু
- শুরু হচ্ছে
- বিবৃতি
- বিবৃতি
- অবস্থা
- ধাপ
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- এখনো
- থামুন
- দোকান
- সঞ্চিত
- দোকান
- গল্প
- অকপট
- কৌশল
- স্ট্রিং
- চিত্রশালা
- জমা
- জমা
- সফলভাবে
- এমন
- যথেষ্ট
- উপযুক্ত
- সুইচ
- সুসংগত.
- টেবিল
- গ্রহণ করা
- লক্ষ্য
- কার্য
- কাজ
- tensorflow
- শর্তাবলী
- পরীক্ষা
- পাঠ
- পাঠ্য প্রজন্ম
- যে
- সার্জারির
- তাদের
- তাহাদিগকে
- তারপর
- সেখানে।
- এইগুলো
- তারা
- তৃতীয় পক্ষের
- এই
- তিন
- দ্বারা
- সময়
- টাইমস্ট্যাম্প
- থেকে
- পথ
- প্রশিক্ষণ
- ভ্রমনের
- সত্য
- চেষ্টা
- দুই
- ধরনের
- অধীনে
- কাঠামোগত
- আপডেট
- URL টি
- ব্যবহার
- ব্যবহার ক্ষেত্রে
- ব্যবহৃত
- ব্যবহারকারী
- ব্যবহারকারী পর্যালোচনা
- ব্যবহারকারী
- ব্যবহার
- ব্যবহার
- সংস্করণ
- ভার্চুয়াল
- ভলিউম
- পদব্রজে ভ্রমণ
- প্রয়োজন
- চেয়েছিলেন
- গুদাম
- ছিল
- উপায়..
- উপায়
- we
- ওয়েব
- ওয়েব সার্ভিস
- সপ্তাহান্তিক কাল
- আমরা একটি
- কি
- কখন
- যেহেতু
- যে
- যখন
- হু
- ওয়াইল্ডলাইফ
- ইচ্ছা
- উইলিয়াম
- সঙ্গে
- মধ্যে
- ছাড়া
- নারী
- কাজ করছে
- মূল্য
- লেখা
- লেখা
- উত্পাদ
- আপনি
- আপনার
- zephyrnet